|
|
[ Branimir Maksimovic @ 07.06.2020. 20:58 ] @
|
| https://www.theregister.com/2020/06/05/moores_law_coding/
Citat:
n a paper [paywall] published Friday in the journal Science, MIT professors Charles Leiserson and Daniel Sanchez, adjunct professor Butler Lampson, and research scientists Joel Emer, Bradley Kuszmaul, Tao Schardl, and Neil Thompson argue that the tech industry needs software performance engineering, better algorithmic approaches to problem solving, and streamlined hardware interaction.
These three areas at the top of the stack will yield less reliable gains than semiconductor density improvements of the past because they're interrelated.
"Unlike Moore’s law, which has driven up performance predictably by 'lifting all boats,' working at the Top to obtain performance will yield opportunistic, uneven, and sporadic gains, typically improving just one aspect of a particular computation at a time," the authors state.
Nonetheless, that's what's present opportunity now that the further miniaturization no longer looks practical.
I onda:
Citat:
This future demands better programming techniques to write faster code. To illustrate that point, the MIT researchers wrote a simple Python 2 program that multiplies two 4,096-by-4,096 matrices. They used an Intel Xeon processor with 2.9-GHz 18-core CPU and shared 25-mebibyte L3-cache, running Fedora 22 and version 4.0.4 of the Linux kernel.
for i in xrange(4096):
for j in xrange(4096):
for k in xrange(4096):
C[j] += A[k] * B[k][j]
The code, they say, takes seven hours to compute the matrix product, or nine hours if you use Python 3. Better performance can be achieved by using a more efficient programming language, with Java resulting in a 10.8x speedup and C (v3) producing an additional 4.4x increase for a 47x improvement in execution time.
Beyond programming language gains, exploiting specific hardware features can make the code run 1300x faster still. By parallelizing the code to run on all 18 of the available processing cores, optimizing for processor memory hierarchy, vectorizing the code, and using Intel's Advanced Vector Extensions, the seven hour number crunching task can be reduced to 0.41s, or 60,000x faster than the original Python code.
Doslo je vreme asemblera vidim ja :P |
[ Dexic @ 07.06.2020. 21:18 ] @
Js vidim da je vreme da se izbaci Python :)
[ nkrgovic @ 07.06.2020. 21:24 ] @
Ma mnogo su pametni... idi, prosto ne znam gde cu od te pameti. Sta li bi bilo da im je neko otkrio bibliotecke funkcije i optimizovane biblioteke? :) Sta sve danas prolazi kao "naucni rad"....
Murov zakon, tja... radi se na svemu. Da, radi se i na brzem (mikro)kodu, tj. na efikasnijim procesorima, radi se i na novim instrukcijama koje nesto ubrzavaju, tako da, broj tranzistora, kao sto je Gordon Moore tvrdio, raste - ali sad na drugi nacin. Slusali smo i pre par godina da smo stigli do granice, da preko 5GHz ne moze, i stvarno vec godinama ne ide preko 5GHz, ali su procesori sve brzi i brzi. Mozda ne bude moglo vise tranzistora po integralcu, ali tu su "chipleti", multi-chip pakovanja....
I da, bolji algoritmi su UVEK bitni. Graph baze su klasican primer, neke stvari rade redovima velicine brze, zbog drugacijeg koda (nije jedini primer, ovo mi je prvo palo na pamet). Jednostavno, bolji algoritmi nisu prestali da budu bitni nikad, ali, osim ako gospoda nisu na fusnoti resili MP kompletne probleme, reci "nek neko napravi bolje algoritme" nece puno pomoci....
[ optix @ 07.06.2020. 21:44 ] @
Da, Murov zakon sahranjuju vec 25 godina..
[ Branimir Maksimovic @ 07.06.2020. 23:30 ] @
Citat: Dexic:
Js vidim da je vreme da se izbaci Python :)
Mislim da su uzeli ovaj primer zato sto Pyhon ionako sluzi kao lepak poziva f-ja implementiranih u C-u,
a sam problem mnozenja matrica je izuzetno lako paralelizovati, a onda i vektorizaovati. Hteli su da
naprave poentu na najociglednijem primeru :P
[ Whitewater @ 07.06.2020. 23:37 ] @
bio je dalekovid Moore
[ Branimir Maksimovic @ 07.06.2020. 23:38 ] @
Citat: nkrgovic:
Ma mnogo su pametni... idi, prosto ne znam gde cu od te pameti. Sta li bi bilo da im je neko otkrio bibliotecke funkcije i optimizovane biblioteke? :) Sta sve danas prolazi kao "naucni rad"....
