|
|
[ SpizaGenije @ 11.02.2014. 14:08 ] @
|
| Pozdrav ljudi dobre volje...
Prvo, MySQL ver. 5.6, engine InnoDB, collation UTF8_unicode_ci
Baza je pravljena za potrebe biblioteke.
Sada, ranija aplikacija koja se vrtila, je pravljena u Delfiju i kačila se na jednu od dve(?!) baze, u zavisnosti jel' pretraga ćiriličnih ili latiničnih naslova! No dobro, da ne ulazim u to šta je bilo, dovoljno sam se napatio dok sam sve to sjedinio i izbacio nepotrebne kolone i dodao potrebne tabele.
U zavisnosti od toga kojim pismom je štampana knjiga, u bazi je taj naslov tako i ubačen - tipa 'Branko Ćopić - Magareće godine', 'Branko Ćopić - Magareće godine''...
Elem, radim join tabelâ 'tbl_autor' i 'tbl_naslov', te FULLTEXT search na kolone 'autor', 'naslov' i 'inv_br'
Problem mi je sledeći:
Kako da ja, tražeći po uslovu 'branko ćopić magareće', dobijem i ćirilični i latinični zapis?
Za sada dobijam rezultat tipa:
Branko Ćopić - Magareće godine;
Branko Ćopić - Prolom
Branko Radičević - Pesme I
...
Trenutno, moram da menjam tastaturu na latiničnu, ili ćiriličnu, da bih dobio jedan, ili drugi rezultat...
Hvala unapred!
|
[ bogdan.kecman @ 11.02.2014. 14:23 ] @
pogledaj kolacije kod mene na mysql.rs tamo imas primer kolacije koja jednaci cirilicu i latinicu pri pretrazi, nisam probao sa full tekst-om ali bi trebalo da radi jedino bi morao da rebildujes ft indexe kada dodas kolaciju (i da postavis tu kolaciju kao default na ta polja), ta kolacija koju sam ja pravio nije "po pravilima srpskog pravopisa" ali je tacno ono sto ti treba u 99% slucajeva a to je da kad trasis "sacuvaj" on ti nadje i sačuvaj i sacuvaj i saćuvaj i "sačuvaj ćirilicom" (es ne pušta ćirilicu pa ..), po srpskom pravopisu c i č i ć se ne jednace ali obzirom na to da su decenijama podaci unoseni osisanom latinicom pored ostalih kombinacija to je neophodna kolacija za normalnu pretragu .. kako za sajtove tako i za biblioteku
[ SpizaGenije @ 11.02.2014. 14:41 ] @
Pregledao ovaj tekst pre par dana, doduše nisam implementirao u praksi.
Iskreno, mislio sam da si tu samo izjednačio dj sa đ, dž sa dz i slično... (ka'ce ne razumem)
Evo pokušam, pa se nadam 'će proguli' i sa full tekstom...
Hvala Bogdane
Citat: U zavisnosti od toga kojim pismom je štampana knjiga, u bazi je taj naslov tako i ubačen - tipa 'Branko Ćopić - Magareće godine', 'Branko Ćopić - Magareće godine''...
Sada i ja skontah da mi ES ne pusti poslednjeg Branka Ćopića - ćirilicom! :D [ bogdan.kecman @ 11.02.2014. 15:03 ] @
nisam probao FT bar 5 godina tako da ne mogu da tvrdim da sa njim rade
kolacije kako treba (ne vidim razlog sto ne bi ali sve je moguce no ja
izbegavam da koristim mysql-ov full text search te ako mi je potrebna
takva pretraga koristim ili neki svoj full tekst implementiran sa
mysql-om ili koristim externe varijante tipa lucene ili sphynx, e sad
navodno sa innodb-om je FT dosta bolji nego onaj stari ali nisam probao,
na mccge-u nema ft-a tako da..), elem bas taj primer prvi (sa 5.1 i 5.5)
ne moze da jednaci dj sa đ i slicno zato sto 5.5 i pre ne podrzavaju te
dual karakter kolacije .. e sad of 5.6 valjda to radi ali iskreno nisam
nikad probao, tamo postoji hrvatska kolacija koja valjano hendla
dvokarakterna slova tako da bi se od hrvatske dala nabudziti srpska ko
ima vremena da se sa tim zeza
[ SpizaGenije @ 11.02.2014. 15:23 ] @
Citat: ...tamo postoji hrvatska kolacija koja valjano hendla
dvokarakterna slova tako da bi se od hrvatske dala nabudziti srpska ko
ima vremena da se sa tim zeza
Evo, imam ja vremena, ali ne znam! :p
Elem, čim dođem kući, ima d'isprobam to što si načuk'o, pa javljam ovde.
