|
|
[ peromalosutra @ 29.09.2013. 11:05 ] @
|
| Za pocetak, procitao sam Bogdanov blog clanak o smecu u bazi tako da mislim da nemam taj problem. :) Dakle imam PHP formu sa pretragom koja treba da pretrazuje i cirilicne i latinicne pojmove jednako. Ako se ukuca "med" na cirilici, trebalo bi da izbaci i cirilicne i latinicne termine koji odgovaraju pretrazi i obrnuto. Koliko sam razumio, to bi trebalo da moze da odradi kolacija utf8_unicode_ci.
Encoding tabele koja se pretrazuje je utf8, a collation je utf8_unicode_ci.
Evo screenshot direktno iz mysql cli, gdje bi se trebalo vidjeti smece u bazi ukoliko ga ima, meni tu sve djeluje ok:
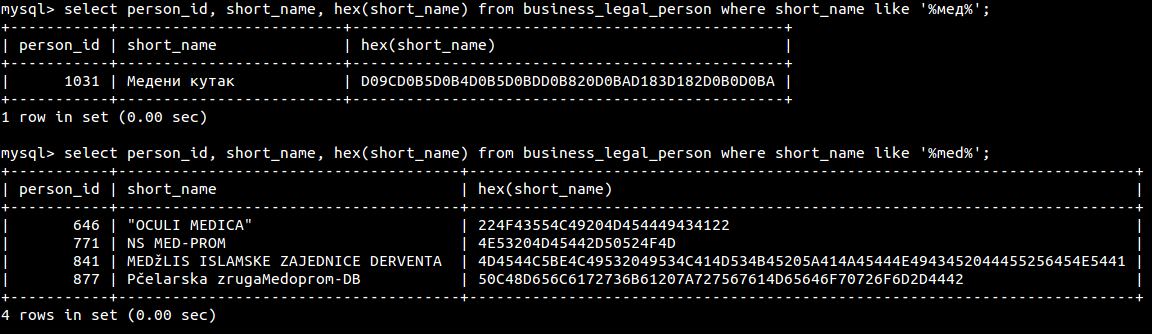
Gdje grijesim?
|
[ bogdan.kecman @ 29.09.2013. 18:11 ] @
Citat: peromalosutra: Za pocetak, procitao sam Bogdanov blog clanak o smecu u bazi tako da mislim da nemam taj problem. :)
po ovom snapshotu - nemas, dakle taj deo je ok
Citat: peromalosutra:
Dakle imam PHP formu sa pretragom koja treba da pretrazuje i cirilicne i latinicne pojmove jednako. Ako se ukuca "med" na cirilici, trebalo bi da izbaci i cirilicne i latinicne termine koji odgovaraju pretrazi i obrnuto. Koliko sam razumio, to bi trebalo da moze da odradi kolacija utf8_unicode_ci.
jok! nisi dobro razumeo
utf8_unicode_ci ne jednaci cirilicu i latinicu, nema nijedne default kolacije koja to radi (ako ima ja sam je preskocio), dakle po unicode ci ti je
Č=Ć=C
Š=S
dakle samo su karakteri sa akcentom == karakterima bez akcenta. Ako hoces da ti to ne bude tako, tj da Č!=Ć i Č!=C i Ć!=C onda na primer uzmes utf8_slovenian_ci i dobijes to da radi kako valja. u 5.6 radi i trailing tako da ako uzmes utf8_croatian_ci onda Nj, Lj, Dz i slicna slova takodje "rade" kako treba, tj postoji jednacenje i sortiranje dvokarakternih slova. ALI TU NIGDE NEMA CIRILICE!! dakle cirilica se nigde ne jednaci sa latinicom.
E sad, zato sam ja napravio externu kolaciju gde jednacim cirilicu i latinicu ovde: http://www.mysql.rs/2010/07/sortiranje-po-azbuci-azbuka-i-mysql/
i ta kolacija jednaci cirilicu i latinicu a sortiranje radi po azbuci.
