|
|
[ Nedeljko @ 25.10.2008. 10:06 ] @
|
| Vremenski trenutci su dati u obliku yyyy.mm.dd hh:mm:ss, pri čemu je yyyy u opsegu od 1901 do 2092. Potrebno je kodirati vremenske intervale (početak,kraj) sa samo 64 bita.
Napominjem da jedan trenutak nije moguće kodirati sa samo 32 bita.
[Ovu poruku je menjao Nedeljko dana 27.10.2008. u 09:50 GMT+1] |
[ Miorot @ 25.10.2008. 13:58 ] @

Uzmimo npr. sledeću funkciju:
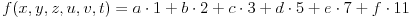
(1, 2, 3, 5, 7 i 11 su prvih šest prostih brojeva)
gde je:
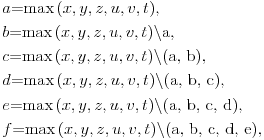
Primer: Datum 5.9.2007 11:28:49 (2007 = 1899 + 108) pamtimo kao 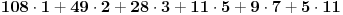 , tj. važna su nam dva sortirana niza (1, 2, 3, 5, 7, 11) koji je fiksiran i (2007, 49, 28, 11, 9, 5) koji se menja u zavisnosti od izabranog datuma.
Dakle, svaki datum funkcijom f preslikavamo u broj. Taj broj je jednoznačno određen, odnosno iz takvog jednog broja se ne može inverznom funkcijom funkcije f odrediti neki drugi datum, nego baš taj datum.
Zašto? Ima jedna teorema iz Algebre, ne sećam se koja, ali sećam se da ona tvrdi ovako nešto.
Inverzan postupak se, dakle, svodi na problem rastavljanja našeg broja na zbir 6 proizvoda 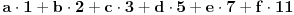 , odnosno određivanja x, y, z, u, v i t, a samim tim i potrebnog datuma.
Da vidimo koliko smo potrošili prostora za čuvanje ovakvih brojeva:
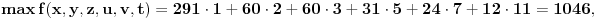
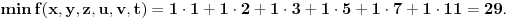
Uzimamo dakle opseg od 1 do 1018 (u postupku određivanja datuma ćemo dodati naknadno razliku 28).
Pošto čuvamo dva datuma 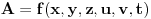 i 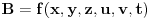 , to je onda
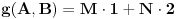 , gde su 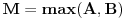 i 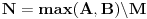 (g je nova funkcija po istom principu kao i f)
Dakle,
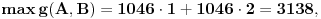
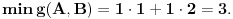
Uzimamo dakle opseg od 1 do 3136 (u postupku određivanja A i B ćemo dodati naknadno razliku 2).
Dakle, 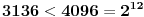 , odnosno, potrošili smo 12 bitova za čuvanje dva datuma.
Kako ćemo znati koji od (a, b, c, d, e, f) su naši (x, y, z, u, v, t)? Pošto podataka u vremenskom trenutku ima ukupno 6 (godina, mesec, dan, sat, minut, sekunda), za čuvanje informacije o sortiranom nizu podataka koristićemo za svaki podatak 3 bita, odnosno nisku od 18 bitova za jedan datum.
Za čuvanje redosleda podataka A i B dovoljno je koristiti nisku od dva bita.
To je ukupno 12+18+18+2=50 bitova. :-) (al' sam ga spalamudio...)
[Ovu poruku je menjao Miorot dana 25.10.2008. u 16:04 GMT+1][ mmix @ 25.10.2008. 14:29 ] @
A sta cemo sa ova dva datuma:
31.12.2190 23:11:07
i
31.12.2190 23:07:11
oba imaju {a, b, c, d, e, f} = {291, 31, 23, 12, 11, 7} i f()=636 i isti je oba datuma iako se oni razlikuju, dakle f() nije "1-1" funkcija niti bi mogao da je rasclanis lepo jer su zadnja dva faktora = 11*7 + 7*11 i ne znas koji potice od kog clana. U prevodu ovo ti je lossy kompresija 
Ovo je trik pitanje iz entropije, uzimajuci punu rezoluciju na nivou sekunde, opseg i prestupne godine (na to ste zaboravili), ukupan broj diskretnih jedinstvenih vrednosti za dva nezavisna datuma je:
86400 * (72*366 + 219*365) * 2 = 0x446B8ED00 (lakse je brojati bite u hex), dakle 64+3 = 67 bita. Slican metod (al u drugim opsezima) koristi Linux timestamp. U ovom sistemu nema redundantnih informacija i ne moze se "kompresovati" bez gubitka preciznosti. Osim ako neko ne zna neku magiju 
[ Miorot @ 25.10.2008. 15:07 ] @
@mmix
Pogrešio sam na kraju, sada sam ispravio, potrebno je manje bitova. :-)
Citat: mmix: A sta cemo sa ova dva datuma:
31.12.2190 23:11:07
i
31.12.2190 23:07:11
oba imaju {a, b, c, d, e, f} = {291, 31, 23, 12, 11, 7} i f()=636 i isti je oba datuma iako se oni razlikuju, dakle f() nije "1-1" funkcija niti bi mogao da je rasclanis lepo jer su zadnja dva faktora = 11*7 + 7*11 i ne znas koji potice od kog clana. U prevodu ovo ti je lossy kompresija ;)
Nije baš tako.
Za 31.12.2190 23:11:07 imamo 291*1+31*2+23*3+12*5+11*7+7*11=636 dok je niska za čuvanje redosleda oblika godina-dan-mesec-sat- minut-sekunda
Za 31.12.2190 23:07:11 imamo 291*1+31*2+23*3+12*5+11*7+7*11=636 dok je niska za čuvanje redosleda oblika godina-dan-mesec-sat- sekunda-minut
Funkcija jeste "1-1" u smislu da jednoj niski brojeva odgovara jedna vrednost, ali ove niske koje čuvaju redosled razlikuju dve funkcije sa istom vrednošću. [ Branimir Maksimovic @ 25.10.2008. 17:13 ] @
U svakom slucaju mozes sa 64 bita da ukodiras range od 200 godina
tako sto bi pamtio "od" i "razliku".
Problem je u tome sto imas tri slucaja:
kad se "od" kodira sa 31 bit a razlika sa 33 bita.
kad se "od" kodira sa 32 bita a razlika sa 32 bita.
kad se "od" kodira sa 33 bita a razlika sa 31 bit.
E sad dakle da bi zadovoljio taj uslov potrebno je samo da
formiras tri niza, jedan za prvi, jedan za drugi, i jedan za treci slucaj.
Ukoliko hoces da range-ove ucitas sa nekog strima
potrebno je samo da prvi podatak u streamu bude tip niza i duzina.
i imas kompresiju, i gotovo. Dekodiranje je jednostavno
a imas i kompresiju ;)
ustedeo si dva bita po podatku ;)
Pozdrav!
[ mmix @ 25.10.2008. 17:36 ] @
To je Citat: Miorot:Nije baš tako.
Za 31.12.2190 23:11:07 imamo 291*1+31*2+23*3+12*5+11*7+7*11=636 dok je niska za čuvanje redosleda oblika godina-dan-mesec-sat- minut-sekunda
Za 31.12.2190 23:07:11 imamo 291*1+31*2+23*3+12*5+11*7+7*11=636 dok je niska za čuvanje redosleda oblika godina-dan-mesec-sat- sekunda-minut
Funkcija jeste "1-1" u smislu da jednoj niski brojeva odgovara jedna vrednost, ali ove niske koje čuvaju redosled razlikuju dve funkcije sa istom vrednošću.
To je ok, ali to je encoding, problem je kad radis decoding, imas samo rezultat f() i imas taj redosled, medjutim kad krenes da rasclanjujes f() na {a, b, c, d, e, f} imas problem sto f-ja nije "1-1" kad je dva ili vise od tvojih maximuma prost broj 1,2,3,5,7 ili 11.
U primeru koji sam pomenuo uzmi recimo da si rasclanio a, b, c, d i znas koliko su tacno, ostaje ti da rasclanis 154, sto je 7*11 + 7*11 (sad sam namerno ovako napisao jer je ultimativno komutativnost mnozenja ono sto ubija tvoju teoriju). Ti ces znati da je e sekunda a f minut (ili obrnuto) na osnovu 3bitnog koda redosleda, ali neces znati da li je {e, f} = {7, 11} ili je {11, 7}, samim tim tvoj decoding ima dva rezultata koji podjednako odgovaraju. [ Branimir Maksimovic @ 25.10.2008. 18:10 ] @
Znace jer je taj opis ujedno i sort odrer opadajuci.