Ukoliko bude bilo nekih problema, sugerišem pa Citat: ko ima vremena da se sa tim zeza a zna, neka ovde ostavi neki legacy za nas obične smrtnike! :D
EDIT:
Citat: koristim ili neki svoj full tekst implementiran sa
mysql-om
Može primer?
Bio bih jako zahvalan.
Možda pruža više, a možda nešto i naučim onako usput... [ bogdan.kecman @ 11.02.2014. 15:46 ] @
pogledaj obavezno i komentare tamo u tom postu ima korisnih informacija
... ja jednom kad uvatim par h slobodno nacukacu srbistansku kolaciju za
5.6 i 5.7 sa uputstvom ali ... nesto mi se javlja da to jos 3-4 meseca
nema sanse
[ SpizaGenije @ 11.02.2014. 16:14 ] @
Znači, otprilike ovako (ako ne proguli sada):
Tete, ako vas mrzi da se svičujete sa lat. na cyr tastaturu za pretrage, moraćete se strpite dok Bogdan ne odradi pos'o! Cirka tri meseca... :)
Bogdane, čekam(o) tete i ja edit srpske kolacije - nestrpljivo! :)
[ bogdan.kecman @ 11.02.2014. 16:18 ] @
pa bolje da ti recimo zagrejes stolicu pa krenes to da napravis i onda
ako zabodes negde kukas pa mi probamo da pomognemo :D
[ SpizaGenije @ 11.02.2014. 16:22 ] @
Iskreno, ja ovde nemam pojma ni u šta gledam! :D
Ali, evo probam, pa se javim... [ bogdan.kecman @ 11.02.2014. 16:32 ] @
trebaju ti neke osnove oko xml formatiranja ali generalno ispratis tekst
na 5.5 mysql-u pa onda kada ti to proradi posle mozes da probas sam da
uradis to isto na 5.6 ili 5.7
1. mysql> show variables like 'character_sets_dir';
ovde vidis gde ti se nalaze fajlovi koji te zanimaju
2. odes tamo i krenes da editujes fajl Index.xml (napravis prvi bekap
negde :D )
prodjes kroz fajl vidis ima collation name = nesto, collation name nesto drugo ... i kao sto postoje sve te kolacije u tom fajlu ti dodas
jos jednu
...
