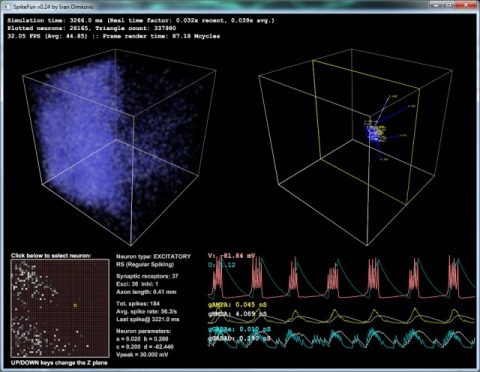
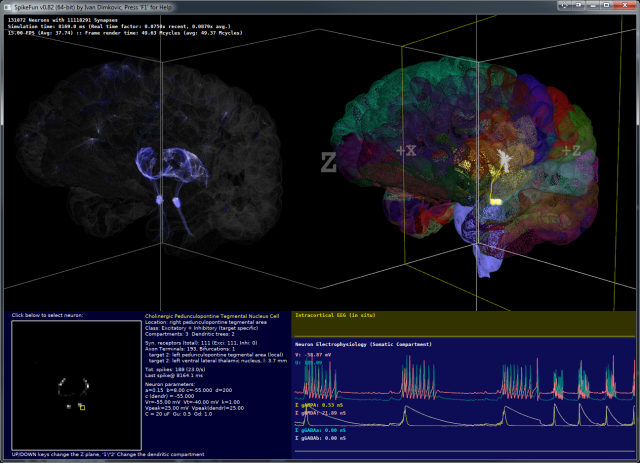
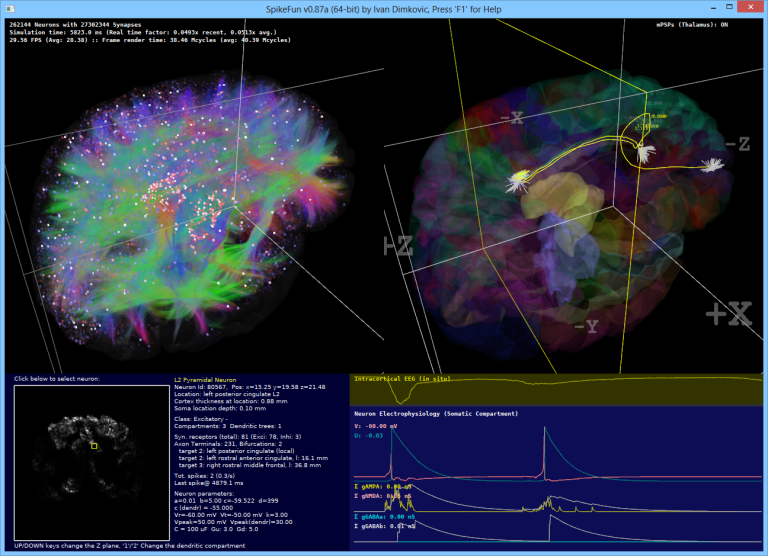
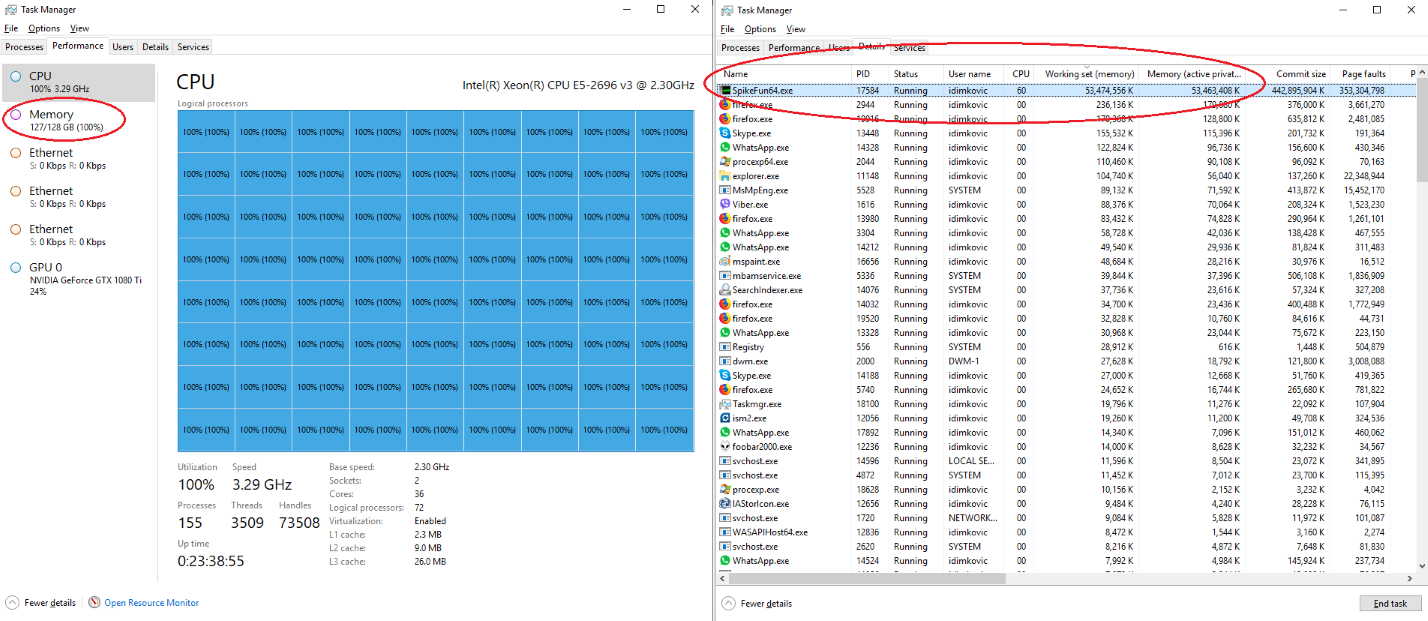
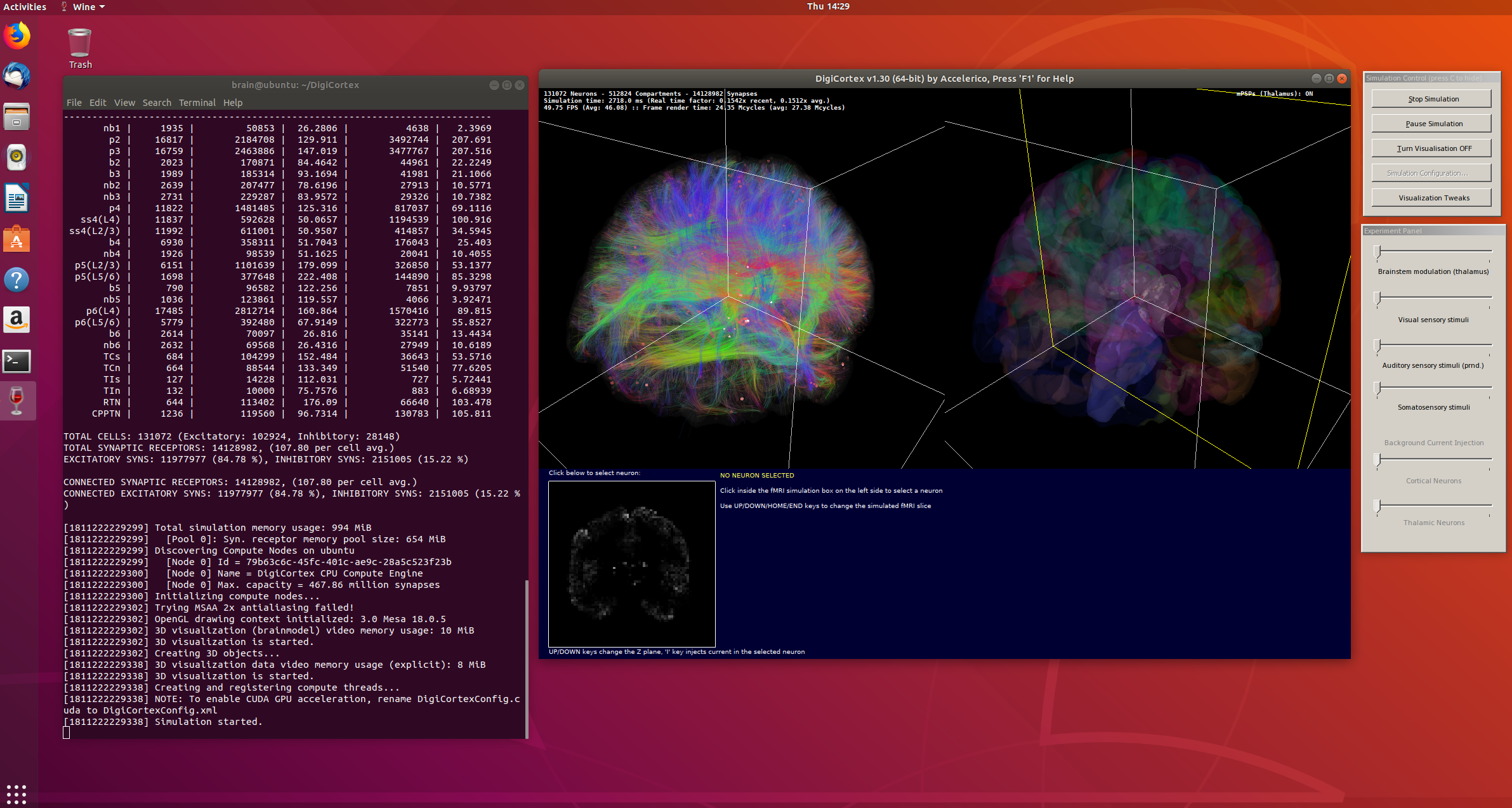
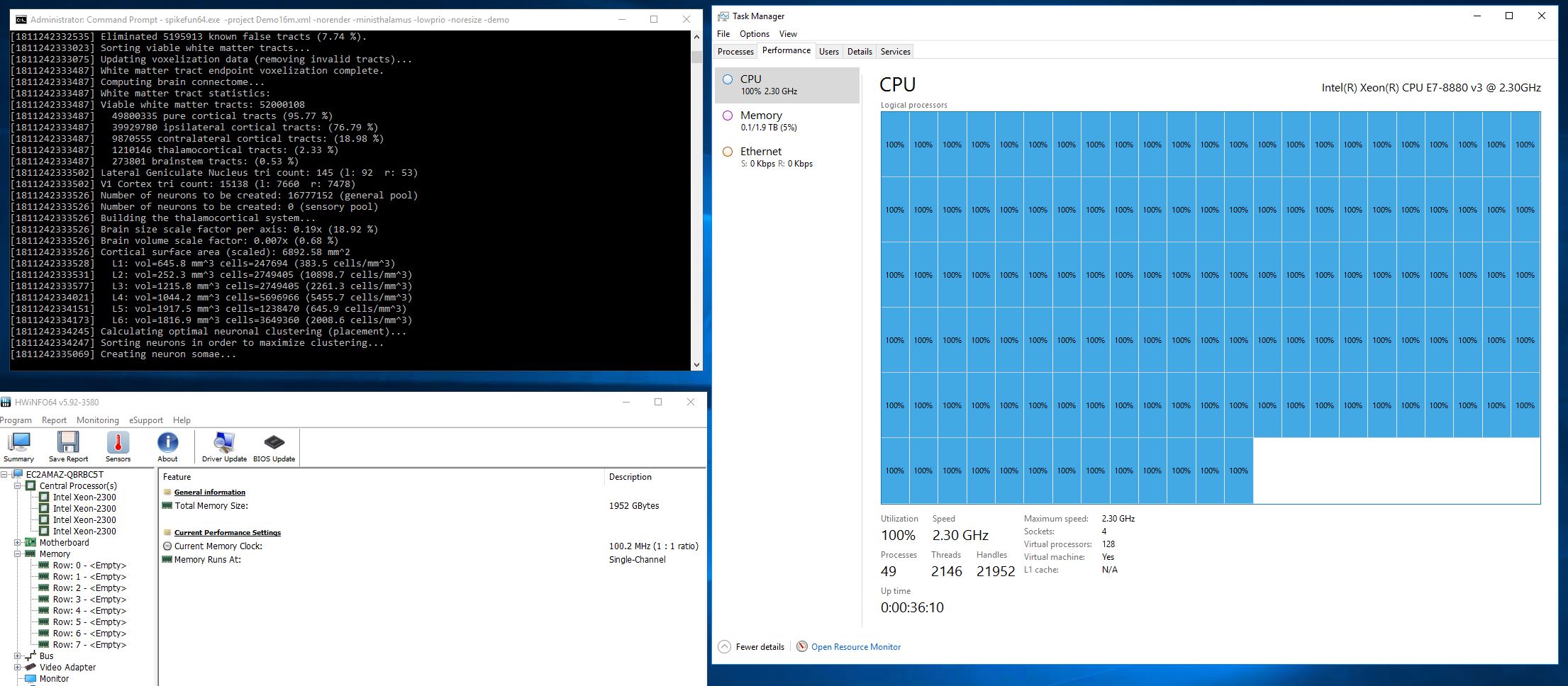
SpikeFun je mali simulator bioloski-realisticnih neuronskih mreza na kome radim vec neko vreme... htedoh da napisem mali post o tome za ljude koje zanimaju neuronske mreze 3-ce generacije (spiking neural networks)...
SpikeFun je u stvarni front-end za "DigiCortex" biblioteku koja je engine za simulaciju unutra i koju polako razvijam kao hobi u slobodno vreme.
Sta se simulira
DigiCortex modelira neurone do nivoa sinaptickih receptora uz pomoc Izhikevich-evog neurona i/ili Brette-Gerstner / "AdEx" modela neurona. Izhikevich-ev i AdEx modeli su fenomenoloski, za razliku od, recimo, Hodgkin Huxley modela sto znaci da su dizajnirani da reprodukuju ponasanje neurona a ne detaljno svaku od jonskih struja, ali su i pored toga u stanju da vrlo verno repliciraju ponasanje 20 vrsta kortikalnih neurona uz drasticno smanjenu kompleksnost u odnosu na Hodgin Huxley model. Izhikevich-evi i Brette-Gerstnerovi modeli su, zapravo, najbolji odnos izmedju bioloske realnosti i kompleksnosti ako se simulacija radi na nivou akcionih potencijala (spajkova).
Moja implementacija je trenutno optimizovana za Intel platformu, ukljucujuci i Sandy Bridge (AVX), mada mi je glavni cilj da implementiram simulaciju na GPU platformama (CUDA, OpenCL) posto je update provodljivosti receptora posao kao stvoren za graficke procesore. Vec je uradjen task-manager koji uposljava worker niti, i koji ce vam lepo zakucati procesor na 99-100% bez obzira na broj jezgara (limit je 256 za sada :-)
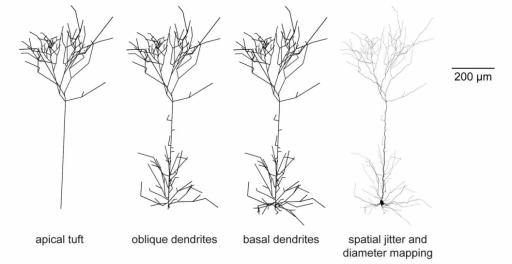
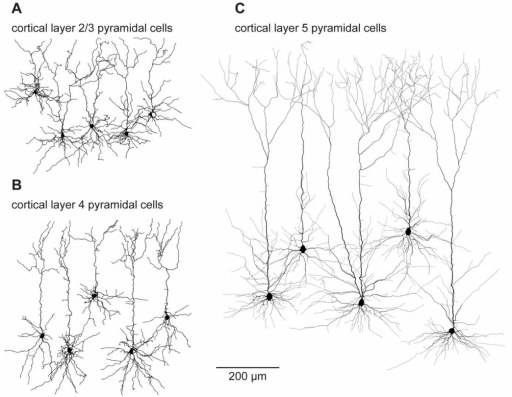
Neuroni su modelirani kao vise-kompartmentalni modeli gde broj kompartemta ide do oko 30 za sad. Simulirani su kortikalni piramidalni, spiny-stellate, basket i non-basket neuroni kao i talamicki neuroni (RTN, talamicki interneuroni i talamo-kortikalni "relej" neuroni).
U trenutnim simulacijama je moguce dobiti 5 vrsta ponasanja neurona (Regular Spiking, Low Threshold Spiking, Intrinstically Bursting, Chattering, Fast Spiking) sto je podskup eksperimentalno izmerenih ponasanja neurona u sivoj masi.
Takodje, modelirani su i najvazniji hemijski receptori:
- Glutamatergicki (pobudjujuci): AMPA i NMDA receptori
- GABAergicki (inhibitorni): GABAa i GABAb receptori
Receptorska kinetika (kratkotrajna potencijacija i depresija) je, takodje, implementirana uz pomoc fenomenoloskog modela (Markram et. al.) i modelira kratkotrajnu sinapticku plasticnost koja je u saglasnosti sa eksperimentalnim podacima.
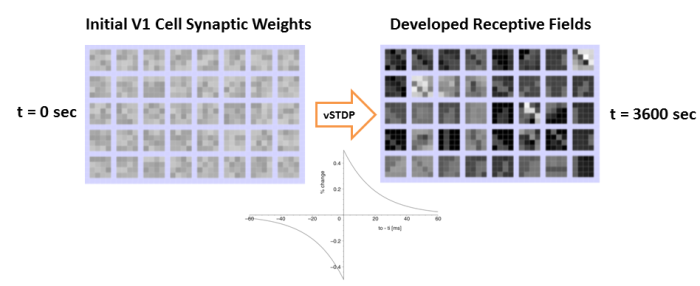
Osim kratkotrajne plasticnosti, modelirana je i dugotrajna sinapticka plasticnost vezana za tajming dolazecih akcionih potencijala (STDP - Spike Timing Dependent Plasticity) koja je, takodje, eksperimentalno potvrdjena i vrlo verovatno predstavlja jednu od glavnih osnova za ucenje u sivoj masi. STDP funkcionise na znacajno duzem intervalu od kratkotrajne sinapticke plasticnosti i, za razliku od nje, menja sinapticke jacine.
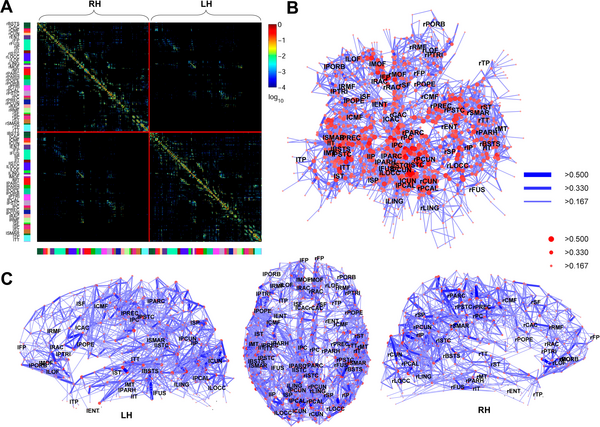
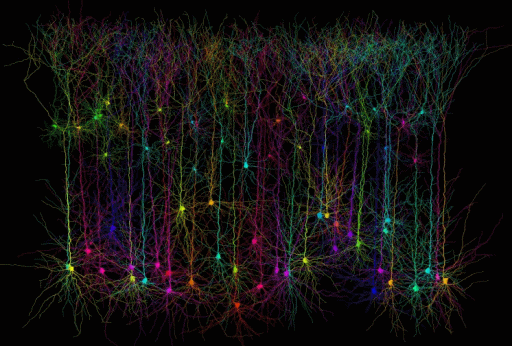
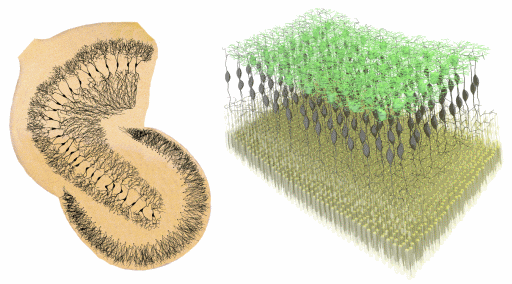
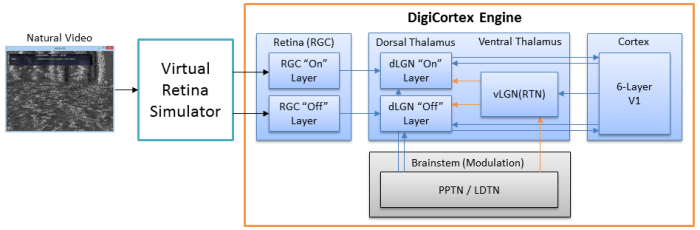
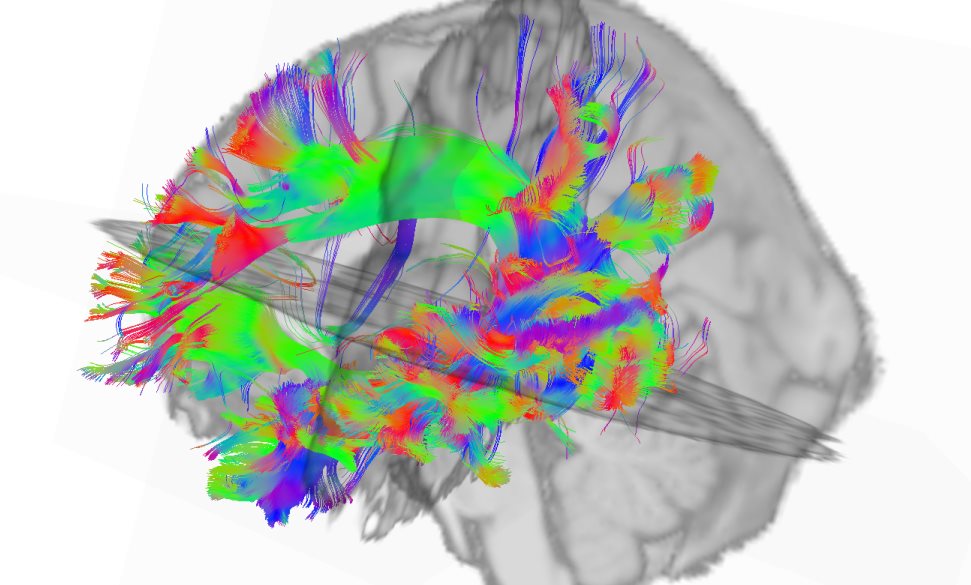
Simulator modelira korteks i talamus. Neuroni se alociraju po kortikalnim slojevima (relativne debljine slojeva je moguce menjati) i na osnovu globalne anatomije dobijene vokselizacijom MRI snimka. Neuroni se lokalno (unutar Brodmanovih zona) uvezuju na osnovu statistickih analiza macijeg vizuelnog korteksa (Binzegger et al., 2004) dok se globalna povezanost neurona modelira na osnovu analize difuznih MRI snimka (DSI - Diffusion Spectrum Imaging tehnika) i uparivanjem sa anatomskim modelom radi dobijanja konektoma.
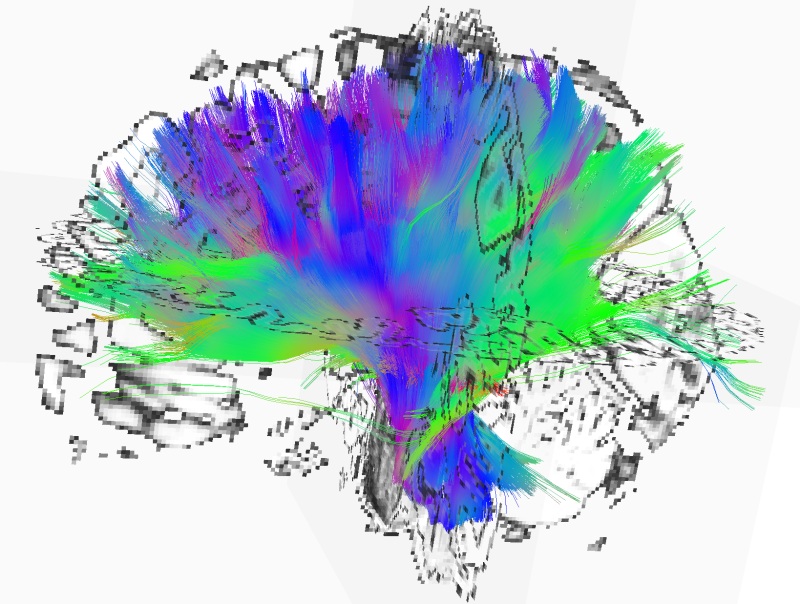
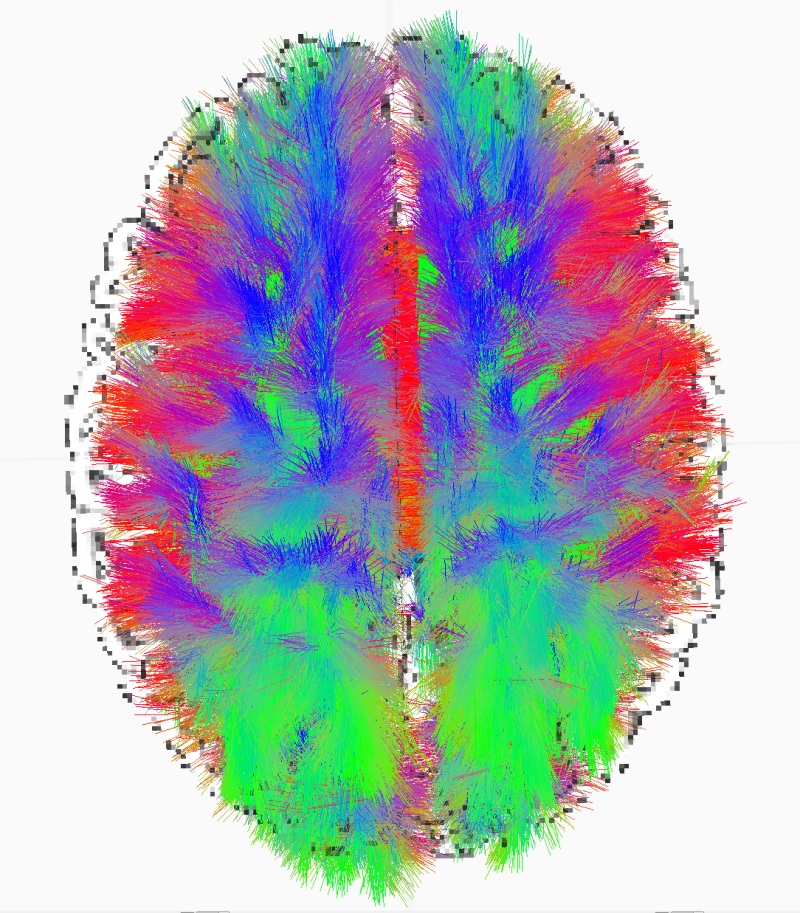
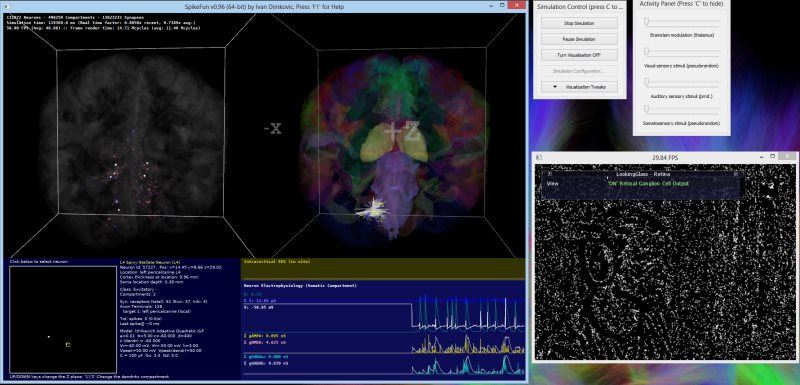
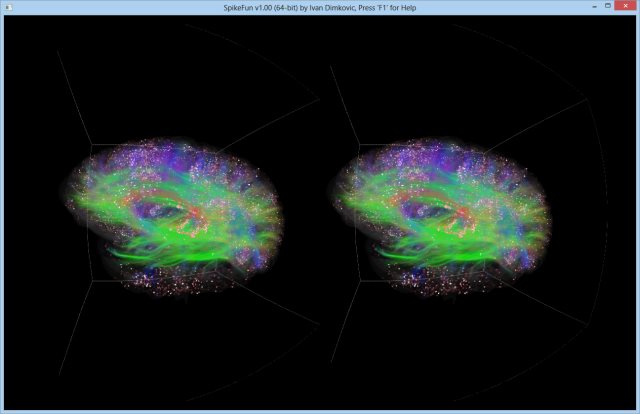
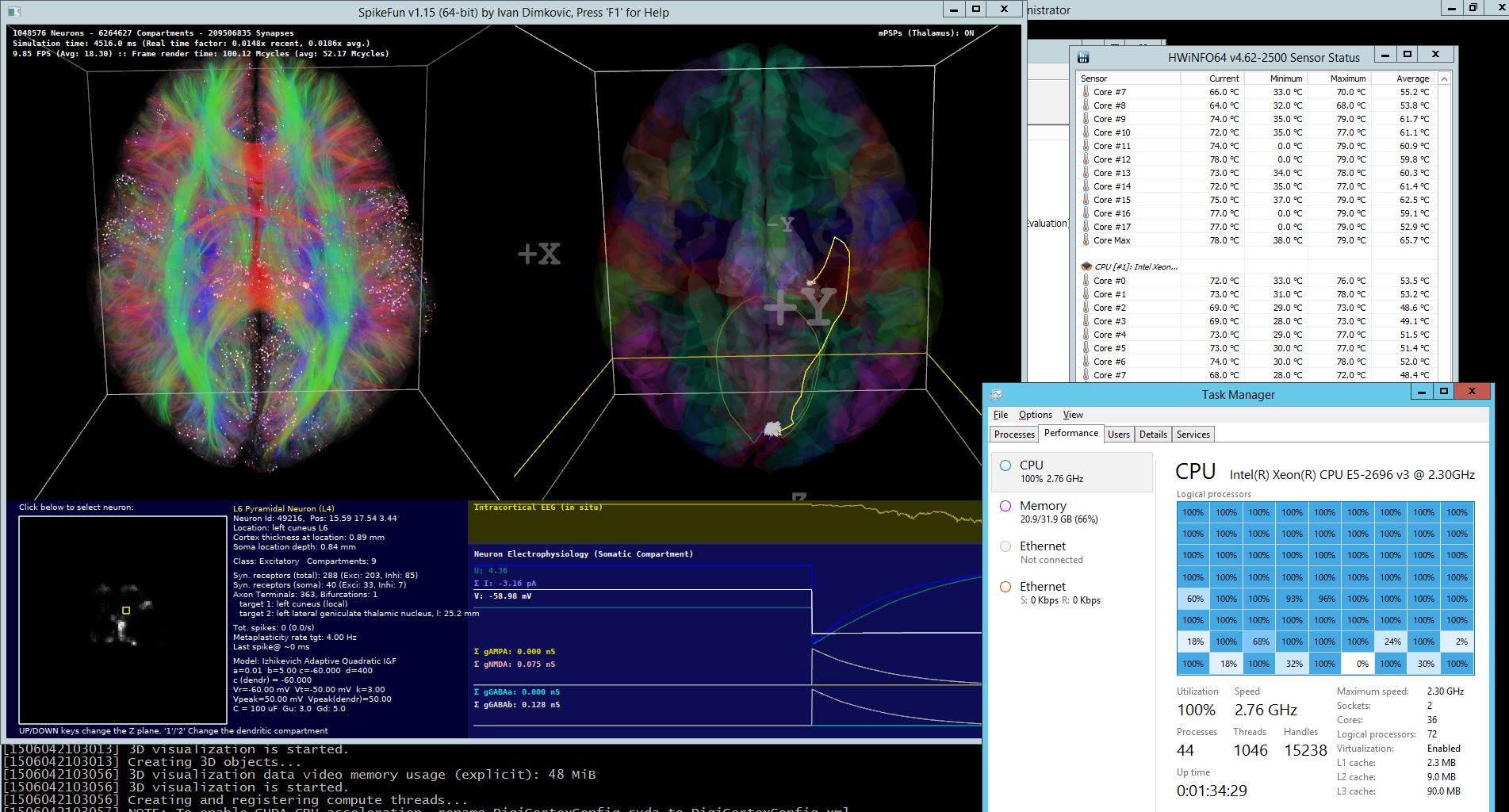
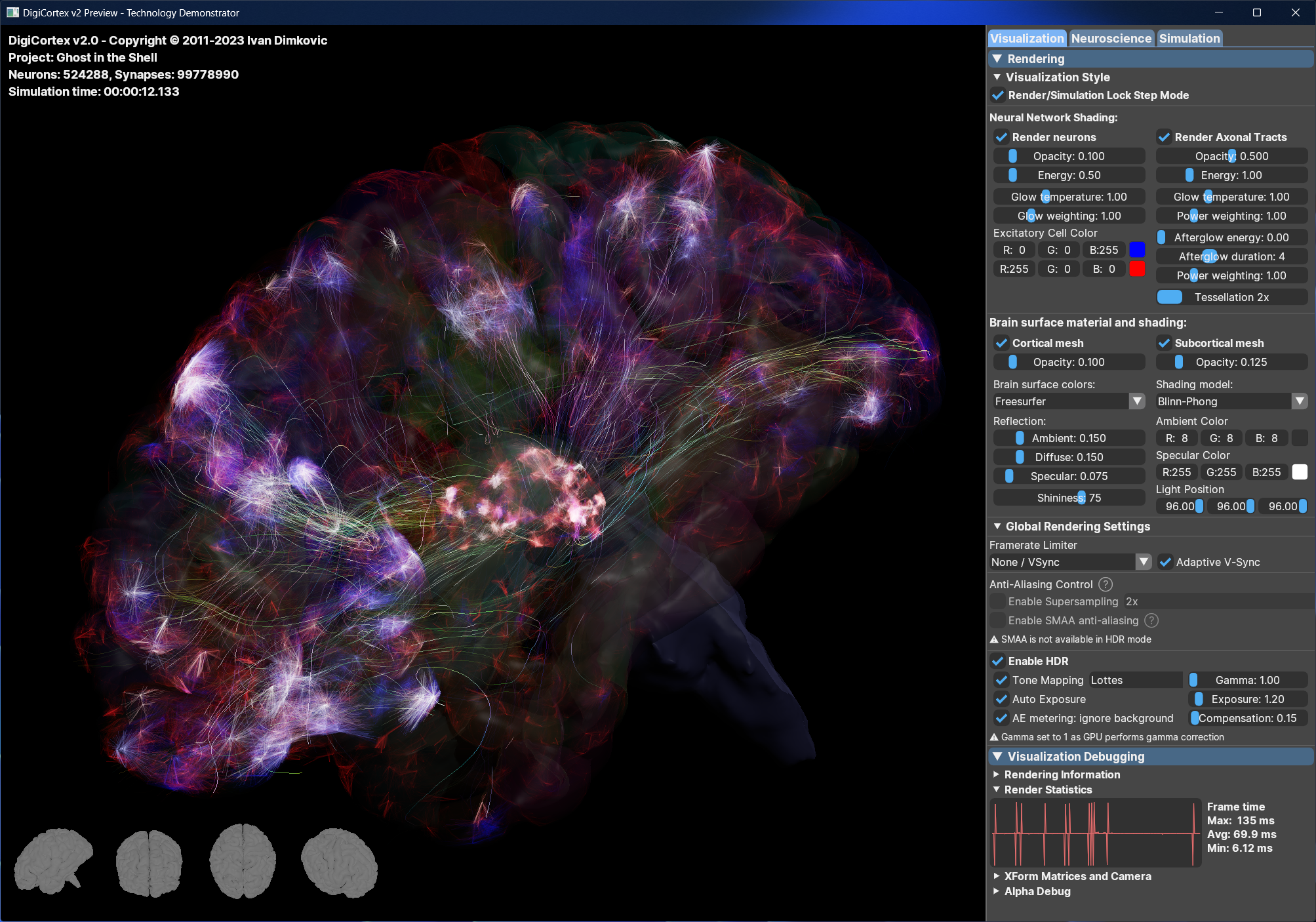
Takodje, implementiran je i OpenGL vizualizator koji mozete videti na slici i videu dole. Vizualizator nije bas super-optimizovan ali ipak koristi VBO (vertex-buffer-objects) tako da je relativno brz na bilo kakvoj diskretnoj grafickoj proizvedenoj u poslednje 3-4 godine... Doduse, za ogromne simulacije preporucujem jaku graficku posto dosta slabih grafickih kartica ima niske limite za velicinu VBO objekata (ako dobijate gresku pri pravljenju simulacije vezanu za VBO - nemate dovoljno memorije na grafickoj za simulaciju), dok ne implementiram volumetricko renderovanje posto se za sada sve renderuje kao prava geometrija ("seljacki" :-).
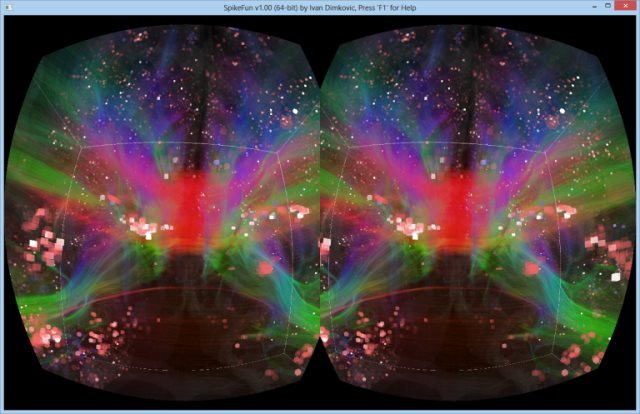
Za sada je moguce sa F5 videti FFT power spectrum plot tj. koncentraciju aktivnosti u delta/alfa/beta/gama frekventnim regionima kao i odnose sinaptickih jacina tokom vremena (sinapticke jacine se menjaju zbog STDP-a)
Prvi Rezultati
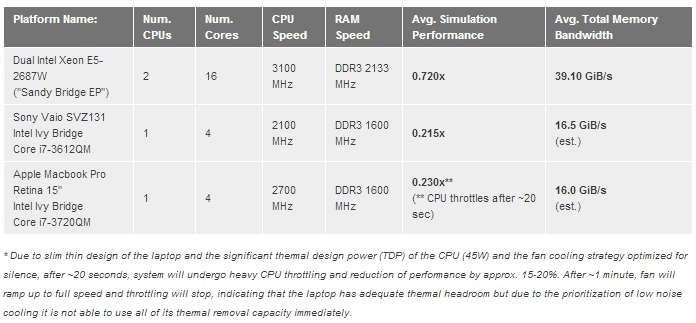
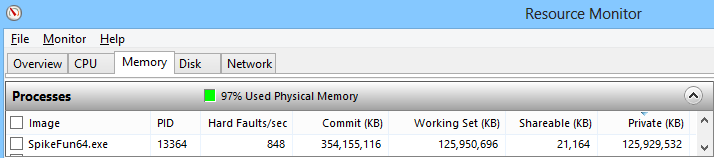
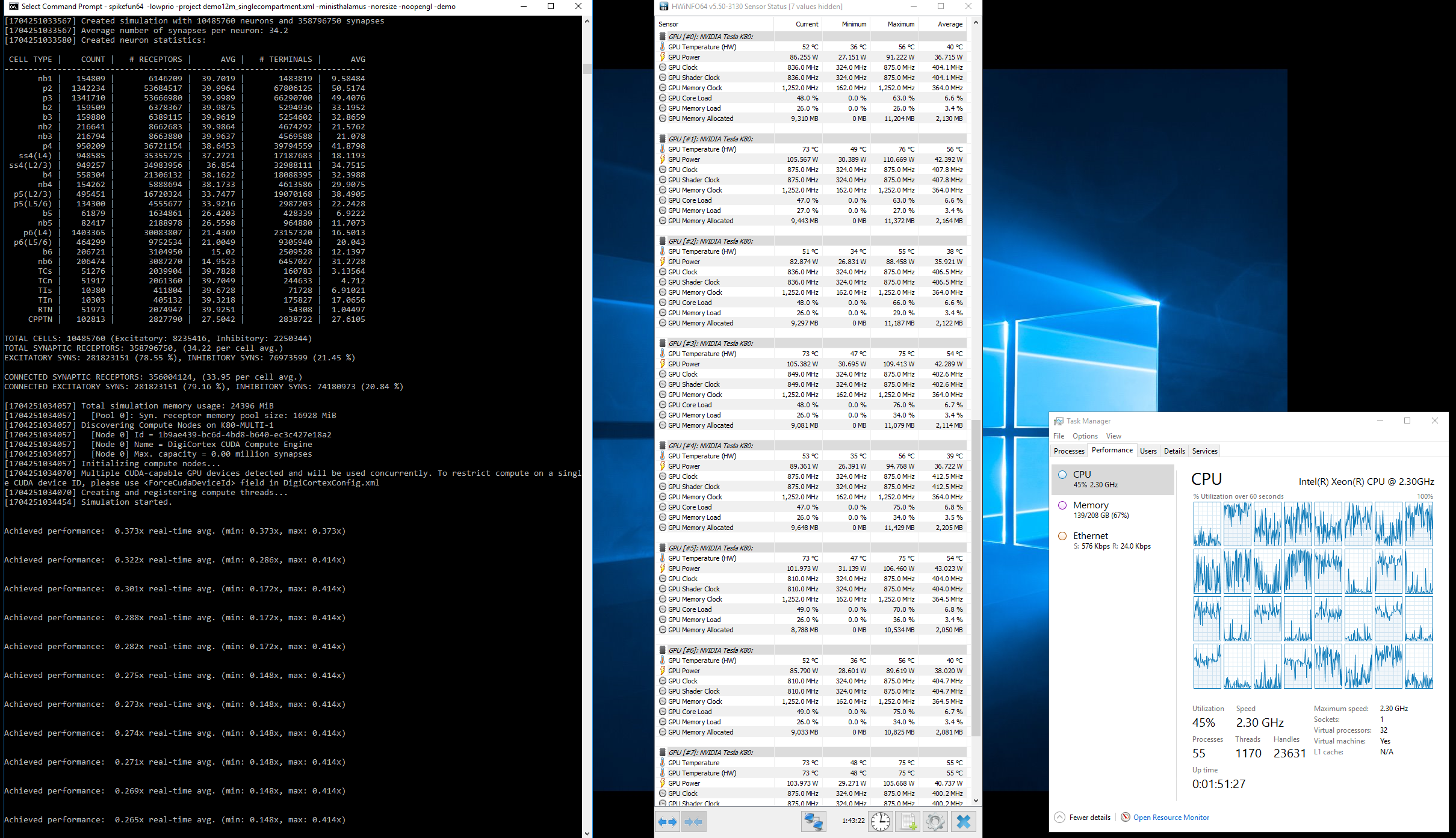
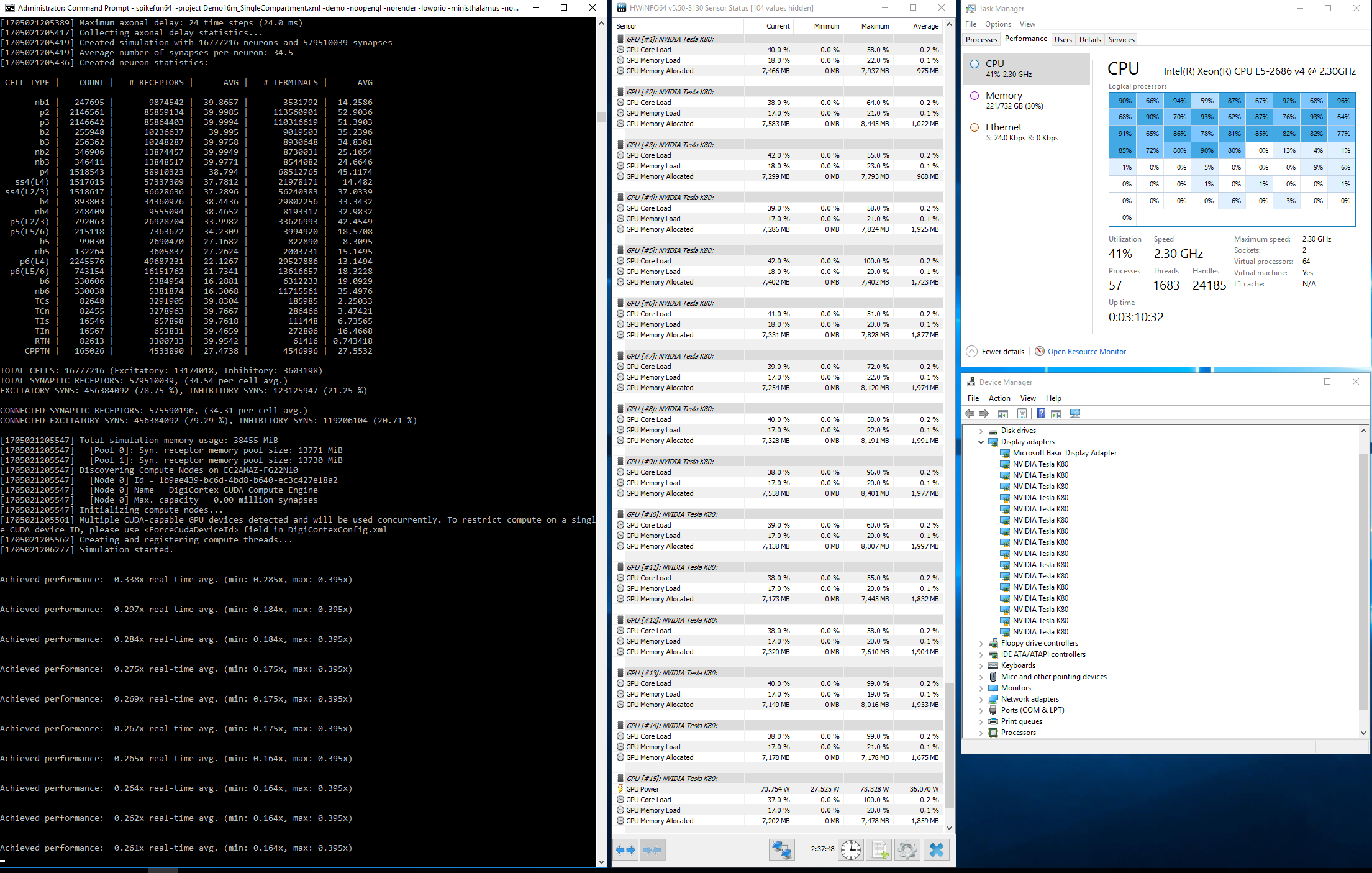
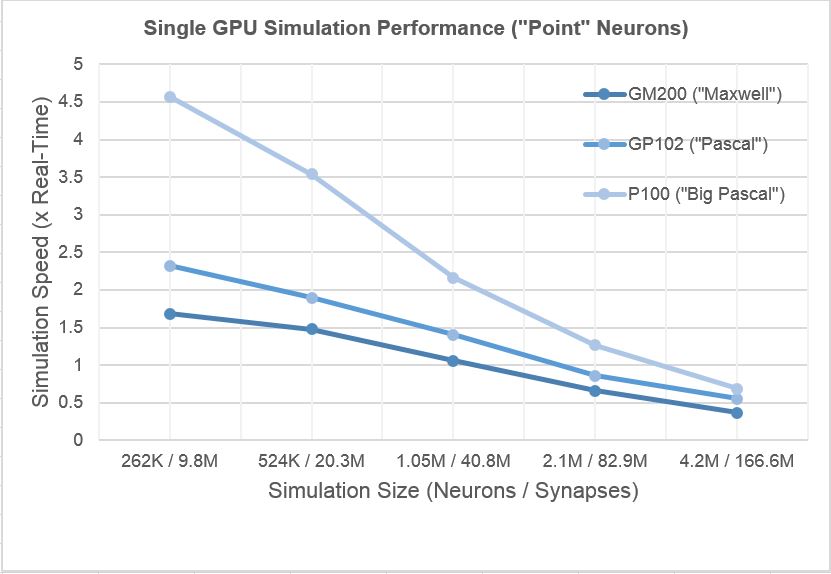
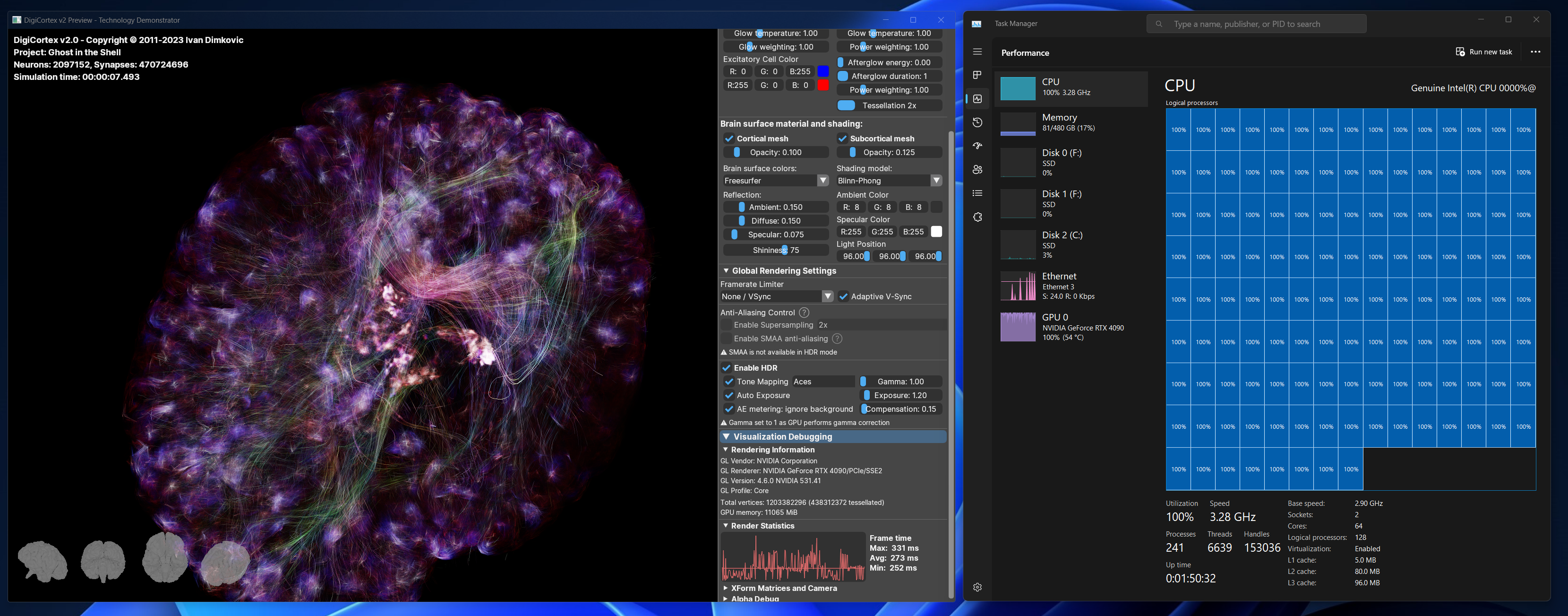
Video dole predstavlja talamokortikalni sistem od 16.7 miliona neurona sa 3.52 milijarde sinapsi. Sama simulacija zauzima oko 350 GB memorije i izvrsava se brzinom od ~0.0005x - ~0x001x realnog vremena na dual Xeon 2687W masini).
Obavezno ukljucite 720p ili 1080p - ako imate 27" ili 30" monitor koji mogu da prikazu 2560 piksela horizontalo, odaberite "original video" u opciji za kvalitet :-)
Prva stvar koja odmah upada u oci je vrlo brza organizacija mreze u nezavisne klastere aktivnosti koji su desinhronizovani na simularnom EEG-u (koji se vidi pri kraju videa)
Ako se mreza ostavi da simulira vise od 15-20 minuta (simulacionog vremena), STDP ce bitno izmeniti ponasanje mreze i "urediti" opaljivanja neurona. Ako bi ste ostavili stalni stimulus i naprasno ga iskljucili posle tog vremena, neko vreme ce ostati "senka" zato sto su se simulirani neuroni "navikli" na konstantnu prisutnost stimulusa bas kao i pravi neuroni....
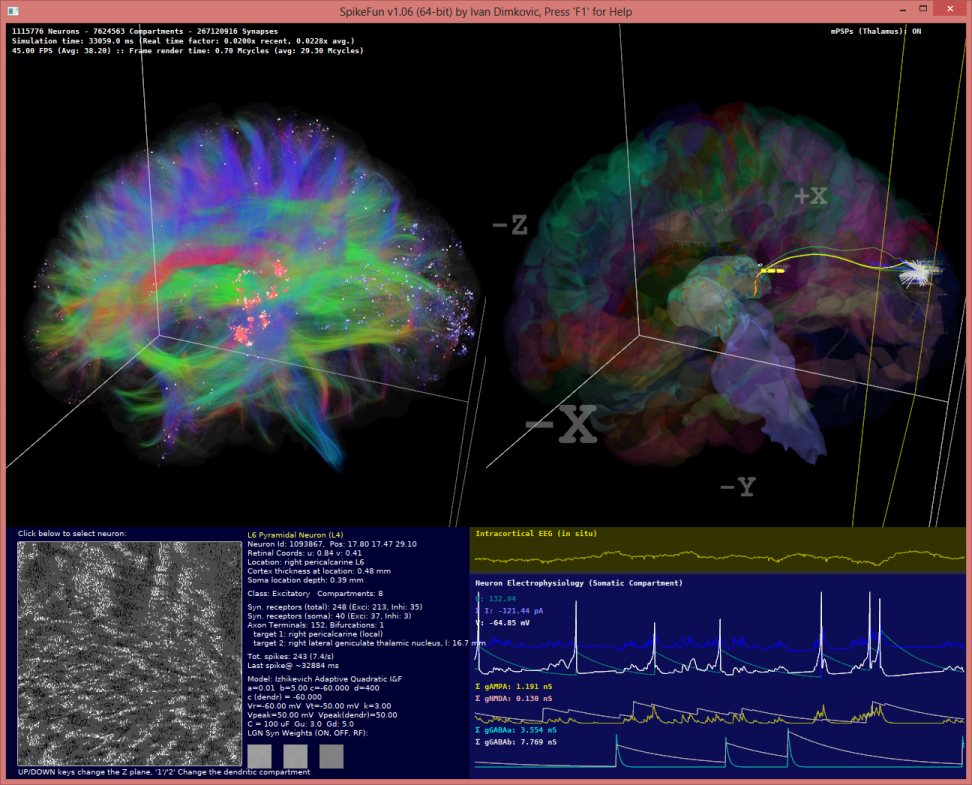
Evo kako izgleda i radni prozor:
Sledeci koraci
Postoji dosta TODO stvari koje hocu da uradim, i koje zavise od kolicine slobodnog vremena:
- Multi-kompartmentalni neuroni [DONE]
- Slobodna geometrija (sto ce omoguciti simulaciju kortikalnih kolona pa i kompletne sive mase i talamusa) [DONE]
- CUDA/OpenCL procesiranje sto bi trebalo da donese bar 10-20x ubrzanja (nadam se ;-) [DONE]
- Klijent/Server model koji ce omoguciti klaster procesiranje [IN PROGRESS]
- I/O sa bazom podataka sto ce omoguciti snimanje i editovanje mreza
- API za kontrolu i interakciju, i povezivanje sa senzorima
Probajte
Koga zanima - SpikeFun moze skinuti ovde - trenutna verzija je 0.90:
[Ovu poruku je menjao Ivan Dimkovic dana 25.08.2013. u 17:28 GMT+1]
[ balavi @ 25.09.2011. 21:43 ] @
Samo mogu da kažem jedno
Dimke, legendo, ti si moj idol .....
[ xtraya @ 25.09.2011. 23:47 ] @
Simpaticno... osim sto mi spaljuje cooler laptopa, predji na serotoninske receptore :) oni su zaduzeni za feeling ...
no, sta sa ranvijerovim cvorovima? kako uopste definises brzinu propagacije obzirom da se razlikuje drasticno prema dendritu i prema axonu ...
[ Ivan Dimkovic @ 26.09.2011. 09:27 ] @
Za sada je modelirana propagacija akcionih potencijala kroz aksone sa mijelinskim omotacem (sa ranvijerovim cvorovima) - ona je u proseku 1 m/s u sivoj masi.
Uskoro cu dodati i propagaciju kroz aksone bez mijelinskog omotaca, ta brzina je oko 0.15 m/s u proseku u sivoj masi.
Zbog trenutnog ogranicenja na 1 kompartment nema kasnjenja unutar samih dendrita, zbog toga hocu da uvedem visestruke kompartmente.
[ Ivan Dimkovic @ 26.09.2011. 20:27 ] @
@xtraya,
5-HT (serotoninski) receptori nisu modelirani zato sto je njihovo dejstvo posredno i vrlo kompleksno. Serotoninski receptori modulisu oslobadjanje drugih neurotransmitera (izmedju ostalog, glutamata i GABA-e, cije je dejstvo modelirano u trenutnom modelu preko NMDA i GABAx receptora) - mozda jednog dana, ali za sada moram prvo da ubacim neke jednostavnije, a bitnije stvari :-)
Ja sam na faksu imao predmete iz oblasti medicine, ali ne na nivou na
kome se to sve izucava na medicinkom (ovde posebno mislim na funkcionisanje
CNS-a i biohemiju oko toga, transmitere, itd), morao bih da uzmem Gajtona u
ruke i dobro se podsetim da bih pohvatao tacno sta ovde zapravo radis :)
Port za Linux - hoce li ga biti? ;)
Nego mi sad pade nesto na pamet... neurotransmitera nema neograniceno,
kako se u simulaciju uklapa prica o "zamoru" sinapsi, tj. trosenju pojedinih transmitera? :)
[ Ivan Dimkovic @ 27.09.2011. 12:23 ] @
Citat:
Svaka čast za trud, Dimke.
Hehe hvala... ma ovo mi je zanimacija za mozak malo da mi ne zakrzlja kad omatorim :-)
Videcemo za Linux port - u principu nema u kodu nicega Windows-specificnog osim GUI elemenata, sve ostalo je cist C/C++ i OpenGL... Videcu mozda da raspisem sve GUI elemente u QT-u posto mi je muka od Win32 API-ja... verovao ili ne, ali najvise vremena sam izgubio na Windows dijalozima i glupostima a ne na samom kodu - sto je najgore, odlucio sam da koristim cist Win32 API a ne MFC... #@#@@*#
Sto se neurotransmitera tice, sam termin objedinjuje razne vrste jedinjenja (amino kiseline, peptidi, ...) tako da nije bas moguce pricati o jednom mehanizmu obnavljanja - ali, u principu, za svaki neurotransmiter postoji sistem samo-regulacije koji obezbedjuje da se u mozgu nalazi optimalna kolicina (kod zdravih organizama, naravno).
Trenutni model ne modelira metabolizam neurotransmitera ali se depresija sinapsi posle aktivnosti modelira kroz kratkotrajnu sinapticku plasticnost.
To mozes lako videti ako pritisnes "E" sto ce poceti da ubacuje stimulus na svakih 50 msec - ako posle nekog vremena zaustavis ubacivanje (sa E) videces da ostaje "rupa" na tom mestu kratko vreme.
[ Srđan Pavlović @ 27.09.2011. 12:41 ] @
Na zdrav organizam sam i mislio, naravno, ali sam mislio na normalan
fizioloski zamor usled trosenja razlicitih neuro-transmitera lokalno, ne neki patoloski proces.
Nego... jesam ja to sanjao (ili si ti editovao nesto, hehe) ili je zaista negde bio pomenut
primarni vizuelni korteks (striatni, V1) u nekom kontekstu... ili je to bila neka druga tema?
[ Ivan Dimkovic @ 27.09.2011. 13:18 ] @
Primarni vizuelni korteks? Hmm... mislim da je bilo u drugoj temi o "citanju misli" gde se cesto koriste argumenti eksperimenata koji "citaju" sta covek vidi tako sto rade analizu neuronske aktivnosti u primarnom vizuelnom (V1) korteksu.
Fora je da je primarni vizuelni korteks najvise obradjivan deo sive mase sa bukvalno najvecom bazom naucnih radova i saznanja - medjutim transformacija podataka je i dalje dovoljno trivijalna da je uz pomoc danasnjih racunara relativno lako moguce rekonstuisati "sliku" koju covek vidi u primarnom korteksu. Tako da je koriscenje tih uspeha prilicno nekorektno kao nekakvo najavljivanje mogucnosti "citanja misli" posto se tu ne citaju nikakve "misli" vec relativno jednostavna transformacija koju razumemo.
U svakom slucaju, kada budem ubacio modeliranje kortikalne kolone (radim na tome) sama statistika konekcije neurona ce upravo biti iz primarnog vizuelnog korteksa (da budemo precizniji, primarnog vizuelnog korteksa macke):
Ovo je Eugene Izhikevich vec uradio pre nekoliko godina - http://www.izhikevich.org/publ...scale_model_of_human_brain.htm - meni je cilj da dodjem prvo do tog nivoa simulacije, ali uz pomoc GPGPU optimizacija, a onda da nastavim sa sirenjem kompleksnosti.
[ Ivan.Markovic @ 27.09.2011. 13:45 ] @
Nista ne razumem ali svaka cast jos jednom :) Jel mozes da ostavis linkove ka resursima za pocetnike u ovoj oblasti (simulacija receptora) ?
[ Srđan Pavlović @ 27.09.2011. 13:58 ] @
Citat:
U svakom slucaju, kada budem ubacio modeliranje kortikalne kolone (radim na tome) sama statistika konekcije neurona ce upravo biti iz primarnog vizuelnog korteksa
E pa moguce da si ovo pomenuo, eto... nisam sanjao ipak :D
Primarni vizuelni korteks je dobar izbor zbog jasne retinotopske organizacije
(prati se organizacija retine u ovim poljima, i zbog visoke modalne specificnosti
neurona ovde koji primaju informacije samo o specificnim aspektima vizuelne drazi).
Dakle prilicno se dobro zna koja gde (topografski) informacija ide.
Nego - jadne macke, mozak bas vole da ispituju na njima :)
@Ivan Markovic - Ako nemas vec neko predznanje o ovome,
mozes da krenes od clanaka na vikipediji, recimo:
Inace, neurotransmitera ima prilicno mnogo, nekima je do sad uloga
jasnije ispitana, a za neke se jos utvrdjuje da li uopste imaju tu ulogu,
i koja je uloga... uglavnom, potrebno je dobro znanje fiziologije CNS-a,
poznavanje gradje neurona, tipova neurona, sinapsi, prirode procesa
koji se desavaju na sinapsama prilikom transmisije signala, itd...
[ deerbeer @ 27.09.2011. 14:14 ] @
Svaka cast Ivane !!!
Interesuje me koliko ti je vremena trebalo da sazvaces neuronsku teoriju s obzirom da bavis tim iz hobija ?
Koliko je tesko zapravo programsko modelovanje ? Postoje li neke biblioteke ili si sve na "ruke" pisao oslanjajuci se na teoriju ?
[ Ivan Dimkovic @ 27.09.2011. 20:32 ] @
Hvala ljudi na cestitkama - ali, ipak, nije ovo nista specijalno niti preterano kompleksno... mozda postane jednog dana :)
@Ivan.Markovic,
Pocni od linkova koje je ostavio Srdjan. To ce ti vec dati prve osnove.
Za computational-neuroscience oblast preporucujem sledece 2 knjige:
^ Ove 2 knjige su odlican uvod u ovu, IMHO izuzetno zanimljivu, oblast. Takodje, imaju jako dobre uvode i poglavlja na kraju koja obradjuju bioloske i matematicke osnove koje su neophodne za razumevanje.
U principu, nije potrebno predznanje iz neurologije (ovo je ipak informatika, pre svega) ali je vladanje matematikom na nivou inzenjerske matematike potrebno (sa akcentom na: diferencijalne jednacine, verovatnocu i statistiku i informacionu teoriju). Za dublju analizu je takodje dobro imati osnove iz digitalne obrade signala.
Ko zeli da ide dublje u modeliranje neurona sa stanovista dinamickih sistema:
Za ovo je vec ipak potrebno imati obimnije znanje iz matematike.
@deerbeer,
Nekoliko meseci. Mada moje znanje nije bas preterano veliko da se ne lazemo. Programsko modelovanje je lako ako znas sta hoces :-) Ja sam pisao sve "na ruke" u C-u od nule, posto mi je cilj da imam punu kontrolu i da mogu da optimizujem kako ja zelim.
Postoji, naravno, sijaset biblioteka i alata na raznim nivoima kompleksnosti... od najprostijih spiking mreza (NeMO framework) pa sve do kompleksnog modeliranja neurona do najsitnijih detalja uz pomoc NEURON softvera.
Licno sam i probao . Zakucava CPU i obara fps na jednostavnom renderingu .
Ne znam da li ce ti pomoci opengl 2.0 da dobijes koji fps vise ali moguce da ti je opengl i pored intenzivnih racunanja jos jedan botleneck sto se tice performansi ,
makar dok ne sidjes do CUDA-e i openCL-a .
[ Ivan Dimkovic @ 29.09.2011. 15:52 ] @
Hmm nisam bas siguran da je OpenGL trenutno kritican.
Samo crtanje potencijala je uradjeno kroz VBO (vertex-buffer-objects) gde je kompletna geometrija na grafickoj kartici od samog starta.
Sa NVidia GTX580 grafickom bez problema se renderuje i mreza od 1.5 miliona neurona sa nekoliko FPS sto je zapravo odlicno uzevsi u obzir da radim vokselizaciju na vrlo "seljacki" nacin preko geometrije gde je svaki "voksel" kocka sa 24 temena+24 normale (moze i 8 temena + 8 "pokvarenih" normala ako u "Configuration" stavite reduced rendering complexity), umesto da to radim preko shader-a kao volumetric render (iskreno, nisam dirnuo OpenGL vise od 10 godina pre ovoga, tako da mi nije bas bilo stalo da se bavim i volumetrickim renderingom od nule :-)
Mreza sa 32 hiljade neurona se renderuje komotno sa 60 FPS, sto je VSync limit. Inace 60-fps je inace limit u samoj simulaciji iznad toga render thread ide u wait() kako OpenGL thread ne bi uzimao previse CPU resursa (nema ni potrebe, pogotovu ako za samo matematicko procesiranje jednog frejma treba vise vremena - sto je slucaj sa sestocifrenim brojem neurona, recimo)
Hendikep sa Windows Vista / Windows 7 verzijama je sto sam Aero ima jedan bafer, pa vasa aplikacija osim svojih lokalnih OpenGL bafera ima i jos jedan, tj. kad uradite SwapBuffers() to ne ide direktno na displej, nego u neki Aero bafer.
Ali to samo po sebi ne bi smelo da nosi neke ogromne penale - max. 10-15%
--
Inace, mali update - trenutno radim na osposobljavanju potpuno slobodne geometrije (ne samo "kockaste"), za sada vec imam rudimentiranu podrsku za cilindricne i sfericne strukture a konacan cilj je 100% free geometrija, sto ce onda omoguciti simuliranje kortikalnih kolona, pa i celog korteksa ako treba.
@deerbeer - posto si pomenuo OpenGL performanse, ubacio sam mogucnost da se iskljuci frame-cap i cekanje na VSync. Ako odes u konfiguraciju, samo iskljuci ove 2 opcije:
Code:
- Limit the render thread to maximum 50 frames per second
- Wait for the vertical sync (VSync) before rendering the next frame
Ako se ove 2 stvari iskljuce, render thread ce renderovati onoliko brzo koliko sistem moze da podrzi. Gornja granica je sam simulator - render thread nece renderovati novi frejm ukoliko novi frejm nije izracunat.