Murov zakon, tja... radi se na svemu. Da, radi se i na brzem (mikro)kodu, tj. na efikasnijim procesorima, radi se i na novim instrukcijama koje nesto ubrzavaju, tako da, broj tranzistora, kao sto je Gordon Moore tvrdio, raste - ali sad na drugi nacin. Slusali smo i pre par godina da smo stigli do granice, da preko 5GHz ne moze, i stvarno vec godinama ne ide preko 5GHz, ali su procesori sve brzi i brzi. Mozda ne bude moglo vise tranzistora po integralcu, ali tu su "chipleti", multi-chip pakovanja....
I da, bolji algoritmi su UVEK bitni. Graph baze su klasican primer, neke stvari rade redovima velicine brze, zbog drugacijeg koda (nije jedini primer, ovo mi je prvo palo na pamet). Jednostavno, bolji algoritmi nisu prestali da budu bitni nikad, ali, osim ako gospoda nisu na fusnoti resili MP kompletne probleme, reci "nek neko napravi bolje algoritme" nece puno pomoci....
Vec sam rekao Dexicu, hteli su da naprave poentu.
Granica je udarena negde 2003 sa p4 na 3Ghz, od tada, jednostavno ide se ka povecanju IPC-a. To sto su dosli do 5Ghz, to je zapravo brzina na single core-u. Svi misle da ce neko neki 8jezgarni(ne daj boze vise od toga)
procesor poterati na toliko. Hm ,pogledaj koliko trosi najnoviji Commet Lake iznad 4Ghz ;)
Sto se tice broja tranzistora, da AMD pravi CCX sa po 4-8 jezgara naustrb vece latencije ka memoriji od Intela. Da li ce Intel ici ka tome, videcemo. Medjutim ovaj clanak govori da performanse nece vise ici daleko,
(cega smo svedoci zadnjih 9 godina). Cene i da dalje od 5nm se nece ici. To znaci da u okviru onoga sto imamo polako dolazi vreme da se misli na taj momenat. Mislim artikl je no brainer, svakom bi palo
napamet da u slucaju stagnacije kod performansi, izvlacimo bolje iz postojeceg hardvera, kao sto je to radjeno 70ih,80ih pa i 90ih.
Mislim da oni pucaju na bolje iskoriscenje postojeceg hardvera, pre nego na algoritme, otud poredjenje Pythona,Jave i C-a.
[ Branimir Maksimovic @ 07.06.2020. 23:39 ] @
Citat: optix:
Da, Murov zakon sahranjuju vec 25 godina..
Mislim da generalno, Murov zakon ne vazi negde od 2003 ;)
[ Branimir Maksimovic @ 07.06.2020. 23:40 ] @
Citat: Whitewater:
bio je dalekovid Moore
Ako procitas artikl, Mur je predvideo za sledecih 10 godina od tog momenta, ne dalje. [ Whitewater @ 08.06.2020. 00:45 ] @
mislim dugo je potrajo ipak
[ optix @ 08.06.2020. 01:11 ] @
Citat: Branimir Maksimovic:
Mislim da generalno, Murov zakon ne vazi negde od 2003 
Pa.. ne bi se bas reklo:
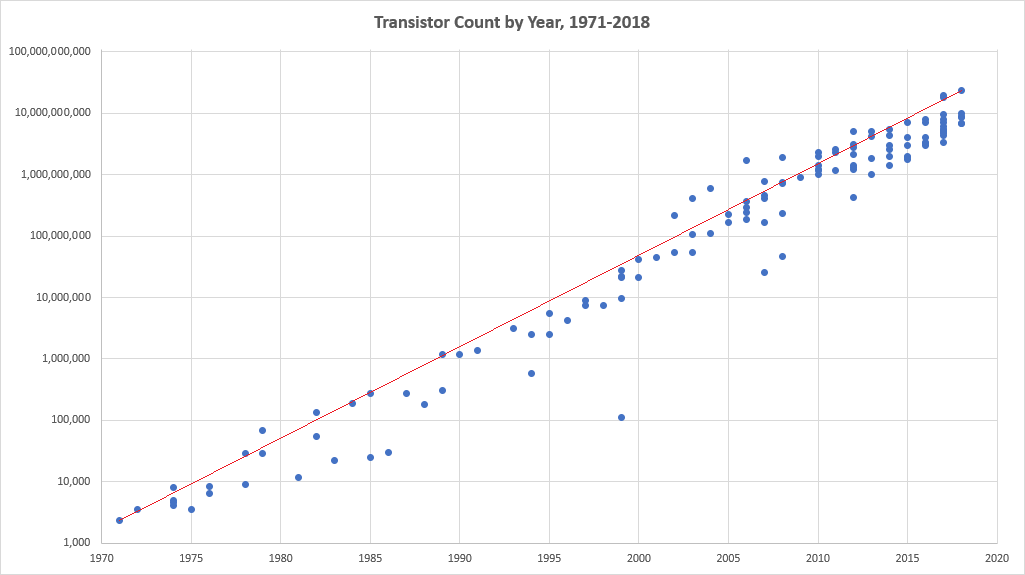
Linija nije 2x povecanje na svake 2 godine, nego 1.9878x na svake dve godine. Mislim da je dovoljno blizu ;-) Ne vidim da se 2003 nesto specijalno desilo.