i prepises copy/paste to sa bloga u tvoj Index.xml
3. snimis
4. restart mysql servera
5. mysql> show collation;
i vidis dal ti se pojavila tvoja nova kolacija
ako nije vrati se nazad vidsi sta si zabrljao, ako jeste sada probaj da
radis sa njom, kad vidis da radi onda je promenis malo (menjas xml fajl
i resetujes mysql server)
Code:
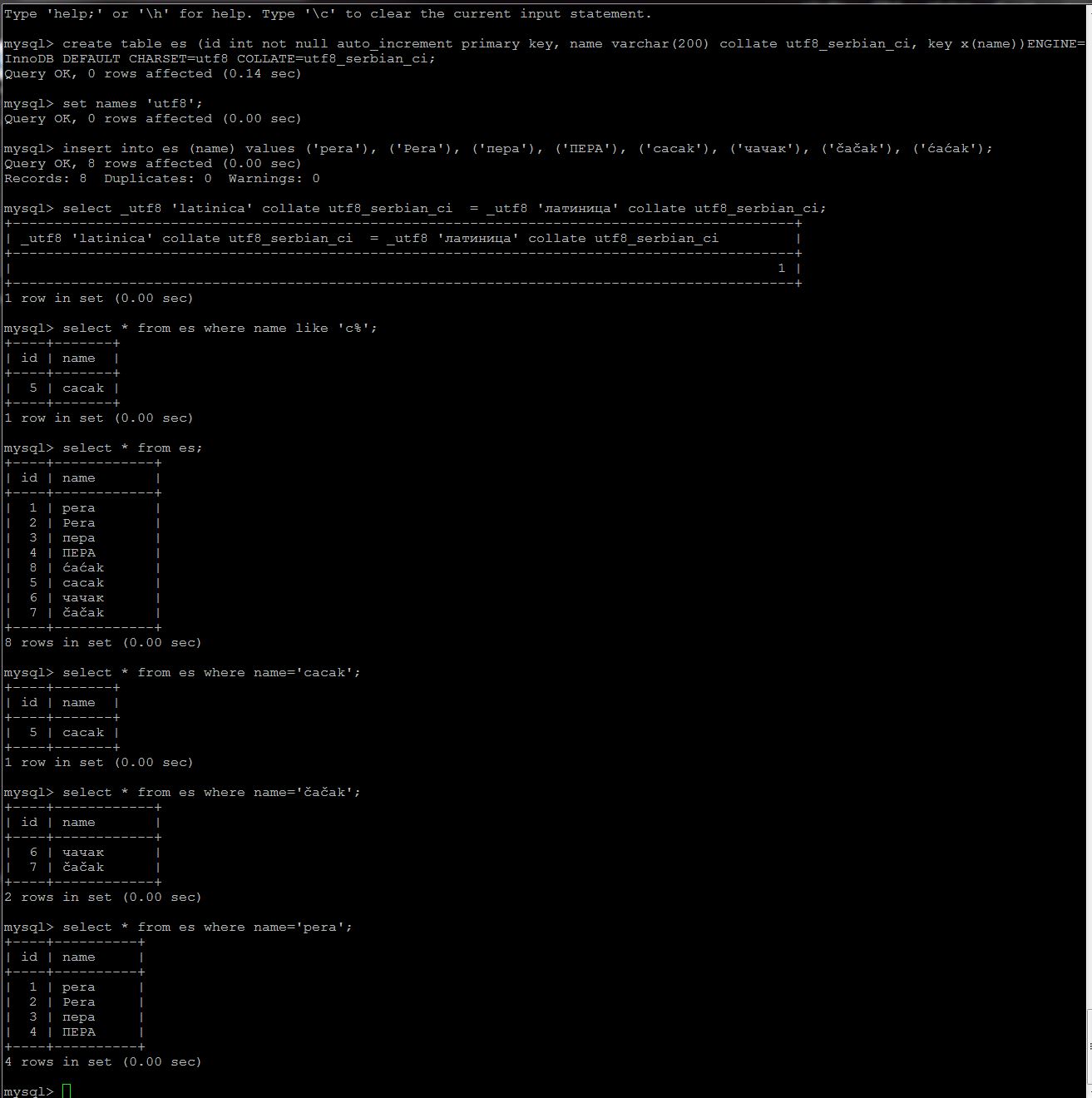
mysql> select 'latinica' = 'latinica';
+---------------------------------+
| 'latinica' = 'latinica' |
+---------------------------------+
| 0 |
+---------------------------------+
1 row in set (0.00 sec)
mysql> select _utf8 'latinica' collate utf8_serbian_ci = _utf8 'latinica' collate utf8_serbian_ci;
+----------------------------------------------------------------------------------------------+
| _utf8 'latinica' collate utf8_serbian_ci = _utf8 'latinica' collate utf8_serbian_ci |
+----------------------------------------------------------------------------------------------+
| 1 |
+----------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
[ bogdan.kecman @ 11.02.2014. 16:34 ] @
hm ovo drugo "latinica" u oba slucaja je napisano cirilicnim slovima, jbg ova ES-ova forsirana transliteracija na latinicu stvarno nekad mega smara :(
 [ SpizaGenije @ 11.02.2014. 17:44 ] @
Mrka kapa...
