|
|
[ Mikky @ 31.08.2003. 15:24 ] @
|
| Neznam sta se desilo sa tom temom na ovom forumu gde sam pitao kako napraviti program koji trazi duplirane fajlove po hard diskovima ali u svakom slucaju uradio sam ga i sad mi treba mala pomoc oko optimizacije.
Dakle treba naci sve fajlove na hardu, ubaciti info o njima u memoriju i uporediti svaki sa svakim. To sam uradio preko resizable arraya, znaci prvo alociram memoriju recimo 10kb i nju popunjavam sa informacijama svakog fajla koga nadjem.
Kad se ona popuni onda zovem funkciju koja prosiruje taj memorijski blok na jos 10kb
i sve tako dok ima fajlova. Na kraju dobijem array sa informacijama o fajlovima,
te informacije stavljam u moju strukturu koja sadrzi ime fajla, path, velicinu, atribute..
E sad dolazi uporedjivanje, za n fajlova ima n(n-1)/2 poredjenja, uzimam prvu strukturu
u nizu i poredim je sa svakom sledecom, znaci pocinjem poredjenje od druge pa do kraja niza.
Kad zavrsim sa prvom uzimam drugu i poredim je sa trecom i svakom sledecom do kraja niza itd..
Sve je to lepo ali provalio sam da je sporo, meni treba 10minuta da izvrsi sva poredjenja
dok Windows commanderu za isti posao treba 2 minuta!!!
Struktura izgleda otprilike ovako (MASM32 sintaksa):
Code:
FileInfo struct
szFileName db MAX_PATH dup(?) ; name of file
CreationTime FILETIME <?> ; file's time of creation
ModifyTime FILETIME <?> ; file's last write time
dwSize dd ? ; file size
dwAttributes dd ? ; file attributes
FileInfo ends
Znaci postoji niz ovakvih struktura, info o fajlovima ne ubacujem po nekom redosledu vec kako koji
fajl nadjem (FindFirstFile/FindNextFile) tako ga ubacim.
Pri poredjenju prvo poredim ove dword-ove, pa ako su isti onda stringove (filename)
jer za to treba manje vremena nego da poredim prvo stringove.
E sad, ja vise nemam ideja kako da ovo optimizujem dalje. I kad bi uspeo nesto sigurno ne bi
dobio toliko poboljsanje na nivou windows commandera.
|
[ tOwk @ 31.08.2003. 15:45 ] @
Pa što ne sortiraš listu jednom, i zatim porediš samo „susedne“?
[ filmil @ 31.08.2003. 15:51 ] @
Tvoja pretraga se svodi na problem sortiranja niza elemenata. Za sortiranje ti je potrebna funkcija poređenja (nazovimo je compare()) koja može da utvrdi da li se dve datoteke razlikuju ili ne. Pretpostavljam da imaš metod kako da utvrdiš da li su dve datoteke jednake ili različite jer umeš da porediš elemente.
Teoretski rezultat kaže da mašina Fon Nojmanovog tipa (svi današnji računari), opremljena operacijom poređenja dva elementa niza ne može urediti elemente brže od 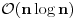 . Poznat algoritam koji ume da uredi elemente niza u datom vremenu zove se Quick sort i izmislio ga je izvesni C. A. R. Hoare (ovo CAR jer je čovek zaista to :) ).
Ideja je da urediš tvoje datoteke prema operaciji compare(), a koristeći Quick sort algoritam. Kako identični fajlovi imaju identične ključeve, u sortiranoj listi naći će se jedni do drugih. Zatim je potrebno proći kroz niz algoritmom unique koji komprimuje višestruke ulaze (odn. omogućava ti da saznaš koji fajlovi se ponavljaju) a koji se može odraditi u linearnom vremenu. Kako je pretraga diska takođe linearna u funkciji broja ulaza, ukupna složenost ovakvog algoritma bila bi a to je malo bolje od tvojih 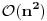 .
f
[ -zombie- @ 31.08.2003. 16:07 ] @
mislim da ću morati da se ne složim sa kolegama filipom i danilom. za ovakav posao je mnogo bolji hash algoritam.
napraviš recimo 16tobitnu hash funkciju od podataka o fajlu, i ubacuješ u niz od 64k elemenata, gde je index niza taj 16tobitni hash.