Par zanimljivih klipova na tu temu od Jim Keller-a - trenutno SVP u Intel-u, inace ko-autora x86-64 arhitekture.
https://www.youtube.com/watch?v=oIG9ztQw2Gc
https://youtu.be/Nb2tebYAaOA?t=1902
Drugi sam malo premotao na relevantan deo, ali je svakako zanimljvo pogledati ceo. [ Branimir Maksimovic @ 08.06.2020. 07:24 ] @
optix:"Ne vidim da se 2003 nesto specijalno desilo."
Ako gledas broj tranzistora, da, ako gledas performanse onda je 2003 doslo do kraja.
A sad se udara i u limit u smanjenju cipova.
Znaci ako cemo da gledamo frkvenciju 3Ghz 2003 i 5Ghz 2020,
ako se to prevede i na poboljsanje IPC-a onda je recimo 9900k po user benchmarku samo
5 puta brzi od p4 iz 2003 (racunam single core)... znaci za 17 godina 5 puta,
a sam 9900k je i dalje aktuelan.
[ ademare @ 08.06.2020. 11:35 ] @
Ova tabela bas i nije relevantna !
Jer Moor je davao dva puta izjave , nije pisao nikakve zakone , vec clanak za popularnu nauku . Prvu je dao 1965 . a drugu 1975 .
U prvoj izjavi je rekao da ce se duplirati svake godine u narednih 10 godina !
U drugoj 1975 . da ce do 1980 ici duplo svake godine , a od 1980 do 1985 duplo na svake 2 godine .
Tako da prikazati tabelu sa kontinuitetom i to od 1971 . nema mnogo veze sa ovim sto je on pricao .
Druga stvar je sto je on kao svaki Amerikanac razmisljao u Imperijalnim merama ! Tako da je on izjavio da ce biti 64.000 komponenti , on se nije bavio Mikroprocesorima u svojoj izjavi , jer tada nisu ni postojali , vec IC , na velicini " quarter square inch " !
Koliko je to ?
Sta Amerikanac pod tim podrazumeva ?
Da li 1/4 inca na kvadrat , ili inc na kvadrat /4 ??
Nekako je neozbiljno raspravljati o necemu , a da se ne zna ni sta je predmet toga " zakona " na sta se odnosi , ni o kakvim se velicinama radi ?
[ nkrgovic @ 08.06.2020. 11:54 ] @
Mislim da tema koju Bane gadja nije "Gordon Moore i tacno slovo njegovih izjava" (sto je irelevantno, osim kao kuriozitet) vec "Kako ce procesori napredovati dalje" i kako ce se povecavati performanse.
Ja i dalje mislim da je clanak senzacionalisticki a primeri glupi. Naravno da ce se ici na paralelizaciju i na specijalizovane "koprocesore", to imamo vec preko 30 godina. To sto je nekad bio Weitek a danas je nVidia ne menja nista sustinski, neke stvari koje su spore se implmenetiraju u hardveru procesora (SIMD intrukcije kao AVX), neke idu na eksterne akceleratore, neke se resavaju paralelizacijom. Racunari iz sedamdesetih su mainframes i minis, to su danasnji serveri - i oni ce napredovati jos znacajno puno godina, na razne nacine. Kucni racunari mozda malo drugacije, ali i oni napreduju jako puno, ako se pogleda trziste "koprocesora" - graficke kartice su sve naprednije. Realno, glavno mesto gde kucni korisnik radi matricne transformacije i jeste grafika :).
A to da "treba raditi na boljim algoritnima" je, i dalje tvrdim, glupa izjava. To svi znamo. Ako autori hoce da to dokazu, nek rese neki konkretan problem, a ne da pricaju "ajde da radimo na algoritmima".... Jedino ako je ovo (los) spin na temu "kme, kme, dajte pare za univerzitete, samo mi mozemo da vas spasemo"....
[ ademare @ 08.06.2020. 12:05 ] @
On moze da gadja i moju tetku ako hoce 
Sta on gadja , to je objasnio , samim tim sto ne zna ni na sta se odnosi Moorov zakon ! Lepo je napisao da ne vazi od 2003. a posle da vazi ako se misli na broj tranzistora , a ne efikasnosti .
