|
|
[ sekvoja @ 18.10.2008. 03:22 ] @
|
| Tekstovi upisani u bazu sadrze nase karaktere čćšđž
Ako neko ukuca "šišarka" pretraga je uspesna, ali ako ukuca "sisarka" nema rezultata.
Zanima ma kako ste vi to resavali...
Meni trenutno pada na pamet samo dupliranje sadrzja u bazi, sto i nije bas neko resenje.
U jedno polje se upisuje regularno a u drugo se upisuje isti tekst samo su nasi karakteri
konvertovani (č->c, š->s itd).
Ili npr da rezultat pretrage ubacim u array pa da sadrzaj tog array-a konvertujem i zatim
pretrazim array...
Hmm, treba mi ideja... poz |
[ dakipro @ 18.10.2008. 08:17 ] @
Sad mozda zavisi od strukture baze i kolicine podataka. Ako nije nesto ogronmo, i ako sadrzaj nije blob (text, a idealno bi bilo da je varchar) onda ubaci duplikate sa obicnim slovima i uvek pretrazuj po obicnim slovima, i to tako sto ces ono sto korisnik unese da pretvoris u 'obicna' slova. Drugo je da za uneto šišarka ti trazis OR šišarka OR sišarka OR šisarka OR sisarka. Sve sem da sve rezultate izvadis u niz pa da pretrazuejes niz, to je lose, neces ni paginaciju imati onda, a imaces upit nad celom tabelom, sto uopste nije dobro.
Sad nisam probavao razliku izmedju prva dva, kazem, zavisi od strukture tabele. Ja cesto klijentu dodam jos jedno polje Search Tags da tu upise sve sto zeli da ima veze sa proizvodom, recimo nekada su proizvodi KVA-2322 pa onda KVA 2322 ili KVA2322 ne daje rezultate, onda klijent sam to resi onako kako misli da je najpogodnije. Opet, nemoz ovo primeniti uvek.
Mozda pak da pogledas neke gotove forume da li i kako oni to resavaju.
[ Nikola Poša @ 18.10.2008. 15:10 ] @
Ne znam kako, ali ja recimo na pretrazi na ovom mom sajtu taj problem nemam. Evo primera: ovo su rezultati pretrage sa unosom "sledeća", a ovo sa unosom "sledeca". Rezultati su kao shto vidish isti... U bazi su mi podaci u UTF8 enkodingu, a upit je standardan za pretragu, odnosno u WHERE-u koristim LIKE: WHERE (t.naslov LIKE '%$unos%' OR t.opis LIKE '%$unos%').
Ali ako vec ne mozhesh da izbegnesh taj problem, mislim da bi ti najbolje reshenje bilo da tu rech koju neko ukuca pre upita "provuchesh" kroz neku vrstu transliteratora, odnosno, da odradish zamenu nashish slova sa standardnim slovima, a onda u upitu da pitash za obe varijante, npr. WHERE (tekst LIKE '%$unos_obichan%' OR tekst LIKE '%$unos_nasha_slova%'). [ sekvoja @ 18.10.2008. 15:44 ] @
I ja koristim standardan upit
Code:
...WHERE "title LIKE '%$searchphrase%'...
ali definitivno nije moguce da vrati 'sledeca' i 'sledeća. Takodje u bazi cuvam podatke u UTF-8 encodingu.
Za sada cu se drzati duplog sadrzaja pa ako nesto smislim promenicu...
P.S.
Kako bih mogao da konvertujem npr 'sisarka' u 'šisarka', 'sišarka', 'šišarka' u nekoj for petlji?
[Ovu poruku je menjao sekvoja dana 18.10.2008. u 17:05 GMT+1][ Jbyn4e @ 18.10.2008. 16:31 ] @
Sta ste svi zapeli za LIKE, kad postoji REGEXP?
http://dev.mysql.com/doc/refman/5.0/en/regexp.html
Code:
SELECT * FROM tabela WHERE uslov REGEXP '[cčć]' ;
ce dati sva polja koja imaju c, č ili ć u uslovu.
Kombinujte to sa str_replace (npr ako je u stringu c, zameni ga sa [cčć] i to prosledi kao regexp...) [ Nikola Poša @ 18.10.2008. 18:26 ] @
Citat: sekvoja:ali definitivno nije moguce da vrati 'sledeca' i 'sledeća.
