|
|
[ mojeKorIme @ 10.03.2009. 06:50 ] @
|
| U prethodnoj temi (Optimizacija MySQL servera) je spomenuto da je pored najbolje optimizacije servera, ako ne projektujemo logicki bazu podataka necemo imati sistem koji "radi kako treba". //imam iskustva sa ovim problemom
Na šta treba obratiti pažnju prilikom projektovanja baze podataka? kako postaiti pravilno indekse, jer oni iako mogu pomoći u nekim slučajevima (select ..) mogu i usporiti unos podataka.
|
[ bogdan.kecman @ 10.03.2009. 12:31 ] @
bojim se da ovde ne mogu da budem toliko koristan :( .... posto za ovo vec mora da se ide u skolu i da se malo uci teorija :)
neke osnovne stvari na koje treba obratiti paznju
- baza treba da bude normalizovana
- mysql moze (za sada) u jednom upitu da koristi samo 3 indexa tako da - pravite kompozitne indexe gde je to potrebno
- indexi u tabeli usporavaju insert
- ako nam je potrebno da nadjemo kolonu A indexi (A) i (A,B) su isti .. tj ako u tabeli postoji index (A,B) index (A) je visak (index (B) nije !)
- imenovanje tabela moze da pomogne, ovo su MOJE preference (nisu kompatibilne sa, recimo, WB-om :) )
o Tabele imenujte JEDNINOM - dakle ENTITET
o Kolone imenujte ENTITET_ATRIBUT
o Ne koristite sva velika slova :D - mnogo ruzno izgleda
dakle neki primer
Code:
create table `korisnik` (`korisnik_id` unsigned bigint primary key auto_increment, `korisnik_ime` varchar(30), `korisnik_prezime` varchar(30), `lokacija_id` unsigned bigint, key (`lokacija_id`));
create table `lokacija` (`lokacija_id` unsigned bigint primary key auto_increment, ....
ako imate "pod entitete" tipa korisnik_lokacija_grad, korisnik_lokacija_drzava ... znaci da DB model nije normalizovan
ako imate IF() / Switch u upitu u 99% clujajeva znaci da DB model nije optimizovan
dalje od ovoga ... uputstvo za erwin :) .. odlicna knjiga za optimizaciju db modela ... cak stavise, neka profanka sa beogradskog pmf-a koja drzi "baze" je isto uputstvo prevela od reci do reci i izdala kao knjigu za svoj predmet :D :D :D ... cak deluje da su to neki studenti prevodili posto se vidi 10 strana jedan nacin pisanja, pa 10 strana drugi, pa 10 strana treci ...
[ bogdan.kecman @ 10.03.2009. 12:55 ] @
evo iskopao sam neki svoj stari text na ovu temu ..
Modeliranje baze podataka - Normalizacija
Normalizacija modela baze podataka je proces definisanja strukture baze podataka (entiteti, atributi i relacije) u optimalni format. Standardne normalne forme su aditivne, dakle ako je neki model sveden na trecu normalnu formu, automatski je u drugoj i prvoj normalnoj formi. Osnovne forme DB modela su:
1NF: Prva normalna forma
2NF: Druga normalna forma
3NF: Treca normalna forma
BCNF: Boyce/Codd normalna forma
4NF: Cetvrta normalna forma (aka izolacija nezavisnih relacija)
5NF: Peta normalna forma (aka izolacija semanticki povezanih relacija)
DKNF: Domen/Kljuc normalna forma (aka savrsen model)
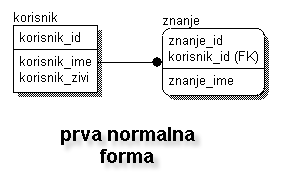
Svodjenje modela na prvu normalnu formu
Krenucemo od jednostavne strukture, imamo spisak clanova foruma koji imaju nekakvo znanje o raznim materijama. Neki clanovi znaju o muzici, neki o hardware-u dok se neki bolje snalaze sa linux-om; naravno, postoje i oni koji vrlo dobro poznaju i hardware i muziku etc. Primer jednostavne tabele bi izgledao ovako:
Code:
ID: 1
KORISNIK: pera peric
ZIVI: Srbija
ZNANJE: Audio
ID: 2
KORISNIK: mika mikic
ZIVI: Srbija
ZNANJE: Video
ID: 3
KORISNIK: zikica zikic
ZIVI: Srbija
ZNANJE: Audio, Video, Hardware, Windows
ID: 4
KORISNIK: mali perica
ZIVI: Srbija
ZNANJE: Audio, Video, Baze, Hardware, Windows, Linux, Programiranje
ID: 5
KORISNIK: mali zikica
ZIVI: BIH
ZNANJE: Programiranje, Hardware
Ako zelimo da saznamo koji korisnik zna "video" moramo proci kroz sve korisnike, proveriti sadrzaj polja "znanje" i pregledati prilicno nepregledno polje "znanje" te otkriti da li doticni korisnik zna "video" ili ne ... Mane ovakve organizacije su ocigledne (brzina, preglednost...) te je ovo vrlo nepraktican nacin za cuvanje informacija.
Klasificiranje podataka u zasebne tabele ce "prisrediti" podatke i omoguciti laksu pretragu. Razdvajanje repetitivnih podataka u zasebne tabele nasu strukturu dovodi u prvu normalnu formu.