Na mojoj masini (Core i7 sa 6 core-ova na 4 GHz, 2 GHz DDR3 i NVidia GTX580) dobijam sledece rezultate:
- 32768 neurona (32x32x32): Izmedju 200 i 300 FPS
- 110592 neurona (48x48x48): Izmedju 50 i 80 FPS
Sve na Windows Server 2008 R2 (ekvivalent Windows 7-mici)... nemam XP nigde ovde da uporedim performanse, doduse... ako neko ima i XP i 7 u dual-boot konfiguraciji, moze da proba...
[ mr. ako @ 29.09.2011. 22:39 ] @
Kod mene na laptopu za FPS pokazuje uglavnom neke lude brojeve.
na 32x32x32 daje oko 40-50, ali povremeno skoci na 1000.00 ili 1666.nesto ili 26xxx.xx ili 20000.00 ili 1333.xx i sl.
na 48x48x48 daje oko 25 na samom pocetku, a posle stoji zakucan na 1000.00 sa povremenim menjanjem na recimo 20455.00 ili 356.32 ili 952.nesto i jos par takvih vrednosti.
[ Ivan Dimkovic @ 29.09.2011. 23:11 ] @
Postojao je bag - najnovija verzija (0.33) to resava :-)
[ mr. ako @ 30.09.2011. 01:55 ] @
Nije resila za mene... i dalje luduju brojevi, ali se sada duze zadrzava na realnim vrednostima.
[ Ivan Dimkovic @ 01.10.2011. 01:44 ] @
Hmm... koji CPU imas na laptopu? Probacu da nadjem slicnu masinu pa da vidimo...
Upravo sam uploadovao v0.35 - koja sada ima i neural-network vizualizaciju a ne samo "kockice".
Ako zelite da vidite kako izgleda, startujte SpikeFun sa /Wireframe parametrom. Vizualizacija cele mreze je VRLO zahtevna, trazi mnogo vise graficke memorije od "kockaste" vizualizacije + vrlo je gadna za geometrijski engine... Plus, kod je prilicno neoptimizovan :-) Dakle, ne pokusavati bez dobre diskretne graficke :-) + Vrlo je moguce da mid-range graficke odbijaju da simuliraju neki od preseta sa vecim brojem neurona (tipa 64x64x64).
Evo jednog video klipa kako izgleda mreza sa 260 hiljada neurona i 8 miliona sinapsi.
OBAVEZNO pogledajte u FullHD 1080p rezoluciji i sa full-screen pogledom:
Na zalost, YouTube prilicno kvari kvalitet videa, tako da sam zakacio jedan frejm sa ovom porukom, cisto da bude jasno sta se renderuje :-)
[Ovu poruku je menjao Ivan Dimkovic dana 01.10.2011. u 13:42 GMT+1]
[ Ivan Dimkovic @ 01.10.2011. 12:53 ] @
v0.36 is out - fixovao sam problem gde je mreza izgledala previse uredjena na "linije" (neuroni su rasporedjeni drugacije sad)
Takodje, malo sam doradio rendering /Wireframe moda tako da je depth-sortiranje (zbog transparencije) nesto malo bolje, ali je i dalje daleko od optimalnog posto su u pitanju linije koje projektuju svuda... ako se zele performanse, mislim da nema nekog dobrog nacina... jedino gruba sila.
[ mr. ako @ 01.10.2011. 15:53 ] @
Citat:
Ivan Dimkovic: Hmm... koji CPU imas na laptopu? Probacu da nadjem slicnu masinu pa da vidimo...
AMD Athlon II Dual-Core M320 2.1GHz
(nisam probao ove dve poslednje verzije...)
[ BBS @ 02.10.2011. 04:10 ] @
Svaka čast za trud. Kako si došao do ovog tj. kad smo već u ovoj oblasti šta je bila prevashodna motivacija za ovaj projekat, kako je nastao hobi?
[ Ivan Dimkovic @ 02.10.2011. 11:38 ] @
Ma prevashodna motivacija je bila "daj da nadjem nesto da zanimam mozak da ne zakrzlja posto ulazim u 30-te :-)" tu negde krajem prosle godine :-)
Cituckanjem o AI pristupima i istorije AI-ja sam dosao do neuroinformatike koja me je vrlo zainteresovala posto ukljucuje gomilu zanimljivih stvari, od oslanjanja na medicinu do informacione teorije. Dodatni izazov su ogromne mogucnosti optimizacije sto mi se vrlo svidja.
Anyway... SpikeFun v0.37 je uploadovan. Optimizovao sam malo iscrtavanje cele mreze.
+ Dodao sam neke opcije zbog zescih razlika u OpenGL drajverima izmedju NVidia-e i Intela...
Evo optimalnih parametara za koriscenje vizualizacije cele mreze.
Za NVidia kartice (testirano na GTX580, mada kontam da kaci i sve ranije modele):
Code:
SpikeFun /Wireframe
Za Intel integrisane GPU-ove (testirano na GMA HD 3000):
Code:
SpikeFun /Wireframe /ColorBuffer
Kako stvari stoje, NVidia OpenGL drajver je zesce optimizovan, i vise se isplati zvati glDrawRangeElements() individuelno za svaki neuron te sa glColor() menjati boju pre iscrtavanja (!!!) i sa if(voltage>THR) filtrirati neaktivne (nevidljive). Kod Intela se daleko vise poslati jedan veliki glDrawRangeElements() poziv za sve aktivne neurone tako sto se u niz koji drzi indekse spakuju samo vidljivi - ali to zahteva da se pre crtanja uploaduje i kompletan niz boja za svaku sinapsu (liniju) kao VBO bafer (sto moze biti i par desetina MB po frejmu!)
Rezultati na NVidia-i su kontraintuitivni posto kontam da i taj drajver mora u jednom momentu da uradi VBO transfer svih boja za svaki neuron/sinapsu + postoji overhead za vise desetina hiljada poziva glDrawRangeElements() po frejmu... ali ocigledno oni taj transfer rade mnogo bolje, verovatno koristeci neko kesiranje i slanje na GPU memoriju samo kada treba mozda i neku kompresiju itd... Intel drajver to ocigledno nema, i individualno crtanje neurona ga totalno urnise (vreme rendera skace i 10x).
[Ovu poruku je menjao Ivan Dimkovic dana 02.10.2011. u 13:07 GMT+1]
[ mr. ako @ 02.10.2011. 13:49 ] @
Novim verzijama se nije nista promenilo sto se tice FPS prikaza:
(btw, grafika je ATI Mobility Radeon HD 5145 512MB)
483
323
Za 323 ovako velike vrednosti se pojavljuju dosta redje, nego kad je 483 gde su skoro non stop prikazane nerealne vrednosti.
[ Ivan Dimkovic @ 02.10.2011. 14:20 ] @
To je ocekivano posto nista nisam menjao povodom FPS prikaza - problem je sto ne mogu kod mene da reprodukujem problem, pa cu morati da nadjem neku drugu masinu za to (sporiju verovatno).
Na srecu imam jedan Core 2 duo mobilni (Merom na 1.8 GHz) pa cu njega da osposobim i poteram SpikeFun tamo...
[ Ivan Dimkovic @ 02.10.2011. 16:02 ] @
Hm, zanimljivo je da ti prikazuje 0 za frame render time uvek... Moram da vidim sta se tu desava, posto koristim direktno rdtsc instrukciju da iscitam tajmer - naravno, testirano na Intel-u :-) Pogledacu da nema neki zez sa AMD procesorima koji ovo onemogucava...
[ Ivan Dimkovic @ 02.10.2011. 16:52 ] @
Uploadovao sam novu verziju (v0.38):
- Fixovan bug u panningu (SHIFT + mouse move) gde se desavalo da se pogled "izgubi"
- Dodate A, D, W i S komande za pomeranje kamere levo, desno, gore i dole (kao u FPS igricama :-)
- Camera reset je prebacen na X taster
- Umesto asemblerske rdtsc instrukcije sada koristm intrinstic instrukciju __rdtsc(), nisam siguran da li ce to promeniti nesto na AMD sistemima (frame render time), ali bar nije lose pokusati... u najgorem slucaju uvek mogu da se vratim na QueryPerformanceCounter() semplovanje...
[ Ivan Dimkovic @ 03.10.2011. 22:32 ] @
v0.40 is out :-)
Dodata je podrska za sferne topologije (mozete izabrati sferne presete u konfiguracionim opcijama).
Evo kako to izgleda:
Sada jos nedostaju aksonski terminali bez mijelinskog omotaca, pa ce simulacija totalno oslikavati eksperiment iz: http://www.izhikevich.org/publications/reentry.htm sto mi je i ovako i onako prvi planirani "milestone".
Sferne topologije su zesci alpha, posto odabir neurona u 2D selektoru ne radi kako treba (moracu da raspisem novu rutinu za "presecanje" po Z osi i odabir pravog neurona koji odgovara X,Y koordinatama misa, posto je sa kockama/kvadrima to dolazilo za dzabe :-)
Takodje, dodao sam i kontrolu transparencije (alfa) u toolbox-u, posto je za render mreze potrebno naci optimalnu vrednost u zavisnosti od broja sinapsi.
Hahhah, vala bash... al' Dimke bar menja brojeve iza nule, decimale... a FF menja cele brojeve, bas sam se iznenadio kad mi je na desktopu ponudio da instaliram FF 7.0.1! Reko WTF?! Kad je izasla 5ica?! :D (na laptopu koristim i dalje 3.6.xx :) )
[ bogdan.kecman @ 04.10.2011. 15:41 ] @
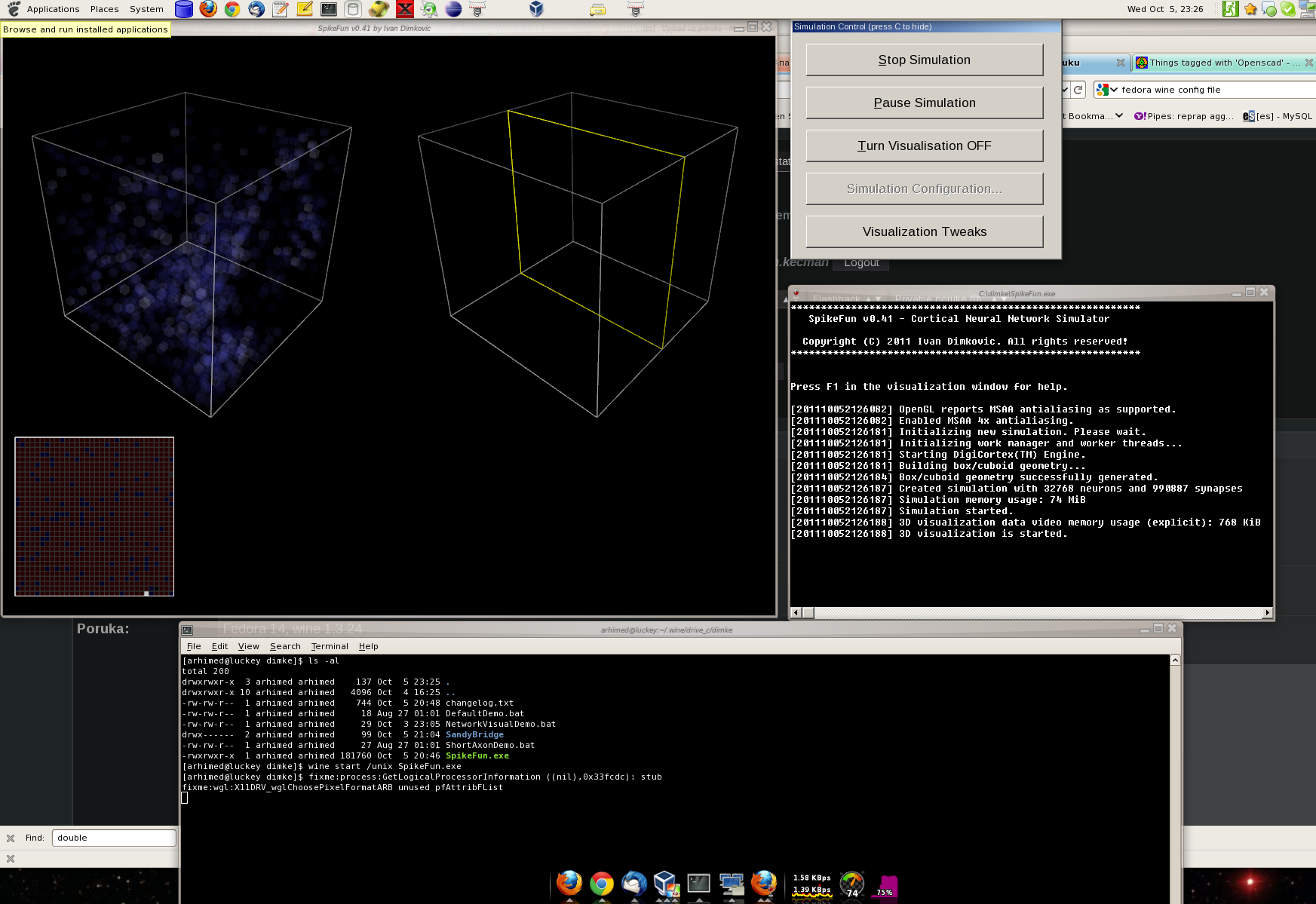
Radi sa wine-om "uglavnom" ... dakle sve radi osim sto kada krene simulacija
1. nema teksta (sim time, fps etc etc)
2. rade strelice da pomeraju presek, radi E da ubaci event, radi levi mis za rotaciju, ali desni klik u simulaciju zabode display simulacije (ostane onaj 2d prikaz ali 3d prikaz nestane)
3. ne radi /demo (moguce da nisam nesto dobro siljno wine za to)
evo ss-a ako nekog zanima
[ Ivan Dimkovic @ 04.10.2011. 15:53 ] @
Hmm... fontovi se kreiraju koristeci wglUseFontOutlines() API poziv, koji je Windows-specific, posto koristi Windows font biblioteke.
Da li ti radi help (sa F1)? Ili FFT plot (sa F5)?
Moguce je da nesto ne radi kako treba... na kraju cu verovatno lepo ubaciti Freetype biblioteku i samostalno praviti potrebne 3D primitive za fontove.
[ bogdan.kecman @ 04.10.2011. 16:03 ] @
nema veze sto je windoze api, wine bi trebao da ga odradi ... F1 prikaze overlay sa bojama ali nema txt-a a F5 prikaze FFT no opet ako treba da ima nekog txt-a nema ga...
moguce da samo nemam font koji koristis pa da zato nije ubacio ... koji font koristis (ako se dobro secam wglUseFontOutlines koristi font iz trenutnog rendering konteksta) .. Mozda bi pomoglo ako bi explicitno setovao font na neki standardni (arial npr) no nisam kucao nista na windozi u ovom veku pa sam malo zardjao :( ... u svakom slucaju ovo deluje da radi prilicno lepo sa wine-om tako da mozda ni ne moras da pravis nativnu verziju :) ... naravno openCL bi pomogao znacajno :)
[ Ivan Dimkovic @ 04.10.2011. 17:08 ] @
Hm... fontovi su Arial i Courier New, pa cak i ako nema tih fontova (sto je malo verovatno, je li) postoji back-up na SYSTEM_FONT...
Moracu da vidim to - probacu da poteram kod sebe SpikeFun na linuxu preko Wine-a sa vise debug opcija pa cemo videti sta mu se ne svidja...
Citat:
naravno openCL bi pomogao znacajno :)
Hehe, CUDA/OpenCL ce doci, samo hocu prvo da uradim glavne stvari na CPU verziji (arhitektura i sl...) kako ne bih posle morao da menjam kod na vise mesta.
[ bogdan.kecman @ 04.10.2011. 17:12 ] @
ifdef rulez :D
[ mr. ako @ 04.10.2011. 17:18 ] @
E lepo da si stavio i nekakvu ikonicu, posto ne volim one default, pa sam promenio bio na neku bezveze samo da ima ()...
...brzo ti programcic postaje kompletan. :)
[ Cola @ 05.10.2011. 10:41 ] @
Super mi ovo izgleda i svaka čast od mene za true :)
Imaš li viziju gdje bi se ovo moglo upotrijebiti (pročito sam sve ali sam možda promašio tu inf.)
[ Shadowed @ 05.10.2011. 10:48 ] @
Pa, zar nije odlican screen saver
[ Srđan Pavlović @ 05.10.2011. 11:52 ] @
"SpikeFun je mali simulator bioloski-realisticnih neuronskih mreza", prva recenica
u prvom postu na temi, dakle upotrebljava se za simulaciju aktivnosti neurona i
mreza neurona (nervnih celija).
Mozda je dobar screen-saver, ali je CPU-killer :)
[ mr. ako @ 05.10.2011. 13:05 ] @
Takodje nije los za grejanje za predstojecu zimu... kao i za podgrevanje caja, ako se casa stavi na izduvnik kod laptopa Vas napitak moze biti prijatne temperature za toplo uzivanje. Porucite vec danas - komplet SpikeFun + laptop, samo 499e!
[ Ivan Dimkovic @ 05.10.2011. 19:55 ] @
Yep - trenutno je glavna aplikacija grejanje uz screen saver :-)
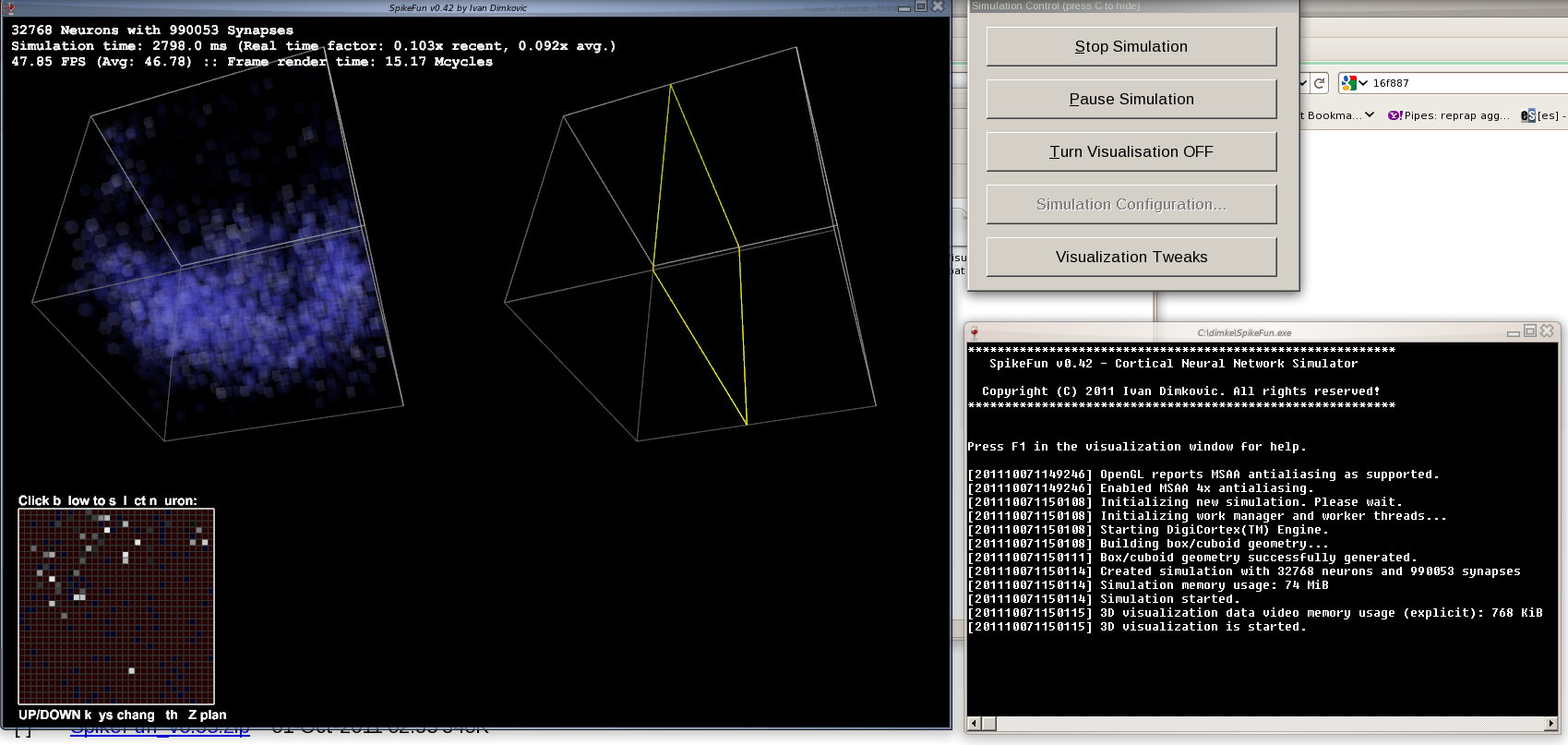
v0.41 is out...
- Sada je moguce menjati render stil ("kockice" vs. cela mreza) sa F12 dok traje simulacija
- Dodao sam /DisableVbo opciju koja iskljucuje koriscenje OpenGL VBO-ova. Ova opcija moze biti korisna za 2 stvari:
a) Ako imate neku matoru Intel integrusu tipa GMA950... koja nema ljudsku podrsku za vertex-buffer-objekte
b) Ako se spikefun zali tokom kreiranja OpenGL scene na nedovoljno memorije
/DisableVbo ce, naravno, lose uticati na performance renderinga - ali moze posluziti kao fallback za mator hardver.
Sto se Wine-a i fontova tice - na zalost, nisam jos u stanju to da proverim posto Ubuntu live USB stick instalira Wine koji odbija da pokrene SpikeFun (tj. pokrene ga, ispise se (C) informacija - i tu stane)... malo sam izmenjao parametre oko kreiranja fontova, ali sumnjam da ce to pomoci.
[ bogdan.kecman @ 05.10.2011. 20:06 ] @
nista se sa fontovima nije promenilo - i dalje nema txt-a
[ Ivan Dimkovic @ 05.10.2011. 20:26 ] @
Nista stavicu neki posten Linux na drugu masinu pa cemo videti...
Btw, sad se setih - pre par nedelja sam razmisljao o ubacivanju Freetype podrske medjutim za sada mi je to glupo posto je sama Freetype biblioteka veca od same aplikacije :-))
[Ovu poruku je menjao Ivan Dimkovic dana 05.10.2011. u 22:01 GMT+1]
[ Ivan Dimkovic @ 05.10.2011. 21:53 ] @
Hmm nikako mi ne polazi za rukom da nateram SpikeFun da radi pod Wine-om... ispise Copyright poruku i tu stane...
Probao Wine 1.2 i 1.3, na Ubuntu 10.04 i 11.stagod... sa virtuelnim desktopom i bez...
instaliraj http://wiki.winehq.org/winetricks i iz njega dodaj cirefints, dotnet11, fontfix, dotnet30 i gecko ... i vidi sta jos ti se ucini zanimljivo :) .. trebalo bi da proradi sve ...
btw ja startam sa "wine start /unix SpikeFun.exe" tako da vidis na tom screenshot-u dobijem konzolu kao poseban program
[ Ivan Dimkovic @ 05.10.2011. 22:43 ] @
E thx - uspelo je sada i meni iz Ubuntu-a... pojma nemam kako :)
Nema ni kod mene teksta nigde... ali sad bar mogu da debagujem :)
[ Ivan Dimkovic @ 06.10.2011. 22:22 ] @
Resio sam problem sa Linux-om sa verzijom 0.42 (dostupna)
Problem sa fontovima je bio bizaran - naime, wglUseFontOutlines() kreira displej liste u kojima se nalaze OpenGL pozivi za crtanje font-poligona i koje se onda zovu sa glCallLists() kada vam to treba...
Elem, unutar tih lista, Microsoft u svojoj ingenioznosti menja orijentaciju lica za izbacivanje (culling) koja je po defaultu suprotna od kazaljke na satu - verovatno je danas na Windowsu malo situacija kada su lica CW a ne CCW pa se problem nije video, dok je implementacija wglUseFontOutlines() u WINE-u ocigledno drugacija.
Resenje je prosto - pre zvanja glCallLists() potpuno iskljucim face-culling - a onda kada se zavrsi, ukljucim back-face culling i resetujem kriterijum za odbacivanje lica na GL_CCW (default). Ne svidja mi se ideja stalnog zivkanja OpenGL-a za ove gluposti, ali sta-je-tu-je...
[ bogdan.kecman @ 07.10.2011. 12:51 ] @
Sada radi pod wine-om 1/1
[ mr. ako @ 08.10.2011. 22:19 ] @
Citat:
Ivan Dimkovic: Yep - trenutno je glavna aplikacija grejanje uz screen saver
:-)
Hmm, sad gledam svoju poruku sto sam napisao pre ovog tvog odgovora... Nisam imao nameru da nipodastavam program niti tudji rad, to mi nije ni na kraj pameti. Samo sam napisao kvazi duhovit post. :)
AKO je bilo ko pogresno protumacio, evo ovo je disclaimer... :)
Inace, poslednja ver i dalje ima ludacke skokove FPS-a... mada average FPS izracunava korektno cini mi se.
[ Ivan Dimkovic @ 09.10.2011. 21:00 ] @
Pitanje jeste skroz na mestu - SpikeFun je za sada prilicno neupotrebljiv bilo sta osim za vizualizaciju slucajno uvezanih mreza.
Kako bude napredovao, bice moguce raditi i druge stvari :-)
Sto se skokova FPS-a tice, mislim da sam uspeo da ih reprodukujem na Core 2 masini ali nisam jos stigao da fixujem to ali ce biti reseno do sledece verzije...
Elem, v0.43 je izbacena, sada sa novom download stranom:
- 64 bitne verzije* (obicna i "sandy bridge") koje omogucavaju enormne simulacije
- Jos malo malih demoa (bat fajlovi)
- "HUD" style statistika u visualization pogledu (F11) - 2 video klipa dole je imaju
- Malo sredjen OpenGL rendering tako da se sada ne razbacuje sa nepotrebnim state-change pozivima GL funkcija
Evo kako izgleda novi "HUD" mode - sa sfernom topologijom:
Ili sa "kockastom":
* Jedina prednost 64-bitnih verzija je mogucnost ogromnih simulacija koje zahtevaju vise od 4 GB RAM-a. Osim toga, nema nikakvih drugih prednosti, cak je i losija sto se performansi tice (od nekoliko pa i do 10-tak % !!!) tako da preporucujem 32-bitnu verziju osim za super-velike simulacije. Budite pazljivi sa ogromnim simulacija - stvarno su ogromne... 80x80x240 (1.5 miliona) ce komotno "pojesti" 5.4 GB fizicke memorije.
Velike simulacije moguce sa 64-bitnom verzijom vrlo verovatno nece raditi u VBO modu na bilo cemu osim najjacim karticama tako da, ako vidite gresku u logu, startujte SpikeFun sa /DisableVbo parametrom. To ce omoguciti da se simulacija renderuje, ali brzinom puza :)
[ mr. ako @ 09.10.2011. 23:22 ] @
Da li mi se cini na ovom klipu ili aktivni neuroni po sferi iscrtavaju polukruzne i/ili spiralne slike? Ne vidim da je takva aktivnost na kocki, od cega to zavisi?
[ Shadowed @ 09.10.2011. 23:31 ] @
Mozda to sto sfera ima neurone samo po povrsini (inace bi bila lopta, jelde:) ) dok je kocka ispunjena.
[ mr. ako @ 10.10.2011. 01:46 ] @
U redu to sto je sfera, ali nekako se uvek prave "linije" u obliku polukruga ili pocetka spirale... nekako je uvek pravilno u tom obliku. Nema mestimicnih grupa nepravilnog oblika ili grupe koja zauzima neku povrsinu u obliku recimo amebe. :P
[ Ivan Dimkovic @ 10.10.2011. 07:53 ] @
@mr.ako - Shadowed je u pravu, razlog drugacijeg izgleda je zbog samog oblika mreze. U slucaju sfere prakticno nema trece dimenzije posto su svi neuroni rasporedjeni po povrsini.
Da je u pitanju lopta, ponasanje (tj. prostiranje akcionih potencijala) bi bilo identicno kocki.
Propagacija zavisi ponajvise od geometrije, duzine aksona i proporcije inhibitornih i pobudjujucih neurona. Simulacija na sferi koja je na videu ima izuzetno kratke aksone.
Startuj SpikeFun bez demo moda (bez parametara u komandnoj liniji), zatim izaberi sferu od 16mm sa 32768 neurona, i ostavi default parametre - videces da je ponasanje skroz drugacije.
[ deerbeer @ 10.10.2011. 08:15 ] @
Dimke ne rade ti ove 64bit verzije :
Dobio sam novu masinu na poslu (intel i5 sandy bridge) i 8 GB RAMA pa rek'o da vidim oce li izdrzati spike attack :)
Treba li neki dodatni binaries da instaliram ?
[ Nozzlezator @ 10.10.2011. 16:56 ] @
Isti problem sa x64 verzijom.
[ Ivan Dimkovic @ 11.10.2011. 04:11 ] @
Argh... prokleti kompajler...
Znam sta je, probacu da sredim to do sutra posto sam u USA trenutno. Sorry...
[ Ivan Dimkovic @ 20.10.2011. 21:38 ] @
Problem resen - 64-bitne verzije su ponovo dostupne, i trebalo bi da rade kako treba.
Neki dan uzeh novu grafulju, 8800GTX ode u penziju, pa taman
da je malo przim sa ovim tvojim... bome, posle dugog rada ode
ona na 63 stepena... :)
[ Ivan Dimkovic @ 24.10.2011. 21:53 ] @
@Nozzlezator,
Thx, provericu na slicnoj masini - trenutno radim povece promene na modelu neurona (multi kompartmenti) sto ce potrajati neko vreme dok ne bude gotovo - pa cu onda uraditi poveci update.
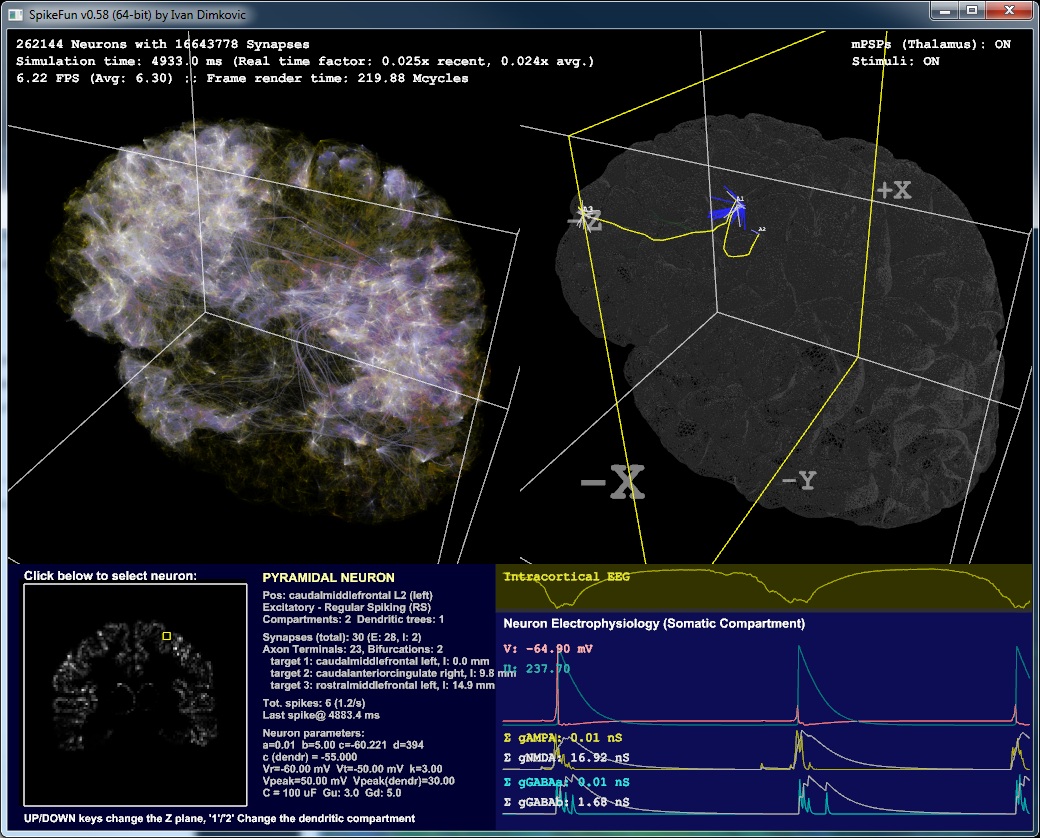
U razvojnoj verziji sam dodao i simulaciju "intra-kranijalnog" EEG-a (kasnije cu dodati i fMRI BOLD simulaciju) - zanimljivo je da je u odredjenim konfiguracijama moguce dobiti spike&wave EEG, koji je tipican za epilepticne napade sa "odsutnoscu" (absence seizure).
[ Ivan Dimkovic @ 25.10.2011. 20:06 ] @
Btw,
Jako dobar tutorial za ljude koje zanima neuroinformatika:
Ovaj tutorial pokriva celokupnu teoriju oko modela neurona i sinaptickih receptora koje koristi SpikeFun.
Obratite paznju i na poslednjih nekoliko strana koje se bave nestabilnoscu forward-Euler metoda za numericko resavanje diferencijalnih jednacina Izhikevich-evog modela, zbog GABAa receptora (zbog oscilacija koje ce dici GABAa provodnost u nebesa, i totalno urnisati simulaciju) - meni je trebalo prilicno vremena da skontam sta se desava (davno bio u skoli ;-) - a evo sad vidim neko to lepo pokrio :-))
Videcu mozda i da ubacim Runge-Kutta metod ili bar eksponencijalni Euler (koji je pogodan za simulacije neurona)... decisions, decisions...
[ maksvel @ 25.10.2011. 21:06 ] @
Zna li ovaj Jizikjevič (ili kako već) za SpikeFun?
Sigurno bi mu bio interesting.
[ Ivan Dimkovic @ 25.10.2011. 21:13 ] @
Ne verujem, doduse samarao sam ga pre nekoliko meseci oko njegovog modela neurona, ali to je bilo pre nego sto sam poceo da kodiram ovo.
Sumnjam da bi mu SpikeFun bio preterano interesantan, posto je on u 2004-toj terao simulator sa 100 milijardi neurona (yep, 100 milijardi) i 1.000.000.000.000.000 sinapsi (10^15) - model je trcao na beowulf klasteru sa 50 CPU-ova. Jedna sekunda modela se racunala 50 dana.
Ono sto je interesantno za taj njegov projekat je toliki broj neurona i sinapsi (uporediv sa ljudskim mozgom), bilo bi apsolutno nemoguce drzati sva njihova stanja u memoriji. To je reseno tako sto su sinapse stalno dinamicki kreirane u svakom koraku. Genijalan primer kako je nekad racunanje stvari iznova bolje nego skladistenje u memoriji.
Videcemo koliko ce meni trebati da to raspisem od nule :)
- Multi-kompartmentalni neuroni (za sada samo piramidalni neuroni imaju vise kompartmenta, ostali stizu uskoro)
- Svaki neuron sada moze imati vise dendritskih stabala i svako stablo moze imati vise kompartmenta
- Napredniji model neurona (i dalje je Izhikevicev, ali sada i sa kapacitetom membrane i jos dodatnih parametara)
- Novi tipovi neurona zahvaljujuci naprednijem modelu:
-- Piramidalni (nekoliko pod tipova: kortikalni L2/3, L4, L5/6 i superficial sa "chattering" nacinom opaljivanja)
-- Spiny-stellate neuroni (kortikalni sloj 4)
-- Basket i non-basket GABAergicni interneuroni
U sledecoj verziji cu kompletirati tipove sa neuronima iz talamusa i retikularne formacije.
- Konacno: Viseslojni model korteksa (6 slojeva)
- Kortikalna simulacija koristi podatke (sinapticke veze i distribucija celija) iz Tom Binzegger-ove mape macijeg primarnog vizuelnog korteksa. Samo uvezivanje nije jos 100% kompletirano (jos nisu koriscena sva pravila zbog trenutno nedostajucih visestrukih aksona u mom modelu) ali u grubim crtama neuroni jesu uvezani na nacin na koji se uvezuju u zivoj sivoj masi.
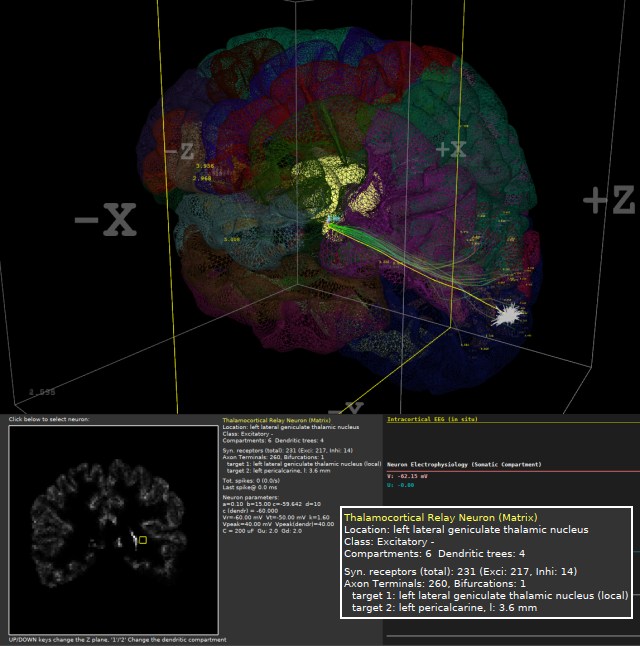
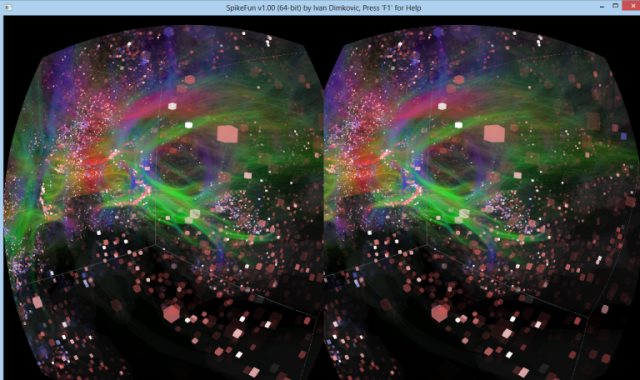
- EEG simulacija: SpikeFun sada simulira i intra-kortikalni EEG (ako kliknete na neki neuron, prvi grafikon ce biti icEEG ako postoji dovoljan broj piramidalnih neurona u blizini izabranog neurona)
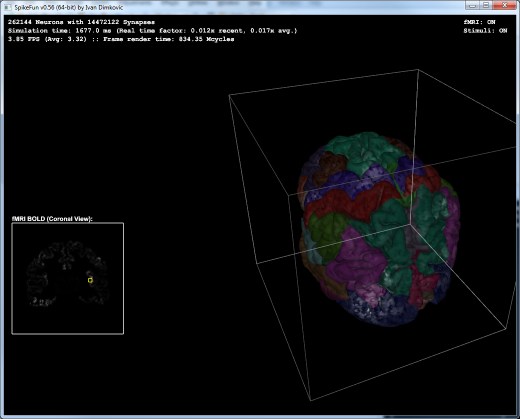
- fMRI BOLD simulacija: Takodje, sada je moguce simulirati i fMRI BOLD "pogled" ('F' taster na tastaturi). fMRI BOLD je u "realnom vremenu" jako spor proces u odnosu na brzinu opaljivanja neurona - a posto je SpikeFun visestruko sporiji od realnog vremena obicno, fMRI "slika" izgleda staticno.
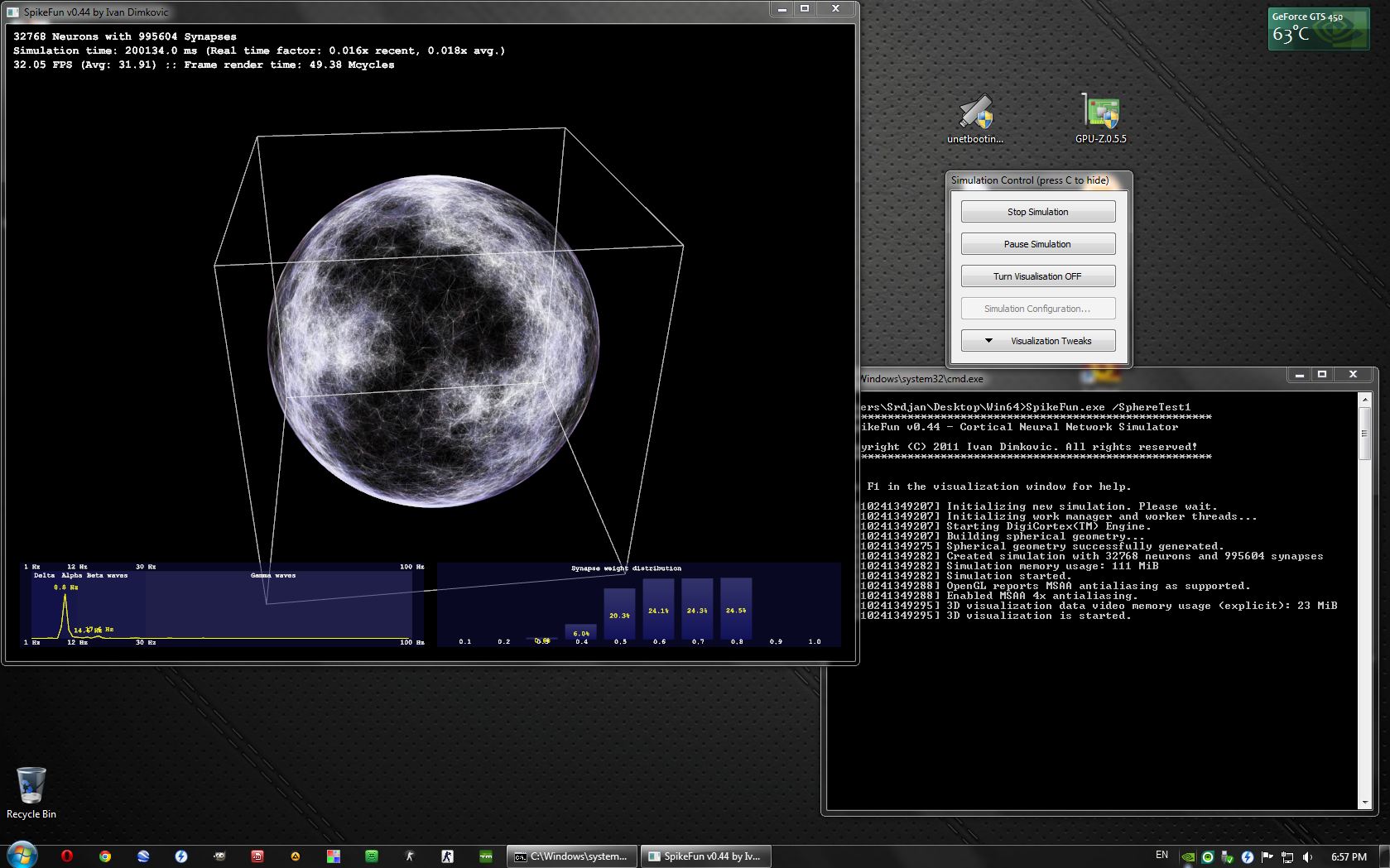
Kortikalnu simulaciju mozete testirati sa SpikeFun.exe /SphereTest1 (ili jedan od 2 bat fajla) -- kreiranje neurona je vrlo neoptimizovano, inicijalizacija mreza vecih od 32K neurona traje jako puno vremena (ovo cu resiti u sledecih nekoliko dana ako budem imao vremena).
Takodje, simulacija sa multi-kompartmentalnim neuronima je vidno sporija :( Ovo ce potrajati dok ne zavrsim sam model neurona i algoritme za kreaciju mreza, a onda cu da se posvetim optimizovanju same simulaicje.
Kod mene se simulacija od 373 hiljade neurona i 33.5 miliona sinapsi kreira za ~70 sekundi. Kreiranje simulacije je i dalje single-threaded, tako da se to moze jos prilicno ubrzati (jedini zez je sto ce morati da se raspise drugacije kako bi se izbeglo ubijanje performansi zbog sinhronizacije niti posto su neuroni prilicno "isprepleteni")
- Za 64-bitne verzije Dodati demo modeli "big" i "biggest", sa 262K/18M i 373K/33.5M neurona/sinapsi
Paznja: Big/Biggest modeli su >vrlo< zahtevni sto se svih resursa (grafickih i memorijskih) tice. Big simulacija zahteva oko 3.5 GB RAM-a, dok Biggest trazi oko 5.6 GB RAM-a. Takodje, vrlo lako moze da se desi da graficka kartica nema dovoljno VRAM-a za VBO objekte (Biggest zahteva oko 786 MB RAM-a za OpenGL VBO geometriju u HighGraphics modu) - ako dobijate OpenGL greske, editujte .bat fajl i dodajte /DisableVbo opciju. Sa ovim ce vrlo verovatno raditi (samo sto ce brzina rendera biti manje ili vise losija u zavisnosti od "pameti" grafickog drajvera)
- U kortikalnoj simulaciji je dodat bias za bliske post-sinapticke "mete", sto je bioloski realno (broj sinaptickih veza opada sa rastojanjem od aksona)
To je to za sad... Sledeci korak je dodavanje talamusa i senzornih ulaza, dopaminski-modulisane sinapticke plasticnosti, "racvajucih" aksona sa terminalima koji nisu ograniceni na kraj aksona, multi-kompmartmentalni modeli za ostale neurone (trenutno samo piramidalni imaju vise kompartmenta)
A onda.. modeliranje topologije i konekcija po pravoj topologiji mozga, uz pomoc MRI skenova i MRI DTI (Diffusion Tensor Imaging) vektora.
Posle toga, GPGPU i optimizacije, koje ce biti vise nego potrebne kad stignem do ovoga :)
[ mr. ako @ 14.11.2011. 19:48 ] @
Meni ne rade ni ova ni prosla x64 verzija...
[ Ivan Dimkovic @ 15.11.2011. 00:28 ] @
:(
Kakvu gresku dobijas? Koju x64 verziju koristis (normalnu ili AVX)? Koji OS?
Kod mene x64 radi na 2 masine - jedna je i7 970 (Westmere generacija) a druga je i7 2620M (Sandy Bridge generacija).
[ mr. ako @ 15.11.2011. 03:30 ] @
Samo mi Win javi da je prog prestao da radi. Normalna ver. OS Win7 Pro.
Kod mene su oba AMD proca, ali sam probao samo na laptopu - nisam jos nijednom pokrenuo da desktopu...
[ Texas Instruments @ 19.11.2011. 13:42 ] @
Čisto da prijavim, isprobao sam sad sve četiri verzije sa RegularDemo.bat pokretanjem i ova Win64_Sandybridge ne radi. Pukne program pri pokretanju.
[ Ivan Dimkovic @ 20.11.2011. 20:26 ] @
Sorry :( 64-bitni SandyBridge je imao problem (koji sam resio, ali je i dalje totalno bizarno kako je taj problem uopste i postojao, a i samo "resenje" je vise patch...)
@mr.ako - ako imas vremena probaj v0.47, mozda je isti problem kacio AMD sisteme posto je vezan za rutinu za detekciju CPU-a.
v0.47 donosi ponovo dosta poboljsanja:
Model talamusa
Od ove verzije kortikalne simulacije (CortexDemo_xxx.bat) imaju i talamus u "centru". Modelirani su talamicki relejni neuroni (specificni - senzorni, i ne-specificni), talamicki interneuroni i retikularni talamicki neuroni (RTN).
Model talamusa je vrlo vazan dodatak simulaciji, posto je sada moguce simulirati petlje (tzv. "talamo-kortikalne petlje") koje su otkrivene in-vivo i za koje su zaduzene projekcije aksona iz talamusa. Do pre izvesnog vremena se na talamus gledalo kao na prost "relej" koji salje signale iz senzornih organa korteksu - medjutim, novija istrazivanja su ovu teoriju potpuno oborila: kako stvari stoje, veza izmedju korteksa i talamusa je drasticno kompleksnija, i signali iz cula cine samo 7% - sve ostalo su unutrasnje sinapticke veze koje omogucavaju propagiranje signala u petljama (bukvalno u krug).
Poremecaji u talamo-kortikalnim petljama izazivaju potpun prestanak svesti (npr: "petit mal" epilepticni napadi) iako metabolicki korteks i dalje radi. Zbog ovog fenomena postoji dosta pristalica misljenja da se kljuc onoga sto nazivamo "svescu" nalazi u propagiranju signala kroz ove petlje.
Sada u simulaciji 'L' (ubacivanje stimulusa) zapravo ubrizgava struju direktno u talamicke neurone (specificne).
Ako malo bolje pogledate u grafickoj vizuelizaciji, aktivnost neurona bukvalno ima "eho" koji ima malo kasnjenje - to je direktan efekat talamo-kortikalnih petlji.
Hemisfere
Dodavanjem talamusa je ubacen i koncept hemisfera (do sada su aksoni bili slucajno razbacani). Talamus ima 2 hemisfere i svaka hemisfera projektuje neurone u istu hemisferu korteksa. Piramidalni neuroni iz kortikalni sloja 3 salju dugacke aksone u suprotnu hemisferu (in-vivo aksoni idu kroz corpus-callosum)
Za sada su lokacije po hemisferama i dalje slucajne, dakle jos nema mapa. Ovo ce biti dodato kasnije kada sferu budem zamenio pravim modelom mozga.
Velike Simulacije
- Dodata i "Huge" simulacija (CortexDemo_Huge) sa milion neurona i 200 miliona sinapsi. Paznja: ova simulacija trazi i do 32 GB memorije!
Optimizacije, bugfixevi..
- Resen problem koji je izazivao krah Sandy Bridge x64 verzije
- Kreiranje kortikalne simulacije je sada multi-threaded, gore pomenuta "huge" simulacija (1M neurona, 200M sinapsi) se kreira za oko 3:30 minuta kod mene
- Jacina sinapsi u vizualizaciji se sada prikazuje skalabilnim fontovima (ako zumirate, brojevi ce biti manji) kako bi se omogucila citljivost neurona sa velikim brojem sinaptickih receptora
[ mindbound @ 21.11.2011. 18:29 ] @
Ivan, is there any possibility of getting one's eyes on the source code of this win?
[ Ivan Dimkovic @ 22.11.2011. 20:21 ] @
I'm afraid not at the moment, sorry - it is still in the very early stage and quite far from the state where I'd be proud if somebody takes a look at it ;-)
[ Ivan Dimkovic @ 27.11.2011. 18:58 ] @
v0.48 is out :)
Citat:
v0.48 - Released on 27th November 2011
--------------------------------------
* Added multi-compartmental models for Spiny-Stellate and
Thalamocortical Relay cells (thalamocortical simulations only)
* Improved multi-compartmental model of Pyramidal neurons
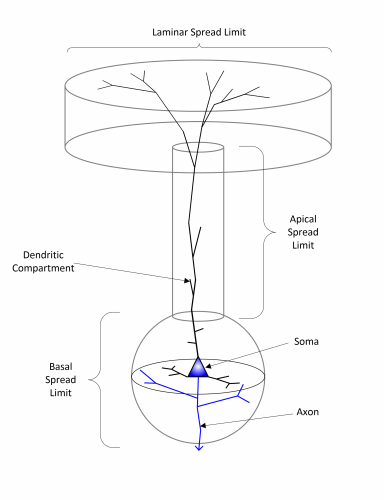
* Support for limiting axonal laminar spreads - enabled for
demo cortcial simulation scripts containing >100K neurons
* Added precise spike timing detection (not locked to the
simulation time-step)
Sa ovom verzijom su svi pobudjujuci neuroni multi-kompartmentalni (Box/Cuboid simulaicje koriste point-neurone!).
Ostali su jos inhibitorni neuroni, sto ce biti dodato u toku sledecih nekoliko verzija.
Takodje, ispravio sam jedan bag gde piramidalni neuroni iz slojeva 5/6 nisu projektovali aksone u talamus.
Poceo sam da radim i na racvajucim aksonima - dodavanje opcije za ogranicavanje laminarnog "spread-a" aksona u v0.48 je neophodni preduslov. Sledeca stvar koja mora biti uradjena je dodavanje mogucnosti "racvanja" aksona i pravljenja stabla gde se "grane" dele na lokalne (bez mijelinskog omotaca) i (kod talamickih i nekih piramidalnih neurona) "long-distance" koji prolaze kroz belu masu i imaju mijelinski omotac.
Ovo zahteva malo vece promene u kodu kao i dodavanje delay-bafera i delay lookup tabela za svaku sinapsu. Do sada je akson bio jednostavni delay bafer gde su post-sinapticki ciljevi bili povezani sa aksonom na kraju, sto je implementaciju cinilo trivijalnom. Racvajuci aksoni ce to da zakomplikuju, mada je to i dalje relativno jednostavno. Veci problem je kako odrzati mogucnost crtanja necega sto lici na "pravu stvar" sto ce zahtevati posebne 3D tacke (samoj mrezi 3D tacke nisu potrebne - jedino sto je bitno je kasnjenje).
Dodao sam i preciznu detekciju kada je neki neuron "opalio":
Do sada je detekcija bila prosto ispitivanje da li je prag (vPeak) predjen u sledecoj iteraciji (t+1). Na zalost, ovim se uvodi greska u preciznosti - u slucaju Izhikevich-evog modela ta greska jeste stetna, zato sto ce spora reset varijabla ('u') akumulirati te greske vremenom, i samim tim prouzrokovati pogresno opaljivanje.
Resenje za ovo je jednostavno - ukoliko je u sledecem koraku (t+1) simulacije potencijal membrane veci od praga opaljivanja, za reset nece biti koriscen potencijal membrane u t+1, vec linearno interpolirana vrednost izmedju t i t+1.
[ Ivan Dimkovic @ 30.11.2011. 22:34 ] @
Mali sneak preview dolazecih verzija :-)
- Geometrija sive mase kreirana kombinovanjem fMRI slajsova u 3D mesh
- Za sada su veze izmedju dugih aksona i dalje slucajne, ali je krajnji cilj koriscenje DTI fMRI tenzora za "navodjenje" aksona
Ima jos puno posla, ali je ostalo jos samo par kljucnih stvari za prvi milestone (simulacija kompletne sive mase i talamusa sa bioloski realnim modelom i vezama izmedju neurona)
[ mindbound @ 03.12.2011. 03:33 ] @
Even if so, please do consider open-sourcing the SpikeFun - its feature set already redeems and outweighs any clumsiness or incompleteness of the code. :)
I find especially praiseworthy and interesting the diverse multi-compartment models, something that I still cannot get in a working condition on my own Izhikevich OpenCL code.
[ Ivan Dimkovic @ 03.12.2011. 20:43 ] @
Let's see how quick I can finish the full branching axons and axonal guidance based on DTI tensor data (fMRI) - then I could do some code cleanup... :-)
v0.50 - Released on 3rd December 2011
--------------------------------------
* Added initial support for real-brain geometry (alpha)
* Improved demo view (now including fMRI and EEG)
* Integrated AVX optimizations in one executable
* Integrated 32-bit and 64-bit downloads
This version comes with one huge update - support for real brain geometry. Brain 3D data was generated using fMRI slices and generating 3D surface out of them.
For now, brain geometry support is not complete - only gray matter is really following the anatomy, while thalamus is still a "sphere" in the center. Furthermore, because 3D mesh does not separate other non-cortical parts (e.g. basal ganglia, thalamus, cerebellum, brainstem etc.) they are filled with cortical neurons. I will correct that in one of the next versions, by "chopping" the 3D data into the appropriate functional units.
Unfortunately, download size has also grown - it is 6 MB now. This is mainly due to the brain 3D data. I am already using 3D mesh compression (OpenCTM) which is decreasing the mesh storage size by the factor of 10, but I think this is still too big... I will experiment with coarser quantization and maybe some mesh reductions to get this down further.
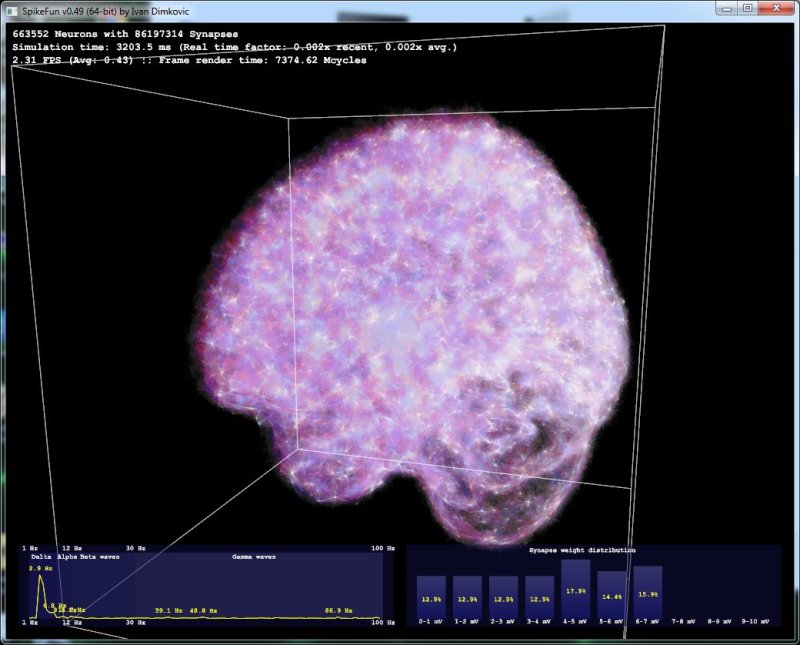
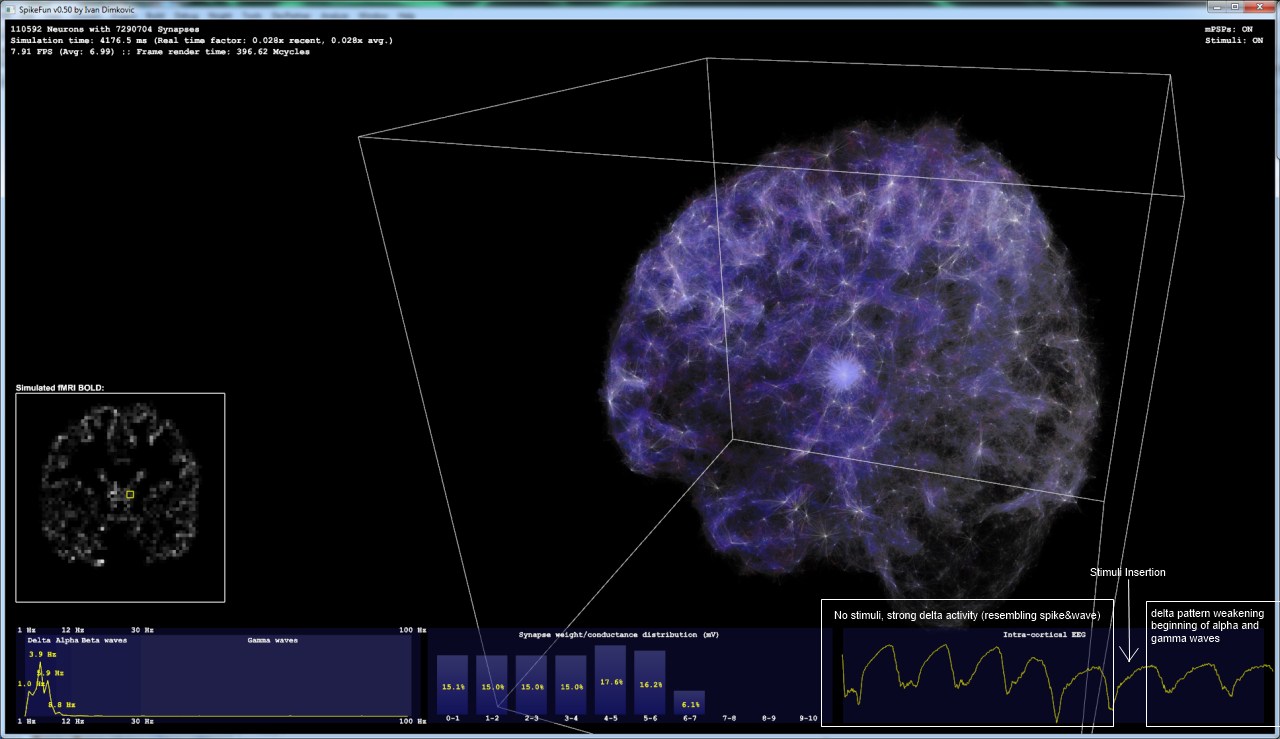
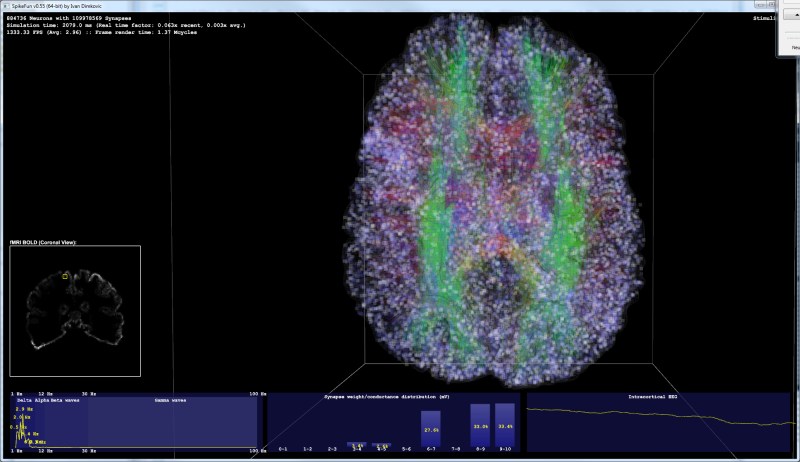
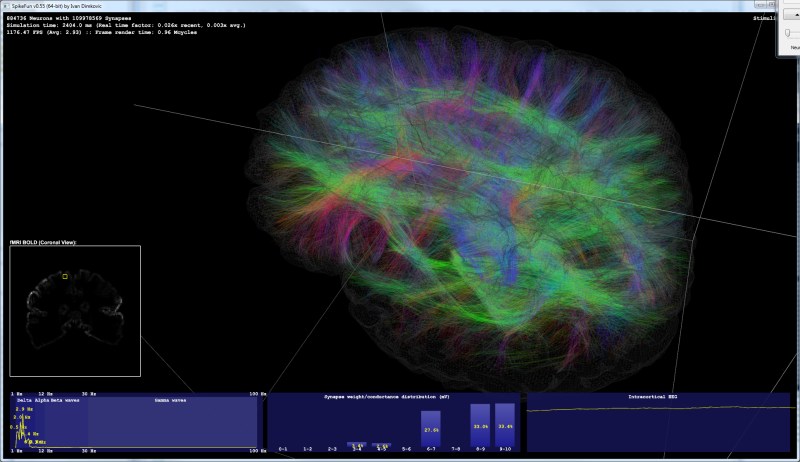
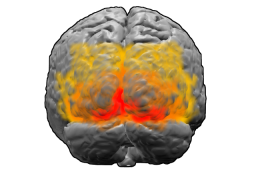
This is the picture of v0.50 in work (below). It is simulating relatively small population of 110K neurons and 7 million synapses. However, even with this low amount of neurons it is possible to induce gamma-band activity by switching on stimuli. If stimuli and mPSPs are switched-off, brain activity will into deep delta-wave state.
With this low number of neurons, this state looks exactly like epileptic "spike and wave" pattern. However, if larger number of neurons is present (e.g. 1 million) the activity will not contain spike and wave discharges. Rather, it will look like slow-wave sleep. Switching the stimuli and mPSPs on will almost immediately force the brain into the alpha/gamma rhythm - resembling awake state.
[ Ivan Dimkovic @ 04.12.2011. 00:14 ] @
And some more examples based on v0.50.
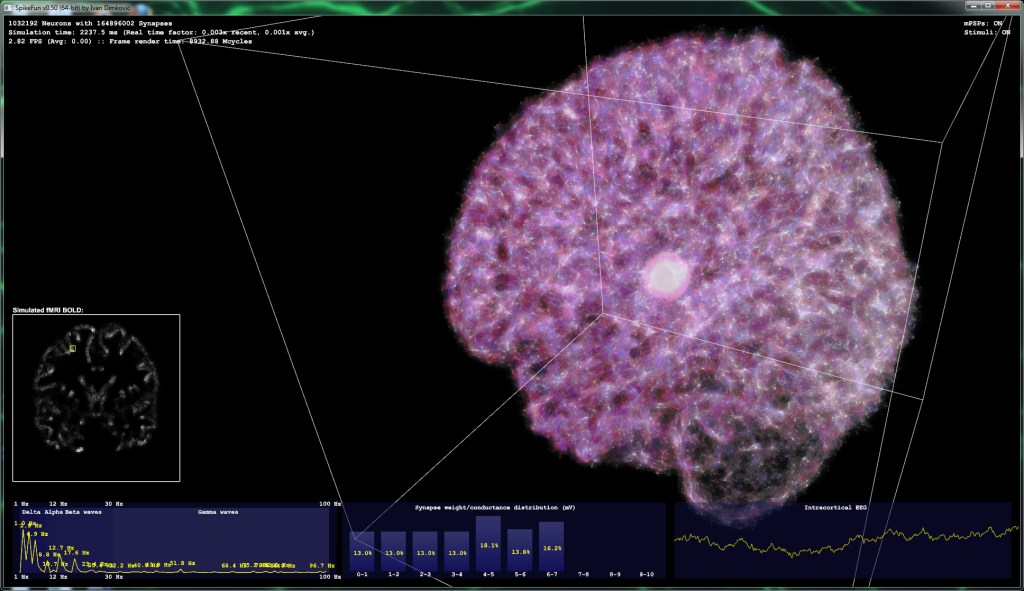
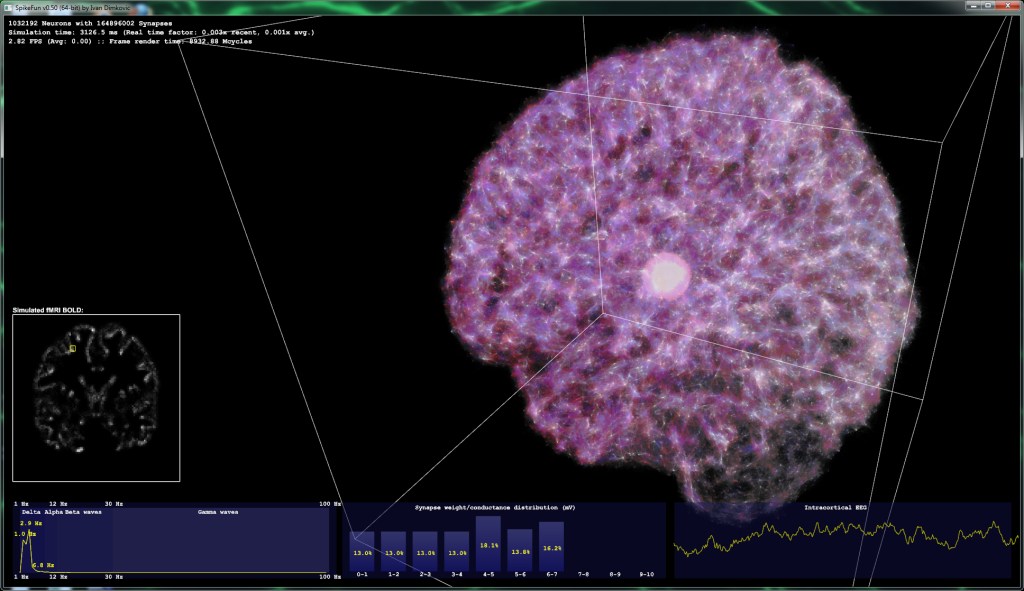
Below two picture snapshots were made on the same simulation - with 1.03 million neurons and ~165 million synapses.
In the first picture, stimulation of sensory areas of thalamus is ON. Simulated brain responds with strong gamma-band activity, which is correlated with awake state and full consciousness in humans.
In the second picture, stimulation is switched OFF . Simulated brain almost immediately enters into the strong delta-wave activity, with no gamma band activity at all. In humans (and in other mammals) this pattern is observable during deep sleep and it is correlated with the absence of conscious experience.