hash računaš recimo običnim xorovanjem dvobajtnih reči u fajl descriptoru (creation time, modification time, size i atributi su ti verovatno 32bitni brojevi, njih podeliš na po dve reči, i xoruješ. na kraju, xoruješ i po dva bajta iz naziva fajla.
kad izračunaš hash_id jednog fajla, dodaš pokazivač na njegov file descriptor u niz na hash_id mestu hash_array[hash_id]
ako se pri takvoj operaciji, ako već u tom mestu postoji već neki fajl, onda izvučeš njegove podatke preko pokazivača na file_info struct, i uporediš ta dva fajla.
mrzi me da sad dokazujem, ali valjda ovaj algoritam teži (pri lepoj raspodeli/odabiru hash algoritma) komplexnosti O(n) (ovde konkretno za broj fajlova ispod milion.. za više, samo povećaš veličinu hash_id ključa...)
[ filmil @ 31.08.2003. 16:19 ] @
Zombi, to je samo pod uslovom da je složenost umetanja u hash tabelu idealnih 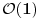 , ali to je moguće samo asimptotski -- ako je hash funkcija idealna, ako ravnomerno raspodeljuje fajlove u pojedine ćelije tabele, ako je tabela beskonačno velika i ako posle toga ne moraš da prolaziš kroz svaku pojedinačnu ćeliju, sortiraš i porediš -- a to ćeš morati da uradiš.
E sad naravno mi govorimo o nekim slovima O -- ali kao što kažu uvek je bitna i ona implicitna konstanta. Može se desiti da tvoja ideja rezultuje u programu koji u nekim slučajevima radi brže. Ali niko ne može potvrditi da će to zaista da se desi.
f
[ -zombie- @ 31.08.2003. 17:09 ] @
hm.. da, zato sam i rekao "teži" pri nekim uslovima. a biću tako hrabar da tvrdim da će ovakav algoritam (za ovaj problem) uglavom dati bolje rezultate od bilo kog sort algoritma.
a i btw, kad malo bolje razmislim, po čemu bi ste vi sortirali listu fajlova?!? po veličini? mislim da će mnogo veća gustina biti oko malih veličina fajlova, pa će i efikasnost quick sorta biti umanjena.
dalje, još jedna prednost hash-a je što se on može puniti odma pri čitanju fajlova, znači ne mora dodatno da troši memoriju na posebnu listu file descriptora. (lično ne znam ni jedan sort algoritam koji može da iskoristi ovu prednost efikasno...)
i generalno (u opštem slučaju), mislim da se uglavnom za nalaženje duplikata koristi hash algoritam, jer najčešće daje najbolje rezultate.
inače miki, verovatno sam i malo preterao.. mislim da ti je za haš u ovom slučaju dovoljan (i brži/jednostavniji/bliži O(1) ;) i samo xor ecimo po dva (niža) bajta iz veličine i vremena kreiranja fajla.. i naravno, to radi odmah, pri nalaženju fajlova, nemoj prvo da ih trpaš u listu, pa da ih prebacuješ u hash mapu....
[ filmil @ 31.08.2003. 18:39 ] @
Sortiranje ne mora nužno da bude po veličini fajla. Dovoljno je da se recimo računa neka vrednost poput hash ključa i da se onda te vrednosti porede za dve datoteke. Sve identične kopije fajlova pritom će se naći jedna do druge. Ostale stvari poput umetanja u letu i slično su optimizacije drugog reda. Drugim rečima to je stavljanje tačke na i, neka prvo proradi sortiranje (to je principijelno poboljšanje) a kozmetika može doći i kasnije.
f
[ leka @ 31.08.2003. 20:52 ] @
Citat: tOwk:
Pa što ne sortiraš listu jednom, i zatim porediš samo „susedne“?
Danilo, to je tipično rešenje koje bi uradio UNIX administrator (verovatno) - sve fajlove na mašini strpao u fajl, propustio isti kroz sort, a onda kroz skript koji ispituje da li trenutna linija tog fajla odgovara sledećoj ... Prosto rešenje koje funkcioniše.
Kad je u pitanju pisanje C aplikacije koja ovo radi, ja bih takođe koristio hash, s tim da bih ja "hash"-irao kompletno naziv fajla sa stazom (primer: /usr/local/share/ede/icons/efileman.png) . [ tOwk @ 01.09.2003. 02:43 ] @
Upotreba heša je potpuno ortogonalna na sortiranje — mogu se kombinovati potpuno nezavisno. Uostalom, ovo bi trebalo da donese znatno veće od petostrukog ubrzanja, ako je zaista nedostatak brzine bio izražen u tome.