Iz naseg primera (gde je sve bilo nagurano u istu tabelu), dobijamo 2 odvojene tabele:
TABELA: KORISNIK
Code:
KORISNIK_ID: 1
KORISNIK_IME: pera peric
KORISNIK_ZIVI: Srbija
KORISNIK_ID: 2
KORISNIK_IME: mika mikic
KORISNIK_ZIVI: Srbija
KORISNIK_ID: 3
KORISNIK_IME: zikica zikic
KORISNIK_ZIVI: Srbija
KORISNIK_ID: 4
KORISNIK_IME: mali perica
KORISNIK_ZIVI: Srbija
KORISNIK_ID: 5
KORISNIK_IME: mali zikica
KORISNIK_ZIVI: BIH
TABELA: ZNANJE
Code:
ZNANJE_ID: 1
KORISNIK_ID: 1
ZNANJE_IME: Audio
ZNANJE_ID: 2
KORISNIK_ID: 2
ZNANJE_IME: VIDEO
ZNANJE_ID: 3
KORISNIK_ID: 3
ZNANJE_IME: Audio
ZNANJE_ID: 4
KORISNIK_ID: 3
ZNANJE_IME: Video
ZNANJE_ID: 5
KORISNIK_ID: 3
ZNANJE_IME: Hardware
ZNANJE_ID: 6
KORISNIK_ID: 3
ZNANJE_IME: Windows
ZNANJE_ID: 7
KORISNIK_ID: 4
ZNANJE_IME: Audio
ZNANJE_ID: 8
KORISNIK_ID: 4
ZNANJE_IME: Video
ZNANJE_ID: 9
KORISNIK_ID: 4
ZNANJE_IME: Baze
ZNANJE_ID: 10
KORISNIK_ID: 4
ZNANJE_IME: Hardware
ZNANJE_ID: 11
KORISNIK_ID: 4
ZNANJE_IME: Windows
ZNANJE_ID: 12
KORISNIK_ID: 4
ZNANJE_IME: Linux
ZNANJE_ID: 13
KORISNIK_ID: 4
ZNANJE_IME: Programiranje
ZNANJE_ID: 14
KORISNIK_ID: 5
ZNANJE_IME: Hardware
ZNANJE_ID: 15
KORISNIK_ID: 5
ZNANJE_IME: Programiranje
Sada je pitanje "koji korisnik zna video?" mnogo lakse odgovoriti. [ bogdan.kecman @ 10.03.2009. 12:56 ] @
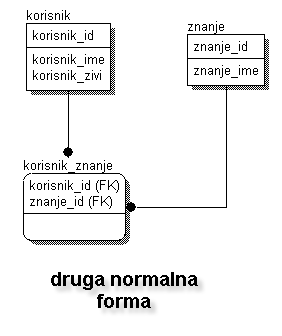
Svodjenje modela na drugu normalnu formu
Ako pogledamo tabelu "ZNANJE" iz prethodnog primer, primeticemo da nam se podaci dupliciraju. Za razliku od tabele "KORISNIK" gde atribut KORISNIK_ID definise slog tabele, u tabeli KORISNIK slog se definisu KORISNIK_ID i ZNANJE_ID atributi zajedno. Ovo u nekim slucajevima moze da ima smisla, ali u nasem slucaju, gde ime "znanja" realno nije ni u kakvoj relaciji sa korisnikom i bezrazlozno se multiplicira u tabeli, mozemo zakljuciti da nam se podaci "dupliraju". Ovo dupliranje podataka, osim sto se odrazava na prostor potreban za cuvanje istih, otezava operacije sa bazom.
Ako na primer zelite da promenite ime jednog znanje (na primer zelite da "Audio" postane "Rad sa zvukom") morate to ime promeniti na vise mesta umesto samo na jednom (anomalija pri promeni). Dalje, pretpostavite da "mali perica" ode sa foruma; u tom slucaju treba obrisati sve slogove vezane za njega; u tom slucaju, potpuno ce nestati referenca da je znanje "Linux" postojalo na forumu (anomalija pri brisanju).
Da bi ste zaobisli ove anomalije, potrebna vam je druga normalna forma.
Da bi "razvili" nasu bazu u drugu normalnu formu, potrebno je da razdvojimo atribute koji zavise od oba kljuca koji definisu tabelu "ZNANJE". Rezultat ce biti dve tabele:
TABELA: ZNANJE
Code:
ZNANJE_ID: 1
ZNANJE_IME: Audio
ZNANJE_ID: 2
ZNANJE_IME: Video
ZNANJE_ID: 3
ZNANJE_IME: Hardware
ZNANJE_ID: 4
ZNANJE_IME: Windows
ZNANJE_ID: 5
ZNANJE_IME: Baze
ZNANJE_ID: 6
ZNANJE_IME: Linux
ZNANJE_ID: 7
ZNANJE_IME: Programiranje
TABELA: KORISNIK_ZNANJE
Code:
ZNANJE_ID: 1
KORISNIK_ID: 1
ZNANJE_ID: 2
KORISNIK_ID: 2
ZNANJE_ID: 1
KORISNIK_ID: 3
ZNANJE_ID: 2
KORISNIK_ID: 3
ZNANJE_ID: 3
KORISNIK_ID: 3
ZNANJE_ID: 4
KORISNIK_ID: 3
ZNANJE_ID: 1
KORISNIK_ID: 4
ZNANJE_ID: 2
KORISNIK_ID: 4
ZNANJE_ID: 3
KORISNIK_ID: 4
ZNANJE_ID: 4
KORISNIK_ID: 4
ZNANJE_ID: 5
KORISNIK_ID: 4
ZNANJE_ID: 6
KORISNIK_ID: 4
ZNANJE_ID: 7
KORISNIK_ID: 4
ZNANJE_ID: 3
KORISNIK_ID: 5
ZNANJE_ID: 7
KORISNIK_ID: 5
[ bogdan.kecman @ 10.03.2009. 12:57 ] @
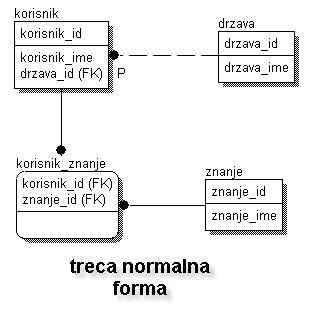
Svodjenje modela na trecu normalnu formu
Ako pogledamo malo bolje tabelu "KORISNIK" videcemo da iako ispunjava i prvu i drugu normalnu formu, atribut "ZIVI" nije direktno zavistan od ID-a korisnika (primarnog kljuca). Da bi postigli trecu normalnu formu, taj podatak mora da se odvoji u zasebnu tabelu. Zasto? Ako uzmemo na primer da "mali zikica" napusti forum, te se slogovi koji njega definisu obrisu, nestace trag o "BIH" (anomalija pri brisanju) ili ako "Srbija" ponovo promeni ime u "Republika Beograd sa okolinom", to ime moramo promeniti na vise od jednog mesta (anomalija pri promeni). Razlaganje na trecu normalnu formu zahteva da podatak o "ZIVI" prebacimo u zaseban entitet.
TABELA: DRZAVA
Code:
DRZAVA_ID: 1
DRZAVA_IME: Srbija
DRZAVA_ID: 2
DRZAVA_ID: BIH
TABELA: KORISNIK
Code:
KORISNIK_ID: 1
KORISNIK_IME: pera peric
DRZAVA_ID: 1
KORISNIK_ID: 2
KORISNIK_IME: mika mikic
DRZAVA_ID: 1
KORISNIK_ID: 3
KORISNIK_IME: zikica zikic
DRZAVA_ID: 1
KORISNIK_ID: 4
KORISNIK_IME: mali perica
DRZAVA_ID: 1
KORISNIK_ID: 5
KORISNIK_IME: mali zikica
DRZAVA_ID: 2
[ bogdan.kecman @ 10.03.2009. 13:01 ] @
[ Zmaj @ 10.03.2009. 23:03 ] @
sta reci, osim, skidam kapu na ovolikom trudu... odavno nisam procitao ovoliko kvalitetnih postova, nevezano za temu i sobu na ovom forumu... e da je vise ovakvih postova...