Doš'o kući, na brzinu ispravio .xml, progulio svaki upit i dobio isti rezultat kao i ti u postu iznad... kreirao novu DB i jednu tabelu sa 4 reda podataka... sve prošlo, ali pretragu opet radi ili ćirilicu, ili latinicu...
Code:
CREATE DATABASE IF NOT EXISTS `new_schema` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_serbian_ci */;
USE `new_schema`;
-- MySQL dump 10.13 Distrib 5.6.13, for Win32 (x86)
--
-- Host: localhost Database: new_schema
-- ------------------------------------------------------
-- Server version 5.6.15-log
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8 */;
/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */;
/*!40103 SET TIME_ZONE='+00:00' */;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
--
-- Table structure for table `new_table`
--
DROP TABLE IF EXISTS `new_table`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `new_table` (
`idnew_table` int(11) NOT NULL AUTO_INCREMENT,
`ss` varchar(45) COLLATE utf8_serbian_ci DEFAULT NULL,
PRIMARY KEY (`idnew_table`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COLLATE=utf8_serbian_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `new_table`
--
LOCK TABLES `new_table` WRITE;
/*!40000 ALTER TABLE `new_table` DISABLE KEYS */;
INSERT INTO `new_table` VALUES (1,'dejan'),(2,'dragan'),(3,'dejan'),(4,'dragan');
/*!40000 ALTER TABLE `new_table` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
-- Dump completed on 2014-02-11 18:34:43
prve dve latinične, druge dve ćirilične vrednosti: Citat: INSERT INTO `new_table` VALUES (1,'dejan'),(2,'dragan'),(3,'dejan'),(4,'dragan'); [ bogdan.kecman @ 11.02.2014. 17:49 ] @
i kad uradis "select * from new_table where ss='dragan';" dobijes samo jedan rezultat?
[ SpizaGenije @ 11.02.2014. 17:55 ] @
Upravo tako... :P
Po svemu sudeći, izgleda da mi ni fulltext neće raditi! :D
[ bogdan.kecman @ 11.02.2014. 18:01 ] @
evo upravo reinstaliram neku masinu sa 5.5 pa cu bas da probam :)
[ bogdan.kecman @ 11.02.2014. 18:31 ] @
sa mog bloga, prvi onaj listing za kolaciju radi, jedino moras da smanjis ID sa 1200 na 250 (pazi da nemas vec neku kolaciju sa tim id-om) ali radi tako sto jednaci cirilicu i latinicu ali C i Č i Ć nisu isti!!! ali su zato latinično i ćirilično Č jednaki.
ona druga kolacija koja je data kao primer jednači C Ć i Č ali ne jednači ćirilicu i latinicu, dakle treba da se napravi treca koja bi bila kombinacija te dve :D
evo zakacicu slicku i index.xml fajl
 [ bogdan.kecman @ 11.02.2014. 18:40 ] @
dakle sad mozes da se igras da nateras da radi ono sto bi ti hteo ... samo lagano :D
[ SpizaGenije @ 11.02.2014. 19:03 ] @
Ako... valjda prođe i na 5.6 ako je progulio kod tebe na 5.5 :)
Indeks sam već smanjio na 450, ali ću ga zakucati na 250, pa šta mu bude...
Moraću se kasnije poigrati sa tim... taj mi miks mi zahteva značajno naprezanje moždanih vijuga (posle 13h rada)...
Javljam večeras ako završim, ili negde zapnem.