Vidish da jeste... :D
Citat: sekvoja: Kako bih mogao da konvertujem npr 'sisarka' u 'šisarka', 'sišarka', 'šišarka' u nekoj for petlji?
Mogao bi sa funkcijom str_replace. Mozhesh npr. da napravish dva niza, pa da u for petlji samo izmenjash slova, ovako:
Code:
$nasha_slova = array('š', 'đ', 'ž', 'č', 'ć');
$slova = array('s', 'dj', 'z', 'c', 'c');
for ($i = 0; $i<count($slova); $i++){
$tekst = str_replace($nasha_slova[$i], $slova[$i], $tekst);
}
Ako si na to mislio... [ Nemanja Avramović @ 18.10.2008. 18:56 ] @
Taj kod ne radi zato što u svakoj iteraciji uzima string $tekst i menja svako pojavljivanje s će zameniti sa š itd...
Ovde bi mogao neki brute-force-like pristup (ili nešto što nema veze sa brute-force-om, ali meni ovakav izraz zvuči skroz logično  ) da se primeni, ali ne znam koliko bi to trošilo resursa? U svakom slučaju vredi pokušati  [ sekvoja @ 18.10.2008. 19:08 ] @
REGEXP obecava ali ga ja jos uvek nisam usavrsio,
moracu da se pozabavim time...
[ Nikola Poša @ 18.10.2008. 21:09 ] @
Citat: Nemanja Avramović: Taj kod ne radi zato što u svakoj iteraciji uzima string $tekst i menja svako pojavljivanje s će zameniti sa š itd...
A pa da, tek sad vidim shta je on trazhio, ja sam mislio da je hteo da od "šišarka" dobije "sisarka", i obrnuto...  [ Nemanja Avramović @ 18.10.2008. 21:54 ] @
I u tom slučaju (da hoće sve da zameni) petlja bi bila nepotrebna. Ovde bi trebalo menjati po jedno slovo u svakoj iteraciji (pa onda po dva, i tako do broja slova koliko ih ima u stringu), a stvar se komplikuje sa brojem slova koja se menjaju (šđč枊ĐČĆŽ).
Zanimljiv izazov... možda bi RegEx pomogao...
[ sekvoja @ 19.10.2008. 03:02 ] @
Citat: Nemanja Avramović:Ovde bi trebalo menjati po jedno slovo u svakoj iteraciji (pa onda po dva, i tako do broja slova koliko ih ima u stringu)...
To sam i mislio, ali garant postoji resenje u jedoj liniji koda,
samo sto ja ne znam... :)
Ako je neko izvalio resenje bilo bi lepo da podeli sa ostalima :)
Pozdrav [ Jbyn4e @ 19.10.2008. 10:14 ] @
Pa zar ovde niko ne zna regularne izraze?
Znaci rekao si:
Citat:
Ako neko ukuca "šišarka" pretraga je uspesna, ali ako ukuca "sisarka" nema rezultata.
regexp na [sš]i[sš]arka ce ti dati i sisarka, i sišarka i šisarka i šišarka. Šta tu nije jasno? [ goldmankm @ 19.10.2008. 10:34 ] @
[ robert63 @ 19.10.2008. 10:34 ] @
Aj sada jedno mozda " nedoraslo" pitanje:
A zasto se u tom programcetu za pretragu ne uradi da kada ukucas
sisarka
( al'smo se u'vatili te sisarke  )
onda program pita : Jeste li mislili na " šišarka "-?
A korisniku se prepusta da se odluci da-ili-ne !
'el bi mozda moglo tako nesto da se izvede?
[Ovu poruku je menjao robert63 dana 19.10.2008. u 13:24 GMT+1][ sekvoja @ 19.10.2008. 17:19 ] @
Citat: Jbyn4e: regexp na [sš]i[sš]arka ce ti dati i sisarka, i sišarka i šisarka i šišarka. Šta tu nije jasno?
Nije jasno sto ne poznajem regexp :), ali vec sam se bacio na ucenje
[Ovu poruku je menjao sekvoja dana 19.10.2008. u 18:32 GMT+1][ darkofdoom83 @ 07.02.2011. 19:30 ] @
izvinjavam se sto ponovo otvaram temu,ali imam isti problem i nikako da ga resim.
Naime hocu da ako korisnik recimo upise slusalice da mu se pojave i slušalice u rezultatima pretraga.