To je za sada jedini nacin da napravis jednacenje cirilice i latinice. Ja sam sa Bar-om probao da ubacim srpsku kolaciju u mysql (u isto vreme kada smo ubacili hrvatsku) ali je problem sto MySQL ne moze da nazove kolaciju srpskom i onda da je napravi 'odokativno' vec smo trazili zvanican dokument od srbije (ambasada u svedskoj, vukova zaduzbina, matica srpska, sanu i jos 4-5 institucija vezano za srpski jezik) i od vecine nismo dobili nikakav odgovor a od onih od kojih smo dobili dobili smo "nas latinica ne zanima, azbuka se sortira ovako.." te zato ni sa 5.6 mysql-om nije dosla srpska kolacija (za nju nema potrebe posto "zvanicnici" u srbistanu kazu da latinicno i cirilicno A nisu isto slovo i da ne treba da se jednace, a u default unicode_ci cirilicna slova su vec poredjana po azbuci) tako da nama ostaje jedino da pravimo kolaciju sami
nije ti ovo mnogo pomoglo ali to je sto je, ja ne stizem da se bavim sada sa svim tim, kada stignem napravicu srpsku kolaciju kao externu za 5.6 i 5.7 (ona sto sam napravio vec radi na 5.5) i okacicu na blog no sigurno ne u narednih mesec dva dana
[ peromalosutra @ 29.09.2013. 19:34 ] @
Bas suprotno, pomoglo je bas, bar ne trazim ono sto ne postoji. Prije postovanja sam prekopao net i nikako ne nalazim to sto mi treba, pa zato dodjoh ovdje.
Koliko vidim najpametnije mi je to rijesiti na aplikativnom nivou, e sad, sta je bolje:
1. da dupliram sve kolone koje ce se pretrazivati (nema ih puno, ime i opis) i stavim kopiju sadrzaja u latinici, a onda u pretrazi uvijek trazim latinicu. Koliko vidim prednost je brzina pretrazivanja, mana zauzece vise memorije / prostora, sto je vjerovatno dosta podnosljivije (bar je memorija jeftina).
2. da prilikom pretrazivanja konvertujem search term u cirilicu i latinicu (sto moze biti problem ako pretvaram latinicu u cirilicu), pa onda pretrazujem po oba kriterijuma. Mana je sto pretrazujem dva puta, pa mi prvo rijesenje zvuci optimalnije.
3. nesto trece :)
[ bogdan.kecman @ 29.09.2013. 19:39 ] @
ne mogu sa 100% da ti kazem zasto je elitesecurity samo na latinici ali je jedan od bitnijih razloga sigurno pretraga :)
resenje broj 2 nije bas zgodno, resenje broj 1 je ok ako nije preveliko dupliranje podataka. zasto ne napravis srpsku kolaciju (imas tamo na sajtu kod mene tacno kako to da uradis) i resis problem "kako valja"? Ako radis sa 5.5 onaj primer radi 1/1 (ja sam ga pravio an 5.5), ako koristis 5.6 verovatno moras malo da adaptiras primer da bi proradio ali generalno je to to .. napravis sebi novu kolaciju, dodas u mysql i vozi misko, imas resen problem kako valja?
[ bogdan.kecman @ 29.09.2013. 19:42 ] @
nego sad se nesto mislim, trebao sam ja bosance da cimam kada smo Bar i ja pokusavali da dodamo srbistan u mysql, bosanci mi sigurno ne bi odgovorili sa "ne priznamo mi cirilicu" ili "ne priznamo mi latinicu" .. jos bi onda to i napravili .. ovako ne vredi, ja mogu da napravim patch za mysql i da ubacim ovu kolaciju direkt u kod, taj patch nikad nece biti odobren jer nam treba "zvanicni papir" :(
[ peromalosutra @ 29.09.2013. 19:57 ] @
Izgleda da je ipak pametnije napraviti novu kolaciju, zvucalo mi to nesto komplikovano, ali vidim da ne treba nista rekompajlirati, samo dodam xml i restartujem mysql server sto nije tako strasno.