Dalje, radi se o podacima koji su već u memoriji, i ne znam zašto ti Leko pominješ neke fajlove, i ko zna šta? ;-) Koliko ja znam, standardni (ISO) C sadrži i jednu vrlo lepu funkciju za ovakve potrebe: qsort().
Sa tim podacima u memoriji, kako lepo pomenu Filip, potrebno je izvesti jedan quicksort. A Zombi, što se tiče toga da će biti mnogo više malih fajlova, ne vidim kakve to veze ima u proceni složenosti QuickSort algoritma? Prosto, za njega nije bitno da li imamo 10 hiljada fajlova koji se razlikuju po veličini za jedan bajt, ili 10 hiljada fajlova koji se razlikuju po veličini za 1MB, već je samo bitno u kakvom početnom poretku se nalaze ovi fajlovi.
Mada, ne znam zašto je problem napraviti funkciju za poređenje koja poredi redosledom kakvim ti god želiš (tj. otkud ti ideja da bismo „mi“ sortirali prema veličini? možemo prema veličini, pa ako je ista prema datumu, pa ako je isti prema imenu, pa... — tako se to i inače radi :-P).
Zatim, potrebno bi bilo izraditi dobru heš funkciju. Kako će sva vremena (vreme pravljenja, izmene, pristupa datoteci) biti u kratkom vremenskom periodu (2–3 godine u odnosu na opseg od 2 milijarde sekundi, ili oko 66 godina), to treba uzeti u obzir, a čini mi se da nijedan predlog to ne radi.
[ sspasic @ 01.09.2003. 10:35 ] @
Meni se cini da bi bila najbolja kombinacija sortiranja po velicini i hash funkcije, obzirom na to da se velicina fajla moze saznati samo citanjem informacije o fajlu koja je zapisana u direktorijumu, a za hash treba procitati i sadrzaj datoteke.
Evo mog predloga:
- Prvi deo
1. Procitas informacije o svim fajlovima (ime, velicina)
2. sortiras tu listu po velicini fajlova
3. prodjes kroz sortiranu listu i za sve grupe fajlova koji su po velicini jednaki ides na drugi deo
- Drugi deo (svi fajlovi jednake velicine)
1. Procitas sve fajlove i odredis im MD5 (ili CRC ili nesto slicno)
2. iz MD5 odredis hash value (1..hash_table_size)
3. stavis informacije o fajlu u hash
4. Ako se u slotu hash tabele na istom mestu nalazi vec neki fajl, prvo uporedis MD5, pa tek ako se i to poklopi uporedjujes fajl bajt po bajt
[ chupcko @ 01.09.2003. 16:03 ] @
http://www.ioccc.org/1998/schweikh3.c
Mozda ovo moze da pomogne, lepo je objasnjeno kako radi :))))
[ bOkIcA @ 01.09.2003. 19:03 ] @
Citat: leka:
...s tim da bih ja "hash"-irao kompletno naziv fajla sa stazom (primer: /usr/local/share/ede/icons/efileman.png) .
Zar ne bi u ovom slucaju dobio dva razlicita rezultata hash-a? [ Mikky @ 08.09.2003. 22:38 ] @
Ok, trebalo mi je malo (vise) vremena da demistifikujem sve vase postove posto nisam "skolovan" programer vec "divljak" :)))))
Ima par problema, prvo velicina strukture tj velicina svakog elementa niza, koji opisuje fajl nije fiksne velicine. Ona zavisi od velicine imena fajla i velicine patha.
npr
c:\1\test.txt
c:\blah\dummy\test.txt
za ovaj prvi fajl bice potrebno manje memorije nego za drugi jer mu je path kraci.
Da kazem da bi ovo mogao da sredim da mi svi elementi niza budu jednaki tako sto cu koristiti pointer na ime fajla umesto da smestam sam string u niz.
znaci umesto
Code:
char szPath[velicina_stringa];
bilo bi
Code:
char *szPath;
Samo nisam siguran da li je ovo potrebno da radim, da li ce mi biti lakse da uradim uporedjivanje i sortiranje ako su svi elementi niza jednake velicine?