Polje u bazi u kojem radim regex je varchar i utf8_unicode_ci .
evo recimo bas za primer reci slusalice samsung sam probao dve vrste regexa,ali ni jedna ne radi:
SELECT * FROM tabela WHERE naslov REGEXP '(.*)[sÅ¡]lu[sÅ¡]ali[cÄć]e(.*)[sÅ¡]am[sÅ¡]ung(.*)' - ovo je verzija kao sto stoji u bazi (pre nego sto se pretvori u utf-8 na stranici)
SELECT * FROM tabela WHERE naslov REGEXP '(.*)[sš]lu[sš¡]ali[cčć]e(.*)[sš]am[sš]ung(.*)' - ovo je verzija sa nasim slovima ali mi ni ovako ne radi.
znaci vrati mi rezultate bas kao sto sam i zadao,bez nasih slova.
Molim vas pomozite neko ako zna posto cu polako da posizim od ovoga... :)
[ darkofdoom83 @ 07.02.2011. 20:12 ] @
ajde da ja odgovorim posto je problem resen.
Pre svakog upisa i iscitavanja iz baze treba opaliti mysql_query("SET NAMES 'UTF8'");
Ako se ovako odradi i obican like "%nesto%" ce da vrati sa i bez nasih slova.
[ peca89bg @ 07.02.2011. 21:16 ] @
kakvi regularni izrazi za pretragu? ?
Code:
$search = $_POST["tekst"];
$search = trim($search);
$serach = clean($search); // f-ja za prevent mysql injection - bilo koja ili jednostavno addslashes()
//ovde upit
while(bla bla)
{
echo "Naziv: " . htmlspecialchars($niz["naziv"]) . "........";
}
[ strutter.poison @ 07.02.2011. 23:19 ] @
Hm. resava li se ovo sa collation recimo utf8_general_ci?
[ darkofdoom83 @ 08.02.2011. 07:13 ] @
ne znam,ali ako posle konektovanja na bazu ne odradim ovo set names tada se u bazu nece upisati čć itd vec html za ove karaktere.
[ vatri @ 08.02.2011. 08:26 ] @
Mislim da to nije to HTML vec "smece" (bas sam ja prije par dana imao problem sa tim).
http://www.mysql.rs/2010/07/smece-u-bazi-po-ko-zna-koji-put/
Znači treba uvjek nakon konekcije uraditi "SET NAMES UTF8". [ strutter.poison @ 08.02.2011. 21:33 ] @
Ah da, video sam taj clanak.
Nekao sam shvatio da su problem nasa mala/velika slova pa zato rekoh za utf8_general_ci. Verovatno sam jos nesto citao pa pobrkao.. Nebitno :)
Nego, kad sam vec tu, nije valjda da nema neki bolji nacin, neko custom poredjenje (kao sto je ci za o i O, tako nesto za kvacice i bez) nego mora kroz regex da se naznaci da su c, č, ć... isto ?
[ mitke013 @ 09.02.2011. 01:37 ] @
Citat: strutter.poison: Ah da, video sam taj clanak.
Nekao sam shvatio da su problem nasa mala/velika slova pa zato rekoh za utf8_general_ci. Verovatno sam jos nesto citao pa pobrkao.. Nebitno
Nego, kad sam vec tu, nije valjda da nema neki bolji nacin, neko custom poredjenje (kao sto je ci za o i O, tako nesto za kvacice i bez) nego mora kroz regex da se naznaci da su c, č, ć... isto ?
Ima jedno resenje, najbolje ali i najkomplikovanije: indeksiranje kljucnih reci.
Pogledaj kako to izgleda u praksi.
Obrati paznju da je term za pretragu: 'Mičhael Jaćkson' i program je ipak nasao 'Michael Jackson'. Isto ce da radi i u suprotnom smeru; ako je title 'Mičhael Jaćkson' a ti upises 'Michael Jackson' za term, dobices iste rezultate.
Ako ces jos da se igras, ukucaj 'adagio for strings' u search polje. Ili 'kevin and perry go large', cisto da vidis kako to sve radi.