Tako da ako ima da bira izmedju 7,11 i 11,7 izabrace
po sort redosledu. Ili sam nesto propustio?
Medjutim dekoding ovoga mnogo traje pa se ne isplati
to raditi po mom misljenju.
Pozdrav!
[ mmix @ 25.10.2008. 18:54 ] @
Primer nije dobar, poradicu na tome. Moram da stavim sve na papir, nek ostane to za sada.
Medjutim i ako uzmemo da je to ispravno, ovaj deo je problematican: g(A, B) = M + 2N za kompresiju dva datuma u 12 bita. Time efektivno dobijas linearnu jednacinu sa dve nepoznate (x + 2y = c) koja nije resiva jer je nepotpun sistem. Tako da moras da zadrzis tih 12 (zapravo 10) bitova po datumu plus oba poziciona niza.
Pride pozicioni niz od 6 elemenata moze da bude kraci od 18 bita. Tu imas 6! permutacija skupa {yy, mm, dd, h, m, s} ako sve permutacije indeksiras u istom pretku mozes da zapises svaku permutaciju brojem od 0 do 719 sto staje u 10 bita.
Tako da je zapravo 2 x (10 + 10) = 40 bita, ali pod uslovom da f()+pos transformacija radi, sto mi deluje veoma neverovatno zbog entropije (skup svih mogucih vrednosti datetime nije redundantan), tako da negde mora da popusti. Misli da problem definitivno lezi u f-1(int) => {a, b, c, d, e, f} samo da nadjem odgovarajuci kontra primer (ili problem lezi u tome da ne vidim redundantnost).
[Ovu poruku je menjao mmix dana 25.10.2008. u 20:05 GMT+1]
[ Nedeljko @ 25.10.2008. 19:10 ] @
Citat: Branimir Maksimovic: Problem je u tome sto imas tri slucaja:
kad se "od" kodira sa 31 bit a razlika sa 33 bita.
kad se "od" kodira sa 32 bita a razlika sa 32 bita.
kad se "od" kodira sa 33 bita a razlika sa 31 bit.
Kada vršiš dekodiranje, ti imaš samo niz od 64 bita i nikakve dodatne informacije tipa "za ovo je korišćen 31 bit, a za ono 33 bita".
Citat: Branimir Maksimovic: Znace jer je taj opis ujedno i sort odrer opadajuci.
Tako da ako ima da bira izmedju 7,11 i 11,7 izabrace
po sort redosledu.
Onda ne može da kodira 7,11, već samo 11,7. Šta ako je kodirao 7,11, a po sort redosledu dekodira 11,7? Neće dobiti isto što je kodirao. mmix je u pravu.
U opsegu od 192 godine sekundi ima 60*60*24*365.25*192 = 6,059,059,200 > 4,294,267,296 = 2 32, pa je za kodiranje jednog trenutka potrebno 33 bita. Parova trenutaka ima 36,712,198,389,104,640,000 < 36,893,488,147,419,103,232 = 2 65, pa je za kodiranje dva trenutka potrebno 65 bitova. Međutim, nas ne zanimaju svi parovi, jer odbacujemo one kod kojih je početak posle kraja, a takvih je oko pola, pa je broj mogućih parova prepolovljen, odakle sledi da se može uštedeti jedan bit. To je bila caka!
Prebrojmo koliko ima parova (a,b) brojeva iz skupa {0,1,...,n-1} kod kojih je a<=b. Parova oblika (*,b) ima b+1 (to su parovi (0,b),...,(b,b)), pa pošto b može biti bilo koji od brojeva 0,...,n-1, sledi da je ukupan broj parova 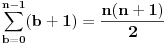 . Kod nas je n=6,059,059,200, pa je ukupan broj intervala 18,356,099,197,581,849,600 < 18,446,744,073,709,551,616 = 2 64, pa se sve može (jedva) zgurati u 64 bita i ne može sa manje od 64. Na sličan način se izračunava da je za opseg od 193 godine nedovoljno 64 bita. [ Nedeljko @ 25.10.2008. 19:18 ] @
Miorot,
prvo, ne znam šta znači ovo:
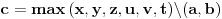
Drugo, kako misliš iz vrednosti
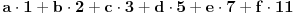
da izračunaš 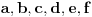 ? [ mmix @ 25.10.2008. 19:45 ] @
Ok, zapravo je bilo jednostavnije nego sto sam mislio, potrebno je samo naci dva sorted {a, b, c, d, e, f} niza koji daju isti f() a za isti niz redosleda daju dva razlicita i smislena datuma.
Neka je niz redosleda za oba {yy, mm, dd, h, m, s}
1900-01-01 07:07:07 => {1, 1, 1, 7, 7, 7}, f=167
1900-01-01 01:05:11 => {1, 1, 1, 1, 5, 11}, f=167
tako da ti f+pos nije jednozacan. I sad kad nedeljko okaci zadnji post, u stvari se vidi i da je f-1 neresiv jer pokusavas da resis jednu jednacinu sa 6 nepoznatih bez sistema, kao posledica toga je i gornji primer.
BTW, nedeljko, imas onda problem u postavci zadatka posto nisi resio svoj zadatak . Opseg koji si dao u prvom postu nije 192 godine vec 291 godinu Pretpostavljam da je typo.
PS: Evo i dva descending sort niza sa istim f koji daju smislene datume:
f = 35
3 3 1 1 1 1
2 2 2 1 1 1
[ Branimir Maksimovic @ 25.10.2008. 19:47 ] @
Citat:
Kada vršiš dekodiranje, ti imaš samo niz od 64 bita i nikakve dodatne informacije tipa "za ovo je korišćen 31 bit, a za ono 33 bita".
Pa vidi dal ces imati tri niza od po 64 bita clanova ili samo jedan ali sa po 66 bita clanova
upravo zavisi dal ces tu informaciju morati da ukodiras zajedno sa podatkom ili ne?
Ako to ukodiras sa podatkom onda ti za to treba vise od 64 bita,
a ako formiras tri niza koja ti nista vise u memoriji nece uzimati nego jedan
postigao si kompresiju a prakticno dobio isto.
Drugo kad nekom saljes stream onda mora da ima header svakako.
A u serijalizaciji su ti potrebna minimum dva podatka: tip i duzina,
(ukoliko druga strana ne zna redosled unapred i kad se radi o nizovima) tako da i tu nista ne gubis.
Ako hocemo da pricamo o realnom problemu i realnom resenju.
Citat:
Onda ne može da kodira 7,11, već samo 11,7. Šta ako je kodirao 7,11, a po sort redosledu dekodira 11,7? Neće dobiti isto što je kodirao. mmix je u pravu.
Pa lepo je objasnio opisna polja koja se kodiraju sa po 3 bita ujedno i predstavljaju opadajuci redosled.
Dakle ako je e,f onda je e vece od f i treba da bude 11,7 ako je f,e onda f treba da bude vece od e
i onda je opet 11,7
Dakle slucaj 7,11 se potpuno odbacuje posto je uslov dekodiranja da redosled opisa ujedno bude i opadajuci
sort order. Koliko sam shvatio.
Pozdrav!
[ mmix @ 25.10.2008. 19:53 ] @
Citat: Branimir Maksimovic: Dakle slucaj 7,11 se potpuno odbacuje posto je uslov dekodiranja da redosled opisa ujedno bude i opadajuci
sort order. Koliko sam shvatio.
OK, eve ga:
f = 35
3 3 1 1 1 1 2003-03-01 01:01:01
2 2 2 1 1 1 2002-02-01 01:01:01
koristeci isti pozicioni niz. [ Nedeljko @ 25.10.2008. 20:08 ] @
Branimire,
To što pričaš sa hederom znači da negde pakuješ dodatne informacije, a to nije to. Potrošio si 66 bita. Ako ne veruješ, reci mi koliko ti prostora treba za serijalizaciju 8,000,000 takvih intervala. 64MB ili 66MB? Trebaju ti dve funkcije: encode koja prihvata trenuke, proverava validnost i vraća int64 i funkciju decode, koja prihvata int64 i vraća početak i kraj. Pritom, bilo koji validan interval kada se kodira, pa dekodira, treba da se dobije ono što je kodirano.
Citat: mmix: BTW, nedeljko, imas onda problem u postavci zadatka posto nisi resio svoj zadatak ;). Opseg koji si dao u prvom postu nije 192 godine vec 291 godinu ;) Pretpostavljam da je typo.