Please note that EEG graphs are auto-scaled during rendering. In simulation, actual measured delta wave amplitudes are much higher than the gamma wave amplitudes.
Picture 1: Gamma band activity ("Awake brain"):
Picture 2: Delta band activity ("Slow-wave sleep"):
[ Ivan Dimkovic @ 11.12.2011. 23:09 ] @
v0.51 is out...
- Fixed-point 3D geometrija za velike simulacije, stedi oko 50% video memorije
- Preciznija alokacija sinapsi i aksona (strozija provera secenja sa geometrijom, na zalost usporava kreiranje mreze oko 30%)
- Multi-kompartmentalni modeli za basket i non-basket inhibitorne interneurone
- 3D model mozga: Implementirana provera prilikom povezivanja da li neuron upada u laminarni aksonalni opseg pre-sinaptickog neurona
Sada se u celom procesu kreiranja neurona (aksoni + sinapse) proverava da deo aksona ili dendrita ne sece 3D mesh (sto bi znacilo da "iskace" iz geometrije). Na zalost ovo zahteva dosta provera da li segment sece trougao, sto usporava kreiranje simulacije.
Upsorenje je negde oko 30% - ali je rezultat daleko preciznija topologija.
- Preciznost simulacije (integration step) je sada 1 ms umesto 0.5 ms, sto simulacije cini 2x brzim
- Dodata opcija za 0.5 ms (staru) preciznost (/HighPrecision)
- Aksoni sada mogu biti sa ili bez mijelinskog omotaca
- Smanjenje zauzeca memorije (preko 10%) uz pomoc optimizovanih struktura i alokacije memorije
- Dodatne optimizacije i bugfixevi u kreiranju simulacije
Takodje, poceo sam dodavati opciju za fixed-point aritmetiku za sinapticko procesiranje kako bi se smanjila potrosnja memorije i memorijski I/O. Na zalost, 16-bitni fixed-point format ne daje spektakularna smanjenja potrosnje memorije tako da ova opcija za sada nije ukljucena.
Mozda rizikujem da ispadnem glup ovim pitanjem ali cemu ovo zaista sluzi?
Danasnji racunari (pogotovo kucni) su daleko od toga da mogu realno simulirati bilo kakav mozak a najmanje ljudski. Mozda bi bilo prakticnije krenuti sa simulacijom sinapsi nekog daleko jednostavnijeg organizma (insekt npr) pa vremenom doci do realne simulacije tog organizma.
[ Ivan Dimkovic @ 30.12.2011. 11:54 ] @
Pitanje je sasvim na mestu - i mislim da ne postoje glupa pitanja, samo glupi odgovori.
SpikeFun ne sluzi nicemu trenutno osim trosenju mog slobodnog vremena i CPU resursa sistema na kojima trci :-)
Sto se samih simulacija tice, pitanje nivoa detalja (a, samim tim, i racunarske snage neophodne za simulaciju) neophodnog za oponasanje CNS-a nekog organizma je nereseno.
- Postoje skole misljenja koje smatraju da ce biti neophodno simulirati biohemijske reakcije na nivou molekula (videti Cajal Blue Brain Project).
- Postoje skole misljenja koje smatraju da je simulacija jonskih kanala u neuronima dovoljna (Henry Markram, Blue Brain Project).
- Postoje skole misljenja koje smatraju da je dovoljno imati fenomenoloske modele koji oponasaju elektrohemijsko ponasanje neurona a ne interne mehanizme koji do tih ponasanja dovode (vise izvora).
- A, naravno, postoje i skole misljenja koje tvrde da je inteligentno ponasanje kvantni fenomen koji se ne moze simulirati sa racunarima (Penrose & Hameroff)
...
U svakom slucaju, pitanje je i sta se tacno zeli postici. Farmaceuti zele model koji ce realno oslikavati ponasanje CNS-a kada se izlozi farmakoloskim sredstvima, informaticari zele model koji simulira inteligentno ponasanje zivotinja/ljudi, neurolozi zele model koji realno modelira bolesti i ostecenja itd...
Moj cilj je ispitivanje koliko je moguce oponasati neka stanja talamo-kortikalnog sistema sisara uz pomoc modela koji je dovoljno jednostavan za masovne simulacije, a opet - dovoljno bioloski realan tako da je u stanju da oponasa elektricna ponasanja glavnih tipova neurona koji postoje u korteksu i talamusu sisara.
Drugim recima, to je put koji se sam ucrtava - cilj je postici sve veci i veci nivo bioloske realnosti.
Bilo bi totalno naivno ocekivati nekakvu vernu replikaciju mozga u bilo kakvo dogledno vreme. Cisto primera radi, mi danas poznajemo oko 150 razlicitih neurotransmitera - gde poremecaj bilo kojeg od njih dovodi do dubokih poremecaja i bolesti centralnog nervnog sistema. Modelirati takav sistem je naravno bar jos decenijama ispred nas. SpikeFun modelira 4 (ali 4 najvaznija za CNS - gde jedan od njih predstavlja grupu).
Medjutim, to uopste ne znaci da jednostavniji sistemi ne mogu biti korisni - od nekh osnovnih eksperimenata, za koje je danas neophodno pobiti dosta zivotinja, pa do konstrukcije nekih inteligentnijih uredjaja koji bi imali rudimentirane mogucnosti CNS-a sisara, recimo vecu pouzdanost u prepoznavanju objekata.
SpikeFun modeli neurona su generalni i vezani za sisare. Nije nikakav problem to adaptirati za simulaciju neurona insekata samo sto je problem sto je daleko vise fenomenoloskih modela neurona i njihovih parametara dostupno za sisare. Razlog je verovatno sto je daleko lakse dobiti research-grant za "istrazivanje CNS-a" jedne macke ili majmuna nego bubasvabe. Slazem se da je to vrlo verovatno naopak nacin ali sta je tu je... Ja nemam kucni lab sa patch-elektrodama i zalihu bubasvaba, mrava ili pcela (sva 3 insekta su vrlo inteligentna i sa oko milion neurona u svojim nervnim sistemima) koje bih mogao da ispitujem, pa ce objavljeni modeli vezani za sisare posluziti :)
[ Ivan Dimkovic @ 08.01.2012. 11:26 ] @
SpikeFun v0.53 ce biti izbacen veceras sa gomilom promena :-)
Za sada, mali demo video:
Ovo je simulacija sa 1.2 miliona neurona i 151.3 miliona sinapsi, koja zauzima oko 18-19 GB radne memorije (samo za simulaciju , vizualizacija ide na to).
# Aksoni piramidalnih neurona se sada racvaju na vise aksonskih grana (do 3):
- Piramidalni LII/III neuroni se racvaju kontralateralno (kroz corpus callosum) kao i ipsilateralno (unutar iste hemisfere)
- Piramidalni LV/VI neuroni se racvaju tako sto jedna projekcija ide u talamus
# Samo kreiranje geometrije je drasticno rigoroznije u smislu testiranja kuda neuroni prolaze. Na zalost, ovaj detalj je visestruko povecao kompleksnost kreiranja geometrije :( Ovo sam nekako pokusao da kompenzujem optimizacijama koje su opisane dole, ali je i dalje kreiranje geometrije 2-3x sporije u odnosu na v0.52. Najveci problem su testiranja presecanja trouglova koji cine 3D mesh tokom kreiranja sinaptickih veza (kako veze ne bi "izletale" van kortikalne mase) - ovo je jedan od tipicnih Computer Science problema koji se srece u, recimo, Ray Tracing-u... ima mesta za dalje optimizacije ali sam ogranicen nekim arhitekturnim detaljima (recimo, nije moguce cast-ovati 4 zraka kao u Ray Tracing implementacijama, pa cu morati da testiram 1 zrak sa 4 trougla ako zelim iskoristiti SIMD paralelizam, a ovo nije bas najoptimalnije)
- Generator pseudo slucajnih brojeva je sada u cistom asembleru i nekoliko puta je brzi od CRT implementacije + ima daleko veci kvalitet izlaza (spada u klasu CMWC tj. Comlementary-Multiply-With-Carry, autor algoritma je George Marsaglia) u odnosu na LCG generator u Visual C++ CRT biblioteci (primera radi, 4 milijarde slucajnih brojeva se generisu za oko 5 sekundi u jednom thread-u)
- Optimizovan je test za intersekciju trougla i linije (ali i dalje ima jos dosta prostora za optimizacije)
- Dalja optimizacija testiranja intersekcije je uradjena kroz bolju vokselizaciju trouglova. Ovde takodje ima jos dosta mesta za poboljsanja
- Kreiranje geometrije za rendering je sada multi-threaded pa je cekanje na start simulacije sa renderom visestruko krace ako imate multi-core CPU
- Alokacija memorije je optimizovana i sada postoji kesiranje za sitne alokacije koji operise sa 32 MB blokovima
Toliko za sad.
Sto se arhitekture tice, ostala je jos samo jedna velika stvar za uraditi - a to je koriscenje DTI podataka (traktografija) za vodjenje aksona kroz 3D prostor kada izadju iz sive mase. Na zalost, mislim da ce ovo morati da saceka bar nekoliko nedelja dok ne nadjem neku MRI masinu i islikam samog sebe kako bih imao sve sto mi treba uravnato i na jednom mestu...
A onda sledi pisanje CUDA kernela. Inicijalni eksperimenti sa CUDA-om i modelima neurona i sinapsi koje SpikeFun koristi pokazuju da je moguce dobiti ubrzanje od preko 15 puta sto je jako dobar znak... :-)
U verziji 0.54 je ubacena rana verzija konektoma, tj. modeliranja aksonalnih puteva kroz belu masu. Trenutno je podrska vrlo rudimentirana ali ce aksoni koji prolaze kroz belu masu biti sprovedeni koristeci podatke koji su dobijeni analizom DSI (Diffusion Spectrum Imaging) podataka.
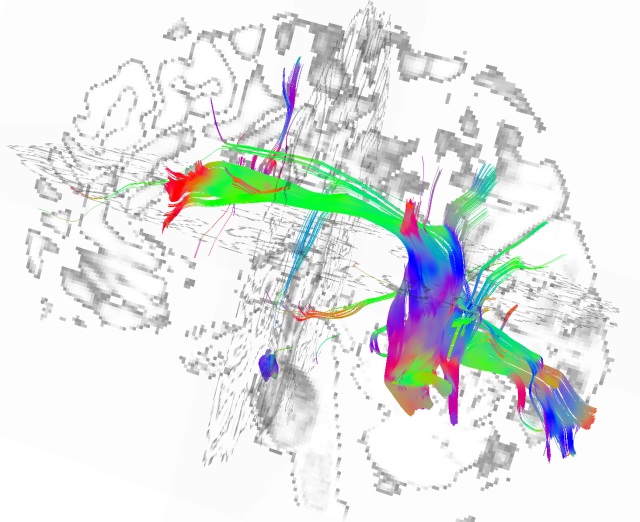
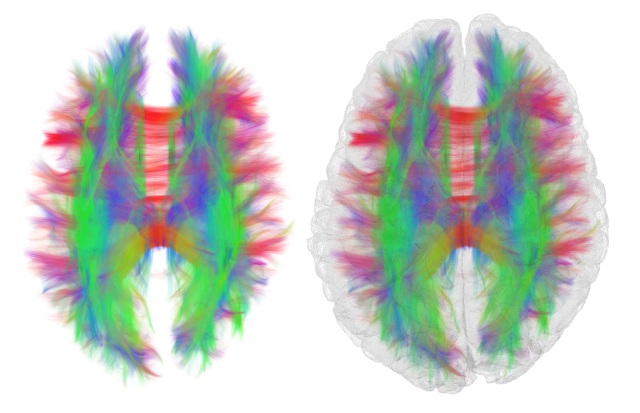
Za razliku od starijeg DTI (Diffusion Tensor Imaging) metoda, DSI je u stanju da razresi prepletene traktove, sto je inace cest slucaj u npr. ponsu / produzenoj mozdini. U sledecim verzijama SpikeFun-a cu se truditi da poboljsam razlucivanje konektoma koristeci bolje statisticke metode.
Evo kako izgleda DSI na delu - svaki trakt na slici predstavlja veliki broj aksona a "kockasta" slika okolo je anatomski T1 MRI koji je koriscen za kreiranje 3D kortikalne povrsine:
Talamus:
Kompletan korteks i corpus callosum (3.7 miliona traktova, korisceni za SpikeFun konektome):
v0.54 donosi i optimizovan 3D mesh za kortikalnu masu, kao i 3D model talamusa (prosle verzije su koristile sferu).
[ Ivan Dimkovic @ 24.01.2012. 19:04 ] @
Inace, koga zanima vise analiza mrezne topologije u mozgu preporucujem sledecu knjigu:
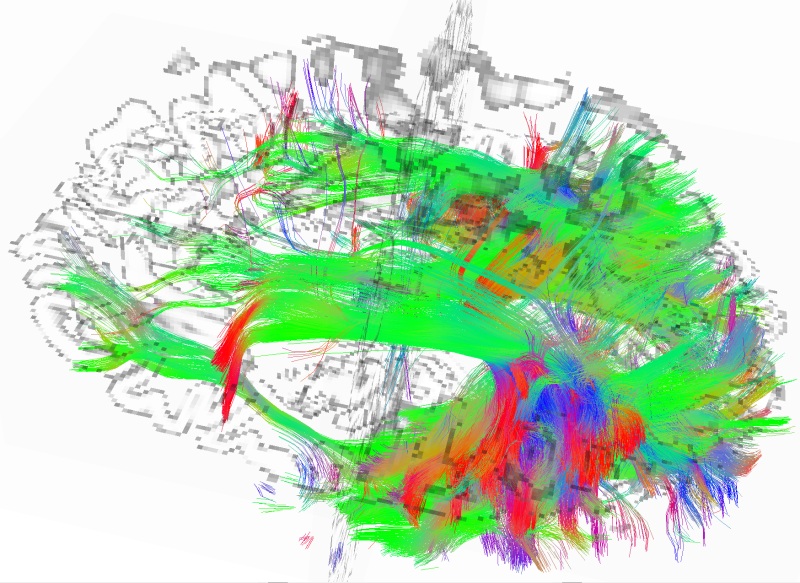
Tehnike kao sto je DSI po prvi put omogucavaju da se 'zaviri' u enormno kompleksnu mrezu izmedju neurona i da se sa nivoom detalja koji je do skoro bio cisti SF, analizira kako su povezani razni delovi mozga izmedju sebe.
Primera radi, evo kako izgleda infero-temporalni deo mozga, u kome se nalaze neuroni koji kodiraju kompleksne reprezentacije objekata koje vidimo ukljucujuci i lica:
Na slici se jasno vide veze sa vizuelnim korteksom (iza) i Broca-inom zonom (napred, infero-frontalni korteks) koja je ukljucena u izgovaranju pojmova kao i Wernicke-ovom zonom (iznad, superiorni temporalni korteks) koja je zaduzena za razumevanje jezika koji cujemo.
Ove veze su bile poznate i od ranije na osnovu funkcionalnih MRI snimaka i, naravno, posmatranja poremecaja tipa slogovi gde se unistavanje veza u temporalnom delu manifestuje sa raznim patologijama tipa nemogucnost prepoznavanja lica / poznatih osoba i sl...
Medjutim, uz pomoc DSI tehnike je moguce mapirati veze do mnogo sitnijih detalja nego npr. pracenje BOLD fMRI-ja koji je vrlo male rezolucije (pokazuje samo "blob-ove" gde je povecana metabolicka aktivnost) i ima ogromnu latenciju.
Primera radi, ceo temporalni korteks:
^ Ovo je samo 100 hiljada traktova. Rezolucije od nekoliko miliona traktova nisu nikakav problem sa modernim 3T MRI aparatima.
Statistickom analizom ovih veza je moguce napraviti mapu veza izmedju funkcionalnih delova mozga, tzv. "konektome". Evo kako izgleda tipican rezultat takve analize (sa: http://flolo.blogspot.com/2010/10/connectome.html):
Vec sada je, na osnovu analiza konektoma, moguce otkriti neke zanimljive stvari u nacinu na koji su uvezani razni, funkcionalno razliciti delovi mozga. Primera radi, odmah se moze identifikovati tzv. "core network" (http://www.popsci.com/science/...ons-form-cerebral-super-entity) tj. 12 "habova" koji su ukljuceni u kompleksne mentalne radnje - ostecenje nekog od delova ove "backbone" mreze dovodi do velikih posledica koje nisu lokalizovane na neku funkciju, dok ostecenja van ove mreze obicno jesu lokalizovana.
Jos jedna zanimljivost je da su sve mreze u mozgu "small world" tipa i procentualno ogromna vecina veza su lokalne - sto je evolutivna prednost zato sto je tako i dalje moguce komuniciranje "na daljinu" ali uz daleko manju metabolicku cenu nego u slucaju da je vecina neurona povezana dugackim aksonima sa dalekim regionima.
[ Ivan Dimkovic @ 05.02.2012. 19:52 ] @
SpikeFun v0.55 is out...
A sa njim i dinamicko mapiranje aksonalnih puteva kroz belu masu (prosla verzija je koristila hardcode-ovane indekse po trouglovima, i to niske rezolucije)
Zbog toga sam morao integrisati ceo DSI Studio (http://dsi-studio.labsolver.org/) engine za ekstrakciju aksonalnih traktova iz raw. DSI snimaka.
Ako pogledate distribuciju - test.fib.gz su zapravo fiberi kreirani na osnovu DSI snimaka koji odgovaraju MRI anatomskim snimcima (isti subjekt) koji se koriste za kreiranje 3D modela mozga.
Ovo je i dalje "work in pgoress" - za sada je moguce samo ucitati samo ovaj fib fajl posto je registracija (transformacija 2 MRI snimka) hardcode-ovana izmedju ova 2 izvora podataka.
Kada budem zavrsio ovo, bice moguce ucitati bilo koji MRI T1 snimak i odgovarajuci DSI snimak i kreirati 3D model korteksa (isosurface) i aksonalnih traktova - a ne samo vezanih za jedan mozak. Ovo ce ipak malo potrajati posto za ovo moram da integrisem i algoritme za ekstrakciju mozga iz slika cele lobanje kao i registraciju tih snimaka sa DSI snimcima, sto ce biti podosta koda.
Elem... trenutno je broj traktova u demoima jednak broju neurona x 4, pa CortexDemo_Small pocinje sa 131072 trakta, dok CortexDemoHuge koristi oko 6 miliona traktova za kreiranje mreze.
Takodje, dodao sam vizualizaciju 3D modela sive mase i izvucenih traktova u SpikeFun -
Ovako to sada izgleda:
Simulacija:
Sami aksonalni traktovi:
[ Ivan Dimkovic @ 12.02.2012. 20:24 ] @
v0.56 is out...
A sa njom:
* Drasticno precizniji 3D model sive mase (T1 MRI procesiran FreeSurfer-om)
* Anotirani delovi korteksa (sada, recimo, mozete izabrati direktno na simuliranom fMRI neurone iz odredjenog dela)
* Simulacija multi-kanalnog "intrakranijalnog" EEG-a (F2 u toku simulacije, samo za talamo-kortikalne simulacije)
* Eksperimentalni (work in progress) 3D mri pogled (/mri3d switch u komandnoj liniji)
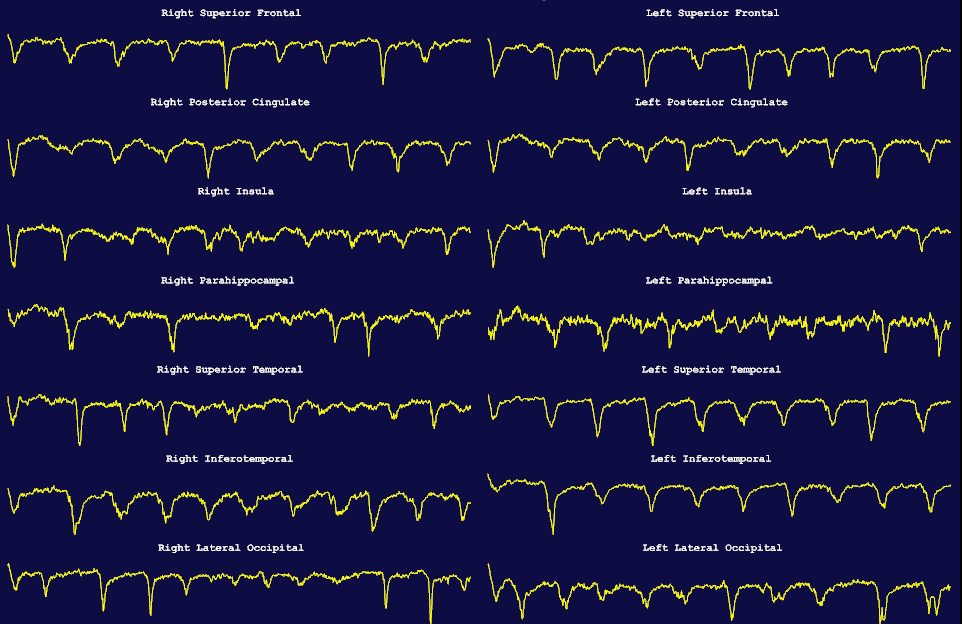
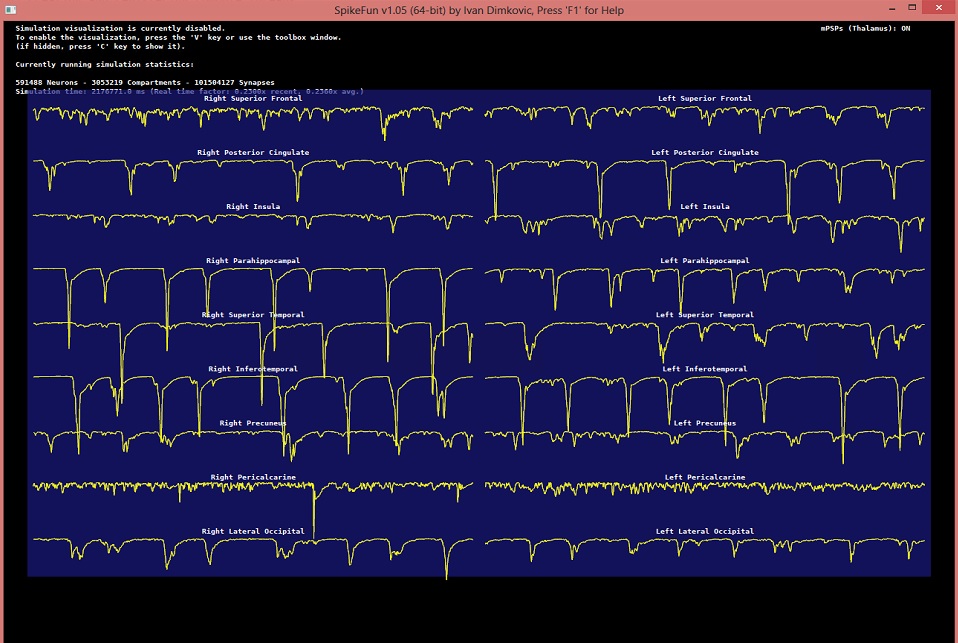
Evo kako izgleda novi multi-kanalni EEG - obratite paznju na razlicite ritmove u razlicitim delovima korteksa:
Kao i eksperimentalna verzija 3D fMRI vizualizacije (i dalje ruzna, nisam zadovoljan - ovo ce da se popravi):
Takodje - obratite paznju na anotaciju (svaki kortikalni region ima drugu boju).
PAZNJA: 3D MRI pogled je jos i dalje neoptimizovan (racunanje se radi "na misice" pa vrlo verovatno uzima drasticno vise resursa nego sto bi trebalo) - ovo ce biti doterano do sledece verzije.
[ Ivan Dimkovic @ 28.02.2012. 11:02 ] @
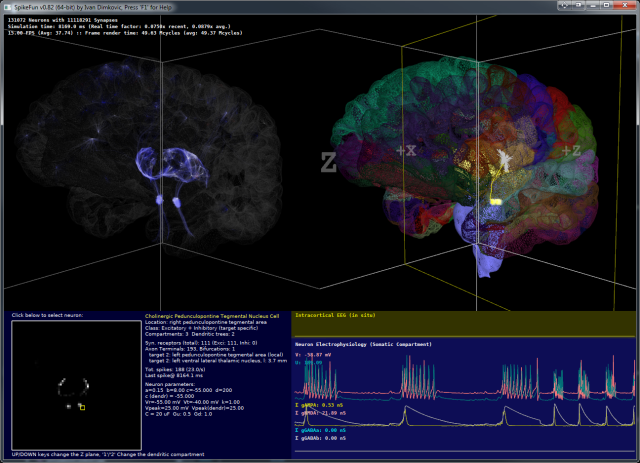
Interesantan eksperiment (v0.57 preview) - na potpuno iskljucenoj kortikalnoj mrezi bez ikakve aktivnosti jedan neuron biva pobudjen (eksterno).
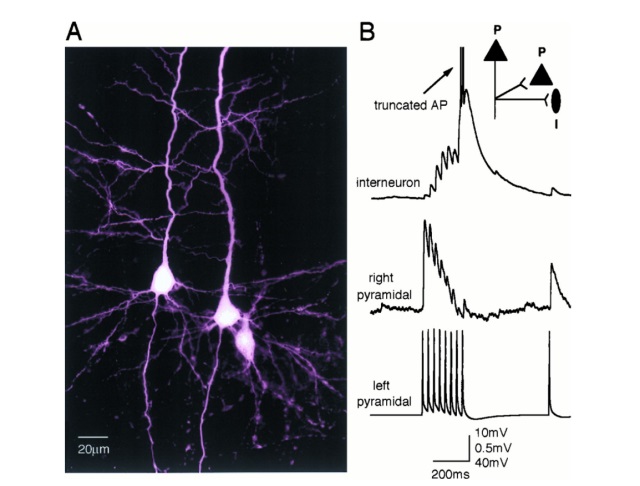
U Spiny-Stellate neuron u kortikalnom sloju 4 vizuelnog korteksa biva ubacen kratak puls struje - struja izaziva depolarizaciju membrane i akcioni potencijal (spike).
E sada ide zanimljiv deo - iako je u pitanju samo jedan neuron u mrezi od preko 800 hiljada neurona koji su potpuno "ucutkani", njegov spajk zapocinje lancanu reakciju - aktivnost raste prvo u samom regionu vizuelnog korteksa a ubrzo zatim se siri na temporalni korteks a potom i frontalni. Ceo lanac se zavrsava u motornom i pre-motornom regionu.
Mreza postaje ponovo tiha na nekoliko stotina ms, a potom zapocinje "rebound" reakcija ovog puta inicirana u temporalnom korteksu.
Cela aktivnost traje oko 2 sekunde - izazvana aktivacijom samo jednog neurona.
Inace, slicna aktivnost se moze videti i in vivo (naravno, bez gasenja celog korteksa posto je to nemoguce) gde stimulacija jednog neurona u snu ne izaziva "lancanu reakciju" (aktivnost zamire za ~100 ms), dok u toku budnosti stimulacija jednog neurona izaziva talase aktivnosti u udaljenim delovima korteksa koji traju i vise stotina ms.
* New cortical network generation algorithm (much faster)
* Fixed overprovisioning of neural compartments
when desired numbers of synapses cannot be found
* Added option to inject brief pulse of depolarizing current
into the selected neuron ('I' key) for spike-induction
* Added GUI for setting the brainstem and sensory modulation of the network
* New command-line interface (-h for help)
* Removed "box" simulation type
* Various bugfixes
Nova verzija donosi prilicno unapredjen algoritam za kreiranje kortikalne mreze koji je ne samo brzi (nekoliko puta) vec koristi jos vise bioloskih pravila pri generisanju sinapsi. Takodje, resen je problem kreiranja prevelikog broja kompartmenta posto je ranije neuron (tj. strukture koje drze kompartmente) bio kreiran pre nego sto su pronadjeni adekvatni kandidati za sinapse. To je za rezultat cesto imalo neurone koji imaju mnogo manje sinapsi po kompartmentu nego sto treba (tipa 2-3 umesto 40) sto je, naravno, dovodilo i do pogresnog ponasanja neurona.
Tipican primer su celije "non-basket" tipa (tipa double bouquet) koje zbog tog baga uopste nisu mogle da postignu depolarizacioni potencijal... sada je to fixovano :)
Evo kako to sada izgleda u praksi, na 1.4 miliona neurona i oko 140 miliona sinapsi:
Gustina celija je dovoljno velika da se pri visokoj rezoluciji (originalnoj - 2560x1600) moze videti "slojevitost".
Eksperimenti
Takodje, od ove verzije je moguce eksperimentisati sa ubacivanjem depolarizujuce struje u odabrani neuron ('I' na tastaturi).
- Ugasite mPSP ('minis') ako su ukljuceni (M dugme na tastaturi)
- Izaberite neki pobudjujuci neuron (najbolje SS4 u sloju 4 ili talamo-kortikalni "relej" neuron u talamusu)
- Pritisnite 'I' - ako je neuron uvezan sa dovoljnim brojem drugih neurona, doci ce do lancane reakcije
Takodje, sada je moguce kontrolisati nivo brainstem modulacije - pojacanje istog ce olaksati pobudjivanje relejnih neurona u talamusu.
Da bi brainstem modulacija funkcionisala mora biti ukljucen "stimulus insertion" mode (L dugme na tastaturi). Modulacija moze biti i "negativna" u kom slucaju ce doci do otezanog opaljivanja relejnih neurona sto se in-vivo desava u stanjima dubokog sna.
Osim brainstem-modulacije se mogu i slucajno pobudjivati neuroni u talamusu sa "sensory modulation" slajderom. Slajder kontrolise maksimalni intenzitet struje koja se slucajno unosi u talamicke neurone koji su zaduzeni za prenos informacija iz cula. Za sada nije moguce birati kontekst (vid, sluh, somato-senzorni) ali to ce biti dodato uskoro... trenutno to i nema puno smisla posto je broj relejnih neurona jako mali (8 hiljada na 1.4 miliona), to ce imati smisla sa simulacijama od 10 miliona neurona+ za sta ce biti potrebna CUDA akceleracija...
[Ovu poruku je menjao Ivan Dimkovic dana 04.03.2012. u 19:55 GMT+1]
Wireframe render je totalno izmenjen tako da sada koristi DSI traktove umesto linija za aksone.
Dodatni bonus su znacajno bolje performanse renderinga u -wireframe modu (bar na NVidia karticama, za AMD jos nisam testirao kao ni na Intel integrusama... ) + smanjena kolicina memorije za geometriju (nemojte se zbuniti ako procitate cifru koja je veca od v0.57 - u pitanju je bag stare verzije koja nije prijavljivala svu zauzetu GL memoriju)
* Initial support for external simulation configuration files
* External stimuli generation divided into visual, auditory and somatosensory modalities
* Further improvements of the wireframe (LineRender) renderer
Sa v0.59 je moguce koristiti eksterne konfiguracione fajlove (pogledajte npr. demoSmall.cfg) gde je moguce podesiti proizvoljan broj neurona, max. broj sinapsi po neuronu, jacine sinapsi itd...
Broj neurona vise nije ogranicen na nekoliko konfiguracija, vec je moguce uneti bilo koju vrednost (simulacija zahteva da broj neurona bude deljiv sa 256 - ako nije, tokom kreiranja ce broj biti "zaokruzen" na prvu manju vrednost deljivu sa 256).
Dodatna novina je mogucnost stimulacije odredjenih "cula" (vid, sluh, dodir) - simulacija ce generisati odredjen broj pseudo-slucajnih sinaptickih oslobadjanja na talamickim relejnim neuronima vezanim za odredjeno culo. Slajder odredjuje prosecan broj oslobadjanja po sekundi (od 0 do 5)
[ Ivan Dimkovic @ 20.03.2012. 21:49 ] @
v0.59a is out...
Pronalazenje DSI traktova je sada oko 20x brze u poredjenju sa v0.59... Primera radi, pronalazenje 1.5 miliona traktova je kod mene trajalo oko 34 sekunde ranije, a sada traje oko 1.5 sekunde.
Takodje sam eliminisao Boost thread-ove u DSI biblioteci tako da sada DLL-ovi mogu lepo da se spakuju na 300-400 KB posto nema vise ogavnih Boost TLS callback-ova ;-) Nadam se da cu imati vremena uskoro da eliminisem kompletan Boost-zavistan kod u DSI Studio biblioteci....
Informisao sam i autora DSI Studio-a o promenama na kodu tako da ce i DSI studio postati brzi cim autor bude implementirao optimizacije.
[ Ivan Dimkovic @ 26.03.2012. 19:50 ] @
v0.60 is out...
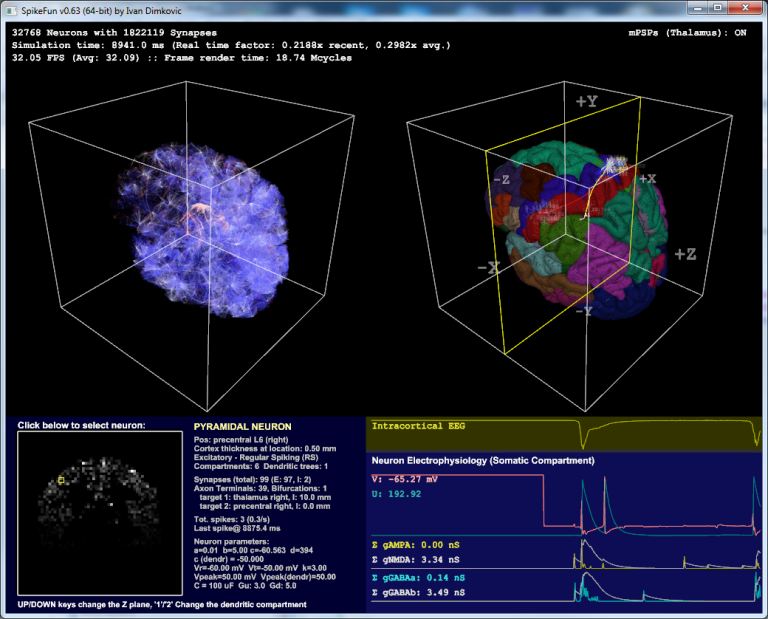
Samo jedna stvar je promenjena - wireframe render (*_HighGraphics demoi npr) sada koristi OpenGL shadere. Sa ovom promenom je render u -wireframe modu znacajno brzi sa mnogo manje CPU->GPU memorijskog kopiranja.
To takodje znaci da -wireframe mod vise nece moci da radi na prematorim grafickim karticama.
Doduse, sami shaderi su trivijalni, tako da bilo kakav harder koji podrzava iole moderniji OpenGL (tipa 2.0+, mada moguce je i da 1.5 radi) ne bi trebao da ima nikakvih problema sa njima. Na zalost nemam nista matoro ovde, ali Intel 2620M/HD4000, NVidia GTX 580 i ATI Mobility Radeon HD5650 rade bez problema.
v0.61 - Released on 8th April 2012
----------------------------------
* Default neuron library parameters are now user-accessible
(please see neuronLibrary.cfg file)
* Synaptic plasticity options are now user-accessible
(please see supplied demo .cfg files)
* Performance improvements of 64-bit build on CPUs with
AVX instruction set (Intel Sandy Bridge, AMD Bulldozer)
* Simulation memory layout optimizations
* Performance improvements of the Wireframe render
for multi-core systems
- Najveca promena je mogucnost editovanja parametara default neurona (neuronLibrary.cfg). Za sada je moguce editovati samo osnovne parametre, a uskoro cu dodati i menjanje parametara extended familija ukljucujuci i aksonalne parametre. Posle toga sledi dodavanje mogucnosti podesavanja parametara za kreiranje same mreze (npr. individualna debljina raznih delova korteksa kao i parametri povezivanja izmedju celija koji ce biti prosireni tako da mogu da se menjaju za svaki individualni deo korteksa / talamusa)
- 64-bitni AVX kod je dodatno rucno optimizovan (za Intel Sandy Bridge / AMD Bulldozer procesore) i sada je po prvi put brzi od 32-bitnog koda (i to 10-20% na Xeon E5-2687W CPU-u bar) tako da sada najzahtevnija rutina (racunanje sinaptickih provodljivosti) koristi svih 16 YMM registara i mislim da ne moze biti puno brza zbog ogranicenja memorijskog bandwidth-a... Ne verujem da ce CPU-kod biti dodatno ubrzavan do Haswell-a koji ce doneti FMA instrukcije.
- Takodje, sami projekti imaju vise opcija za podesavanje, npr. kompletno je moguce menjati parametre vezane za kratkotrajnu i dugotrajnu sinapticku plasticnost
- Wireframe render je dodatno ubrzan koristeci vise niti za sam render (na mojoj masini je vreme potrebno za render jednog frejma brainSmall projekta u Wireframe modu palo sa ~16 miliona RDTSC ciklusa na ~8-9 miliona RDTSC ciklusa)
- Wireframe render sada korektno renderuje inhibitorne neurone uzimajuci u obzir njihov individualni opseg membranskog potencijala izmedju Vr i Vp
+ bugfixevi itd...
[ Ivan Dimkovic @ 08.04.2012. 21:00 ] @
Mali update - uploadovao sam novu verziju (v0.62)
v0.62 ima novi low-complexity box render (demoi sa *_LowGraphics.bat) koji sada takodje koristi GPU shader-e. Probao sam kako to sada radi na Intel integrusi i mogu reci da je cak i podnosljivo :-))) Naravno, radi se o maloj simulaciji. Na nekoj postenijoj diskretnoj grafickoj bi trebalo da leti. Kao i za wireframe render, shaderi su trivijalni i trebalo bi da rade na bilo kakvom hardveru mladjem od dinosaurusa (OpenGL 2.0).
U svakom slucaju, box-render ce raditi na mnogo vecem broju konfiguracija posto zauzima mnogo manje video memorije. Male simulacije bi trebalo bez problema da rade i na iole modernim grafickim karticama sa 256 MB VRAM-a. Ako imate rendering probleme -disablevbo i dalje funkcionise (ali su shaderi i dalje potrebni).
[ Ivan Dimkovic @ 09.04.2012. 14:14 ] @
Jos jedan mali update (v0.63):
Dodao sam podrsku za FreeSurfer mape debljine korteksa (lh.thickness i rh.thickness fajlovi). Uz pomoc ovih mapa SpikeFun varira debljinu sive mase na svakom 3D temenu. Za sada za svaki trougao koristim prosecnu vrednost sva 3 temena i ta debljina se koristi za sve neurone koji se generisu "ispod" tog trougla ali cu uskoro dodati i interpolaciju uz pomoc baricentricnih koordinata (za svaki neuron, u odnosu na njegove baricentricne koordinate na povrsini)
Takodje, debljinu korteksa na lokaciji je sada moguce videti kada se izabere kortikalni neuron:
[Ovu poruku je menjao Ivan Dimkovic dana 09.04.2012. u 15:31 GMT+1]
[ Ivan Dimkovic @ 10.04.2012. 23:43 ] @
v0.64 is out...
- Jos malo OpenGL optimizacija :)
- Verovatnoca mPSP oslobadjanja se sada moze podesavati
(default: 1 oslobadjanje po sinapsi po sekundi, random)
- 64-bitna verzija je imala bag u prikazivanju fMRI slike, to je sada popravljeno
Please consider open-sourcing this piece of impressive work. Put it up on GitHub, Google Code or some other preferred repository under any sort of FOSS licence, so that we can learn from it and explore computational neuroscience on the level that is already comparable with the big academic neural simulations.
The temporary messiness or incompleteness of the code isn't an issue, we all have the same sort of thing with our own projects. :)
[ Tyler Durden @ 11.04.2012. 08:02 ] @
Stvarno Dimkovicu, mogao bi da otvoris kod.
Sta te sprecava?
[ Ivan Dimkovic @ 11.04.2012. 22:10 ] @
@mindbound,
First of all, thanks for your kind words. Regarding open sourcing, I will give this a thought - but it will definitely have to be cleaned-up first if I decide to open it, it is just me and myself not liking untidy code :)
@Tyler, ne sprecava me nista osim sto ne mislim da je kod u stanju za bilo kakvo otvaranje u ovom momentu.
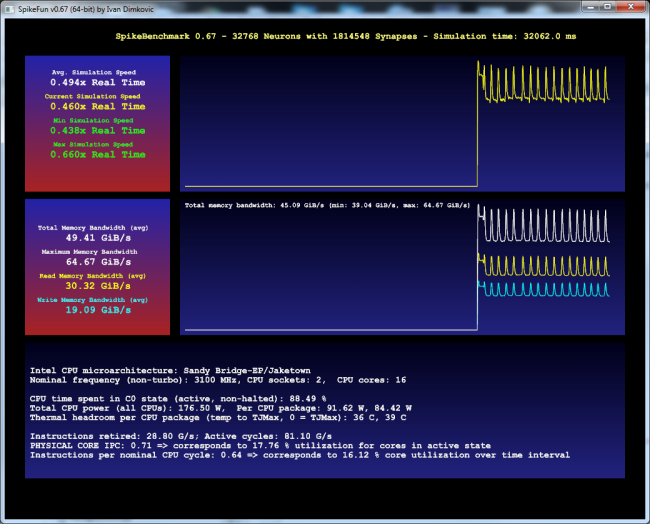
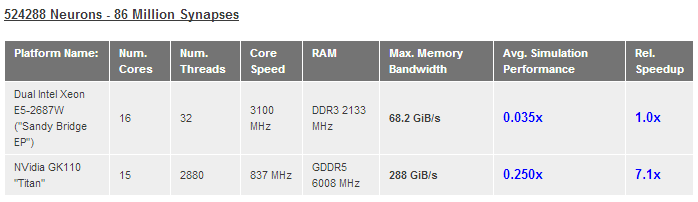
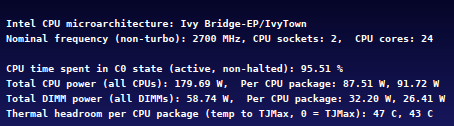
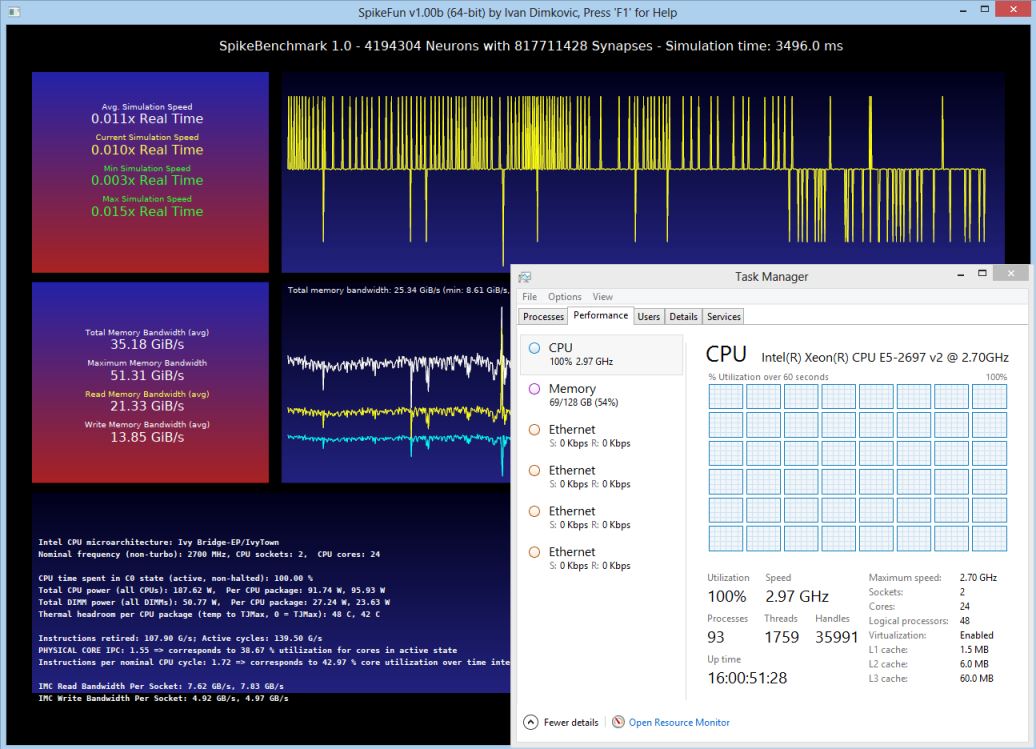
Evo kako stvari izgledaju na 2 x Xeon 2687W masini (3.1 GHz, 2 CPU-a, 16 jezgara, ASUS Z9PE D8 WS ploca):
Kao sto se vidi, razlike su prilicno velike - rucna optimizacija alokacije memorije i thread schedulinga donosi drastican skok u performansama. Takodje, na ovom primeru se vidi i da Windows scheduler nije bas efikasan kada je kod neoptimizovan za NUMA-u tako da zapravo dolazi do pada u performansama u poredjenju sa sistemom koji nema NUMA ACPI tabele.
SpikeFun 0.65 koristi sledece strategije za NUMA optimizacije:
- Ravnomerna alokacija memorije za neurone po NUMA cvorovima
- Afinitet i optimalni CPU za svaki worker thread odgovaraju NUMA arhitekturi sistema
- Work thread manager se trudi da worker niti prvo procesiraju neurone u sopstvenom NUMA cvoru i tek ako je sve u njihovom cvoru gotovo prelaze da "pomazu" u drugim cvorovima
- Spike delivery je razdvojen na lokalne i strane neurone (po NUMA nodu) gde se lokalni spajkovi procesiraju na samom spike-delivery thread-u (koji ima afinitet na lokalnom CPU-u) dok strani neuroni bivaju prebaceni na strani NUMA nod, gde ce ih procesirati lokalni worker thread
Za XP korisnike: Windows XP nema VirtualAllocExNuma() API, tako da nije moguce naterati Windows memory manager da alocira memoriju na odredjenom NUMA cvoru, tako da ce performanse biti vidno losije - za najbolje performanse preporucujem >bar< Windows Server 2008 / Vista-u a optimalno Windows Server 2008 R2 / Windows 7 koji imaju dodatne multi-CPU optimizacije.
[Ovu poruku je menjao Ivan Dimkovic dana 22.04.2012. u 01:16 GMT+1]
[ Ivan Dimkovic @ 22.04.2012. 18:23 ] @
v0.66 is out...
Dodata je opcija za koriscenje "large page" memorije. Large-page memorija koristi vece stranice (npr. 2 MB umesto 4 KB) tako da u procesorski TLB cache stane znacajno vise adresirane memorije. Rezultat su poboljsane performanse u memorijski-intenzivnim aplikacijama, pogotovu na 64-bita.
Jedini problem sa large-page memorijom je sto Windows memory manager trazi da region bude kontinualan - ovo nije uvek moguce, pogotovu posle dugog rada racunara gde dolazi do fragmentacije memorije. SpikeFun ce pokusati da alocira large-page region - ako alokacija ne uspe, bice alociran region sa normalnom velicinom stranica.
Osim ovoga, uradjeno je jos par optimizacija tako da, recimo, na referentnom testu SpikeFun postize 0.430x real-time faktor.
[ Ivan Dimkovic @ 22.04.2012. 23:29 ] @
A evo i novog shader-based rendering engine-a na delu (izaberite 1080p ili "original size" ako imate 2560x monitor):
* Added benchmarking option (-bench) for system performance
benchmarking purposes. Please see the benchmark.pdf file
for a description of the typical benchmark scenarios
* Added support for forcing the PRNG to emit fixed sequence
of pseudorandom numbers (-fixrand). Enabled by default for
-bench mode
* Improved logging of performance-related data (simulation
real-time factor, renderer frame rate, etc.)
* Added option for system hardware profiling using Intel(r)
Performance Monitoring Unit (PMU). Based on Intel's PCM
tool (see copyrights.txt), SpikeFun supports measurement
of memory bandwidth (Sandy Bridge EP/Jaketown CPUs only),
CPU power draw (Sandy Bridge, SB-EP), CPU temperature
(Nehalem and later), IPC rate and C0 residency. Please
note that hardware profiling requires accessing of the
MSR registers, which typically requires administrator
privileges (to load SpikeMsr.sys / pikeMsr64.sys driver)
* Optimized memory prefetching strategy, bringing about
3-5% improvements on multi-socket NUMA systems
* Additional AVX optimizations
* Memory optimizations for synaptic receptor and
axonal terminal storage
* Wireframe render now also contains wireframe render of
the pial surface
* Various bugfixes
Od ove verzije je moguce raditi benchmark sistema (pogledajte benchmark.pdf, kao i benchmark_???_??bit.bat fajlove). Implementirana su 4 benchmarka:
- benchmark_small_??bit.bat --> Benchmark za desktop sisteme (32768 neurona, 1.8 miliona sinapsi)
- benchmark_small_max_bandwidth_??bit.bat --> Kao (#1) ali sa potpuno tihom mrezom (maksimalni memorijski bandwidth)
- benchmark_large_64bit.bat --> Benchmark za workstation/server sisteme (trazi 6 GB RAM-a, 262144 neurona, ~38 miliona sinapsi)
- benchmark_large_max_bandwidth_64bit.bat --> Isto kao #3, samo sa ugasenom mrezom (max. bandwidth)
Na mojoj referentnoj masini su max rezultati za mali benchmark (#1):
Code:
Intel CPU microarchitecture: Sandy Bridge-EP/Jaketown
Nominal frequency (non-turbo): 3100 MHz, CPU sockets: 2, CPU cores: 16
Takodje, od ove verzije je implementirana podrska za Intel PMU registre za merenje performansi - sa njima je moguce nadgledati IPC (instructions per cycle), memorijski bandwidth (na Socket 1366 i Socket 2011 procesorima), potrosnju CPU-a, temperaturu i sl...
Evo kako to izgleda kod mene:
Takodje, ova verzija ima potpuno nov kod za merenje performansi, FPS-a i sl.. tako da bi trebalo da nema vise praistorijskih bagova sa FPS displejom. Performanse na NUMA masinama su dodatno unapredjene, tako da sada simulacija kod mene dostize ~0.515x real-time factor - sto je prilicno veliko unapredjenje od ~0.32-0.33x sa kojima sam poceo NUMA optimizacije.
Kao sto se vidi, za 32768 neurona i 1.8 miliona sinapsi bi bilo potrebno oko 100 GB/s memorijskog I/Oa za real-time performanse... To jako lepo oslikava koliko je arhitektura danasnjih racunara nepodesna za neuronske simulacije - ako uzmete u obzir da, recimo, jedna macka ima oko 300 miliona neurona u korteksu sa vise stotina milijardi sinapsi...
Da li je moguce napraviti model mozga obicne muve ili ose koji bi mogao da procesira vizuelne podsticaje i da kao izlaz ima vektore koji bi ga usmeravali ka odredjenom cilju ?
Muva ima oko 340 000 neurona, dok neke vrste osa imaju mizernih 4600 neurona.
[ Ivan Dimkovic @ 02.05.2012. 19:14 ] @
Pa... ako hoces da modeliras mozak muve, vrlo verovatno ces morati da modeliras i celu muvu.
U principu, najlakse bi bilo poci od C. Elegans-a (nematoda) koji ima ukupno samo 302 neurona, koji su uvek isti.
Medjutim, iz nekih razloga modeliranje ovog crva nije vrlo popularno :)
[ Igor Gajic @ 02.05.2012. 19:17 ] @
Model primitivnijeg insekta bi bio vrlo zanimljiv, pogotovo iz vojne perspektive. Navodjenjenje projektila kao jedan primer.
[ Ivan Dimkovic @ 04.05.2012. 19:21 ] @
:-)
IMHO, za navodjenje projektila ti ne treba bas imitacija prave muve - daleko jednostavniji algoritmi rade posao.
Cak i ako bi u neko dogledno vreme bilo moguce replicirati "muvlju inteligenciju" razmisli koliko bi to bilo prakticno, mislim da li mozes da nateras pravu muvu da radi nesto korisno? Vestacka muva koja "emulira" pravu ne bi bila nista korisnija :-)
Moje licno misljenje oko kompleksnih neuronskih modela je da ce te stvari biti daleko korisnije ako se primene na nove, ne prirodne nacine - bioloska inteligencija prima informacije preko prirodnih "senzora" ogranicenih na samo nekoliko modaliteta. Vestacka inteligencija ne bi patila od tih limitacija.
Na primer, umesto "ociju" ulaz bi mogla da bude globalna meteoroloska mreza za detekciju zemljotresa ili cunamija i sl...
Btw, porucio sam 64 GB DDR3-2400 memorije (2 x G.Skill TridentX 32 GB), posto nisam mogao da cekam na DDR3 2666 :-) Dobra stvar sa dual-CPU plocom je sto procesori koriste potpuno odvojenu memoriju, pa nemas problem da sva memorija mora da bude "uparena", sto znaci da 2 posebna 32 GB kit-a savrseno rade na max. frekvenciji.
Sa jednim CPU-om sve mora da bude upareno - znaci 8 DIMM-ova moraju biti kupljeni u kitu ako se ocekuje 100% da ce sve raditi na nominalnoj frekvenciji memorije...
A stigao mi je i digitalni sertifikat za authenticode - pa cu moci da distribuiram custom Ring0 drajvere za hw. profiling :-)
* Added support for processor groups (feature of Windows
Server 2008 R2 / Windows 7 or newer kernels). With this
addition, SpikeFun can now properly schedule threads on more
than first 64 processors installed on the system
* Added support for simulation video capturing to Google(R)
WebM(TM) format (enabled with -webm switch). Configuration
options are added to control the WebM encoding quality (e.g.
target bitrate, bit allocation mode - CBR/VBR/CQ, FPS).
Please see webm.txt for the licensing / copyright info.
* Improved spike-delivery load balancing on NUMA systems.
Number of threads has been reduced by the number of logical
CPUs installed on the system
* Added memory-bandwidth estimation for systems that do not
expose hardware monitoring registers for memory bandwidth
measurement (NOTE: only total memory bandwidth is estimated)
* Added additional options allowing manual specification of
the simulation rendering window size (-height and -width
command line parameters)
* Added command line option to control rending thread priority
(-hpgui)
* Fixed crashing on systems where number of logical CPUs is
not power of 2 number (e.g. 3/6-core CPUs)
* Switched to GLEW (The OpenGL Extension Wrangler Library) for
initializing and managing various OpenGL extensions that are
not part of standard Windows OpenGL API set (pretty much any
recent OpenGL API). Please see glew.txt for the GLEW
copyright note / licensing info
Verzija 0.68 donosi podrsku za procesorske grupe (Windows Server 2008 R2 / Windows 7 kernel, 64-bitna verzija). Procesorske grupe omogucavaju scheduling thread-ova na procesore ciji je indeks veci od 63 (sistemi sa 64+ procesora). Windows NT kernel 6.1 podrzava max. 4 procesorske grupe, sa 64 procesora u svakoj - sto omogucava max. 256 procesora.
Takodje, dodatno je optimizovano "dostavljanje" spajkova na NUMA sistemima tako da je sada broj worker thread-ova smanjen za N (gde je N broj logickih procesora na sistemu) a performanse su iste ili bolje + latencija je manja zato sto je manji broj niti koje scheduler mora da "provrti".
Dodao sam i WebM format za video capture, tako da je sada moguce direktno snimiti simulaciju u jedan (.webm) fajl, umesto u niz JPEG slika koje je onda neophodno kompresovati u video fajl kao do sada. Preko komandne linije je moguce podesiti ciljni bitrate, nacin alokacije bitova (CBR, VBR, CQ) kao i min/max kvantizatore i kvalitet.
Sve u svemu, WebM nije bas spektakularan sto se kvaliteta i brzine tice (SpikeFun ce podesiti WebM lib da koristi vise niti) - dobri H.264 enkoderi su i brzi i daju vidno bolji kvalitet za istu kolicinu bitova, ALI WebM je bar nominalno "besplatan" sto se tice patenata (bar za sad) tako da je meni lakse da ga ukljucim u besplatan app nego H.264 gde bih eventualno mogao imati problema sa vlasnicima patenata...
Na kraju krajeva, postoji workaround za kvalitet - a to je da se bitrate nabije na neku visoku vrednost (ja snimam u 128 Mbit/s :-) za youtube upload...)
Jos jedna novina je u benchmark modu: sada se radi procena memorijskog bandwidth-a na sistemima koji nemaju hardverske registre za merenje memorijskog I/O-a... U pitanju je vrlo gruba procena ali sam je "kalibrisao" na sistemu koji ima hw. registre i predvidjanje je obicno unutar ~5% sto je opet bolje nego nista.
* WebM capture is now default capture method, for JPEG-sequence
capture please use -jpeg switch
Takodje, od verzije 0.69 SpikeFun.exe i SpikeFun64.exe su "launcheri" za odgovarajuci DLL - ovo je uradjeno zbog nekih problema sa mesanjem AVX i SSE koda u 32-bitnoj verziji, tako da se sada ucitava ili SSE ili AVX DLL, sto takodje malo poboljsava i performanse posto nema dinamickog patch-ovanja koda kao ranije.
[ Ivan Dimkovic @ 17.05.2012. 20:04 ] @
v0.70 is out...
Nema nekih velikih promena osim par bugfixova i razdvajanja tracto biblioteke na SSE i AVX verzije.
[ Ivan Dimkovic @ 30.05.2012. 22:05 ] @
Malo sam eksperimentisao sa mogucnostima skaliranja SpikeFun-a :)
Na primer, 8 miliona neurona sa 1.45 milijardi sinapsi:
Nekoliko zanimljivih fakata:
- Simulacija zauzima 130 GB RAM-a
- Dodatnih 20 GB RAM-a je potrebno za pomocne podatke (vizualizacija, DSI traktovi, ...)
- Za procesiranje jedne sekunde simulacije je neophodno "provuci" oko 200 TB podataka kroz procesor
- Za vodjenje aksona je "izvuceno" 16 miliona DSI traktova
- Kreiranje simulacije je trajalo oko 1 sat i 10 minuta na 16-core masini
- Prosecan broj sinapsi po neuronu je ~175
[ Texas Instruments @ 30.05.2012. 23:30 ] @
Xe, xe. Samo se ti igraj, videćeš kad jednog dana računar dobije ekstremitete i odšeta iz sobe. :)
- Simulacija zauzima 130 GB RAM-a
- Dodatnih 20 GB RAM-a je potrebno za pomocne podatke (vizualizacija, DSI traktovi, ...)
- Za procesiranje jedne sekunde simulacije je neophodno "provuci" oko 200 TB podataka kroz procesor
- Za vodjenje aksona je "izvuceno" 16 miliona DSI traktova
- Kreiranje simulacije je trajalo oko 1 sat i 10 minuta na 16-core masini
- Prosecan broj sinapsi po neuronu je ~175
Uh ovo je odlican izgovor da UVEK imas najnapucaniji komp u stanu, bez da se zena/devojka ljuti sto trosis hiljade evra na isti... :P ...ustvari, ljutice se one u svakom slucaju, al bar imas opravdanje. :D
[ ventura @ 31.05.2012. 14:00 ] @
Taj server mora da vuče kilowat struje, što ako radi 24/7 po Nemačkim tarifama dođe oko 200 evra mesečno :)
[ Ivan Dimkovic @ 31.05.2012. 16:57 ] @
Verovao ili ne - ne vuce :)
Bas cu da izmerim veceras ako stignem - memorija vuce oko 65W, procesori vuku oko ~160-180W (oba) u full-loadu (undervoltovani), graficka oko 200W pod load-om... cipset je verovatno oko 20W, hardovi 50-tak max., SSD-ovi 10-15...
Sve u svemu, sumnjam da ide preko 500-600W, ako i toliko.
Razlog je sto Xeon E5 ne mozes da overclock-ujes, nominalni TDP po komadu je 150W ali u praksi zbog niske voltaze + dodatnog undervoltinga ne prelazi 100W ni u najgorem load scenariju. Da je Intel dopustio overclock kao na consumer verziji Sandy Bridge E procesora onda bi pricali o necemu drugom, sa 1.35v i 4 GHz bi 2687W vukao bar 200W ako ne i vise.
Trenutno oba procesora hladim sa tihim Noctua ventilatorima, i temperatura na otvorenom kucistu ne prelazi 50C.
Citat:
mr.ako
Uh ovo je odlican izgovor da UVEK imas najnapucaniji komp u stanu, bez da se zena/devojka ljuti sto trosis hiljade evra na isti... :P ...ustvari, ljutice se one u svakom slucaju, al bar imas opravdanje. :D
Hehe yep :)
[ negyxo @ 31.05.2012. 17:01 ] @
Haha, nasmejali me kometari, pa moram da dodam, Ivane gasi internet kada to cudo radi, mozda skonta samog sebe pa dobijemo skynet :-)
[ Ivan Dimkovic @ 31.05.2012. 19:40 ] @
Hehe
Evo izmerih sada potrosnju - u idle-u makina vuce 210W a u full load-u 448W.
Cenim da idle potrosnja moze da se spusti jos, i da vecina iste dolazi od GTX580 graficke.
[ ventura @ 01.06.2012. 00:10 ] @
Znači 85 evrića za struju mesečno :)
[ Ivan Dimkovic @ 01.06.2012. 12:43 ] @
Pa dobro ne trci taj server 24/7 - u standby modu trosi oko 20-tak W a imam wake-on-demand ako mi treba kada nisam qci :-)
Struju kupujem unapred, 4000 kWh za godinu dana "prepaid" - do sada jos nisam dobio ekstra racun :-))
Morao sam da doplacujem ranije, dok sam imao staru Core 2 Extreme masinu sa GTX 8800 grafickom - ta zver je trosila preko 800W u load-u, zahtevala je vodeno hladjenje (cak sam uradio volt-mod na grafickoj) i vise puta mi je iskakao glavni osigurac zbog te masine... to su bila vremena.
[ ventura @ 01.06.2012. 13:36 ] @
Citat:
Ivan Dimkovic:
Struju kupujem unapred, 4000 kWh za godinu dana "prepaid" - do sada jos nisam dobio ekstra racun :-))
v0.71 - Released on June 03rd 2012
----------------------------------
* Improved DSI tract mapping
* Automatic cortical thickness scaling
* Improved simulation creation speed with SSE4-optimized
segment-triangle hit testing (used for neuron topology
build-up) and further small optimizations
* Even faster pseudo-random number generator
* Added SSE4-optimized DLL builds for newer Core 2 and
first generation Core i3/5/7 computers
Ova verzija donosi 10-20% ubrzanje u kreiranju simulacija, zahvaljujuci rucno raspisanim asemblerskim rutinama za testiranje presecanja duzi sa trouglovima kao i jos brzi pseudorandom generator (na masinama koje imaju SSE4).
Takodje, od ove verzije se intenzivno koriste neke SSE4 instrukcije kao recimo dpps (skalarni proizvod) - zbog toga sam kreirao i posebne SSE4 dll-ove za ljude koji jos nemaju Sandy Bridge ali imaju bar 45nm Core 2 (ili prvu generaciju i7 masina - Nehalem/Westmere). SSE4 optimizacije se, naravno, automatski koriste u AVX modu.
Jos malo je doteran i DSI tracking tj. ko-registracija (uravnavanje) sa korteksom... Takodje, od ove verzije se automatski racuna debljina korteksa na osnovu scaling-factora celog mozga, nema potrebe da se eksplicitno navodi u konfiguracionim parametrima (mada je sada dodata opcija za dodatno forced skaliranje ako neko zeli da eksperimentise).
[ Ivan Dimkovic @ 03.06.2012. 23:26 ] @
Posto je vrlo brz, okacio sam kod pseudorandom number generatora ovde:
Kod koristi SSE4 (kad moze) i brzi je nekih ~27 puta od MSVC rand() implementacije. I ne samo sto je brzi, vec je i daleko kvalitetniji po pitanju "slucajnosti" izlaza. U pitanju je MWC1616 algoritam (MWC = Multiply-with-carry) ciji je autor George Marsaglia. Period ovog algoritma je veci od 10^18, i kao takav je drasticno bolja alternativa od rand() implementacije u MSVC-u - kako po statistici tako i po brzini.
Na test masini, koristeci jedno jezgro moja SSE4 implementacija moze da generise oko 2 milijarde slucajnih brojeva u sekundi. Microsoftov rand() za istu kolicinu brojeva radi 27 sekundi. To prakticno znaci da za generisanje jednog pseudo-slucajnog broja moja MWC1616 implementacija trosi oko 1.5 ciklus ili ~0.5 ns.
Uskoro (sledece godine :-) ce biti moguce udvostruciti performanse uz pomoc AVX2 instrukcijskog seta koji ce biti lansiran sa Haswell arhitekturom. Doduse, vec Ivy Bridge ima hardverski generator slucajnih brojeva koji su FIPS-140 kompatibilni, ali je u stanju da ispuca manje brojeva za isto vreme (oko 2-3 Gbps).
Kod mozete skinuti odavde, kod je licenciran pod BSD licencom, tako da ga mozete koristiti u vasim projektima.
Implementacija je neverovatno jednostavna - evo SSE4 snippeta, koji koristi SSE intrinsics f-je, pa bi trebao da radi na svakom postenom kompajleru:
Code:
//////////////////////////////////////
// MWC1616 --> SSE4 version //
// Copyright (C) 2012 Ivan Dimkovic //
// Licensed under BSD license //
//////////////////////////////////////
static inline void FastRand_SSE4(fastrand *f)
{
__m128i a = _mm_load_si128((const __m128i *)f->a);
__m128i b = _mm_load_si128((const __m128i *)f->b);
SSE4 verzija koristi pmullud instrukciju koja omogucava da se u jednom prolazu pomnoze 2 vektora sa 4 32-bitna integera. Za CPU-ove bez SSE4 to mnozenje se mora razbiti na 2 dela - visi i nizi 16-bitni, i 32-bitni rezultat se na kraju dobija shift-ovanjem i OR-ovanjem medju-rezultata, sto zahteva nesto vise instrukcija od SSE4 verzije.
[Ovu poruku je menjao Ivan Dimkovic dana 04.06.2012. u 01:25 GMT+1]
v0.72 - Released on June 10th 2012
----------------------------------
* Updated tractography module to the latest DSI Studio
code-base (June 4th)
* Better fiber source (more inclusive brain mask generated
with non-linear registration of T1 MRI to DSI B0 and
extracting brain mask from the registered structural MRI
image)
* Improved DSI tract->surface mapping accuracy with very
little performance penalty for the level 0 (see below)
* Added option to control the DSI tract->surface mapping
precision (accuracy) with '-dsimaplevel <n>' switch,
where n can be:
0 --> Fastest mapping (precision better than v0.71)
1 --> Better precision
2 --> Best precision (slowest)
Default mapping level as of v0.72 is 2, you can get it
to lower level if you are running the simulation on a
slower computer and feel that DSI tract to surface
mapping is taking too much time
* Fixed DSI tract rendering bug (extra lines)
Verzija 0.72 donosi znacajno unapredjen proces kreiranja konektoma. Fiber tracking biblioteka bazirana na DSI Studio kodu je upgrade-ovana na najnoviju verziju koda.
Ali to je samo pocetak - sam kod za mapiranje traktova na kortikalne i talamicke strukture je ispisan ponovo tako da je preciznost drasticno unapredjena. Ovo za rezultat ima anatomski-korektno mapiranje konekcija.
Sledece unapredjenje je u samom izvoru traktova - u predhodnim verzijama je korisceno automatsko kreiranje mozdane maske kao ulazni parametar za generisanje fibera. Na zalost, DSI Studio propusta bitne strukture i ima suvise grub algoritam za generisanje maske. Ovo je popravljeno tako sto koristim FreeSurfer za kreiranje maske a onda tu bolju masku importujem u DSI Studio. Rezultat je potpuniji seeding region za traktove.