[ bogdan.kecman @ 10.03.2009. 23:34 ] @
fala pedja, koliko se ja secam i vi u vast-u koristite mysql :) .. mozete da podelite iskustva :) ... doduse, vi ga uglavnom koristite kao "communication layer" nego kao bazu podataka :) no to je isto zanimljiva primena (koristiti bazu podataka za interprocess komunikaciju na oblaku - posto se to sto vi radite - sa tim brojem masina - ladno moze nazvati oblak)
[ mojeKorIme @ 11.03.2009. 07:21 ] @
nema me neko vrijeme ..a vec se postavi nekoliko vrlo kvalitetnih postova..
gdje si bio Bogdane dok sam studirao... bolji post o normalizaciji još nisam pročitao..:D..
PS Na koju normu je najbolje svesti sistem.. ima li neko pravilo to koje određuje?
[Ovu poruku je menjao mojeKorIme dana 11.03.2009. u 08:45 GMT+1]
[ bogdan.kecman @ 11.03.2009. 14:02 ] @
Citat: gdje si bio Bogdane dok sam studirao...
eh... za kompjuterom verovatno ...
Citat:
bolji post o normalizaciji još nisam pročitao..:D..
post je par godina star... planirao sam i ostale norme da obradim al nikad nisam nasao dovoljno slobodnog vremena ... ne ide mi bas pisanje ... posebno ne na srpskom, posto nikad o ovim stvarima ne diskutujem na srpskom ... osim evo sad na ovom forumu i tamo na onom mom mysql blogu .. (sve to tek par meseci)...
Citat: PS Na koju normu je najbolje svesti sistem.. ima li neko pravilo to koje određuje?
there is no silver bullet :D
teoretski, sto "normalnija" baza to bolje .. e sad, vrlo cesto, zbog nesavrsenosti rdbms-a, mi radimo denormalizaciju baze i dupliciramo neke podatke namerno, da bi dobili na brzini .. ono sto dba/dbdev-a cini velikim je da zna kada, koliko i zasto ce to da uradi, da ima mere i slicno ...
dakle teoretski DKNF je "idealna forma" .. prakticno .... nije lako reci, normalne forme preko trece krecu gadno da komplikuju stvari :D .. na vecini domacih fakulteta ih ni ne spominju ni imenom a kamoli objasnjavaju kako sljakaju :D (ok, nije neki reper, skole nam nisu ni za ...) ali mozes pogledati par referenci ...
http://en.wikipedia.org/wiki/Database_normalization
http://en.wikipedia.org/wiki/Boyce-Codd_normal_form
...
http://en.wikipedia.org/wiki/Domain/key_normal_form
...
http://en.wikipedia.org/wiki/Sixth_normal_form
[ misk0 @ 11.03.2009. 19:23 ] @
Svaka cast za postove!!
Jedna mi je stvar zapela za oko (onako, ekserom) :)
Citat:
o Tabele imenujte JEDNINOM - dakle ENTITET
o Kolone imenujte ENTITET_ATRIBUT
Ako dobro ovo shvatam znaci:
table_name = ucenik
col_name = ucenik_ocjena
I onda malo dugacko izgleda query tipa
SELECT ucenik.ucenik_ocjena, ucenik.ucenik_prosjek, ucenik.ucenik_vladanje .....
Po meni vishe ima smisla koristiti za imena kolona ATRIBUT jer:
- kad radis sa jednom tabelom, naravno da su svi to atributi od te tabele i nista se ne mjesa
- kad radis sa vishe tabela, naravno da ces koristiti prefix tabele ispred kolone da napravis razliku.
Mozda ima jos nesto sto ja ne vidim??
[ bogdan.kecman @ 11.03.2009. 23:21 ] @
Citat: misk0:
Jedna mi je stvar zapela za oko (onako, ekserom) :)
Ako dobro ovo shvatam znaci:
table_name = ucenik
col_name = ucenik_ocjena
I onda malo dugacko izgleda query tipa
SELECT ucenik.ucenik_ocjena, ucenik.ucenik_prosjek, ucenik.ucenik_vladanje .....
jup, bude "dugacak upit" to jeste, ali ...
1. mnogo je lakse za normalizaciju, tj. vidi se iz aviona ako ne odradis normalizaciju kako treba
2. ako u tabeli EKSER imas polje CEKIC_ID vidi se iz aviona da je cekic_id strani kljuc iz tabele cekic ..
3. ako imas t1.t1_id, t1.t2_id, t2.t2_id mozes da radis join using (t2_id) sto inace ne bi mogao ...
4. ako radis upit select t1.ucenik_id, t2.ucenik_sveska, t3.grad_zip from ucenik t1, ucenik t2, grad t3 where .... ne moras da prodjes kroz ceo upit (da ucenik t1, ucenik t2 mogu da budu potrebni) da bi video sta je gde :) ja inace preferiram ti sa t1/t2/t3 vrlo cesto da radim zbog lakse optimizacije upita kasnije (cisto nacin na koji ja radim, nema veze sa realnim potrebama)
e sad, to je moja preferenca .. ide jos iz vremena kada innodb nije postojao a Monti ubedjivao svet da je svako kome trebaju strani kljucevi los developer. Za imenovanje atributa postoje razni predlozi, ne postoji usvojen standard. Ono oko cega se svi slazu je da entitete zovete jedninom, dakle nije "ucenici" nego "ucenik", sto se samog atributa tice, misljenja su podeljena - pogledaj samo kako mysql workbench naziva imena polja, posebno ona koja su deo stranog kljuca ... [ bogdan.kecman @ 12.03.2009. 02:36 ] @
Evo nekih "tudjih" pogleda na imenovanje entiteta i atributa:
http://www.peachpit.com/articl...cle.aspx?p=30885&seqNum=10
http://justinsomnia.org/2003/0...-naming-conventions-and-style/
http://www.interaktonline.com/....html?id_art=24&id_asc=221
generalno, "pravilo" je koristenje jednine za imena tabela "mada se mnogi zale i to ne postuju" ..