Druga stvar, u mom programu sam ostavio opciju da se fajlovi porede po onome sto user izabere... znaci on moze da izabere da li ce da poredi po velicini, vremenima, i imenu ali isto tako moze da izabere da se porede samo po imenu. Znaci u ovom drugom slucaju sortiranje niza po velicini bi bilo besmisleno jer velicina neigra nikakvu ulogu u poredjenju i trazenju duplikata. Takodje cu da ostavim opciju da se poredjenje po imenu vrsi kao case sensitive. U slucaju da nije case sensitive onda hasiranje imena fajla opet ne bi imalo smisla jer bi dobio dva razlicita hasha za iste fajlove npr "Test.txt" i "tEST.txt". (znaci program je za win32 gde fajlovi nisu casesensitive kao na unixu).
Ovo cu jos da vidim kako cu da resim.. verovatno cu da na osnovu onoga sto je korisnik izabrao kao kriterijum za uporedjivanje odredim i kako cu da poredim. Npr ako izabere velicinu i modify time, onda cu da sortiram niz po velicini i sl.
BTW koji od ova dva je efikasniji (brzi) nacin sortiranja niza u mom slucaju
1. Nadjem sve fajlove, pa uradim quicksort
2. Kako koji fajl nadjem ubacujem ga u niz i odmah sortiram (npr bubble sort)
[ Rapaic Rajko @ 10.09.2003. 12:52 ] @
Elem...
1) Prvi nacin je definitivno bolji, jer quicksort najbolje radi na nesortiranim podacima.
2) Zaboravi bubblesort u bilo kojoj varijanti; to je prevazidjen algoritam, i pominje se samo u udzbenicima.
3) Tebi treba varijanta quicksorta u kojoj prosledis Compare funkciju; na taj nacin sortiras kako zelis podatke.
Pozdrav
Rajko
[ Mikky @ 16.09.2003. 23:46 ] @
Evo cisto da se javim i zahvalim na pomoci, uspeo sam i rezultat je vise nego sto sam ocekivao. Znaci za onaj posao sto mi je prva rutini radila 10 minuta a Windows Commander za samo 2 minuta (znaci 5x brze), sad mi treba samo 1 sekund a mozda i manje, nisam tacno merio
Znaci ubrzanje... 600 puta u odnosu na prvobitnu rutinu, odnosno 120 puta u odnosu na wincmd  [ tOwk @ 17.09.2003. 00:10 ] @
Citat: Mikky:
Znaci ubrzanje...
A upotreba memorije (bar okvirno)?
Bilo bi lepo i da kažeš šta ti je konkretno dalo najbolje rezultate (tj. najveće ubrzanje), kad su se već ljudi toliko trudili da ispišu gomilu mogućnosti ;-)
[ Mikky @ 17.09.2003. 00:54 ] @
Ok, znaci upotreba memorije na minimalnom nivou.
Za svaki pronadjen fajl imam u memoriji po jednu onu strukturu (od cinimi se 7 dword-ova tj 28 bajtova) + full path string. U pocetku sam za svaki fajl uzimao struktura + MAX_PATH bajtova za skladistenje stringa sto je u 99% slucajeva bacanje resursa jer skoro ni jedan fajl (sa pathom) nema velicinu MAX_PATH (sto je cinimi se 260 bajtova). Dakle memoriju korisitm samo koliko je potrebno, ni bajt vise.
A ubraznje je najvise postignuto tako sto prvo poredim samo fajlove po velicini, pa ako je to jednako onda poredim ostalo (ime, date/time..), tako da je to velika usteda. Pre toga samo koristio quicksort da sortiram niz po velicini fajlova, njemu treba recimo mozda 0.1 sekunda da sortirara taj niz od 100 hiljada clanova (svaki clan niza == ona struktura gore)
Tako da dobijem jedne pored drugih clanove sa istim velicinama i tako ih poredim, cim naidjem na sledeci clan koji nema istu velicinu tu prekidam poredjenje i prelazim na sledeci fajl.
Nisam pravio nikakve hashove, mislim da bi mi to samo usporilo celu akciju posebno ako je neki sloze algo tipa crc32.
Naravno sve ovo uradjeno u asembleru, pokusao sam sto manje da koristim promenljive u memoriji a sto vise registre, mada ima jos malo mesta za optimizaciju ali to je moze se reci nebitno ako niste fanatik kao ja.