MySQL je verzija 5.5.*, dakle ovo bi trebalo da radi bez problema: http://www.mysql.rs/2010/07/sortiranje-po-azbuci-azbuka-i-mysql/
Btw, taj post mi je i trebao od pocetka, ne znam kako sam ga preskocio.
Hvala puno na pomoci :) [ peromalosutra @ 30.09.2013. 11:29 ] @
Ok, jos problema :) U Index.xml sam dodao novu serbian kolaciju u utf8 dio, restartovao mysqld i mysqld vidi novu kolaciju.
Kad uradim ovaj test, sve je ok:
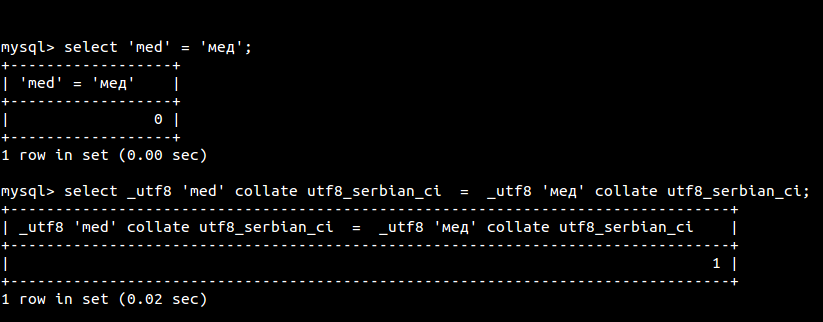
Medjutim kada pokusam promjeniti kolaciju na tabeli, dobijem gresku Can't create table? Ukoliko pokusam sa nekom drugom kolacijom sve prodje ok.
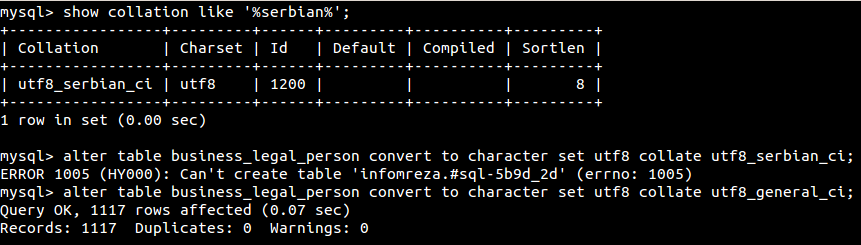 [ bogdan.kecman @ 30.09.2013. 11:44 ] @
hm nisam video error 1005 sa errno 1005 nikad, obicno je errno 150 (ne valja ti contraint) ili -1 (neko ime polja ti ne valja)
da li si probao da kreiras obicnu tabelu sa tom kolacijom? (samo jedno char(10) polje?)
[ peromalosutra @ 30.09.2013. 12:36 ] @
Ista stvar, ne moze da kreira tabelu sa serbian kolaciom. Google isto izbacuje samo errno 150 sto je vezano za foreign kljuceve, sto nije slucaj ovdje, pogotovo kad kreiram novu tabelu.