"prefix the name of every field with the table name, excluding foreign key" je takodje je "pravilo" ali ga mnogi ne postuju
etc etc ...
dakle, sve u svemu .. stil / konvencija koju ja koristim / zagovaram je "matoro (ne)pisano pravilo" i danas se mnog o ta pravila oglusuju / namerno ih, sa objasnjenjem ne postuju. Kao sto sam naveo, sam MySQL u WB-u ne postuje tu konvenciju .. no, ja sam navikao i zagovaram te neke "stare sisteme vrednosti" :) ... navika je cudo [ Leksiko @ 12.03.2009. 09:57 ] @
Bravo, sjajna tema i sjajni postovi.
[ Drasko M @ 12.03.2009. 11:40 ] @
Ovaj tekst o normalizacijama je zaista bio koristan mada mi je na neki nacin ostalo nejasno zasto se normalizacije nazivaju:prva, druga, treca..
Hocu reci, da meni sve normalizacije izgledaju isto - razlaze se neki kompleksni redundantni entitet na jednostavnije neredundantne. U zavisnosti od 'slozenosti' pocetne strukture proces razlaganja moze da ima jedan ili vise nivoa.
Sto se tice 'dobre prakse' do kog stepena treba ici to zavisi od toga sta zelite da postignete.
Ukoliko vam je cilj 'konzistentnost podataka' tj. da se izmene u jednom entitetu reflektuju i na drugim entitetima onda svakako sto veci stepen normalizacije.
Nekad vam to nece biti cilj.
Zamislite da imate tabelu proizvodi koja ima polja proizvodID i cena
Druga tabela su porudzbine gde imate porudzbinaID , kolicina , ukupna cena
Ukupna cena bi mogao biti redundantan podatak jer se moze dobiti iz cene (tabela proizvodi) i kolicine (tabela porudzbine)
Medjutim, mozda je poslovna politika takva da cena proizvoda moze biti promenjiva i da je za realizovanu porudzbinu bitna cena proizvoda u tom trenutku(trenutku prodaje) .Onda vam svakako polje ukupna cena nece biti na odmet.
[ bogdan.kecman @ 12.03.2009. 18:03 ] @
Citat: Drasko M: Ovaj tekst o normalizacijama je zaista bio koristan mada mi je na neki nacin ostalo nejasno zasto se normalizacije nazivaju:prva, druga, treca..
Hocu reci, da meni sve normalizacije izgledaju isto - razlaze se neki kompleksni redundantni entitet na jednostavnije neredundantne. U zavisnosti od 'slozenosti' pocetne strukture proces razlaganja moze da ima jedan ili vise nivoa.
sam kazes "proces razlaganja moze da ima jedan ili vise nivoa" ..
no, normalne forme su rangirane po broju resenja koje nude ... manji broj normalne forme, manje problema resava ... no .. taj deo teorije stvarni nije bitno ... da sam pisao onako kako lelemu.. ovi na faxu kod nas em niko nista ne bi razumeo em bi se svi smorili ...
sto se tice denormalizacije .. kao sto rekoh, zavisno od zahteva, zavisno od rdbms-a denormalizacija se radi u nekim slucajevima. tvoj primer nije bas idealan posto si ti dao primer kada taj info ne moze da se izvuce iz tabele te samim tim podatak nije redundantan jer "politika takva da cena proizvoda moze biti promenjiva" - sa ovim zahtevom ti realno nemas nacin da izvadis taj podatak osim da ga cuvas / nije redundantan
ali na primer ako imamo (slican / isti slucaj)
tabela: istorija cena
[pk] proizvod_id
[pk] proizvod_datumcene
proizvod_cena
tabela: racun
racun_id
racun_datum
tabela: artikli
[pk] racun_id
[pk] prioizvod_id
kolicina
cena
ti mozes da na racunu znas cenu artikla tako sto ces proveriti cenu artikla u tabeli istorija cena na dan racuna ... tj artikli.cena je cena iz istorije cena na datum racuna * kolicina :) ... e sada, posto je tabela artikli "write only" .. tu se samo dodaje, nema nikakvih promena - to se prodao po toj ceni, mi stavimo atribut cena u tabelu artikli koji je redundantan (rekoh kako ga mozemo izracunati) ali tih par bajtova po neindeksiranoj koloni nece mnogo smetati a bilo kakav report ce biti mnooooooooooogo brzi / jednostavniji ....
da ne knaram ... sad sam ja poceo da lele.udim sa teorijom koja nicemu ne sluzi ... cela ta teorija je osmisljena da bi se stvar koju svaki dobar dba radi "po osecaju" iz prve, objasnila onima sa "zeljom" ... [ Shavgan @ 12.03.2009. 23:49 ] @
Za bogdana jedan veliki RESPECT... svaka cast majstore uvijek imas umjeren odgovor sa dosta korisnih informacija..predlazem ti ako imas vremena da uradis jedan vid video turtorijala za rad sa bazama koristeci mysql sistem...mislim da bi to bio pun pogodak..nesto slicno je uradio Istok za rad u Flash-u
[ Drasko M @ 13.03.2009. 00:24 ] @
Hvala na odgovoru., lepo je imati coveka iz Sun-a , odnosno MySql Development Team-a na ovom forumu - informacije iz prve ruke :)
[ bogdan.kecman @ 13.03.2009. 01:13 ] @
Citat: Shavgan:vid video turtorijala za rad sa bazama koristeci mysql sistem
rad sa bazama ne podrazumeva nista "graficki" da bi bilo kakav "film" pomogao, to nije program koji ti koristis pa da imas 30 opcija koje neko treba da objasni kroz primere ... ja licno ne koristim nikakav gui za rad sa mysql-om, za zivota sam koristio nekoliko, na windozi je ems mysql manager najbolji koji sam probao (500$ kosta i prave ga rumuni ili madjari ili tako neka firma iz okoline) .. koristim mysql cli za sve sto imam da radim sa mysql-om .. od grafickih alata koristim WorkBench i ne znam ga nista bolje nego sto bi ti znao da kroz njega klikces 10 dana ... ali WB nema bas mnogo veze sa mysql-om
Citat: Drasko M: Hvala na odgovoru., lepo je imati coveka iz Sun-a , odnosno MySql Development Team-a na ovom forumu - informacije iz prve ruke :)
nema na cemu, no, ja radim u timu "MySQL Support", "MySQL Development" team je drugi tim (sa kojima ja tesno saradjujem, komuniciram svaki dan, koje cimam za dodatne informacije i slicno)... Moj posao je konsalting i podrska vezana za MySQL Cluster i u slobodno vreme radim development za MySQL Cluster .. Generalno, mi iz "support" tima radimo i development i konsalting, oni iz developmenta rade samo development i oni iz konsaltinga rade samo konsalting. Malo je to "komplikovano organizovano" ... mi radimo konsalting koji je ukljucen u suipport (gold i platinum kontrakti), dakle sa postojecim klijentima, a "konsalting grupa" radi sa firmama koje nisu klijenti vec uzimaju ili 1time konsalting ili uzimaju pre-sales konsalting; tako da niti radim support/konsalting za MySQL Enterprise Server, MySQL Enterprise Monitor, MySQL Workbench ... niti mi je to u opisu posla :) sve ovo napisano je mogao da napise bilo koji malo obrazovaniji DBA, nisu ovo nikakve "tajne formule iz MySQL laboratorije" .. na zalost, problem je sto ti "malo obrazovaniji DBA" misle da su uvatili .... za .... pa svoje znanje cuvaju kao zmija noge i prave od svega toga veliku filozofiju ... evo cujes da DB2 DBA-ovi pricaju kako DB2 ne moze da se nauci za ceo zivot a da bi postao oracle DBA moras 12 godina da ucis ... za 12 godina ljudi postanu hirurzi na mozgu, rade doktorate na novim tehnologijama, ceo database sistem se napise za godinu dana ... tako da .. sve je to lelemudjenje od strane ljudi koji su odlicno placeni da ne rade nista ... i treba da budu placeni posto imaju odgovoran i bitan posao, i kada ne rade nista znaci da svoj posao rade odlicno .. sve je to ok, ali treba znati sta su bubrezi a sta ....