Eh sad kad gledam wincmd mi je bas spor nesto, kod mene ni nevidis kad na dialogu proleti progress od 0 do 100% :)
[ Mikky @ 17.09.2003. 01:30 ] @
Evo za memoriju konkretno, u WinXp kada izvrsim pretragu na mom hardu od 80gb windows commanderom i mojim programom, windows task manager mi kaze
Wincmd 30.9mb
Moj program 18.6mb
Ukupno ima 185.134 fajlova neracunajuci foldere.
[ Rapaic Rajko @ 17.09.2003. 11:41 ] @
Auh, svaka cast: quicksort + assembler!
Mislim, radio sam sa quicksort-om u mnogo varijanti, ali mi je ipak zvucalo malo prebrzo: sort na 100000 clanova za 0.1 sekunde. A onda sam procitao da si pisao u assembleru...
Evo ti i jedan hint kako da ubrzas stvar jos vise. Koristio si niz struktura (recorda) za podatke o fajlovima, je li tako? Shodno tome, swap (zamena) dva recorda u nizu ti radi sa kompletnim strukturama (kopira se po 28 bajtova). A da razmislis o nizu pointera na recorde? Na taj nacin ne bi swap-ovao kompletne recorde (ostaju u memoriji gde jesu), vec samo pointere na njih (recorde). Velicina pointera je 4 bajta...
Pozdrav
Rajko
[ -zombie- @ 17.09.2003. 17:47 ] @
Citat: Mikky:
Nisam pravio nikakve hashove, mislim da bi mi to samo usporilo celu akciju posebno ako je neki sloze algo tipa crc32.
ma nema potrebe za crc32. mislim da sam ti već rekao da bi i jednostavni hash završio posao. ajde probaj ovo, umesto da sortiraš po veličini fajla, sortiraj po XORovanoj vrednosti veličine i vremena fajla (isto 4 bajta). taj jedan xor neće ništa usporiti program.
i izmeri za nas i postuj dužinu trajanja drugog dela tvog programa (onaj koji prolazi taj niz i poredi članove). teoretski (a sigurno i praktično) drugi deo programa će biti mnogo brži jer ćeš imati vrlo malo (ako uopšte) fajlova sa istim hashom.
[ Reljam @ 17.09.2003. 18:48 ] @
Citat: Mikky:
Znaci za onaj posao sto mi je prva rutini radila 10 minuta a Windows Commander za samo 2 minuta (znaci 5x brze), sad mi treba samo 1 sekund a mozda i manje, nisam tacno merio
Znaci ubrzanje... 600 puta u odnosu na prvobitnu rutinu, odnosno 120 puta u odnosu na wincmd :)
Cekaj, Windows Commander procita ceo disk (tj dirove) i onda uradi sort i to sve zavrsi za ta 2 minuta.
Tvoj program samo sortira iste te podatke za par sekundi. Ali gde je tu citanje diska? Siguran sam da tvoj program ne moze da procita sve direktorijume za 1 sekundu.
Tj. otkud znas da i commander ne odradi sort (ili bilo koj vec algoritam) za istu tu 1 sekundu?
Takodje, redosled je bitan. Kada jedanput protrcis kroz sve direktorijume, Windows ce da kesira njihov sadrzaj, tako da ako prvo benchmarkujes Commander pa onda tvoj program dobices bitno razlicit rezultat nego da resetujes kompjuter, pa onda uradis istu stvar obrnutim redom.
Super je to sto si uradio, nego samo da utvrdimo objektivne mere... [ Mikky @ 18.09.2003. 01:12 ] @
Rajko, ok ideja da umesto niza struktura imam niz pointera zvuci kao jos vece ubrzanje, samo trenutno sam ovim zadovoljan tako da me trenutno mrzi da opet prepravljam dosta toga ali uradicu i to uskoro
-zombie-, problem je sto u programu moze da se bira da li ce u kriterijum poredjenja ubaciti i creation/modify date/time tako da to xorovanje bi bilo ok u tom slucaju ali ove opcije uglavnom se nece koristiti jer ti kad kopiras fajl na drugo mesto njemu se promeni creation (ili bese modify) vreme tako da on ne bi bio prepoznat kao duplikat ako bih im poredio i ta vremena.