Takodje, uravnavanje anatomskih i povezujucih izvornih podataka je poboljsano posto sada koristim i T2 snimak i registraciju izmedju T1/T2 i DSI MRI snimaka. Rezultujuca afina transformaciona matrica sa 12 tacaka se koristi u SpikeFun engine-u za transformaciju traktova tako da se oni slazu sa kortikalnim itd... povrsinama. Ova procedura je neophodna posto DSI snimci obicno imaju distorzije i nisu identicni strukturnim T1 MRI snimcima (koji se koriste za kreiranje povrsina). Bez korekcije distorizija dolazi do razlike tj. gresaka u pozicioniranju traktova na kortikalne i sub-kortikalne strukture koje su generisane uz pomoc T1 MRI snimka.
v0.73 - Released on June 17th 2012
----------------------------------
* Improved neuron and axon vertical placement using
interpolated mesh normals and cortical thickness
(interpolation using barycentric coordinates of the
cortical/thalamic mesh triangles below which somae/axons
are located)
* Further improvements (precision) of DSI tract mapping
* Added option to limit the number of tracts that will be
rendered (-trdrawlimit <N> where N can be a value between
0 and 5)
* Improved neuron picking precsion
* Fixed bug that resulted in incorrect cortical thickness
calculation
* Improved thalamic surfaces (better matching to the
anatomic MRI data)
* Fixed a bug where moving/panning/zooming of the camera
and responding to GUI elements became very slow if the
3D data takes considerable time to render
[ mindbound @ 18.06.2012. 00:01 ] @
Please consider open-sourcing this, it's like a cock tease for a computational neuroscience enthusiast with far too many ongoing programming endeavours to make yet another thing from scratch such as myself. :D
Seriously, from what can be seen it does look like for massive biologically realistic networks your codes are currently the most interesting non-supercomputing level thing out there.
[ Ivan Dimkovic @ 24.06.2012. 16:34 ] @
@mindbound, thx! Like I said I will consider open-sourcing at some point when the code is mature and clean.
v0.74 - Released on June 24th 2012
----------------------------------
* Fixed fMRI BOLD calculation bugs (fade out during pause)
* Various OpenGL speedups (reduced state changes, all graphs
are now drawn using VBOs)
* Switched to freetype+FreeType-GL for font rendering,
ensuring unique text look across graphics cards and
operating systems and also improving rendering
performance (text rendered directly to vertex buffers)
* Switched to DejaVu open fonts instead of using Microsoft(R)
Windows(TM) system fonts ensuring consistent look even
when SpikeFun is run with Wine on Linux
* Fixed a bug where contralateral tract was selected in place
of ipsilateral tract for axon guidance in rare cases
Ova verzija sadrzi razne OpenGL optimizacije, i prelazak na freetype font rendering. Ostalo je jos samo jedno mesto u kodu gde se koristi wglUseFontOutlines() - sinapticke tezine. Kada to zamenim, ceo kod ce biti potpuno nezavistan od Windows font rasterajzera.
Takodje, presao sam na DejaVu fontove, umesto Windows fontova - tako da je to jos jedan korak ka nezavisnosti od Windowsa. Kada budem uklonio poslednji trag Windows font engine-a jedino sto je ostalo sto je Windows-specific je osnovni GUI (glavni prozor i dijalozi).
Evo kako izgleda renderovanje fontova uz pomoc freetype i Freetype-GL biblioteka:
Dodatne prednosti koriscenja freetype engine-a:
- Tekst izgleda isto na svim verzijama Windows-a i na razlicitim grafickim karticama
- Ako se SpikeFun tera pod Wine-om na Linux-u, isto vise nece biti razlika u izgledu teksta
- Bolje performanse zato sto se tekst renderuje uz pomoc vertex-bafera za razliku od displej lista koje koristi wglUseFontOutlines()
[ cluemarine @ 28.06.2012. 18:06 ] @
Ivan, Igor, for simulation of Caenorhabditis elegans neural network, there is an open source simulator called "openworm" here:
Skinuh danas i pokrenuh ga, ali program "Stops working",
nakon klika na "Restore Defaults" (u Simulation Configuration).
Ne daje neku posebnu poruku samo pukne.
(i 32 i 64 bit verzija)
Komp je Intel C2D E6850 sa 4GB rama, Intel ICH9R chipset, graficka GF GTS 450, 1GB ddr5
nvidia drajveri su 301.42
Ako oces neki debug info, reci gde ga ima :)
[ Ivan Dimkovic @ 01.07.2012. 16:18 ] @
Ne radi trenutno restart simulacija, moras da kreiras simulaciju u .cfg fajlu i da je startujes iz komandne linije...
Znam, prljav kod :) Ali sta je tu je :)
@edit - a vidim sad, ovo nije normalno. Bice fixovano veceras.
[Ovu poruku je menjao Ivan Dimkovic dana 01.07.2012. u 17:32 GMT+1]
[ Srđan Pavlović @ 01.07.2012. 16:35 ] @
Onda sam pokrenuo i onaj prvi batch file (large 64 bit),
radio je, ali je pukao kada sam kliknuo na "Stop Simulation".
Inace, taj prvi batch nije za moju kantu, otelila se jadna
prvo dok nije kreirala sve, a posle simulacija pici u nekih 4fps :)
Mada, ukljucio sam u nvidia driverima obavezni AA i AF na 2 ili 4x... tako nesto...
tj. kod nvidia drivera mi nije sve na defaultu, ako ima neka znacajna stavka
reci da proverim, zbog nekih igara sam malo podesio setup drivera kako mi odgovara.
[ Ivan Dimkovic @ 01.07.2012. 16:39 ] @
Fixovao sam oba baga - nije nista do tvojih drajvera :)
v0.75 - Released on July 1st 2012
---------------------------------
* Connectome mapping speed optimizations
* Added support for Ivy Bridge CPU hardware monitoring
in benchmark mode
* Added performance-workaround for Intel HD graphics
(MSAA antialiasing will be disabled for Intel HD graphics)
* Bugfixes (crashes when trying to stop simulation, or
'restore defaults' in the simulation configuration)
Posto Intel HD graficke imaju pateticne performanse kada je ukljucen MSAA (multisample antialiasing) posto verovatno isti racunaju "na silu" sada ce MSAA biti iskljucen u slucaju Intel HD graficke. U tom slucaju FPS skace nekoliko puta.
Naravno, onda sve izgleda krzavo - zato cu u nekoj od sledecih verzija dodati neki od onih shader post-procesing AA algoritama tipa FXAA ili SMAA...
- Font rendering na ATI karticama (bag u freetype-gl biblioteci), napravio sam workaround koji resava problem sa vertex. atributima tako sto gamma/shift parametre piggybackuje u z/w koordinate tekstura. Prijavio sam bag autoru - posten fix ce zahtevati vecu izmenu koda za mapiranje atributa... do tada, moj workaround radi posao
- Poslednjih 128/256 neurona nisu bili pravilno inicijalizovani. Ovo je najvise kacilo male simulacije posto su poslednji neuroni zapravo talamicki neuroni, a kako ih ima ~1%, male simulacije su imale veliki % lose inicijalizovanih talamickih neurona
A sa njim i puno novih stvari... Ova verzija donosi potpuno izmenjen konfiguracioni sistem koji je sada XML-baziran, i koji otvara kompletnu konfiguraciju za simulaciju i modele neurona. Od sada modeli neurona vise nisu hardcode-ovani vec su kompletno definisani u svojim XML "model" fajlovima. Koga zanima, kompletna biblioteka neurona je sada u /NeuronLibrary folderu.
Takodje, ista stvar vazi i za statistike uvezivanja izmedju neurona, kao i raspodelu tipova neurona - u principu, od ove verzije je moguce skoro kompletno izmeniti simulacije i kreirati eksperimente. Ali ovo je tek pocetak - u sledecim verzijama ce biti ubacena mogucnost konfigurisanja razlicitih nacina uvezivanja neurona po delovima mozga (npr. drugacija statistika uvezivanja za frontalni korteks u odnosu na somato-senzorni, itd...)
Code:
v0.77 - Released on July 24th 2012
----------------------------------
* New XML-based configuration manager and project format
* XML-based neuron libraries, including open access to
neuron type parameters, including adding/removing base
and extended neuron types, modifying electrophysiological
parameters as well as axonal and dendritic arbor spreads
(defined for each brain structure / layer)
* Each base and extended neuron types are identified by the
corresponding UUID, allowing for complete freedom in the
simulation arrangements (not relying on hardcoded neuron
names / types)
* XML-based and fully configurable cortical connectivity
parameters, including per-neuron-type synaptic connectivity
statistics, per-neuron type allocation ratios for number
of cells and synaptic receptors
* Configurable axonal action potential propagation velocity
(axon conduction velocity) for each individual base neuron
type (separate parameters for myelinated and non-myelinated
axonal collaterals), allowing for different speeds of
spike propagation based on the neuron type
* Configurable per-neuron type axonal projection/bifurcation
parameters allowing for custom branching rules for each
neuron type (projection destination, ipsilateral vs.
contralateral hemisphere, etc.)
* Added -noopengl option to allow benchmarks without need
for graphics / GUI. Useful for benchmarks on the server
systems with limited or no graphics hardware at all
* Memory allocation fix for firing buffer (crashes if the
number of spikes was extremely high)
* Fixed several incorrect parameters related to the cell
electrical behavior
Nastavljena su poboljsanja u mogucnostima konfiguracije simulacije. Sada je moguce definisati karakteristike sinapticke veze za svaki par baznih tipova neurona ([pre sinapticki][post sinapticki]). Uz pomoc ovih parametara je moguce imati neurone koji formiraju razlicite jacine sinapticke veze u zavisnosti od ciljnog post-sinaptickog neurona.
U buducim verzijama ce biti uvedena i mogucnost da jedan neuron deluje pobudujuce za jednu grupu post-sinaptickih neurona i inhibitorno za drugu grupu, kao npr. neuroni iz retikularnog aktivacionog sistema mozdanog stabla koji pobuduju relejne neurone iz talamusa a inhibisu retikularne talamicke neurone promovisuci budnost... no, o tome neki drugi put :)
Dodata je i mogucnost definisanja relativinih debljina individualnih kortikalnih slojeva. Takodje, moguce je definisati razlicite debljine kortikalnih slojeva za razlicite regione (recimo - primarni vizuelni korteks, pre frontalni korteks i sl...). Ove relativne velicine ce onda biti skalirane za svaku lokaciju uz pomoc ukupne kortikalne debljine na toj lokaciji. Za sada ova opcija nije preterano korisna, ali bice uskoro kada budem implementirao podrsku za definisanje razlicite raspodele neuronskih veza za razlicite delove korteksa :-)
I, konacno, dodata je opcija za konfiguraciju sklonosti ka opadanju gustine aksonalnih terminala u zavisnosti od udaljenosti od "centra" aksonalnog vretena (sto je u saglasnosti sa neuroanatomskim nalazima). Default opcija je linearno opadanje (verovatnoca formiranja sinaptickog terminala opada linearno sa udaljenoscu od centra aksonalnog vretena), ali je moguce podesiti i eksponencijalno opadanje kao i eksponencijalni faktor. Ovaj parametar je moguce podesiti individualno za svaki tip neurona.
Code:
v0.78 - Released on July 29th 2012
----------------------------------
* Enabled per-base neuron type synaptic conductance
configuration (see ./NeuronLibrary/BaseNeuronTypes.xml)
* Added possibility to define per-base neuron type rules
("exceptions") for synapse conductance (weight) including
min/max conductance range, STDP plasticity enable/disable
and runtime randomization parameters. With this option,
it is possible to define different synapse parameters
for pre-synaptic base neuron neuron type depending on the
base type of the post synaptic neuron (for example, one
set of synaptic parameters when the target is a Pyramidal
base cell type and other set when the target is of Basket
base type)
* Added possibility to override synaptic conductance
configuration for wide-range of neurons in the project
configuration (for all excitatory cortical, excitatory
thalamic and inhibitory base neuron types). DemoSmall.xml
and DemoMedium.xml are using synaptic parameter override,
while other projects are only relying on per-base neuron
type synaptic conductance parameters.
* Added configuration data for individual cortical layer
thickness (relative, will be scaled to the the anatomic
cortical height at location, see ./BrainAnatomy.xml)
* Added option to bias the axonal connectivity preference
based on linear vs. exponential distance falloff factor.
Each neuron type can have its own value. Default option
is linear falloff (number of synaptic terminals
decreases linearly to 0 at the border of the axonal
arbor)
* Fixed bugs in neuron drawing where axonal depth location
was incorrectly calculated.
v0.79 - Released on August 6th 2012
-----------------------------------
* Added somatic diameter parameter for each neuron
(see Neuron Library). Default values are selected
from the neuroanatomical measurements
* Simulation creation now takes into account somatic
diameters when placing neuron somae (no overlap)
* Improved simulation creation speed (30% +) for
large simulations
* Fixed axonal tract search algorithm which in some
cases returned incorrect "best fit" resulting in
tracts being abnormally far from the GM entry
point of the axonal collateral
* More bugfixes in neuronal drawing (wrong axonal
positions in some cases)
Kreiranje velikih simulacija je prilicno ubrzano - primera radi, na mojoj masini:
Verzija 0.80 donosi preview novog GUI-ja (DigiCortexIDE) - koji je u vrlo ranoj fazi, ali su promene "ispod haube" mnogo vece. Novi GUI komunicira sa DigiCortex bibliotekom preko client-server API-ja za razliku od SpikeFun.exe demoa koji samo ucitava fiksiranu demo rutinu u DigiCortex_XXX biblioteci.
API je trenutno interni i vrlo nedovrsen, ali posto je "eat your own dog food" najbolji nacin za razvoj, u sledecih N meseci ce svakako napredovati. Sledeci korak je razdvajanje komputacionih modula sa idejom da komunikacioni moduli budu "loadable" klijenti koji mogu biti kako lokalni tako i distribuirani (CPU, GPU, klaster). Ovo ce zahtevati dosta posla ali su prvi koraci vec napravljeni u ovoj verziji ali se za sada jos ne vide (osim preview-a novog GUI-ja).
Evo kako izgleda novi GUI - mozete ga probati startujuci DigiCortexIDE_32bit.exe ili DigiCortexIDE_64bit.exe:
Dodatna novina je novi algoritam za kreiranje konektoma subkortikalnih struktura (za sada je jedina struktura talamus). Novi algoritam je daleko stroziji u klasifikaciji i ne ukljucuje traktove koji nisu zaista u vezi sa konkretnom strukturom.
Dodatna prednost novog algoritma je mogucnost klasifikacije talamickih nukleusa - algoritam koristi podatke prikupljene iz difuznog MRI snimka i nukleuse prepoznaje po globalnim projekcijama koje voksel pravi sa korteksom. Na zalost, algoritam jos pravi greske (tipa, misklasifikacija voksela kao pripadajuci lateralnom-genikulatnom nukleusu umesto pulvinarnom) ali ce to biti reseno u sledecim verzijama.
Na slici dole mozete videti kako algoritam radi - izabrani neuron je talamicki (relejni neuron), nalazi se u lateralnom genikulatnom nukleusu talamusa i projektuje jednu od aksonalnih grana (bifurkacija) na primarni (V1) vizuelni korteks (pericalcarine cortex):
Kao sto se moze primetiti, traktovi su daleko uniformniji - sto je posledica pravilnog klasifikovanja. Prosle verzije su pravile gresku i ukljucivale strane traktove kao talamicke (recimo, traktove koji pripadaju globus pallidus-u ili hipotalamickim nukleusima) sto je dovodilo do nepravilnih topografskih projekcija.
Ova promena je daleko veca od kozmeticke - ako ucitate DemoBiggest.xml, na primer, primeticete vrlo interesantnu aktivnost koja se moze opisati kao "hot-spotovi" aktivnih neurona koji se ili polako krecu ili su stacionarni i ostaju aktivni vise od nekoliko stotina milisekundi. Ovo je direktna posledica reciprocnih talamokortikalnih veza (izmedju neke zone u korteksu i talamickog nukleusa koji projektuje u tu zonu i obrnuto).
[ Ivan Dimkovic @ 27.08.2012. 22:13 ] @
Mali update: v0.80a vise nema ogranicenje za ucitavanje projekata (vazi za DigiCortex_IDE.exe)
Na zalost, i dalje postoji memory leak kada se ucita drugi projekat, ali je za to ponajvise zasluzan modul koji nisam ja pisao tako da cu morati da ga okrpim.
Takodje, presao sam na installer, zbog paranoidnog Google browsera koji fleguje .zip fajl sa exe fajlovima unutra kao opasan.
------------------------------------------------------------------------
v0.81 - Released on September 16th 2012
------------------------------------------------------------------------
* Added additional algorithm for connectome mapping, supporting high
precision topographic mapping of axonal tracts. It is activated as
a global setting (see "MappingPrecision" option in tractography
parameters inside demo project XML files)
* Thalamic neurons can now be created inside nuclei, instead of
simplified surface-only approach used in previous versions. Please
note that this option should only be used when number of thalamic
neurons is relatively high. It is enabled in demo simulations that
have 262144 neurons or more. See "FlattenSubcorticalRegions" option
inside the demo project XML files.
* Even more strict subcortical white matter tract identification
* Fixed a bug where white-matter axonal length was miscalculated
leading to significant decrease in reported size and corresponding
network effects due to lack of actual longer-range connections
* Fixed a bug where local-circuit connections of insular/cingulate
cortex "leaked" to thalamus in low-neuron-count simulations
(due to large bounding limits and disabled additional geo. checks)
Nova verzija donosi topografsko mapiranje konektoma, tako da je moguce kreirati aksonalne traktove koji projektuju na vrlo preciznu lokaciju (do nivoa baricentricnih koordinata trouglova koji cine 3D mesh odredjene strukture). Predhodne verzije su imale "rezoluciju" samo do nivoa individualnih trouglova, na osnovu cega im se dodeljivao "tag" gde pripadaju.
Trenutno nije preterano korisna kao opcija, ali ce postati zanimljiva kada budem ubacio podrsku za interfejs sa senzornim korteksom kao i za kreiranje kortikalnih kolona.
Verzija 0.82 donosi prvu podrsku za modeliranje mozdanog stabla. Prvi nukleus koji je podrzan je PPTN (Pedunculopontine Tegmental Nucleus).
PPTN je izuzetno vazan skup neurona koji salju jake projekcije ka talamusu i u stanju su da inhibisu retikularne neurone i u isto vreme da pobude relejne neurone. PPTN neuroni ovaj trik izvode tako sto njihovi aksoni formiraju sinapticke kontakte sa razlicitim receptorima u zavisnosti od vrste neurona u talamusu:
- Sa relejnim celijama: M1 muskarinicni* i nikotinski** receptori
- Sa retikularnim celijama: M2 muskarinicni*
*, ** - v0.82 jos nema podrsku za ove receptore, tako da su PPTN neuroni modelirani preko NMDA/AMPA i GABA receptora.
Konacan rezultat je mogucnost PPTN neurona da direktno modulisu nivo pobudjenosti raznih delova talamusa i, samim tim, korteksa. Kao sto se i da pretpostaviti, PPTN neuroni predstavljaju jedan od kljucnih habova u tzv. uzlaznom retikularnom aktivacionom sistemu (ARAS). Najveca aktivnost PPTN neurona je za vreme budnosti i REM sna, dok je najmanja aktivnost PPTN neurona u NREM snu.
Za vise detalja o PPTN nukleusu kao i drugim delovima ARAS sistema preporucujem ovaj rad:
SpikeFun 0.82 "Brainstem Modulation" slajder sada direktno odredjuje nivo pobudjenosti PPTN neurona - povecanjem se direktno menja pobudjenost talamusa i moze se videti prelazak u plavu boju (gasenje retikularnih neurona).
Evo kako izgleda aktivnost jednog od PPTN neurona:
[ Ivan Dimkovic @ 01.10.2012. 13:21 ] @
A evo i kako to funkcionise u praksi:
Aktivacija PPTN neurona pocinje u drugoj sekundi - tokom njihove bursting aktivnosti dolazi do inaktivacije inhibitornih RTN neurona u talamusu i aktivacije relejnih celija, i ta aktivnost se preliva u korteks...
[ Ivan Dimkovic @ 03.10.2012. 17:49 ] @
SpikeFun je napunio 1 godinu - prvi public-release (v0.24) se desio krajem septembra 2011. Aktivni razvoj (u slobodno vreme) je poceo oko pola godine pre prvog release-a - i u tom momentu je moje znanje o neuroanatomiji i neurofiziologiji bilo negde na nivou discovery-channela.
Danas, posle 2 godine od kada sam se poceo interesovati za ovu oblast bar mogu da kazem da razumem koliko malo znam i koliko je nervni sistem fascinantno komplikovan i prelepo dizajniran od strane prirode za 4 milijarde godina (a mozda i mnogo duze)... ako nista drugo, bar neke stvari koje su mi pre 2 godine zvucale kao ruzna rec na kineskom umem da grubo modeliram racunski :-)
Na ovom linku se moze videti pregled sta je uradjeno za ovih godinu dana, kao i neke od ideja sta ce biti dodato u buducnosti:
Za ovih godinu dana je dodato puno stvari - od multi-kompartmentalnih neurona, XML konfiguracije, preko neuroanatomije korteksa, talamusa i delova mozdanog stabla pa sve do koriscenja konektoma i unapredjenja u performansama i renderingu...
Sa druge strane, sto vise stvari se dodaje - broj ideja za unapredjenja raste vrtoglavo... Sto celu stvar cini jos zanimljivijom :)
[ Shadowed @ 03.10.2012. 18:29 ] @
Shrederu, gde je moje teeelooo!?!
[ mr. ako @ 03.10.2012. 20:02 ] @
U jbt, nije valjda vec godinu dana proslo u pm...?! Secam se kad sam skinuo prvu verziju, kao da je bilo juce. :P
Cestitke Dimke zaista!
S obzirom da planiras da jos usloznis simulaciju trebace ti dosta jaca masina od trenutne (a i to je vec topnotch masina). Da li postoji neka racunarska arhitektura koja bi mogla bolje simulirati neurone od fon nojmanove ?
[ Ivan Dimkovic @ 03.10.2012. 21:35 ] @
@mr.ako, +1 - thx! :)
Btw, izbacio sam "rodjendansku verziju" - v0.83, koja donosi 20-30% ubrzanja u simulaciji kao i smanjenu potrosnju memorije. U pitanju je relativno prosta matematicka optimizacija koja ne menja rezultate - ali ne zahteva da se vrednosti sinaptickih receptora cuvaju za svaki receptor posebno, vec je dovoljno da se cuva suma po kompartmentu.
* Big optimizations in the computation engine, yielding ~20-30% speed
improvements (on AVX-capable CPUs) and runtime RAM usage reduction
* Fixed a bug where cerebellar tracts were selected for guiding PPTN
neuron axons.
* More stringent testing of suitable reticulo-thalamic white matter
tracts, eliminating incorrectly guided PPTN axons
@Igor Gajic,
Hvala na cestitkama! Najveci problem bioloskih simulacija je masivni paralelizam gde imas ogromnu kolicinu podataka koji se razmenjuju izmedju nodova. To je upravo suprotno Von Neumann-ovoj arhitekturi, gde imas uzak bas (u odnosu na ukupnu kolicinu memorije) izmedju memorije i procesora.
Na zalost, u ovom momentu ne postoji idealna arhitektura za neuronske simulacije - masivne paralelne arhitekture su definitivno pogodnije, pa cak i custom-made FPGA kola - ali i tu imas problem enormne kolicine podataka koji se razmene izmedju udaljenih nodova. Na srecu, arhitektura nervnog sistema zivih bica je imala iste probleme, pa su veze izmedju udaljenih nodova daleko redje nego lokalne veze (tzv. "small world" topologija) - ali i to "redje" je i dalje vrlo visoko: primera radi, corpus callosum svezanj traktova sadrzi ~250 miliona kontralateralnih aksonalnih projekcija.
Mermistori su jedna od tehnologija koja obecava - ukoliko se teorija pokaze mogucom, uz pomoc mermistora ce biti moguce drasticno pojednostaviti elektronski ekvivalent neurona, sto bi omogucilo daleko manji gubitak energije za simulaciju neurona i daleko vecu gustinu neurona na silikonu.
------------------------------------------------------------------------
v0.84 - Released on October 22nd 2012
------------------------------------------------------------------------
* Different STDP parameters can now be specified for individual base
neuron type allowing expression of different long-term plasticity
behaviors for each base neuron type
* Added option to bias the axonal preference for a specific part of
post-synaptic cell (soma, proximal dendrites and distal dendrites)
* Added option to configure the maximum number of synapses allowed
per single neuronal compartment (default value: 40)
* New memory allocation strategy used during network build-up. Unlike
the old approach, new memory allocator starts with reserved virtual
address space and then commits the memory as needed. New approach
avoids costly reallocations and also does not "grab" large chunk of
memory at the beginning
* Eliminated firing buffer memory reallocations that seldom occured
during larger simulations
* Fixed a bug in computation of the dendritic currents in neurons
with multiple compartments
------------------------------------------------------------------------
v0.85 - Released on October 30th 2012
------------------------------------------------------------------------
* Added RPC Server (using ZeroMQ as the transport layer) which will be
used in the future for remote simulation control/management and
distributed computing. Currently with 0.85 only 4 command line
tools are provided (enable_neuron, disable_neuron, axonal_delays)
with the aim to extend this list significantly in the future.
* Introduction of the compute plug-ins. Compute plug-ins will be used
in the future to add more compute hardware support (e.g. OpenCL,
CUDA and distributed computing). Currently with 0.85 only one plugin
is provided, for CPU-based compute (port of the old built-in CPU
compute core)
* Simulation runtime thread-management code is now 100% lock-free,
which gives performance gains up to 1% on large-threaded systems
* Optimized dendritic-current calculation (faster dendritic tree walk)
Sa v0.85 sam poceo implementaciju RPC client/server komunikacije koja ce omoguciti potpunu kontrolu SpikeFun-a preko mreze kao i distribuirani computing. Za sada postoje samo 3 utility cmdline tool-a (enable_neuron.exe, disable_neuron.exe i delay_stats.exe) koji mogu da kontrolisu trenutnu simulaciju, dok ce u buducnosti biti dodato jos mnogo drugih alatki.
Za transport koristim ZeroMQ paket, koji nudi vrlo efikasnu TCP-baziranu messaging implementaciju bez bloat-a. Planiram da izbacim RPC API kao deo SDK-a u buducnosti.
Sledeca novost je plug-in model za computing module. Jos uvek je u work-in-progress stadijumu ali je stari compute kod vec prebacen u novu arhitekturu i sledeci korak je CUDA plug-in.
Takodje, v0.85 ima potpuno lock-free kod za menadzment worker niti. Eliminacija lock-ova je bio posao sa puno glavobolje, ali je sada konacno gotov. Ubrzanja nisu spektakularna na hyperthreading masini sa 32 logicka procesora, oko 1% ali ce verovatno biti veca na masinama sa vise procesora + nije lose znati da niti nece biti blokirane dok procesiraju zajednicke podatke.
[ Ivan Dimkovic @ 30.10.2012. 19:44 ] @
Inace, delay_stats alatka daje distribuciju duzine aksonalnih konekcija (u vremenskom domenu - tj. vremenu koje je potrebno za propagaciju akcionog potencijala).
Startujte SpikeFun sa nekom simulacijom, i u command-prompt prozoru otkucajte:
Code:
delay_stats -c
I dobicete CSV listu koja se moze importovati u, recimo, Excel.
Evo kako izgleda distribucija duzina konekcija u simulaciji sa 4 miliona neurona i 870 miliona sinapsi:
Kao sto se vidi, distribucija konekcija je takva da je najveci broj konekcija vrlo kratak (preko 90% konekcija su krace od 5 ms) sto odgovara "small-world" mreznoj topologiji koja je karakteristika nervnih sistema zivih bica. Small-world topologija je optimalna sto se potrosnje energije tice i predstavlja dobar kompromis izmedju mogucnosti komunikacije na daljinu i stednje energije za prenos podataka.
[ Ivan Dimkovic @ 04.11.2012. 12:57 ] @
v0.86 is out - sto se vidljivih promena tice, manje-vise je bugfix-release:
------------------------------------------------------------------------
v0.86 - Released on November 4th 2012
------------------------------------------------------------------------
* Optimized in-memory neuron grouping which improves cache locality
* Fixed a bug which triggered rare random crashes during simulation
build-up on NUMA systems
[ Ivan Dimkovic @ 04.11.2012. 18:37 ] @
Dodao sam jos jednu malu stvar:
Code:
* Optimized thread-barrier code with hybrid spinning / wait strategy.
This hybrid approach improves performance on systems with the large
number of CPU cores and simulations with low number of synapses,
where Windows thread scheduling quantum is too coarse and ends in
worker threads spending too much time suspended (waiting to be
'unlocked'). Hybrid spinning is set in a way that does not tax the
CPU too much but at the same time manages to catch many occasions
where the thread would end up sleeping for 10-15 ms otherwise
Problem sa malim simulacijama (tipa manje od milion neurona) na brzim masinama sa puno procesora (recimo, 32 logicka) je da granularnost (tj. quantum) Windows scheduler-a (koja je obicno 10 ms ili 15 ms) suvise dugo traje u odnosu na workload individualnih thread-ova.
U tom slucaju niti provode dosta vremena cekajuci da budu probudjene - cak i ako su ostale niti zavrsile posao jednu milisekundu (ili krace), zbog relativno dugog vremena Windows scheduler kvanta nit ce provesti do 14 milisekundi u stanju cekanja.
Situacija se najbolje vidi na mom test sistemu: Xeon E5, 16 jezgara sa 32 logicka CPU-a, mala simulacija od 32768 neurona ne moze da zauzme vise od ~60% procesora :( Ako se analizira sta se desava, vidi se da work niti provode abnormalno puno vremena cekajuci da budu odblokirane od strane thread-barijere. Da bi se postigao CPU load od 97-100% potrebno je terati 2 miliona neurona.
Dakle, situacija nije dobra.
Windows API ima vrlo gadan tandem poziva timeBeginPeriod()/timeEndPeriod() sa kojim bukvalno bilo koja aplikacija moze da setuje globalni (OS-wide) kvantum i da spusti vreme do jedne milisekunde. Problem sa tim pristupom je da se drasticno povecava overhead u servisiranju interapta - mnoge aplikacije zloupotrebljavaju timeBeginPeriod()/timeEndPeriod() posto su pisane jako lose, pa developeri pribegavaju ovom silovanju sistemskog scheduler-a koji takodje povlaci i losije trajanje baterije na laptopu. Obicno aplikacije koje zahtevaju preciznost nekih tajmera to rade, posto je timeBeginPeriod() najlaksi nacin da se postigne cilj - iako je pogresan, i gotovo sigurno ukazuje da je aplikacija lose projektovana (osim u retkim slucajevima gde je zaista potrebno imati tako nisko vreme)
SpikeFun v0.86a ima nedokumentovanu komandu -setquantum <n> gde je n broj milisekundi - medjutim ova komanda je samo za debugging i iskreno ne preporucujem koriscenje iste. Posto timeBeginPeriod/timeEndPeriod() predstavlja cist 100% bad coding, ovaj problem sam donekle resio na drugi nacin:
Thread barijera sada ima odredjen broj ciklusa koje provodi u busy-wait loop-u gde ce egzekucija biti prebacena na drugu HT nit. Tek kada broj spinova predje odredjen threshold nit ce otici na spavanje gde je jedini nacin da se nastavi budjenje od strane OS-a (event).
Threshold je izabran tako da ne bude suvise veliki (sto bi rezultovalo bacanjem CPU ciklusa na cekanje) ali i dovoljno veliki da "uhvati" dovoljan broj situacija gde bi nit otisla na spavanje (i samim tim bila nedostupna u sledecih 1-15 ms).
Situacija se definitivno popravila - sada simulacija sa 32768 neurona uzima 75% procesorskog vremena, i biva brza i do 10% ali ocigledno jos ima mesta za unapredjenje tako da cu jos eksperimentisati sa ovim.
Najbolje resenje za Windows 7+ bi bilo koriscenje User Mode Scheduling ekstenzija. Windows 7 API ima mogucnost da aplikacija totalno preuzme procesor(e) i da manuelno scheduluje niti na njima. U toj situaciji ne bi bilo nikakvog cekanja posto scheduler moze odmah da zna da su sve niti zavrsile svoj posao...
[ Ivan Dimkovic @ 04.11.2012. 18:57 ] @
Inace, koga zanima, evo svih varijanti koje sam probao za implementaciju thread barijere:
1. Windows Event-only (niti se bude sa SetEvent(), spavaju sa WaitForSingleObject) --> ~0.710x real-time, ~60-65% CPU
2. Windows Condition Varijable + Critical Section (Vista+ Kernel) --> ~0.550-0.6x real-time, ~95% CPU
3. Ideja sa http://www.spiral.net/software/barrier.html --> ~0.550x real-time, ~100% CPU
4. Hibridni "Sleeplock" (Busy-wait + yield na drugu HT nit) + Windows Event --> 0.75-0.79x real-time, ~75% CPU
Kao sto se vidi, metod #4 se pokazao najbolje, ali je CPU load i dalje relativno nizak, sto znaci da postoji prostor za optimizaciju.
Metode #2 i #3 su uspesne u zakucavanju procesora na blizu 100% ali, na zalost, usporavaju izvrsavanje simulacije. Nisam se previse udubljivao zasto se to desava, doduse.
Iskreno, najvece razocarenje su mi Windows Vista API-ji za tzv. "lightweight" sinhronizaciju. Condition Varijable u NT6 kernelu su user-mode objekti i Microsoft ih je reklamirao kao optimalno resenje. Na zalost, u mom workload-u su se pokazale kao lose resenje.
[ Tyler Durden @ 05.11.2012. 08:11 ] @
Kad bi morao da portuješ SpikeFun na Linux, šta bi bio najveći problem u tom procesu?
I koliko bi slabije performanse bile, i zašto? Znam je ovo nezahvalno procijeniti, ali baš me zanima.
[ Ivan Dimkovic @ 05.11.2012. 10:51 ] @
Najveci problem? Pa mislim da nema nekih problema, samo treba da se sedne i odradi ;-)
- GUI: Ovo je jedino Windows-specific, znaci treba raspisati novi GUI, recimo u QT-u
- Jako malo koda je Windows-specific, jedino neke osnovne primitive za sinhronizaciju / threading, ali to se lako da prebaciti na Linux/POSIX
Planiram da to uradim cim se odradi CUDA podrska, posto za CUDA podrsku i ovako i onako moram da skockam svu arhitekturu, pa ce onda biti i laksi posao da se to prebaci na Linux.
Citat:
I koliko bi slabije performanse bile, i zašto?
Sumnjam da bi performanse bile slabije - u najgorem slucaju bi trebalo da budu uporedive sa Windows-om.
Mozda je moguce izvuci i nesto bolje performanse na Linuxu zbog vecih mogucnosti tweak-ovanja OS scheduler-a. Mislim da je Linux, na kraju krajeva, bolji izbor za ovakav tip aplikacije od Windows-a posto imas vise mogucnosti tweakova za HPC upotrebu.
[ Tyler Durden @ 05.11.2012. 12:07 ] @
Možda sam malo preskočio priču sa početka pa je ovo odgovoreno, ali koliko grafička utiče na performanse?
Jer ipak se grafički drajveri na Windowsu bolje održavaju i više su optimizovani. Bar mi se čini tako što se tiče optimizacije.
[ Ivan Dimkovic @ 05.11.2012. 12:34 ] @
Za sada, simulacija se radi kompletno na CPU-u - GPU samo radi vizualizaciju, tako da jedino to moze trenutno da se ponasa drugacije.
E sad, sam OpenGL kod za vizualizaciju nije kompleksan - par shader-a i dosta geometrije, to su OpenGL 2.0 feature-s tako da sumnjam da posteni Linux drajveri imaju problema sa tim, no bilo bi interesantno to testirati i videti da li je zaista tako.
Kada budem ubacio CUDA podrsku onda ce GPU raditi i deo simulacije - ali koliko znam, CUDA podrska je odlicna na Linuxu tako da to ne bi smelo biti problem.
------------------------------------------------------------------------
v0.87 - Released on November 17th 2012
------------------------------------------------------------------------
* NUMA-specific performance optimizations
* Fixed a bug on Win7+ x64 systems where processor affinity was not
set properly for the worker threads
Vidljivih promena je malo - posto sam trenutno busy sa razvojem plug-in arhitekture.
------------------------------------------------------------------------
v0.87a - Released on November 17th 2012
------------------------------------------------------------------------
* Disabled wireframe rendering of the brain mesh due to significant
drop in rendering performance on NVidia Kepler GPUs with 30x.xx
drivers when GL_LINE is used as glPolygonMode(). Rendering switched
to GL_FILL with background thread doing depth sorting of brain polys
every 10th frame (when camera angle is changing) to save CPU time.
* Reduction in memory reservation for the spiking buffers due to
better estimation of worst-case spiking scenarios. Total reserved
memory (not necessarily used, just reserved for the worst case)
has been reduced by approx. 50%
* Optimized memory layout for synaptic storage with 32 bits of data
per synapse removed.
* 32-bit build of SpikeFun is now linked as "large address aware",
allowing slightly larger simulations to run as it is able to use up
to 3 GB (on 32-bit Windows) or 4 GB (on 64-bit Windows) of address
space where OS is configured to allow large-address space for 32-bit
applications. However, 64-bit SpikeFun is recommended to be used
when possible (when running on 64-bit Windows)
Manje-vise bugfix release, sa malo optimizacija.
Zbog NVidia Kepler grafickih kartica sam morao da iskljucim wireframe render kortikalne povrsine, posto su performanse drasticno losije nego sa svim ostalim modelima. Problem je u drajverima, koliko mogu da primetim, posto npr. na Macbook Retina Kepler-u (650M) problem ne postoji sa originalnim drajverima, ali cim se predje na novije 30x.xx FPS pada na ~4-5. Ista stvar se desava i na desktopu sa GTX 680 karticom, samo sto u tom slucaju nisam proveravao da li problem nestaje sa starim drajverima.
U svakom slucaju, novi render izgleda ovako:
Dodatna komplikacija sa renderingom transparentnih punih/osencenih trouglova kao u ovom slucaju je sto pri iscrtavanju moraju biti sortirani po inverznoj udaljenosti od kamere (tj. dalji se crtaju pre blizih, posto je depth-cull iskljucen). Zbog toga je neophodno sortirati ~800 hiljada trouglova svaki put kada se promeni pozicija kamere. Kako bi ovo sto manje smanjivalo rendering performanse, depth-sort se radi max. jednom u 10 frejmova i u posebnom thread-u (asinhrono). Mislim da je to optimalni kompromis izmedju kvaliteta rendera i CPU zahteva.
------------------------------------------------------------------------
v0.88 - Released on November 25h 2012
------------------------------------------------------------------------
* Improved thalamic nuclei parcellation, including division of the
pulvinar thalamic nuclei into anterior, medial and lateral. Rules
guiding synapse formation of thalamic relay cells have been extended
so that cross-nuclei connections between core TRN cells are not
allowed.
* Reduced GPU memory load and faster rendering of the cortical surface
* Dendritic current computation optimizations resulting in speed gains
[ Ivan Dimkovic @ 26.11.2012. 22:36 ] @
Posto sam prodao Z i moram da ga posaljem sutra, uradio sam up-to-date testiranje performansi:
Kao sto se vidi, SVZ je samo nesto malo sporiji sto se CPU-a tice, nesto malo brzi sto se memorijskog I/O-a tice.
Ono sto se ne vidi je GPU, gde je MBPR dosta bolji, naravno.
Interesantan kuriozitet je strategija hladjenja - SVZ gotovo odmah krece u full-speed za hladjenje, i temperaturu drzi konzistentno nekih 15-17 stepeni ispod kriticne (TJunction).
Macbook Retina ima sasvim drugaciju strategiju - prvih 10-20 sekundi ventilator uopste ne radi, i CPU jako brzo (za oko 15-20 sec) ulazi u throttling mod gde svakih 2-3 sekunde frekvencija sa 3.3 GHz pada na 1.7 GHz. Tek posle ~1 minut MBPR ventilatori krecu u full-speed mod i onda throttling prestaje ako GPU nije previse aktivan.
Ako je GPU previse aktivan, apsolutno je nemoguce izbeci throttling sa CPU-om na frekvencijama iznad 2.7-2.8 GHz. Po defaultu je meni CPU u Windowsu setovan da ne ulazi u Turbo (!?!) mozda je ovo upravo i razlog - posto Apple drzi NV GPU stalno ukljucen.
Ako sa ThrottleStop-om forsirate CPU u Turbo rezim, posle 20-tak sekundi ce CPU flegovati PROCHOT situaciju, i halt-ovati klok na delic sekunde svake sekunde, sto je jos gori efekat nego Apple strategija.
--
Ocigledno je Apple-ov prioritet bila tisina, posto laptop ima termalne mogucnosti da se izbori bar sa Intel-ovim CPU-om na turbo frekvenciji -ali samo ako je ventilator na 100% brzini, sto se ne desava skoro citav minut. Moram da vidim da li postoji neki nacin da se ventilator aktivira brze.
* Extension of the implementation of the Tsodyks-Markram model of
synaptic release allowing differential signalling via the same axon
of a given pre-synaptic neuron. It is now possible to define
different synapse types that obey Thodyks-Markram kinetics
(depressing, facilitating, pseudo-linear; see SynapseLibrary.xml)
and configure different synaptic expression of a pre-synaptic neuron
type depending on the post-synaptic target type.
For example, Pyramidal neurons form facilitating synapses with LTS
interneurons, and depressing synapses with other neuron types. For
each synapse type (and there are no limits with the number of
defined synapses) it is possible to tweak U, F and D parameters
* Pyramidal neurons now form facilitating synapses with LTS cells
* Pyramidal neurons of L6 now form facilitating synapses with thalamic
neurons (all types)
* Configurable ratios of fast (AMPA/GABAa) and slow (NMDA/GABAb)
receptors for each synapse types (see SynapseLibrary.xml). This way
it is possible to create synapses that are pure AMPA/GABAa and/or
synapses with non-equal ratio of the AMPA/GABAa to NMDA/GABAb
* Pyramidal neurons of Cortical Layer V are now of IB (Intrinsically-
Bursting) type. See BaseNeuronTypes.xml, p5_l23.xml and p5_l56.xml
* New improved dendritic tree builder with customizable tree branching
factor for each cell type (except pyramidal neurons, where factors
are still hardcoded, making them configurable is work in progress)
* Maximum allowed number of synapses per neuron increased to 10000
(previous limit was 1024). Please note that the maximum number of
synapses per simulation is still 2^32-4 (4294967292). Simulations
where total possible number of synapses is larger than 2^32-4 will
fail during build-up phase.
* Misc. small bugfixes
^ Na slici sa leve strane se vide 2 piramidalna neurona i jedan inhibitorni interneuron.
v0.89 donosi nekoliko vecih dodataka u simulaciji:
- Diferencijalna signalizacija uz pomoc razlicitih tipova sinapsi u zavisnosti od ciljanog neurona
Ovo je u stvari prosirenje dosadasnje implementacije Tsodyks-Markram modela sinapsi koje sada dozvoljava da se za svaki tip neurona (pre sinapticki) definisu razliciti tipovi sinapsi koje taj neuron moze formirati sa razlicitim tipovima post-sinaptickih neurona.
Ovaj fenomen je vidjen in vivo u korteksu, gde npr. piramidalni neuroni formiraju tzv. "depresivne" sinapse (jacina EPSP-ova opada sa vremenom pri ponavljajucim pobudjujucim postsinapcikim potencijalima) sa drugim piramidalnim neuronima, ali sa odredjenim tipovima kortikalnih interneurona (inhibitornih) sinapse imaju potpuno drugacije ponasanje (tj. "facilitating" - gde se amplituda EPSP-ova povecava u slucaju ponavljajuceg stimulusa)
Evo kako to izgleda u originalnim merenjima (Markram et al [1])
Sa leve strane su rekonstrukcije 2 piramidalna neurona i jednog inhibitornog interneurona. Sa desne strane (gore i dole) se vidi razlicito ponasanje sinapsi koje levi piramidalni neuron formira sa interneuronom (gore) i desnim piramidalnim neuronom (dole). Sinapse formirane sa interneuronom manifestuju tzv. "facilitating" ponasanje gde se EPSP amplituda povecava u slucaju ponavljajuceg stimulusa, dok sinapse formirane na drugom piramidalnom neuronu imaju potpuno obrnuti efekat (tzv. "depresiju")
- Konfigurabilni odnos izmedju brzih i sporih receptora (AMPA:NMDA i GABAa:GABAb)
Od sada je, takodje, moguce definisati odnos izmedju razlicitih vrsta receptora formiranih na post-sinaptickom neuronu u zavisnosti od tipa sinapse. Dosadasnje verzije SpikeFun-a su imale hardkodovan jednak odnos izmedju AMPA i NMDA (GABAa i GABAb) receptora. Sa ovim je moguce, na primer, definisati senzorne sinapse.
Na primer, sinapse koje formiraju retinalne ganglionske celije sa talamickim relejnim neuronima ukljucuju samo AMPA receptore na post-sinaptickoj strani. Takodje, ove sinapse su "facilitating" tipa, sto se takodje moze postici podesavanjem U, F i D parametara za sinapsu...
[1] - "Differential signaling via the same axon of neocortical pyramidal neurons"
Proc. Natl. Acad. Sci. USA Vol. 95, pp. 5323–5328, April 1998 Neurobiology
Henry Markram, Yun Wang, Misha Tsodyks
[ Ivan Dimkovic @ 12.12.2012. 21:10 ] @
Evo jos malo skaliranja:
16.7 miliona neurona, 2.1 milijarde sinapsi
Pretpostavljam da je ovo najveca simulacija kortikalnih neurona izvedena u kucnoj radinosti :-)
[ Igor Gajic @ 12.12.2012. 21:18 ] @
Ovakva simulacija je za PhD nivo. Da li si imao takvih planova ?
[ Ivan Dimkovic @ 12.12.2012. 21:28 ] @
Hmm, hvala za pohvalu ali mislim da je ovo dosta ispod PhD nivoa.
Razlog je prost, u pitanju je samo implementacija postojecih modela, efikasna/optimizovana, ali i dalje samo implementacija. Cak i "nize" doktorske titule (Ph.D.) zahtevaju mnogo vise tj. konkretno istrazivanje sa novinama, a o "visim" tipa Sc.D. i da ne pricamo.
[ staticInt @ 12.12.2012. 23:46 ] @
Istina nije za PhD ali svakako ima potencijal da se razvija u vise smerova i da poprimi ozbiljnije oblike.
Ivane bilo bi dobro da uradis neki joint research sa nekom ekipom koja radi u toj oblasti kapiram da bi tako software doprineo necem korisnom i za druge osim za tebe :) posto shvatam da ti je ovo projekat gde si zeleo da i sam izucis nesto a i da se zabavis, software svakako ima potencijal da preraste u nesto ozbiljnije.
[ Ivan Dimkovic @ 14.12.2012. 19:34 ] @
Videcemo. Mozda ce biti neke kooperacije sa odredjenim CPU/GPU vendorima i njihovim exascale timovima - ali je previse rano za bilo kakvu pricu na tu temu.
Sto se akademije tice, mislim da u ovom momentu SpikeFun jos nije na nivou koji moze biti koristan - ali do verzije 1.0 planiram da dodam prilicno puno stvari koje ce ici u smeru generalnog large-scale simulatora koji moze da se siri i modelira najnovije fenomenoloske modele neurona i plasticnosti... onda ce mozda i biti smisla za kooperaciju sa akademijom.
[ Ivan Dimkovic @ 28.12.2012. 00:43 ] @
v0.90 is out:
Code:
------------------------------------------------------------------------
v0.90 - Released on December 27th 2012
------------------------------------------------------------------------
* Increased complexity level of the pyramidal neurones, including
basal dendrites and dendritic tree branching (apical tuft)
* Improved axonal and dendritic arbor spreading boundary checking by
employing optimized (Monte Carlo method) intersection test between
the spreading region cylinders. Previous versions of DigiCortex did
only limited checks by approximating cylinder regions as capsules
* Optimized dendritic current calculation
* Improved matching of desired connectivity statistics (requires pool
of pre-synaptic neurons large enough to accomodate the requirements,
which is typically only possible when neuron volume density is high
enough)
* Improved drawing of individual neuron axonal terminals and dendrites
when neuron is selected
Verzija v0.90 donosi kompleksnije morfologije piramidalnih neurona. Do sada su piramidalni neuroni modelirani kao "ball and stick" aproksimacije sa somatskim kompartmentom i nizom vertikalnih (apikalnih) kompartmenta - bez grananja. Ova aproksimacija je propustala neke od bitnih karakteristika piramidalnih neurona kao sto su grananja u "tuft" regionu (tj. "cuperku" koji nastaje u distalnom regionu).
Novi model podrzava grananja u dendritskom stablu, bazalne dendrite i bifurkaciju u apikalnom regionu ("tuft"):
Konfiguracija za svaki neuron omogucava zadavanje laminarnog pruzanja dendritskog i aksonalnog stabla kao i verovatnocu grananja (ovo ce u buducnosti biti zamenjeno daleko boljim modelom, ali o tom po tom).
Sa novim modelom piramidalnih neurona je moguce modelirati zanimljive fenomene koji postoje u piramidalnim neuronima - recimo zasebna racunanja u razlicitim granama dendritskog stabla koja se u prirodnim kolima koristi za detekciju koincidencije npr.
Kreiranje Morfologija
Kao sto se vidi iz slike gore, dendritsko i aksonalno stablo imaju laminarne limite koji se mogu aproksimirati cilindrima (i sferom za bazalne dendrite). Testiranje da li se 2 neurona tj. njihova aksonalna i dendritksa stabla uopste preklapaju zahteva testiranje preseka izmedju 2 cilindra (ili cilindra i sfere, za peri-somatski slucaj).
Na zalost, numericko resenje za testiranje preseka 2 cilindra je kompleksno i dosadasnje verzije SpikeFun-a su pribegavale klasicnoj optimizaciji iz 3D aplikacija poput gaming-a i ray-tracinga - cilindri su tretirani kao "kapsule" (za neupucene, kapsula je cilindar koji ima polu-sfere kao "poklopce"). Testiranje preseka 2 kapsule je trivijalno - potrebno je samo izracunati udaljenost 2 duzi koja predstavljaju ose cilindara - ako je udaljenost manja od zbira radijusa 2 cilindra koja se testiraju, kapsule se preklapaju.
Medjutim, aproksimacije cilindara kapsulama uvode i problem laznih pozitva tj. situacija kada se kapsule preklapaju ali pravi cilindri ne (npr. ako je presek samo izmedju polusfera koje cine "zatvarace" kapsula). U slucaju neurona ovo znaci i mogucnost da se 2 neurona, koja inace ne bi mogla povezati, spoje.
SpikeFun 0.90 radi testiranje preseka "pravih" cilindara ako test kapsula daje pozitivan rezultat. Medjutim, umesto numerickog resenja se koristi Monte Karlo metoda radi sto boljih performansi. Metoda se sastoji u kreiranju slucajno rasporedjenih tacaka unutar zapremine jednog od 2 cilindra i testiranja da li se tacke nalaze unutar drugog cilindra. Test je moguce implementirati jako efikasno uz pomoc par optimizacija (recimo nije potrebno generisati slucajne tacke duz celog cilindra vec samo unutar osnovice - a onda se samo "kloniraju" duz ose, takodje tacke je moguce transformisati tako da drugi cilindar bude uravnat sa osama sto testiranje cini trivijalnim), tako da je uticaj na brzinu kreiranja simulacije minimalan, a preciznost mapiranja sinaptickih veza je daleko veca.
Novi Rekord
Video dole predstavlja najvecu simulaciju do sad - sa 3.5 milijardi sinapsi i 16 miliona neurona! Ukupna kolicina memorije za celu simulaciju je 350 GB. Zapravo, simulacija je samo 0.5 milijardi sinapsi od trenutnog limita DigiCortex engine-a od 4 milijardi sinapsi. Kreiranje simulacije je trajalo 2 sata na 16-core masini.
Na videu se moze videti formiranje klastera neuralne aktivnosti koji su na EEG-u (pri kraju videa) jasno desinhronizovani.
Evo kako to izgleda u resource monitoru :-)
[ cyBerManIA @ 28.12.2012. 03:17 ] @
Ivane, koliko vidim PC ti je bas slab a i imas brate mili premalo RAMa. Zamisli kad jedna mala aplikacija ne moze da izvrti u realtimeu prostu animaciju, koliko li ce tek Winamp da secka
^ opasna sala, da ne pomisli neko stvarno
Mind blowing, nema sta. Steta sto ja i velika vecina forumasa (pretpostavljam) ne mozemo da ispratimo toliko pricu s' razumevanjem, ali se trudimo i usput divimo benchmarku
[ Ivan Dimkovic @ 28.12.2012. 11:26 ] @
Thx :-) Samo, bice potrebno malo vremena da simulacija iz videa trci u realnom vremenu.
Za pocetak, memorija koja moze da iscita i upise oko 20-tak TB/s :-)
[ Ivan Dimkovic @ 28.12.2012. 17:17 ] @
Inace, jedan od "todo" kandidata za neku od sledecih verzija SpikeFun-a je vrlo zanimljiv algoritam za kreiranje realisticnih morfologija neurona. Hermann Cuntz je autor doticnog algoritma koji je takodje prakticno dostupan u TREES Toolbox paketu, koji je javno dostupan i implementiran u MATLAB-u.
U pitanju je brilijantno jednostavan i podjednako mocan algoritam koji se zasniva na 2 principa (ciji je originalni autor Ramon Cajal):
#1 - Princip konzervacije citoplazme (optimizacija dostupnih resursa)
#2 - Princip konzervacije vremena provodljivosti (optimizacija prirodne funkcije)
Iterativni algoritam koji se trudi da odrzi ova 2 principa u prisustvu slucajno distribuiranih tacaka "nosaca" je u stanju da prilicno verno replicira morfologije neurona - od insekata pa sve do sisara. Dodavanje dodatnih uslova kao sto su granice prostiranja unutar ciljanog substrata je u stanju da proizvede spektakularno realne rezultate:
Iterativnim "gajenjem" mnostva neurona koji se "takmice" za nove "nosioce" se mogu dobiti kola koja su identicna sa prirodnim:
Levo je sinteticki generisano kolo CA3 hipokampalnih neurona, desno je sinteticki generisano kolo bipolarnih celija i fotoreceptora u retini. Kao sto se vidi, rezultati su fantasticno realni - i pokazuju da priroda stvara rezultate pridrzavanjem jednostavnih principa. Jos bolje, fantasticna realnost se ne zaustavlja samo na izgledu neurona - sinteticki generisani neuroni imaju takodje elektricna svojstva koja su neprepoznatljiva ako se uporede sa "pravim" neuronima:
^ Slika gore tj. grafici pod "L" pokazuju tzv. elektrotonicke "potpise" nekoliko sinteticki generisanih neurona uz pomoc TREES toolbox-a (sa razlicitim faktorima balansiranja bf - faktor balansiranja je parametar koji se koristi prilikom odabira tacaka nosioca) i jednog "pravog" neurona (grafik desno) - kao sto se vidi, faktor balansiranja u okolini vrednosti bf=~0.7 generise sinteticke neurone koji su identicni realnim. Grafik M pokazuje odnos faktora balansiranja i prosecne duzine kompartmenta.
--
Takodje, nova saznanja koja su rezultat istrazivanja unutar Blue Brain Projekta* [1], pokazuju da funkcionalna povezanost izmedju neurona u najvecoj meri sledi iz njihovih individualnih morfologija - eksperiment pokazuje da jednostavno slucajno pozicioniranje neurona unutar kortikalne kolone vrlo dobro predvidja pozicije individualnih sinapsi (tj. da je morfologija najveci kontributor - a dodatni hemijski mehanizmi odbijanja i privlacenja predstavljaju samo mali kontributor konacnoj povezanosti). To znaci da priroda nema neki "magicni stapic" koji individualnom neuronu pokazuje sa kojim neuronima da se poveze, vec da je ta povezanost u najvecoj meri predeterminisana samim rastom tog neurona (a, kao sto se vidi iz rezultata TREES toolbox-a, sam rast je takodje baziran na prostim pravilima)
Ovo je jako bitan rezultat - koji u mnogome pojednostavljuje skup pravila koja uticu na konacan izgled samih neuronskih "kola" koja se sastoje iz mnostva neurona. Prakticno, to znaci da sinteticko "gajenje" neurona algoritmom poput algoritma implementiranog u TREES toolboxu i njihovo nasumicno pozicioniranje predstavljaju vrlo dobru bazu za konacno 'uvezivanje', tj. da nije potrebno simuliranje dodatnih nepoznatih mehanizama kako bi se dobilo funkcionalno (skoro) ekvivalentno kolo realnom!
Sta to znaci prakticno? To znaci da nece biti potreban reverzni inzenjering svake celije ponaosob kako bi se utvrdila povezanost. Odlicna vest za buduce simulatore bioloskih funkcija... losa vest za proizvodjace elektronskih mikroskopa mozda :-)
--
[1] S.L.Hill, Y.Wang, I.Riachi, F.Schürmann, H.Markram: Statistical connectivity provides a sufficient foundation for specific functional connectivity in neocortical neural microcircuits, PNAS, Published online before print September 18, 2012, doi: 10.1073/pnas.1202128109
[Ovu poruku je menjao Ivan Dimkovic dana 28.12.2012. u 23:16 GMT+1]
------------------------------------------------------------------------
v0.91 - Released on January 6th 2013
------------------------------------------------------------------------
* STDP model changed to Voltage-based STDP model (Clopath et al.[1])
which is in agreement with the larger set of experimental data.
[1] "Connectivity reflects coding: a model of voltage-based STDP
with homeostasis"
Clopath C, Buesing L, Vasilaki E, Gerstner W.
Nat Neurosci. 2010 Mar;13(3):344-52
* Tract mapping speed optimizations
* Small bugfixes / cleanups
Novost je novi model plasticnosti koji se bazira na post-sinaptickoj voltazi. Nemam vremena sad da opisem o cemu se tacno radi, ali to cu uraditi kada se vratim sa CES-a.
------------------------------------------------------------------------
v0.92 - Released on January 27th 2013
------------------------------------------------------------------------
* Synaptic receptor state processing has been switched from time-based
to event based (where 'event' is a presynaptic spike). As a result
significant memory I/O has been saved as the receptor state is
updated only per preynaptic spike and not for every simulation time
step. New AVX-optimized synaptic processing code is also better at
grouping data into chunks suitable for processing in AVX registers.
Next big improvements can be expected by Intel(R) Haswell(TM) AVX2
VGATHER instruction, which is going to be supported in the future
version of DigiCortex Engine.
Overall speed improvement is approx. 30% across all demo projects
* Optimized neuron clustering algorithm allowing for greatly improved
neuron locality in the memory. As a result, simulation build-up
time is significantly improved (20%+ on NUMA systems).
* Optimized worker thread scheduling by using NUMA-friendly spinlocks
(spinlock are still 'hybrid' in a sense that they will be used up to
the defined number of spins with exponential backoff, after which
scheduler will try switching to other threads and, finally, sleep
the thread if the work of other threads is not completed at that
point). In addition, false sharing of per-thread data has been
eliminated by padding remaining structures to the L1 cache line size
* Memory usage optimizations by removing certain unnedeed variables
from the Neuron structure
* Added option to inject brief pulse of hyperpolarizing current into
the selected neuron/compartment with the 'O' key
Verzija 0.92 je ~30% brza zahvaljujuci promeni nacina procesiranja stanja sinaptickih receptora. Naime, Markram-Tsodyks model sinaptickih receptora se sastoji od 2 diferencijalne jednacine koje modeliraju evoluciju 2 varijable u vremenu (R i w). Dosadasnje verzije SpikeFun-a su u svakom koraku racunale nove R i w vrednosti koriscenjem Euler-ovog metoda.
Medjutim, trenutne R i w vrednosti su potrebne samo ako je doslo do presinaptickog akcionog potencijala tj. kada je taj potencijal "stigao" do receptora. SpikeFun 0.92 sada racuna novu R i w vrednost u momentu stizanja AP-a uz pomoc male lookup tabele koja sadrzi preracunate e^x vrednosti za R i w varijable za odredjen broj vremenskih koraka. Prilikom stizanja AP-a se utvrdi kada je poslednji put doslo do AP-a i R i w vrednosti se "osveze" tako da su up-to-date.
Uz pomoc ove procedure se stedi na memorijskom I/O-u zato sto vise nije potrebno ucitati i upisati R i w vrednosti za svaku sinapsu (2 float read-a i write-a za svaku sinapsu u svakom koraku) u svakom koraku, vec samo u momentu kada je doslo do spajka (sto se za vecinu sinapsi desava samo nekoliko puta u sekundi).
Simulacija sada trci oko ~30% brze - i na mojoj masini konacno prelazi real-time za 32768 neurona i 1.8 miliona sinapsi. Nije lose ako se uzme u obzir da je nekadasnja 0.63 verzija na istoj masini trcala <0.3x real-time.
Takodje, nova verzija ima bolje klasterovanje neurona tako da je maksimizovan broj lokalnih konekcija u klasteru - ovim se smanjuje memorijski saobracaj van LLC-a (last-level-cache). Medjutim, mislim da je moguce jos znacajno unaprediti klasterovanje sto ce verovatno biti tema jedne od sledecih verzija.
[ Ivan Dimkovic @ 01.02.2013. 21:58 ] @
Inace, primetih da novi Windows API (za Windows 8 i Server 2012) ima nekoliko novih i vrlo interesantnih sinhronizacionih primitiva:
Koliko vidim, novi barrier API koristi ntdll.dll metod RtlBarrier, koji je postojao jos od kernel verzije 6 (Vista), ali je tek sa 8-micom Microsoft odlucio da javno otvori ovaj poziv kroz standardni i javni Win32 API - verovatno su procenili da ce taj poziv da ostane.
Barijera daje mogucnosti kombinacije spinovanja i spavanja niti, bas kao i moj kod - tako da nema nekih prednosti osim eventualno ako Kernel koristi informaciju koje su niti u barijeri kada donosi scheduling odluke, sto nisam proveravao.
Pogledao sam malo asemblerski kod i u pitanju je standardna kombinacija spinlock-a (sa PAUSE instrukcijom) i WaitForXXX API-ja sa malo back-off logike (moguce je podesiti koliko spinova thread moze da odradi pre nego sto krene na spavanje).
Testirao sam performanse, i one su gotovo identicne sa mojom hibridnom barijerom. Tako da cu za Windows 8 / Server 2012 verovatno koristiti Microsoft-ov API posto je onda kod nesto manji.
Cekanje na memorijsku adresu:
Ovaj API je isto vrlo zanimljiv za HPC aplikacije - posto omogucava isto fine-grained sinhronizaciju izmedju niti sa preciznoscu vecom od standardnog scheduler kvanta. "Obicnim" pa i vecini HPC aplikacija to vrlo verovatno nece trebati - ali ako nekome zatreba, svakako nije lose imati jednostavnu OS API funkciju umesto pisanja poveceg koda koji to radi i koji moze patiti od sinhronizacionih problema.
Na zalost, problem sa ovim API-jima je sto su za Windows 8 / Server 2012 (mada, pretpostavljam da je bezbedno koristiti RtlBarrier API direktno preko NtDll.dll-a u kom slucaju ce kod raditi na svim Windows-ima od Viste pa do danas) - tako da ce ljudi sigurno jos dugo vremena morati da imaju fallback za starije Windows-e.
Takodje, ovi API-ji su genericki (mada su performanse, bar barijera, svakako dobre) - neke HPC aplikacije mogu profitirati od custom scheduler-a sa specificnim strategijama za sinhronizaciju. Medjutim, takav kod je cesto potrebno "tune-ovati" za svaki procesor / brzinu memorije ponaosob + sto veca kolicina "lock-free" koda samo povecava mogucnost za propuste i bagove.
U svakom slucaju, SpikeFun 0.93 ce verovatno koristiti Win 8 barijere ako nadje metod u KernelBase.dll.
------------------------------------------------------------------------
v0.93 - Released on Feb 3rd 2013
------------------------------------------------------------------------
* Neuron Long-term Plasticity Homeostasis
* Updated performance monitoring code to Intel(R) PCM v2.3, supporting
memory I/O metrics for single-socket Sandy Bridge-E architecture.
Added support for memory bandwidth I/O readouts from uncore per each
CPU socket (requires uncore IMC readout support - supported by Intel
Nehalem, Westmere or Jaketown / Sandy Bridge-E architectures )
* Significantly increased simulation throughput for small simulations
running on large number of CPUs where threads spent significant time
(20+ %) in wait state. In SpikeFun 0.93 thread workload divergence
has been minimized thanks to improved load balancer, which allows to
nearly eliminate time threads spend spinning (or sleeping when wait
time is too large).
* Added support for Windows 8 / Server 2012 new Kernel synchronization
primitives ( Synchronization Barriers )
Verzija v0.93 donosi poboljsani load balancer koji sada pouzdano zauzima 99 - 100% procesora bez obzira na broj (provereno sa do 32 procesora). Minimizovano je vreme koje niti provode u cekanju na zavrsetak ostalih (obicno je vreme cekanja manje od 0.1ms po thread-u po time step-u)
Tako da su male simulacije na velikim sistemima nekih 20-30% brze - iz prostog razloga sto je u ranijim verzima zbog razlika u load-u dolazilo do "bacanja" ~20-tak % CPU vremena.
Jedina losija nuspojava je da sada kada SpikeFun trci, neki drugi procesi mogu ostati bez puno CPU ciklusa. Recimo, Windows 8 / Server 2012 task manager ne crta grafikone za CPU zauzece kada SpikeFun trci. Ako vam ovo predstavlja problem, mozete startovati SpikeFun sa -lowprio switchem, koja ce celom procesu dati nizi prioritet.
Uradio sam i referentni benchmark na dve masine sa novim SpikeFun-om:
Takodje, SpikeFun v0.93 moze da koristi sistemski API za thread barijere. SpikeFun direktno koristi interni (NTDLL) API RtlBarrier(), tako da ova opcija radi od Viste pa na dalje - a ne samo na Windows 8 / Server 2012 masinama. Prilicno sam siguran da Microsoft nece menjati ovaj API, posto vidim da i Windows 8 API koristi identicnu strukturu (RTL_BARRIER) samo sa drugim imenom.
Razlog zasto koristim Windows barijeru je samo zato sto mozda (nije provereno) ona daje hint Windows kernelu da je grupa niti u istoj barijeri.
--
Nova verzija, takodje, sadrzi novi Intel-ov referentni kod za merenje performansi (Intel PCM) koji sada moze da cita memorijski I/O saobracaj i na HEDT Sandy Bridge-E platformi (Core i7 36xx, 38xx). Dosadasnje verzije SpikeFun-a su koristile stariji PCM kod koji nije mogao da pristupa Sandy Bridge E uncore registrima vec je zahtevao Xeon E5.
--
I, konacno, STDP algoritam sada ima i algoritam za postizanje homeostaze. Homeostaza funkcionise kontrolom LTD koeficijenta (long-term-depression) koja ce smanjiti koeficijent ako uproseceni membranski potencijal u proteklih 1 sec padne ispod neke vrednosti. Time se sprecava depression runaway efekat koji bi izazvao kolaps simulacije zbog premalih jacina sinapsi.
------------------------------------------------------------------------
v0.94 - Released on March 3rd 2013
------------------------------------------------------------------------
* Added support for Adaptive Exponential Integrate and Fire (AdEx)
neuron model [Brette R. and Gerstner W. (2005)]. To test the AdEx
model, just rename BaseNeuronTypes.adex to BaseNeuronTypes.xml (in
this file, pyramidal neurons of layer V/VI will be simulated using
AdEx model).
* Added support for injection of background current to every neuron.
To enable background current injection, just set the <InjectCurrent>
parameter in the simulation XML file <BaseSimulationParams> block.