ja kada bih pisao te stvari koje radim, malo kome bi bile interesantne (na zalost malo ko bi ih i razumeo posto je potrebno znanje o specificnoj problematici) a 99.9999999% ljudi sa tim nikada nece doci u kontakt ... oni koji dolaze sa tim u kontakt su vec klijenti :) i smaraju me na dnevnoj osnovi :)
[ dusaSaLagera @ 17.03.2009. 14:14 ] @
Citat:
- ako nam je potrebno da nadjemo kolonu A indexi (A) i (A,B) su isti .. tj ako u tabeli postoji index (A,B) index (A) je visak (index (B) nije !)
Recimo ako imam tabelu friend(+s plus prefix pride :) ) sa kolonama friend_id1,friend_id2,...jos par kolona
Primarni kljuc mi je kompozitni friend_id1,friend_id2.
Dugo sam se dvoumio da li bi ikakvu korist dobio ako bih stavio kljuc i na friend_id1 jer se u where/joinima uglavnom ova kolona pojavljuje. Ako sam te dobro razumeo, moj pristup je ispravan, jel tako?
Takodje(ovako iz prve ruke da mi odgovoris ako mozes), u kolikoj meri je insert/update/select nad myISAM tabelama brze u odnosu na InnoDB engine? Isto tako sam primetio da na vecini hostinga na kojima sam hostovao svoje web aplikacije InnoDB nije dobro podesen, pa se precesto desavalo pucanje(a uz to nisam znao tad za sve prednosti MySQLi - tipa automatski rollback transakcija i u slucaju pucanja skripte na nepredvidjenom delu - pre rollbacka...da napomenem - ako nije jasno, pricam o PHP) . Da li mi mozes dati neke inside informacije o cemu(kojim varijablama) da vodim racuna prilikom podesavanja mysql-a za InnoDB? Posto sada imam pristup svom serveru(tj nije bas moj, ali duga je to prica :) ). Da napomenem, recimo da mi je neki optimum da sajt radi normalno tako sto sam stavio 500 konekcija(mada cu verovatno morati vise) ka bazi u jednom trenutku. Dok je bilo na default podesavanjima(mislim da je oko 100 konekcija), ponestajalo je konekcija svakih par sekundi kad navale useri+botovi :)
[ bogdan.kecman @ 17.03.2009. 16:36 ] @
Citat: dusaSaLagera: Recimo ako imam tabelu friend(+s plus prefix pride :) ) sa kolonama friend_id1,friend_id2,...jos par kolona
Primarni kljuc mi je kompozitni friend_id1,friend_id2.
Dugo sam se dvoumio da li bi ikakvu korist dobio ako bih stavio kljuc i na friend_id1 jer se u where/joinima uglavnom ova kolona pojavljuje. Ako sam te dobro razumeo, moj pristup je ispravan, jel tako?
ne treba ti zaseban index na friend_id1 posto bi bio redundandan, samo bi usporavao insert/updata/delete a nista ne bi znacio pri select-u
Citat:
Takodje(ovako iz prve ruke da mi odgovoris ako mozes), u kolikoj meri je insert/update/select nad myISAM tabelama brze u odnosu na InnoDB engine?
sorry ali odgovor je ZAVISI :D
ako imas samo insert i nista vise, i to, bulk insert iz jednog treda ... myisam rulez :D brzi je ~3 puta od innodb-a
sve ostalo je "zavisi" ... myisam radi table lock a innodb radi row lock (u stvari page lock ali aj da ne idemo u crevca) sto znaci da teoretski 10 tredova mogu istovremeno da menjaju 10 razlicitih podataka ako koristis innodb a za myisam moraju jedan po jedan, posto myisam lepo zakljuca celu tabelu da bi dodao/promenio/obrisao jedan slog. tako da je u tom slucaju innodb brzi ..
za select .. zavisi .. select iz jedne tabele koja je dobro indexirana je nesto brzi sa myisam-om ali tu opet ima razlike kako je setovan server ... kada je join u pitanju sve zavisi ....