Hvala ti Bogdane na strpljenju i pomoći
[ bogdan.kecman @ 11.02.2014. 19:32 ] @
nema na cemu, taman se i ja malo podsetim ovog "zemaljskog" mysql-a :D
ima sa id-om neka fora, na 5.1 je valjda morao da bude izmedju 100 i 128
recimo, na 5.5 je u startu trebao da bude preko 1000 pa se to onda
promenilo (vidis da sam ja tu terao ma 5.5.m3 1200 id a to sam npr na
novom 5.5 nece da prodje mora da se smanji, ja smanjio prvo na 240 i ono
nije radilo kako terba zato sto vec ima neka kolacija sa 240 pa sam
proverio nema 250 kod mene pa stavio da to bude 250 ) .. no kao sto
rekoh slabo stizem to da pratim, sad smaram kolege da mi neko da crash
course za 5.7 sta je novo i kako sta radi i sta se promenilo .. zastareh
:D ..
[ SpizaGenije @ 11.02.2014. 20:06 ] @
Aha... aman da mi proguli onaj prvi .xml :D
Ako ovo bude radilo kako treba (još proveravam), trebao bih od ova tvoja dva skrpti jedan, pa kačam ovde, nek' se narod služi! :)
Elem, nemoj mi se udaljavati od ES, imam zajeban osećaj da ćeš mi trebati još koji put u narednih par sati! ;)
[ peromalosutra @ 11.02.2014. 21:23 ] @
Ako ti šta pomogne, bila je slična tema ranije, mada je Bogdan strpljivo ponovio većinu priče :)
http://www.elitesecurity.org/t469412-0#3351313[ bogdan.kecman @ 11.02.2014. 21:30 ] @
sto se ne javi ranije ja sam skroz zaboravio na to :D
jel to tebi na kraju proradilo ?
[ peromalosutra @ 11.02.2014. 22:17 ] @
Jeste, pretražuje ok tj. izbacuje i ćirilične i latinične rezultate, osim što ne radi jednačenje između č,ć i c, što u suštini i nije greška, ali ljudi ukucaju "andric" i očekuju da im izbaci "andrić".. Takođe, sortiranje sada sortira prema azbuci, što je ok ali većina rezultata u sistemu je na latinici, pa to izgleda malo nespretno. :)
Sistem je još u razvoju, rješavao sam neke urgentnije stvari, ovih dana ću se još malo pozabaviti sa tim da dotjeram tu kolaciju onako kako mi paše pa ako još bude aktivna tema postovaću ovdje. Dakle treba mi da sortira po latinici, da jednači č, ć, c, kao i njihove ćirilične ekvivalente. E sad, to će stvoriti možda novih problema (jer c treba da se jednači sa č i ć, ali č i ć između sebe treba da se razlikuju, npr kad tražim kuće ne treba da mi izbacuje i kuče). xD
Pretpostavljam da treba da se poigram malo sa onim xmlom i da bi se dalo uraditi nešto takvo, u svakom slučaju čini mi se da ću morati napraviti neke kompromise. Sad mi je jasno zašto ES konvertuje sve u latinicu.
[ bogdan.kecman @ 11.02.2014. 22:23 ] @
ne znam da li je moguce da c jednači sa č i c jednači sa ć ali č ne
jednači sa ć .. možda jeste no ne znam.
za sortiranje po latinici moras da uradis drugacije xml inače ćeš imati
previše posla, umesto da resetujes ćirilicu i dodaješ na nju pravila ti
resetujes latinicu i na latinicu dodaješ pravila tako dobiješ da ti
ostaje sort po latinici a ćirilica ti je "isto što i latinica" umesto
kako je u ovom xml-u koji sam ja pravio da je latinica isto što i ćirilica
[ SpizaGenije @ 12.02.2014. 08:22 ] @
Jok!
Sinoć sam se na blic obradovao da je progulio, međutim - moša!
Definitivno ove izmene u index.xml ne rade na ver. 5.6.
Elem, digao sam 5.5 na drugu mašinu... meni svejedno da li se kačim na '127.0.0.1' ili na '192.168...', a tetama će biti em drago, em milo što ne moraju da se svičuju sa ćirilične na latiničnu tastaturu i obratno... uostalom, ako je biblioteka sve ove godine izdržala na "onome", izdržaće i na 5.5 serveru.