* It is now possible to specify all neuron model parameters (except
gUp/gDown) for somatic and dendritic compartments separately
* Added option to toggle the rendering of orientation axes (0 key)
Verzija 0.94 donosi jos jedan model neurona - Adaptive Exponential Integrate and Fire (AdEx ili Brette-Gerstner). Vise o ovom modelu mozete procitati ovde:
AdEx model je kvalitativno vrlo slican Izhikevich-evom modelu, tj. pripada klasi hibridnih dvodimenzionalnih modela sa resetom i ima vrlo slicno ponasanje kada su bifurkacije u pitanju. Medjutim, za razliku od Izhikevich-evog modela, inicijacija akcionog potencijala je modelirana eksponencijalnom fukcijom (za razliku od kvadratne kod Izhikevich-evog modela) sto je, inace, priblizniji opis prirodne inicijacije AP-a (posto su aktivacione krive u prirodnim neuronima najpribliznije opisane Boltzmann-ovim funkcijama).
Takodje, AdEx paramteri, za razliku od parametera Izhikevich-evog modela, su direktno u relaciji sa bioloskim parametrima koji se mogu direktno izmeriti, sto bar u teoriji znaci da se AdEx parametri mogu lakse prilagoditi tako da model opisuje "pravi" neuron. To se zaista i pokazalo u praksi, gde je AdEx model moguce relativno jednostavno tune-ovati uz pomoc Brian simulatora (GPU model fitting). Uz algoritam opisan u [3], AdEx model je bio u stanju da "pogodi" 89.9% akcionih potencijala pravog neurona koji je bio "tretiran" razlicitim strujama.
Interesantno, Brette i Gerstner [1] su pokazali da AdEx model moze da pogodi 96% akcionih potencijala kompleksnog modela neurona Hodgkin-Huxley tipa. Zapravo 100% fit je nemoguc, posto i prirodni neuroni nemaju 100% verno "ispaljivanje" AP-ova. 96% je jako visok procenat ako se uzme u obzir drasticno manja kompleksnost AdEx modela u poredjenju sa HH modelima.
Sve ovo AdEx, zajedno sa Izhikevich-evim modelom, cini vrlo dobrim modelom za simulacije koje imaju veoma veliki broj neurona, gde nije potrebno modelirati posebno razlicite jonske struje sto je jedino moguce sa drasticno kompleksnijim modelima Hodgkin-Huxley tipa.
Evo kako izgleda ponasanje AdEx modela u poredjenju sa prirodnim kortikalnim neuronom:
Primetiti da Izhikevich model u ovom takmicenju nije imao visok skor - medjutim algoritam za model-fitting nije dobar za Izhikevich-ev model neurona i vrlo verovatno mnogo bolji rezultati mogu da se postignu koriscenjem drugacijeg modela za nalazenje optimalnih parametara, recimo: http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=5530803
Inace, koga zanima, AdEx model opisuje evoluciju membranskog potencijala ("voltaze") uz pomoc dve diferencijalne jednacine i jednog reset uslova:
Kao sto se vidi, model je vrlo slican Izhikevich-evom. Razlike su: inicijacija akcionog potencijala je opisana eksponecijalnim, a ne kvadratnim, izrazom. Takodje, svi parametri modela imaju direktno biolosko znacenje, sto u teoriji omogucava jednostavno nalazenje optimalnih parametara za konkretan prirodni neuron. Takodje, moguce su i direktne redukcije modela Hodgkin-Huxley tipa, kao sto je pokazano u vezbi 3 u [1]
Kompleksnost AdEx modela je slicna Izhikevich-evom. AdEx model zahteva nesto vise instrukcija po neuronu/kompartmentu zbog eksponencijalne funkcije, ali to je moguce kompenzovati nekom od aproksimacija exp() f-je koje postoje na svim popularnim platformama. DigiCortex engine trenutno ne koristi aproksimaciju za eksponencijalnu f-ju ali to ce biti dodato u nekoj od sledecih verzija.
Malo vesti - CUDA verzija SpikeFun-a vrlo lepo napreduje, tako da ce biti releasovana uskoro. GTX680 bez problema krcka neurone brze nego 16 Xeon jezgara i to vise puta :-)
A za testiranje mi je upravo stigla i fina kartica :-)
+ jos jedna Tesla C2075, cisto da se zagreje gajba.
[ ventura @ 14.03.2013. 11:43 ] @
Mnogo ti je skup taj screen saver :)
[ Ivan Dimkovic @ 14.03.2013. 12:48 ] @
Pa nema ozbiljnog hobija bez ozbiljnih ulaganja :-)
Dobra stvar je sto i GTX Titan i Tesla C2075 imaju po 6 GB VRAM memorije. Bice interesantno videti da li mogu da napakujem milion neurona na njih :)
[ Ivan Dimkovic @ 15.03.2013. 00:07 ] @
Evo nekih preliminarnih rezultata (samo jedan GPU aktivan, GTX Titan):
Dakle, vrlo rana verzija DigiCortex CUDA koda je trenutno nekih 5-6 puta brza na jednoj GTX Titan kartici od 16 Xeon jezgara na 3.1 GHz.
Nije lose, uzevsi u obzir da taj Titan (koji inace nije jeftina kartica) nekih ~4x jeftiniji od 2 Xeon-a 2687W, znaci dobijamo 20-24x vece performanse po $/EUR :)
Ono sto je vazno napomenuti - u pitanju je vrlo optimizovan CPU kod (koji koristi 256-bitne AVX instrukcije). Cesto se u poredjenjima CUDA vs. CPU koristi neoptimizovan CPU kod pa rezultati nemaju puno smisla.
Ovde je u pitanju CUDA kod koji nije previse optimizovan vs. optimizovan CPU kod. I pored svega toga, GPU bez problema biva ~7x brzi od 16 modernih CPU jezgara. To samo pokazuje koliko su GPU-ovi dobri danas za naucne i industrijske aplikacije.
------------------------------------------------------------------------
v0.95 - Released on March 16th 2013
------------------------------------------------------------------------
* First (alpha) release of CUDA compute capability. To enable CUDA,
DigiCortexConfig.cuda should be renamed to DigiCortexConfig.xml
CUDA support is in a very early stage, and support only a subset
of DigiCortex features.
Limits of the current CUDA compute module:
- Support for 64-bit version of DigiCortex only
- Only one GPU is supported
- It is not yet possible to spread the simulation between compute
nodes (e.g. CPU + GPU)
- Only Izhikevich model is supported (AdEx coming soon)
- STDP is not supported yet
* Fixed a bug where video capture was extremely slow during simulation
v0.95 donosi preview buduce podrske za GPU akceleraciju. U pitanju je vrlo rana verzija koda, koja jos nije optimizovana i kojoj nedostaje dosta feature-a DigiCortex-a. Ali bez obzira na to, i tako ran GPU kod bukvalno ostavlja u prasini optimizovan CPU kod koji trci na 16-jezgara.
Cak i na mom laptopu, bedni GTX 650M izvlaci 0.3x real-time faktor za simulaciju od 110 hiljada neurona i 11M sinapsi, sto je 30% brze od dual Xeona E5 sa 16 jezgara na 3.1 GHz! Naravno sve ovo je moguce zato sto su simulacije neurona inherentno masivno paralelne, i kao takve predstavljaju pogodan cilj za optimizaciju na GPU arhitekturama.
Cisto primera radi, mala simulacija sa 32 hiljade neurona / 2 miliona sinapsi radi "samo" duplo brze na CUDA-i, ali kada se broj popne na 500 hiljada neurona i 86 miliona sinapsi, GPU pocinje da urnise CPU sa >7x brzom simulacijom. I to neoptimizovani GPU kod...
[ Ivan Dimkovic @ 27.03.2013. 22:22 ] @
insideHPC intervju sa GTC2013 o DigiCortex projektu sa Anom (koja je napisala CUDA kod) i mojom malenkoscu:
Next step ce biti multi-GPU support i real-time simulacija milion neurona / par stotina miliona sinapsi na jednom GPU-u.
[ Nebojsa Milanovic @ 27.03.2013. 22:30 ] @
Bravo Ivane!
Šta reći... svaka reč je suvišna
[ Ivan Dimkovic @ 28.03.2013. 18:28 ] @
Hvala hvala :-)
[ dejanet @ 28.03.2013. 20:53 ] @
Engleski ti je odlican, takodje i projekat..
[ plus_minus @ 28.03.2013. 21:41 ] @
Ej, mnogo ste dobar par! D:
Ono, reklo bi se da prosto udarate nokaute - iz hobija! D:
Nadam se da zdravlje i strpljenje neće nikada da vas napusti.
Srbi bre! Yeeey!
[ mr. ako @ 18.04.2013. 14:34 ] @
Daj Dimkovicu neki update, sta se desava sa SpikeFun/DigiCortex-om... you've got us hooked! :) Navik'o da svakih 20ak dana bude neka vest, pa ono... :D
[ deerbeer @ 18.04.2013. 21:14 ] @
Bravo Dimke legendo , ulazis polako u Hall of Fame forever :)
Zelim ti puno uspeha u daljem radu ...
[ Ivan Dimkovic @ 21.04.2013. 12:24 ] @
Hehe, veliki task radim pa treba vremena - bice update sledece nedelje :)
Za sada, evo mali sneak preview o cemu se radi:
Ovo desno dole je output retinalnih ganglionskih celija, live feed sa web camere prolazi kroz nekoliko stepena procesiranja u virtuelnoj retini i na kraju dolazi na ganglionske celije, koje salju signal relejnim neuronima u talamusu.
Aktivnost u prozoru dole je jedna SS4 celija u vizuelnom korteksu.
[ Ivan Dimkovic @ 21.04.2013. 18:55 ] @
Inace, ovako ce izgledati preview feed iz retine:
Bele tackice su akcioni potencijali (spajkovi) tzv. 'ON' retinalnih celija, dok su crne tackice akcioni potencijali tzv. 'OFF' celija.
Interesantno, retina je jako dobra u detekciji kontura (kao sto se vidi).
Implementacija koristi VirtualRetina (http://www-sop.inria.fr/neurom...public/software/virtualretina/) paket za procesiranje vizuelnog signala (u pitanju je live capture sa kamere uz pomoc OpenCV biblioteke, ali bice dodata i mogucnost ucitavanja snimljenih sekvenci) do struje RGC celija, dok su same retinalne celije modelirane sa DigiCortex neuronima (Izhikevich-ev model, Class 1 pobudljivost tako da frekvencija akcionih potencijala raste sa intenzitetom RGC struje koja se feed-inuje iz Virtual Retina paketa)
Akcioni potencijali iz ON i OFF retinalnih celija ce stizati do ON i OFF relejnih neurona u lateralnom genikulatnom nukleusu (LGN) talamusa, a odatle preko jedne sinapticke veze signal stize do primarnog (V1) vizuelnog korteksa.
[ Shadowed @ 21.04.2013. 19:39 ] @
Ima li neki video za videti? :)
[ Ivan Dimkovic @ 21.04.2013. 19:49 ] @
Nisam jos implementirao snimanje retinalne aktivnosti, mada to je trivijalno uz pomoc OpenCV biblioteke pa cu verovatno ubaciti to za koji dan.
Sledeca verzija SpikeFun-a ce imati retina modul, koji bi trebao da radi sa svakom web-kamerom, pa ce svako moci da ga testira.
Interesantno, jedan frejm ima malo informacija posto je dosta informacija kodirano kao korelacija izmedju akcionih potencijala razlicitih neurona. To postaje jasno cak i gledajuci video gde neuroni koji "vide" odredjene konture opaljuju akcione potencijale koji su sinhronizovani.
Inace, web kamere koje su u stanju da capture-uju 60 fps ili, jos bolje, 120 fps su skoro pa nepostojece. Vecina kamera koje sam testirao su max. 30 fps na 640x480, a cesto imaju i neku detekciju aktivnosti pa im FPS padne na 15 fps.
Interesantno, Sony PS3 Eye kamera za Playstation 3 ima senzor koji je u stanju da grebuje 640x480 u 60 FPS i 320x240 u 120 FPS (!). Da stvar bude jos bolja, ta kamera kosta 10-tak EUR (!). Slicne kamere koje su nominalno za snimanje brzih sekvenci kostaju od nekoliko stotina EUR pa na dalje.
Narucio sam 4 komada PS3 Eye-a... treba da stignu za koji dan.
Inace, u ovom radu su utvrdili da je potreban minimum 100 FPS input sa malo suma kako neuroni ne bi lock-ovali svoje opaljivanje na FPS. Recimo sa standardnim 25p/30p signalom dolazi do 25 Hz / 30 Hz pikova u aktivnosti retinalnih neurona posto reaguju na dinamiku scene koja se menja sa svakim frejmom. Na 100 Hz taj efekat nestaje ako je signal prirodan i sa malo suma.
Ovo ponasanje je u saglasnosti sa eksperimentima gde retina moze da detektuje 100 Hz treperenje monitora, recimo.
[ Ivan Dimkovic @ 25.04.2013. 23:00 ] @
Retina napreduje - ubacio sam podrsku i za PS3 Eye Cam
78 FPS za 640x480 capture:
PS3 Eye je u stanju da grebuje i do 187 FPS u 320x240, sto u principu nije tesko dostici sa dobro napisanim kodom za grebovanje. Medjutim, problem je sto kod koji radi retinalno procesiranje (VirtualRetina paket) nije optimizovan vec je cist single-threaded C++ kod. Tako da je 78 FPS gornja granica bez obzira na rezoluciju na 3 GHz Sandy Bridge masinama.
Inace, morao sam da pribegnem trikovima kako bi resio trenutnu limitaciju PS3 Eye SDK-a (napisan od strane nezavisne firme, nema veze sa Sony-jem) - naime, iako SDK ima 64-bitni drajver, nije moguce grebovati iz 64-bitnog procesa (pretpostavljam da neki DLL koji radi konverziju podataka ima samo 32-bitnu verziju).
Problem sam resio sa malim 32-bitnim serverom koji nista drugo ne radi osim sto grebuje :) DigiCortex i taj server komuniciraju preko shared memorije a za sinhronizaciju se koristi spinlock tako da je latencija minimalna (zapravo nepostojeca). Sledeca verzija SpikeFun-a ce imati i sors za taj server, pa ko zeli da implementira neki drugi grebing moze to tu da ubaci.
[ Ivan Dimkovic @ 26.04.2013. 23:39 ] @
Zapravo, stvar izgleda mnogo bolje (jasnije) uzivo - evo primera:
Kao sto se moze videti, retinalne ganglionske celije su vrlo efikasne u reprezentaciji ivica i istaknutih detalja. Takodje, moze se primetiti da staticna slika jako brzo postaje beli sum, sto je takodje osobina pravih retinalnih celija. Jedini razlog zasto nama slike ne nestaju je zbog pokreta ociju (sakada i mikrosakada).
Cak i kada vam je oko potpuno fiksirano na neku tacku, ono u delicu sekunde pravi male pomeraje (tzv. mikrosakade). Ovo omogucava odrzavanje slike. Kada se uz pomoc intervencije fiksira neki objekat za oko (recimo implantacijom u samo oko) u jako brzom roku mozak prestaje da registruje taj objekat.
Takodje - zaustavite bilo koji frejm, i umesto slike cete videti samo slucajno djubre. Bez vremena tj. promene signala u istom percepcija zapravo i ne postoji.
[ cyBerManIA @ 27.04.2013. 11:47 ] @
^ Ovo je odlicno! :)
Reci mi kako si dosao na ideju da u SpikeFunu ubacis i simulaciju retine sa kamerom?
I jel' se za sada nekako manifestuje retina modul na SpikeFun grafike, ili je kao dodatak DigiCortexu?
[ Ivan Dimkovic @ 27.04.2013. 14:42 ] @
Thx :-)
Pa, senzorni ulazi su bili prirodan sledeci korak za razvoj engine-a. Vizuelni sistem je prakticno "najlaksi" (figurativno receno) za implementaciju zbog toga sto je to ujedno i najvise istrazivani (sa najvise naucne literature) deo CNS-a.
Takodje, vizuelni sistem je vidno najvaznije culo posto vrlo veliki % kortikalne povrsine kod zdravih sisara biva namenjen procesiranju vizuelnih senzacija (sa izuzetkom zivotinja koje zive u mraku tipa krtice).
Retina modul je add-in za DigiCortex - aktiviranje istog ce biti konfiguracioni parametar.
Ukoliko je modul aktiviran, neuroni u V1 vizuelnom korteksu ce dobijati retinalni signal. Trenutno je veza direktna (sto nije prirodno) - ali bas sad radim na implementaciji procesiranja koje se desava u talamusu (lateralni genikulatni nukleus). Veza izmedju oka i korteksa nije direktna, vec retinalne ganglionske celije svoje aksone salju u LGN a LGN relejni neuroni salju svoje aksone u korteks.
LGN (kao i ceo talamus) su dugo vremena smatrani za "relej" posto svi senzorni modaliteti osim cula mirisa moraju proci kroz talamus pre nego sto stignu do korteksa. Medjutim, moderna istrazivanja su otkrila da talamus zapravo radi kompleksno procesiranje signala uz pomoc "feedback" signala koji stize iz korteksa. Kada je culo vida u pitanju, LGN je zaduzen za filtriranje u vremenskom domenu kao i za selektivno pojacanje signala koji je u trenutnom interesu korteksa. Zapravo, vizuelni sistem je u stanju da selektivno "poveca rezoluciju" za delove slike koji su trenutno u fokusu paznje.
Efekat retinalnog modula je vidljiv na vizualizaciji korteksa. Takodje, plasticnost oblikuje jacine samih sinapsi. Postoje dokazi da je sama priroda ulaznog signala dovoljna za uspostavljanje vrlo specificnih odziva pojedinacnih neurona u V1 korteksu (svaki neuron je tu specijalizovan za odredjen oblik vizuelne senzacije - recimo, orijentaciju linija itd...)
Pa, senzorni ulazi su bili prirodan sledeci korak za razvoj engine-a. Vizuelni sistem je prakticno "najlaksi" (figurativno receno) za implementaciju zbog toga sto je to ujedno i najvise istrazivani (sa najvise naucne literature) deo CNS-a.
Ja sam i ocekivao da ce neki sledeci korak biti implementacija nekog senzora, samo sto mi je na umu bio neki elektromagnetni senzor. Tipa sa nekom plocicom koji ce se lepiti na neki deo tela (glava, ruka, grudi.. ), fazon EKG. Hvata te podatke i simuliara ste se desava u mozgu.
Sad sam skontao da zelis da dovedes neki signal koji ce emulirati analogni signal naseg nekog cula, i to simuliras dalje u DigiCortexu.
Analiza audio signala nije toliko CPU intensive za razliku od video signala, pa bi mogao da nakacis 2 MICa i probas stereo separaciju i orjentaciju u mozgu.
No, to kad zavrsis sa retina modulom, posto je veoma zanimljiv.
------------------------------------------------------------------------
v0.96 - Released on April 27th 2013
------------------------------------------------------------------------
* Retinal model: Prototype version of the visual system. Early
visual system processing (retinal outer and inner plexiform layers)
is implemented using INRIA Virtual Retina package feeding ON and OFF
retinal ganglion cells (RGC). LGN relay is not yet implemented but
it will be added in the future version of DigiCortex.
Retinal input is fed from the live camera capture source. Two modes
of capture are implemented:
You can configure the capture mode in the XML configuration file,
please refer to <RetinaVideoSource> node in the project XML config
file (e.g. DemoSmallRetina.xml).
Please note that retinal processing is done on the CPU and it is
recommended to use retinal processing only when CUDA acceleration is
enabled (by renaming DigiCortexConfig.cuda to DigiCortexConfig.xml).
Otherwise, retinal processing will "steal" CPU cycles from the
neuron processing.
* CUDA Compute: Added support for Voltage-depentent STDP with
homeostasis (model of Clopath et. al). STDP implementation is
still not optimized and it slows down CUDA processing by ~10-15%
* CUDA Compute: Added support for synapse weight read-out for the
selected neuron (synapse weight display is updated every 500 ms)
Signal iz kamere sada ide kroz talamus, a ne direktno u vizuelni korteks - bas kako se to desava i u pravim organizmima.
Zbog malog broja neurona u test simulacijama je rezolucija u LGN-u prepolovljena (160x120). Svaki neuron u lateralnom genikulatnom nukleusu u talamusu je povezan sa do 4 retinalne ganglionske celije ('ON' retinalne celije se povezuju sa 'ON' celijama u LGN-u). Dalje, LGN celije projektuju u primarni vizuelni korteks gde dolazi do ekspanzije (jedan V1 SS4 / piramidalni neuron se vezuje sa do 18 LGN celija, broj V1 celija je mnogo veci od broja LGN celija).
Evo kako ce to izgledati (pogled na aktivnost LGN 'OFF' celija):
[ Andrej013 @ 20.05.2013. 00:39 ] @
@Ivan Dimkovic
Ovo izgleda jako lepo.
Da li postoji opcija simulacije epilepticnog napada?
Ukoliko ne postoji, da li imas neke ideje/iskustvo vezano za simulaciju epilepticnih napada i koliko bi bilo tesko implementirati tako nesto?
Pitam zato sto sam bio na XY seminara vezanih za predikciju napada i speakeri uglavnom prikazuju video u kojem je svaki piksel elektroda EEG-a ili ECoG-a niske rezolucije pa to sve izgleda kao da je iz osamdesetih godina. Kladim se da bi bili presrecni da mogu da pokazu nesto ovako (uz tvoju dozvolu naravno-ne znam kako se to regulise).
Na mom faksu se konkretno radi na softveru za simulaciju rada epilepticnog mozga(to rade uglavnom master studenti kao thesis) ali mi se cini da nije uradjeno nista vise od integrade and fire modela i Hodgkin-Huxley(sto u osnovnom obliku nema veze sa epilepsijom vec sa obicnom simulacijom rada neurona) a znam zasigurno da to sto su ovde radili ne izgleda ovako fino, vec je rezultat algoritma u najboljem slucaju neki scatter plot u matlabu.
[ Ivan Dimkovic @ 20.05.2013. 11:22 ] @
Thx!
U principu, simulirati epilepticni napad sa mrezom spiking neurona (bez obzira da li su I&F ili HH modeli) nije toliko tesko. Potrebno je samo da sistem bude uzicen tako da pobudjujuci neuroni ne bivaju balansirani inhibitornim i mreza ce sama upasti u abnormalan (za zive mozgove) nacin rada. Ako zelis da modeliras konkretan oblik talasa kao sto je recimo spike & wave, potreban ti je model korteksa sa modelom talamusa koji imaju uzajamni feedback. Ovim stvarima se bavio pokojni Mircea Steriade - potrazi njegove radove na temu gating-a, tu ima dosta malih modela normalnih i nenormalnih (epilepticnih) talamokortikalnih oscilacija.
Zapravo, daleko je teze naterati kompleksnu mrezu spiking neurona da radi nesto korisno nego da sama upadne u rezim rada koji je vrlo slican prirodnom epilepticnom napadu.
Epilepticni napad se sa stanovista dinamickih sistema se elegantno modelira tzv. "atraktorima":
Primeti da epilepticni atraktor postoji i u zdravom mozgu, ali je separacija izmedju njega i stabilnog atraktora velika, i moguce je "premostiti" istu samo u patoloskim slucajevima (vrlo visoka temperatura, odredjeni medikamenti koji spustaju prag epilepticnih napada, itd.).
U bolesnom mozgu je separacija izmedju normalnog i epilepticnog atraktora manja i tokom vremena dolazi do spontanog prelaska u abnormalni rezim. Frekvencija prelaska zavisi od samih parametara sistema, sto u zivom organizmu znaci metabolicke i genetske faktore. U zivom mozgu izlazak iz epilepticnog atraktora se desava verovatno zato sto se neuroni "istrose" tj. potrose zalihe neurotransmitera (vrlo verovatno postoje i sekundarni mehanizmi koje mozak koristi kako bi se izborio sa epilepticnim napadima, recimo skoro je izasao rad gde je pronadjeno da se neuroni bukvalno "sele" iz regiona koji je inicijator epilepticnih napada. Naravno, u vecini slucajeva ovo nije dovoljno pa su neophodni medikamenti ili cak operacije)
--
DigiCortex, takodje, moze da modelira napade - potrebno je eksperimentisati sa maksimalnim sinaptickim strujama (recimo SynParamOverride u XML projektu, ili direktno u biblioteci neurona /NeuronLibrary/BaseNeuronTypes SynWeightParams) kako bi se mreza prebacila u epilepticni model rada. Nisam to probao vec dugo vremena, ali se secam da sam u ranim verzijama cesto dobijao spike&wave pattern (sto nije pozeljno za ono sto meni treba ;-).
Kao sto rekoh, verovatno je daleko teze izbeci epilepticno ponasanje mreze nego simulirati epilepticni napad.
------------------------------------------------------------------------
v0.97 - Released on May 26th 2013
------------------------------------------------------------------------
* Model of early vision: Added LGN visual pathway. Retinal ganglion
cell axons now project to thalamic lateral geniculate nucleus (LGN).
Retinal ganglion cell pathways are currently separated in two layers
'ON' and 'OFF', with corresponding LGN layers. Thalamocortical
relay cells from LGN project to V1 visual cortex.
In addition to the thalamocortical relay cells, both inhibitory cells
of the reticular thalamic nucleus (RTN) and thalamic interneurons are
also present along with the cortico-thalamic "feedback" pathway from
the pyramidal cells of cortical layer 6.
NOTE: It is also possible to see visualized activity of the TC 'ON'
and 'OFF' layers when retinal simulations are run. However, this is
limited to CUDA accelerated simulations only at this moment.
* Started using diffusion MRI data from Human Connectome Project (HCP)
Please see the data source notice at the beginning of this document.
* Simulated intracranial EEG (F2 key) is now also available with the
CUDA-accelerated simulations.
* PS3 Eye Capture Cam process (EyeCamServer.exe) now has built-in
watchdog ensuring that EyeCamServer exits in case DigiCortex engine
becomes unresponsive, avoiding having "zombie" EyeCamServer running
and preventing initialization of camera capture on the next run
* Various small bugfixes
Verzija 0.97 donosi kompletiran rani vizuelni sistem - koji je sada potpun i ukljucuje prolaz kroz dorzalni lateralni genikulatni nukleus (dLGN) talamusa, kao i povratni kortikalni "feedback" koji modulise relejne neurone u talamusu. LGN neuroni ukljucuju:
Simulirani dLGN nukleus ima dva sloja (ON i OFF) na koji su povezane odgovarajuce ON i OFF retinalne ganglionske celije. Za sada je odnos izmedju RGC i LGN TC celija hardcode-ovan tako da je rezolucija dLGN slojeva 160x120 (vs. 320x240 u retini). To znaci da na 1 dLGN TC neuron projektuju 4 retinalne ganglionske celije. Ovo ce biti prosireno u sledecoj verziji DigiCortex-a tako da ce biti moguce podesiti rezolucije.
Takodje, DigiCortex 0.97 je prva verzija koja koristi MRI podatke iz Human Connectome Projecta (HCP). HCP je vrlo ambiciozni projekat u USA koji je dobio $40 miliona za mapiranje tzv. konektoma. U saradnji sa Siemens Medical-om je razvijena nova platforma za skeniranje, Siemens Connectom MRI skener. Siemens Connectom MRI skener je optimizovan za traktografiju i ima drasticno vecu amplitudu gradijenata (100 - 300 mT m^-1). U konkretnom slucaju za DigiCortex projekat to znaci dodatnu preciznost identifikacije aksonalnih puteva - pogotovu kada se radi o kratkim "krivim" traktovima, koje MRI skeneri slabije snage nisu u stanju da razluce.
------------------------------------------------------------------------
v0.97a - Released on June 2nd 2013
------------------------------------------------------------------------
* Model of early vision: Added option to use video files instead of
live camera input (see DemomSmallRetinaFileSource.xml for syntax).
NOTE: It is recommended to use at least 100 FPS videos in order to
avoid phase locking of the retinal ganglion cells to the frame rate
of the source video. Above ~100 FPS this unwanted side-effect is
diminished. In our internal tests we use 1000 FPS videos generated
by motion-adaptive frame rate upconversion of the original videos.
Due to patent restrictions we do not redistribute OpenCV ffmpeg DLLs.
You need to download OpenCV 2.4.4 pre-built binaries from here:
And copy opencv_ffmpeg244.dll and opencv_ffmpeg244_64.dll from the
binary OpenCV distribution to the folder where all DigiCortex DLL
files are located (this is usually the DigiCortex installation path)
WARNING: File-source is untested with source data which resolution
is not 320x240, and which frame rate is not equal to 1000 FPS!
* Cleaned-up DSI fiber data used for long-range axonal tract guidance,
with removed cerebellar and ponto-cerebellar tracts.
* Added post-processing step designed to remove incorrectly resolved
cortical axonal tracts projecting contralaterally and not being part
of any known commissure. These tracts are likely to be artifacts
of the fiber tracking process and thus do not represent anatomically
valid data.
Ovo je manje-vise "maintenance" release. Kod zaduzen za traktografiju je apdejtovan, dodata je mogucnost koriscenja snimljenih AVI clip-ova umesto kamere za retinalni model (vazno: morate iskopirati OpenCV 2.4.4 FFMPEG DLL-ove u DigiCortex folder!) i par malih bugfixeva.
Sledeci build (v0.98) ce imati Haswell AVX2 optimizacije - u principu AVX2 kod je vec bio implementiran ali cekam da mi stigne Haswell masina za testiranje i validaciju AVX2 koda. Videcu ako stignem i da dodam TSX podrsku, mada dok ne stigne Haswell EP platforma ovo sa Haswell-om je vise zezancija, posto 4-jezgra ne mogu ni da prismrde nekoj mid-range NVIDIA kartici. EP platforma sa svoja 4 socket-a po 15 jezgara ce vec biti nesto drugo :-)
------------------------------------------------------------------------
v0.98 - Released on June 9th 2013
------------------------------------------------------------------------
* Early support for Intel Haswell microarchitecture with the dedicated
AVX2 optimizations (Fused Multiply & Add, Gather)
* Added support for hardware performance counter monitoring for Intel
Haswell microarchitecture
* Added support for memory bandwidth measurement using hardware perf.
counters in desktop processors based on Intel Sandy Bridge and
Ivy Bridge microarchitectures. Previously, on non-server
architectures memory bandwidth was estimated by software means
* Fixed a bug where icEEG was not computed for retinal simulation with
offline AVI file as the visual input source
Glavna novost u verziji 0.98 je podrska za nove Intel Haswell CPU instrukcije: AVX2, FMA (Fused Multiply-Add) i Gather.
DigiCortex 0.98 ima posebne AVX2 DLL-ove i rucno kodirane rutine za procesiranje sinaptickih receptora koje su AVX2 optimizovane (ukljucujuci FMA i Gather). Iako je gather u Haswell mikroarhitekturi implementiran preko mikrokoda (i, samim tim, definitivno nije brz koliko bi bilo moguce da je implementiran direktno, posto mikrokod zapravo generise load instrukcije) - ukupni dobici u performansama clock-for-clock u odnosu na Ivy Bridge su oko 22%.
Obratite paznju - 22% ne zvuci kao mnogo, ali ako se uzme u obzir da je DigiCortex prvenstveno memory-bound, sto znaci da CPU jezgra cesto provode i 70% vremena cekajuci da podaci stignu sa memorijskog kontrolera, ovo ubrzanje je zapravo impresivno. Pravo IPC ubrzanje kada bi se eliminisao faktor cekanja na memoriju bi zapravo bilo blize ~70% . Ovi dobici su moguci samo zahvaljujuci AVX2 instrukcijama.
Sve u svemu, Haswell generacija mozda nije impresivna za neke druge stvari kada su u pitanju desktop aplikacije - ali ako vasi algoritmi mogu da iskoriste AVX2/FMA/Gather instrukcije ubrzanja su prilicno dobra. Ako se uzme u obzir da ce EX verzija Haswell-a imati 16-20 jezgara i podrsku za 8 socket-a mislim da ce enterprise-market ubrzanja biti nista manje od fantastickih u poredjenju sa danasnjim Sandy Bridge EP ili Westmere EX platformama.
Bice interesantno pratiti market - ako Intel prosiri AVX na 512 ili cak 1024 bita u Skylake inkarnaciji i spusti procesore sa 16+ jezgara dolazimo do situacije da CPU i GPU arhitekture pocinju da zesce lice jedne na drugu. NVIDIA je isto tako zauzeta prosirivanjem CUDA arhitekture sa dodatcima koji olaksavaju portovanje ne-masivno-paralelnih algoritama i unapredjivanjem kesa.
Sasvim je moguce da za 4-6 godina dodje do izjednacavanja CPU i GPU arhitektura.
------------------------------------------------------------------------
v0.99 - Released on July 6th 2013
------------------------------------------------------------------------
* Improved performance of the CPU simulations by using new event-based
synaptic update workflow. Time steps can be processed up to 2 times
faster in certain workloads with high number of action potentials
* Improved CUDA simulation performance (up to 50%). Real-time simulation
performance achieved with 300K neurons on single GK110 TITAN GPU
* Added in-place preview of the retinal activity in the main simulation
window (activated with the 'F' key)
* Fixed a bug where incorrect candidate pre-synaptic neurons were
used in simulation build-up phase. While the correct pre-synaptic
type was obtained it might not conform to the target distance between
its axon branch and post-synaptic neuron's dendritic branch
* Fixed a bug where vSTDP weights were updated improperly on the CPU
simulation in certain cases.
Sve u svemu, CPU verzija je i do 2x brza. CUDA verzija je do 50% brza i uspeli smo da izvedemo real-time simulaciju sa 300K neurona na jednoj GK110 (Titan) kartici.
------------------------------------------------------------------------
v0.99a - Released on July 28th 2013
------------------------------------------------------------------------
* Changed identification of the primary visual cortex using FreeSurfer
5.3 detection method
* Improved neuron soma distribution across cortical surface
* Added -homedir command line option for SpikeFun.exe enabling setting
home path for all project files and configuration data (useful when
executing from external application)
* Fixed a severe performance degradation when running on CPUs with
core count different than power of 2 (e.g. 6, 10, 12)
* Added performance monitoring support for Intel architecture codename
IvyTown / Ivy Bridge EN/EP/EX (Xeon E5/E7 2600/2800/4600/4800/8800 v2)
* Fixed a bug which resulted in a crash when retinal simulation is run
on CPU-s (CUDA disabled) and the number of logical CPUs is larger
than 32
Ova verzija je mahom bugfix release, sa dodatom podrskom za performance-monitoring Ivy Bridge EP / Ivy Bridge E procesora (IvyTown) kao i fx za bag gde je dolazilo do vidnog pada performansi na sistemima sa brojem procesora razlicitim od stepena broja 2 (6, 10, 12...)
Takodje, fixiran je i problem koji je dovodio do kraha na sistemima sa brojem logickih procesora vecim od 32.
Dodata je i -homedir opcija koja omogucava da se simulacija pokrene iz nekog drugog foldera, recimo ako je SpikeFun instaliran u C:\SpikeFun folderu:
------------------------------------------------------------------------
v1.00 - Released on August 24th 2013
------------------------------------------------------------------------
* Added support for Oculus Rift VR headset. To enable Oculus Rift
visualization mode, add -oculus to SpikeFun.exe / SpikeFun64.exe
command line. Oculus Rift support works in multi-monitor mode
(non fullscreen). In addition, it is also possible to configure
supersampling for increasing quality on limited-resolution Oculus
Rift development kits: use -osfac <N> where N is the supersampling
factor (default 2).
Posle ~2.5 godine, nestalo mi brojeva sa 2 decimale ispod 1.0 :-)
Salu na stranu, verzija 1.0 je zaokruzen demonstrator pa reko' da je vreme da se predje na 1.x.
Verzija 1.0 donosi podrsku za Oculus Rift Virtual Reality headset. Ovaj fantastican gadget omogucava, po prvi put, potpunu imerziju u VR svet za (relativno) male pare. Ako imate Oculus Rift kit, sada mozete terati i DigiCortex simulacije na njemu. Vizualizacija ce, takodje, pratiti pokrete i polozaj vase glave tako da sa Oculus Rift-om zaista postajete deo simulacije.
U ovom modu, ispred vas ce se naci simulirani mozak u koji bukvalno mozete da "udjete" i gde vase pokrete glave vizualizacija verno prati (naravno, moguce je i kretati se kroz simulaciju sa w, a, s i d dugmicima na tastaturi ili pokretima glave ili misa, kao u 3D FPS-u :-).
Trenutno nema puno stvari koje se prikazuju, ali u buducnosti ce biti dodate razne statistike kao i mogucnost interakcije sa simulacijom (selekcija individualnih delova mozga, neurona, prikaz simuliranog EEG-a, fMRI-ja i sl..)
Ako zelite da poterate simulaciju sa Oculus Riftom, trenutno DigiCortex podrzava isti u multi-monitor modu (ne fullscreen):
Kako trenutni Oculus Rift development kit ima relativno nisku rezoluciju (1280x800), po defaultu ce DigiCortex super-semplovati rendering 2x, tako da ce renderovati prvo u bafer od 2560x1600 piksela i na njemu raditi post-procesiranje distorzije Oculus Rift sociva. Ovime se donekle poboljsava kvalitet. Ako zelite jos vise da povecate supersampling, to mozete uraditi sa -osfac <N> command line parametrom gde je N faktor super-semplovanja (default 2).
Konacno, jako je tesko opisati kako izgleda Oculus Rift simulacija bez da se vidi uzivo. Najkrace receno - osecaj je da ste 100% "unutra" i potpuno neuporediv sa 3D monitorima u pozitivnom smislu.
Ali kao sneak-preview, evo kako izgleda debug pogled na Oculus render - tj. sta oba oka vide. Mozete primetiti korekciju distorzije HMD sociva. Kao sto rekoh, na ekranu je ovo neuporedivo sa VR projekcijom.
Cestitke na ver1.0, narastao mali skoro 57MB! :)
Odlicna je stvar taj Oculus, ali da li ima neku funkcionalnu prednost nad obicnim prikazom? Msm, imerzija je sigurno visestruko veca, no osim za vizuelni ugodjaj jel ima mogucnosti za neku drugu namenu?
[ Ivan Dimkovic @ 24.08.2013. 23:14 ] @
Hvala hvala :)
Tehnicki, sve informacije koje vidis mozes imati i na 2D ekranu. Medjutim, prednost VR imerzije je zato sto omogucava prirodnu navigaciju i motivise ljude da dodatno istrazuju.
Mislim da ce to imati veliki uticaj na vizualizacije podataka - pogotovu velike kolicine podataka. Mislim da ce u kombinaciji sa dodatnim trekovanjem pokreta ruku i sl.. to omoguciti drasticno intuitivnije korisnicke interfejse i nove nacine pregleda podataka.
Otprilike kao iz SF filmova - "udjes" u podatke i prolazis kroz iste pokretima svog tela.
[ Ivan Dimkovic @ 25.08.2013. 12:52 ] @
Evo jos jednog screenshot-a, gde je korekcija distorzije ociglednija:
Pogled sa lokacije vizuelnog korteksa uperen ka frontalnim strukturama. Crvena masa su traktovi corpus callosum strukture.
Ali, kao sto rekoh, bez Oculus Rift HMD-a je jako tesko opisati kako to zaista izgleda.
[ Ivan Dimkovic @ 25.08.2013. 13:04 ] @
Ili pogled na temporalni korteks:
[ mr. ako @ 25.08.2013. 20:11 ] @
Haha, ss-ovi izgledaju totalno tripozno. :D To uz kombinaciju neke dznaki muzike moze da ustedi silne pare za pecurke! :D :D
Btw, jel ima negde na sajtu MD5 hash latest instalacionog fajla?
[ Ivan Dimkovic @ 25.08.2013. 20:59 ] @
Nema - ali to mogu da napravim.
Inace instalacioni fajl je digitalno potpisan.
[ mr. ako @ 26.08.2013. 15:08 ] @
Aj' stavi negde ako te ne mrzi...
Thx!
[ Ivan Dimkovic @ 26.08.2013. 18:46 ] @
Evo ti MD5 za poslednji SpikeFun_Latest.exe (1.00a)
I posalji mi debug.txt - pa cu da pogledam. Interesantno, dobio sam jos jedan mail od korisnika da mu SF puca, problem je sto ne testiram vise na masinama starijim od IvyBridge-a, pa mozda to pravi problem.
Hvala unapred!
[ bogdan.kecman @ 02.09.2013. 12:24 ] @
cpu: neki i7 na 3.34G (na windozi sam sad pa na mogu da uradim cat /proc/cpuinfo :D nemam pojma koji je procesor tacno )
mb: X58
gpu: nvidia gtx295
ram: 12G
ovaj tvoj cmd nije puko .. hm ... kada ga startam iz start menija, ucitam neku simulaciju, on trkelja nesto, prikaze glavne dve slike i onda krene da otvara nesto u gornjem levom cosku desnog monitora i tu prsne...
dakle kada uradim ovo:
SpikeFun64.exe -vv -project DemoSmallRetina.xml -noresize -ministhalamus -demo > debug.txt
ili
SpikeFun64.exe -vv -project DemoSmallRetina.xml -demo > debug.txt
on radi, ali kada ga startam iz start menija, ucitam demosmallretina.xml i pustim ga on trkelja i kada treba da prikaze onaj prozor gde se bira neki view (nisam skonto cemu sluzi) on prsne
[ Ivan Dimkovic @ 02.09.2013. 12:27 ] @
Da, to je Nehalem / Westmere CPU (X58), a njih nemam vise.
Moracu da vidim da nemam negde zaturen neki pa da probam.
Ali cudno je da ne puca iz komandne linije - mozda ti samo 32-bitni puca?
Ako ti 32-bitna verzija puca, to je onda verovatno zato sto Westmere / Nehalem, koliko se secam, i dalje imaju aligment zahteve za movaps SSE instrukcije te da 32-bitni kompajler nesto nije uravnao. To se na Sandy Bridge / Ivy Bridge / Haswell platformi ne primecuje.
Ako je to u pitanju, onda cu to lako da fixujem, samo da se dokopam neke matorije masine.
Citat:
on radi, ali kada ga startam iz start menija, ucitam demosmallretina.xml i pustim ga on trkelja i kada treba da prikaze onaj prozor gde se bira neki view (nisam skonto cemu sluzi) on prsne
DemoSmallRetina zahteva capture uredjaj (kameru) kompatibilnu sa OpenCV bibliotekom.
Ako nemas kameru, to nece raditi - ne bi trebao da puca (to moram da vidim) ali bi trebao da prijavi neku OpenCV gresku na kraju u logu.
Da li imas neku web kameru zakacenu? Ako nemas, to nece ici. Postoji opcija da se ucita AVI fajl, pogledaj u changelog.txt (trazi OpenCV):
Citat:
------------------------------------------------------------------------
v0.97a - Released on June 2nd 2013
------------------------------------------------------------------------
* Model of early vision: Added option to use video files instead of
live camera input (see DemoSmallRetinaFileSource.xml for syntax).
NOTE: It is recommended to use at least 100 FPS videos in order to
avoid phase locking of the retinal ganglion cells to the frame rate
of the source video. Above ~100 FPS this unwanted side-effect is
diminished. In our internal tests we use 1000 FPS videos generated
by motion-adaptive frame rate upconversion of the original videos.
Due to patent restrictions we do not redistribute OpenCV ffmpeg DLLs.
You need to download OpenCV 2.4.4 pre-built binaries from here:
And copy opencv_ffmpeg244.dll and opencv_ffmpeg244_64.dll from the
binary OpenCV distribution to the folder where all DigiCortex DLL
files are located (this is usually the DigiCortex installation path)
WARNING: File-source is untested with source data which resolution
is not 320x240, and which frame rate is not equal to 1000 FPS!
U sledecoj verziji cu ubaciti podrsku i za snimljen dump retinalnih neurona (spajkovi) umesto video fajla, sto bi trebalo da bude i brze i lakse za testiranje.
[ bogdan.kecman @ 02.09.2013. 12:38 ] @
Citat:
Ivan Dimkovic:
Ali cudno je da ne puca iz komandne linije - mozda ti samo 32-bitni puca?
bem li ga, startovao sam 64bitni iz start menija :D taj je pucao
radi kako sam i ocekivao, kazem ti startujem 64bitni iz starta i on pukne kada treba da prikaze taj novi prozor (ili kada treba da prikaze spisak video uredjaja bem li ga, to nikad ne prikaze u toj varijanti kad puca, kada startam iz cmd-a prikaze mi listu kamera, sve tri uredno prikaze)
Citat:
DemoSmallRetina zahteva capture uredjaj (kameru) kompatibilnu sa OpenCV bibliotekom.
Ako nemas kameru, to nece raditi - ne bi trebao da puca (to moram da vidim) ali bi trebao da prijavi neku OpenCV gresku na kraju u logu.
Da li imas neku web kameru zakacenu? Ako nemas, to nece ici. Postoji opcija da se ucita AVI fajl, pogledaj u changelog.txt (trazi OpenCV):
hm imam neki freetalk klasicnu web kameru (hd ovo ono) za skype i imam neke specijalizovane (za mikroskop), dal je sta od toga podrzano od opencv-a nemam pojma, bas sam ovih dana hteo da probam malo da se igram sa opencv-om posto moram pod hitno da ozivim moje projekte za decije robote jerbo sam vec u zakasnjenju sa tim (klinac dosao a finalna ideja daleko od realizacije)
[ Ivan Dimkovic @ 02.09.2013. 12:48 ] @
Jel mozes da editujes bat/cmd fajl koji startujes iz start menija tako da ima -vv opciju, kao i
Code: > debug.txt
na kraju, pa mi saljni debug.txt da vidim sta ga tacno zeza.
[ bogdan.kecman @ 02.09.2013. 12:53 ] @
on kaze da iz start menija startuje direkt exe ?!
(C:SpikeFunDigiCortexIDE_64bit.exe ) nisam ja vican ovom winblowsu ali
desni klik na start meni pa properties kaze to ?!
[ Ivan Dimkovic @ 02.09.2013. 12:54 ] @
Aaa ti startujes IDE, - OK, to je vec nesto drugo.
To moram da vidim sta je tacno onda - moguce je da retina ne radi sa njim, posto je nisam ni testirao unutar IDE-a :-)
Probacu veceras kad dodjem sa posla. Thx!
[ bogdan.kecman @ 02.09.2013. 12:57 ] @
pazi sad kad sam ti c/p i ja sam provalio da u cmd cukam spikefun64.exe
a vamo pikam ide :D
nego imal neki "super brz" nacin da vidim dal mi kamera kompatibilna sa
opencv-om? ovo tvoje kad startam kad odaberem moju kameru tamo sve
"crno", tj oni mozgovi nesto pickecu i one linije igraju, ali u tom
prozoru za retinu se nista nigde ne desava bez obzira sta odaberem ? pa
cisto jel ima neki opencv "demo" da vidim el mi kamera sljaka sa tim ili
ne (da te vec iskoristim :D, svuda vidim samo sorsove, iskompajliro bi ja neki demo na brzaka, ali jos na vindozi nemam nijedan kompajler :( )
[ Ivan Dimkovic @ 02.09.2013. 13:14 ] @
Baci mi log i od SpikeFun64.exe onda, to bi me zanimalo - da li baca neki warning i sl...
Sto se OpenCV-a tice, probaj da prikljucis samo jednu kameru (koliko razumem, imas ih nekoliko) - posto za sada nemam opciju da se konfigurise camera ID (dodacu to u sledecoj verziji).
#include "cv.h"
#include "highgui.h"
#include <stdio.h>
// A Simple Camera Capture Framework
int main() {
CvCapture* capture = cvCaptureFromCAM( CV_CAP_ANY );
if ( !capture ) {
fprintf( stderr, "ERROR: capture is NULL \n" );
getchar();
return -1;
}
// Create a window in which the captured images will be presented
cvNamedWindow( "mywindow", CV_WINDOW_AUTOSIZE );
// Show the image captured from the camera in the window and repeat
while ( 1 ) {
// Get one frame
IplImage* frame = cvQueryFrame( capture );
if ( !frame ) {
fprintf( stderr, "ERROR: frame is null...\n" );
getchar();
break;
}
cvShowImage( "mywindow", frame );
// Do not release the frame!
//If ESC key pressed, Key=0x10001B under OpenCV 0.9.7(linux version),
//remove higher bits using AND operator
if ( (cvWaitKey(10) & 255) == 27 ) break;
}
// Release the capture device housekeeping
cvReleaseCapture( &capture );
cvDestroyWindow( "mywindow" );
return 0;
}
^ ista prica, pretpostavljam da CV_CAP_ANY moras da zamenis sa camera ID-om ili da prikacis samo jednu kameru koja ce biti auto-detektovana.
[ bogdan.kecman @ 02.09.2013. 13:24 ] @
fala za linkove, sad cu da probam (mada evo stigo i VS2012, samo da ovi
iz firme posalju sta treba za aktivaciju),
za kameru, kako nisi implementirao ID ako me pita koju kameru hocu da
koristim? i vidim da mi upali ledaru na kameri koju sam odabrao (dakle
definitivno je odabere)
za log
[1309021134000] WARNING: Neuron 49152, Compartment 0x84edc20 --> Unable
to meet target synaptic allocation (18 synapses missing of 40 requested)
[1309021134000] WARNING: Neuron 49153, Compartment 0x84ee280 --> Unable
to meet target synaptic allocation (12 synapses missing of 40 requested)
[1309021134000] WARNING: Neuron 49154, Compartment 0x84eeb80 --> Unable
to meet target synaptic allocation (33 synapses missing of 40 requested)
tako da deluje da nema problema
[1309021135138] NOTE: To enable CUDA GPU acceleration, rename
DigiCortexConfig.cuda to DigiCortexConfig.xml
a izgleda ne koristi cuda :(
[ Ivan Dimkovic @ 02.09.2013. 13:48 ] @
Ako pita za kameru, to mora da je neka OpenCV fora u njihovoj biblioteci, ja to nisam video posto nisam kacio vise od jedne podrzane kamere.
Moj kod trenutno salje CV_CAP_ANY argument, a OpenCV verovatno ima neku svoju foru da te pita koju kameru hoces.
U sledecoj verziji cu dodati da camera ID moze eksplicitno da se setuje u konfiguracionom fajlu posto mi se ne svidja da mi API poziv blokira neki 3rd party GUI neocekivano :)
Ako hoces CUDA-u da koristis, preimenuj DigiCortexConfig.cuda u DigiCortexConfig.xml
[ bogdan.kecman @ 02.09.2013. 14:21 ] @
upalio sam cuda (onaj gore rar ti je log sa cuda-om mada ne vidim neke znacajne warninge) .. bice da je problem neki sa ide-om to ce verovatno da puca i kod tebe na novoj makini :D
inace, bas leti sa cuda-omm :D
[ bogdan.kecman @ 04.09.2013. 06:54 ] @
radi ok ova kamera sa cv-om, zahvaljujem na primeru. izgubih ceo dan da
nateram uopste cv da radi sa vs2012, tj, prvo dok sam skontao da je
vs2012 verzija 11, pa dok sam se malo privikao na ovu ogavrstinu, pa dok
sam dodao 64bitni target, pa nece ucita dll-ove (falio mi ; u sistemskom
path-u za ocv)... vec sam skoro zazalio sto sam se vratio na windozu...
nego da se vratimo na spikefun, mozda ti je jos iskusnije da koristis
cv2 umesto cv?
Code:
#include <opencv2/opencv.hpp>
using namespace cv;
int main(){
VideoCapture cap(1);
Mat src;
if (!cap.isOpened()) return -1;
while(true){
cap >> src;
flip(src, src, 1);
imshow("mw", src);
int q=waitKey(15);
if ((char)q=='q') break;
}
}
ne znam za sta uopste koristis cv u spikefun projektu.. vidim da cuda i
pecl jesu koristeni u opencv-u i kapiram da iz opencv-a moze da se
iskoristi nesto od njih ali moze i bez opencv-a? ili opencv koristis
samo za grab slike sa kamere i dalje sve radi tvoj sw za simulaciju,
cisto nisi hteo da se smaras sa citanjem raw date sa kamere i knaranjem
sa dx-om?
uzdravlje, ovaj tvoj projekat bas lepo napreduje .. malo cudan hobi ali
jos nisam naisao na neki koji nije a da vredi :D (cudan u smislu, ti
sedis pored kompa 24/7 za "sljaku" .. ja sam zbog toga nasao hobi koji
je potpuno drugaciji, vrlo "opipljiv"/"mehanican" za razliku od ovog
virtuelnog sveta u kom radimo, ti si i za hobi uvatio opet istu tu
virtualiju :D .. ovi moji 3d printeri kad nesto naprave bar mozes da
pipnes :D )
[ Ivan Dimkovic @ 04.09.2013. 17:04 ] @
Ma OpenCV koristim samo za video-capture, zato sto je jednostavan da se setuje (kao sto vidis iz primera) i ne moram da se drkam sa DirectShow-om i njegovim API-jem posto su oni to vec uradili ;-)
Za PS3 EyeCam capture ne koristim OpenCV vec pristupam preko CL Eye biblioteke - sa njom mogu da izvucem do 175 FPS za 320x240 sto je suludo dobar FPS za kamericu koju danas mozes da kupis za 10 EUR.
Citat:
uzdravlje, ovaj tvoj projekat bas lepo napreduje .. malo cudan hobi ali
jos nisam naisao na neki koji nije a da vredi :D (cudan u smislu, ti
sedis pored kompa 24/7 za "sljaku" .. ja sam zbog toga nasao hobi koji
je potpuno drugaciji, vrlo "opipljiv"/"mehanican" za razliku od ovog
virtuelnog sveta u kom radimo, ti si i za hobi uvatio opet istu tu
virtualiju :D .. ovi moji 3d printeri kad nesto naprave bar mozes da
pipnes :D )
Thx :-) Sto jes' jes', kad 3d isprintas mozes da pipnes :-) Doduse, razmisljam o malim robotima sa mini-nervnim sistemima (nista fancy, mozda koja desetina hiljada vestackih neurona na nekom malom GPU-u) - pa onda mogu i da budzim nesto :)
[ AMbx @ 15.09.2013. 15:19 ] @
Avast prijavljuje false positive pri instalaciji...
Ma 'oce Dimkovic da ti koristi racunar za kopanje Bitcoina dok ti kao gledas u mozak... :D :D ...ozbiljno, deinstaliraj Avast (i stavi nesto drugo, recimo AVG).
[ Ivan Dimkovic @ 19.09.2013. 19:45 ] @
Prijavicu AVAST ekipi false positive, pa cemo videti..
Elem, posto je Ivy Bridge E/EP sada javno lansiran - evo kako izgleda SpikeFun na trenutno najjacem Ivy Bridge EP Xeonu 2697 v2:
Kao sto vidite, zauzece procesora je 100% sto uopste nije jednostavno izvesti zapravo. Naravno, i sa svih 24 jezgra simulacija od 4 miliona neurona i 800 miliona sinapsi trci u 1/100 realnog vremena (0.011x)
[ bogdan.kecman @ 19.09.2013. 19:52 ] @
okaci negde neki video kako to izgleda real time za nas sa jeftinijim
ulaznicama :D
[ mr. ako @ 20.09.2013. 01:30 ] @
Nije tema, ali kakvi su rezultati sa tom konfiguracijom i Win7, ako si probao?
[ Ivan Dimkovic @ 20.09.2013. 15:08 ] @
Win7 radi isto kao i Win8 - ono sto je bitno je da je 64-bitna verzija.
Razlog je jednostavan - 32-bitne verzije ne mogu da vide vise od 32 logicka procesora, dok u ovom slucaju postoji 48 logickih procesora.
Sve ostalo je manje-vise isto sto se podrske tice. I Win7 i Win8 podrzavaju procesorske grupe (64-bitne verzije), NUMA je podrzana jos od Servera 2003.
[ mr. ako @ 20.09.2013. 19:10 ] @
Da, pretpostavio sam da su oba 64bita... nego sam pomislio da ima bitnijih razlika u performansama cim vozis W8. :)
[ AMbx @ 24.09.2013. 13:41 ] @
GTX650ti i CUDA
[ Ivan Dimkovic @ 25.09.2013. 01:42 ] @
Za vreme simulacije, pritisni 'M' za ukljucenje random aktivnosti na senzornim neuronima, posto bez toga mreza nece biti aktivna.
[ Ivan Dimkovic @ 25.09.2013. 01:44 ] @
Citat:
mr. ako:
Da, pretpostavio sam da su oba 64bita... nego sam pomislio da ima bitnijih razlika u performansama cim vozis W8. :)
Ma jok, jedini razlog zasto teram W8 (zapravo Server 2012 R2) je bolja podrska za multi-monitore. Sve ostalo mi je manje-vise isto ili nesto losije u slucaju W8, kao recimo flat GUI.
W8 je zanimljiviji za laptop masine, zato sto su unapredili kernel (timer coalescing) - za HPC probleme kao sto je DigiCortex, nema nekih bitnih promena.
Simulirano je 0.5 miliona neurona sa oko 100 miliona sinaptickih veza sa DigiCortex 1.01 simulatorom. Neuroni u 4-tom sloju primarnog vizuelnog (V1) korteksa (SS4 tipa) su pobudjeni sa prirodnim signalom koji dolazi iz Virtual Retina simulatora preko dorzalnog talamusa (dLGN):
Projekcije dLGN neurona su retinotopicki mapirane tako da verno prenose sliku sa retine na vizuelni korteks. Takodje, sinapticke veze izmedju dLGN neurona i V1 kortikalnih neurona su plasticne, gde je plasticnost modelirana takozvanim vSTDP algoritmom (voltage-dependent spike-timing dependent plasticity). Ovaj algoritam je vrlo slican standardnom STDP algoritmu, ali dodaje i zavisnost od post-sinapticke voltaze i time jos vernije oslikava plasticnost pravih neurona.
Svaki V1 SS4 neuron prima signal iz 32 dLGN neurona (16 'ON' i 16 'OFF') gde su 'ON' i 'OFF' veze grupisane u dve 4x4 matrice (retinotopicki mapirane).
U pocetku simulacije su jacine sinaptickih veza izmedju dLGN neurona i SS4 V1 neurona slucajne.
E, sad, zanimljiva stvar - bez ikakve spoljne intervencije u toku simulacije kortikalni neuroni u V1 korteksu postaju osetljivi na orijentaciju stimulusa.
To izgleda ovako:
Kao sto vidite, posle odredjenog vremena (1h simulacije u ovom slucaju) dolazi do reorganizacije jacina sinaptickih veza tako da svaki V1 SS4 neuron formira neku svoju "omiljenu" orijentaciju. To znaci da posle formiranja "omiljene" orijentacije taj neuron najvise reaguje upravo na identicnu orijantaciju signala posto ga najvise pobudjuju dLGN neuroni koji odgovaraju tim "pikselima".
Ono sto je zanimljivo - identicne osobine su izmerene u pravim V1 neuronima gde se smenjuju kolone neurona sa razlicitom "omiljenom" orijentacijom. Iz eksperimenata sa zivotinjama je poznato je da se osetljivost neurona na orijentaciju linija formira uz pomoc prirodnog signala na koji je zivotinja izlozena posle otvaranja ociju po rodjenju.
Fenomenoloski iz simulacija poput ove se moze zakljuciti da je vSTDP algoritam plasticnosti dovoljan da objasni ovaj fenomen.
Postavlja se pitanje - da li se ovaj proces nastavlja i posle jednostavnih V1 neurona? Poznato je da, kako se ide dalje propagacijom signala, osetljivost neurona postaje sve kompleksnija da bi, na kraju, neuroni u infero-temporalnom korteksu bili osetljivi na, recimo, odredjene oblike ili cak lica.
[ minddll @ 29.09.2013. 22:19 ] @
Molim vas da podijelite kôd za vSTDP algoritam (kao što ste učinili s FastRand)? Našao sam provedbu obavile Clopath (za NEURON), ali ja ne mogu činiti da se to prevesti na C++ (htjela ga usporediti sa standardnim "najbliži susjed" STDP). :(
[ Ivan Dimkovic @ 29.09.2013. 22:44 ] @
Uh to nece biti tako jednostavno, posto je vSTDP kod prilicno uvezan sa ostatkom simulacije.
Ali probacu da napisem pseudo C++ kod, koji onda mozete integrisati u vas simulator. Postovacu za dan-dva.
[ minddll @ 29.09.2013. 22:55 ] @
Hvala. :) Simulator sama neće biti open source, zar ne?
Albert Einstein's corpus callosum, the bundle of fibers that connects the brain's two hemispheres and facilitates inter-hemispheric communication, was unusually well-connected, according to a new study published in the journal Brain, which suggests that Einstein's high level of cranial connectivity may have contributed to his brilliance.
[ Ivan Dimkovic @ 15.10.2013. 09:50 ] @
@minddll,
Izvini za kasnjenje, evo kako stvari stoje oko vSTDP-a:
vSTDP se sastoji od dve nezavisne komponente: depresije (LTD) i potencijacije (LTP). Obe komponente koriste varijable koje su vezane za post-sinapticki potencijal membrane (neurona ili kompartmenta).
Nazovimo te dve komponente vLTP i vLTD. One se dobijaju low-pass filtriranjem trenutne vrednosti membranskog potencijala post-sinaptickog neurona/kompartmenta.
Dakle, u svakom koraku simulacije (time-stepu) se ove 2 varijable racunaju u momentu kada se izracuna nova vrendost membranskog potencijala:
^ tMinus i tPlus su konstante koje mozete preuzeti iz radova Claudie Clopath.
LTD doprinos se racuna prilikom "dolaska" pre-sinaptickog akcionog potencijala na post-sinapticki sinapticki receptor (sto znaci da se moze procesirati kao 'event' u momentu dostavljanja AP-a na ciljani neuron):
LTD se radi ako i samo ako filtrirani post-sinapticki potencijal (vLtd) jeste veci od thetaMinus konstante za konkretan neuron.
Takodje, u ovom momentu se varijabla X (za svaku sinapsu) uvecava za 1. X predstavlja filtrirani post-sinapticki potencijal koji eksponencijalno opada brzinom tX
//
// w = jacina sinapse
// vLtd = trenutna vrednost filtriranog post-sinaptickog potencijala (u okolini sinaptickog receptora)
// thetaMinus = vSTDP prag za LTD (konstanta)
// aMinus = maksimalna jacina depresije za konkretan post-sinapticki neuron
float ltdFac = vLtd - thetaMinus;
if (ltdFac > 0.0f)
{
//
// Slabljenje sinapticke veze (LTD)
w += aMinus * ltdFac;
}
//
// Uvecati sinapticku varijablu X za 1
// Ako se zeli ograniciti uticaj AP-ova samo na poslednji += treba biti zamenjeno sa =
X += 1.0f;
}
LTP doprinos se racuna prilikom obrade post-sinaptickog potencijala (recimo unutar rutine koja racuna trenutne vrednosti voltaze post-sinaptickog neurona)
LTP se aktivira ako i samo ako su zadovoljena 2 uslova:
- Trenutni membranski potencijal post-sinaptickog neurona je veci od thetaPlus konstante
- Filtirani post-sinapticki potencijal (vLtp) je veci od thetaMinus konstate
Takodje, LTP je zavistan od varijable X, koja predstavlja filtrirani niz akcionih potesnicjala:
if(ltpFac > 0.0f)
{
//
// Pojacavanje sinapticke veze (LTP)
w += aPlus * ltpFac * X;
}
}
Ostaje jos samo jedna stvar: sinapticka varijabla X mora opadati u svakom vremenskom koraku: X -= X / tX
Medjutim, vrlo je neefikasno ovo raditi u svakom vremenskom koraku, posto se ova operacija radi za svaku plasticnu sinapsu.
Ovo je moguce izvesti efikasno tako sto cemo X umanjiti u momentu kada nam vrednost X i treba, i to tako sto ce se X umanjiti za broj proteklih vremenskih koraka: exp(-ts/tX), gde je ts vreme izmedju poslednjeg "osvezavanja" X varijable i trenutnog vremena (delta).
Za ovo je neophodno znati kada je poslednji put X promenjeno, ali ovo obicno nije problem posto se ovaj parametar obicno cuva za svaku sinapsu u simulaciji.
U ovoj varijanti se X "osvezava" pre nego sto mu se doda 1 u LtdUpdate(). Takodje, u LtpUpdate() pre nego sto se vrednost varijable X upotrebi, ona mora biti umanjena za vreme proteklo izmedju trenutnog momenta i poslednjeg osvezavanja koje je izvedeno u LtdUpdate(), posto je moguce da je proteklo vreme od poslednjeg pre-sinaptickog AP-a i momenta kada se radi LTP.
--
Konacno, ovo gore je najjednostavnija implementacija vSTDP-a. Ovu implementaciju je moguce prosiriti sa homeostazom (gde jacina LTD depresije nije konstantna tj. aMinus, vec varijabilna u zavisnosti od prosecne aktivnosti neurona u proteklih N sekundi), renormalizacijom sinaptickih jacina, modulacijom efekta vSTDP-a u zavisnosti od koncentracije dopamina itd...
[ ventura @ 15.10.2013. 12:31 ] @
Ti si baš rešio da mučiš ovoga sa Google Translateom :)
[ Ivan Dimkovic @ 15.10.2013. 14:58 ] @
Heh, uopste nisam ni obratio paznju :)
No dobro, ako ima problema sa translate-om javice se :)
@mr. ako,
Ne bih se nesto previse uzdao u te mere - sumnjam da je na mozgu mrtvom vise decenija moguce utvrditi sta je konkretno bilo odgovorno za genijalnost. Ako malo bolje razmislis, to mi danas ne mozemo da uradimo ni sa zivom osobom a kamo li sa mrtvim mozgom.
Mislim pazi ti ovo:
Citat:
Florida State University evolutionary anthropologist Dean Falk participated in the study led by Weiwei Men of East China Normal University. Falk said this study, more so than any other to date, "really gets 'inside' Einstein's brain."
Ovo ne zvuci nista bolje od nekadasnje frenologije.
A evo i zasto:
1. Kao prvo, analiza povezanosti koju mi danas mozemo da izvodimo je vrlo gruba. Primera radi, jedan voksel DTI ili DSI MRI skena je obicno 1-2 kubna milimetra, i na njemu dobijas neku metriku koja ti ukazuje na prosecnu orijentaciju traktova u tom vokselu. Najbolje metode koje imamo danas mogu da razluce orijentaciju niskog dvocifrenog broja traktova u vokselu (DSI). Problem je sto kroz 1-2 kubna milimetra u ljudsom mozgu prolazi vise desetina hiljada aksonalnih traktova.
Dakle imamo problem a) rezolucije i b) gubitka podataka ako si u regionu gde postoji vise od par ukrstenih traktova
2. Drugo, analiza povezanosti koju dobijas preko DTI/DSI MRI skena ti ne govori nista o mikro-povezanosti. Dobijas samo glavne puteve (traktove) - ali nista time ne saznajes o lokalnoj povezanosti neurona. Ovo moze biti vrlo bitno za performanse, i taj podatak, jednostavno, nemas bez analize elektronskim mikroskopom koja je danas i dalje daleko od nivoa koji bi bio neophodan za katalogizaciju celog mozga. Pricamo o eksabajtima podataka.
3. Trece, cak i da imas super-preciznu mapu povezanosti na makro i mikro nivou, to ti i dalje nista ne govori o funkciji kola, posto funkcija zavisi od efikasnosti receptora, produkcije neuro-transmitera. Za ovo ti je prvo potreban ziv mozak, kao i kompletno mapiranje sinaptickih receptora i aktivacije gena na nivou neurona!!! Evropa je upravo ove godine dodelila jednu milijardu EUR gde je cilj da se u sledecih nekoliko godina, za pocetak, razviju metode za snimanje aktivnosti neurona. IMHO, za jedno 10 godina cemo mozda biti u stanju da prikupimo podatke za vise stotina hiljada neurona istovremeno. I ti podaci ce verovatno zauzimati vise hiljada TB.
4. Konacno, cak i da imamo sve ovo gore ^ mi danas i dalje pojma nemamo o tome kako strukturna i funkcionalna povezanost daju za rezultat svesno ponasanje, jos manje sta cini efikasno ili manje efikasno svesno ponasanje. Bice potrebne decenije da dodjemo do dobre teorije sta neku grupu neurona cini odlicnim "kolom", kako to danas znamo za elektronska kola.