Citat:
Isto tako sam primetio da na vecini hostinga na kojima sam hostovao svoje web aplikacije InnoDB nije dobro podesen, pa se precesto desavalo pucanje(a uz to nisam znao tad za sve prednosti MySQLi - tipa automatski rollback transakcija i u slucaju pucanja skripte na nepredvidjenom delu - pre rollbacka...da napomenem - ako nije jasno, pricam o PHP) .
mnogi hosting provajderi su poceli da se bave hostingom sa par masina i pozajmljenim / ukradenim linkom.... stede na svemu, ponajvise na skupim/kvalitetnim inzenjerima tako da je u 99% slucajeva to problem ...
sa druge strane, ni mysql ni ostali open source db sistemi koje oni nude nisu bas optimizovani da ih koriste hosting provajderi ... mysql ne podrzava kvote po bazi tako da hosting provajderi idu i koriste trikove limitirajuci te sa kvotama na filesistemu (sto u slucaju povelike temp tabele ili prerastanja tvoje tabele zabada mysql jel mu filesistem uskrati dobrodoslicu - sto zabode CEO mysql a ne samo usera koji je napravio sr**e ...) ... neki pribegavaju skriptama koje "mere" velicinu pa ti zabodu usera kad ti baza predje kvotu i slicno ... isto tako ... ti ako na jednom serveru hostujes 10 baza, 1 user koji ima pristup jednoj bazi moze da "zauzme" ceo server ... tj da uzme sve resurse i da ostali useri mogu da pevaju ... sa prosecno nekoliko hiljada baza na hosting serveru to je prilicno veliki problem .... tako da hosting provajderi pribegavaju i tu trikovima i resetuju db server / zabadaju konekcije ako nesto "predugo traje" .. da ne spominjem opet da to uglavnom rade polupismeni ameri sa 2 nedelje kursa ili indijci koji su prepisivali na testu tako da je sve to u startu konfigurisano nogama :(
Citat:
Da li mi mozes dati neke inside informacije o cemu(kojim varijablama) da vodim racuna prilikom podesavanja mysql-a za InnoDB? Posto sada imam pristup svom serveru(tj nije bas moj, ali duga je to prica :) ). Da napomenem, recimo da mi je neki optimum da sajt radi normalno tako sto sam stavio 500 konekcija(mada cu verovatno morati vise) ka bazi u jednom trenutku. Dok je bilo na default podesavanjima(mislim da je oko 100 konekcija), ponestajalo je konekcija svakih par sekundi kad navale useri+botovi :)
:D :D :D
za botove imas da podesis u robots.txt koliko zelis da smaraju ... za ostala setovanja svog servera pogledaj temu namenjenu tome:
http://www.elitesecurity.org/t357167-Optimizacija-mySQL-servera
ili moj blog sa slicnim (malo drugacije organizovanim) informacijama: http://mysql.crsndoo.com/wp/2009/03/optimizacija-mysql-servera/
sto se php-a tice ... mysqli je mnogo bolji interface, ne znam koliko je stabilan ja ga licno nisam mnogo koristio (mozda 10tak malih projekata) ..
trebalo bi da je http://dev.mysql.com/downloads/connector/php-mysqlnd/ bolji od svih njih, ako ne "laksi" onda bar "Brzi" ali ja ga u zivotu nisam probao tako da .. tj http://dev.mysql.com/downloads/connector/php-mysqlnd/ je zamena za low level mysql drajver na php-u .. on bi trebalo da "poboljsa" rad sa mysqli-em .. ali .. "nikad probao" .. [ dusaSaLagera @ 17.03.2009. 17:23 ] @
Hvala ti na odgovorima, a svakako cu prouciti malo i ovo sto si mi dao na linkovima.
Jedino da te razjasnim sta sam mislio na botove :) : nisam mislio samo na google, yahoo i ostale search & other stuff botove, vec na one zlonarne skripte koje ne daju nikakve dodatne informacije(tj ponasaju se kao i obici neregistrovani useri), ali stalno pokusavaju da se registruju i loguju na sajtu, imaju 100000 zahteva u sekundi(ovo sam resio na neki nacin, mada opet ne najbolji jer imam database session storage) i trose i bandwith i resurse. Mada sve ovo nije ni bitno i skroz je offtopic :).
Hvala jos jednom, ako budem imao jos nesto da pitam(a imacu sigurno) - pitacu.
[ iizuzetan @ 20.03.2009. 09:30 ] @
A da pitam, da li je brža pretraga ili računanje ili donosenje nekih računskih ili bilo kakvih zaključaka direktno iz MySQL baze podataka ili u PHP-u? Na primer imam dve tabele sa podacima i isčitam cele obe tabele pa napravim u PHP-u algoritam koji ce da mi pretrazi, izracuna ili donese odredjene zaključke.... Ili je brže ako napravim MySQL algoritam koji će to uraditi a u PHP-u da mi vrati samo krajnji rezultat pretrage ili šta već, tih dveju tabela?
[ bogdan.kecman @ 20.03.2009. 12:01 ] @
Citat: iizuzetan: A da pitam, da li je brža pretraga ili računanje ili donosenje nekih računskih ili bilo kakvih zaključaka direktno iz MySQL baze podataka ili u PHP-u?
:D .. zavisi :)
ako se mysql vrti na quad xeonu a php na 486 brzi je mysql, ako se mysql vrti na 486 a php na quad xeonu brzi je php .. ako su na istoj masini - zavisi ....
Citat: Na primer imam dve tabele sa podacima i isčitam cele obe tabele pa napravim u PHP-u algoritam koji ce da mi pretrazi, izracuna ili donese odredjene zaključke.... Ili je brže ako napravim MySQL algoritam koji će to uraditi a u PHP-u da mi vrati samo krajnji rezultat pretrage ili šta već, tih dveju tabela?
vidi ovako, zamisli da su to dve "normalne" tabele sa po 2 miliona slogova ...
- iskopiras obe tabele u php
- napravis php skript koji ce da prodje kroz te podatke
- izracunas "rezultat"
kako to moze u bilo kom realnom slucaju da bude brze? Dakle to moze da bude brze samo ako su te dve tabele potpuno pogresno dizajnirane i taj upit napisan tako da mysql radi table scan ... pa cak i tada ce mysql nesto brze odraditi posao nego php...