Code:
mysql> create table `test` (`kolona` varchar(10) character set utf8 collate utf8_serbian_ci);
ERROR 1005 (HY000): Can't create table 'infomreza.test' (errno: 1005)
mysql> create table `test` (`kolona` varchar(10) character set utf8 collate utf8_general_ci);
Query OK, 0 rows affected (0.08 sec)
Update, probao sam na 2 servera, ista stvar na oba, na virtuelnoj masini imam:
Code:
mysql> SHOW VARIABLES LIKE "%version%";
+-------------------------+-------------------------+
| Variable_name | Value |
+-------------------------+-------------------------+
| innodb_version | 1.1.8 |
| protocol_version | 10 |
| slave_type_conversions | |
| version | 5.5.24-0ubuntu0.12.04.1 |
| version_comment | (Ubuntu) |
| version_compile_machine | x86_64 |
| version_compile_os | debian-linux-gnu |
+-------------------------+-------------------------+
7 rows in set (0.00 sec)
[Ovu poruku je menjao peromalosutra dana 30.09.2013. u 13:57 GMT+1][ bogdan.kecman @ 30.09.2013. 13:16 ] @
neka je glupost tu problem, uploaduj xml ovde (Taman ga mozda jos neko
iskoristi) a ja cu da pogledam popodne o cemu se radi, sad imam neku
frku na poslu
[ peromalosutra @ 30.09.2013. 13:28 ] @
Evo ga Index.xml
[ vujkev @ 30.09.2013. 21:39 ] @
Odmah da se ogradim da MySQL ne koristim, ali sam otvorio ovaj XML da vidim šta tu piše i video nešto što je možda tvoj problem
U root nodu imaš atribut "max-id=99", a ti si utf8_serbian_ci stavio sa ID=1200. Možda ne može da bude veće od 99?
[ peromalosutra @ 30.09.2013. 22:16 ] @
To je to, svaka cast!
Stavio sam max id i utf8_serbian_ci id = 100 i sad je donekle ok. Kad kazem donekle, mislim na to da alter table prodje ok:
Code:
mysql> alter table business_legal_person convert to character set utf8 collate utf8_serbian_ci;
Query OK, 1115 rows affected (0.06 sec)
Select po cirilici izbacuje i latinicu:
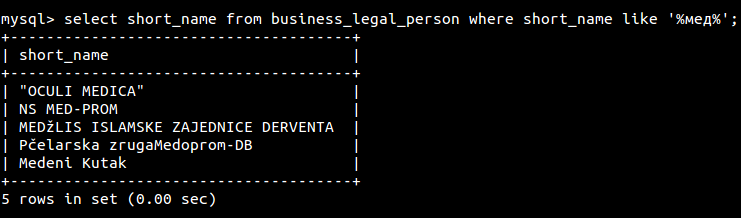
Medjutim cirilicni nazivi su mi iskonvertovani u latinicne ("Medeni kutak" je prije pisalo cirilicom), pretpostavljam tokom alter table.. Kada dodam nove redove nakon altera, ostanu u pismu u kom su dodani, dakle sve ok. Nemam mnogo cirilice pa mogu to rucno da prekrojim, bitno je da mi od sad radi kako treba, ali eto samo da napomenem. Zakacio sam novi xml fajl u attachmentu.
Hvala puno obojici na pomoci, ES rulz. :)
[ Shinhan @ 01.10.2013. 09:37 ] @
Jeste da je ovo malo tangenta, ali hteo sam i ja da se ubacim.
Mi smo za pretragu počeli da koristimo SOLR i u njemu ima jedan super fazon: Unicode normalizacija 1 2.
Bogdane, da li postoji šansa da MySQL doda Unicode normalne forme u kolacije? Ne znam koliko bi to bilo komplikovano za napraviti, ali bi vrlo lepo rešilo ovakve probleme, a pošto je deo standarda ne moraju se pitati državne institucije. [ bogdan.kecman @ 01.10.2013. 10:27 ] @
da se to uskoro napravi, sanse su izmedju male i nikakve ..
implementacija trailing karaktera je otprilike zaokruzila sve feature
requestove koji su postojali po pitanju karakter setova i mysql-a tako
da se tu prica realno zavrsava ... naravno to je moje misljenje .. no
sto se normalnih unicode formi tice ja ne vidim kako to pravi jednacenje
cirilce i latinice posto latinicno B i cirilicno B nigde u unikod
standardu nisu izjednaceni
[ Shinhan @ 02.10.2013. 14:23 ] @
Ah, sad sam još pogledao, izgleda se izjednačavanje latinice i ćirilice radi u ICUTransformFilterFactory a ne u ICUNormalizer2FilterFactory.
Copyright (C) 2001-2024 by www.elitesecurity.org. All rights reserved.
|