Moorov zakon se nikada nije odnosio na Efikasnost !
Ne odnosi se ni na cenu razvoja koja je sve veca i veca itd .
To sta ljudi kasnije vide u onome sto je on rekao , sta izvode iz toga je sasvim druga prica .
On je bio dovoljno Pametan da svoje izjave ogranici na rok od 10-20 godina ! Kada sam bio klinac jos nisam ni bio posao u skolu cuo sam staru pricu o sahovskoj tabli i zitaricama i tada jos kao Predskolsko dete shvatio da je nemoguce da nesto raste duplo u nedogled ! Tada jos nisam znao da se to naziva Eksponencijalni rast , ali shvatio sam da je duplo !
https://en.wikipedia.org/wiki/Wheat_and_chessboard_problem[ optix @ 08.06.2020. 13:02 ] @
Citat: Branimir Maksimovic:
optix:"Ne vidim da se 2003 nesto specijalno desilo."
Ako gledas broj tranzistora, da, ako gledas performanse onda je 2003 doslo do kraja.
A sad se udara i u limit u smanjenju cipova.
Znaci ako cemo da gledamo frkvenciju 3Ghz 2003 i 5Ghz 2020,
ako se to prevede i na poboljsanje IPC-a onda je recimo 9900k po user benchmarku samo
5 puta brzi od p4 iz 2003 (racunam single core)... znaci za 17 godina 5 puta,
a sam 9900k je i dalje aktuelan.
Murov "zakon" i jeste o broju tranzistora po jedinici porvsine, ili inverzno njihovoj velicini, a ne o radnoj frekvenciji procesora.
U tom smislu, originalni text i clanak je mogao da se zove drugacije, a ne da se poziva na "Murov zakon" koji ocigledno nije "mrtav", svakako da je svaka optimizacija i pozeljna i potrebna.. ali ce ovako privuci vise citalaca..
Kao sto i Jim u tom jednom intervjuu kaze - ljiudi vole katastroficne izajave tipa.. we will run out of food, water, space... ili kompjuterskih performansi, da ne kazem broja tranzistora
"The number of people predicting the death of Moore's law doubles every two years"
Peter Lee, VP Microsoft research [ Branimir Maksimovic @ 08.06.2020. 13:40 ] @
Citat: nkrgovic:
Mislim da tema koju Bane gadja nije "Gordon Moore i tacno slovo njegovih izjava" (sto je irelevantno, osim kao kuriozitet) vec "Kako ce procesori napredovati dalje" i kako ce se povecavati performanse.
Ja i dalje mislim da je clanak senzacionalisticki a primeri glupi. Naravno da ce se ici na paralelizaciju i na specijalizovane "koprocesore", to imamo vec preko 30 godina. To sto je nekad bio Weitek a danas je nVidia ne menja nista sustinski, neke stvari koje su spore se implmenetiraju u hardveru procesora (SIMD intrukcije kao AVX), neke idu na eksterne akceleratore, neke se resavaju paralelizacijom. Racunari iz sedamdesetih su mainframes i minis, to su danasnji serveri - i oni ce napredovati jos znacajno puno godina, na razne nacine. Kucni racunari mozda malo drugacije, ali i oni napreduju jako puno, ako se pogleda trziste "koprocesora" - graficke kartice su sve naprednije. Realno, glavno mesto gde kucni korisnik radi matricne transformacije i jeste grafika :).
A to da "treba raditi na boljim algoritnima" je, i dalje tvrdim, glupa izjava. To svi znamo. Ako autori hoce da to dokazu, nek rese neki konkretan problem, a ne da pricaju "ajde da radimo na algoritmima".... Jedino ako je ovo (los) spin na temu "kme, kme, dajte pare za univerzitete, samo mi mozemo da vas spasemo"....
Mislim da je clanak jasan po tome da se ne radi o Murovom zakonu u smislu broja tranzistora, nego, generalno o performansama procesora. Mislim predlog da se poradi na implementaciji i optimizaciji govori u prilog tome.
[ Branimir Maksimovic @ 08.06.2020. 13:40 ] @
Citat: optix:
Citat: Branimir Maksimovic:
optix:"Ne vidim da se 2003 nesto specijalno desilo."
Ako gledas broj tranzistora, da, ako gledas performanse onda je 2003 doslo do kraja.
A sad se udara i u limit u smanjenju cipova.
Znaci ako cemo da gledamo frkvenciju 3Ghz 2003 i 5Ghz 2020,
ako se to prevede i na poboljsanje IPC-a onda je recimo 9900k po user benchmarku samo
5 puta brzi od p4 iz 2003 (racunam single core)... znaci za 17 godina 5 puta,
a sam 9900k je i dalje aktuelan.