uzmi primer .. imas tabelu od 1M slogova koja ima jedan integer. uradi "select avg(x) from t1;" iz mysql-a i povuci celu tabelu u php pa uradi u php-u avg ... onda izmeri vreme u prvom i vreme u drugom slucaju + izmeri koliko si memorije potrosio u prvom a koliko u drugom slucaju ... [ iizuzetan @ 20.03.2009. 12:35 ] @
Hvala na odgovoru. U principu shvatio sam odgovor, MySQL je "prva ruka" podataka a PHP "druga" pa je i logicno da je prva ruka brža jer "druga ruka" je malte ne dupliranje podataka i isčitavanje nepotrebnih. Samo da pojasnim naravno da je glupo i nisam mislio da treba izvlaciti sve podatke iz tabela pa praviti skriptu u PHP da bi se nesto naslo ako to "nesto" ima direktno ili indirektno iz par podataka iz baze. Mislio sam na neke podatke koje nemamo (skoro) direktno vec do kojih treba da se dodje recimo obradom mnogih podataka iz mnogih tabela a pritom pitanje je da li su i sve te tabele povezane (opisno na primer da bi to uradili preko baze MySQL upit treba da bude kilometarski :) ). Pitao sam jer nekako kako vreme odmice baze vise nisu baze podataka u izvornom smislu reci koje samo treba da omoguce brz pristup jednom podatku koji je trazen sa vise mesta u jednom trenutku vremena. Baze sve vise prerastaju u programe koji racunaju, uporedjuju idt koje je nekad radio samo program. Naravno ovo prosirenje funkcije baza je itekako opravdano ukoliko se bar 1% ubrzava donosenje krajnjeg rezultata. Nikad nisam radio u bazama koje imaju 1M slogova pa zato i pitam sta je brze jer ti imas iskustva. A glupo je išta testirati i meriti "prolazna vremena" vezano za stvari iz mog pitanja na MySQL bazi koja ima desetak ili sotinak tabela sa po desetak kolona. Na kraju krajeva ako se vec stvar krece u tom smeru da baze sve vise preuzimaju funkcije PHP programa ili bilo kog drugog onda je logicno da se integrisu PHP i MySQL u jednu celovitu, na primer nazovimo to "MyPHPSQL" programsku platformu, ili na primer PHP+BAZA, ili samo PHPB, ili MySQLPHP sve u zavisnosti da li PHP programeri ili MySQL programeri prvi naprave integraciju . Sto opet dolazimo do moje teorije da sve je jedinstveno po principu COMMODORE64 i da se vratimo Nemackom shvatanju filozofije računara a ne Američkom profitabilnom windows shvatanju i filozofiji!! Na primer RAM memorija i HARD, u buducnosti ce samo biti RAM jer je glupo imati sporu memoriju kad vec postoji brza tehnologija, kao i glupo je imati baze ako vec imamo programe itd da ne sirim temu, ili glupo je imati bazu ako vec imamo "inteligentne" procesor memorije u NASA-i i pentagonu. Ali naravno za nas OVCE od obicnih ljudi sve mora po Americkoj filozofiji da se "isecka" u male "porcije" kako bi se sto vise "isisao" novac i profit.
[Ovu poruku je menjao iizuzetan dana 20.03.2009. u 13:56 GMT+1]
[Ovu poruku je menjao iizuzetan dana 20.03.2009. u 13:58 GMT+1]
[Ovu poruku je menjao iizuzetan dana 20.03.2009. u 14:01 GMT+1]
[Ovu poruku je menjao iizuzetan dana 20.03.2009. u 14:05 GMT+1]
[Ovu poruku je menjao iizuzetan dana 20.03.2009. u 14:12 GMT+1]
[Ovu poruku je menjao iizuzetan dana 20.03.2009. u 14:14 GMT+1]
[Ovu poruku je menjao iizuzetan dana 20.03.2009. u 14:17 GMT+1]
[ bogdan.kecman @ 20.03.2009. 13:28 ] @
Citat: MySQL je "prva ruka" podataka a PHP "druga" pa je i logicno da je prva ruka brža jer "druga ruka" je malte ne dupliranje podataka i isčitavanje nepotrebnih.
to je ok analogija, obrati paznju da nije samo pitanje o iscitavanju nepotrebnih podataka ... neke stvari mysql moze da izvuce direktno iz indexa bez pipanja tabele, neke stvari moze da izvuce na "specifican nacin", na primer ima storage engine koji ti u 1 koraku vraca bilo koji sum, avg, max, min podatak za bilo koji numeric iz tabele ... i slicno .. tako da, one podatke koje moze mysql da vrati, treba mysql da vrati, nista ti neces (pogotovo ne u php-u koji je interpreter) brze odraditi matematiku nego sto ce to odraditi mysql koji u pomoc moze da koristi i indexe, da cita samo potrebna polja i slicno.
Citat:
Samo da pojasnim naravno da je glupo
pored onog "there is no silver bullet", ja volim da kazem i da "nema glupih pitanja / glupih resenja" ... resenje moze da bude manje ili vise optimalno, ako radi - resenje je i nije glupo .. a da moze bolje - uvek moze bolje ..
teoretski, nekada se nad podacima mora izvrsiti malo kompleksniji zahtev. tada mozemo deo podataka baciti klijentu da ih obradi, ili, napisati "stored procedure" koja ce to odraditi ... ne bih sada ulazio u detalje posto je tema vezana za modeliranje baze podataka a ne za programiranje ...
Citat: Pitao sam jer nekako kako vreme odmice baze vise nisu baze podataka u izvornom smislu reci koje samo treba da omoguce brz pristup jednom podatku koji je trazen sa vise mesta u jednom trenutku vremena
tu se necemo sloziti ... RDBMS je to, uvek je bio to i uvek ce biti to ... ono na sta treba obratiti paznju je da jedan "program" ne mora da ima samo jednu funkciju .. kao sto masina xyz moze i da pere i da susi ves a masina zzy moze samo da pere .. to ne znaci da sada pranje vesa postaje i susenje ... vec da masina moze i jedno i drugo ...
MySQL je RDBMS, ne pretenduje da radi nista drugo, nema u planu da u skorije vreme radi bilo sta drugo i ni u jednom trenutku nije zamisljen da radi ista drugo ... Ako pogledamo neki drugi sistem, na primer Oracle, on jeste pored toga sto je RDBMS i mnogo sta drugog .. MySQL je zamisljen kao deo nekog sistema koji je AS (isto kao i M$ SQL, DB2 i mnogi drugi), dok na primer Oracle pretenduje (od starta) da "bude sistem" da bude full platforma koja vrti celu aplikaciju... mislim .. oracle ima svoj web server ... sta dalje pricati .. RDBMS je samo jedan deo onoga sto Oracle moze ... (necemo sada ulaziti u to koliko one druge stvari dobro radi, niti je ovo mesto da pricamo o oraklu)
Citat: Nikad nisam radio u bazama koje imaju 1M slogova
ne znam sta da ti kazem, 1M slogova je mala baza .. obican log / statistika za 3 bloga imaju nekoliko tabela sa vise od 1M slogova .. to su tabele po 10-20MB .. to uopste nije veliko .. velike tabele su preko 1G, ogromne su oko 1T a one vece su i dalje "veeeeeeeeeeeeeeelike" :D
Citat: onda je logicno da se integrisu PHP i MySQL u jednu celovitu, na primer nazovimo to "MyPHPSQL" programsku platformu, ili na primer PHP+BAZA, ili samo PHPB, ili MySQLPHP sve u zavisnosti da li PHP programeri ili MySQL programeri prvi naprave integraciju
nisam bas preterano "Stalozen" da bi mogao ovo da prokomentarisem bez da ... - ovo je klasican sto x a ne y ... prvo .. zasto php a ne java ili c ili dot nemoj ili paskal ili rubi ili ... ne mislim da se php bilo cime istice u odnosu na bilo koji od ovih ... (nemoj me pogresno svatiti ja imam mnogo vise iskustva sa php-om nego sa javom i rubijem, mnoooogo vise nego sa dot nemoj ... ali .. nista php nije bolji od asp-a) ... no .. onda treba da integrisemo i web server? sto apache a ne websphere ili neki peti ? ...