Uveo sam da uvek proverava po velicini i imenu, znaci te opcije nemogu da se menjaju a ove ostale mogu. Tako da mozda ako imas neki predlog sa ovakvom situacijom reci.
Reljam, znaci ovde pricam samo o uporedjivanju onoga u memoriji.. Naravno da je potrebno malo vise vremena da se ceo hdd pretrazi... khm, treba li da spominjem da sam i u tome prilicno nadmasio wincmd (u obzir je uzeto kesiranje hdd-a) ;)
Znaci 2 minuta treba wincmd da od trenutka kad zavrsi pretragu fajlova tj od trenutka kad pocne uporedjivanje do trenutka kad se zavrsi i izbaci rezultate duplih fajlova.
U tih 2 minuta on odradi sortiranje i uporedjivanje (pretpostavljam da sortiranje radi posle zavrsene pretrage mada moguce je i da sortira u letu, tj kako koji fajl nadje tako ga sortira)
A ovo sto sam ja napisao odradi quicksort za nesto ispod sekunde, a posle toga sledi uporedjivanje koje traje isto jako kratko ne vise od par sekundi. Znaci ceo posao odradi za par sekundi a wincmd za 2 min.
Naravno ovo su sve odokativne metode tako da ne drzite me za rec.
Sto se tice kesiranja, to ovde nisam uzimao u obzir jer je diskusija o onome sto se desava posle pretrage, tj ono sortiranje i uporedjivanje u memoriji, dakle brzina hdd-a ne utice.
Mada sam primetio da kad jednom uradim search sa mojim programom i posle jos jednom, taj drugi put hdd u opste se necuje, dok kad to isto uradim sa wincmd hdd se drugi put ipak malo cuje kad pretrazuje neke zabacenije folder.
Uradicu bas ovih dana malo preciznije merenje (mada nisam siguran kako to bas da izvedem najbolje) + jos malo optimizacije pa cu javiti rezultate.
[ bOkIcA @ 18.09.2003. 01:20 ] @
Probaj to da radis na network disku, mislim da se tada ne radi kesiranje.
[ -zombie- @ 18.09.2003. 01:33 ] @
hm.. da, shvatam. u tom slučaju ne bi moglo (btw, ne menja se vreme pri kopiranju).
elem, ako uvek porediš veličinu i ime, možeš recimo da xoruješ veličinu faja i jedan long (4 bajta) sastavljen od: dužine imena fajla (jedan bajt), i tri karaktera iz imena fajla (tri bajta).
e sad, još samo kako najbolje odabrati ta tri karaktera. recimo, bez mnogo filozofiranja, uzmi prvi, treći i poslednji karakter u imenu (naravno, reši spec. slučaj kada ime ima 2 ili manje karaktera nekako, sve jedno)
a što se merenja tiče, pa, najbolje je da onaj deo programa čiju brzinu meriš (a znaš i sam da ne valja meriti brzinu celog programa odjednom) ponoviš više puta, recimo 10 ili 100, i naravno, zapamtiš vreme pre izvršavanja i vreme posle, oduzmeš i podeliš sa 100.
to bi trebalo da je to.. ajde probaj, pa nam javi ;)
[ Dragi Tata @ 18.09.2003. 02:25 ] @
Citat: Mikky:
Naravno sve ovo uradjeno u asembleru, pokusao sam sto manje da koristim promenljive u memoriji a sto vise registre
Nadam se da se ovo "sve" odnosi samo na funkciju koja sortira fajlove, jer praviti UI u asembleru nema baš nekog smisla.
Takođe, interesuje me koliko bi se izgubilo na performansama da si umesto qsort-a u asembleru koristio standardnu C++ std::sort() funkciju.
[ Reljam @ 18.09.2003. 02:31 ] @
Nadam se da ako sortiras podatke, da ces sortirati niz pointera na podatke, a ne niz samih podatke (pointere bi naravno dereferencirao prilikom poredjenja). Ovo je mnogo brze od sortiranja samih podataka.
[ Mikky @ 18.09.2003. 13:41 ] @
Network disk nemam a i ne znam tacno sta je to, posto nemam iskustva sa mrezama
tako da ce to malo da saceka.