Murov "zakon" i jeste o broju tranzistora po jedinici porvsine, ili inverzno njihovoj velicini, a ne o radnoj frekvenciji procesora.
U tom smislu, originalni text i clanak je mogao da se zove drugacije, a ne da se poziva na "Murov zakon" koji ocigledno nije "mrtav", svakako da je svaka optimizacija i pozeljna i potrebna.. ali ce ovako privuci vise citalaca..
Kao sto i Jim u tom jednom intervjuu kaze - ljiudi vole katastroficne izajave tipa.. we will run out of food, water, space... ili kompjuterskih performansi, da ne kazem broja tranzistora :D
"The number of people predicting the death of Moore's law doubles every two years"
Peter Lee, VP Microsoft research
Gledaj, ovi predvidjaju da je 5nm kraj puta :P
[ Branimir Maksimovic @ 08.06.2020. 13:47 ] @
Ja bih jos dodao amandman na ovu pricu, ovo sto se danas govori bice aktuelno za par godina :P
Procesori nisu brzi a softver je sve ambiciozniji, tako da ce pre ili kasnije taj killer feature biti kod
onoga ko zna bolje da optimizuje stvari. Mislim mp3 stream mi ne uzima ni 4% jednog kora, h264 25%
jednog kora, ima to lufta dok ne pocne da bude malo :P
[ Ali Imam @ 08.06.2020. 14:17 ] @
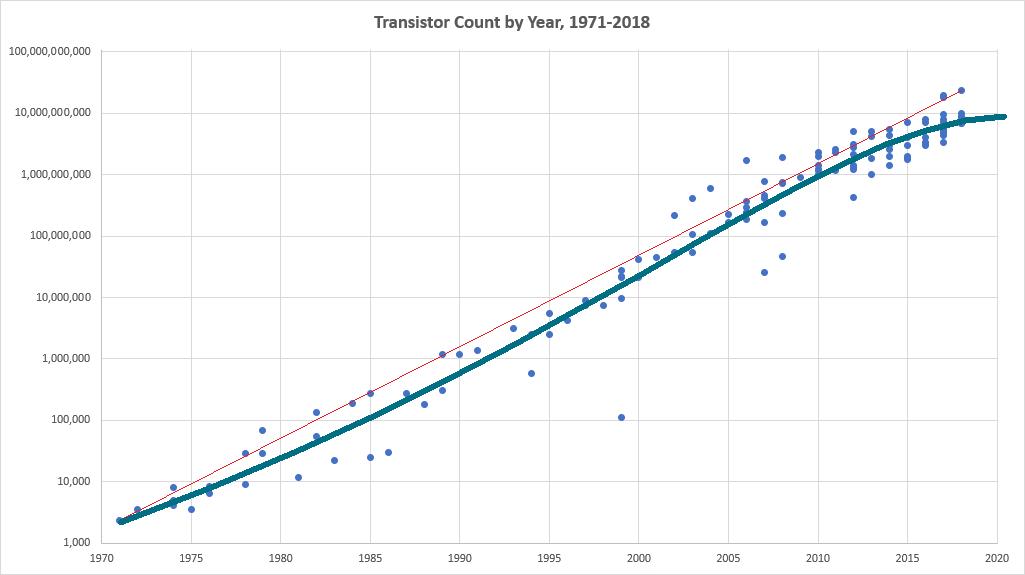
Šta fali krivoj na slici koju sam priložio?
Približava se nekoj asimptoti oko 10 milijardi.
[ Ivan Dimkovic @ 08.06.2020. 19:44 ] @
@Branimir,
Citat:
Doslo je vreme asemblera vidim ja :P
Mislis WebAssembly? :-)
Jedan razbijac programer sa debelim iskustvom sa optimizacijama kosta $100K-$500K u USA, EUR 80K-150K u Nemackoj i tako dalje.
Tim sa nekoliko prosecnih i nekoliko ovih razbijaca + resto kosta par miliona EUR/$ godisnje.
Koliko brzih "v2.0" kutija mozes da kupis za te pare? Puno.
Sta? Stace proizvodnja brzih kutija zbog tripovanja da je gotov "Murov zakon"? Sve i da je to tacno (nije), skaliranje ce preci u inteligentno pakovanje (a-la Foveros), nalepljenu HBM2+ memoriju, brzi I/O, RAM...
Danas mozes da odes u prodavnicu i da kupis kutiju sa 128 jezgara za istu cenu koliko si placao 20 jezgara pre 6 godina. O ostalim stvarima da ne pricamo, ubaci 8 PCIe 4.0 GPU-ova sa HBM2 RAM-om, NVMe SSD-ove i kilo 8-kanalne memorije.
Ta masina je brza za dvocifreni faktor, i to solidan.