Da, sad vidim da sam lupio. Mislio sam na 100 godina manje. Hvala. No, ipak sam dokazao da ne postoji rešenje za opseg od >=193 godine. [ Nedeljko @ 25.10.2008. 20:13 ] @
Ja ne znam o kom vi sortiranju pričate. Delovi datuma ne moraju biti sortirani. Trenutak 2007-12-31 17:45 33 je validan i mora ga biti moguće kodirati i pri dekodiranju dobiti baš njega. O kakvom odbacivanju pričate?
[ Nedeljko @ 25.10.2008. 20:31 ] @
Imam, u pogledu stepena kompresije, skoro optimalan algoritam za kompresiju nekih netrivijalnih skupova podataka, kao što su šahovske partije i šahovske pozicije, pa čak i metod za procenu ukupnog broja šahovskih pozicija (mada me mrzi da kodiram), pa sam čak mislio i da vas navedem na njega postupno, primerima, ali ne mogu toliko da visim po ES-u, morao bih dosta da piskaram. U dilemi sam, koliko to druge zanima i koliko se isplati trošiti vreme na takve gluposti.
[ mmix @ 25.10.2008. 20:33 ] @
Pretpostavka njegovog resenja je da je {a, b, c, d, e, f} sortiran nanize (to je bila svrha onih Max izraza za koje si pitao), nije bas matematicki pravilno definisao al sam skontao sta je hteo da kaze. Na stranu to nije ispravno.
[ Branimir Maksimovic @ 25.10.2008. 20:35 ] @
Citat:
To što pričaš sa hederom znači da negde pakuješ dodatne informacije, a to nije to. Potrošio si 66 bita. Ako ne veruješ, reci mi koliko ti prostora treba za serijalizaciju 8,000,000 takvih intervala. 64MB ili 66MB?
Nedeljko jesi li ti glup ili se samo pravis? Oprosti ali ovo je debilno ocigledno.
Na bilo koju velicinu podatka overhead je ako recimo cuvas tip i duzinu u 32 bitnim intovima
64x3 == 192 bit-a fiksno.
Znaci na tvojih 8miliona ili 8ziliona overhead ti je uvek 192 bit-a na strimu .
U memoriji imas overhead u zavinosti od toga koliko je heavi niz.
U C++-u ti je overhead 2 pointera vise sto je 64 ili 128 bita u zavisnosti od
toga gde si kompajlirao.
Miljane:
Citat:
f = 35
3 3 1 1 1 1 2003-03-01 01:01:01
2 2 2 1 1 1 2002-02-01 01:01:01
3*3+3*5+1*7 == 9+15+7 == 31
2*3+2*5+2*7 == 6+10+14 == 30
Ili sam ja totalno otisao u aut ;(
Pozdrav!
[ mmix @ 25.10.2008. 20:49 ] @
Citat: Branimir Maksimovic: 3*3+3*5+1*7 == 9+15+7 == 31
2*3+2*5+2*7 == 6+10+14 == 30
Ili sam ja totalno otisao u aut ;(
Po njegovoj postavci f(niz) = 1*a + 2*b + 3*c + 5*d + 7*e + 11*f, ne znam po kojoj formuli si dobio ovo gore.
1*3+2*3+3*1+5*1+7*1+11*1 = 1*2+2*2+3*2+5*1+7*1+11*1 = 35
[ Nedeljko @ 25.10.2008. 20:53 ] @
U nizu od 8 miliona intervala nisu svi istog tipa, pa ti treba za svaki od njih treba još dva bita da bi znao kom od 3 tipa pripada (31+33 ili 32+32 ili 33+31). Ja te očigledno nisam dobro razumeo jer nemam pojma o kojih 64x3=192 bitova pričaš. U svakom slučaju, nešto ti ne valja ako tim postupkom opseg od 193 godine možeš da obuhvatiš sa 64 bita, jer to je nemoguće.
Ako bilo koji od 3 tipa kodiraš sa 64 bita, onda ti pri dekodiranju treba još i informacija o tipu, što je još 2 bita.
Možeš li ti da napraviš ovakve funkcije:
Citat: Nedeljko: encode koja prihvata trenuke, proverava validnost i vraća int64 i funkciju decode, koja prihvata int64 i vraća početak i kraj. Pritom, bilo koji validan interval kada se kodira, pa dekodira, treba da se dobije ono što je kodirano.
Odgovor je da ili ne. [ Nedeljko @ 25.10.2008. 20:58 ] @
OK, ako ste vi razumeli one formule, šta znači
c = max(x,y,z,u,v,t) \ (a,b) ?
Ja ove oznake ne razumem.
[ Nedeljko @ 25.10.2008. 21:02 ] @
Pošto ja Miorot-ove formule ne razumem, jel bi mogao neko da ih iskodira, pa da vidimno kako radi.
[ mmix @ 25.10.2008. 21:08 ] @
Ovo pretpostavljam razumes:
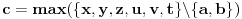 a posto svaka sledeca iteracija uzimam preostali maksimum, onda je niz {a, b, c, d, e, f} implicitno sortiran ka dole.
Al nije ni vazno, jer mu svejedno resenje nije dobro.
A inace i ne moze da se iskodira dekoder jer f-1() nije resivo sto si i sam primetio, a nije ni jednoznacno sto sam ja zametio [ Branimir Maksimovic @ 25.10.2008. 21:09 ] @
Miljane, kapiram. Mislio sam da si uzeo njegove koeficijente od 3,5,7,....
Dakle ipak bez obzira na sort mogu se pogoditi dva datuma sa istom vrednoscu.
Nedeljko, imaces tri encode i decode f-je.
Koju ces izabrati zavisi od toga koji niz dekodiras.
A koji niz dekodiras znaces u programu ocigledno, a sa strima iz toga sto ce prvi podatak biti
tip pa duzina. Sa ovom metodom mozes obuhvatiti opseg od nesto vise od 200 godina cini mi se.
E sad ako ne kapiras da treba da sve datujme grupises u tri niza sta ti ja mogu ;)
Pozdrav!
[ mmix @ 25.10.2008. 21:16 ] @
Citat: Branimir Maksimovic: Miljane, kapiram. Mislio sam da si uzeo njegove koeficijente od 3,5,7,....
Dakle ipak bez obzira na sort mogu se pogoditi dva datuma sa istom vrednoscu.
Pa i uzeo sam njegove koeficijente, on i koristi koeficijente 1,2,3,5,7,11, samo sto sam za moguce vrednosti a-f uzeo upravo te koeficijente, kako bih sto brze kroz iteracije dosao do kolizije f-1 funkcije (brojevi koje sam napisao su vrednosti a do f), a pride te vrednosti mogu da dodju na bilo koje mesto u datumu sto je ucinilo niz poredka besmislenim. Iteratoru nije trebalo dugo da dodje do kolizije. [ Nedeljko @ 25.10.2008. 21:26 ] @
Ne, ja hoću jednu encode i jednu decode funkciju. Može li ili ne? Da ili ne? To je formulacija problema "kodirati sa 64 bita".
Problem je u tome što ja znam kako nešto da dekodiraš koristeći dva bita koja si primio pre toga. Izvini, ali ta dva bita moraju da se uračunaju, jer nose informaciju, budući da ja bez njih ne mogu da dekodiram interval, to jest da znam koju decode funkciju da primenim.
Tako kako si zamislio ja mogu da kodiram slovo engleske abecede sa samo jednim bitom. Podelim velika i mala slova u 26 tipova: tip A za slova "a" i "A", tip B za slova "b" i "B",..., tip Z za slova "z" i "Z", a onda serijalizujem heder sa tipom i još jedan bit sa informacijom da li je slovo veliko ili malo. Na osnovu tipa, pozovem odgovarajuću decode funkciju
Code:
char decode_A(bool b)
{
if (b) return 'a';
else return 'A';
}
...
char decode_Z(bool b)
{
if (b) return 'z';
else return 'Z';
}
Tako možeš i traženi interval da "kodiraš" sa jednim bitom pomoću 2 63 decode funkcija, ali to nije kodiranje jednim bitom. [ Nedeljko @ 25.10.2008. 21:34 ] @
Citat: mmix: Ovo pretpostavljam razumes:
a posto svaka sledeca iteracija uzimam preostali maksimum, onda je niz {a, b, c, d, e, f} implicitno sortiran ka dole.