--
Prema tome, uz sve ovo gore, kada neko kaze, citiram, "this study, more so than any other to date, "really gets 'inside' Einstein's brain" - odmah treba da bude jasno da je ili ocigledno u pitanju PR stunt, ili osoba nema pojma o cemu prica.
Na zalost, ali realnost je takva. Sve te price i merenja koju izvode "kognitivni naucnici", "evolutivni antropolozi" su toliko gruba i deficitarna u pogledu saznanja, da ih ja ne vidim nista boljim od frenologije :(
[ Ivan Dimkovic @ 15.10.2013. 15:21 ] @
Konacno, rekao bih nesto i o korpus-kalosumu - godinama je citiran neki rad gde se tvrdi da postoji statisticki znacajna razlika izmedju zena i muskaraca u pogledu debljine korpus-kalosuma, gde se tvrdilo da zene imaju bolju povezanost.
Onda su se na tu tvrdnju nakacili "kognitivni naucnici" koji su u tome videli odgovor na hipotezu da su zene bolje u "multitaskingu" od muskaraca itd...
Na kraju, kada je uradjena studija na vecem uzorku i, jos bitnije, kada je velicina korpus-kalosuma normalizovana tako da se u obzir uzima i zapremina mozga - rezultati su bili da ne postoji statisticki bitna razlika (stavise, u malom broju slucajeva gde je postojala razlika ona je bila u korist muskaraca).
Sta hocu da kazem - nase znanje o vezi izmedju strukture i funkcionalne povezanosti mozga sa jedne strane i svesnog ponasanja sa druge, je i dalje na nedovoljno razvijenom nivou za bilo kakav sud o tome sta, recimo, velcina korpus-kalosuma znaci u pogledu svesnog ponasanja (ako znaci bilo sta, uopste).
Ne mogu a da ne primetim da neke naucne discipline, poput kognitivnih-nauka, recimo. suvise olako izvode zakljucke o necemu o cemu, jednostavno, nemaju dovoljno znanja.
Svedoci smo rapidnog upliva gomile sarenih snimaka i jos sarenijih teorija koje pate od nedostatka naucnog rigora. fMRI je, recimo, postao univerzalna alatka koja se koristi za kreiranje gomile hipoteza koje se granice sa pseudo-naukom. Svako ko zna kolika je latencija fMRI-ja, koliko je niska rezolucija i, konacno, sta fMRI zapravo "meri" ne moze a da se ne zabrine za kredibilitet gomile studija i radova.
Dobro citanje je NeuroSkeptic blog na DiscoverMagazine-u :-)
zbog nase bezbednosti bolje da ipak kazemo da zene imaju ''bolji'' mozak :-)
[ mr. ako @ 16.10.2013. 15:24 ] @
OK, znaci novinarsko poznavanje "nauke"... :) Ocekivao sam da je rezolucija MRI daleko veca.
Nego ono sto sam pitao se odnosilo na tvoj model, tj. sta bi se desilo ako bi ga izmenio tako da leva i desna hemisfera budu bolje povezane kao sto je sugerisano u clanku.
[ Ivan Dimkovic @ 16.10.2013. 18:54 ] @
Povecavanjem trans-kalosalne povezanosti bi dobio vecu korelaciju aktivnosti izmedju leve i desne hemisfere.
Mada, i sa normalnom velicinom korpus-kalosuma je broj konekcija jako veliki - recimo vecina piramidalnih neurona u slojevima 3 i 5 korteksa salju jednu od aksonalnih grana u suportnu hemisferu.
Kakve to konkretne efekte ima u pravom mozgu - to ne znamo.
Imaj u vidu sledecu stvar: odredjen mali % ljudi su rodjeni bez korpus-kalosuma. Takodje, u retkim slucajevima epilepsije koja ne reaguje na lekove se nad pacijentima izvodi intervencija presecanja korpus-kalosuma radi zaustavljanja sirenja epileptogene aktivnosti na zdrave delove mozga.
Fascinantno, efekti na ponasanje i intelekt ljudi su prilicno mali osim ako se ne napravi eksperiment koji eksplicitno "gadja" nedostatak! Tu i tamo se javljaju bizarni efekti kao, recimo, leva ruka zakopcava kosulju dok je desna otkopcava i sl... ali kada se sve uzme u obzir, fantasticno je koliko su mali efekti kada se uzme u obzir da se presecanjem prekida vise stotina miliona nervnih puteva.
Tako da je upitno koliko je debljina korpus-kalosuma presudna na intelekt, mada se to svakako danas ne moze iskljuciti.
------------------------------------------------------------------------
v1.02 - Released on October 13th 2013
------------------------------------------------------------------------
* Fixed a bug where axonal paths for V1 cortico-thalamic and thalamo-
cortical tracts were resolved incorrectly
* Added an option for printing-out currently selected compartment
connectivity statistics ('Y' keyboard key shortcut)
[ Ivan Dimkovic @ 08.11.2013. 20:37 ] @
Dodao sam par dodatnih koraka u vSTDP:
- Reskaliranje ON i OFF sinapsi tako da je ukupna max. ON struja = max. OFF struja
- Dodatnu homeostaticku regulaciju jacine sinapsi koja je vezana za frekvenciju spajkovanja neurona
Pre ove 2 korekcije, distribucija V1 receptive-field orijentacija je bila prilicno nagnuta ka jednoj orijentaciji (dijagonalnoj).
Sada je distribucija ravnomernija (videti sliku dole, slika je formirana tako sto je svaki piksel kodirana jacina ON i OFF sinapsi koje pripadaju istom "pikselu" retine). Inace, homeostaticka kontrola jacine sinapsi je eksperimentalno potvrdjena - medjutim jos nemamo kompletan model koji oslikava to homeostaticku kontrolu, ali je poznato dosta osobina homeostatickog skaliranja.
Slika dole je formirana posle ~1h (simulacionog) vremena, pustajuci 1000 FPS video snimljen "cat cam-om" (pogled iz macije perspektive - http://www.koerding.com/experiments.html):
[ Ivan Dimkovic @ 15.11.2013. 12:59 ] @
Implementirao sam metodu homeostatickog sinaptickog skaliranja iz [1] koja je vrlo dobra u smislu da stabilizuje RF-ove V1 neurona i, takodje, ubrzava ucenje tako da stabilni RF-ovi nastaju vec posle ~10-20 minuta simulacije. Formirani RF-ovi su stabilni koliko vidim - tj. nisu se promenili bitno posle ~4h simulacije. Naravno, u slucaju zivih organizama ucenje je sporije, ali se to moze lako postici tj. usporiti jednostavnim skaliranjem parametara vSTDP-a.
Novi SpikeFun ce izaci cim zavrsim GPU optimizacije za sinapticko skaliranje i dodam opcije za podesavanje (ovo ce mozda malo potrajati posto sam trenutno prilicno zauzet sa drugim projektom).
Za sada je kontrola sprovedena kroz ciljanu prosecnu frekvenciju neurona (tako da se sinapse skaliraju "na gore" ako neuron opaljuje manje od ciljane frekvencije ili "na dole" u obrnutom slucaju).
Medjutim, meni se ne svidja ta ideja kontrole kroz fiksiranu ciljanu frekvenciju post-sinaptickog neurona previse, posto smatram da prosecna frekvencija moze varirati na osnovu individualnih fizioloskih karakteristika tj. da nije pozeljno imati hardcode-ovanu frekvenciju po tipu neurona zbog individualnih varijacija. Vec imam situacije gde ovaj algoritam neuspesno pokusava skalirati sinapticke jacine do maksimuma a prosecna frekvencija nije u stanju da se popne do cilja zato sto ulaz, jednostavno, nije dovoljno cest.
Alternativa je homeostaticka kontrola na osnovu maksimizacije transfera informacija izmedju pre-sinaptickog signala i ciljanog neurona [2]. Probacu da implementiram i ovu metodu, pa cemo videti kako izgleda.
Kad ovo zavrsim, model V1 korteksa je manje-vise gotov, i onda prelazim na dalje module kao i motorne reakcije (pokrete ociju tj. kamere) kroz superiorni kolikulus (ciji model jos nije implementiran u SpikeFun-u).
[2] - Stemmler, Martin, and Christof Koch. "How voltage-dependent conductances can adapt to maximize the information encoded by neuronal firing rate." Nature neuroscience 2.6 (1999): 521-527 -- http://papers.klab.caltech.edu/202/1/130.pdf
[ Ivan Dimkovic @ 15.11.2013. 20:12 ] @
Btw, kad smo vec kod sinaptickog skaliranja, skoro je objavljen vrlo zanimljiv rad:
Memory storage in the brain relies on mechanisms acting on time scales from minutes, for long-term synaptic potentiation,
to days, for memory consolidation. During such processes, neural circuits distinguish synapses relevant for forming a longterm storage, which are consolidated, from synapses of short-term storage, which fade. How time scale integration and
synaptic differentiation is simultaneously achieved remains unclear. Here we show that synaptic scaling – a slow process
usually associated with the maintenance of activity homeostasis – combined with synaptic plasticity may simultaneously
achieve both, thereby providing a natural separation of short- from long-term storage. The interaction between plasticity
and scaling provides also an explanation for an established paradox where memory consolidation critically depends on the
exact order of learning and recall. These results indicate that scaling may be fundamental for stabilizing memories,
providing a dynamic link between early and late memory formation processes.
------------------------------------------------------------------------
v1.03 - Released on November 24th 2013
------------------------------------------------------------------------
* Added metaplasticity (STDP homeostatic control) based on average
and target firing rates. It is possible to set the desired target
firing rate for each extended neuron type with the following param:
<MetaTargetFiringRate> (e.g. see NeuronLibrary/p2.xml) and the vSTDP
will attempt to reach this target rate by rescaling synaptic weights
in a way that preserves individual ratios between synapses.
NOTE: Metaplasticity is currently implemented for CUDA simulations
only. It will be enabled in CPU simulations with the next release
* Added extended information related to pre-synaptic connections that
can be displayed in the console by pressing 'Y' keyboard button
(requires that neuron is picked in the OpenGL simulation)
* Improved receptive-field formation using vSTDP with retinal
simulations. NOTE: For camera (live) based simulations, strenght
(gmax) of the LGN synapse must be set at ~45.0 or higher as retinal
live simulation is not step-locked with the thalamocortical simulation
and typically runs slower (so LGN neurons get retinal spikes every
other time step). For file-based (or RGC dump) based retinal
simulations, retinal synapse maximum strenght should be set at 21.0
This yields typical firing rates of ~2 Hz for LGN TC neurons (as
opposed to ~7 Hz average firing rate for RGC cells)
See: NeuronLibrary/SynapseLibrary.xml <gmax> value for retinal
synapse.
A pa to nije nikakav problem - SpikeFun i ovako i onako gradi kortikalnu mrezu na osnovu MRI i dMRI snimaka.
SpikeFun trenutno koristi HCP_003 datased od Human Connectome Project-a, koliko se secam u pitanju je snimak pacijenta muskog pola.
U jednoj od buducih verzija cu dodati mogucnost da se slobodno ucitava bilo koji adekvatno procesirani MRI+dMRI snimak, pa nece biti problem izabrati muski/zenski pol.
Sto se samog istrazivanja tice - nije lose primiti to sa zdravom dozom skepticizma, evo malo stvari o kojima treba razmisliti:
Hvala vam puno, Ivan. Još jedno pitanje - može li reći gdje da se upoznaju kodiranja geometriji dendrita i aksona smjernice? Napisao sam simulator pomoću AdEx neurona i (zahvaljujući vaše objašnjenje) vSTDP ali ja bih pokušati simulirati pojednostavljenom kortikalni koloni sa svim različitim neuronskih vrste (piramidalni, basket, itd) i ne-trivijalne povezivanja.
Imate sve to radno, možda neke savjete za početnika? :)
Luckey, 21, originally planned to make a small number of kits for enthusiasts using mobile components. But his project blew up when John Carmack, cofounder of id Software and lead programmer of Doom and Quake (and now Oculus VR's chief technical officer), heard about the Rift and requested a prototype. There are now around 40,000 Oculus headsets with developers worldwide, and they are finding creative uses for it. Disunion is a game whose players experience a virtual death by guillotine; Digicortex is a neural-network simulator which now has an Oculus mode, letting players enter the world of brain simulation. Non-gaming uses include architectural visualisation and medical and military training, such as Bossa Studios' Surgeon Simulator.
------------------------------------------------------------------------
v1.04 - Released on March 9th 2014
------------------------------------------------------------------------
* Extended capabilities of the RPC server required for upcoming SDK
release
* Fixed OpenGL rendering issues with 33x NVIDIA drivers
* Limited maximum tract length in order to eliminate non-anatomic
DSI tracts
* Improved brain diffusion source data (improved eddy current removal
and motion correction), resulting in more precise tract mapping to
the cortical areas
Sa verzijom 1.05 je izbacen prvi software development kit (SDK). Mozete ga naci u /SDK folderu unutar instalacije. SDK trenutno radi sa x64 CPU simulacijama (CUDA simulacije nisu trenutno podrzane, ali ce biti u sledecoj verziji).
Citat:
First SDK release also contains neuron_query C++ example showing the following capabilities (currently, the only exposed APIs so far):
- Searching for and obtaining the list of pyramidal neurons of layer V, located in cuneus and pericalcarine regions
- Creating a mapped neuron buffer containing above neurons, which is used for further operations
- Injecting current (1 nA) in the somatic compartment of the first neuron in the buffer
- Updating mapped neuron buffer with the latest information from the simulation
- Waiting for the asynchronous update to complete
- Showing membrane voltages and spike information of the first 10 neurons in the buffer
To build neuron_query example, Visual Studio 2012 (or later) is needed. SDK requires x64 platform and compilers. After the build is complete, neuron_query64.exe should be copied to the folder where the DigiCortex engine binaries reside and executed after start of the simulation.
If everything is executed well, the output of neuron_query64.exe should look similar to this:
Code:
Number of p5(l5/6) neurons found in PERICALCARINE and CUNEUS regions: 70
Successfully mapped 70 neurons
Neuron 0 (real idx: 33576): Vsoma=-59.877 mv, spikes: 188, last spike ts: 39504
Neuron 1 (real idx: 33676): Vsoma=-74.762 mv, spikes: 0, last spike ts: 0
Neuron 2 (real idx: 52858): Vsoma=-74.741 mv, spikes: 0, last spike ts: 0
Neuron 3 (real idx: 52977): Vsoma=-74.743 mv, spikes: 0, last spike ts: 0
Neuron 4 (real idx: 52989): Vsoma=-74.742 mv, spikes: 0, last spike ts: 0
Neuron 5 (real idx: 53002): Vsoma=-74.741 mv, spikes: 0, last spike ts: 0
Neuron 6 (real idx: 53023): Vsoma=-74.742 mv, spikes: 0, last spike ts: 0
Neuron 7 (real idx: 53091): Vsoma=-74.743 mv, spikes: 0, last spike ts: 0
Neuron 8 (real idx: 53097): Vsoma=-74.742 mv, spikes: 0, last spike ts: 0
Neuron 9 (real idx: 53143): Vsoma=-74.742 mv, spikes: 0, last spike ts: 0
[ Shadowed @ 17.03.2014. 19:30 ] @
Aj' daj i neki .NET wrapper :)
[ Ivan Dimkovic @ 17.03.2014. 20:34 ] @
VB.NET ili nesto drugo? :-)
[ minddll @ 17.03.2014. 20:38 ] @
Izvorni kod! ^_^
Ozbiljno, to je super.
[ Shadowed @ 17.03.2014. 20:49 ] @
Citat:
Ivan Dimkovic:
VB.NET ili nesto drugo? :-)
Sve jedno, kad kompajliras, koristi se iz bilo kog .net jezika :)
[ Ivan Dimkovic @ 18.03.2014. 10:09 ] @
Interesantna slika: trenutno testiram dugotrajan efekat izlaganja vizuelnog korteksa signalu iz oka.
Ako pogledate simulirani EEG videcete da primarni vizuelni korteks (pericalcarine) ima oscilacije u gama opsegu (sto je konzistentno sa pravim mozgom, gama talasi su prisutni prilikom koncentracije i aktivnog pretrazivanja prostora).
Takodje, gama aktivnost se prenosi na desni superiorni frontalni korteks.
Medjutim, temporalni korteks (kao i parahipokampalni) su u debelom s*anju tj. sa jakim oscilacijama u delta i slow rezimu, slicnom epilepticnom napadu.
Interesantno je da i u bioloskim mozgovima, veliki % epilepticnih napada pocinje u temporalnom korteksu i zahvata parahipokampalni region.
Jako je tesko kontrolisati ponasanje neurona u ovom regionu - epilepticna aktivnost nastaje i posle 30% smanjenja jacine NMDA i AMPA receptora.
------------------------------------------------------------------------
v1.06 - Released on April 16th 2014
------------------------------------------------------------------------
* New longe-range axonal connectivity data based on MGH Human
Connectome Project Data: Gmax=300 mT/m, bmax=10000 s/mm2, res 1.5mm
iso - in the upcoming versions of DigiCortex, we will perform
further improvements of tractography and elimination of false tracts
* Reduced GPU memory load for tractography visualization ("box" mode)
v1.06 dolazi sa novim MRI podacima koji sluze kao osnova za "izgradnju" mozga.
Radi se o novim snimcima Siemens Connectom skenera koji je trenutno najprecizniji instrument za mapiranje konekcija unutar ljudskog mozga. Siemens Connectom skener je specijalno dizajniran za Diffusion MRI snimke i za ovu svrhu ima 8x jace polje od klinickih skenera. Za postizanje do sada nevidjene rezolucije ovaj skener zahteva 24 megavata (uporedivo sa nuklearnom podmornicom).
Novi snimci koje DigiCortex koristi za konstrukciju talamo-kortikalnog modela su izuzetno visoke rezolucije: vokseli su 1.5mm^3 (tipicni klinicki dMRI snimci su rezolucije 2.5-3mm^3). Jos jedan bitan parametar za rekonstrukciju aksonalnih puteva je broj direkcionih snimaka. Tipican klinicki dMRI pregled se sastoji od 6-32 snimaka. DigiCortex koristi HCP dataset od 515 direkcionih snimaka. Drasticno veca kolicina snimaka omogucava rekonstrukciju visestrukih aksonalnih puteva unutar voksela, dok tipicni klincki dMRI pregledi nisu u stanju da razluce vise od 1 dominantnog smera, MGH HCP nema ogranicenje i u stanju je da detektuje visestruke smerove unutar voksela.
Osim drasticno vece kolicine direkcionih snimaka, MGH HCP podaci koriste osetljivost do 10000 s/mm^-2 (klinicki dMRI: bmax=1000 s/mm^-2). Na "obicnim" klinickim MRI skenerima bi snimanje sa ovolikom osetljivoscu bilo besmisleno zato sto bi SNR bio neupotrebljiv. Siemens Connectom skener omogucava ovoliku osetljivost zahvaljujuci skoro 8x jacem polju (Gmax = 300 mT/m, klinicki MRI skeneri: Gmax = 40 mT/m)
Evo kako izgleda rekonstrukcija traktova srednjeg temporalnog reznja:
Glavna razlika izmedju Connectom snimaka i tipicnih klinickih dMRI snimaka je u rezoluciji (sa klinickim dMRI snimcima je obicno samo moguce rekonstruisati glavne traktove, dok sa Connectom snimcima je moguce rekonstruisati i sporedne traktove, ukljucujici i male traktove "U" oblika duzine 10-15mm), kao i u mogucnosti rekonstrukcije ukrstenih i savijenih traktova (semiovalni centar, npr. sadrzi "raskrsnicu" 3 glavna trakta. "Obicni" klinicki dMRI snimci nisu u stanju da razluce vise od jednog trakta i ukrstanje "vide" samo kao pad difuznosti).
Evo kako rekonstruisani sistem izgleda u DigiCortex-u:
[ mr. ako @ 22.04.2014. 04:37 ] @
Posto si rekao da ces ubaciti posebne modele za muski i zenski mozak, izgleda da ces morati i za "umetnicki". :)
Artists 'have structurally different brains'
Citat:
Artists have structurally different brains compared with non-artists, a study has found.
Participants' brain scans revealed that artists had increased neural matter in areas relating to fine motor movements and visual imagery.
The research, published in NeuroImage, suggests that an artist's talent could be innate.
But training and environmental upbringing also play crucial roles in their ability, the authors report.
Btw, trenutni mozak je zenski (ovaj novi od pre par nedelja) :-)
Te razlike koje nalaze mozda nastaju genetski a mozda i u vreme ranog detinjstva. Medjutim ja bih sacekao jos sa proglasavanjem specificnih razlika za odgovorne za umetnicki dar dok se ne izvrsi jos puno studija koje potvrdjuju rezultat. Studija koja je linkovana je radjena na 44 osobe. IMHO, to je suvise mali uzorak za generalizovanje, ali rezultati svakako zavredjuju dalje istrazivanje. Dodatni hendikep je trenutno ogranicenje metoda za snimanje. Doduse, ako BRAIN inicijativa u USA urodi plodom, za 10 godina cemo imati drasticno bolje mogucnosti za snimanje i pracenje aktivnosti u mozgu.
Btw,
Napravio sam novi kratak video: kompletan rani vizuelni sistem (Retina -> dLGN <-> vLGN <-> V1 -> ...):
- 4 milijarde sinapsi
- 16.7 miliona neurona (talamus + korteks)
- 153 hiljade retinalnih ganglionskih celija u 2 sloja (efektivna rezolucija: 320x240 piksela, "ON" i "OFF" sloj)
- 38 hiljada relejnih neurona u vizuelnom talamusu isto 2 sloja (efektivna rezolucija: 160x120 piksela, "ON" i "OFF" slojevi)
- Oko 400 hiljada senzornih neurona u primarnom (V1) vizuelnom korteksu (spiny-stellate i piramidalne celije u kortikalnim slojevima 2/3 i 4)
- Na jedan relejni neuron u talamusu dolazi 10 senzornih neurona u vizuelnom korteksu
- Signal dalje posle V1 korteksa ide ka visim centrima, na osnovu traktografije (podaci iz Human Connectome Projekta)
- Cela simulacija zahteva oko 500 GB RAM-a (496 GB, da budemo precizniji :-)
Na kraju to izgleda ovako:
^ Vizuelnim korteksom dominiraju talasi u "alfa" i "gama" frekventnom opsegu. Alfa talasi se vide na videu kao "prelivanje".
Evo kako to izgleda na "pravom" mozgu (doduse slika dole ukljucuje i zone izvan V1):
------------------------------------------------------------------------
v1.07 - Released on April 27th 2014
------------------------------------------------------------------------
* Compiled with CUDA 6 SDK. CUDA simulations now require CUDA 6
capable drivers / hardware.
* Added ability to configure multiple STDP parameters for each base
cell morphology (NeuronLibrary/BaseNeuronTypes.xml). STDP parameters
can be configured independently for each post-synaptic target cell
type.
For example, see configuration for SS4 cell, which has "regular"
STDP curves with all cells except with the SS4/P4 cells where
STDP curves are "inverted" in order to help decorrelate the input
sensory input.
STDP parameters that can be individually configured are:
Other STDP parameters (theta+/-, T+/-) are fixed per base cell type
since they are dependent on post-synaptic compartment's configuration
* Added ability to define a "black list" of neuron types for each
target post-synaptic neuron type. Neuron types in the "black list"
will be forbidden from forming synaptic connection with the neuron
* Fixed STDP-homeostasis control so that the homeostasis-control factor
is inverted for inhibitory synapses as well as synapses with inverted
STDP curves.
* Changed the circuit-building strategy so that it attempts to maintain
the ratio between inhibitory and excitatory cell types even if the
proximity rules would bias in favor of excitatory cells (typical for
simulations with low neuron density)
Phineas Gage je, verovatno, najcuveniji neuroloski pacijent u istoriji.
Njegova nesreca i povreda koja je rezultovala od incidenta sa barutom su rezultovali u prosirivanju vidika medicine.
Za neupucene i one koje mrzi da citaju: Gage je bio zaduzen za ubacivanje baruta izmedju kamenja, koristeci sipku za "sabijanje" baruta. Health & Safety propisi nisu bili u modi u to vreme, doslo je do eksplozije i sipka od ~3 cm debljine i ~20-tak cm duzine je izletela iz procepa i proletela pravo kroz Mr. Gage-ovu glavu, kroz vilicu, iza oka i kroz prednji deo lobanje. Udarac je bio toliko jak da je Mr. Gage bio odbacen nekoliko metara iza, a sipka je kompletno probusila njegovu lobanju i na njoj je, ocigledno, ostalo dosta mozdanog tkiva (o krvi i da ne pricamo).
Povreda je izgledala monstruozno, i niko nije ocekivao da ce Mr. Gage preziveti. Doktor koji je prvi dosao na lice mesta je napisao da je scena izgledala kao vojna bolnica od kolicine krvi.
Medjutim, desila se sreca i Mr. Gage se potpuno oporavio bez skoro ikakvih posledica (osim izgubljenog oka iza koga je prosla sipka)
Tako je bar izgledalo na prvi pogled.
Posledice na Mr. Gage-a su bile daleko suptilnije: doslo je do kompletne promene njegovog karaktera. Mr. Gage je od odlicnog radnika postao nepristojna pijandura i prostak, bez ikakvog morala. To je kompletno urnisalo njegov zivot.
Njegova povreda je omogucila medicini da sazna da je prednji deo mozga, na prvi pogled ne-kritican za osnovne svesne operacije, kritican za stvari koje nas cine ljudima. Slucaj Mr. Gage-a je otvorio citavo novo poglavlje razumevanja mozdanih funkcija koje ce kulminirati u modelima funkcionisanja tzv. "izvrsnih" reznjeva u sivoj masi koji su skoncentrisani u prednjem delu glave.
Pre nekoliko meseci je Jack Van Horn sa USC-a (inace ukljucen u Human Connectome Project, podatke koje SpikeFun koristi za rekonstrukciju traktova) uspeo da modelira povredu na osnovu analize lobanje i "fit-ovanja" template mozga unutar Mr. Gage-ove lobanje.
Slika koju je mr.ako okacio pokazuje verovatne puteve bele mase koji su najverovatnije bili osteceni sa sipkom koja je Mr. Gage-u promenila kompletan zivot.
Radnja fabule? Sitnica, operacija na mozgu (vadnjenje tumora) dok je pacijent ziv i svestan okruzenja oko sebe i u stanju je da odgovara na pitanja.
Odstranjeni tumor je prikazan na 8:25. Pacijent je sve vreme pricao sa bolnickim personalom koji se stara o njegovoj operaciji. Mozete i videti kako hirurg testira da li motorne funkcije i dalje funkcionisu.
[ Shadowed @ 15.05.2014. 07:31 ] @
Citat:
Ivan Dimkovic: dok je pacijent ziv i svestan okruzenja oko sebe i u stanju je da odgovara na pitanja.
Hteo si reci budan? Da nije ziv, ne bi se ni cimali da vade tumor
------------------------------------------------------------------------
v1.09 - Released on May 21st 2014
------------------------------------------------------------------------
* Added support for Adaptive Exponential Integrate and Fire neuron
model in CUDA simulations (for configuring AdEx neurons please
replace BaseNeuronParams.xml with BaseNeuronParams.axex)
NOTE: Current CUDA implementation causes huge warp divergence when
simulation contains both AdEx and Izhikevich-type neurons. This
results in decrease in performance. This problem will be solved
in future version of DigiCortex.
* Added option for limiting maximum allowed axonal delay (in msec):
MaxAxonalDelay (in AxonalParams section)
Radnja fabule? Sitnica, operacija na mozgu (vadnjenje tumora) dok je pacijent ziv i svestan okruzenja oko sebe i u stanju je da odgovara na pitanja.
Odstranjeni tumor je prikazan na 8:25. Pacijent je sve vreme pricao sa bolnickim personalom koji se stara o njegovoj operaciji. Mozete i videti kako hirurg testira da li motorne funkcije i dalje funkcionisu.
Uh, vec par dana se teram, al' nikako da pogledam video... nisam imao stomak za to ovih dana. Danas se naterao. :) Sve pohvale i za Charlesa i za doktore, jedva sam pogledao sve. :D Ali me, jos taj dan kad si ostavio link, nista nije sprecilo da se setim one scene i Hannibal Lectera. O.O
Kad vec prljamo temu, evo jos jedan interesantan link:
Researcher controls colleague’s motions in 1st human brain-to-brain interface
Citat:
University of Washington researchers have performed what they believe is the first noninvasive human-to-human brain interface, with one researcher able to send a brain signal via the Internet to control the hand motions of a fellow researcher.
A photo showing both sides of the demonstration.
Using electrical brain recordings and a form of magnetic stimulation
Razlog je sto nisam imao vremena u proteklih par meseci.
Sledeci korak je kompletno iznova raspisan "runtime" koji izvrsava simulaciju.
Novi runtime (codename: neutrino) ce biti kompletno raspisan od nule sa fokusom na multi-GPU i cluster simulaciju i model vizuelnog korteksa tacnije ventralni "stream" koji kod zivotinja i ljudi sluzi za identifikaciju objekata (sa nekolicinom koraka: Retina -> LGN -> V1 -> V4 -> IT).
Takodje, neutrino ce biti potpuno nezavistan i u njega ce moci da se "ucita" bilo kakva simulacija, proizvoljne geometrije i organizacije mreze. Cilj je da na tipicnom racunaru (nodu) moze da se simulira bar nekoliko miliona neurona u realnom vremenu.
Bice par malih izmena u SpikeFun-u dok ne proradi neutrino engine, a onda ce neutrino biti "ubacen" i u DigiCortex.
[ Odin D. @ 08.08.2014. 22:13 ] @
Možda da prebaciš to na ovu novu IBM-ovu platformu :)
Problem sa silikonskim resenjima je sto su suvise ogranicena u smislu kastomizacije.
U ovom momentu jos i dalje ne znamo koji je nivo "detalja" neophodan za replikaciju inteligentnog ponasanja, pa je prednost imati mogucnost dodavanja / oduzimanja detalja po potrebi.
Hardverska (IC) resenja moraju "zamrznuti" dosta parametara, pa ako ti treba vise od toga, moras da przis novi cip.
------------------------------------------------------------------------
v1.10 - Released on November 10th 2014
------------------------------------------------------------------------
* Added support for Intel(R) Crystalwell architecture for performance
benchmarks / measusrement (-pmu command line switch)
* Added support for Intel(R) Haswell-EP/EX (Xeon E5-2600/4600 v3) CPUs
benchmarks / measusrement (-pmu command line switch)
* Rendering fixes for NVIDIA drivers 33x, removing OpenGL warnings
Dodata je performance-monitoring podrska za Haswell EP/EX procesore, kao i za Crystalwell procesore (sorry, ovo sam trebao ranije da odradim...).
SpikFun na dual Xeon E5 2697 v3 sistemu (28 jezgara):
------------------------------------------------------------------------
v1.11 - Released on December 3rd 2014
------------------------------------------------------------------------
* Initial support for Oculus Rift DK2 devices (-oculus command line)
Uspeo sam da se dokopam jednog Oculus DK2 prototipa, pa sam patch-ovao kod za podrsku tako da sada radi i sa DK2.
Na zalost, nisam jos stigao da integrisem najnoviji Oculus SDK (0.4.3), posto je dosta promenjena interna struktura i klase koje sam koristio iz 0.2.x verzije nisu vise iste pa cu morati malo vise vremena da utrosim kako bih adaptirao kod da radi sa 0.4.3 SDK-om. Do tada sam samo hardcode-ovao DK2 detekciju i parametre, mada koliko vidim i "zvanican" 0.4.x kod trenutno nije nista bolji, tako da ce biti potrebno ponovo patch-ovati kod kad izadje komercijalna verzija.
Trenutno sa DK2 radi samo render (koji je FHD sad). Kontroler jos nije podrzan, posto stari SDK ne detektuje DK2 kontroler :(
[ Ivan Dimkovic @ 17.12.2014. 23:09 ] @
Novi hardver stize, za mali kucni superracunar...
Ovo je prvi batch: 8 komada Xeon Phi kartica, svaka ima 57 procesora, svaki procesor ima AVX512 engine sa kojim moze da procesira 16 float-ova odjednom.
Drugi batch ce isto biti 8 komada kartica, tako da ce konacan rezultat biti:
- 16 Xeon Phi kartica (bice ustekane u 4 blade-a servera gde svaki blade "puni" 4 kartice a izmedju blade-va ce biti 10gBE mreza za razmenu poadataka)
- Jacina: 57 procesora x 16 kartica = ~32 TFLOPS-a (za 32-bitne float operacije).
Jedini je zez ohladiti ovo... svaka kartica ima 270W TDP i napravljena je za pasivno hladjenje. Radim na custom soluciji koja ce da ih hladi.
[ plague @ 18.12.2014. 00:24 ] @
Zar jos nisi dosao do trenutka gde je isplativije iznajmiti racunare da odrade posao?
Ne znam da li mozda ima veze sa konkretnim optimizacijama koje pises za hardware?
[ Shadowed @ 18.12.2014. 00:48 ] @
Ali to onda nece biti mali kucni superracunar :)
[ Tyler Durden @ 18.12.2014. 10:52 ] @
^lol, bice da je to u pitanju.
koliko kosta to zadovoljstvo dimkovicu? i je l' ces koristiti samo za spikefun?
[ bogdan.kecman @ 18.12.2014. 11:14 ] @
uh bre treba da ohladis 5kW a te kartice su sve pasivnjaci ... uzmes jednu 24000btu inverter klimu (800-1000eur ovde, ne znam koliko kostaju tu kod tebe) i resis problem .. to ti je taman to sto ti treba, samo napravis custom rack, napravi da mozes i da vrtis lokalni vazduh (rek da ti bude zatvoren sistem) i da mozes da upucavas kroz klimu sa jedne strane vazduh u rek a onda sa druge strane da ga pumpas napolje .. i jedna i druga varijanta mogu da budu korisne zavisno od konfiguracije reka i prostorije gde je rek ... ako se dobro secam te toplotne matematike 24000btu moze da ohladi oko 6kW
[ the_tosic @ 18.12.2014. 14:51 ] @
Citat:
Tyler Durden:
^lol, bice da je to u pitanju.
koliko kosta to zadovoljstvo dimkovicu? i je l' ces koristiti samo za spikefun?
E bile su skoro na popustu ove kartice ~200$ komad. Ako nadjem link okacicu :)
[ ventura @ 18.12.2014. 14:57 ] @
Dimkoviću tebi bi bilo bolje da se navučeš na kokain ko sav normalan svet, a i jeftinije je ;)
[ brainbuger @ 18.12.2014. 17:08 ] @
Nice beast.
Nego, čudno je da si odlučio da ideš na multiple CPU varijantu, zar ne beše multiple GPU bolji za paralelizam (a valjda i ekonomičniji)?
[ Ivan Dimkovic @ 18.12.2014. 20:44 ] @
Citat:
plague
Zar jos nisi dosao do trenutka gde je isplativije iznajmiti racunare da odrade posao?
Ne znam da li mozda ima veze sa konkretnim optimizacijama koje pises za hardware?
Nisam skoro pravio racunicu oko toga. Poslednji put kada sam gledao, to sto je moglo da se iznajmi mi nije odgovaralo.
Takodje, ove Intel kartice sam kupio po izuzetno niskoj ceni oko $110 po kartici :)
Citat:
Tyler Durden
^lol, bice da je to u pitanju.
koliko kosta to zadovoljstvo dimkovicu? i je l' ces koristiti samo za spikefun?
Imam par ideja koje hocu da provrtim, videcemo kako ce da rade.
Citat:
the_tosic
E bile su skoro na popustu ove kartice ~200$ komad. Ako nadjem link okacicu :)
16 Xeon Phi kartica ce me izaci negde oko $1800, sto je neverovatno dobra cena - pre samo par meseci je toliko kostala jedna.
Trenutno su na zescem popustu, Intel ih trenutno valja prakticno po proizvodnoj ceni.
Pretpostavljam da su ovo Xeon Phi kartice koje su Kinezi koristili u onom njihovom Tianhe-2 superracunaru tj. verovatno sada rade upgrade na Knights Landing. Kada su Kinezi pravili Tianhe-2 pre par godina, suskalo se da im je Intel valjao Xeon Phi kartice po proizvodnoj ceni.
Citat:
brainbuger
Nice beast.
Nego, čudno je da si odlučio da ideš na multiple CPU varijantu, zar ne beše multiple GPU bolji za paralelizam (a valjda i ekonomičniji)?
Xeon Phi arhitektura nije previse drugacija od GPGPU-ova sto se programiranja tice.
A uzeo sam ih zbog popusta, prakticno po ceni 2 TITAN kartice imam 16 Phi-jeva...
@bogdan.kecman,
Ha, dobra ideja - nisam uopste razmisljao o klimi, prva ideja mi je bila hrpa high-RPM ventilatora.
Inace, da, kartice su bitch za hladjenje... kako sam i ocekivao. Jedan mid-RPM ventilator po kartici nije dovoljan tj. radna temperatura brzo predje 100 C. Doduse, to je bio brzi budz-test, bez materijala koji bi vazduh usmeravao kako treba. Videcu da napravim mali proof-of-concept plasticni vod, pa bi sa jednim high-rpm 80mm ventilatorom mogao da hladim 2 Phi kartice.
@Ventura, dop je jos jeftiniji :-)
[ Space Beer @ 19.12.2014. 17:56 ] @
Citat:
Ivan Dimkovic:
Xeon Phi arhitektura nije previse drugacija od GPGPU-ova sto se programiranja tice
Da, ali zar nisi ti koristio CUDA kada si počeo sa GPGPU-om? Da li to znači da prelaziš na OpenCL? Ili nešto drugo?
[ Ivan Dimkovic @ 19.12.2014. 21:00 ] @
Nisam jos 100% siguran, OpenCL je na papiru fino resenje posto bar u teoriji znaci da bi kerneli mogli da rade i na NVIDIA, AMD i Intel hardveru ali nisam siguran da se tako dobija optimalan kod za Phi platformu, a za NVIDIA kartice je CUDA kod brzi.
Phi podrzava i druge nacine programiranja, od MPI-ja preko OPENMP-a, Intel-ovih biblioteka (TBB i sl.), Intel-ovih ekstenzija (Cilk) pa sve do low-level pthreads-a sa intrinsic-ima.
Trenutno se dvoumim izmedju OpenCL-a i low-level (pthreads) varijanti.
[ Shadowed @ 19.12.2014. 22:35 ] @
Ima li toga u slobodnoj prodaji (po toj ceni?) ili to nabavljas preko svojih masonskih veza?
[ Ivan Dimkovic @ 19.12.2014. 23:24 ] @
Ja sam kupio u potpuno slobodnoj prodaji, da sam jurio preko veze verovatno ne bih morao da ih platim ista :)
[ mr. ako @ 20.12.2014. 04:54 ] @
Sto se tice hladjenja grafika, pogledaj po forumima gde se skuplja Bitcoin masa, oni su to doktorirali... :)
Hehe, hvala @mr.ako, vidim da su definitivno doktorirali :-)
Za sada, dok testiram jednu karticu, privremeno radi posao jedan high-RPM 120mm ventilator koga sam se dokopao (Noctua NF-F12 IndustrialPPC) koji je nabijen "tik" do kartice na izlazu sa duct-tapeom. Radna temperatura je oko 100C sto je podnosljivo za testiranje.
Trenutno pisem mali OpenCL test kod da vidim kako izgledaju OpenCL performanse, ako su razumne mozda ostanem na OpenCL-u koji ima prednost da moze da trci na raznim platformama i sa par tweak-ova velicine work-itema i sl. koliko vidim u teoriji moze raditi "OK" na raznim platformama.
Phi ima sirok vektorski engine, koji moze odjednom da procesira 16 float-ova - sa OpenCL kodom prakticno paralelelnost mozes postici jednostavno (samo lansiras kernel sa gomilom podataka) ali je onda pitanje koliko je OpenCL drajver u stanju da to efikasno iskompajlira - koliko vidim, neki po forumima nisu bas preterano zadovoljni Phi performansama.
Ako su performanse lose, probacu native, dakle rucno lansiranje par stotina thread-ova (koristeci pthread) i rucno vektorizovani kod. Pretpostavljam da tu mogu da koristim vec postojeci x86 kod kao startnu poziciju, ali sumnjam da bez debelih optimizacija za Phi mogu da se postignu razumne performanse.
U slucaju da OpenCL zakaze a native opcija trazi previse posla, kartice idu na ebay :)
[ Ivan Dimkovic @ 21.12.2014. 20:38 ] @
Danas sam konacno nasao vremena da malo eksperimentisem...
Portovao sam najtezi CUDA kernel iz DigiCortex-a (racunanje membranskog potencijala i procesiranje "opaljivanja") na OpenCL, i onda sam provrteo kernel sa "test" workload-om: 5 miliona elemenata (compartment-a) i 1000 vremenskih koraka (1 sekunda simulacije).
Ideja je da se izmere performanse "grubo" - bez ikakvih optimizacija osim onoga sto kompajler moze da uradi.
Dakle, na test kodu, bez ikakvih optimizacija, jedan Xeon Phi je oko 3 puta brzi od 28 Haswell jezgara - sto se verovatno moze zahvaliti brzini memorije, posto je test kernel limitiran brzinom memorije. Xeon Phi ima GDDR5 memoriju brzine 320 GB/s.
Sa druge strane, Xeon Phi je 2x sporiji od TITAN-a.
Treba imati u vidu da se NVIDIA ne trudi nesto oko OpenCL podrske pa bi cist CUDA kod verovatno bio jos par desetina % brzi sigurno. Ali, isto tako, sigurno se mogu izvuci dodatne performanse optimizacijom kernela za Xeon Phi.
Doduse, sa trenutnom cenom tj. dok jos ima zaliha, tesko da nesto moze da ubije Phi od $100-$200 (koliko uspete da se pogodite) sto se performansi po dolaru tice :)
Na osnovu ovih rezultata mislim da mogu da ekstrapoliram da jedan Phi moze da simulira 200-300 hiljada neurona u realnom vremenu.
[ ventura @ 21.12.2014. 21:09 ] @
Citat:
Ivan Dimkovic:
Na osnovu ovih rezultata mislim da mogu da ekstrapoliram da jedan Phi moze da simulira 200-300 hiljada neurona u realnom vremenu.
Znači fali ti još samo 399,984 Phi kartica :)
[ Ivan Dimkovic @ 21.12.2014. 21:14 ] @
Ili da zamolim Kineze da poteraju exe :-)
[ Space Beer @ 23.12.2014. 05:18 ] @
Citat:
Ivan Dimkovic:
Treba imati u vidu da se NVIDIA ne trudi nesto oko OpenCL podrske pa bi cist CUDA kod verovatno bio jos par desetina % brzi sigurno.
Bilo nekad. Sudeći po testovima, Maxwell odlično gura OpenCL. Ali kao što reče, po ceni za koju možeš da uzmeš Xeon Phi, nema razloga da razmišljaš o bilo kom drugom hardveru. Mogao bi možda da nađeš nekog rudara koji ima par komada R9 290(X), da vidiš kako AMD vrti tvoj kod
[ Ivan Dimkovic @ 24.12.2014. 20:58 ] @
Mozda tera dobro OpenCL Maxwell (nemam ih jos, cekam GM100/110 :-) ali definitivno jos i dalje za*ebavaju:
Ja sam prvi OpenCL kod u zivotu napisao pre nekoliko dana, a vec sam skupio par problema:
1. Hoces printf() iz OpenCL kernela? Moze, ali malo sutra sa NVIDIA hardverom. Mogucnost printf()-a iz CUDA kernela radi vec duze vreme...
2. Hoces OpenCL 1.2? Na primer clEnqueueFillBuffer()? NVIDIA OpenCL ICD ce te pozdraviti sa unresolved external simbolom clEnqueueFillBuffer...
Za brzinu ne mogu da kazem jos nista, dok ne isportujem ceo DigiCortex CUDA kod, za sada nisam primetio da nesto sporo trci na NVIDIA hardveru.
Ima Intel isto svoje idiotarije - recimo OpenCL drajver za Xeon Phi odbija da prihvati bilo sta sto ima veze sa teksturama. Neko ce reci, OK - Xeon Phi nije graficka kartica* pa nije cudno da OpenCL implementacija nema teksturne operacije... OK, ima logike, ali Intel-ov CPU OpenCL drajver ima podrsku za teksture!.
* Zapravo, Knights Corner (trenutna Xeon Phi generacija) ima teksturne jedinice (!), posto je KNC bio zbrda-zdola rework propalog Larrabee GPU projekta, na KNC cipu su ostale teksturne jedinice. E sad, mozda je Intel odlucio da ne rade validaciju tog dela cipa pa se ne moze garantovati da teksturne jedinice uopste rade. Ne vidim ama bas ni jedan drugi razlog zasto ih ne bi koristili, mada cak i da ne rade opet nema logike da nemaju emulaciju kao sto im CPU drajver ima.
[ Ivan Dimkovic @ 20.01.2015. 16:50 ] @
Bah, posle malo intenzivnijeg testiranja se pokazalo da je Phi sporiji nego sto sam mislio.
Kada sam portovao kompletne kernele, NVIDIA GK110 je oko 4-5 puta brza od 31S1P. Ovo sam vise puta proverio, cak sam terao i VTune koji kaze da je efikasnost vektorizacije oko 12 (od mogucih 16), sto nije lose uopste, sto znaci da je razlika u brzini do hardvera.
Doduse, CL kerneli za Phi su direktno samo portovani, moguce je da bi mogle da se izvuku dodatne performanse nekim specificnim Phi optimizacijama ali sumnjam da bi to moglo da drasticno promeni rezultat.
Tako da, Phi kartice idu na dobos a ja ostajem na NVIDIA platformi :)
Interesantno, za neuralne simulacije uopste nije potrebno juriti najskuplju/najbrzu karticu, posto je usko grlo memorijski bandwidth. Sto znaci da je bolje uzeti 3 GTX 970 kartice nego, recimo, jednu buducu Titan 2 karticu. Verovatno ce kostati iste pare, ali sa 3 GTX 970 ce biti moguce izvuci vise zato sto ce GTX Titan 2 morati da provodi solidno vreme cekajuci na podatke iz globalne memorije.
Sa druge strane, sacuvacu OpenCL test kod za sledeci mesec kada bi trebalo da izadju AMD-ove kartice sa stacked-RAMom (HBM). Ovo bi moglo doneti kvantni skok u performansama neuronskih simulacija, zato sto ce HMB RAM imati nekoliko puta vece performanse.
Performance per dollar, bar za ovo sto trcim, je i dalje prilicno na strani NVIDIA-e.
GTX970, sa sve tom potencijalnom kvakom sa sporijih 0.5 GB VRAM-a, trci kod 30% brze od GK110 Titan-a (kompletan VRAM je zazuet u testu).
To je cini 6.5x brzom od Xeon Phi 31S1P-a - a sama kartica je oko 2.5x skuplja. Cak i ako u kalkulaciju ubacimo da Xeon Phi 31S1P ima 2x vise RAM-a i da to direktno ubacimo u kalkulaciju kao 2x, opet je GTX970 performance-per-dollar bolji.
Naravno, ovo je samo u slucaju jednog problema, vasi problemi mogu imati drugacije rezultate. Takodje, Xeon Phi ima ECC memoriju (za sta je u slucaju NVIDIA-e neophodno kupiti Tesla akceleratore koji su drasticno skuplje), kome je ECC neophodan onda je Xeon Phi 31S1P trenutno najisplativije resenje, ako i dalje mozete da se dokopate kartice sa popustom.
Ne treba gubiti iz vida i da je moj kod je vec raspisan u CUDA-i - neko ko pocinje od nule, tj. od cistog C/C++ koda, moze doci do drugacije racunice, posto Xeon Phi, bar na papiru, omogucava lakse (brze) portovanje koda. Ali tu ne treba gubiti iz vida da to nije za dzabe: tacno je da je sa Phi-jem lakse doci do koda koji radi na samom akceleratoru, zato sto je u pitanju x86 kompatibilna arhitektura, ali takav kod nece biti optimalan.
Realno, ako je cilj iskoristiti hardver maksimalno, i u slucaju NVIDIA-e i Intel-a je neophodno raspisati kod koji je specificno optimizovan za arhitekturu.
--
Videcemo kako ce se odvijati ova trka - Knights Landing Xeon Phi ce preci na Atom OoO jezgra i efikasniju arhitekturu, sto ce sigurno Intel-u povecati performanse bar 3-4 puta, ako ne i vise. Medjutim, ni NVIDIA ne sedi skrstenih ruku: imali su vec head-start sa Kepler-om, a Maxwell je solidno efikasniji.
Takodje, AMD ce u sledecih par nedelja izbaciti prve kartice sa stacked-RAM-om, koji ce imati nekoliko puta veci bandwdith od GDDR5. NVIDIA ce izbaciti svoje stacked-RAM akceleratore sa Pascal arhitekturom.
Mislim da cemo u sledecih par godina imati velika unapredjenja u performansama: od stacked RAM-a koji ce konacno omoguciti TB/s performanse na akceleratoru, pa sve do eliminacije PCI Express bus-a kao interconnect-a, koji ce biti zamenjen drasticno brzim bus-evima.
Vec je sada izvesno da ce se unapredjenja u procesima fabrikacije usporiti - i verovatno ce svi veliki silicon vendori (Intel, TSMC, GlobalFoundries) u sledecih par godina, po prvi put, doci u situaciju da sledece generacije procesa fabrikacije ne donose ustedu u troskovima po tranzistoru. Ovo ce ih prisiliti da pribegnu novim nacinima optimizacije i inovacije, kao sto su prelazak na nove materijale i 3D "zidanje".
------------------------------------------------------------------------
v1.12 - Released on February 12th 2015
------------------------------------------------------------------------
* CUDA compute plug-in now selects the GPU with the highest amount of
SMs for computation
* Added command line option -cudevice <N> for manual selection of CUDA
accelerator
------------------------------------------------------------------------
v1.13 - Released on March 1st 2015
------------------------------------------------------------------------
* Added configuration options for meta-plasticity with homeostatic
regulation for each neuron type. Values are configurable per each
extended neuron type in their respective XML configuration file
(e.g. /NeuronLibrary/P2.xml):
EnableMetaplasticity --> Enable / Disable Metaplasticity
MetaScalingFactor --> Scaling factor controling the rate of control
MetaTargetFiringRate --> Target firing rate (in Hz)
MetaMinSynWeightThresh --> Threshold below which adjustment stops
MetaMaxSynWeightThresh --> Threshold above which adjustment stops
* Fixed a bug where reticular thalamic neurons adjectant to LGN layer
did not have correct retinotopic coordinates assigned to them
(affected simulations with retinal model only)
* Added option to print out list of post-synaptic neurons of the
selected neuron with the 'U' key (list of axon terminals)
* Added printing of retinotopic coordinates (UV) for pre-synaptic
neurons of LGN and V1 when showing compartment statistics ('Y' key)
* Updated brain structural data based on improved registration between
T1 and Diffusion spaces, resulting in improved alignment of the
axonal tracts with cortical surface
* Fixed a bug where configuring MaxAxonalDelay in the simulation
configuration resulted in all axon terminals to be incorrectly set
to the MaxAxonalDelay value
* Fixed a bug in CUDA compute which resulted in some neuron categories
flags to be transmitted to the GPU incorrectly, resulting in wrong
computation of membrane voltage for thalamic neurons
[ Ivan Dimkovic @ 08.04.2015. 17:31 ] @
Vreme je za malo bolju opremu... :-)
12 GB VRAM-a baby :-) Ako se pokaze dobra, ima da napravim cluster :-)
Nema double, ali kome to jos treba :-)))
[ Space Beer @ 09.04.2015. 05:50 ] @
I to će te držati do leta. Onda ćeš uzeti Fiji sa HBM-om, pa ćeš za Božićne praznike da častiš sebe kupujući Knights Landing :D
Aj da vidimo šta novi Titan stvarno može, kači rezultate :)
[ Ivan Dimkovic @ 09.04.2015. 10:41 ] @
Hehe :-)
E, ovako, nisam jos mogao da uradim puno testova, ali ono malo sto sam odradio, novi Titan X je zver.
Simulacija sa milion neurona, bez ikakvih specificnih optimizacija za Maxwell, trci oko 0.3x real-time na Titan X-u. Zbog enormne kolicine memorije, na karticu moze da "stane" i preko, do 1.3 miliona multi-kompartmentalnih neurona.
Na starom Titan-u simulacija sa 500K neurona trci oko 0.25x real-time.
Za ovaj task je Titan X 2.5x brzi - a cena skoro ista.
Sto se tice HBM memorije, mislim da ce to biti najveci skok sto se neuralnih simulacija tice, tako da cu to svakako imati u vidu za upgrade.
[quote]
------------------------------------------------------------------------
v1.14 - Released on April 19th 2015
------------------------------------------------------------------------
* Improved precision of the white matter tract tracing by decreasing
the step size to 1/2 of the diffusion MRI dataset voxel size, which
is 1.5 mm for the current dsi.fib.bin dataset. Previous versions
of DigiCortex were using fixed step size of 5 mm (6.66x larger).
To compensate for the vastly increased number of tract segments, new
strategy is applied for reducing the number of 3D points for tract
rendering by effectively downsampling the inner tract points, which
reduces the number of vertices to render but without compromising
the resolution of the data used for connectome mapping (beginning
and termination tract segments)
* Improved registration of the white matter tracts with the cortical
mesh, resulting in improved accuracy of the long-range connections
of the cortical and thalamocortical/corticothalamic neurons
* Fixed several bugs related to the generation of short-range synaptic
connections inside the cortex
------------------------------------------------------------------------
v1.15 - Released on May 28th 2015
------------------------------------------------------------------------
* White matter tracts are now being traced from a dataset which also
includes voxel-wise corrections of gradient non-linearities on bvals
/ bvecs (Bammer et al., 2003; Sotiropoulos et al., 2013)
References:
Bammer, R., Markl, M., Barnett, A., Acar, B., Alley, M.T., Pelc,
N.J., Glover, G.H., Moseley, M.E., 2003. Analysis and generalized
correction of the effect of spatial gradient field distortions in
diffusion-weighted imaging. Magn Reson Med 50, 560-569
Sotiropoulos, S.N., Jbabdi, S., Xu, J., Andersson, J.L., Moeller, S.,
Auerbach, E.J., Glasser, M.F., Hernandez, M., Sapiro, G., Jenkinson,
M., Feinberg, D.A., Yacoub, E., Lenglet, C., Van Essen, D.C.,
Ugurbil, K., Behrens, T.E., 2013. Advances in diffusion MRI
acquisition and processing in the Human Connectome Project.
Neuroimage 80, 125-143.
* Fixed Linux (Wine) compatibility of 64-bit DigiCortex binaries. Wine
1.6.x has no implementation of GetNumaProcessorNode() and related
API calls. This problem has been fixed by disabling NUMA-aware calls
when DigiCortex is running under Wine environment on Linux and
falling back to legacy memory allocation.
* Fixed compatibility problems of 64-bit DigiCortex binaries running on
x64 editions of Windows XP and Windows Server 2003 R2 caused by
attempted usage of non-existent Windows 7 Processor Group APIs
* Fixed rendering problem on certain VMWare installations which was
caused by accessing OpenGL states (glGetFloat) from additional
(non-rendering) thread not having its own OpenGL context
* Fixed a bug in handling of synaptic min/max range for homeostatic
control affecting CUDA-accelerated simulations
[ Ivan Dimkovic @ 29.05.2015. 10:12 ] @
Btw, inace verzija 1.15 koristi korigovane dMRI podatke gde je u rekonstrukciji traktova takodje uracunata i korigovana nelinearna distorzija zbog varijacije intenziteta i pravaca difuzionih gradijenata u prostoru.
Ovo je zahtevalo dodavanje korekcije u DSI Studio i koja se vrsi u toku GQI rekonstrukcije (gde se za svaki voxel koriste "ispravljeni" bval/bvec a "ispravljanje" se vrsi mnozenjem sa 3x3 matricom koja predstavlja distorziju u 3D prostoru).
------------------------------------------------------------------------
v1.16 - Released on June 4th 2015
------------------------------------------------------------------------
* Fixed a crash when running on Windows Server 2008 R2+ systems with
multiple processor groups (number of logical processors > 64), such
as 4S Intel Xeon E5 V2 systems or 2S Xeon E5 2699 V3 (this 2S setup
has 72 logical cores configured in two Windows processor groups)
Na zalost, nekako se provukao bug koji je izazivao krah na sistemima koji imaju vise od jedne procesorske grupe.
To su sistemi koji trce Windows Server 2008 R2 (Windows 7 kernel) ili kasniji i sa vise od 64 logicka procesora kao npr. cetvorostruki Xeon E5 46xx V2, cetvorostruki / osmostruki Xeon E7 V2 ili dvostruki Xeon E5 2699 V3.
Problem je sada fixovan i SpikeFun radi bez problema i na sistemima sa vise od 64 jezgra.
Dokaz, evo bez problema popunjen dvostruki 2696v3 (OEM verzija 2699v3) - 36 fizickih / 72 logicka jezgra. Task manager je dole desno :)
[ Space Beer @ 11.06.2015. 05:18 ] @
E dobro je, sad više ne moram da vadim drugi procesor kad hoću da pokrenem simulaciju :D
Hello,
I would like to ask if there is intention to provide source codes of SpikeFun for scientific purposes only? Up to now I only found neural simulators strictly for Linux but the SpikeFun. Anyway there are some points to be adujsted for my research on it.
Seems to be very interesting project with lot of ideas I would await from such simulator, hence I'm fascinated by it.
Hope this project won't fall into oblivion and will keep on.
[ mindbound @ 05.03.2016. 02:10 ] @
Very much seconded. :)
[ cyBerManIA @ 05.03.2016. 04:34 ] @
Ivane, dugo nije bilo update-a u vezi projekta. Dokle si stigao? :)
Dodata je podrska za Intel Skylake EP/EX ("Purley") platformu sa AVX-512 instrukcijama. CUDA compute modul sada koristi CUDA 8.0 i dodata je podrska za NVIDIA Pascal arhitekturu.
Citat:
------------------------------------------------------------------------
v1.19 - Released on March 20th 2017
------------------------------------------------------------------------
* Added option to control number of warmup time steps (-warmupsamples)
* Added option to exit DigiCortex once benchmark results are written
to a file (-benchexit)
* Simulation time step is now written in the benchmark log
* Added support for Intel Skylake-EP / AVX-512 instruction set
* CUDA runtime updated to v8.0
* Updated hardware performance monitoring to support following CPUs:
NOTE: Hardware performance monitoring run on multi-socket Haswell
EP systems will not run in 32-bit mode, resulting in bug check.
If running on multi-socket system and with hardware performance
monitoring (-pmu switch), please use 64-bit version of DigiCortex
* Fixed a bug where, during circuit building, incorrect pre-synaptic
neuron was selected for connection (affects neurons with retinotopic
coordinates only e.g. LGN TC, V1 Pyr. etc.)
* Fixes a bug where command line help (-h) switch was crashing
* Fixed a bug where 32-bit simulation crashed if number of logical
CPUs is higher than 32. Note: maximum number of logical CPUs on
32-bit simulations is 32. For supporting systems with number of
logical CPUs higher than 32, please use 64-bit version of DigiCortex
------------------------------------------------------------------------
v1.20 - Released on March 21st 2017
------------------------------------------------------------------------
* Added an option to control number of benchmark samples
(-benchsamples, default 5000)
* Improved performance when running on systems with number of CPUs
different than 2^N (e.g. 6, 10, 18, etc.)
* Fixed a bug where number of simulation threads was capped at 64
* Fixed a bug where simulations might run incorrectly on systems with
number of logical cores higher than 64. DigiCortex now supports up
to 4 processor groups with 64 cores each, totalling 256 cores. This
will be improved in the future for supporting more than 256 cores.
* Fixed a bug on NVIDIA Optimus systems where running CUDA simulation
and OpenGL visualization would not work. This problem is fixed by
forcing DigiCortex to run on NVIDIA GPU. In order for this to work,
Optimus configuration settings must be set to "Auto"
for GPU selection
Sto se performansi tice, za slucaj da sistem ima broj jezgara koji nije 2^N, v1.20 ce znacajno bolje iskoristiti dostupne resurse.
Kao u ovom slucaju sa 72 jezgra:
[Ovu poruku je menjao Ivan Dimkovic dana 22.03.2017. u 01:21 GMT+1]
[ Ivan Dimkovic @ 24.04.2017. 10:30 ] @
Dolazeci v1.21 ce podrzavati multi GPU kao i optimizacije za NVIDIA Pascal arhitekturu...
1.8 miliona neurona sa 70 miliona sinapsi u realnom vremenu, na jednom GP102 GPU-u. Poboljsanja u odnosu na Maxwell generaciju su do 2.08x, a to je sve sa GDDR5X memorijom.
50% brza HBM2 memorija bi sigurno ovaj rezultat poboljsala jos solidno.
O Multi GPU podrsci vise informacija uskoro :)
[ Ivan Dimkovic @ 25.04.2017. 12:30 ] @
v1.21: Multi GPU podrska, simulacija 10 miliona neurona / 358 miliona sinapsi na 4 NVIDIA Tesla K80 kartice (8 GPU-ova ukupno):
0.265x real-time:
[ lospalos @ 25.04.2017. 12:51 ] @
Performance seems still better ;-)
Ivan, do you think - will be there sometime in future support for another sensory inputs (acoustic, thermo, attitude, etc ) besides retinal input?
And new and old question - will you release source code ever?
[ Ivan Dimkovic @ 02.05.2017. 15:43 ] @
@lospalos,
Thanks! Yes, I plan to add support for additional sensory inputs, it is on my TODO list :)
As for the source code, no plans as of right now. I would suggest to check Brian simulator in case you are looking for source code of AdEx / Izhikevich neuron models or voltage-based STDP implementations.
------------------------------------------------------------------------
v1.22 - Released on May 2nd 2017
------------------------------------------------------------------------
* CUDA simulations will limit GPU firings buffer size in case there is
not enough VRAM for default firings buffer size. When operating with
constrained firings buffer size, some spikes might be missed
* Fixed the problem preventing simulations from starting on systems
with 16 GPUs due to memory allocation failure
------------------------------------------------------------------------
v1.21 - Released on April 25th 2017
------------------------------------------------------------------------
* Added support for NVIDIA Pascal architecture
* Support for simultaneous use of multiple NVIDIA CUDA devices, please
see comments in DigiCortexConfig.cuda
* Fixed CPU discovery on systems with number of CPU groups higher
than four
* CUDA compute now requires at least Kepler generation GPU
* Added configuration option for forcing circuit builder to generate
neurons with single compartments (<ForceSingleCompartmentNeurons>),
for usage please see Demo*_SingleCompartment.xml files
* Added more example projects (_SingleCompartment.xml)
Sada DigiCortex moze da radi sa 16 GPU-ova.
Screenshot simulacije 16.7 miliona neurona sa 579 miliona sinapsi na 16 NVIDIA K80 GPU-ova - 0.26x real-time.
[ mindbound @ 03.05.2017. 23:18 ] @
Citat:
Ivan Dimkovic:
I would suggest to check Brian simulator in case you are looking for source code of AdEx / Izhikevich neuron models or voltage-based STDP implementations.
Possibly much more interesting would be to see some examples detailing the methods for reconstructing the neural connectivity and doing axonal guidance from the DTI data. Could you write a post or article about that at some point or point to relevant literature?
Zanimljivo, mislim da je Blue Brain Project dobio solidno superracunarsko vreme za dalje istrazivanje u ovom pravcu, videcemo krajem godine kakve ce to rezultate dati.
[ Ivan Dimkovic @ 22.06.2017. 11:48 ] @
Konacno rezultati na NVIDIA P100 ("Big Pascal") sistemu:
P100 je stvarno zver od kartice, sa 2 komada DigiCortex moze da simulira 5 miliona neurona / 200 miliona sinapsi u realnom vremenu. Takodje, ubrzanje u odnosu na "consumer" Pascal GPU (GP102 / 1080 Ti) je prilicno. Razlog za to je mnogo veci dostupni memorijski protok (720 GB/s vs. 484 GB/s) kao i mogucnosti koje samo Tesla kartice imaju (preklapanje memorijskih transfera).
Evo kako izgleda poredjenje performansi izmedju GP100, GP102 i GM200 na jednom GPU-u:
I, tabela performansi na referentnim sistemima:
[ Ivan Dimkovic @ 26.10.2017. 14:26 ] @
v1.22 na 8x NVIDIA Volta V100
16 miliona neurona, 575 miliona sinapsi - 0.75x real-time. Zauzece Voltinog memorijskog kontrolera: 95% (to je 855 GB/s, po kartici), nije lose :-)
v1.29 - Released on November 5th 2018
------------------------------------------------------------------------
* Fixed incorrect OpenGL video memory usage report
* Improved rendering in high-quality ("connectome") mode including
showing of long-range connections
* Fixed rendering bug in high-quality ("connectome") mode when running
simulations including retinal input
* Added support for rendering of very large simulations in high-quality
mode even when rendering objects size is larger than VRAM size of
the visualization GPU (exact behavior can depend on the actual
OpenGL implementation, correct operation has been confirmed with the
NVIDIA 416.16 driver and GeForce GTX 1080 Ti GPU)
Malo sam poradio na vizualizaciji visoke rezolucije (render svih konekcija izmedju neurona) tako da i jako velike simulacije mogu da se renderuju bez obzira na kolicinu GPU VRAM-a.
Evo, npr. ova dole ima 16.7 miliona neurona i samo kompresovani (pakovani tj.) OpenGL atributi zauzimaju ~17 GB memorije i sve se to i dalje renderuje na 1080 Ti koja ima "samo" 11 GB VRAM-a.
Predhodne verzije nisu mogle ovo da renderuju zato sto je sve bilo inicijalizovano kao jedan ogroman VBO, sad sam napravio "cepkanje" OpenGL VBO objekata u batch-eve koji su manji od VRAM-a pa video drajver moze da se izbori i "swapuje" delove mesh-a kako bi uspeo da izrenderuje kompletan frejm. Brzina rendera je naravno bedna, ali to nije za cudjenje kada objekat ima oko ~800 miliona temena :) Sama cinjenica da ovo uopste moze da se renderuje danas na kucnom hardveru je impresivna.
[ Ivan Dimkovic @ 06.11.2018. 11:09 ] @
Btw, maksimalna trenutno moguca simulacija (16.7M/4B) bi zahtevala oko 128 GB RAM-a samo za graficke podatke ako se renderuje u visokom kvalitetu (tih 128 GB je samo za grafiku, dakle bez simulacije, koja bi zauzela malo vise od toga :-). Ako budem imao vremena i pristup nekoj masini sa bar 1 TB RAM-a i postenoj NVIDIA Quadro grafickoj (sa bar 24 GB VRAM-a, idealno 48 GB kao ova nova RTX 8000) mozda i napravim demo render maksimuma koji DigiCortex moze da ispuca.
Na zalost mislim da niko jos ne nudi cloud rental takve masine.
[ Ivan Dimkovic @ 17.11.2018. 12:33 ] @
Optimizovao sam hi-quality rendering mod tako da graficki podaci zauzimaju manje memorije (dodatnom kompresijom atributa temena i teksturnih lokacija u jedan 32-bitni fleg "niz" koji posle shader "otpakuje" u sta mu vec treba)
Sada graficki podaci za kompletnu 16M/4B simulaciju uzimaju oko ~80 GB video RAM-a. To cak uspe i da izrenderuje po neki frejm kod mene sa maleckom 1080Ti grafikom (11 GB VRAM-a) ali posto ceo sistem ima 128 GB memorije (+ 1 TB SSD "swap") sve se to vucara do neupotrebljivosti posto za svaki frejm prvo mora da se prodje kroz celu simulaciju (~300 GB), pa onda da se izrenderuje 80-tak GB trouglova. Uprkos cinjenici da je swap drajv Samsung 960 Pro PCIe konstantan paging drasticno usporava sve.