Cena je uvek manje-vise ista u konstantnim dolarima. Imas jeftinu kutiju ($5K), mid-size kutiju ($20K) i skupu kutiju ($100K) i vozi. [ Branimir Maksimovic @ 08.06.2020. 20:30 ] @
Citat: Sta? Stace proizvodnja brzih kutija zbog tripovanja da je gotov "Murov zakon"?
Po ovima 5nm je kraj :P
Proizvodnja nece stati, ali nece biti brze :P
[ Ivan Dimkovic @ 09.06.2020. 01:25 ] @
Murov "zakon" je bio vezan za broj tranzistora koji mozes napakovati na fiksnoj povrsini (btw, cak i na 5nm, Murov "zakon" nije pokrio 3D pakovanje).
Brzina nema veze sa tim.
Brze ce biti sasvim sigurno, sve i da si zakucan na nekom procesu, ima jako puno prostora za dalje optimizacije:
- 3D pakovanje jezgara (Foveros)
- Dodavanje vrlo brze memorije u pakovanje (HBM2)
- Brzi interconnect
- Brzi I/O sa perferijama (PCIe 4.0+)
Za jos zahtevnije, umesto mase CPU-ova imaces masu GPU-ova ili "glupih" izvrsnih jedinica koje krckaju tenzore.
Svakako u nekom momentu zbog Amdahl-ovog zakona pumpanje novih jezgara nema smisla (za konkretnu aplikaciju).
Za proizvode koji su u slepoj ulici sto se hiper-paralelizacije tice ima mesta, tipa brzi I/O i memorija.
[ Branimir Maksimovic @ 09.06.2020. 01:42 ] @
Znas kako, sve je to super, ali masovna paralelizacija ne pije vodu zato sto vecinu algoritama nije lako paralelizovati.
Ono sto vidimo je da aktuelni procesori nisu ni dva puta brzi od sandy bdridga iz 2011. Sve to limitira mogucnosti
softvera i onoga sto je izvodljivo na trenutnom hardveru :P
Brza memorija svakako da ce ubrzati donekle ali sa obzirom da vecina algoritama sasvim fino koristi CPU cache
i da zbog toga vidimo da brza memorija ne donosi proprocionalna ubrzanja, benefitirace samo baze i algoritmi
koji jure pointere po memoriji. Dakle umesto sorta linked liste koji u proseku izvrsava 0.3 instrukcije po kloku
videcemo sort od 1 instrukcije po kloku na procesoru koji u proseku vozi 3-4 instrukcije po kloku
zbog utilizacije cache-a :P
[ nkrgovic @ 09.06.2020. 08:32 ] @
Bane, aj' se odluci? :)
Prvo si nam rekao da za sve sto si probao desktop related, vec ne koristis ni 25% CPU-a koji sad imas, a onda nam kazes da imas problem sa paralelizacijom. Sta paralelizujes? Cak i te primene koje si naveo mogu da se paralelizuju, tako da ne ocekujemo da ce biti bilo kakvih problema kod kucnih korisnika. Kod servera, kako da ti kazem, paralelizacija nije bitna.... Jednostavno, za sada bar, server ima mnogo vise korisnika nego jezgara, tako da je gusto pakovanje i dale odlicno resenje. Za ne-paralelabilne serverske primene se koriste razni akceleratori, ili se prelazi na aproksimacije numerickim metodama koje nisu podjednako tacne, ali su dovoljno tacno - a masivno paralelabilne. Danas imas klinke koje vloguju o sminci, ali naravno sa dekolteom i svime pratecim - koje skupe tipa 100K "pratilaca" ocas posla. Klijenata ima sve vise, to je glavni problem infrastrukture - a klijenti su po definiciji nezavisni - i samim tim paralelabilni.
Kao sto ti je Ivan gore rekao, cak i u Srbiji (dobrim delom zbog poreza i dazbina) tim od 20-30 ljudi da razvijes neku platformu kosta nekih, recimo dva miliona godisnje (ballpark). U Nemackoj za to dobijes core team, ovde dobijes sve... Ali cak i za to, troskovi masivnog hardvera se isplate. Zapravo, svodi se na:
- Desktop primene preseliti sto vise u cloud
- Desktop procesori moraju da budu dovoljno brzi za media consumption (ovo vise nije ni blizu)
- Cloud i server primene skaliraju sve dok imas vise korisnika nego jezgara
- Serverske primene najvise boli brzi I/O, a ovde ima jos o-ho-ho mesta za optimizaciju.
Da, malo se vraca client-server model, ali... to ti je sto ti je.
[ nkrgovic @ 09.06.2020. 08:39 ] @
Citat: Ali Imam: Šta fali krivoj na slici koju sam priložio?