Taj fazon. E, pa, onda trenutci 2007-12-9 10:11 13 i 2012-9-7 13:11 10 imaju iste a,b,c,d,,f, pa samim tim i isti f. Znači, on prvo pomeša minute, godine, mesece i "zaboravi" šta je zapravo bilo šta, pa onda sa tim radi dalje. [ Branimir Maksimovic @ 25.10.2008. 21:38 ] @
E kad si toliko uporan da isteras svoj argument;)
Ovaj primer ti sa slovima ne ide zato sto onda mozes samo da kodiras
slova 'a' odvojeno od slova 'b' itd. sto bas i nema nekog smisla zar ne?;)
Ovde se radi o prostoj kompresiji koja se jednostavno i vrlo lako implementira ;)
A ti sad smisljaj argument za pricu to mora da bude decode single datuma-range-a
u single 64 bit podatku. E ta prica nema smisla u realnosti.
Pozdrav!
[ Nedeljko @ 25.10.2008. 21:46 ] @
Citat: Branimir Maksimovic: A ti sad smisljaj argument za pricu to mora da bude decode single datuma-range-a
u single 64 bit podatku. E ta prica nema smisla u realnosti.
Ma, ne mora uopšte, ali zna se šta znači kodirati sa 64 bita. Znači, na 8 miliona podataka mi treba hederčina sa 2x8,000,000 bitova sa tipovima iza koga dolazi onih 64,000,000 bajtova, a onu hederčinu od 2,000,000 bajtova sa tipovima ćemo da zaboravimo. Pazi, tvrdio si da imaš preko 64xN bita konstantan overhead od 192 bita, i napravi me budalom zbog toga, a ono ispade 2,000,000 bajtova. I dalje ne razumem kako si došao do cifre od 192 bita, ali nema veze. [ mmix @ 25.10.2008. 21:52 ] @
Citat: Nedeljko: Taj fazon. E, pa, onda trenutci 2007-12-9 10:11 13 i 2012-9-7 13:11 10 imaju iste a,b,c,d,,f, pa samim tim i isti f. Znači, on prvo pomeša minute, godine, mesece i "zaboravi" šta je zapravo bilo šta, pa onda sa tim radi dalje.
Upravo tako, i onda je to "ispravio" tako sto je uveo pozicioni niz da bi se prisetio sta su a,b,c,d,e i f, medjutim to sve ne moze da sljaka jer f sam po sebi nije upotrebljiv jer postoje i kombinacije dva i vise sortiranih nizova a-f koji daju isti f() a za isti pozicioni nize daju razlicite trenutke. [ Nedeljko @ 25.10.2008. 21:53 ] @
Nego, može li neko da napiše algoritam kodiranja/dekodiranja na osnovu onog mog posta? Ja sam prebrojavanjem samo dokazao da je moguće sa 64 bita. Rešenje nije kompletirano.
[ Branimir Maksimovic @ 25.10.2008. 21:54 ] @
Nedeljko, odustajem.
Pozdrav!
[ Nedeljko @ 25.10.2008. 21:59 ] @
Branimire, izvini ako te nerviram. Tako je ispalo i na onoj temi sa referencama, gde si mi stvarno pomogao sa pravim objašnjenjem (na čemu sam ti zahvalan), koje sa dobio posle većeg broja postova. Šta da radim, tako ispada.
[ Miorot @ 25.10.2008. 22:07 ] @
Izvinjavam se što se ovako kasno javljam.
Nisam najsrećnije napisao ono što je bunilo Nedeljka, ali mmix je lepo razjasnio.
Citat: Nedeljko: Taj fazon. E, pa, onda trenutci 2007-12-9 10:11 13 i 2012-9-7 13:11 10 imaju iste a,b,c,d,,f, pa samim tim i isti f. Znači, on prvo pomeša minute, godine, mesece i "zaboravi" šta je zapravo bilo šta, pa onda sa tim radi dalje.
Pa pomešam ih, ali zato imam nisku koja čuva šta je šta.
mmix, lepo si primetio i našao kontraprimer
Citat:
f = 35
3 3 1 1 1 1 2003-03-01 01:01:01
2 2 2 1 1 1 2002-02-01 01:01:01
koristeci isti pozicioni niz.
Moraću da vidim u čemu je greška, verovatno u tome što koristim brojeve 1, 2, 3, 5, 7, i 11. Verovatno treba da se koristi niz prostih brojeva koji su veći od maksimalnih vrednosti koje mogu da imaju godine (291), dani (31), meseci (12), sati (24) i minuti/sekunde (60). Recimo, 293 za godine, 37 za dane, 13 za mesece, 29 za sate, 61 i 67 za minute i sekunde. Moraću to da izračunam kasnije, sada ne mogu da stignem. Ne znam da li ću u tom slučaju da ostanem u okviru 64 bita...
E sad, Nedeljko se pita kako izgleda dekodiranje... pitam se i ja :-) Baš sam ga zakomplikovao. Brute force svakako može, ali to nije elegantno...
Razmisliću... [ Nedeljko @ 25.10.2008. 22:13 ] @
Imaš 192 godine. Sa 193 godine ti već treba 65 bitova.
Mislio sam na funkcije za kodiranje/dekodiranje na osnovu mojih ideja, jer ih nisam dao, ali nema veze, daj da vidimo bilo koje korektno rešenje. Za početak može i brute force, ali definitivno u 64 bita.
[ Miorot @ 25.10.2008. 22:19 ] @
Zar nisi rekao 1900 do 2190?
2190-1900=290 godina? [ Branimir Maksimovic @ 25.10.2008. 22:41 ] @
Miriot vec napocetku je receno. I sad ja pocinjem da mislim.
Ne mozes skup od 6milijardi elemenata jednoznacno preslikati f-jom u skup
sa manje elemenata od toga, dakle uvek mora da ima preklapanja.
Ako se ne uradi kompresija kakvu sam predlozio, onda sa 64 bita u jednoj
varijabli mozes maksimalno da spakujes range od oko 136 godina.
Bas bih voleo da vidim Nedeljkovo resenje za 192 godine.
Pozdrav!
[ mmix @ 25.10.2008. 22:56 ] @
Citat: Miorot: Moraću da vidim u čemu je greška, verovatno u tome što koristim brojeve 1, 2, 3, 5, 7, i 11. Verovatno treba da se koristi niz prostih brojeva koji su veći od maksimalnih vrednosti koje mogu da imaju godine (291), dani (31), meseci (12), sati (24) i minuti/sekunde (60). Recimo, 293 za godine, 37 za dane, 13 za mesece, 29 za sate, 61 i 67 za minute i sekunde. Moraću to da izračunam kasnije, sada ne mogu da stignem. Ne znam da li ću u tom slučaju da ostanem u okviru 64 bita...
Problem je sto je entropija informacija neumoljiva, ni u kom slucaju cak i da napravis resiv f-1 nece moci da zauzmes manje bitova za datum nego sto je pun opseg vrednosti. A glavni problem koji imas sa ovim resenjem jeste resivost f-1().
Pazi ovako, ako uzmes samo dve nepoznate i jednu jednacinu, njeno resenje je prava, znaci (iz nekog razloga tex nece da mi renderuje ni \fracni \over kako treba, jel to do mene ili ?):
ax + by = c
x = -(b/a)x + c/a
Cak iako svedes resenje samo na diskretne vrednosti i dalje ih imas beskonacno mnogo (ili nemas nijedno).
Za tri nepoznate resenje ti je ravan, a za 6 nepoznatih resenje je neka 5D hyper-ravan. Nije resivo jednostavno zato sto se domeni promenljivih preklapaju. Jedno od resenja je da razdvojis domene i da resenja uzimas preko MOD (ostatak pri deljenju), ali tek ces onda da se natrosis bitova na razliku izmedju velicine svakog domena i najblizeg stepena 2-ke (npr 60 sekundi ima 60 diskretnih vrednosti od 0 do 59 ali bi njegov domen bio 6 bitova, gde gubis 4 diskretne vrednosti od 60-63). Najoptimalnije resenje za jedan datum bez gubitka je jednostavno broj sekundi protekao od (1.1.1900 00:00:00), i metod slican tom se koristi skoro svuda u datetime tipovima.
Citat: Nedeljko: Nego, može li neko da napiše algoritam kodiranja/dekodiranja na osnovu onog mog posta? Ja sam prebrojavanjem samo dokazao da je moguće sa 64 bita. Rešenje nije kompletirano.