Takodje, na zalost, kada graficki podaci predju 64 GB NVIDIA hardver se cudno ponasa bar na Windowsu, nekad radi a nekad aktivira neki watchdog timeout od OS-a koji ubije aplikaciju misleci da je graficki drajver blokiran (a u stvari se on samo znonij konstantnim "swapovanjem" u i iz framebuffer-a). Moguce je ugasiti to ponasanje ali to ne resava problem brzine izvrsavanja na mojoj ogranicenoj masini, jedino resenje za test render je cloud.
ALI... do sad sam vec 3 puta uspeo da potpuno blokiram Google Compute instancu sa "P100 virtual workstation" GPU-om i to tako da je nemoguce resetovati ili stopirati vec samo obrisati, nesrecnik se samo zakuca i ne mozes mu nista osim da ukucas delete u gcloud shell-u i cekas da neki Google-ov proces primeti da je instanca fubar i ubije je silom :-) Ne znam sta se desava :-)
[ Shadowed @ 18.11.2018. 10:57 ] @
Da li bi mozda mogao da renderujes podskup podataka? Recimo da ukoliko je vise neurona blizu napravis neki prosek ili nesto slicno tome. Mislim, lupam primer jer ne znam detalje ali nesto tog tipa.
[ Ivan Dimkovic @ 18.11.2018. 15:06 ] @
Verzija v1.29 vec razbija 3D podatke na "batch-eve" koji su otprilike ~1 GB velicine, tako da komotno drajver moze da se nosi sa tim i da ubacuje/izbacuje batch po batch u/iz video memorije tokom rendera. Sa ovom promenom prolaze renderi koji su 1.5-2x veci od VRAM-a bez problema.
Medjutim, svejedno, ako imas 64 GB+ 3D podataka i dalje ima problema :(
Jedna od nezgoda je sto bar matori OpenGL API nema uopste koncept "video" / "sistemske" i sl. memorije, to je poptuno apstrakovano od tebe. Kad kreiras VBO objekat (u kome drzis geometriju i indekse), GL drajver je zaduzen da vidi sta ce i kako ce sa njim da barata i na GL drajveru je da odluci kad i kako ce da sibne podatke na GPU. Stavise, nije nemoguce da GL drajver napravi i jos jednu lokalnu kopiju 3D podataka u sistemskom RAM-u koju kasnije DMA-uje na GPU po potrebi ili vraca sa GPU-a, zapravo mozda ovde lezi jedan od problema posto je ukupna kolicina RAM-a 128 GB a mozda mu za sve to treba puno non-pageable memorije.
Resenje za ovo bi bilo da ja manuelno radim "swap" 3D podataka tako sto cu imati, recimo, jedan ili par VBO-ova sa kojima zauzmem ceo (ili skoro ceo) VRAM a onda ja rucno kopiram nove podatke iz moje memorije (znaci ne VBO) tako da GL drajver nikada ne uzme vise od VRAM-a za svoje interne bafere, ali to je onda dodatan memcpy() sa moje strane za svako crtanje (+ mozda jos jedna kopija unutar drajvera ako drajver misli da je pametnije da podaci "stoje" jos malo u sistemskom RAM-u).
A da, jos jedan problem je AntTweakBar koji koristim za vizualizaciju retine koji trci u posebnom thread-u sa svojim posebnim GL kontekstom / prozorom ... izgleda je taj pun pogresnih GL poziva koje NVIDIA drajver uspesno "pegla" (samo baca warning-e u GL debuggeru), ali izgleda u ovoj situaciji ozbiljno pretrpane memorije stvari pocinju da bivaju nestabilne i ti problemi pocinju da se prelivaju i na moj kontekst koji crta glavnu vizualizaciju.
Izbacivanjem AntTweakBar-a (nova verzija ce imati skrivenu opciju -noretinatwbar, za ovakve situacije) stvari postaju malo stabilnije, CodeXL GL debugger se vise ne buni, ali i dalje nije garantovano stabilno da render prodje za sve frejmove.
--
Sve u svemu, pravo resenje bi bilo da se batali OpenGL kompletno i predje na Vulkan, sa postenim memorijskim menadzmentom ogromnih 3D podataka. Ali mislim da to necu raditi u skorije vreme.
[ Ivan Dimkovic @ 19.11.2018. 16:49 ] @
OK, kombinacija fixeva sa moje strane (iskljucivanje AntTweakBar-a) + najnoviji NVIDIA drajver (416.94) + sledeca registry podesavanja resavaju problem:
TdrLevelOff je zapravo najvazniji (to bi trebalo da gasi Windows-ov watchdog)
Po defaultu, ako koristite isti GPU za racunanje i displej, Windows ima default timeout od 2 sekunde (TdrDdiDelay) za koje vreme ocekuje da se operacija crtanja GUI-ja zavrsi, posle koga ce restartovati graficki drajver zato sto misli da je GPU zakucan. Interesantno, profesionalne NVIDIA kartice (Quadro) izbace message box koji kaze da je Tdr limit istekao i da ce ubiti aplikaciju umesto da restartuju drajver. Na zalost, na Google Compute instanci sa tom grafickom posle toga vise ne mogu da pristupim istoj bez da je obrisem :-)
Consumer NVIDIA drajveri/graficke (bar kod mene) ne prikazuju nikakvu gresku vec vam aplikacija samo pukne u nvoglv64.dll bez ikakve indikacije ZASTO je aplikacija pukla. Zanimljivo, graficki drajver ne biva restartovan vec samo vasa aplikacija krahira (requestd program exit u nvoglv64.dll).
U ovom slucaju je verovatno problem bio sto je GPU bio zakucan mnogo duze od Tdr limita samo prebacujuci 3D objekte u VRAM i iscrtavajuci ~800 miliona indeksa. Komotno resenje bi bilo koristiti jedan GPU za app rendering a drugi za Windows/displej.
Ako budem imao vremena mozda probam ovo u Linuxu cisto da vidim da li pati od istih problema.
[ Ivan Dimkovic @ 19.11.2018. 21:15 ] @
A evo i indirektnog dokaza da OpenGL drajver duplira bafere, tj. koristi sistemsku memoriju za "staging" (sto je i logicno, posto posle glBuffer(Sub)Data drajver mora da se snadje sta ce sa svojim podacima),
Obratiti paznju na "nestalih" ~75 GB RAM-a koliko je inace iznos mojih grafickih podataka poslatih GL drajveru ;-)
[ Ivan Dimkovic @ 20.11.2018. 23:32 ] @
I evo ga, konacno render kompletne simulacije bez kompromisa - znaci ~75 GB RAM-a samo za 3D podatke :)
Snimljeno i u 4K (isto prvi put), obavezno izaberite max. kvalitet:
To bi bilo to sto se tice vizualizacije. Moguce je jos dodati da se svaki neuron drugacije osvetli u zavisnosti koja je voltaza kompartmenta i bilo bi super cool da se nekako vizualizuje propagiranje impulsa kroz aksone, pogotovu duge... ovo je prvo relativno lak posao (samo sto bi dodao dosta na zahtevima za teksturnu memoriju), ovo drugo, bas i ne...
[ bogdan.kecman @ 20.11.2018. 23:46 ] @
niiiiiiiiiiiiiiiice ... bilo bi cool da je iznad ovog "izlaz" umontiran
u video i "ulaz"
[ Ivan Dimkovic @ 21.11.2018. 12:27 ] @
Hahaha dao si mi odlicnu ideju, posalji izlaz ponovo retini da cela stvar gleda samu "sebe".
Ako me ne bude mrzelo mozda to i implementiram :-)
Moze da se postavi kao umetnicko delo - "simulirani mozak gleda samog sebe".
[ mjanjic @ 21.11.2018. 21:33 ] @
To je kao kad bi napravio simulaciju mozga koji posmatra i "razume" svoje okruženje (renderovano ili sa kamere), a onda mu ubaciš ogledalo u simulaciju :)
Savetovao bih da se smanji kvalitet grafike, ali da logika bude detaljnija i bogatija. Setimo se kvaliteta Google AI botova koji se nadmeću ko će prikupiti više jabuka, niti se vide botovi niti jabuke :)
[ Ivan Dimkovic @ 22.11.2018. 10:40 ] @
Graficki deo samo renderuje mrezu, kakva je mreza takva ce biti i grafika ;-)
DigiCortex je optimizovan za bioloski realizam, a takve mreze se jako tesko treniraju da rade ono sto zelis. Ako hoces AI koji zelis da istrenira da radi sta hoces, daleko bolji izbor danas su neuronske mreze druge generacije uvezane na nacin koji odgovara problemu (npr. CNN ili LSTM) obicno u vise slojeva koji se na kraju zavrsavaju sa nekim klasifikatorom.
U odnosu na bioloski sistem, vizualizacija cak i najguscih "deep learning" neuronskih mreza je jednostavna, ali to je zato sto su one napravljene tako da mi mozemo da ih treniramo. Cak i za tako, relativno govoreci, jednostavne mreze su potrebne hiljade GPU-ova ili TPU-ova koje koriste Google / Facebook za treniranje za neke ozbiljnije probleme tipa (relativno) pouzdano prepoznavanje govora.
Na zalost, za mreze slicne bioloskim neuronskim mrezama i dalje nemamo efikasan algoritam za treniranje, plus nedostaje gomila podataka vezana za rad sinapsi i nacin uvezivanja neurona da bi to moglo da se iskoristi za resavanje kompleksnih problema.
[ Ivan Dimkovic @ 22.11.2018. 22:09 ] @
Btw, sad sam sredio malo kod tako da vizualizacija radi i sa Mesa 3D softverskim OpenGL drajverom, tako da ce moci simulacije da trce i na masinama bez GPU-a ali sa enormnom kolicinom procesora i da nesto cak i renderuju :-)
Izbacio neke praistorijske Windows-only wglXXX() pozive za fontove, i to je to.
Bice u verziji 1.31 :-)
[ Ivan Dimkovic @ 22.11.2018. 22:31 ] @
Za kolege Linuxovce, v1.31 sa softverskim (Mesa 3D) OpenGL renderingom, tako da moze da trci u svakom jeftinom VM-u :-)
[ Shadowed @ 22.11.2018. 23:08 ] @
Koliko softverski render usporava simulaciju?
[ Ivan Dimkovic @ 22.11.2018. 23:41 ] @
Nisam jos poterao neku ozbiljniju pa da ima nekog osetnog efekta, na malim simulacijama sa 100K neurona / 1.5 miliona sinapsi, hi-quality render uzme ~10% CPU-a (skoci na ~20% u FHD modu).
Moja ideja za sw. render je da se trci na masinama koje ili nemaju 3D akceleratore uopste (recimo velike GCP/AWS instance) ili imaju NVIDIA Tesla akceleratore u forsovanom TCC modu gde te kartice ne mogu da se koriste za render. Ideja bi bila, radis simulaciju na GPU-ovima a vizualizaciju na CPU-ovima sto je bizarno ali je jedan od nacina zaobilazenja NVIDIA-inih cudnih ogranicenja za cloud :-)
[ MajorFatal @ 23.11.2018. 00:06 ] @
Nemam pojma ni o cemu pricas ni sta radi :) ali za neke slozenije rendere recimo oni sto prave 3D crtaće koriste " Render farme " a tih farmi ima i za iznajmljivanje pa mozda ti bude od pomoći npr: https://de.rebusfarm.net/en/?g...7uv6ej6jAtMAUAXuQaAoF6EALw_wcB
[ Ivan Dimkovic @ 23.11.2018. 11:50 ] @
Ako hoces da izrenderujes svaku sinapsu, moras za svaki frejm da povuces ~80 GB podataka. Moze da se optimizuje recimo da se fizicke promene na mrezi salju svakih N sekundi (mozda cak i na minut), a izmedju toga da se salju samo promene voltaze, sto je otprilike jedna 4096x4096 tekstura sa jednim 8-bitnim kanalom, sto je oko 16 GB po sekundi.
16 GB po sekundi (+ par stotina GB svakih par minuta) nije strasno, ali cela simulacija bi morala da radi offline u lock-stepu sa render farmom kako bi svaki frejm bio izrenderovan.
Moze to da se resi i u lokalu - tipa 7 GPU-ova budu Tesle u TCC modu koje rade racunanje, a 8-mi GPU bude Quadro/GeForce koji renderuje. Na zalost ni jedan Cloud provajder ne nudi takva resenja za sad (mozes da unajmis ili ciste GPU-ove za grafiku ili ciste Tesle koje mogu samo da racunaju).
Mislim da matori K80 i dalje moze da se koristi u isto vreme za racunanje i render na cloud-u (samo ako imas neki VNC klijent).
Moram da nateram da to sve lepo radi pod Linuxom posto je onda rentiranje na Amazonu, relativno jeftino - 8x NVIDIA K80 sa 64 vCPU-a i 416 GB RAM-a je ~$1.8 na sat, sa tim bi u teoriji mogli da se urade i duzi renderi za relativno male pare, pod uslovom da nateram multi-GPU akceleraciju i OpenGL rendering da rade na Linuxu :-)
[ Ivan Dimkovic @ 23.11.2018. 16:12 ] @
@Shadowed,
Ok, evo resio sam da sad i na Linuxu moze da se renderuje softverski, samo treba uraditi ovo:
Ovo ce naterati Mesa 3D GL implementaciju da crta sve softverski sa (valjda) njihovom najoptimalnijom sw. implementacijom (llvmpipe).
Performanse su, ocekivano, jadne i nesto mi ne izgleda da preterano iskoriscavaju vise jezgara (testirano na 16-core VMWare masini, top daje max %CPU od ~380, dakle mogu da uposle 4 jezgra za crtanje).
Ali ako nista drugo bar je moguce izrenderovati sliku na Linux masini koja nema nikakvu 3D akceleraciju, sto je i bila ideja :-)
[ MajorFatal @ 23.11.2018. 16:29 ] @
A Makintoš? Kad ga "testiraju" pa se hvale ispada da scenu iz Bryce-a Mac na 500 Mhz izrenderuje tri puta brže nego PC na 3 Ghz?
I Bryce ti je zanimljiv program, poodavno je napravljen a neki ga i dan danas koriste i to samo za rendering umesto za ono za šta je namenjen, njegov netvork klijent je BryceLightening ili tako nekako.
U dosta programa max rezolucija tekstura je zakljucana na 4000x4000 piksela, a ti si se izrazio kompjuteraški (4096x4096) jesi li probao da popričaš sa nekim grafičarem ili nekim ko je više radio 3D programe, igrice, piksele, šedere...rendering je zahtevna operacija pa pretpostavljam da imaju neke svoje trikove kako rešavaju stvari.
[ Ivan Dimkovic @ 23.11.2018. 16:50 ] @
Danas je 4096x4096 nista za teksture. Moderne graficke kartice podrzavaju mnogo vece teksture. Ako neki program ima 4000x4000 limit to je iz nekih sasvim drugih razloga, mozda istorijskih.
Npr. trenutne jace "kucne" NVIDIA graficke (a-la 1080) prijavljuju 32768x32768 kao max. velicinu teksture.
Uzgred, istorijski, 3D graficke kartice su prvo podrzavale samo 2^N velicinu tekstura a tek kasnije su dobile mogucnost podrzavanja tekstura dimenzija koje nisu 2^N. Naravno, ovo ogranicenje nikada nije kacilo softverske pakete koji su renderovali grafiku softverski.
Citat:
A Makintoš? Kad ga "testiraju" pa se hvale ispada da scenu iz Bryce-a Mac na 500 Mhz izrenderuje tri puta brže nego PC na 3 Ghz?
Nije brzina rendera uopste problem posto tolika simulacija i ovako i onako ne radi u realnom vremenu.
Problem je velicina grafickih objekata vs. kolicina video memorije koja zahteva od OpenGL drajvera da za jedan frejm uradi vise velikih DMA operacija zato sto ne moze kompletna scena da stane u VRAM. Dok graficki drajver radi DMA, graficka nije u stanju da opsluzuje Windows GUI (ako se koristi ista graficka za render i GUI).
Negde od Viste je Windows uveo neki watchdog tajmer koji detektuje situaciju da se graficki pozivi ne zavrsavaju u zadatom vremenu (default: 2 sekunde) i zbog toga je Windows kernel pokusavao da restartuje graficki drajver kao failsafe metod za crtanje sopstvenog GUI-ja. Registry hack koji sam pomenuo gore resava taj problem (po cenu da Windows GUI biva blokiran na po nekoliko sekundi svaki put kada drajver ubacuje / izbacuje deo scene).
Alternativno resenje je koriscenje druge graficke kartice za render simulacije, ili kompletan softverski render ako simulacija trci na hardveru bez 3D grafike.
[ Ivan Dimkovic @ 23.11.2018. 21:56 ] @
Heh, moja ideja za jeftino trcanje sa renderom na Google Linux kantama sa puno CPU-ova je pala u vodu...
Problem #1 - Wine nije u stanju da prikaze Linux sistem sa >64 procesora kako treba mojoj Win32 aplikaciji:
Code:
[1811232150342] CPU has AVX512 Instruction Set - Enabling AVX512 Optimizations
[1811232150342] Number of detected CPU cores: 65 (logical: 65)
Lepo je da je sistem prepoznao Skylake. Ali losa vest je da je broj prijavljeni broj procesora totalno idiotski, takodje Wine ne prijavljuje ni da je sistem NUMA :-)
Trebalo bi da bude 96 procesora, podeljenih u 2 procesorske grupe (jedna sa 64 CPU-a, druga sa 32 CPU-a).
Wine iz nekog razloga ne prijavljuje procesorske grupe kako treba, pretpostavljam da to uopste nisu ni testirali posto verovatno malo kome treba (testiram wine-development verziju, Ubuntu 18.04). Mada mi nije jasno odakle broj 65... 64 bih i razumeo (da ne vidi uopste ostalih 32), ali 65...
Problem #2 - Mesa 3D softverski OpenGL ne radi preko VNC servera :(
Zali se da nema 64-bitni OpenGL drajver (mislio sam da oni to mogu da kompletno emuliraju u softveru)? U Windowsu Mesa moze da kompletno emulira OpenGL i na VMWare SVGA grafickoj bez 3D-a... izgleda da na Linuxu to nije bas tako jednostavno, verovatno zbog X servera.
Citao sam da moze da se nabudzi da OpenGL ide preko VNC-a... ali tutoriali su za 3D graficke, a meni treba kompletna sw. emulacija, tako da me mrzi da gubim sat-dva na kobasice i drndanje sa necim sto mozda i ne radi.
[ Ivan Dimkovic @ 23.11.2018. 23:54 ] @
Zapravo quick&dirty resenje bi bilo da AWS ili Google daju da se na njihove mega masine sa 96/128 procesora moze poterati Windows Server trial verzija za testiranje. Onda bi cena "igranja" bila oko dolar na sat.
Sa Windows licencom cela ta stvar skoci na 5-6 dolara na sat + ako ti treba GPU...
Koliko vidim ima proces da mozes da "uneses" svoj VM, ali izgleda proveravaju da li je taj VM Windows (podrzani) i, ako jeste, deaktiviraju tvoju licencu i menjaju je sa njihovom koju naplacuju po taksimetru :)
[ Ivan Dimkovic @ 24.11.2018. 23:36 ] @
Btw, bas sad proveravam skaliranje na 4xNUMA sisteme... radi sve kako treba :-)
Evo Xeon E7 8800 v3 makine, 4 NUMA noda, 128 logickih procesora, svi lepo zauzeti 100% kako treba :-)
[ MajorFatal @ 25.11.2018. 00:43 ] @
Citat:
Ivan Dimkovic:
Danas je 4096x4096 nista za teksture. Moderne graficke kartice podrzavaju mnogo vece teksture. Ako neki program ima 4000x4000 limit to je iz nekih sasvim drugih razloga, mozda istorijskih
Možda, ali ako su više od dva programa u pitanju uključujući i fotošop i irfanview možda nisu istorijski razlozi nego zdravorazumski, znaš kako u igricama kod 60 fps se zaustave jer iznad toga ljudsko oko više ne može da primeti razliku, slično 4000x4000 je već tolika rezolucija da je dovoljno dobra za bilo kakve potrebe od postera do bilborda veličine zgrade, za većinu današnjih monitora 1024x768 je mislim savršeno dobro i slično za televizore, a fps 25 i 30, u bioskopu da li beše još manje tipa 12fps, a da smanjiš sa 4000 na 1024 to ti je 16 puta kraće vreme za render.
Ne znam čemu služi ta vizuelizacija, ali pretpostavljam da kako god da je uradiš svejedno nećemo moći da okom vidimo svih 16 miliona veza, sinapsi čega god?
[ Shadowed @ 25.11.2018. 00:51 ] @
Mnoge igre koriste jednu ogromnu teksturu iz koje onda mapiraju delove umesto vise malih.
[ Ivan Dimkovic @ 25.11.2018. 09:44 ] @
Citat:
MajorFatal:
Citat:
Ivan Dimkovic:
Danas je 4096x4096 nista za teksture. Moderne graficke kartice podrzavaju mnogo vece teksture. Ako neki program ima 4000x4000 limit to je iz nekih sasvim drugih razloga, mozda istorijskih
Možda, ali ako su više od dva programa u pitanju uključujući i fotošop i irfanview možda nisu istorijski razlozi nego zdravorazumski, znaš kako u igricama kod 60 fps se zaustave jer iznad toga ljudsko oko više ne može da primeti razliku, slično 4000x4000 je već tolika rezolucija da je dovoljno dobra za bilo kakve potrebe od postera do bilborda veličine zgrade, za većinu današnjih monitora 1024x768 je mislim savršeno dobro i slično za televizore, a fps 25 i 30, u bioskopu da li beše još manje tipa 12fps, a da smanjiš sa 4000 na 1024 to ti je 16 puta kraće vreme za render.
Prvo, velicina teksture uopste ne utice na vreme rendera (tekstura se koristi samo za skladistenje voltaza a semplovanje teksture na bilo kom GPU-u iz proteklih 10+ godina je prakticno dzabe, cak dobijes i interpolaciju za dzabe :-) Ti ni u jednom momentu >ne vidis< ovde tu teksturu zato sto ona ne sadrzi podatke koji se renderuju.
Takodje, oko velicine (iako ovde to nema veze, kao sto rekoh), ti teksturi od 4000x4000 mozes u simulaciji gde se slobodno setas (recimo igrica) da se priblizis tako da je jedan piksel na teksturi mnogo veci na renderovanom poligonu, zar ne? :-) Naravno, za to postoje i dodatna resenja (visestruki nivoi detalja tj. MIP-mape) ali, u svakom slucaju, fakat da danasnja gejmerska NVIDIA prihvata 32768x32768 teksture dovoljno govori o tome kakve su potrebe igracke industrije, a profesionalna rendering industrija je obicno jos mnogo zahtevnija (zato sad imas ove nove QUADRO graficke sa po 48 GB VRAM-a).
Veruj mi, 4000x4000 kao tekstura je nista za danasnje GPU-ove. Ali bukvalno nista.
Druga stvar, kao sto Shadowed rece, cesto se kombinuje dosta asset-a u jednu teksturu kako bi se izbegli visestruki transferi na GPU. Svaki transfer iz sistemske memorije na GPU zahteva setanje iz userspace-a u kernel mod, stavljanje komandi u GPU komandni baferi, na kraju, izvrsavanje DMA operacije koja ce da povuce memoriju iz sistemskog u video RAM. Bolje to da uradis jednom (posto za svaku ovakvu operaciju gubis milisekunde), recimo na pocetku igrice, nego da to cepkas na mnogo malih operacija.
Sve u svemu, 4096x4096 za teksture je inkonsekventno.
Trece, velicina te teksture je potpuno nebitna za vreme rendera posto svi moderni GPU-ovi imaju hardverske teksturne jedinice, obicno mnogo njih (bar 8 komada vec N godina).
U ovom konkretnom slucaju je problem geometrija, zato sto se renderuje svaka sinapsa a njih ima puno i ne mogu da stanu u VRAM pa kartica mora za svaki frejm da "swapuje" 7 puta vecu kolicinu podataka od kompletnog VRAM-a.
Citat:
Ne znam čemu služi ta vizuelizacija, ali pretpostavljam da kako god da je uradiš svejedno nećemo moći da okom vidimo svih 16 miliona veza, sinapsi čega god?
Worst case.
I ako zumiras, nece se ni renderovati 4 milijarde sinapsi vec samo one koje se vide (doduse, shader pipeline ce i dalje morati da odbaci one koje se ne vide, sto nije skupo ali je problem sto ukupan broj prelazi kolicinu video memorije pa bi early-rejection morao da se radi na CPU strani)
[ mjanjic @ 25.11.2018. 20:25 ] @
Apropo hardverske zahtevnosti, ima na YT dobrih primera sa Mandelbrot Fractal Zoom, ali mi ovaj nekako baš godi iako nije možda hardverski najzahtevniji od nekih drugih (na 2:30... hm): https://www.youtube.com/watch?v=aSg2Db3jF_4
[ Ivan Dimkovic @ 26.11.2018. 14:25 ] @
Jos malo sitnih fix-eva u v1.32 - sada, uz mali trik je ponekad moguce trcati simulacije i sa vise od 4 milijardi sinapsi.
Kazem ponekad, zato sto je sada ogranicenje 4 milijarde sinapsi po jednom compute cvoru, sto je u praksi ili jedan NUMA nod.
Takodje, nova verzija ima fix za simulacije sa ukupnim brojem sinapsi vecim od 4 milijarde, zato sto je na par mesta u kontrolnom kodu limit bio 32-bitni integer, sto je izazivalo overflow i gresku prilikom validacije mreze. Uspesno sam testirao promene sa simulacijom od ~4.6 milijardi sinapsi na NUMA sistemu sa 2 noda i sve radi OK.
A sad upravo testiram v1.32 na ovim novim Amazonovim AMD EPYC instancama.
Zanimljivo je da najveca AWS AMD masina (r5a.24xlarge) sa AMD EPYC 7571 CPU-om ima 96 virtuelnih jezgara podeljenih u 6 NUMA nodova, tako da mi je to odlicna prilika da se i to proveri, posto do sad nisam imao prilike da testiram ni na cemu sa vise od 4 NUMA noda.
[ Ivan Dimkovic @ 26.11.2018. 14:39 ] @
Zanimljivo zapazanje, prilikom kreiranja mreze na Amazonovoj EPYC 7571 masini, zauzece procesora ne prelazi 80% - mreza se pravi sa 96 niti i tokom rada CPU izgleda zauzet ovako:
Na Intel-ovom hardveru gde je masina 100% vasa i gde je NUMA mapirana kako treba u OS-u, zauzece procesora prilikom pravljenja mreze bi trebalo da bude 99-100%.
Nemam nista za profiliranje na ovoj Amazonovoj AMD masini, prepostavljam da je problem u nejednako efikasnom pristupu memoriji (uprkos cinjenici da Amazon prijavljuje sistem kao NUMA i da ima 6 nodova).
Ne znam kako hardverski izgleda ta Amazonova r5a.24xlarge masina, mislim nude 96 vCPU-ova / 768 GB RAM-a, nije mi jasno kakav je onda to hardver tj. kako izgleda fizicki?
Tj. da li je to fizicki zapravo dual-socket EPYC 7571 masina sa ukupno 64 jezgra / 128 vCPU-ova koju Amazon rentira kao dve (ili vise) instance kupcima?
Ako je tako, onda ovo objasnjava probleme sa performansama koje vidim posto onda zapravo delim masinu sa nekim i mozda ne pristupam memoriji optimalno.
[ Ivan Dimkovic @ 26.11.2018. 14:55 ] @
Btw, malopre sam zbog brzog testiranja radio isti test i sa Intel instancom (r5.24xlarge) - i sa Intel instancom gradjenje mreze zauzima 100% svih 96 vCPU-ova.
Intel masina je isto sa 96 virtuelnih CPU-ova, samo sto je "unutra" fizicki CPU Intel Xeon Platinum 8175M koji ima 24 jezgara / 48 vCPU-ova, pa je cela r5.24xlarge masina zapravo "vasa" tj. rentiraju vam ceo dual-socket sistem.
Takodje, Intelov sistem ima samo 2 NUMA noda sa po 48 vCPU-ova u svakom.
Na prvi pogled mi deluje da je problem sto Amazon verovatno "cepka" AMD masinu na vise instanci i da se to ne odrazava lepo na performanse aplikacija koje su izuzetno zahtevne po pitanju memorijskog bandwidth-a.
Btw kreiranje mreze na Intel masini traje duplo krace vremena.
- 20% razlike se moze pripisati problemu opisanom gore (uzrok nepoznat)
- Intel-ovi CPU-ovi trce na 2.5 GHz, AMD-ovi na 2.2 GHz
Ostatak je verovatno AVX throughput.
[ Ivan Dimkovic @ 26.11.2018. 15:13 ] @
I evo, simulacija sa 4.6 milijardi sinapsi koja trci na AMD EPYC masini.
Moj scheduler uspeva da drzi procesore uposljene 96-97%, nije lose.
Sad i AMD EPYC moze da se doda u listu kompatibilnih :)
[ Ivan Dimkovic @ 26.11.2018. 19:07 ] @
Heh, sad pogledah malo Wine kod i mnogo toga mi je jasnije ;-)
Na AWS masini ako trcim kod pod Wine-om dobijem sistem od 48 fizickih CPU-ova, 32 logicka (?!) i 1 NUMA nod :-)
[ MajorFatal @ 28.11.2018. 02:09 ] @
Citat:
Ivan Dimkovic:
Ako hoces da izrenderujes svaku sinapsu, moras za svaki frejm da povuces ~80 GB podataka. Moze da se optimizuje recimo da se fizicke promene na mrezi salju svakih N sekundi (mozda cak i na minut), a izmedju toga da se salju samo promene voltaze, sto je otprilike jedna 4096x4096 tekstura sa jednim 8-bitnim kanalom, sto je oko 16 GB po sekundi.
16 GB po sekundi (+ par stotina GB svakih par minuta) nije strasno, ali cela simulacija bi morala da radi offline u lock-stepu sa render farmom kako bi svaki frejm bio izrenderovan.
A jel ima varijanta da ako nećeš da izrenderuješ baš svaku sinapsu (jer ionako ne možemo da vidimo 5 milijardi sinapsi) da umesto da se promene šalju svakih N sekundi - renderuješ svaki N-ti neuron i njegove sinapse? Tipa svaki hiljaditi na 16 mil neurona opet ćeš imati render od oko najmanje16000 objekata na sceni, opet ćeš imati scenu sličnu ovoj koju već imaš i moći da pratiš šta se dešava...?
Pobornik sam teorije da u svakoj šali ima malo istine, ekhm, da ljudi olako predju preko nekih potencijalno dobrih ideja, simulirani mozak koji gleda sam sebe zvuči malo blesavo, ali da jedna hemisfera posmatra drugu nije čini mi se nemoguć scenario pogotovo u ranim fazama razvoja, i pri ponašanju neurona i sinapsi kakve si opisao, u tim fazama ionako ništa drugo ne bi imale da "gledaju".
A slaže se i sa tvojim opisom šta se dešava prilikom presecanja korpus kolonusa ili kako se zove beše.
Tek sad sam pregledao temu malo detaljnije, koji si ti luđak , u pozitivnom smislu naravno. :)
U vezi sa renderom, ako ne odustaješ od doslednosti možda opet da proveriš kako renderuju dim, prašinu, kapljice i sl. u 3D programima i u igricama, ovaj tvoj model me najviše podseća na to, tu idu oni neki "objekti" tipa particles, naravno da zoom ne pomaže...
[ Ivan Dimkovic @ 28.11.2018. 10:47 ] @
Pa imas redukovanu vizualizaciju, ona je aktivna po defaultu i ona ne renderuje individualne sinapse vec samo neurone, i prilicno je brza.
Sto se trikova iz igrica tice, u nekom smislu bi svakako pomoglo, nije nikakav problem (mislim teorijski, prakticno sigurno nekoliko dana posla da to izgleda OK i radi brzo) napisati shader koji ce da proceduralno generise "sinapse".
Ali to bi onda bile slucajno generisane pozicije (posto su upravo pozicije te koje zauzimaju najvise mesta) i to onda ne bi bila mreza koju si generisao, vec neka "lazna" mreza koju su shaderi generisali.
Alternativno resenje je mozda redukcija preciznosti - tipa kodiras lokaciju neurona i kompartmenta, a sinapse okolo kodiras kao, npr. 8-bitne fixed-point brojeve. Onda imas 24 bita za indeks neurona (ciju lokaciju i ovako i onako cuvas) i 24 bita za indeks sinapsi, ukupno 48 bita, umesto 96 bita za kompletnu lokaciju sinapse (3x32). Znaci oko 50% ustede, samo sto onda moras u shaderu to da otpakujes, gledas tabele lokacija neurona i sl.... ajde da je usteda 10x pa da ima smisla cimati se ali za 2x... pa nije bas neki posao :)
[ MajorFatal @ 29.11.2018. 01:06 ] @
Pa izvini, temu sam pogledao kad se tek pojavila pa mi nije delovala obećavajuće (simulacija nečeg što ne može biti dostignuto po kompleksnosti, funkcionalnosti i na neodgovarajućoj podlozi u vidu hardvera), ali šta si sve uradio u medjuvremenu i na koji način stvarno svaka čast.
Nisam mislio na trikove koji su varanje, nego trikove koji rešavaju neku vrstu problema sa kojom ili sličnom se ti sad suočavaš, tipa ako su pre 20 godina imali softver koji simulira vlati kose kod ljudi, a istih ima oko 100.000 na glavi, to je već u ravni sa tvojom jednom od slabijih simulacija po broju neurona, i sad ako su bar donekle neuroni uporedivi sa vlatima kose (kompleksniji su naravno) a oni rešili i "koližn detekšn" i preseke valjaka i render i ovo ono, da se ne mučiš oko nečeg što već ima rešenje, slično je sa drvećem s tim što ono već više podseća na neuron, zadaju x grana, 1000 x lišća pa kad izrenderuje...a obično ostave i otvorene one slajdere pa možeš da zahtevaš I drvo sa milion grana, doduše to onda ume da potraje. w-ray ili kako beše je valjda standard za neke ozbiljnije 3D programe, ali sam i vidjao da kad se smore sa time, naročito kad su kompleksnije scene u pitanju, ubace scenu u Bruce i odrade kako treba i u kratkom roku.
Nego ne znam ništa o neuronskim mrežama, a ni o renderingu mnogo pa da se odjavim.
[ Ivan Dimkovic @ 29.11.2018. 08:39 ] @
@MajorFatal,
Ali nije problem proceduralno generisati neuronsko "drvo" na GPU-u, sa slajderom ili konfiguracionom opcijom kako zelis da se grana (ima cak i jako lepih radova na tu temu kako proceduralno generisati realno izgledajuce neurone cak mislim da smo i diskutovali o tome ovde: http://www.elitesecurity.org/p3223987, doduse ne za GPU vec uopste ali portovati to na shader ne smatram problemom vec samo pitanjem programerskog vremena).
Problem je ako zelis da tacno predstavis gde ti se neka sinapsa nalazi, onda moras da kodiras njenu poziciju u 3D prostoru. Imas ih 4 milijarde npr. u simulaciji, i to je puno podataka. Kao sto rekoh, mozes malo da se izvuces pa da ne kodiras sinapsu kao 3 float-a, ja je vec kodiram kao 3 short-a (16-bitna fixed pointa) a verovatno moze jos malo da se ustedi ako se zna da su sve relativno blizu referentne tacke (grane od "drveta") pa mozda i 8-bitna preciznost moze da prodje (znaci 24 bita po 3D poziciji).
Ako im ne kodiras pozicije vec neke proceduralne parametre sa kojima generises celo "drvo" ili "sumu", onda varas, ne renderujes simulaciju vec "simulaciju simulacije", sto je isto OK ako mene pitas za neki drugi projekat, moze biti i vrlo zanimljivo, ali nije problem koji resavam ovde.
Trenutno je jos jedna usteda ta da se smatra da su sinapse "nedaleko" od grane kompartmenta pa se ne kodiraju individualne pozicije sinapsi vec "samo" grana kompartmenta (grana) neurona, ali i to je i dalje jako puno podataka (jedan neuron ima i preko 200 kompartmenta ako simulacija radi u multi-compartment modu koji pravi realisticne neurone, u single-compartment modu su "neuroni" samo "tacke"). Ali zapravo najveci podatak su indeksi koji kazu sta treba da se crta (linija od tacke A do tacke B, itd.).
[ Ivan Dimkovic @ 03.12.2018. 00:00 ] @
U sledecoj verziji ubijam podrsku za Windows XP, Vistu a mozda (verovatno) i 32-bitne izvrsne fajlove.
Nova verzija (1.33) ce imati jos bolje optimizovani CPU work scheduler, koji ce uzimati u obzir i kes hijerarhiju CPU-ova kao i relativnu udaljenost izmedju NUMA nodova na vecim serverskim sistemima. Na zalost API-ji za ovo postoje samo u Win7/Server2008 v2 OS-evima, i odrzavanje duplog koda zbog starih OS-eva postaje nocna mora.
Takodje, nisam siguran da je 32-bitna verzija puno relevantna danas - takodje nema pola API-ja koji mi trebaju za ovo i zbog toga imam workarounde.
[ MajorFatal @ 03.12.2018. 02:12 ] @
Rukovodiću se onom da "nema glupih pitanja", mada mislim da autor te izreke nije imao i mene u vidu...
Citat:
Ivan Dimkovic:
Ali nije problem proceduralno generisati neuronsko "drvo" na GPU-u, sa slajderom ili konfiguracionom opcijom kako zelis da se grana (ima cak i jako lepih radova na tu temu kako proceduralno generisati realno izgledajuce neurone cak mislim da smo i diskutovali o tome ovde: http://www.elitesecurity.org/p3223987, doduse ne za GPU vec uopste ali portovati to na shader ne smatram problemom vec samo pitanjem programerskog vremena).
Ne znam kako svaki put shvatiš da ti predlažem nešto proceduralno, kosu i drvo nisam naveo zbog načina na koji ih generišu, već zbog složenosti, velikog broja objekata na sceni i onog što sledi posle, zbog rendera, mislim da se ne radi kako si ti opisao da se prvo crtaju udaljeniji objekti pa onda bliži, nego i za njih važi da se oni objekti koji se ne vide iz ugla posmatranja nikad ni ne iscrtavaju, ovo nisam 100% siguran pa me ne moraš držati za reč.
Citat:
Problem je ako zelis da tacno predstavis gde ti se neka sinapsa nalazi,
A kako ti znaš gde ti se neka sinapsa tačno nalazi??? Ja sam stekao utisak da sa onog skenera dobijaš 1^3 mm kockice ali za njih samo info da li su "short" neuroni (masa) ili snop neurona prolazi kroz taj deo prostora? To nisu tačne pozicije sinapsi?
Citat:
onda moras da kodiras njenu poziciju u 3D prostoru. Imas ih 4 milijarde npr. u simulaciji, i to je puno podataka. Kao sto rekoh, mozes malo da se izvuces pa da ne kodiras sinapsu kao 3 float-a, ja je vec kodiram kao 3 short-a (16-bitna fixed pointa) a verovatno moze jos malo da se ustedi ako se zna da su sve relativno blizu referentne tacke (grane od "drveta") pa mozda i 8-bitna preciznost moze da prodje (znaci 24 bita po 3D poziciji).
Ako već dobijaš pozicije od nekud, te pozicije su nekako zabeležene, sa nekim nivoom preciznosti, kako onda smeš da toliko redukuješ preciznost?
Citat:
Ako im ne kodiras pozicije vec neke proceduralne parametre sa kojima generises celo "drvo" ili "sumu", onda varas, ne renderujes simulaciju vec "simulaciju simulacije", sto je isto OK ako mene pitas za neki drugi projekat, moze biti i vrlo zanimljivo,
Sad bi se sporečkali ali da ne tupim, ako imaš flašu vode i daš 10 ljudi da urade simulacije te flaše, i oni urade 10 različitih simulacija, svaku od njih možeš da proglasiš za "simulaciju simulacije" jer će više ličiti međusobno nego bilo koja od njih na original, možeš samo da tvrdiš da je neka preciznija simulacija od neke druge...ali dobro skontao sam da ti težiš što većoj biološkoj doslednosti ili već koji si termin upotrebio.
Citat:
ali nije problem koji resavam ovde.
Kad smo već kod te sitnice, detalja, koji ti tačno problem rešavaš tu? :)
Citat:
Trenutno je jos jedna usteda ta da se smatra da su sinapse "nedaleko" od grane kompartmenta pa se ne kodiraju individualne pozicije sinapsi vec "samo" grana kompartmenta (grana) neurona, ali i to je i dalje jako puno podataka (jedan neuron ima i preko 200 kompartmenta ako simulacija radi u multi-compartment modu koji pravi realisticne neurone, u single-compartment modu su "neuroni" samo "tacke"). Ali zapravo najveci podatak su indeksi koji kazu sta treba da se crta (linija od tacke A do tacke B, itd.).
Možda bi mogao da razmisliš da napišeš kraći rečnik manje poznatih reči i izraza naročito za neurološki deo, u medjuvremenu sam pročitao celu temu (i dalje frapiran šta si sve uradio) ali neću biti prvi koji kaže da se ovo teško uopšte prati...pročitao a i dalje na primer ne znam šta je kompartment? Deo ili tačka odakle polaze grupa dendrita, akson...?
Zar nisu za raznorazne indekse tata-mate oni što se bave bazama podataka? Da li bi išta promenilo ako koordinatni početak smestiš u centar mozga? Sve projekcije su ti čini mi se iz perspektive, i ona kocka sa prve strane teme je izometriski deformisana, možda bi bilo zgodno top view za korteks, right za korpus, front za talamus? Ti pogledi nisu izometrijski već kao projekcija na ravan...
[ MajorFatal @ 03.12.2018. 02:22 ] @
Citat:
Ivan Dimkovic:
Alternativno resenje je mozda redukcija preciznosti - tipa kodiras lokaciju neurona i kompartmenta, a sinapse okolo kodiras kao, npr. 8-bitne fixed-point brojeve. Onda imas 24 bita za indeks neurona (ciju lokaciju i ovako i onako cuvas) i 24 bita za indeks sinapsi, ukupno 48 bita, umesto 96 bita za kompletnu lokaciju sinapse (3x32). Znaci oko 50% ustede, samo sto onda moras u shaderu to da otpakujes, gledas tabele lokacija neurona i sl.... ajde da je usteda 10x pa da ima smisla cimati se ali za 2x... pa nije bas neki posao :)
Da nisi nešto zeznuo ovde, u prvom slučaju računaš neuron i kompartment plus sinapse, a u drugom samo sinapse, ako je u drugom slučaju sinapse 96 plus neuron i kompartment još 32 onda je to 128, u odnosu na 48 ~2,5x tj. 1/4, nije isto čekati render 4 sata ili 1 sat? :)
[ Ivan Dimkovic @ 03.12.2018. 08:35 ] @
Citat:
MajorFatal:
Rukovodiću se onom da "nema glupih pitanja", mada mislim da autor te izreke nije imao i mene u vidu...
Citat:
Ivan Dimkovic:
Ali nije problem proceduralno generisati neuronsko "drvo" na GPU-u, sa slajderom ili konfiguracionom opcijom kako zelis da se grana (ima cak i jako lepih radova na tu temu kako proceduralno generisati realno izgledajuce neurone cak mislim da smo i diskutovali o tome ovde: http://www.elitesecurity.org/p3223987, doduse ne za GPU vec uopste ali portovati to na shader ne smatram problemom vec samo pitanjem programerskog vremena).
Ne znam kako svaki put shvatiš da ti predlažem nešto proceduralno, kosu i drvo nisam naveo zbog načina na koji ih generišu, već zbog složenosti, velikog broja objekata na sceni i onog što sledi posle, zbog rendera, mislim da se ne radi kako si ti opisao da se prvo crtaju udaljeniji objekti pa onda bliži, nego i za njih važi da se oni objekti koji se ne vide iz ugla posmatranja nikad ni ne iscrtavaju, ovo nisam 100% siguran pa me ne moraš držati za reč.
Razumeo sam ja tebe sta predlazes (bar mislim da jesam), ali mislim da je za veliki broj podataka radjenje eliminacije onoga sta ce biti vidjeno izuzetno ogroman posao sam po sebi, i bio bio radjen na CPU (nemas memoriju).
OK, to imalo smisla ako zadas fiksni "FOV" i ne setas kameru, vec se jednom pre-kalkulise nivo detalja i samo ti neuroni se renderuju, sto i nije losa dodatna opcija (dodacu je :-)
Citat:
Citat:
Problem je ako zelis da tacno predstavis gde ti se neka sinapsa nalazi,
A kako ti znaš gde ti se neka sinapsa tačno nalazi??? Ja sam stekao utisak da sa onog skenera dobijaš 1^3 mm kockice ali za njih samo info da li su "short" neuroni (masa) ili snop neurona prolazi kroz taj deo prostora? To nisu tačne pozicije sinapsi?
Generator mreze, simulator i vizualizator su tri razlicite komponente.
To sto generator generise pozicije sinapse relativno slucajno i proceduralno na onsnovu (relativo) nepreciznih MRI podataka i podataka iz literature o grananju neurona i gustine i tipa sinapsi ne znaci da u buducnosti to nece biti 100% tacno skenirana mreza.
Zbog toga neko proceduralno generisanje neurona u vizualizatoru nije smisleno, njegov posao je da tacno renderuje ono sto si mu poslao da renderuje, bez obzira na to kako je to nastalo.
Citat:
Citat:
onda moras da kodiras njenu poziciju u 3D prostoru. Imas ih 4 milijarde npr. u simulaciji, i to je puno podataka. Kao sto rekoh, mozes malo da se izvuces pa da ne kodiras sinapsu kao 3 float-a, ja je vec kodiram kao 3 short-a (16-bitna fixed pointa) a verovatno moze jos malo da se ustedi ako se zna da su sve relativno blizu referentne tacke (grane od "drveta") pa mozda i 8-bitna preciznost moze da prodje (znaci 24 bita po 3D poziciji).
Ako već dobijaš pozicije od nekud, te pozicije su nekako zabeležene, sa nekim nivoom preciznosti, kako onda smeš da toliko redukuješ preciznost?
Smes da redukujes preciznost zato sto su sinapse relativno malo udaljene od centra "drveta" (reda velicine max 0.1 mm) pa mozes da prodjes sa nizom preciznosti zato sto kao referentnu tacku koristis centar njihovog "partent" drveta.
Citat:
Ako im ne kodiras pozicije vec neke proceduralne parametre sa kojima generises celo "drvo" ili "sumu", onda varas, ne renderujes simulaciju vec "simulaciju simulacije", sto je isto OK ako mene pitas za neki drugi projekat, moze biti i vrlo zanimljivo,
Sad bi se sporečkali ali da ne tupim, ako imaš flašu vode i daš 10 ljudi da urade simulacije te flaše, i oni urade 10 različitih simulacija, svaku od njih možeš da proglasiš za "simulaciju simulacije" jer će više ličiti međusobno nego bilo koja od njih na original, možeš samo da tvrdiš da je neka preciznija simulacija od neke druge...ali dobro skontao sam da ti težiš što većoj biološkoj doslednosti ili već koji si termin upotrebio.
Citat:
Citat:
ali nije problem koji resavam ovde.
Da.
Citat:
Kad smo već kod te sitnice, detalja, koji ti tačno problem rešavaš tu? :)
Sto brza simulacija modernih modela neurona, generator mreze i vizualizator su samo dodatne alatke za validaciju ovog prvog.
Citat:
Citat:
Trenutno je jos jedna usteda ta da se smatra da su sinapse "nedaleko" od grane kompartmenta pa se ne kodiraju individualne pozicije sinapsi vec "samo" grana kompartmenta (grana) neurona, ali i to je i dalje jako puno podataka (jedan neuron ima i preko 200 kompartmenta ako simulacija radi u multi-compartment modu koji pravi realisticne neurone, u single-compartment modu su "neuroni" samo "tacke"). Ali zapravo najveci podatak su indeksi koji kazu sta treba da se crta (linija od tacke A do tacke B, itd.).
Možda bi mogao da razmisliš da napišeš kraći rečnik manje poznatih reči i izraza naročito za neurološki deo, u medjuvremenu sam pročitao celu temu (i dalje frapiran šta si sve uradio) ali neću biti prvi koji kaže da se ovo teško uopšte prati...pročitao a i dalje na primer ne znam šta je kompartment? Deo ili tačka odakle polaze grupa dendrita, akson...?
Zar nisu za raznorazne indekse tata-mate oni što se bave bazama podataka? Da li bi išta promenilo ako koordinatni početak smestiš u centar mozga? Sve projekcije su ti čini mi se iz perspektive, i ona kocka sa prve strane teme je izometriski deformisana, možda bi bilo zgodno top view za korteks, right za korpus, front za talamus? Ti pogledi nisu izometrijski već kao projekcija na ravan...
Najprostije, ako neuron gledamo kao drvo, kompartment je "grana" - ta trana moze biti dendrit ili deo aksona (zamisli dendrit kao granu drveta a akson kao granu korena, recimo). Sinapsa je veza izmedju 2 kompartmenta 2 razlicita drveta.
Sto se projekacija tice, ali ti uvek pocinjes uvek od istih kompletnih 3D podataka, a onda ih projektujes u zavisnosti od pogleda kamere itd. To graficka kartica zapravo najefikasnije transformise.
[ Ivan Dimkovic @ 03.12.2018. 08:49 ] @
Citat:
MajorFatal:
Citat:
Ivan Dimkovic:
Alternativno resenje je mozda redukcija preciznosti - tipa kodiras lokaciju neurona i kompartmenta, a sinapse okolo kodiras kao, npr. 8-bitne fixed-point brojeve. Onda imas 24 bita za indeks neurona (ciju lokaciju i ovako i onako cuvas) i 24 bita za indeks sinapsi, ukupno 48 bita, umesto 96 bita za kompletnu lokaciju sinapse (3x32). Znaci oko 50% ustede, samo sto onda moras u shaderu to da otpakujes, gledas tabele lokacija neurona i sl.... ajde da je usteda 10x pa da ima smisla cimati se ali za 2x... pa nije bas neki posao :)
Da nisi nešto zeznuo ovde, u prvom slučaju računaš neuron i kompartment plus sinapse, a u drugom samo sinapse, ako je u drugom slučaju sinapse 96 plus neuron i kompartment još 32 onda je to 128, u odnosu na 48 ~2,5x tj. 1/4, nije isto čekati render 4 sata ili 1 sat? :)
Cek da proverimo (plus, zaboravio sam jedan broj: indeks kompartmenta u neuronu), originalni slucaj:
1. Slucaj A: Sinapse kodiramo kao zasebne 3D float-ove: 3 x 32 bita = 96 bita
- Ukupno: 96 bita po sinapsi
^ Obrati paznju, 3D pozicija neurona/kompartmenta se ne racuna u ovom slucaju zato sto nam ona treba i ovako i onako za druge stvari i MORA biti u mrezi, ne mozemo da je eliminisemo
2. Slucaj B: Sinapse kodiramo kao:
- Indeks neuona (24 bita) + indeks kompartmenta u neuronu (8 bita) = 32 bita
- Relativnu 3D poziciju sinapse u odnosu na centar kompartmenta: 3 x 8 bita = 24 bita (kako bi znao kako da izvedes pune 3D koordinate)
- Ukupno: 56 bita po sinapsi
Znaci, usteda 1.71x, manje od 2x
ALI mogli bi da se posluzimo jos jednim trikom, posto ima vise sinapsi po kompartmentu mogli bi smo podatke da pakujemo kao [INDEKS NEURONA + KOMPARTMENTA = 32 BITA] [NIZ KOORDINATA SINAPSI 24 BITA] - i time ustedimo mnogo vece ustede ako je broj sinapsi veliki, a broj moze biti par desetina sinapsi na malim simulacijama, preko vise stotina ako hocemo da simuliramo neurone 1:1 sa brojem sinapsi.
Problem je sto u tom slucaju shader na grafickoj mora da radi malo drugacije, tj. da "otpakuje" sve sinapse u nizu pre crtanja kompartmenta (samo tad zna ko je "parent" sinapse radi rekonstrukcije 3D pozicije) , nije nemoguce ali IMHO ovo mi, onako, 'sac metodom' zvuci kao bar nekoliko dana full-time posla.
[ Ivan Dimkovic @ 03.12.2018. 14:30 ] @
Btw, preview is nove verzije, evo kako izgleda tabela "cene" pristupa stranoj NUMA memoriji.
Vrednosti su relativne (1.0 je najbrzi pristup), kada vidite da je pristup istom NUMA nodu malo veci od 1.0 (tipa 1.05), to je zato sto merenje nije savrseno, OS je mozda prekinuo proces interaptom i sl. Ali razlike izmedju stranih nodova su mnogo vece nego greske u merenju.
Matrica je [M][N] gde su M=N broj NUMA nodova a vrednosti su relativno "kostanje" pristupa memoriji u M nodu iz noda N (i obrnuto)
Sistem je Amazonova R5a masina sa 96 EPYC jezgara, kada vidite da pristup
Kao sto se vidi, na ovakvom sistemu su pristupi memoriji ponekad >vrlo< skupi ako se nalazite u dalekom NUMA nodu.
Sledeca verzija DC-a ce uzimati i ovo u obzir (uzimala je i ranije u smislu da je prvo procesirala lokalne podatke a onda strane, ali bez sortiranja stranih po vremenu pristupa).
[ Ivan Dimkovic @ 03.12.2018. 21:17 ] @
Tragajuci za nekim performance bug-om koji kaci 4S (a mozda i 8S, ko zna) Haswell E7 Xeon-e (Amazon nudi x32 konfiguraciju sa 128 CPU-ova) sam ukapirao da Linux ima bolju podrsku za NUMA-u od Windows-a.
Naime, Linux ima libnuma-u koja ima sve korisne API-je, ukljucujuci i informacije o "ceni" pristupa sa noda na nod + vazno koliko fizicke memorije je zakaceno na koji NUMA nod. Zasto je ovo bitno? Pa da bi recimo znali kako da raspodelite niti tako da optimalan broj njih cita "stranu" memoriju (jako skupo) na procesorima koji nemaju dovoljno svoje da budu zauzeti 100% vremena.
Windows nema taj ekvivalent (nema ni ekvivalent "cene" pristupa iz noda X u noda Y i zvanican savet im je da parsirate ACPI tabelu (!!!).
Ili bar ja ne mogu da ga nadjem, a verujte mi da sam trazio detaljno :( Jedino priblizno sto postoji je neki Hyper-V performance counter sa kojim mogu da izracunam koliko fizickih stranica pripada kojem NUMA nodu i time dobijem otprilike RAM "sliku", ali to radi samo ako je masina pod Hyper-V hipervizorom... Jedini drugi nacin koji mi pada na pamet je da sam enumerisem hardver i provalim koji DRAM stick je prikacen na koji CPU kao sto rade oni hardverski programi poput HwInfo i sl.... ali to mi stvarno ne pada na pamet, plus sto niko ne garantuje da ce to da radi u buducnosti :(
Takodje, na tom Amazon sistemu je Windows prijavljena NUMA topologija (koji core-ovi pripadaju kojem nodu) potpuno drugacija od Linux topologije i imam jako cudne probleme sa performansama koji mi deluju kao da CPU-ovi pristupaju pogresnoj memoriji (stranoj, ne lokalnoj).
Sve u svemu, ako budem ikad pisao nesto novo ovakvog tipa, Linux (tj. cross-platform) ce biti glavna platforma.
Pretpostavljam da Microsoftova ekipa koja pise MS SQL server ima pristup gomili internih API-ja i u kernelu koji im daju sve sto treba.
[Ovu poruku je menjao Ivan Dimkovic dana 03.12.2018. u 22:29 GMT+1]
[ MajorFatal @ 05.12.2018. 02:19 ] @
Citat:
Ivan Dimkovic:
Ali nije problem proceduralno generisati neuronsko "drvo" na GPU-u, sa slajderom ili konfiguracionom opcijom kako zelis da se grana (ima cak i jako lepih radova na tu temu kako proceduralno generisati realno izgledajuce neurone cak mislim da smo i diskutovali o tome ovde: http://www.elitesecurity.org/p3223987, doduse ne za GPU vec uopste ali portovati to na shader ne smatram problemom vec samo pitanjem programerskog vremena).
Pisao si o tome da se približavaju po performansama GPU i CPU, ne postoji varijanta da važnije delove i puteve odradiš kao i do sad, a onda ostatak prostora popuniš ovako proceduralno, ako su ljudi već isproveravali sve i ponaša se zadovoljavajuće?
Citat:
Razumeo sam ja tebe sta predlazes (bar mislim da jesam), ali mislim da je za veliki broj podataka radjenje eliminacije onoga sta ce biti vidjeno izuzetno ogroman posao sam po sebi, i bio bio radjen na CPU (nemas memoriju).
Valjda sam nekad negde pročitao da se "svodi" na proveru da li su dva objekta na istoj liniji pogleda?
Citat:
Generator mreze, simulator i vizualizator su tri razlicite komponente.
To sto generator generise pozicije sinapse relativno slucajno i proceduralno na onsnovu (relativo) nepreciznih MRI podataka i podataka iz literature o grananju neurona i gustine i tipa sinapsi ne znaci da u buducnosti to nece biti 100% tacno skenirana mreza.
Zbog toga neko proceduralno generisanje neurona u vizualizatoru nije smisleno, njegov posao je da tacno renderuje ono sto si mu poslao da renderuje, bez obzira na to kako je to nastalo.
Jasno ko dan, hvala, mada to će biti neka daleka budućnost al ajd...
Citat:
Smes da redukujes preciznost zato sto su sinapse relativno malo udaljene od centra "drveta" (reda velicine max 0.1 mm) pa mozes da prodjes sa nizom preciznosti zato sto kao referentnu tacku koristis centar njihovog "parent" drveta.
Sad mi opet nešto nije jasno, ovde pominješ centar "parent" drveta, a u jednom od narednih komentara centar kompartmenta u istom kontekstu - kao orijentir za poziciju sinapse?
Citat:
Sto brza simulacija modernih modela neurona, generator mreze i vizualizator su samo dodatne alatke za validaciju ovog prvog.
Hm, da si to hteo napravio bi nekoliko modela super brzih simulacija nekih neurona, piramidalnih, vretenastih itd i rekao bi super su, meni sve ovo deluje kao simulacija rada glavnog dela centralnog nervnog sistema - velikog mozga?
Citat:
Trenutno je jos jedna usteda ta da se smatra da su sinapse "nedaleko" od grane kompartmenta pa se ne kodiraju individualne pozicije sinapsi vec "samo" grana kompartmenta (grana) neurona, ali i to je i dalje jako puno podataka (jedan neuron ima i preko 200 kompartmenta ako simulacija radi u multi-compartment modu koji pravi realisticne neurone, u single-compartment modu su "neuroni" samo "tacke"). Ali zapravo najveci podatak su indeksi koji kazu sta treba da se crta (linija od tacke A do tacke B, itd.).
Zar nisu sinapse uvek na kraju kompartmenta, u tom slučaju tačka B je uvek ujedno i pozicija sinapse? Ako sinapse crtaš (pozicioniraš) relativno u odnosu na kompartment zar ne možeš isto tako kompartmente u odnosu na jezgro nervne ćelije, tj. kraj aksona tj...
Za kraj naravno najgluplje pitanje: ako postoje delovi mozga koji su ispunjeni short neuronima, pa u tom delu završi kraj nekog aksona i opali impuls, a ako ovi prenose signale kako je rečeno, zar ne bi trebalo efekat da bude da se signal prostire na sve strane radijalno, kao kad se raketa od vatrometa rasprsne na noćnom nebu? Pregledao sam par animacija koje si priložio i to nisam video?
Deluje da nedostaju i vijuge, znam da ne voliš frenologiju ali pametnije životinje - više vijuga po jedinici površine korteksa, navodno, ipak mu to dodju kao neke prepreke za prostiranje signala, ili bar kašnjenje?
[ MajorFatal @ 05.12.2018. 03:31 ] @
Citat:
128, u odnosu na 48 ~2,5x tj. 1/4
Dobro je da niko nije primetio moju "preciznu" računicu, imam samo dve greške u istom redu, verovatno se potiru, znači da još uvek nisam zarđao :)
Citat:
Cek da proverimo (plus, zaboravio sam jedan broj: indeks kompartmenta u neuronu), originalni slucaj:
1. Slucaj A: Sinapse kodiramo kao zasebne 3D float-ove: 3 x 32 bita = 96 bita
- Ukupno: 96 bita po sinapsi
^ Obrati paznju, 3D pozicija neurona/kompartmenta se ne racuna u ovom slucaju zato sto nam ona treba i ovako i onako za druge stvari i MORA biti u mrezi, ne mozemo da je eliminisemo
Mora biti ali i zauzima prostor i trebalo bi da se renderuje, znači 96 + 32 = 128, ne možeš da je eliminišeš ni u "Slučaju B" pa je računaš?
Citat:
2. Slucaj B: Sinapse kodiramo kao:
- Indeks neuona (24 bita) + indeks kompartmenta u neuronu (8 bita) = 32 bita
- Relativnu 3D poziciju sinapse u odnosu na centar kompartmenta: 3 x 8 bita = 24 bita (kako bi znao kako da izvedes pune 3D koordinate)
- Ukupno: 56 bita po sinapsi
Znaci, usteda 1.71x, manje od 2x
Ovde pozicije sinapsi gledaš relativno u odnosu na centar kompartmenta, a par komentara iznad si u odnosu na centar njihovih "parent" drveta (može biti da misliš na isto, ali zbunjuje). Ako kompartmente iscrtavaš uvek istim redosledom za svaki pojedinačni neuron u odnosu na apsolutne koordinate (ose 3D prostora) a sinapse su uvek na kraju kompartmenta, i kompartmenti uvek približno iste dužine, možeš možda da završetak kompartmenta proglasiš za tačnu lokaciju sinapse, ili još brže da indekse kompartmenta direktno transformišeš u 3D koordinate sinapsi (po određenom pravilu i u opsegu ili obliku koji dozvoliš)? Tad bi lokacije sinapsi bile 32, u odnosu na 96 tri puta manje?
Citat:
ALI mogli bi da se posluzimo jos jednim trikom, posto ima vise sinapsi po kompartmentu mogli bi smo podatke da pakujemo kao [INDEKS NEURONA + KOMPARTMENTA = 32 BITA] [NIZ KOORDINATA SINAPSI 24 BITA] - i time ustedimo mnogo vece ustede ako je broj sinapsi veliki, a broj moze biti par desetina sinapsi na malim simulacijama, preko vise stotina ako hocemo da simuliramo neurone 1:1 sa brojem sinapsi.
Problem je sto u tom slucaju shader na grafickoj mora da radi malo drugacije, tj. da "otpakuje" sve sinapse u nizu pre crtanja kompartmenta (samo tad zna ko je "parent" sinapse radi rekonstrukcije 3D pozicije) , nije nemoguce ali IMHO ovo mi, onako, 'sac metodom' zvuci kao bar nekoliko dana full-time posla.
Pa ako može...
[ MajorFatal @ 05.12.2018. 03:37 ] @
Citat:
128, u odnosu na 48 ~2,5x tj. 1/4
Dobro je da niko nije primetio moju "preciznu" računicu, imam samo dve greške u istom redu, verovatno se potiru, znači da još uvek nisam zarđao :)
Citat:
Cek da proverimo (plus, zaboravio sam jedan broj: indeks kompartmenta u neuronu), originalni slucaj:
1. Slucaj A: Sinapse kodiramo kao zasebne 3D float-ove: 3 x 32 bita = 96 bita
- Ukupno: 96 bita po sinapsi
^ Obrati paznju, 3D pozicija neurona/kompartmenta se ne racuna u ovom slucaju zato sto nam ona treba i ovako i onako za druge stvari i MORA biti u mrezi, ne mozemo da je eliminisemo
Mora biti ali i zauzima prostor i trebalo bi da se renderuje, znači 96 + 32 = 128, ne možeš da je eliminišeš ni u "Slučaju B" pa je računaš?
Citat:
2. Slucaj B: Sinapse kodiramo kao:
- Indeks neuona (24 bita) + indeks kompartmenta u neuronu (8 bita) = 32 bita
- Relativnu 3D poziciju sinapse u odnosu na centar kompartmenta: 3 x 8 bita = 24 bita (kako bi znao kako da izvedes pune 3D koordinate)
- Ukupno: 56 bita po sinapsi
Znaci, usteda 1.71x, manje od 2x
Ovde pozicije sinapsi gledaš relativno u odnosu na centar kompartmenta, a par komentara iznad si u odnosu na centar njihovih "parent" drveta (može biti da misliš na isto, ali zbunjuje). Ako kompartmente iscrtavaš uvek istim redosledom za svaki pojedinačni neuron u odnosu na apsolutne koordinate (ose 3D prostora) a sinapse su uvek na kraju kompartmenta, i kompartmenti uvek približno iste dužine, možeš možda da završetak kompartmenta proglasiš za tačnu lokaciju sinapse, ili još brže da indekse kompartmenta direktno transformišeš u 3D koordinate sinapsi (po određenom pravilu i u opsegu ili obliku koji dozvoliš)? Tad bi lokacije sinapsi bile 32, u odnosu na 96 tri puta manje?
Citat:
ALI mogli bi da se posluzimo jos jednim trikom, posto ima vise sinapsi po kompartmentu mogli bi smo podatke da pakujemo kao [INDEKS NEURONA + KOMPARTMENTA = 32 BITA] [NIZ KOORDINATA SINAPSI 24 BITA] - i time ustedimo mnogo vece ustede ako je broj sinapsi veliki, a broj moze biti par desetina sinapsi na malim simulacijama, preko vise stotina ako hocemo da simuliramo neurone 1:1 sa brojem sinapsi.
Problem je sto u tom slucaju shader na grafickoj mora da radi malo drugacije, tj. da "otpakuje" sve sinapse u nizu pre crtanja kompartmenta (samo tad zna ko je "parent" sinapse radi rekonstrukcije 3D pozicije) , nije nemoguce ali IMHO ovo mi, onako, 'sac metodom' zvuci kao bar nekoliko dana full-time posla.
Pa ako može...
[ Ivan Dimkovic @ 09.12.2018. 01:21 ] @
Evo mali preview kako nova verzija radi i na cloud sistmima:
Kao sto se vidi, performanse drasticno variraju cak i kad je arhitektura / broj alociranih vCPU-ova isti. Razlog je verovatno u drugacijim hardverskim topologijama pravog (hipervizora) sistema i nacin na koji hipervizor onda deli fizicki hardver. Amazonove Skylake VM performanse sa 96 jezgara su mozda najblize "bare metalu" sto mozete imati.
Google je ocajan, mada verujem da je njihov cilj sasvim drugi - optimizacija za mikro servere koji nisu toliko osetljivi na latenciju memorije i broj hop-ova koje ce CPU morati izvesti da dodje do podataka, nego zakupis gomilu single-CPU mini servercica i svaki vrti neki mikro servisic i to je to.
v1.33 - Released on December 8th 2018
------------------------------------------------------------------------
* Added new server benchmark for HEDT/Workstations and large servers
(spikebenchmark_v104_ws_server.bat, using Demo1mBench.xml)
* Please note that the output CSV format of the benchmark tool has
been updated (description of the columns will be in the first
row of the CSV file)
* Minimum OS is now Windows 7 x64 / Windows Server 2008 R2 x64
Windows XP and Windows Vista support has been deprecated as well
as support for 32-bit Operating Systems
* Improved CPU work scheduling algorithm, taking into account the
NUMA systems with more than two nodes where access cost between the
nodes might not be identical. At the beginning of every DigiCortex
simulation, a small benchmark (taking few seconds) will be performed
to measure relative NUMA to NUMA node memory access cost.
This change impacts only NUMA systems with e.g. different routing
costs between CPU X and CPU Y
* CPU work scheduling has been improved to take into account
CPU cache hierarchies more when performing work stealing
Btw, ko ima jaku makinu moze da pokrene spikebenchmark_v104_ws_server.bat i podeli rezultate (spikebenchmark_bench_results.txt), posebno bi mi bili zanimljivi 1S sistemi sa puno jezgara kao sto su AMD Threadripper ili Intelova nova HEDT ponuda.