-zombie-, da li ja tebe dobro razumem:
Code:
1. poredjam po velicini
2. napravim xor hash od velicine i par karaktera
3. poredim po velicini,
ako su isti
{
4. poredim hash, ako su isti
5. poredim sve ostalo
}
Dragi Tata, nazalost ja jednostavno ne znam da programiram GUI u c++ tj ceo taj oop
koncept programiranja mi je jako tezak, nemogu da se snadjem kad nevidim tok
programa, izgubim se kad gledam tu hijerarhiju klasa itd.. ali to je sad druga tema.
Tako da je meni sve u asm pa i UI ali MASM ima makroe koji odradjuju jako dobar
posao pa je asm u win32 prakticno kao C, samo sto daje bolje rezultate :)
npr ovo je cist asm bez makroa
Code:
cmp eax,0
jz do_stuff
jmp do_other_stuff
a ovo je sa MASM makroima
Code:
.if eax==0
; do stuff
.else
; do other stuff
.endif
Ovo ce MASM da prevede u onaj gore kod koji bi inace pisao rucno.
Takodje "invoke" makro
cist asm
Code:
push parm2
push parm1
call API
C fazon
Code:
invoke API,parm1,parm2
A za std::sort() bi mogao da probam samo ne znam da li ona moze staticki da se linkuje
sa mojim programom, tj ako je to sve u sklopu neke klase (std?) onda ne znam da li ce moci?
A ako je to "standalone" C funkcija sa npr __stdcall nacinom pozivanja onda nije nikakav
problem jer sam vec radio slicne stvari.
Inace bas cu malo da pogledam po shareware trzistu utilite ovog tipa, bas da vidim ima
li neki koji radi ovaj posao brze od mene pa cu da javim :)
[ -zombie- @ 18.09.2003. 22:28 ] @
Citat: Mikky:
Code:
1. poredjam po velicini
2. napravim xor hash od velicine i par karaktera
3. poredim po velicini,
ako su isti
{
4. poredim hash, ako su isti
5. poredim sve ostalo
}
najn. izračunaj hash za svaki fajl recimo kad ga učitaš u memoriju (tj podatke o njemu) i poređaj po tom hashu, a ne po veličini.
onda će (bar teorijski) da se u poređanom nizu jedan pored drugog, sa istim hashom, nađu samo fajlovi sa istom veličinom i istim imenom. time će ti broj poređenja biti mnogo manje nego ako ih ređaš samo po veličini... [ Dragi Tata @ 19.09.2003. 16:51 ] @
Citat: Mikky:
Dragi Tata, nazalost ja jednostavno ne znam da programiram GUI u c++ tj ceo taj oop
koncept programiranja mi je jako tezak, nemogu da se snadjem kad nevidim tok
programa, izgubim se kad gledam tu hijerarhiju klasa itd.. ali to je sad druga tema.
Nisam ni mislio na C++ i OOP, već na plain old C. Doduše, asembler sa makroima je već skoro C (hehehe), ali ipak mislim da je C udobniji. [ tOwk @ 19.09.2003. 17:03 ] @
Citat: Mikky:
A za std::sort() bi mogao da probam samo ne znam da li ona moze staticki da se linkuje
sa mojim programom, tj ako je to sve u sklopu neke klase (std?) onda ne znam da li ce moci?
A ako je to "standalone" C funkcija sa npr __stdcall nacinom pozivanja onda nije nikakav
problem jer sam vec radio slicne stvari. (ANSI, ISO, kako već ko voli da ga zove) obezbeđuje funkciju qsort kojoj prosleđuješ niz (preko početka i veličine elementa) i funciju za poređenje dva člana. Probaj sa tim da vidiš kakve rezultate daje :-)
[ Shadowed @ 19.09.2003. 22:11 ] @
Pratim sve vreme ovu temu i moram reci da sam primetio da ne uzimate u obzir mogucnost da fajlovi budu duplirani a da im ime (na primer) bude razlicito. Isto moze da bude slucaj sa datumom i svim ostalim osim sa veliciom tako da mi izgleda pogresno raditi sa hash-om koji se dobija iz velicine i jos necega ili uopste sa uporedjivanjem bilo cega osim velicine.
Naravno sve ovo ne vazi ako je program od pocetka i trebao da bude takav da pronalazi iste fajlove sa istim osobinama (a ne samo saadrzajem).
Ili sam ja nesto pogresno shvatio (a mislim da nisam)  ...
Copyright (C) 2001-2026 by www.elitesecurity.org. All rights reserved.
|