Okusacu se sutra, sad je vec kasno
[ Odin D. @ 26.10.2008. 00:12 ] @
Sa 64 bita moze da se predstavi 2^64 razlicitih kombinacija. Ako broj mogucih slucajeva koji hocemo da kodiramo prelazi 2^64, nema nacina da se to uradi u 64 bita.
Mozete vi vrtiti te bitove kako hocete, praviti jednacine i postavljati kakve god hocete sisteme, ali nikad nemozete u tih 64 bita dobiti neku novu kombinaciju koja nije jedna od onih prvobitnih 2^64.
Prema tome, dzaba se mucite i gubite vreme. Kad bi to bilo moguce sa 64 bita onda bi bilo moguce i sa dva. Sa dva bita se mogu predstaviti 4 razlicita slucaja. Ako bi vi nekim funkcijama i preslikavanjima mogli nekako dobiti 5 slucajeva, onda bi mogli nastaviti dalje lancano, pa pomocu tih 5 napraviti novih 8 npr. i tako unedogled f1(f2(f3(...fn(xy)))), gdje xy predstavljaju dva bita.
Tom logikom bi onda sve moglo da se predstavi samo sa dva bita ako imas dovoljno nekakvih funkcija, cak stavise moglo bi i sa jednim bitom, od koga bi se dobila dva, a od njih 3 itd...
Valjda uvidjate apsurdnost toga.
Granicni slucaj je 192 godine i vise od toga ne moze.
[ Srđan Pavlović @ 26.10.2008. 09:09 ] @
64-bit Unsigned: 0 to +18,446,744,073,709,551,615
sa ovoliko sekundi na raspolaganju se moze opisati oko 585 milijardi godina, sto i nije tako lose za jedan kalendar ...
heh, znam da to nije problematika, ali cisto onako, zanimljiv podatak.... :)
[ negyxo @ 26.10.2008. 10:29 ] @
Evo ga:
C# code
Code:
public partial class Form1 : Form
{
const ulong maxDateValue = 6071500800;
ulong yearOffset = 0;
ulong dayOffset = 0;
ulong hourOffset = 0;
ulong minuteOffset = 0;
public Form1() {
InitializeComponent();
this.dateTimePicker1.Value = new DateTime(1900, 10, 1, 1, 1, 1);
this.dateTimePicker2.Value = new DateTime(1900, 10, 2, 1, 1, 1);
yearOffset = 366 * 24 * 60 * 60;
dayOffset = 24 * 60 * 60;
hourOffset = 60 * 60;
minuteOffset = 60;
}
private ulong PairDates(DateTime d1, DateTime d2) {
ulong x = ConvertDate(d1);
ulong y = ConvertDate(d2);
ulong n = maxDateValue;
ulong m = n - x + 2;
ulong pos = 0;
if (m > n) {
pos = (ulong)(maxDateValue - y + 1);
}
else {
pos = (ulong)((n - m + 1) * (n + m)) / 2 + (maxDateValue - y + 1);
}
return pos;
}
private ulong ConvertDate(DateTime d) {
return (ulong)(d.Year - 1900) * yearOffset + (ulong)d.DayOfYear * dayOffset + (ulong)d.Hour * hourOffset + (ulong)d.Minute * minuteOffset + (ulong)d.Second;
}
private void UnpairDates(ulong pairDate, out DateTime d1, out DateTime d2)
{
bool search = true;
ulong sum = 0;
ulong total = 0;
ulong stepen = 1;
while (search) {
stepen = stepen << 1;
total += stepen;
sum = Sum(maxDateValue, maxDateValue - total + 1);
if (sum >= pairDate)
{
total -= stepen;
stepen = 1;
total += stepen;
sum = Sum(maxDateValue, maxDateValue - total + 1);
if (sum >= pairDate) {
break;
}
}
}
ulong ud1 = total;
sum = Sum(maxDateValue, maxDateValue - total + 2);
ulong ud2 = maxDateValue - (pairDate - sum) + 1;
d1 = GetDate(ud1);
d2 = GetDate(ud2);
}
private DateTime GetDate(ulong pos) {
ulong year = pos / yearOffset;
ulong day = (pos - year * yearOffset) / dayOffset;
ulong hour = (pos - year * yearOffset - day * dayOffset) / hourOffset;
ulong minute = (pos - year * yearOffset - day * dayOffset - hour * hourOffset) / minuteOffset;
ulong second = pos - year * yearOffset - day * dayOffset - hour * hourOffset - minute * minuteOffset;
DateTime d = new DateTime(1900 + (int)year, 1, 1);
DateTime d2 = d.AddDays(day - 1);
return new DateTime(d2.Year, d2.Month, d2.Day, (int)hour, (int)minute, (int)second);
}
private ulong Sum(ulong n, ulong m)
{
return ((n - m + 1) * (n + m)) / 2;
}
private void button1_Click(object sender, EventArgs e) {
ulong res = PairDates(dateTimePicker1.Value, dateTimePicker2.Value);
DateTime d1;
DateTime d2;
UnpairDates(res, out d1, out d2);
dateTimePicker3.Value = d1;
dateTimePicker4.Value = d2;
textBox1.Text = res.ToString();
}
}
Kasnije cu ulepsati malo, nemojte obracati toliko paznju na imena, refaktor kasnije, i ovako nisam pola noci spavao;
Evo i solution za VS 2005.
E sad ako ovo radi posle ide objasnjenje. Mada mozda sam negde promasio za 1 bit. :)
[ mmix @ 26.10.2008. 10:57 ] @
Na stranu refaktor, mislim da ti ovo ne radi u opstem slucaju, posto se u encodingu nadas da mudjurezulat nece preci 64 bita ;)
A i decoding ti je mnogo spor, evo vec deset minuta crunchuje dva datuma u 2091 godini i ne izgleda blizu odgovora.
Imam i ja konja za trku, samo da zavrsim testiranja :) Za sada sam na oko 6 sekundi
[ mmix @ 26.10.2008. 12:01 ] @
Ok, gotovo, isto C#, evo encode.decode, ceo sors sa pomocnim f-jama je zakacen. Imao sam malih problema sa tacnoscu TimeSpan vrednosti kad broj sekundi prelazi 32bita, ali je to sad reseno.
Code:
static ulong Encode2DT(DateTime start, DateTime stop)
{
unchecked
{
ulong max = getMaximumSpan();
// skloni detalje implementacije jezika, vazno je da dobijemo broj sekundi od 1.1.1900/0:0:0
ulong startSpan = getSeconds(start);
ulong stopSpan = getSeconds(stop);
// validacija opsega
System.Diagnostics.Debug.Assert(startSpan < max);
System.Diagnostics.Debug.Assert(stopSpan < max);
// osiguraj da je stop>=start
sortSpans(ref startSpan, ref stopSpan);
ulong totalSpan = stopSpan - startSpan;
// ok, encoding
ulong blob = 0;
for (ulong cnt = 1; cnt <= startSpan; cnt++) blob += (max - cnt + 1);
blob += totalSpan;
return blob;
}
}
static void Decode2DT(ulong blob, out DateTime start, out DateTime stop)
{
unchecked
{
ulong max = getMaximumSpan();
// validacija opsega
System.Diagnostics.Debug.Assert(blob < getMaximumBlob());
// decoding
ulong startSpan = 0;
for (ulong cnt = 1; cnt <= max; cnt++)
if (blob >= (max - cnt + 1)) blob -= (max - cnt + 1);
else { startSpan = cnt - 1; break; }
start = getDateFromSeconds(startSpan);
stop = getDateFromSeconds(startSpan + blob);
}
}
Enc D1: 1900-01-01 00:00:00
Enc D2: 2091-12-31 23:59:59
Enc Encoding...
Enc Encoded: 16924967f
Enc Vreme encodinga: 00:00:00.0020000
Dec Decoding...
Dec Vreme decodinga: 00:00:00.0010000
Dec D1: 1900-01-01 00:00:00
Dec D2: 2091-12-31 23:59:59
Enc D1: 1900-01-01 00:00:01
Enc D2: 2091-12-31 23:59:59
Enc Encoding...
Enc Encoded: 2d2492cfe
Enc Vreme encodinga: 00:00:00.0040000
Dec Decoding...
Dec Vreme decodinga: 00:00:00
Dec D1: 1900-01-01 00:00:01
Dec D2: 2091-12-31 23:59:59
Enc D1: 2091-12-31 23:59:59
Enc D2: 2091-12-31 23:59:59
Enc Encoding...