Lep projekat koji omogucava skracivanje duzine skeniranja vise puta (odilicno i za poacijente i institucije). Ciljna grupa su MRI skenovi koje zelis da zavrsis u sto kracem vremenu u odgovarajucem kvalitetu.
Koliko vidim, ovaj algoritam koristi AI algoritme da popuni nedostajuce k-space podatke verovatno pristupom slicnim koji se vec neko vreme koristi za denoising/resizing fotografija i video slika, samo treniran na drugacijem datasetu.
Na zalost mislim da taj pristup nece pomoci cilju rekonstukcije neuronskog konektoma - za to su potrbeni pravi a ne interpolirani podaci, a takodje trenutna MRI rezolucija je daleko iznad rezolucije individualnih neurona, pitanje je da li ce ikada i biti takvih mogucnosti.
Tako da je danas jedini nacin za za mapiranje individualnih neuronskih karakteristika slajsovanje smrznitih tkiva, elektronska mikroskopija i post-procesiranje kako bi se iz slika sa 'slajsova' formirali 3D modeli neurona i sinapsi.
v1.35 - Released on December 22nd 2018
------------------------------------------------------------------------
* Added support for more than 64 CPUs/threads for dMRI-based axonal
fiber tracking (based on DSI Studio library)
* Added support for more than 64 CPUs/threads for generation of high
detail 3D geometry (-wireframe mode)
* Added more verbose progress tracking for simulation generation with
simulations containing large number of neurons, thus potentially
reducing confusion that the simulation generation process is "stuck"
Nista posebno, samo neke sitne optimizacije /dorade.
ALI, zaboravih da kazem, kod verzije 1.33, gde je ukinuta podrska za 32-bita, Windows XP i Vistu, na zalost, prestala je da radi i Wine podrska na Linuxu :(
Razlog je zato sto Wine nema implementirane neke od kljucnih Windows Kernel32 API-ja vezanih za grupe procesora (podrska za vise od 64 procesora) i NUMA nodova. Kapiram da to nije ni ciljna grupa Wine korisnika tako da ih cela stvar ne zanima previse (pretpostavljam da bi mogla da se uradi, da ima zelje i vremena).
Dosadasnje verzije DigiCortex-a su imale "Wine" workaround koji je sistem, prakticno, tretirao kao Windows XP, ali sa uklanjanjem XP podrske je i ovaj kod izbacen, a sa novom verzijom work scheduler-a se stvarno prevorio u pakao za odrzavanje (jel XP, nije XP, jel Server 2008 R2, Wine...).
Tako da, sorry Linux korisnici, sledeci put kad budem pisao ovakav kod pocece od native Linux/POSIX baze.
[ MajorFatal @ 25.12.2018. 18:58 ] @
Hteo sam da skinem v 1.32 jer je to valjda poslednja verzija koja radi na XP, prvo kod mene piše v 1.25 alfa, drugo ništa ne radi, ni na 'c' mi ne izbacuje onaj toolbox, i imaš grešku već na uvodnom ekranu piše Start Simulatoin umesto Simulation, verovatno zbog te greške ne možeš da postigneš real time rendering :)
[ Ivan Dimkovic @ 28.12.2018. 09:05 ] @
Taj "IDE" je stvarno alpha, zapravo pre-alpha (i verzija IDE-a kasni za verzijom "engine"-a) - hvala na gramatickoj ispravci, glavni interfejs je zapravo komandna linija. Nisam odavno testirao nista na XP-u tako da ne mogu da garantujem da nema nekih drugih problema.
Ali ako hoces da probas IDE, pre startovanja simulacije moras da otvoris neki projekat sa file/open, recimo DemoSmall.xml - simulacija ce se ucitati, i startovace se sama.
Onda mozes, recimo, da pritisnes 'm' na tastaturi da ukljucis slucajnu aktivaciju sinapsi (sto se desava i u "pravim" mozgovima) ili da sa slajderima na eksperimentalnom panelu pobudjujes odredjene delove korteksa ili mozdanog stabla). Kada simulirani "mozak" postane aktivan, mozes u donjem desnom prozoru (simulirani fMRI) da izaberes neuron ciju aktivnost zelis da pratis.
Sa up/down tasterima na tastaturi pomeras MRI "slajs" u Z-osi tako da mozes da dodjes do dela koij te zanima. Na zalost zumiranje ili selekcija specificnih neurona nisu implementirani jos.
[ MajorFatal @ 31.12.2018. 21:23 ] @
Citat:
Ivan Dimkovic:
- hvala na gramatickoj ispravci,
? Nema na čemu, da čudnog jezika tog Engleskog, znači to se kod njih vodi kao gramatička greška? :)
Hvala tebi za precizna i iscrpna uputstva, radi sve na XP, malo čudno ali radi, deo scene se pojavio tek kad sam krenuo da isključim program, a program se tad nije isključio nego tek iz sledećeg puta. Aj da kažemo da sam i ja skapirao da je vizuelizacija najmanje bitan deo, pravio sam neke scene za sebe sa 4000 objekata mnogo više poligona, vreme rendera jednog jedinog frejma varira od 0,08 sekundi do 4 minuta u zavisnosti koji sve rej trejsinzi, anti alijansizi i slično su uključeni ili isključeni i sa koliko zrakova, koliko prolaza itd...
Kako se vrše eksperimenti iz oblasti koje si naveo da bi mogle da se rade, ako je osoba recimo popila aspirin, ili da nervni sistem nauči nešto i slično? Imao sam neka pitanja i na prethodnoj strani pa kad te ne bude mrzelo posle nove godine...
[ Ivan Dimkovic @ 04.01.2019. 20:21 ] @
Sto se DigiCortex-a tice, eksperimenti koji mogu da se rade su ograniceni i vrlo jednostavni, mozes eliminisati grupe neurona ili njihovih receptora, ukljuciti dodatnu struju u specifican neuron i sl. Modeliranje delovanja lekova zahteva drasticno komplikovaniji model neurona i, verovatno, drugih celija.
Citat:
Ovde pozicije sinapsi gledaš relativno u odnosu na centar kompartmenta, a par komentara iznad si u odnosu na centar njihovih "parent" drveta (može biti da misliš na isto, ali zbunjuje). Ako kompartmente iscrtavaš uvek istim redosledom za svaki pojedinačni neuron u odnosu na apsolutne koordinate (ose 3D prostora) a sinapse su uvek na kraju kompartmenta, i kompartmenti uvek približno iste dužine, možeš možda da završetak kompartmenta proglasiš za tačnu lokaciju sinapse, ili još brže da indekse kompartmenta direktno transformišeš u 3D koordinate sinapsi (po određenom pravilu i u opsegu ili obliku koji dozvoliš)? Tad bi lokacije sinapsi bile 32, u odnosu na 96 tri puta manje?
Mogu, to bi zahtevalo komplikovaniji shader ali bi zahtevalo manje memorije. Nesto za probati kad budem imao vremena.
[ MajorFatal @ 08.01.2019. 11:11 ] @
Ne mogu sad čitati temu iz početka, spominjao si razne vrste neurona koje si modelovao ali ne mogu da se setim da si spomenuo (možda jesi ali dosta naziva je na Engleskom) mislim da ih zovu "račvasti" neuroni ili tako nekako, jedan akson ali se u nekoj tački račva na dva dela, ima ih malo u odnosu na ostale vrste neurona, ali kontam kad su toliko specifični i kad ih je tako malo, moguće da imaju neku specifičnu ulogu, čim se on račva i pronosi (isti) signal do nekih specifičnih delova, može biti da igra ulogu u nekom odlučivanju, ili poređenju na primer ili tako nešto slično...
[ Ivan Dimkovic @ 27.07.2022. 01:09 ] @
Posto je hardver uznapredovao... sneak preview:
Nova verzija ce imati kompletno nov GUI koji vise ne koristi Windows kontrole, vec je sve na GPU-u renderovano. I najnoviji hardver ce se dobro znojati :-)
[ bogdan.kecman @ 27.07.2022. 04:24 ] @
lepo lepo da se ovo i dalje razvija :D .. vidim slobodno vreme prsti :D
btw bilo bi interesantno da umesto "random stimuli" ima neki stimulans koji moze da se prati u odvojenom prozoru, kontam bilo bi zanimljivije... (bese mackin model mozga? ili misonja?)
[ Ivan Dimkovic @ 27.07.2022. 06:42 ] @
Dve nedelje odmora ;-) A sve pocelo tako sto primetih da ima problema na Alder Lake-u (nije procesor kriv nista, nego Windows - koji zakuca program na E jezgra. Inace posle ne znam koliko godina, pa mozda 20 imam situaciju da program uspeva da dovede do isprekidanog zvuka, starije verzije Windows-a to nisu ispoljavale, tacno vidis da se muce sa scheduler-om - a mozda je poslednja osoba koja je znala kod napustila firmu odavno :-)
Onda primetis da nije HIDPI, pa fixujes, pa ti se ne svidja kako crta tekst - i to fixujes (Inter font ftw)... pa matori Win32 UI, to izbacis... onda muzejski OpenGL kod, to zamenis sa #version 430, to je bar 2017 a ne 199x... (ima jos malo tu i tamo glBegin/glEnd, to mora da leti) - sve vreme primecujes i popravljas bagove i tako :)
Btw, sa >1B temena po frejmu ovo je vec debelo uslo u domen gde ray tracing / path tracing moze biti boljih performansi. A ako bi se preslo na ray tracing, onda nema granica kakvi detalji mogu da se rendaju (prakticno skoro "za dzabe" zato sto mozes matemtaickim f-jama da generises geometriju, bez trouglova, ili stilovi tipa fiber-glass efekat, mada to bi kostalo ohoho ako hoces kaustiku).
Citat:
btw bilo bi interesantno da umesto "random stimuli" ima neki stimulans koji moze da se prati u odvojenom prozoru, kontam bilo bi zanimljivije... (bese mackin model mozga? ili misonja?)
Bice :) Sad je jos moguce i imati real-time feed postenijih performansi. Probelm ranije je bio sto si morao da sinhronizujes CPU i GPU (posto takve simulacije radis na GPU svakako) da posaljes frejm od kamere, sto je urnisalo GPU simulaciju - sad bi trebalo da mozes da dopustis da svi sistemi rade asinhrono, sve dok ima dovoljno da konacna simulacija bude 1x real-time.
[ bogdan.kecman @ 27.07.2022. 07:02 ] @
eh docekacu ja te dve nedelje jednom kad zavrsim kucu... docekacu... valjda...
scheduler na dozi je uvek bio problematican za high load, najbolji je bio na solarisu pre tonu godina kada su izbacili onih 200 tredova po procesoru ... ne znam da li je to u medjuvremenu portovano na linux, znam da su sve zivo korisno ovi moji portovali sa solarisa na linux, od dtrace-a pa do raznih sitnica... navodno je to sa win10 trebalo da se fixuje u dozi, bem li ga, nisam ispratio nema se vremena za to...
nego mi je zanimljivo ovo sada sa RT posto nove nvidija karte imaju taj hardwerski RT ... mislim da ovaj moj AMD (RX6900XT) to nema, ima neke "ray accelerators" .. ne znam u cemu je razlika ali svakako bi to bilo interesantno implementirati
Ovo za stimulanse, kapiram da bi bilo zanimljivo cak i da nije realtime i 0.1x bi bilo zanimljivo videti kako reaguje na poznati a ne na random stimulans posebno ono odvojeno recimo stimulansi za oci, usi, dodir/brkove ... ne napisa koji je model mozga, macka ili nesto drugo pisao si vec al 20 strana unazad :)
[ Ivan Dimkovic @ 27.07.2022. 07:43 ] @
Mislim da je ovo drugi tip problema - koji je Microsoft zapravo imao resen kako tako: desktop masina, jak load.
Ali verovatno su mahnito optimizovali sve za ove hibridne procesore (E/P jezgra) i minimalnu potrosnju i s*ebali ko zna sta u procesu. To je jedan od onih momenata kada "f*ck it, let's make a new one" mozda pocinje da zvuci primamljivo :-)
Citat:
nego mi je zanimljivo ovo sada sa RT posto nove nvidija karte imaju taj hardwerski RT ... mislim da ovaj moj AMD (RX6900XT) to nema, ima neke "ray accelerators" .. ne znam u cemu je razlika ali svakako bi to bilo interesantno implementirati
Razlika?
Ovo je real-time path tracing. Ovakve stvari su se renderovale danima po frejmu u ne tako davnoj proslosti. OG GPGPU hardver i nije bio bas idealan za RT, ali sa dodatkom malo dodatne logike i koriscenja tenzorskih procesora se dobijaju rapidne performanse + RT postaje deo "normalnog" render pipeline-a, sto znaci integraciju sa svim ostalim sto se crta na grafickoj.
Samo treba sesti i zagrejati stolicu - stici ce i to posto je to meni kao sudoku, odlaze demenciju ;-)
Citat:
Ovo za stimulanse, kapiram da bi bilo zanimljivo cak i da nije realtime i 0.1x bi bilo zanimljivo videti kako reaguje na poznati a ne na random stimulans posebno ono odvojeno recimo stimulansi za oci, usi, dodir/brkove ... ne napisa koji je model mozga, macka ili nesto drugo pisao si vec al 20 strana unazad :)
- Statistika mikro (sinapticke) povezanosti i populacija neurona koristi podatke sakupljene od macaka (visual cortex) i miseva (barrel cortex)
- Model sinapsi i sinapticke plasticnosti baziran na podacima prikupljenih na pacovima i misevima
- Modeli neurona su trenirani koristeci snimanja raznih celija, raznih zivuljki
- Makro povezanost je bazirana na difuzionim MRI snicima (Up-portovano na 0.76 mm^3 MGH USC dataset, sto je ~8x vise detalja nego ranije*)
- Model retine je macko-ljudski hibrid (zbog dostupnosti podataka) u pitanju je: https://team.inria.fr/biovision/virtualretina/
^ Obratiti paznju, 1.5 mm^3 je bio 'state of the art' pre nekoliko godina a i danas je daleko od klinicke upotrebe.
[ bogdan.kecman @ 27.07.2022. 08:32 ] @
ma znam za RT, nego ne znam u cemu se razlikuje od RA, da li je RA samo amd-ova verzija iste price ili je nesto drugo u pitanju..
Citat:
Mislis na ovo verovatno:
da, to je bilo onda, ali kontam sad si unapredio :D
Citat:
model
mislio sam bas ovo sto je na videu sta je u "makro povezanost", bila mi u glavni od negde macka ali ... sad je jasno :D
vrh je ovo sve :D
[ Ivan Dimkovic @ 27.07.2022. 09:17 ] @
Thx ;-) Nije unapredjen input posto od kraja 2018 do skoro nisam uopste nista radio na ovom projektu. Ima zilion stvari, moraju u listu prioriteta :)
Btw, Francuzi su skenirali mozak neke pokojne babe na 11.7T naucnom skeneru 6000 sati (hiljada, nije greska) kako bi se dobilo dovoljno podataka za 0.2 mm^3 difuzionu rezoluciju, sto je opet ~8x vise podataka nego trenutno:
Dataset je jos pod embargom, ali cim bude javno objavljen bice testiran i integrisan ako moze.
Citat:
ma znam za RT, nego ne znam u cemu se razlikuje od RA, da li je RA samo amd-ova verzija iste price ili je nesto drugo u pitanju..
Implementacije su drugacije, koliko mi je poznato AMD ima specijalizovani hardver samo za testiranje prolaza zraka kroz trouglove i kvadre, dok prolaz kroz BVH drva izvode kroz genericke shader-e. NVIDIA, sa druge strane, ima specijalizovan hardver i za BVH prolaze sto jako koristi za kompleksne scene, ali uz cenu dodatnih tranzistora.
Dodatni problem generickog pristupa je sto imas vise sanse za blokiranje ostatka grafickog pipeline-a (delis procesore) dok radis raytracing
Taj isti problem je imala NVIDIA sa TUxxx hardverom koji nije imao mogucnost za konkurentni RT i sencenje. Plus, tvrde da su ubrzali intersekcione testove 2x sa Ampere arhitekturom.
NVIDIA je imala i jos trikova u pocetku kao "first mover" kao sto je DLSS+RT sa kojim si mogao da RT-ujes u nizoj rezoluciji bez da to bude puno primetno.
Mozda je ova situacija sada bolja, nisam u toku.
[ bogdan.kecman @ 27.07.2022. 09:25 ] @
super zanimljivi podaci, sa petabajtnim datasetovima na zalost imam iskustva:( ali za grafiku, bem li ga, ja sam toliko out of date sa svom tom tehnologijom, sta da ti kazem da je zadnji opengl koji sam ja pisao radio na ovim masinama:
[ Ivan Dimkovic @ 27.07.2022. 09:30 ] @
E znas kako, matori kod koji izbacujem je upravo iz te ere - ono imao par shadera, ali gomila koda:
Code:
glEnableThis();
glDisableThat();
glBegin(GL_TRIANGLES); // ili jos gore GL_QUADS
glVertex3f(bla bla truc);
glVertex3f(bla bla truc);
To je SGI legacy, mislim super bilo za 80-te i pocetak 90-tih... Nesrecna stvar sa takvim programiranjem (gde je graficki procesor "state machine") je sto poziva na losu strukturu i rastrkavanje svega svuda. Sto kasnije ima glavobolje kao posledice :)
U principu najbolje prebaciti sve na Vulkan - ili bar na cisti moderni GL 4.x (sto i radim sad).
Problem je sto smo svi kao deca ucili OpenGL kako je SGI zamislio :-)))) Ova danasnja deca odmah startuju sa compute shader-ima ili ray tracingom bogtemazo.
[ bogdan.kecman @ 27.07.2022. 09:49 ] @
ja nisam ni znao da moze drugacije od glBegin...glVertex... :D bas cu zdraknem na sta to danas lici taman sam mislio da bi mogao da napravim neki "drugaciji" g-code vizualizer za ove moje masine :D
[ Ivan Dimkovic @ 28.07.2022. 09:52 ] @
Evo kako se to danas radi:
1. Spremi geometriju i uploaduj sve sto mozes sa sto manje batcheva na GPU (idealno, kao DirectStorage zaobilazeci skoro sve sta mozes na CPU-u i dekompresujes na GPU)
2. Sibni sve shadere na GPU, pripremi komande tako da minimizujes broj poziva drajveru i broj PCIe transakcija
Evolucija:
1990-te (kraj): render je state masina, ti sve lagano crtkas malim pozivima za svaku tacku, boju, promenu flag-ova... transformacija i rasterizacija u softveru
1990-te (kraj): isto kao gore, sam sto neki elementi (rasterizacija) ponekad trce na grafickoj kartici
2000-te (pocetak): graficka kartica postaje GPU, pocinje da radi transformaciju geometrije i osvetljenje - i dalje je CPU glavni i orkestrira, graficki prolaz je potpuno fiksan (fixed function pipeline), postepene inovacije po pitanju sencenja (razne mape uz pomoc tekstura za imitaciju senki, vode, ...)
2000-te (sredina): pojava shader-a - pocetci mogucnosti programiranja procesa sencenja, za pocetak kroz per-vertex i per-fragment/pixel procesiranje, a onda polako i mogucnost poboljsnaja nivoa detalja kroz geometrijske shader-e (shader moze da generise nove detalje)
2000-te: (kraj): umesto fisiriranog pipelina je sada sve pod programerskom kontrolom, i dalje imas dosta apstrakcija i mnoge stvari treba da radis na propisan nacin ako hoces performanse, ali mozes i drugacije
2010-te: (pocetak): compute shader-i (dx 2009, ogl 2012) sa kojima imas jos vise fleksibilnosti, nisu deo grafickog pipeline-a ali mozes da ih upotrebljavas u grafici bez dr*anja sa CUDA/OCL/... kontekstima
2010-te: (sredina): primeceno da zbog enormne istorije tradicionalni API-ji imaju limite kad su performanse u pitanju, re-write kroz Vulkan (Khronos), Metal (Apple) i DirectX 12 (Microsoft) - novi API-ji su potpuno GPU-centricni i nizeg nivoa gde programer ima mnogo vise kontrole
2010-te: (kraj): ray/path tracing akcelerisani na GPU, napredni AA algoritmi za upscaling, koriscenje AI/ML za poboljsanje detalja, ...
Za crtanje par trouglova, ovo je verovatno overkill, ali za bilo sta komplikovano je drasticno efikasnije.
I, naravno, mozes da vidis sta klinci (i ne samo klinci) rade sa svim zahebancijama na https://www.shadertoy.com/ - gde mozes sam instant da probas shader-e. Ovo je spiritualni naslednik nekadasnje 4K/64K demo/intro scene :-)
Mozes da editujes shader-e i da ih ucitas (zahvaljujuci WebGL-)
[ bogdan.kecman @ 29.07.2022. 20:24 ] @
Niiiice, bas cu zdraknem :) hvala ... webgl je izgleda bas napredovao
mozda se isplati praviti ovaj viewer za web, ne mora se drndam sa
kompajliranjem na svim os-ovima koje trosim...
Blago deci danas :) Ja sam tu fazu imao pre tik pre pravih 3D kartica (NVIDIA Riva-u 128 sam kupio krajem 1997-me) pa si tad morao pisati rasterizaciju rucno, sto je danas par linija koda u shader-u.
[ bogdan.kecman @ 30.07.2022. 05:59 ] @
hahahah gledam ovaj RT sa kuglama, pisao sam neki app 1989 koji radi
ovo, 2 metalne kugle u metalnoj kutiji... rendao je nekih 19 dana 1
frame :D :D :D eeeeeeeeeeeee
[ Ivan Dimkovic @ 02.08.2022. 01:03 ] @
Jos jedan vikend, jos malo dodataka:
(4K)
- Phong sencenje
- Order-Independent Transparency (za "stakleni" efekat bez z-tuce)
- Floating point teksture*
- SMAA antialiasing (ne koristi se u videu)
- Podrska za hardversko video kodiranje, direkt sa teksture koja izlazi iz render-a (bez da ide na CPU)
A da - i 2 milijarde temena, sto stati na 1 milijardu...
@bogdan.kecman: editor je deo aplikacije, i ovo sto drndam po kodu sto menja vizualizaciju je bilo live :)
[Ovu poruku je menjao Ivan Dimkovic dana 05.08.2022. u 03:31 GMT+1]
[ bogdan.kecman @ 05.08.2022. 15:10 ] @
vrh :D
bilo bi cool da ovaj tuctuc sto ide u pozadini feedujes na audio kortex kao ulazni nadrazaj :D
kad ces ti da bacis ovo na github da moze raja da se igra :D ili mislis da postoji nacin da ovo komercijalizujes? kontam, ako je samo za sprecavanje degradacije neuronskih veza moze bude zanimljivo za sire narodne mase...
[ Ivan Dimkovic @ 06.08.2022. 10:21 ] @
Bice ulaza sa kamere i mikrofona/zvucnika direkt na simulator, samo da stigne :)
Za pocetak ce shaderi biti otvoreni - ubacujem da mogu kompletno da se edituju i menjaju, cak do nivoa da mozes da zahtevas dodatnu memoriju za sebe i da konfigurises sta hoces da dobijes od simulatora. To ce omoguciti vrlo zanimljive efekte.
Ostatak koda, pre svega mislim da nije u stanju da je prezentabilan (cak ga ni ja ne razumem ponekad :-) - ali i to se cisti polako.
Prio 1 je izbacivanje zavisnosti od Windows API-ja i UI-ja (ovo je skoro gotovo).
btw, znam nekoliko odlicnih projekata koji su umrli jer dev nije hteo da ih podeli dok "ne sredi kod, sada je mnogo ruzan" i onda se desilo nesto i jbg ... (jedan od takvih projekata je moj, meni se desio pozar i nestanak 30 godina projekata, dokumenata, slika ... ostalo mi je samo ono sto je bilo dostupno i on-line .... tu je bilo min 2 odlicna projekta od kojih su mnogi mogli da imaju koristi ali "samo jos jednom da refaktorisem i dicicu online") ... sada je drugo vreme, on-line backup nije skup, internet je brz..
elem, taman si mi sad dao dovoljno informacija da nemam vise izgovora da odlazem ovaj vizualizator za g-code :D :D :D
[ dejanet @ 06.08.2022. 11:06 ] @
Svaka cast Dimke!
Nisam znao da ti Lex Fridman radi review, do j*ja.
Mislim da sam video ranoje da DigiCortex koriste kao jedan od testova za gpu na nekim poznatim sajtovima.
Sto se tice koda, github private, cisto da se ne desi ovo sto prica Bogdan.
[ TheSpiridon @ 06.08.2022. 11:10 ] @
Kad završite taj veštački nervni sistem, molio bih vas da probate da implementirate na meni.
[ Ivan Dimkovic @ 06.08.2022. 22:35 ] @
Evo ga - HDR:
A tek je pola vikenda proslo :-)
[ bogdan.kecman @ 07.08.2022. 10:42 ] @
kontam ovaj deo kada ne pise hdr off je hdr on :D
[ Ivan Dimkovic @ 07.08.2022. 16:08 ] @
da :) da skratim vreme hehe...
Btw, za prelaz sa OpenGL 1.x glBegin() / glEnd() na nesto iole moderno, evo jos materijala:
- Vizualizacija sada ukljucuje i propagaciju impulsa kroz aksone (pri kraju klipa se najbolje vidi, mada... treba mi bloom* filter sad ;-)
- Drasticno bolja traktografija (ovo je pojelo jako puno CPU i I/O vremena ;-) - aktivnost je mnogo koherentnija i mogu se prepoznati glavni asocijativni i talamo-kortikalni traktovi po aktivnosti
- Aksonalni putevi se sada renderuju kao Bezjeove-ove krive, sa teselacijom do 64x (!) zahvaljujuci relativno jeftinim prolazom kroz teselacioni shader (tako da broj temena postaje sumanut)
- Rendering je sada kompletno 16-bitni floating point od pocetka do kraja, a finalni video capture+encode ide u 10-bitni H.265 direktno na GPU-u iscitavanjem FBO teksture (ako postoji hardver)
Ispod haube, da bi se renderovala propagacija impulsa kroz aksone, potrebno je zapamtiti predhodne voltaze negde (kada neuron "opali" u vremenu T, da bi signal stigao do neke proizvoljne tacke na aksonu, potrebno je X koraka u vremenu u zavisnosti od fizioloskih parametara specificnih za tip neurona). Kako moze biti jako puno tih segmenata po jednom aksonu stotine, pomnozeno sa milionima aksona ocigledno nije prakticno to cuvati kao promenljive vertex atribute.
Umesto toga, upotrebljene su "Bindless" teksture sa kojima nema vise limta od 32 aktivne teksture po shader fazi (arhaicni OpenGL limit) - moderni GPU-vi imaju stotine TMU jedinica - npr. NVIDIA RTX 3090 ima 328. Niz bindless tekstura duzine N (gde je N najduzi akson) pamti "snapshot" voltaza samo neuronskih tela (koja iniciraju impuls) u tom momentu kao kvantizovna 8-bitna vrednost. Prakticno niz tekstura postaje "ring buffer" gde sa svakim vremenskim korakom samo pomeramo gde upisujemo trenutne vrednosti :) 0 kopiranja.
Onda kad sencimo svaki trakt - za svaki segment na putu znamo koliko je udaljen od "parent" neurona, a kasnjenje sa kojim bira indeks za citanje iz tekstura dobijamo mnozenjem sa faktorom brzine propagacije signala za taj tip celije (to se cuva kao relativno jeftin info posto se ne menja, treba nam 6-7 bitova za trenutne simulacije, sto je spakovano u 96-bitni vertex atribut zajedno sa svim ostalim: 3D lokacijom, indeksom neurona, bojom i sl.) tako da uvek mozemo da izracunamo trenutnu voltazu za svaki segment (prostim semplovanjem iz niza tekstura koje sluze kao "look-up" tabele "iz proslosti").
Prilikom teselacije za novostvorene segmente jednostavno interpoliramo vrednosti izmedju najbliznih pre-tess koordinata i to je to.
I tako shader kod instant iz arhaicnog GL 2.x postade GL 4.5 sa obaveznim ekstenzijama :) Dodatna korist je sto sa bindless teksturama vise nema bind/unbind dr*anja - jednom kreirana, tekstura ima 64-bitni handle koji je permanentan i bilo kom shaderu se dobaci kao uint64 jednom pri kompajliranju i koji se ne menja.
--
TL;DR: Sve ovo omogucava da se sistem sa desetine miliona aksonalnih segmenata + 64x teselacija renderuju sa ~30 FPS - sve ukljucujuci upload voltaza za svaki frejm sa CPU-a (GPU akceleracija simulacije jos nije ukljucena za novu verziju).
(*)
:-)
[ Ivan Dimkovic @ 23.08.2022. 15:09 ] @
Btw, tih 30 FPS - najvise vremena ne odlazi na aksone (na njih ode ~8ms po frejmu sa 30 miliona segmenata - teorijski 125 FPS) vec na neuronska tela (~25ms) koja se crtaju kao gomila odvojenih linija. Sto je ironicno, posto najveci deo geometrije odlazi na aksone. Moracu nesto tu da uradim.
I da, ovaj "ring buffer" od bindless tekstura - upload se desava sa drugih (compute) niti i to asinhrono na teksturni "slot" koji trenutno nije u upotrebi, tako da ne blokira GL crtanje vec GPU moze na miru da crta i radi DMA bez blokade.
v2.00 PREVIEW - Released on April 17th 2023
--------------------------------------------------------------------------------
NOTE: this is a technology demonstrator with a limited feature set
Focused on showing the new rendering engine capabilities. Most of the
advanced neuron toolkit UX features are not enabled in this preview.
* New "Neon Connectome" Rendering Engine
- Long-Range Axonal Pathways rendered as Bezier paths
- Propagation of action potentials through white matter visualized
- Custom color schemes for neurons and axonal pathways supported
- Rendering control per major tract pathway, neuron type or area
- HDR Floating Point rendering support with automatic tone mapping
- Order Independent Transparency (OIT) rendering for brain surfaces
- Phong and Blinn-Phong lighting models for brain surfaces
- SMAA Anti-Aliasing Support for non-HDR rendering
- Entire rendering engine upgraded to OpenGL 4.6 Core profile:
all legacy / compatibility OpenGL profile code removed
- Added support for bindless textures
- CPU<->GPU data transfers / texture uploads fully asynchronous
- Detail enhancement supported by using tessellation shaders
- Reduced GPU memory usage with custom vertex fetching and data layout
- Hardware accelerated HDR 4:4:4 H.265 video capture (NVENC)
* Completely removed Windows UI controls, new UI is using Dear ImGui
* Diffusion MRI dataset upgraded to MGH 0.7mm high resolution dMRI data,
with 8x improvement in 3D resolution over previous data
* New tractography engine (Tract-o-Matic), dramatically cutting down
connectome loading speeds and improved tracking quality
* Tractography engine now groups fibers in major neuroanatomical tracts
fully selectable in the UI
* Brainstem ARAS structures anatomy rebuilt from high quality atlas
* Added support for hybrid CPU architectures (P-cores / E-cores) including
explicit disabling of power throttling, as a hint to OS scheduler
* Additional AVX-512 optimizations for CPU simulation runtime including
Intel x86-simd-sort library (>10x speedup for FLOAT32 sort)
* Improved lockless task scheduler with built-in awareness of the system
memory (NUMA) layout and cache hiearchy for efficient work/task stealing
* Additional optimizations for systems with over 64 CPU cores
NOTE: Compute engine is still limited to 256 CPUs, this is to be fixed
* Switched to fast user-space synchronization primitives where it
was not possible to use lockless algorithms (WaitOnAddress())
* Removed support for Windows versions prior to Windows 10
NOTE: Windows 11 or above is highly recommended
* Removed support for CPUs without AVX2 instruction set
* CUDA compute plug-in temporarily removed, pending rewrite
v2.00 - Released on April 30th 2023
--------------------------------------------------------------------------------
NOTE: some features (retina support, advanced stats and CUDA acceleration) are
still TBD for the 2.x releases, they will be enabled in the near future
* Rendering backend is now using DXGI, allowing smooth resize, native HDR
support and improved performance
* Font rendering engine updated to FreeType 2.13.0 with Harfbuzz support
* Added support for acrylic background effect for tool windows
* Added "Neuron Properties" and "Neural Network Stats" windows including EEG
[ MajorFatal @ 16.12.2023. 10:44 ] @
Evo mala ispomoć :)
[ Ivan Dimkovic @ 17.12.2023. 15:45 ] @
How hard can it be? :-)
[ MajorFatal @ 17.12.2023. 16:39 ] @
Malo aproksimiraj, sve je to manje više amigdala :)
Ako su ljudi umeli da naprave poster, šta je teško napraviti simulaciju ..
[ Ivan Dimkovic @ 27.12.2023. 08:12 ] @
Sta je problem? Pa, recimo, sto nigde na toj semi ne vidis JTAG ili neki drugi debug interfejs :-) Za pocetak...
[ mjanjic @ 28.12.2023. 17:13 ] @
Ali, na posteru "Cerebellum contains 3/4 of the neurons in the brain (approx 50 billion) and is 1/10th the size of the entire brain" je otprilike kao kad bismo rekli da glavni čip (motornog) računara u autu (ECU) sadrži 3/4 provodnika celog auta (svejedno da li u kilometrima ili po broju vodova), a taj ECU je 1 promil mase auta.
Kroz Cerebellum prolaze svi neuroni za motoriku i većina "senzora".
Nego, mnogo je veća "tajna" kako se od jedne oplođene jajne ćelije i kasnije zigota razvije tako složen mozak. Jeste zahvaljujući DNK, ali opet, kako određeni elementi imaju baš takva svojstva kakva imaju zahvaljujući različitom broju protona, neutrona i elektrona. Ako se neutron posmatra kao kombinacija protona i elektrona, eto imamo samo 2 osnovna elementa (da ne ulazimo u priču o kvarkovima), i kod računara imamo dva osnovna "elementa", nula i jedan, pa pomoću njih nismo uspeli da napravimo ništa približno mozgu :)))
[ Shadowed @ 28.12.2023. 17:25 ] @
Citat:
mjanjic: Ako se neutron posmatra kao kombinacija protona i elektrona, eto imamo samo 2 osnovna elementa (da ne ulazimo u priču o kvarkovima)
Paa, neutron nije kombinacija protona i elektrona upravo jer postoji prica o kvarkovima :)
Oba se sastoje od po tri kvarka, nema tu elektrona.
[ Ivan Dimkovic @ 28.12.2023. 18:32 ] @
Ne sastoji se od 3 kvarka, to je samo jedna specificna konfiguracija, pod specificnim uslovima posmatranja (tj. razbijanja).
U realnosti su proton i neutron “supe” stalno menjajucih elementarnih cestica, van bilo kakvog domasaja danasnjih superracunara za “de novo” simuliranje iz osnovnih principa. Cak i sa svim precicama i koriscenjem Lattice QCD modela smo jos prilicno daleko od toga.
A to je samo jedan delic atoma… jedan virus a kamo li celija su beznadezno daleko po kompleksnosti ako zelimo da ih modeliramo klasicnim racunarima.
Ne treba gubiti iz vida razmere - od velicine coveka do Plankove duzine ima mnogo vise redova velicine nego od velicine coveka do velicine vidljivog univerzuma. Plus, nista ne garantuje da je Plankova duzina limit ispod kojeg se nista ne desava, to je samo teorijski limit dostupan nasem posmatranju (od koga smo prakticno prilicno daleko).
Eto, ponekad se u protonu moze zadesiti i "charm" kvark, koji je inace 1.5x masivniji od samog protona. Da stvar bude jos ludja, ako se potrefi da proton sadrzi taj tip kvarka, on nosi samo 1/2 mase tog istog protona!!!
Citat:
Although this successful framework has by now been worked through in great detail, several key open questions remain open. One of the most controversial of these concerns the treatment of so-called heavy quarks (that is, those whose mass is greater than that of the proton; mp = 0.94 GeV). Indeed, virtual quantum effects and energy–mass considerations suggest that the three light quarks and antiquarks (up, down and strange) should all be present in the proton wavefunction. Their PDFs are therefore surely determined by the low-energy dynamics that controls the nature of the proton as a bound state. However, it is well known8,13,14,15 that in high enough energy collisions all species of quarks can be excited and hence observed inside the proton, so their PDFs are nonzero. This excitation follows from standard QCD radiation, and it can be computed accurately in perturbation theory.
[ mjanjic @ 09.01.2024. 14:25 ] @
Da, ali si u prethodnoj poruci napisao "to je samo jedna specificna konfiguracija, pod specificnim uslovima posmatranja", tako da mi to "vidimo" zbog načina posmatranja, odnosno posrednog detektovanja tih čestica, pa je pitaje šta je suština tih elemenata.
Slično kao kada bi neki domoroci imali radio prijemnik i pravili teorije odakle dolazi muzika ili drugi zvuk kad menjaju poziciju pokazivača na skali (tj. frekvenciju prijema), ali nikad ne bi mogli da dođu do suštine - elektromagnetnih talasa, a i kad bi to uradili, pitanje je da li bi došli na ideju kako da stvaraju elektromagnetne talase i preko njih prenose tu muziku ili drugi zvuk, jer bi onda možda imali ideju odakle ta muzika koju čuju na pojedinim frekvencijama.
Mi trenutno nismo (ili delimično jesmo npr. u CERN-u) u poziciji da kontrolisano stvaramo mikročestice ili je možda još važnije pitanje da li možemo energiju da pretvorimo u neke od mikročestica. Kad bismo to uspeli, možda bismo mogli da napravimo model po kome je nastala sva materija u Svemiru, a možda i uspeli da odgovorim na pitanje šta je "tamna materija" koja se pojavljuje u nekim modelima po kojima postoje delovi Svemira koji gravitaciono utiču na kretanje nama vidljive okolne materije, a tu trenutno ne detektujemo nikakvu materiju.
[ Ivan Dimkovic @ 15.01.2024. 17:07 ] @
Sta je 'sustina' necega za sada nemamo ni izgleda da znamo, posto je cak i na filozofskom nivou limit spoznaje sa onim cime raspolazemo samo nas model (tj. nase razumevanje), baziran na osmatranju.
A osmatranje je, prakticno, interakcija. Bez interakcije je stanje sistema nedefinisano, a prilikom interakcije u akceleratorima neminovno dolazi do stvaranja/razaranja cestica. Kakvih? To zavisi od energije sudara.
Sudari visih energija pokazuju da je struktura nukleusa vrlo komplikovana. Takodje, zbog prirode jake sile nije moguce koristiti trikove koji su sljakali sa QED-om i zanemariti stvari koje divergiraju u beskonacnost.
A ovo je sve pre upliva gravitacione sile, sto tek povecava problem ako se pokusava dokuciti bilo sta gde sve 4 sile jesu vazne. Drugim recima, sto se ide ka manjem, stvari postaju komplikovanije - a ne obrnuto.
Citat:
a tu trenutno ne detektujemo nikakvu materiju.
Tamna materija jeste problem, ali sustinski daleko manji od ovoga gore. Mislim da ce pre ili kasnije biti pronadjena cestica 'odgovorna' za tamnu materiju - po samoj prirodi stvari, ocigledno je tesko 'uhvatljiva'. Mi tek dobijamo kakve-takve mogucnosti za osmatranje neutrina iz daleka, u zavisnosti od prirode tamne materije to sto je predstavlja moze biti jos grdje za detekciju ali - za sada nema razloga da se to odbaci kao ideja.
[ MajorFatal @ 11.10.2024. 18:43 ] @
Voćna mušica uvek zanimljiva, mapirali ceo mozak, sve neurone i sve veze, konekcije ...
Videh vest juče ili preključe, sad ostaje da to "usade" u neki dron, koji će umesto na voće ići na neprijateljske vojnike i tehniku :)
[ Ivan Dimkovic @ 11.10.2024. 21:15 ] @
Pih, za to ti ne treba nista ni priblizno kompleksnosti vocne musice :-)))
Doduse, prednost bioloski inspirisanih mreza optimalno implementiranih hardverski je drasticno manja potrosnja energije, tako da bi takav dron mogao da bude potpuno autonoman bez da mu SoC/CPU vuce previse baterije.
Problem je treniranje takvih neuronskih mreza da rade ono sto hoces (ne mozes da koristis backpropagation algoritam) mada postoje precice 'portovanja' modela treniranih na klasicnim arhitekturama (RNN/CNN/...).
Sto se tice mapiranja celog mozga, to je svakako impresivan uspeh ali samo mapiranje ne daje kompletnu sliku neophodnu da se reprodukuje ponasanje. Jos pre 10-tak godina je kompletno mapiran nervni sistem C. Elegans crva sa svim sinapsama, ali cak ni to ne reprodukuje kompletnu dinamiku.
Za sada i verovatno jos u doglednoj buducnosti, razumevanje bioloskih sistema moze eventualno pomoci u nalazenju novih algoritama za primenu u ML polju, ali neki kompletan "reverzni inzenjering" radi reprodukcije ponasanja deluje prilicno daleko.
[ Shadowed @ 11.10.2024. 21:23 ] @
Ono sto nas zanima je mozes li ti da mapiras to na SpikeFun ili ne
[ Ivan Dimkovic @ 11.10.2024. 21:52 ] @
Sa beskonacno vremena i racunarskih resursa, mozda :-)))
[ MajorFatal @ 11.10.2024. 22:29 ] @
Citat:
mjanjic:
Nego, mnogo je veća "tajna" kako se od jedne oplođene jajne ćelije i kasnije zigota razvije tako složen mozak. Jeste zahvaljujući DNK, ali opet, kako određeni elementi imaju baš takva svojstva kakva imaju zahvaljujući različitom broju protona, neutrona i elektrona. Ako se neutron posmatra kao kombinacija protona i elektrona, eto imamo samo 2 osnovna elementa (da ne ulazimo u priču o kvarkovima), i kod računara imamo dva osnovna "elementa", nula i jedan, pa pomoću njih nismo uspeli da napravimo ništa približno mozgu :)))
Dnk oko 5 megabajta podataka, ali 5 megabajta uputstava recimo .. na toliko papira možeš da napišeš upustva za pravljenje nekog kompjutera recimo ..
Meni nešto drugo bilo zanimljivo, jajna ćelije se podeli na dve ćelije, pa na 4, pa na 8 i sve do tada su stem, matične ćelije, već pri sledećoj deobi sa 8 na 16 ovih novonastalih 16 više nisu stem, i više nisu iste, identične međusobno, nego polovina od tih 16 sadrži informaciju da je u pitanju (budući) gornji deo tela, a druga polovina da je donji .. kako, na koji način? Da li bi mogao da se napravi softver koji se tako ponaša, da se umnoži na 2, pa 4, pa 8, i da je sve vreme identičan uključujući čak i naziv softvera, i ceo kod, a pri sledećoj deobi da polovina od broja softvera postane različita?
Pri svemu tome softver bi od početka morao da ima na svoj osnovni kod još bar 100 Mb informacija, jer prilikom ovih prvih deoba ćelije još uvek nemaju mogućnost rasta, nego se smanjuju, od jedne postanu dve manje, pa 4 još manje, pa 8 najmanjih, koje još uvek moraju da budu veće od 5 Mb koliko je najmanje potrebno da se pothrani dnk niz ..
Citat:
Ivan Dimkovic:
Sto se tice mapiranja celog mozga, to je svakako impresivan uspeh ali samo mapiranje ne daje kompletnu sliku neophodnu da se reprodukuje ponasanje. Jos pre 10-tak godina je kompletno mapiran nervni sistem C. Elegans crva sa svim sinapsama, ali cak ni to ne reprodukuje kompletnu dinamiku.
Šta znači "čak ni to ne reprodukuje kompletnu dinamiku"? Softverski crv nije osećao glad? :)
[ Shadowed @ 11.10.2024. 22:49 ] @
Ako mislis na ljudsku DNK, ima znatno vise od 5MB podataka.
Sto se embrionalnog razvoja tice, a i inace, sve celije tela imaju isti DNK. Celije se diferenciraju na osnovu toga koji su geni aktivni. Podela nije bas gore/dole u startu, ali nebitno. Jedan deo celija (one koje su unutar sigota) aktivira druge gene i pocinje da se razlikuje od drugih celija.
Softver moze da napravi x svojih kopija a zatim jos x drugacijih. To je trivijalno.
[ MajorFatal @ 11.10.2024. 23:35 ] @
Citat:
Shadowed: Ako mislis na ljudsku DNK, ima znatno vise od 5MB podataka.
U vreme mog školovanja dnk je imao 3 miliona parova, vidim sad ima 220 miliona, svejedno to mu dođe oko 450 Mb podataka, dovoljno za upustva za dobar kompjuter ..
Citat:
Softver moze da napravi x svojih kopija a zatim jos x drugacijih. To je trivijalno.
Eh pa ne X kopija, već X polovina sebe, jer se za tih nekoliko podela ćelije smanjuju, i posle toga ne X drugačijih, nego da 8 do tada identičnih po kodu softvera napravi 16 novih softvera, od kojih su 8 jednog tipa i 8 drugog tipa .. ? Ne mogu to da zamislim, a da su uputstva u samom softveru, samim tim uputstva su sve vreme ista .. tjah ..
[ Shadowed @ 12.10.2024. 01:07 ] @
Imao je isto i u vreme tvog skolovanja.
Poredjenje sa softverom ti je svakako besmisleno.
Inace, brazdanje oplodjene jajne celije nije bukvalno presecanje na pola. I dalje se odvija kompletan proces mitoze, samo celije posle deobe ne rastu.
[ Ivan Dimkovic @ 12.10.2024. 08:04 ] @
Citat:
MajorFatal
Šta znači "čak ni to ne reprodukuje kompletnu dinamiku"? Softverski crv nije osećao glad? :)
E da smo bar dosli do toga, bili bi na konju - kad budemo mogli da filozofiramo da li softverski crv oseca ili ne, stigli smo negde ;-))))
Softverski crv ne radi uopste, sa sve individualnim sinapsama zato sto nedostaje bog-te-pita-sta-jos. To sto mi vidimo kao, lupam, mesto sinaptickog receptora je komplikovan molekularni 'aparat', da se tako izrazim, koji se opet sastoji od komplikovanih 'aparata' zvanih molekuli koji se sastoje od... vidis vec gde idem sa ovom pricom :-)
Worst-case scenario je da ti ni lattice-QCD nivo 'emulacije' nije dovoljan da dobijes paritet u ponasanju u realnim uslovima, sto svakako za sada ne mozemo da proverimo zato sto sa tim nivoom 'rezolucije' nismo u stanju ni najjednostavniji molekul da simuliramo zbog eksponencijalnog rasta kompleksnosti ako hoces taj nivo detalja (ovaj problem je potencijalno resiv sa kvantnim racunarima koji bi mozda bili najbolji nacin za simulacije prirode... pod uslovom da uspemo da sklepamo to sokocalo da ima dovoljan broj qbita). Plus... ni Lattice QCD nije bez precica, da ne otvaram sad dodatna pitanja oko kompletnosti tog modela.
Ostaje nada da je OK zadovoljiti se sa nekim visim nivoom apstrakcije, ali jedini dokaz za to ce biti nesto sto funkcionise kako treba kompletno, sto se jos nije desilo. Mislim, kul je sto sa nekoliko diferencijalnih jednacina mozes da reprodukujes konacni 'izlaz' neurona, ali to je samo u specijalnom izolovanom rezimu gde si replicirao ponasanje neurona kako ga vidis u lab. uslovima sa zakacenim sondama - to nije isto sto i ponasanje u hrpi neurona sa gomilom neurotransmitera i ko-zna-cega-jos sto pliva okolo.
[ MajorFatal @ 12.10.2024. 13:30 ] @
Citat:
Shadowed:
Poredjenje sa softverom ti je svakako besmisleno.
Ta nisam ništa poredio sa softverom, ali kao što i sam znaš softver može da posluži da nekad nešto simuliramo .. nit bi mogao da ima brojač, jer ćelije nemaju brojače, ili ne da ja znam, nit bi mogli da komuniciraju među sobom jer ćelije ne komuniciraju, ok od istog napraviti različito, ali ko će da prebroji da ih je tačno 8 jednih, i tačno 8 drugih a da nije izvan tog sistema od njih 16 .. bah ..
Citat:
Ivan Dimkovic:
Softverski crv ne radi uopste, sa sve individualnim sinapsama zato sto nedostaje bog-te-pita-sta-jos. To sto mi vidimo kao, lupam, mesto sinaptickog receptora je komplikovan molekularni 'aparat', da se tako izrazim, koji se opet sastoji od komplikovanih 'aparata' zvanih molekuli koji se sastoje od... vidis vec gde idem sa ovom pricom :-)
Pa ni biološki crv ne radi bogzna šta, recimo da živi u jabuci, bukvalno je okružen hranom, sve što treba da radi je da 1 ide napred i 2 jede, 3 olakšava se, eventualno može da ima neki centar kome jave senzori na koži da je stigao do ivice, i krenuo da ispada iz jabuke to je 4, sve ukupno 4 funkcije .. možda sad kad ima simulacija mozga mušice, može da se dokaže da njen mozak ima dovoljno kapaciteta da obezbedi letenje okolo, a da mozak crva nema dovoljno potencijala za takvo nešto šta ti ja znam ..
[ mjanjic @ 12.10.2024. 13:30 ] @
Mi još ne znamo šta je ŽIVOT (ne mislim na provod i sl., već u biološkom smislu) i pitanje je da li ćemo ikada saznati.
Živa bića, pa čak i biljke, očigledno nisu samo jednostavno "malo" složeniji molekularni roboti, tu će uvek nedostajati ona neka komponenta koju ne razumemo.
Pre neki dan pročitam negde MEME, nešto tipa kad fizičar proučava ponašanje atoma, ako imamo u vidu da se ljudsko telo sastoji iz atoma, onda to praktično znači da jedna grupa atoma proučava druge atome :)[/quote]
[ Ivan Dimkovic @ 12.10.2024. 14:57 ] @
@MajorFatal,
Problem je sto taj softverski crv ne radi ni to sto njegova bioloska verzija radi, koliko god da je to prosto. Za softversku vocnu musicu su jos manje sanse da ce biti funkcionalna u skorije vreme :-)
Mislim da je biranje nervnog sistema tj. fenomenoloskih modela neurona i sinapsi cist proizvoljni nivo apstrakcije koji smo mi izabrali kao nekakav izazov, gde jedan deo ljudi veruje da je taj nivo apstrakcije dovoljno detaljan da na proizvede korisno ponasanje takve simulacije.
Ta tvrdnja nema neko utemeljenje u teoriji, posto je nemamo, niti za sada ta tvrdnja moze da se posluzi eksperimentalnom potvrdom, koju takodje nemamo. Za sada smo replicirali neke fenomene koje mozemo eksperimentalno izmeriti i na "pravoj stvari" ali bilo sta slicno konkretnom ponasanju ili bilo kojoj kompleksnoj akciji je i dalje izazov.
Bukvalno cela stvar pociva na veri da je to moguce - a ako se pokaze da nije, zna se, spusticemo nivo apstrakcije na nizi nivo npr. molekularni... pa ako i to ne sljaka, mozemo i dalje da se spustamo (koliko stanje racunarske nauke dozvoljava) i, mozda, jednog dana, repliciramo zivu materiju.
A mozda i ne....
Veliki pomak bi bio kad bi mogli biti u stanju da simuliramo neki jednocelijski organizam... ali cak ni to za sada nije moguce. A svaki neuron te vocne musice je, prakticno, organizam za sebe.
[ MajorFatal @ 13.10.2024. 12:36 ] @
Citat:
Ivan Dimkovic:
Problem je sto taj softverski crv ne radi ni to sto njegova bioloska verzija radi, koliko god da je to prosto. Za softversku vocnu musicu su jos manje sanse da ce biti funkcionalna u skorije vreme :-)
Ne vredi, opet slabo razumem, tvrdiš da su softverskom crvu obezbedili softversku jabuku, ali on odbija da gmiže i jede .. ? Ili na koji način ne radi to što biološka verzija radi?
[ Ivan Dimkovic @ 13.10.2024. 13:46 ] @
Taj softverski crv ne radi nista, daleko su oni i od mogucnosti da mu daju 'softversku jabuku'.
Sofisticirana verzija pinokija, ali i dalje - Pinokio ;-)
[ MajorFatal @ 13.10.2024. 14:22 ] @
Mora da jede, makar na silu .. :) šalim se, šalim, ali dosta razgovora iz oblasti o kojoj malo znam ..
[ Ivan Dimkovic @ 13.10.2024. 14:51 ] @
Za sada jede samo struju koju trosi za vreme simulacije :-)
Btw, SpikeFun 2.15 je izbacen - ima optimizacije u shader-ima i optimizacije za trcanje malih simulacija (do ~1M neurona) na masinama sa velikim brojem jezgara (>96) - ubrzanja su od ~25% za 1M neurona do >2x za 200K neurona.
Problem je drzati npr 128 jezgara zauzetim sa tako malim simulacijama, a ako nit ode 'na spavanje' to pravi latenciju koja ubija performanse. Resenje je hibridna barijera koja neko vreme koristi spinlock (sa pause instrukcijom, naravno). Naravno ovo je pipava stvar kao i svako koriscenje spinlock-ova u userspace-u, ali mislim da sam nasao odgovarajuci tradeoff koji ne ubija performanse sistema a performanse su unutar 5% maksimalnih mogucih (scenario gde sve radne niti imaju realtime performanse i koriste spinlock za sinhronizaciju).
Na vecim simulacijama (2M neurona+) ovo nije ni ranije bio problem, zato sto ima dovoljno batch-eva za scheduler da popuni sve procesore uvek. Isto tako i sa malim simulacijama, ovaj problem se ne vidi na masinama sa manjim brojem jezgara (8-32 mozda i 64, nisam probao), tek postaje vidljiv kada je broj jezgara dovoljno velik.
[ kosmopolita @ 13.10.2024. 15:44 ] @
Znači da se radne niti sinhronizuju ovako:
- nit1 sa spinlock ulazi u sinhronizaciju
- nit2 sa spinlock čeka
- nit3 sa spinlock čeka
..
- nit1 završava
- nit2 počinje
- nit3 i dalje čeka
..
[ Ivan Dimkovic @ 13.10.2024. 18:55 ] @
Zapravo, u najvecem delu posla nema sinhronizacije, sinhronizacija je samo eventualno potrebna za vreme barijera.
Pseudokod:
Code:
void Nit_Za_Procesiranje() {
do {
// pocetak svakog koraka simulacije
update_struja_provodljivosti_voltaza();
barijera();
dostavi_akcione_potencijale();
barijera();
// Novi korak simulacije
// simTimeStamp += 1 --> ovo radi poslednja nit koja napusta barijeru gore
} while(!stop);
}
Svi poslovi (update_xxx, dostavi_xxx) imaju work scheduler koji je u stanju da "krade" posao od sporijih niti na istom NUMA nodu. Sam scheduler je lockless i ni jedna funkcija u procesiranju nema zavisnost podatka sa drugim nitima, osim dostavljanja akcionih potencijala gde se atomickim instrukcijama uvecavaju provodljivosti ali to je mali broj neurona (relativno) sa, takodje, jos manjom 'guzvom'.
Problem je sto se cesto desi da neka od niti (jedan CPU = jedna radna nit) ili uspava na kratko od strane OS schedulera, ili se na kraju ipak sve svede da su sve ostale niti gotove dok par niti procesira poslednji batch.
U slucaju barijere koja uspava nit koja ceka da se barijera oslobodi imas problem da to automatski znaci bar desetine mikrosekundi gubitaka zbog OS schedulera i puta u kernel. To onda uspori sve ostalo zato sto ta latencija blokira da se ostale stvari zavrse i tako ponavljaj sa svakim korakom u simulaciji. Napomena - ovo je samo problem sa relativno malim simulacijama, sa dovoljno posla (batch-eva) se ovaj problem ne primecuje i svi procesori cak i da ih ima trocifren broj su zakucani na 100% :-)
Alternativa je da barijera malo 'spinuje' pre nego sto odustane i otera nit na spavanje - trik je u tome koliko je to 'malo' dovoljno da 'ispegla' dziter u vremenima zavrsavanja poslednjih batch-eva a da ne preoptereti sistem zato sto u tom slucaju imas vecinu niti koje spinuju i cekaju da par poslednjih niti zavrsi posao.
Resenje koje imam na Windows platformi je kombinacija privremenog spinovanja i konacno WaitOnAddress(); / WakeByAddressAll(); sto je Windows varijanta futex koncepta na Linuxu (sa najvisim performansama od svih ostalih slicnih sinhronizaconih primitiva). Ovo daje performanse unutar 95% performansi cistog spinovanja sa najvisim prioritetom (gde nema inverzije) - ali bez losih posledica po performanse celog sistema.
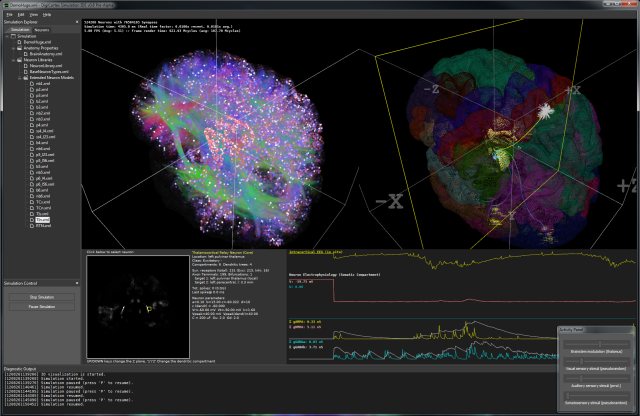


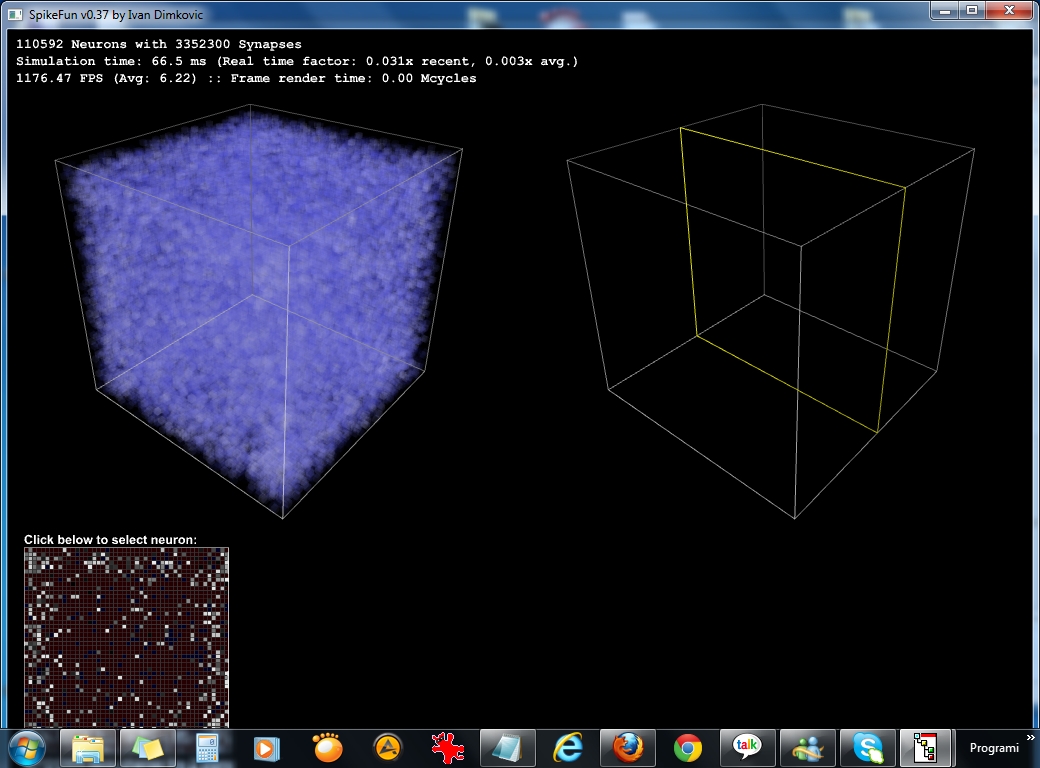
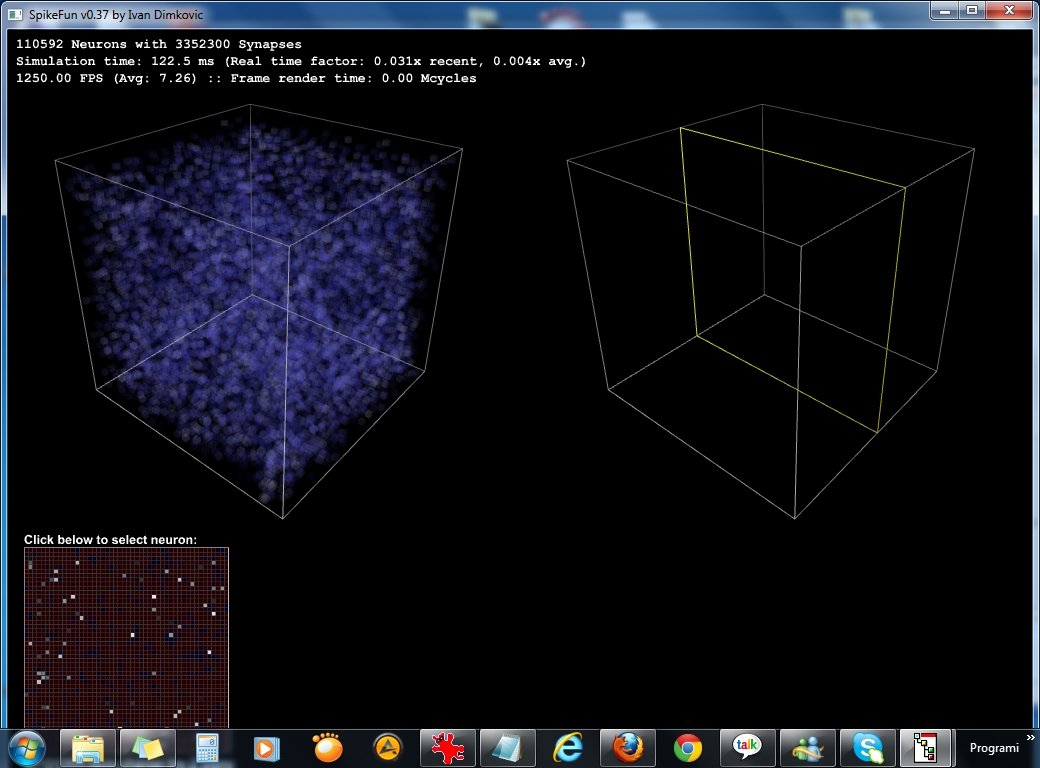
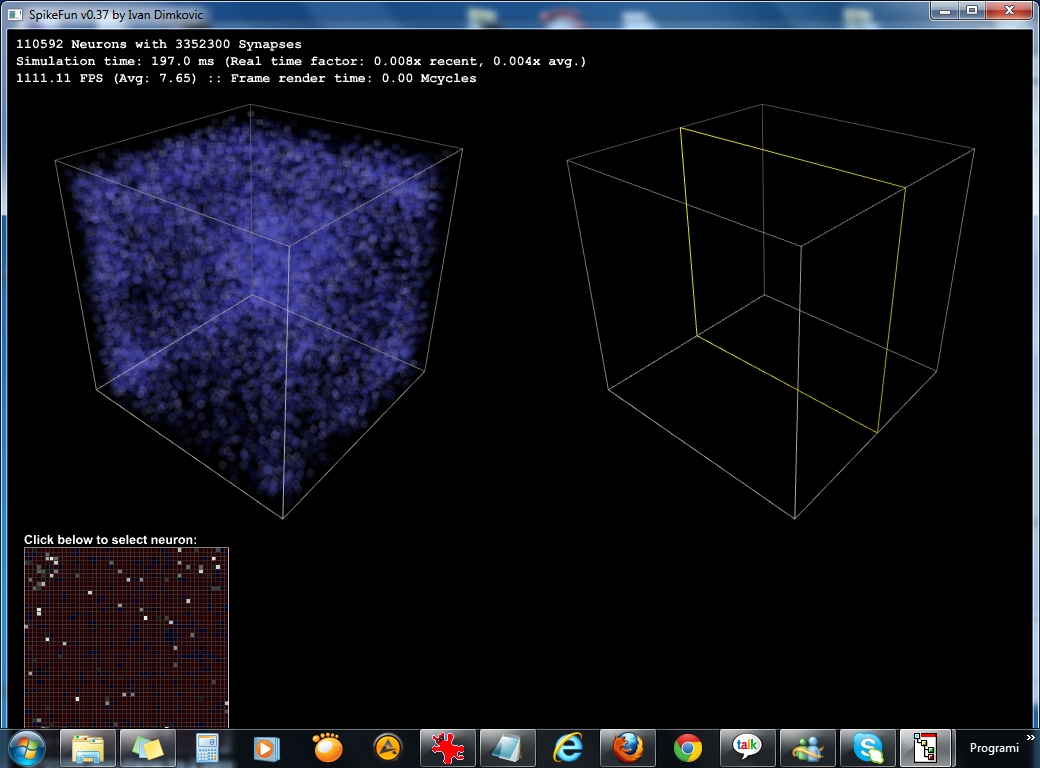

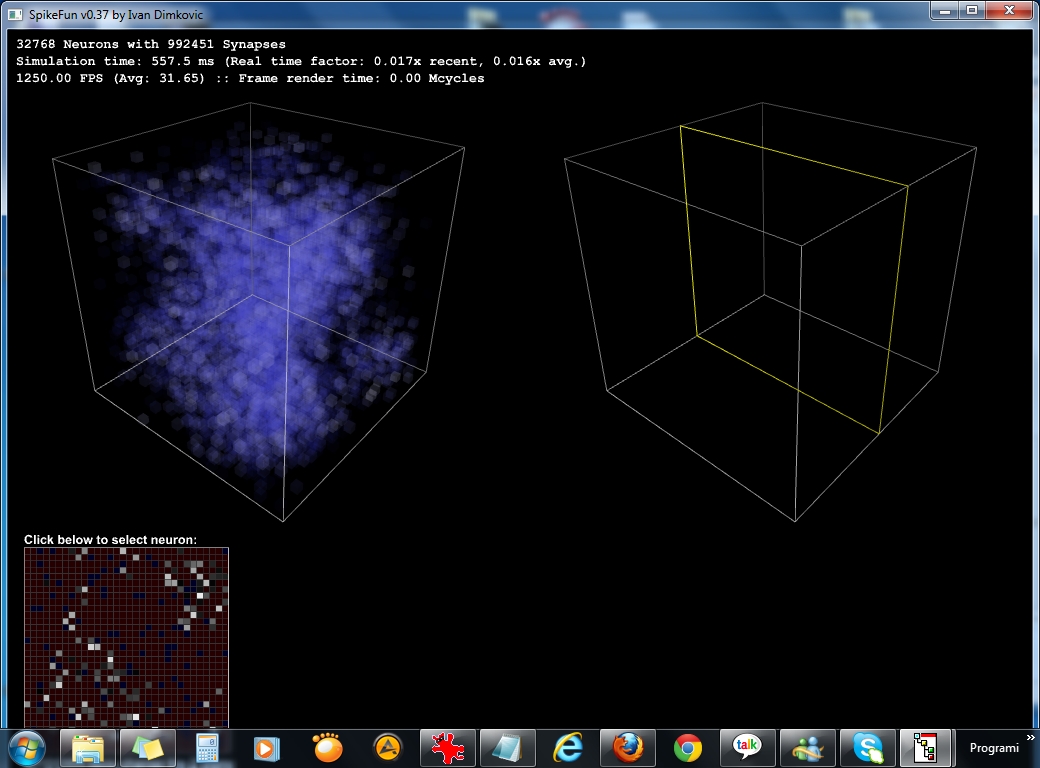
 )...
)...