Približava se nekoj asimptoti oko 10 milijardi.
nVidia Ampere A100 GPU ima 54 milijarde tranzistora. Think again? :) To ne ukljucuje nalepljenu HBM2 memoriju. Ima FPGA, Xilinix VU19P FPGA, sa 35 milijardi tranzistora - od toga mozes da pravis sam akcelerator za sta 'oces.... Intel XE grafika sa Foveros pakovanjem, koja btw treba da izadje ove godine kao graficka kartica i konkurencija nVidia i AMD-u isto ima skoro 40 miliona tranzistora. (Raja Koduri koga je intel ukrao iz AMD Radeon tima za ovaj projekat je rekao "desetine miliona"). [ Ali Imam @ 11.06.2020. 15:32 ] @
Citat: nkrgovic
nVidia Ampere A100 GPU ima 54 milijarde tranzistora. Think again? :)
Thinkio sam i zaključio da taj dijagram može da se tumači na različite načine.
Mislim, povlačenje krive pomoću lenjira i krivuljara nije više hit.
Za tačnije procene potrebni su numerički podaci i numerička interpolacija.
Ovako zaključak je isti kao i naslov :)
[ Ivan Dimkovic @ 11.06.2020. 16:35 ] @
Citat: Branimir Maksimovic:
Znas kako, sve je to super, ali masovna paralelizacija ne pije vodu zato sto vecinu algoritama nije lako paralelizovati.
Ono sto vidimo je da aktuelni procesori nisu ni dva puta brzi od sandy bdridga iz 2011. Sve to limitira mogucnosti
softvera i onoga sto je izvodljivo na trenutnom hardveru :P
Brza memorija svakako da ce ubrzati donekle ali sa obzirom da vecina algoritama sasvim fino koristi CPU cache
i da zbog toga vidimo da brza memorija ne donosi proprocionalna ubrzanja, benefitirace samo baze i algoritmi
koji jure pointere po memoriji. Dakle umesto sorta linked liste koji u proseku izvrsava 0.3 instrukcije po kloku
videcemo sort od 1 instrukcije po kloku na procesoru koji u proseku vozi 3-4 instrukcije po kloku
zbog utilizacije cache-a :P
Mislim da je nkrgovic pokrio sve.
Van HPC/AI/naucne primene, na serverskoj strani uopste nemas problem sa paralelizacijom. Serveri izvrsavaju zadatke po korisniku/sesiji/stagod. Kako nemas deficit u broju sesija i taj broj je mnogo veci od broja jezgara, ne zanima te uopste paralelizam unutar sesije.
Koji ce ti. Procesor dobije sesiju/korisnika/stagod i imas paralelizam bez da se zlopatis sa borbom sa Amdahl-ovim zakonom (koji je zaista zakon a ne "zakon" kao Murov).
Kad se bude doslo do najmanjeg procesa fabrikacije (i ako se ne nadje neki novi materijal ili dizajn tranzistora), industrija ce preci u gusto 3D pakovanje. Tu imas nove probleme, poput hladjenja. Ali vidis, tu je bas super sto trcis u datacentru, zato sto u datacentru mogu da instaliraju neko svemirsko hladjenje.
Citat:
Brza memorija svakako da ce ubrzati donekle ali sa obzirom da vecina algoritama sasvim fino koristi CPU cache
i da zbog toga vidimo da brza memorija ne donosi proprocionalna ubrzanja, benefitirace samo baze i algoritmi
koji jure pointere po memoriji.
Da i svi AI algoritmi koji su ograniceni propusnom moci (citaj: skoro svi). Sva prepoznavanja lica, fotografija, glasa, razni Asistenti i ostalo ce jako lepo biti ubrzani sa jos nabacane brze memorije.
Citat:
Ono sto vidimo je da aktuelni procesori nisu ni dva puta brzi od sandy bdridga iz 2011. Sve to limitira mogucnosti
softvera i onoga sto je izvodljivo na trenutnom hardveru :P
Mislim da posmatramo sasvim druge segmente industrije. Ti posmatras segment desktop/WS masina, ja posmatram DC/HPC segment.
2011 godina je bukvalno praistorija sto se, recimo, AI-a tice. 2011 su ljudi jos ziveli u ideji da je klasifikacija slika sa performansama uporedivim sa ljudskim tezak problem bez resenja.
Sledece godine se desila revolucija koja je problem ucinila resivim u kratkom roku. Par godina kasnije su klasifikatori prestigli performanse ljudi.
Kolicina operacija koje mozes da izvedes je nastavila da skace kao da se nista nije desilo. [ Branimir Maksimovic @ 11.06.2020. 17:04 ] @
Ivan:"Ti posmatras segment desktop/WS masina, ja posmatram DC/HPC segment."