Enc Encoded: febc1ad88acf6b3f
Enc Vreme encodinga: 00:00:13.4580000
Dec Decoding...
Dec Vreme decodinga: 00:00:22.2450000
Dec D1: 2091-12-31 23:59:59
Dec D2: 2091-12-31 23:59:59
Vreme progresivno raste sto je nizi datum blizi gornjoj granici jer ima vise iteracija.
Algoritam tretira parove kao elemente gornje trougaone matrice gde je jedna 0-based koordinata pocetni trenutak, a druga koordinata broj sekundi od tad do kraja (timespan) i gde vrednosti u matrici kontinualno rastu od 0 do (n2+n)/2-1. Iako encoding moze da se optimizuje matematicki:
p1=kn- ∑_(x=0)^(k-1) x
p1=kn-((k-1)^2+k-1)/2
p1= -(k^2)/2+kn+k/2
gde je k prvi trenutak a n maximalni span
medjurezultati ovoga ne bi stali u 64 bita (ako je k 33 bita k^2 moze biti 65 bita u nasoj postavci), i ovo bismo moglid a koristimo samo uz 128bit math ekstenzije.
Dekoding sa druge strane ne vidim kako optimizovati? Matematicari?
PS: Optimizovani release build je uradio pun span encoding/decoding za 4.7s/8.3s. (Core2 8400 x64 3Ghz)
[Ovu poruku je menjao mmix dana 26.10.2008. u 13:14 GMT+1][ mmix @ 26.10.2008. 12:15 ] @
SAd sam se setio jos nesto, moze se na osnovu prednosti prvog datuma videti da li je blizi pocetku ili kraju matrice pa mogu da se naprave dva iteratora, jedan koji vozi unapred od pocetka i drugi koji vozi unazad od kraja, to bi trebalo da presece vreme na pola. Probacu kasnije, idem sad malo da oladim mozak :)
[ Nedeljko @ 26.10.2008. 13:47 ] @
@mmix
Da, to sa trougaonom matricom je rešenje. Čim otvorim firmu imaš posao kod mene. Šalim se. Ima jedan mali problem. Odakle mi firma. Ostalo je OK.
Ne znam šta vas je to toliko namučilo oko dekodiranja, ali evo C++ rešenja, pa merite vremena. Nisam ga optimizovao do kraja. Hteo sam da koristim što manji fragment jezika, a da se ipak vide sve formule koje su potrebne u postupku. Pikirao sam na jednostavnost za posetioce koji ne znaju C++. Takođe, sav račun je u 64 bita, tj. svi međurezultati su u opsegu od 0 do 2 64-1.
Code:
#include <iostream>
using namespace std;
// Compiler depended code. This is definition of unsigned 64-bit integer.
// This code can be compiled using GNU C++ compiler and MinGW C++ compiler.
typedef unsigned long long int UInt64;
// March is the first month in the modified calendar (number 0).
// January and February belong to the previous year.
// March = 0, April = 1, May = 2, June = 3, July = 4, August = 5,
// September = 6, October = 7, November = 8, December = 9, January = 10, February = 11
int days_in_month[12] = {31, 30, 31, 30, 31, 31, 30, 31, 30, 31, 31, 28};
// Converts datetime to 64-bit unsigned integer.
UInt64 to_num(int year, int month, int day, int hour, int minute, int second) {
UInt64 result = 0;
// Conversion from standard calendar to the modified calendar.
if (month < 3) {
month += 9;
year = year - 1;
} else
month -= 3;
// Number of days in 400 years is 365.2425*400 = 146097.
result = result + (year/400) * 146097;
year = year % 400;
// Number of days in 100 years (of the rest <400 years) is 365.25*100 = 36525.
result = result + (year/100) * 36525;
year = year % 100;
// Number of days in 4 years (of the rest <100 years) is 365.25*4 = 1461.
result = result + (year/4) * 1461;
year = year % 4;
// Number of days in one year (of the rest <4 years) is 365.
result = result + year * 365;
// Add the number of days in previous months.
for (int m = 0; m < month; m = m + 1) {
result += days_in_month[m];
}
// Add the number of previous days in month.
result = result + day - 1;
// Switch to seconds
result = result * (24*60*60);
// Add the number of previous seconds in the day.
result = result + (60*60)*hour + 60*minute + second;
return result;
}
void to_datetime(UInt64 number, int &year, int &month, int &day, int &hour, int &minute, int &second) {
// Conversion from seconds since epoch to days and seconds in day;
int days = number / (24*60*60);
int seconds = number - days * (24*60*60);
int year400 = days / 146097;
year = 400 * year400;
days = days - year400 * 146097;
int year100 = days / 36525;
year = year + 100 * year100;
days = days - year100 * 36525;
int year4 = days / 1461;
year = year + 4 * year4;
days = days - year4 * 1461;
int year1 = days / 365;
year += year1;
days = days - year1 * 365;
int m;
for (m = 0; days >= days_in_month[m]; m = m + 1) {
days = days - days_in_month[m];
}
month = m;
day = days + 1;
hour = seconds / (60*60);
seconds = seconds - hour * (60*60);
minute = seconds / 60;
seconds = seconds - minute * 60;
second = seconds;
// Conversion from modified calendar to standard calendar.
if (month < 10) {
month = month + 3;
} else {
month = month - 9;
year = year + 1;
}
}
UInt64 epoch = to_num(1901, 1, 1, 0, 0, 0);
struct DateTime {
int year;
int month;
int day;
int hour;
int minute;
int second;
};
UInt64 to_num(DateTime datetime) {
UInt64 result = to_num(datetime.year, datetime.month, datetime.day,
datetime.hour, datetime.minute, datetime.second);
result = result - epoch;
return result;
}
DateTime to_datetime(UInt64 number) {
DateTime result;
number = number + epoch;
to_datetime(number, result.year, result.month, result.day,
result.hour, result.minute, result.second);
return result;
}
struct Time_interval {
DateTime from;
DateTime to;
};
// Returns n*(n+1)/2.
UInt64 binomial(UInt64 n) {
// Computing without overflow
if (n % 2 == 0)
return (n/2) * (n+1);
else
return n * ((n+1)/2);
}
UInt64 encode(Time_interval interval) {
UInt64 from = to_num(interval.from);
UInt64 to = to_num(interval.to);
return binomial(to) + from;
}
Time_interval decode(UInt64 code) {
UInt64 min = 0;
// Computing constant 6,074,000,999 without overflow.
// This is the greatest integer n such that n*(n+1)/2 < 2^64.
UInt64 max = 6074001;
max = max * 1000;
max = max - 1;
// Binary search of the greatest number n such that n*(n+1)/2 <= code.
while (min +1 < max) {
UInt64 middle = (min + max) / 2;
if (binomial(middle) > code)
max = middle;
else
min = middle;
}
Time_interval result;
result.to = to_datetime(min);
result.from = to_datetime(code - binomial(min));
return result;
}
ostream& operator<<(ostream &ostr, DateTime datetime) {
ostr << datetime.year
<< "-" << datetime.month
<< "-" << datetime.day
<< " " << datetime.hour
<< ":" << datetime.minute
<< ":" << datetime.second;
return ostr;
}
ostream& operator<<(ostream &ostr, Time_interval interval) {
ostr << interval.from << " " << interval.to;
return ostr;
}
istream& operator>>(istream &istr, DateTime &datetime) {
char ch;
istr >> datetime.year;
istr >> ch;
istr >> datetime.month;
istr >> ch;
istr >> datetime.day;
istr >> datetime.hour;
istr >> ch;
istr >> datetime.minute;
istr >> ch;
istr >> datetime.second;
return istr;
}
istream& operator>>(istream &istr, Time_interval &interval) {
istr >> interval.from;
istr >> interval.to;
return istr;
}
int main() {
cout << "Enter the time interval (from-to) in the format yyyy-mm-dd hh:mm:ss yyyy-mm-dd hh:mm:ss" << endl;
Time_interval interval;
cin >> interval;
UInt64 code = encode(interval);
cout << "It's 64-bit code is " << code << " (decimal)" << endl;
Time_interval check = decode(code);
cout << "Decoded interval is\n" << check << endl;
return 0;
}
[Ovu poruku je menjao Nedeljko dana 26.10.2008. u 15:29 GMT+1][ Nedeljko @ 26.10.2008. 13:59 ] @
Nisam vas valjda toliko namučio? Ja samo lupio zadatak dok sam kucao poruku u temi "kako postati progrmer" i još zeznuo račun pa napisao 200 godina, a ono ispade tema od tri strane.