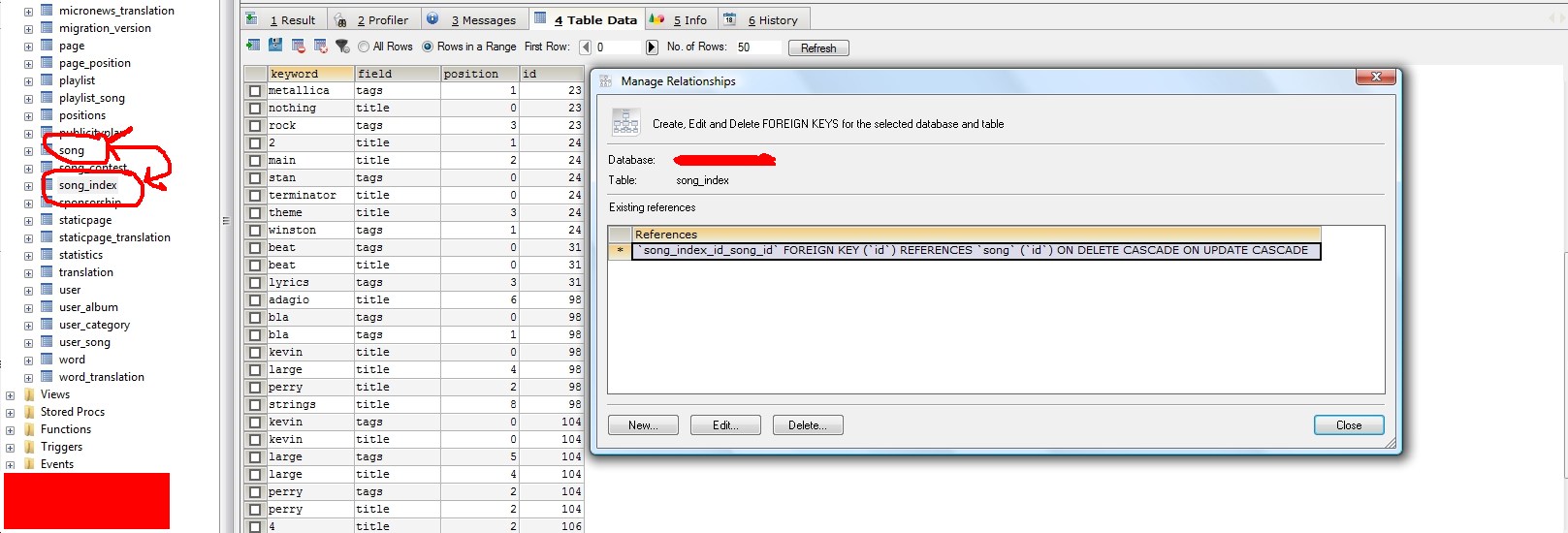
Prica iza toga je sledeca:
nema 'LIKE' komande; suvise je spora i neprakticna. Tabela song ima jos jednu pratecu tabelu 'song_index' gde se cuvaju kljucne reci za pretragu; u gornjem primeru, to su kolone 'title' i 'tags'. Tamo se upisuju 'ociscene' reci tj. 'Mičhael' postaje 'michael' i stavlja se referenca ka pesmi gde se ta rec nalazi. Pogledaj sliku, bice ti jasnije.
Program radi tako sto prvo protrci kroz 'song_index', pokupi id-eve pesama, a zatim vrati pesme po vaznosti pretrage. Tj. po zbiru reci koje se poklapaju.
E sad;
ja koristim Doctrine koji prljavi deo posla radi za mene. Da bi ti uradio ovako nesto, prouci ovaj tekst . Videces da nije neki problem izvesti isto sa obicnim sql-om, programer je pokazao koji se SQL-ovi izvrsavaju.
Pros:
1. dobijam rezultate poredjane po vaznosti (relevance). Cak i ako neka rec nije pravilno upisana, program ce uraditi pretragu po ostalim recima
2. daleko brza pretraga nego koriscenjem 'like'. Like radi tako sto prodje kroz SVE rezultate iz tabele, vrseci poredjenje bajt po bajt. Vrlo, vrlo sporo kod vecih tabela (recimo 10.000++ redova, verovatno i manje). Tek sa regexp-om se sve to uspori preko svake mere.
Cons:
ako ne koristis ORM, moraces rucno da napises ovako nesto. Zato sam ti dao link da shvatis kako to radi u pozadini, zapravo sam kod uopste nije ni toliko komplikovan. Vazna je ideja koju je autor Doctrine-a koristio.