Mislim da je to jedini segment gde treba vise od 16 kora, ajde 16 na 8 smo od 2017 ;)
No generalno sve o cemu pricas je zapravo optimizacija koda, na hardveru koji sporo
napreduje u performansama :P
"zato sto u datacentru mogu da instaliraju neko svemirsko hladjenje."
Heh, ali data centri nisu ono oko cega se vrti svet ;)
U svakom slucaju mi ovde imamo paralelizaciju, koja van specificnih problema
nema neku primenu za najvise algoritama, kao sto sam rekao. Usvakom slucaju
se opet vracamo na pocetak a to je problem paralelizacije postojecih algoritama
sto donosi drasticna ubrzanja...
[ Ivan Dimkovic @ 11.06.2020. 18:30 ] @
Citat: Branimir Maksimovic
Heh, ali data centri nisu ono oko cega se vrti svet ;)
To neki citat iz 1990-te?
Ako uzmes samo stvari koje prosecan covek koristi danas - Google / YouTube, Netflix & Co., Amazon, Facebook itd. su masivni Cloud servisi.
Zameni sve ovo gore sa lokalnim alternativama ako pricas o Kini.
Onda na sve to dodaj DC resurse koji kreiraju mobilne mreze, digitani TV, procesiraju transakcije sa karticama i tone baza podataka, AI servisa.
Intelov CCG (potrosacki procesori) je doneo $10B u prihodima (Q4 2019)
Intelov DCG (datacentar) je doneo $7.2B u prihodima (Q4 2019)
Samo sto, DCG ima rast 19%, CCG 2%.
Ali ono sto je interesantnije je da 7 firmi kupi pola Intelovih serverskih procesora. Te firme su cloud provajderi i hyperscaleri, cist DC.
Citat:
U svakom slucaju mi ovde imamo paralelizaciju, koja van specificnih problema
nema neku primenu za najvise algoritama, kao sto sam rekao. Usvakom slucaju
se opet vracamo na pocetak a to je problem paralelizacije postojecih algoritama
sto donosi drasticna ubrzanja...
Samo si propustio sitnicu da servisi koji pokrecu Internet, TV i mobilnu komunikaciju uopste nemaju potrebu za "paralelizacijom algoritama" posto paralelizaciju dobijaju za dzabe samom prirodom servisa.
A HPC/AI problemi su mahom masivno paralelni i pogodni za klasicne tehnicke paralelizacije.
Ostaju stvari koje uopste nisu ni smislene za paralelno izvrsavanje. Da, moj kalendar na laptopu nece moci da iskoristi 1000 jezgara. Koga briga?
Citat:
Mislim da je to jedini segment gde treba vise od 16 kora, ajde 16 na 8 smo od 2017 ;)
No generalno sve o cemu pricas je zapravo optimizacija koda, na hardveru koji sporo
napreduje u performansama :P
Ti si jednostavno izignorisao da je skoro svo racunanje otislo iz tvog PC-ja u DC/Cloud.
Kad trazis nesto na Google-u to se izvrsava na servisu od miliona nodova. Jedna glupa pretraga koja ti deluje da malo duze traje (par sekundi) je bukvalno "proletela" kroz indekse velciine hiljada terabajta. Probaj to kod kuce za par sekundi.
Kad gledas Netflix/YouTube/.. tvoj racunar samo prikazuje video. Glavni deo posla se izvrsava u DC-u.
Kad kupujes robu online, tvoj racunar samo renderuje HTML. Glavni deo posla se izvrsava u DC-u.
Kad zoves nekog preko mobilnog ili WhatsApp-a, Vibera - tvoj terminal je data pumpa sa codecima. Sve ostalo se radi u DC-u.
Da, ne treba ti vise od 16 jezgara. Zato sto je neko pametan premesto centar racunanja tamo gde je jeftniji i efikasniji. Pogodi kako stoje stvari sa brojem jezgara koja krckaju tvoje Google pretrage ili ti salju YouTube video pakete.
[ Branimir Maksimovic @ 12.06.2020. 03:22 ] @
Ivan:"Ti si jednostavno izignorisao da je skoro svo racunanje otislo iz tvog PC-ja u DC/Cloud. "
To je samo deo toga. Internet servisi i ini, i to ne svi nego oni veliki. Nije bas tako da se sve odvija
kod velikih.
"Da, ne treba ti vise od 16 jezgara."
Ne iz razloga sto se sve odvija u data centrima, nego zbog toga sto trenutni softver retko koristi
i 8 kamoli 16. Znaci amendum na osnovi artikl je paralelizacija postojeceg softvera.
Copyright (C) 2001-2024 by www.elitesecurity.org. All rights reserved.
|