[ Nedeljko @ 26.10.2008. 14:03 ] @
Hoćete li uopštenje ovog zadatka, pa polako ka kompresiji šahovskih partija i pozicija? Imam algoritam.
[ Branimir Maksimovic @ 26.10.2008. 15:03 ] @
Nedeljko, izvinjavam se za juce malo sam se iznervirao umes da mi pogodis zivac ;)
ne radi ti resenje. Posto n(n+1)/2 sabiras sa nekim brojem to sto radis
binary search za n(n+1)/2 poredeci sa to+neki broj nista ti ne znaci mislim.
bmaxa@maxa:~$ ./nedeljko
Enter the time interval (from-to) in the format yyyy-mm-dd hh:mm:ss yyyy-mm-dd hh:mm:ss
1900-1-1 0:0:0 2000-1-1 0:0:0
It's 64-bit code is 4880117873397326400 (decimal)
Decoded interval is
1998-12-31 0:0:0 1999-12-31 23:59:59
Miljanovo resenje radi ali recimo da dekodira onih tvojih 8miliona datuma sa strima
za jednu sekundu po dekodingu, trebalo bi mu jedno 3meseca ;)
a kako sad izgleda bice da je jedno pola godine minimum.
Sta fali onom mom resenju, to moze da se primeni u praksi?
Pozdrav!
[ mmix @ 26.10.2008. 15:11 ] @
Nedeljko, mislim da imas bug negde u resenje, ne (de)kodira pun span dobro:
C:\>encoding
Enter the time interval (from-to) in the format yyyy-mm-dd hh:mm:ss yyyy-mm-dd hh:mm:ss
1900-01-01 00:00:00 2091-12-31 23:59:59
It's 64-bit code is 18163434907925668800 (decimal)
Decoded interval is
2090-12-30 23:59:59 2091-12-31 23:59:58
AL zanimljiv algoritam za dekoding, probacu da primenim kod mene. [ Nedeljko @ 26.10.2008. 15:17 ] @
Branimire,
U rešenju je dozvoljen opseg godina od 1901-2092. Nije ni čudo što si dobio besmislen rezultat. Ako hoćeš od 1900 god. onda moraš da promeniš liniju UInt64 epoch = ...
Nisam hteo da opterećujem program proverama ulaza, ali to se ispostavio kao greška.
Nedostatak tvog rešenja je što nisi sve iskodirao sa 64 bita, već ti trebaju još 2 bita da bi odredio tip.
Za 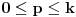 važi 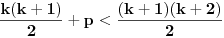 , pa sa onim pretraživanjem nema problema. [ Branimir Maksimovic @ 26.10.2008. 15:19 ] @
Oki doki,
najbolji si.
Pozdrav!
[ Nedeljko @ 26.10.2008. 15:24 ] @
Zaista me mrzi da merim brzinu onog mog programa, ali ako nekoga ne bi mrzelo, bio bih mu zahvalan.
[ Nedeljko @ 26.10.2008. 16:13 ] @
Kod mene ispade ispod 0.4 mikrosekunde za kodiranje i ispod 2 mikrosekunde za dekodiranje.
[ Nedeljko @ 26.10.2008. 16:36 ] @
Ako su vam ovakve teme zanimljive, mogu ja i da nastavim.
[ mmix @ 26.10.2008. 16:49 ] @
Nije lose, samo sto ja prelazim nazad u pasivne posmatrace, pocinje mi novi projekat sutra i ne mogu vise da aktivno ucestvujem.
[ Nedeljko @ 26.10.2008. 17:10 ] @
Informacioni sistem fakulteta treba za svakog studenta da memoriše datum njegovog rođenja i datum rođenja njegovog oca. Pritom, fakultet mora da unese kako podatke o ranijim i sadašnjim studentima, tako i da ubuduće unosi podatke o novim studentima. Fakultet je ogroman, a hard disk mali.
Koliko je bitova potrebno po studentu za memorisanje ta dva podatka ako se zna:
- da su oba datuma u opsegu od 1900-1-1 do 2099-12-31, (posle se kupuje veći hard disk)
- da starosna razlika između oca i sina ne može biti manja od 16 godina (dakle, iznosi najmanje 5844 dana)?
P.S. Posle ubacujemo i dedu.
[ negyxo @ 26.10.2008. 17:32 ] @
@mmix
Jel gotov racun za onaj opseg :)
Elem,
Ja sam se iskreno namucio sinoc, u stvari enkoding mi nije bio problem, brzo se videlo da je u pitanju trougasta matrica, ali za dekoding nisam znao kako da namestim, prvo sto mi je padalo je O(n) search, ali sam znao da ce to da potraje mnogo dugo, pa mi je prvo sleedece palo da namestim algoritam brzine pretrage O(log n) ali sam tek sad vidim, pogresio u implementaciji.
Pogledacu vasa resenja, bas me interesuje implementacija dekodinga, posto za njega nisam imao nikakvu optimizovanu ideju.
[ Nedeljko @ 28.10.2008. 11:07 ] @
Da li za novi zadatak nema interesovanja ili da objavim resenje?
[ Branimir Maksimovic @ 29.10.2008. 17:26 ] @
Nedeljko, pazi ovo O(1) resenje ;)
Code:
const uint64_t maxDateValue = 6074000999ull;
uint64_t encodeDate(uint64_t start, uint64_t stop)
{
uint64_t rc;
if(stop-start>maxDateValue/2)
rc = (maxDateValue/2-start)*maxDateValue+stop;
else
rc = (stop-start)*maxDateValue+start;
return rc;
}
void decodeDate(uint64_t blob, uint64_t* start, uint64_t* stop)
{
uint64_t s1 = blob/maxDateValue;
uint64_t s2 = blob%maxDateValue;
if(s1 + s2 >= maxDateValue)
{
*start = maxDateValue/2-s1;
*stop = s2;
}
else
{
*start = s2;
*stop = s1+s2;
}
}
edit: pardon treba if(s1+s2>=max) zato sto je max neparan
Pozdrav!
[Ovu poruku je menjao Branimir Maksimovic dana 29.10.2008. u 23:35 GMT+1][ Nedeljko @ 30.10.2008. 11:11 ] @
Ako je 0<=a<m i 0<=b<n, onda je code = a*n+b, a = code/n, b = code-a*n, 0<=code<m*n
Medjutim, na taj nacin ces zadatak sa kodiranjem intervala u opsegu od 192 godine sa rezolucijom od 1s resiti sa 65 bitova, jer je 0<=code<m*n. Kada bi posebno pamtio pocetak, a posebno kraj intervala, za svaki od njih bi ti trebalo 33 bita, pa bi ukupno potrosio 66 bitova. Ovako, kada ih pamtis "grupno" prethodnim algoritmom, treba ti 65 bitova. Medjutim, na taj nacin neces doboti resenje sa 64 bita, jer nisi iskoristio uslov da pocetak ne moze biti posle kraja, tj. imas i kodove "intervala" kod kojih je pocetak posle kraja. Da bi resio problem u 64 bita, moras iskoristiti i taj uslov koji odbacuje polovinu parova cime se stedi jos jedan bit.
P.S. Svaki algoritam koji resava ovaj problem (makar i grubom silom, kako god) ga resava u vremenu O(1). Sta mislis zasto.
[ Branimir Maksimovic @ 30.10.2008. 14:19 ] @
Jesi ti proverio da li ovo radi ;) a radi.
Tacno je to sto kazes ali sve zavisi od nacina kako kodiras.
Fora je da a*m+b bude tako da uvek a<=m/2 i b<m
Sta mislis jel sam ovo poslao napamet ili sam prvo proverio da li radi ;)
Nego logika mi govorila da ovo moze sa O(1) samo sam trebao da uhvatim
pravilnost ;)
Ako ti nije jasno objasnicu u sledecem postu.
Drugo, ne kapiram sta podrazumevas pod time pocetak posle kraja?valjde je uslov da interval a,b bude takav da a<=b ili ne?