Evo ti jos 'food for thoughts' , pogledaj 'related audios' dole desno. Prvih 6 rezultata je 'relevance search', donja 4 se drugacije racunaju (duga prica). Cela prica je veoma slicna youtube-u.
Note:
ovaj program je work-in-progress pa ako natrcis na prazan link, samo se vrati nazad i probaj neki drugi. If it is not a bug, it's a feature
 [ darkofdoom83 @ 09.02.2011. 06:21 ] @
Citat: Like radi tako sto prodje kroz SVE rezultate iz tabele, vrseci poredjenje bajt po bajt. Vrlo, vrlo sporo kod vecih tabela (recimo 10.000++ redova, verovatno i manje)
Nije istina da vrlo sporo radi kod 10.000 redova,ja imam u tabeli vise od 200.000 redova i radi brzo jos uvek.Jedan prijatelj koji se mnogo duze bavi programiranjem od mene je
rekao da se neko usporenje primeti tek kod ~2.000.000 redova. [ VladaSu @ 09.02.2011. 12:03 ] @
Ako neko trazi: šišarka, šisarka, sišarka, sisarka ti to uvek sa php prebacis u sisarka.
U bazi da imas jednu kolonu ili tabelu za pretrag gde ces staviti sve bitne reci koje ti trebaju. U ovom slucaju ubacices rec sisarka.
Pretraga ce raditi brze, bice fleksibilnije jer ces moci ubaciti i varijacije reci, npr sisarkE. sisarkOM, sisarkU, sve kolone ce biti u jednoj koloni...
Ali ti rece da ti se ne svidja zbog dupliranja sadrzaja. Sve zavisi. U nekim slucajevima moze biti dobro.
Mislim da se ovaj Mitketov primer svodi na to.
Druga nacin da ti utf8 bude u utf_8_general_ci koji ne pravi razliku izmedju č, ć i c, izmedju š i s.
Jedino đ i dj moze da ti bude problem ali sam search tekst mozes da pripremis da ti dj bude d a i ostavis original rec.
A ako ti nije utf_8_general_ci koristi nesto kao WHERE col LIKE 'šisarke ' COLLATE utf8_general_ci
Svaki collation ima svoj order i svoje slicne karaktere.
[Ovu poruku je menjao VladaSu dana 09.02.2011. u 13:15 GMT+1]
[ strutter.poison @ 09.02.2011. 16:32 ] @
Pa da, secam se da sam jednom probavao nesto sa collation. Ali nisam bio siguran za kukice, pa jos niko ne pominje utf8_general_ci, reko bolje da priznam gresku nego da se ubedjujem kad nisam siguran. :)
@mitke013
To je dobro resenje, citao sam na dosta mesta da se savetuje upravo to. Daki je pomenuo tagove sto je vrlo slicno. Jednostavno je i fleksibilno. Tako sam odradjivao pretragu onako na brzinu.
Meni sa mojim maleckim iskustvom nije jos trebalo full text search u bazi (polja gde je taj text, ne tagovi). Izveo sam to preko lucene posto je bilo na dohvat ruke u zend-u. Tu se dobija i poredjenje rezultata pretrage, pa onda na vrhu budu relevantniji. Trebalo bi i da je brze nego baza, plus kod mnogo pretrage db server nije opterecen.
Ovo je tvoj sajt? Nisam sad u prilici, ali pogledacu. Vidi li se kod negde ili samo kako funkcionise?
[ mitke013 @ 09.02.2011. 19:37 ] @
Citat: strutter.poison:
Ovo je tvoj sajt? Nisam sad u prilici, ali pogledacu. Vidi li se kod negde ili samo kako funkcionise?
To je sajt koji radim za klijenta, bice gotov za par dana. Mozes da vidis samo kako funkcionise, kod i da ti posaljem ne verujem da ce ti nesto pomoci ako ne koristis Doctrine. [ tkaranovic @ 09.02.2011. 21:37 ] @
Kada sam pravio program Pretraga tražio sam da vidim kakvih sve ima sličnih programa i sećam se da sam nalazio pograme koji su radili pretragu sajtova i izbacivali rezultate. Čini mi se i u nekom obliku koji se mogao koristiti ali se slabo sećam detalja...
Nemam nikakav link i ovo sam napisao samo po sećanju... a ne mogu da se setim ni kako sam ih pronalazio niti imam više neki kod sebe.
Copyright (C) 2001-2026 by www.elitesecurity.org. All rights reserved.
|