MySQL je RDBMS, i on je deo jednog sistema (LAMP / SAMP / WAMP su najpopularniji ali nisu jedini) te niti postoji ikakav realan razlog - niti postoji bilo kakva pretenzija da mysql postane sistem per se. Uvek je bolje raditi jednu stvar da valja nego tri polovicno ... posebno sto nikakav benefit niko ne bi imao od toga .. [ bantu @ 20.03.2009. 14:12 ] @
@iizuzetan: Al' ga sada otjera u neku tešku filozofiju.
Ja lično preferiram javu i mislim da kada bi se i desilo to o čemu pričaš ta integracija PHP MySQL da bi MySQL izgubio čitav jedan community programera. Ovako je bolje imaš slobodu da si izabereš platformu kako ti odgovara i bog te vido, RDBMS koji hoćeš, app server koji hoćeš i uživaj.
Ali mislim da se polako udaljavamo od teme. :)
[ balavi @ 10.04.2009. 08:54 ] @
Odlican text Bogdane, lepo objasnjena normalizacija, napokon je sad skontah!
[ Miroslav Ćurčić @ 10.04.2009. 12:08 ] @
Pre nekih 4 godine sam testirao brzine baš zbog ovakvih pitanja i došao do zaključaka:
vreme potrebno za izvršavanje jednog prostog upita (jednostavan SELECT) je isto kao i za stotinak naknadnih dovlačenja rezultata (fetch), pa je kod malih tabela (do 50kb) praktično isto hoćeš li čitati jedan red ili celu tabelu, tako da kad sam siguran da će mi bar nešto trebati iz tabele ja je pročitam celu u bafer pa kasnije kako šta zatreba vadim iz bafera
isto tako, kad bi istu tu malu tabelu umesto u mysql-u držao u običnoj lokalnoj datoteci i čitao je sa fread(), potrebno vreme je skoro 100 puta kraće
Test je bio na localhost wamp okruženju na 900mhz.
Posledica testa, tamo gde mi ne treba neka napredna pretraga ili join-ivanje (razne konfiguracione tabele npr.) držim u lokalnoj datoteci.
[ bogdan.kecman @ 10.04.2009. 12:24 ] @
Citat: vreme potrebno za izvršavanje jednog prostog upita (jednostavan SELECT) je isto kao i za stotinak naknadnih dovlačenja rezultata (fetch), pa je kod malih tabela (do 50kb) praktično isto hoćeš li čitati jedan red ili celu tabelu, tako da kad sam siguran da će mi bar nešto trebati iz tabele ja je pročitam celu u bafer pa kasnije kako šta zatreba vadim iz bafera
isto tako, kad bi istu tu malu tabelu umesto u mysql-u držao u običnoj lokalnoj datoteci i čitao je sa fread(), potrebno vreme je skoro 100 puta kraće
Posledica testa, tamo gde mi ne treba neka napredna pretraga ili join-ivanje (razne konfiguracione tabele npr.) držim u lokalnoj datoteci.
1. svaki db server danas (ukljucujuci mysql) kesira podatke tako da ce ta tvoja tabela od 50k biti u ramu sve vreme ako je sve podeseno kako treba
2. mysql dodatno ima query_cache koji moze da se upotrebi
3. svaki iole normalan db server (ukljucujuci mysql) ima podrsku za memory tabele - tako da to uvek mozes da koristis kada je potrebno
varijantu da ti se 90% podataka nalazi u bazi a 10% po fajlovima na disku - to je dizajn koji ne zelim uopste da komentarisem
par cinjenica
- tabela sa manje od 100 redova slabo moze da iskoristi prednost indexa .. nju svejedno rdbms drzi u ramu i izbacuje iz istog samo kad mora
- ako vam upit vraca vise od 50% rezultata iz jedne tabele, index u toj tabeli nema preterano bitan uticaj na performanse - caj stavise - mozda usporava celu pricu
- kesiranje je jedan od osnovnih nacina za povecanje performansi... mysql sa "default" setovanjem ne uzima dovoljno ram-a za kesiranje .. pisano je vec o tome kako konfigurisati mysql server tako da necu sad da se ponavljam
- kesiranje ne podrazumeva samo kesiranje na bazi, postoji kesiranje u aplikaciji kao i kesiranje izmedju aplikacije i baze .. vise o tome neki drugi put (bas spremam neki txt na tu temu)
- normallizacija je bitna ali ne znaci uvek ubrzanje, potrebno je znati i neke interne stvari o serveru sa kojim radite da bi pravilno optimizovali bazu... na primer, spominjao sam da mysql u jednom upitu moze da koristi max 3 indexa... ima jos mnogo slicnih ogranicenja i za ovaj rdbms i za sve druge ..
- ne optimizuje se isto baza sa pata, sata ili san storage subsistemom ...
- ne optimizuje se isto baza koja ima odnos upit:upis 1000:1 i baza koja ima 2:1 ili 1:1 ili 1:50
etc etc etc ... [ Miroslav Ćurčić @ 10.04.2009. 16:55 ] @
Ok, ubedio si me, odvojiću malo vremena i ponoviti testove u novim uslovima, i ovde podeliti izmereno.
[ bogdan.kecman @ 10.04.2009. 17:15 ] @
nemam potrebu da te ubedjujem ni u sta ... jos ce brze da bude ako hardkodiras tih 50 redova tabele u source umesto da drzis u lokalnom text fajlu ... poenta je da je to losa arhitektura aplikacije ... uvek ce biti brze da procitas lokalni fajl nego da procitas taj isti fajl kroz mrezu .. kao sto rekoh - to je vezano za arhitekturu
[ kubur @ 13.04.2009. 14:55 ] @
Veoma pohvalno objasnjenje prve tri normalne forme, stoga bih zamolio Bogdana, naravno ako je u mogucnosti s vremenom, da takodje ukratko objasni i ostale normalne forme kroz primercic!
Hvala u svakom slucaju!
Copyright (C) 2001-2026 by www.elitesecurity.org. All rights reserved.
|