Pa ni tvoje niti bilo koje drugo resenje ne radi u tom slucaju zato sto sa 64 bita
*ne mozes* pokriti te slucajeve jer onda imas n^2 a ne n(n+1)/2 mogucnosti ;)
Pozdrav!
edit: sto se tice kompleksnosti algoritma tvoj za dekodiranje ima O(log n) kompleksnost a ne O(1)
[Ovu poruku je menjao Branimir Maksimovic dana 30.10.2008. u 15:45 GMT+1]
[ Nedeljko @ 30.10.2008. 16:27 ] @
Proverio sam tvoj algoritam i ima samo jedan lako otklonjiv nedostatak: Izasao si iz 64-bitne aritmetike. Kada je start blizu pocetka, a stop blizu kraja, imaces prekoracenje (s1+s2 je oko 3*m/2). No, to se moze srediti racunanjem u 128-bitnoj aritmetici.
Svaki algoritam koji ima konacan broj mogucih vrednosti na ulazu ima slozenost O(1). Ovde mogucih vrednosti na ulazu ima n=18356099197581849600 mogucih vrednosti na ulazu. To su celi brojevi od 0 do n-1. Neka je v(x) vreme potrebno za dekodiranje vrednosti x (ceo broj od 0 do n-1). Vrednost v=maxxv(x) je konacna kao maksimum konacnog skupa konacnih vrednosti. Kakav god da je ulaz, ne treba ti vise od v vremena (a v je konstanta) za dekodiranje, pa je to svakako O(1), bez obzira na algoritam (ukljucujuci i najgrublju silu).
No, svakako da imam log2(n) iteracija, ali, strogo govoreci, kod nas je n konacno, pa je i broj mojih iteracija ogranicen (na 64), tako da je svakako O(1). Medjutim, ako smatramo da je n nesto mnogo veliko, onda smatramo moje vreme logaritamskim po n, mada je strogo matematicki govoreci ograniceno.
No, tvoj algoritam je svakako bolji. Svaka ti cast! Tesko bih se ovoga setio.
[ Nedeljko @ 30.10.2008. 16:30 ] @
Citat: Branimir Maksimovic: Drugo, ne kapiram sta podrazumevas pod time pocetak posle kraja?valjde je uslov da interval a,b bude takav da a<=b ili ne?
Pa ni tvoje niti bilo koje drugo resenje ne radi u tom slucaju zato sto sa 64 bita
*ne mozes* pokriti te slucajeve jer onda imas n^2 a ne n(n+1)/2 mogucnosti ;)
Tacno. Zato se taj uslov mora iskoristiti da bi se sve spakovalo u 64 bita (tj. moraju se odbaciti parovi kod kojih je pocetak posle kraja, koji su besmisleni, da se ne bi kodovi trosili na njih). To je caka koju sam imao na umu kada sam postavljao zadatak. [ Nedeljko @ 30.10.2008. 20:20 ] @
Citat: Nedeljko: Proverio sam tvoj algoritam i ima samo jedan lako otklonjiv nedostatak: Izasao si iz 64-bitne aritmetike. Kada je start blizu pocetka, a stop blizu kraja, imaces prekoracenje (s1+s2 je oko 3*m/2). No, to se moze srediti racunanjem u 128-bitnoj aritmetici.
Može se ispitati dali je s1+s2>=maxDateValue i unutar 64-bitne aritmetike.
[ Branimir Maksimovic @ 30.10.2008. 20:38 ] @
s1+s2 == max 34 bitni broj ;)
probaj za sve vrednosti i videces da radi. ;)
nema nikakve 128 butne aritmetike.
No kapiram tesko je poverovati da ovo radi, ali radi ;)
Pozdrav!
edit: i jos jedan pozdrav i hvala na zadatku, da malo razbijem monotoniju dnevnog posla ;)
sto se tice kompleksnosti na input od n elemnata binary search daje O(log n) kompleksnost
bez obzira sto je n fiksno u nasem slucaju. Medjutim u zavisnosti od inputa
imas minimum 1 a maksimum log n iteracija. Zbog toga se tako kaze cini mi se.
[Ovu poruku je menjao Branimir Maksimovic dana 31.10.2008. u 02:51 GMT+1]
[ Nedeljko @ 31.10.2008. 08:00 ] @
Ako je n konstanta, onda su O(n) i O(log n) isto sto i O(1). No, razumeli smo se.
[ Nedeljko @ 31.10.2008. 11:16 ] @
U pravu si bio da nema prekoracenja. Sve je u 64-bitnoj aritmetici.
Nego, da li bi mogao da napravis uopstenje ovoga? Recimo, kodirati parove (x,y) tako da je 0<=x<=y<n vrednostima 0,...,n*(n+1)/2-1. Rekao bih da u slucaju y-x>n/2, mozes svoji algoritmom da dobijes kodove koji nisu manji od n*(n+1)/2. Takodje, resavao si slucaj kada je n parno. Neka n bude proizvoljan priridan broj.
[ Branimir Maksimovic @ 31.10.2008. 18:54 ] @
Mislim da ovo resenje radi i za parne i neparne maximalne vrednosti.
U pocetku sam stavio originalni uslov s1+s2>max sto je pokrivalo samo parne
ali sa s1+s2>=max pokriva i neparne max.
Da u pravu si maximalna vrednost je n(n+2)/2 - 1 ali sa obzirom da celobrojno deljenje
skrati n/2 za 1 bit to se svodi na k(2k+2) sto je k(n+1) gde je n == 2k+1 u slucaju neparnog.
A u parnim slucajevima ovo ne prelazi 64 bita posto je max neparni.
Da je max paran broj ovo ne bi radilo.
E tu sad stoji jedno interesantno pitanje: jel max neparan slucajno ;)?
Pozdrav!
[ Nedeljko @ 01.11.2008. 20:38 ] @
Još jednom, sve čestitke za briljantno rešenje.
Šaljem rešenje za opšti slučaj u PDF formatu.
P. S. Kada je n veliko, tj. izlazi iz opsega ugrađenih tipova, pa se mora koristiti aritmetika u proizvoljnoj tačnosti, naša rešenja imaju, do na O (tj. do na konstantan faktor) istu složenost, ali o tome ću neki drugi put.
[ Nedeljko @ 03.11.2008. 10:55 ] @
Pretpostavimo da je n(=broj mogucnosti za trenutak) jako veliko, tj. da daleko premasuje opsege ugradjenih tipova, pa da se mora koristiti aritmetika za racunanje u proizvoljnoj tacnosti. U toj aritmetici, (sa najbrzim poznatim algoritmima) slozenost racunskih operacija iznosi:
- O(n) za sabiranje i oduzimanje, kao i za mnozenje i delenje malim vrednostima (koje su unutar opsega ugradjenih tipova), npr. sa 2 i za poredjenje (u najgorem slucaju),
- O(n log(n)) za mnozenje,
- O(n log2(n)) za delenje, kao i za korenovanje proizvoljnog stepena.
Moj algoritam za kodiranje ima dva sabiranja, jedno mnozenje i jedno delenje sa dva, odnosno slozenost O(n log(n)). Moj algoritam za dekodiranje ima O(log(n)) iteracija koje ukljucuju poredjenje, sabiranje, mnozenje i delenje sa 2. Znaci, iteracije imaju slozenost O(n log(n)), ali posto iteracija ima O(log(n)), cela petlja ima slozenost O(n log2(n)). Nakon toga imam fiksan broj mnozenja, sabiranja, oduzimanja i delenja sa 2, pa je O(n log2(n)) ukupna slozenost algoritma.
Branimirov algoritam za kodiranje ima slozenost O(n log(n)) jer ukljucuje fiksan broj sabiranja, oduzimanja, delenja sa 2, mnozenja i poredjenja. Algoritam za dekodiranje ima fiksan broj operacija, od kojih je najzahtevnije delenje (za izracunavanje vrednosti s1), pa ima slozenost O(n log2(n)).
Dakle, ovako posmatrano, slozenost oba algoritma je ista do na konstantan faktor. Medjutim, ako treba izvrsiti veliki broj kodiranja i dekodiranja sa istom vrednoscu n, onda se veliki broj delenja sa uvek istom vrednoscu moze vrsiti sa slozenoscu O(n log(n)) po delenju, pa u tom slucaju (ako program radi uvek sa istom vrednoscu za n, koja se jednom zadajen na ulazu u program), onda je Branimirov algoritam brzi, tj. ima slozenost O(n log(n)).
Sa druge strane, unutar opsega ugradjenih tipova, jeste da se delenje vuce ko mrcina u poredjenju sa drugim operacijama, ali je ipak brze od moje petlje, jer je hardverki implementirano.
Jos jednom, sve cestitke za Branimira.
Copyright (C) 2001-2026 by www.elitesecurity.org. All rights reserved.
|