S obzirom da sam poprilično 'noob' u odnosu na neke ljude na ovom forumu, priznajem da ne znam prilagoditi taj .xml na 5.6 i 5.7, pa ću prekrštenih ruku čekati gotovo rešenje... :D
Što se tiče sortiranja prema azbuci, za sada mi odgovara, jer je većina naslova ćirilična, naravno za razliku od većine slučajeva gde je latinično sortiranje prihvatljivija opcija.
Nego, primetio sam da kada uradim alter nad tabelom (nekom testnom) sa par redova zapisa, da mi ćirilicu konvertuje na latinicu. Mislim da bi se to moglo rešiti tako što ću napraviti novu bazu sa novom kolacijom, pa samo iz bekap fajla povući insert upite za svaku tabelu ponaosob. Valjda proguli. Ipak mi je to par desetina hiljada redova podataka, pa ne bih želeo da se bavim prekuckavanjem. :)
Nego, kada sam se već dotakao bekapa, pa da ne otvaram novu temu:
Perkonin xtrabackup? Meni radi posao, pa samo da čujem dva - tri mišljenja?
Citat: pa ako još bude aktivna tema postovaću ovdje
Pero, nadam se da će biti aktivna. Ja gotovanski očekujem i update za 5.6! ;) [ bogdan.kecman @ 12.02.2014. 09:43 ] @
Da li ti radi to na 5.5 ?
nisam te skontao za ovaj alter, pojasni?
bekap - meb je ubedljivo najbolje resenje, xtrabackup je takodje
odlican, jednom nedeljno uradi i mysqldump, vrlo je zgodno imati i
logicki a ne samo binarni bekap.. obavezno upalis binary log ... za
ozbiljniju pricu oko bekapa napravis posebnu temu (posto za bekap nije
mnogo bitno dal je cirilica ili latinica)
[ SpizaGenije @ 12.02.2014. 09:51 ] @
Sinoć na brzaka dignem 5.5 na drugoj mašini i importujem onaj tvoj .xml koji si okačio u nekom od prethodnih postova...
Proradilo je, s tim što će mi (recimo) uz uslov "LIKE '%Magareće%'" pronaći i ćirilični i latinični zapis, a uz uslov 'Magarece' ih ne pronađe...
Koliko sam razumeo Peru i tebe, samo moram da izjednačim c, ć, č (i latinične i ćirlične) i radiće mi posao bez problema...
A što se tiče altera, ili sam ja bio previše umoran, ili mi je onaj moj "Dejan, Dragan" (oba pisma) primer, konvertovao ćirilični zapis u latinični?!
Za bekap sam postavio pitanje, a sada razmišljam i o temi! ;)
[ bogdan.kecman @ 12.02.2014. 09:57 ] @
za alter probaj ponovo mozda si cp sa foruma gde je ES prebacio sve u
latinicu :D
za 5.5 jeste treba da se doda to jednacenje, probaj sam ne bi trebalo da
je problem (mada ..)
za bekap, to je dobra tema, proveri samo da li mozda slicna vec postoji
[ SpizaGenije @ 12.02.2014. 10:07 ] @
- verovatno je u pitanju c/p altera sa ES! Više se i ne sećam svega, bilo je mnogo rano ujutro...
- što se tiče jednačenja, nisam ni pokušavao, ali verujem da je ovako nešto:
Code:
<reset>\u040B</reset>
<i>\u0106</i>
<i>\u0107</i>
<i>\c</i>
Nemam gde da probam, na poslu mi 5.6, ali mislim da sam ub'o! ;)
- pitanje: koliko će mi ovo igranje uticati na performanse (brzinu pretrage i sl.)
Mislim da neće biti problem kod par hiljada, ili par stotina hiljada zapisâ, ali kada pričamo o milionima - recimo? [ bogdan.kecman @ 12.02.2014. 10:17 ] @
kolacija ko svaka druga nece uticati na brzinu
[ pirrat @ 28.02.2014. 08:45 ] @
Postgresql ima ugrađen FTS koji omogućava definisanje unaccent pravila. Jednostavno se mapiraju ćirilična slova u latinična, kao i šćčđždž u sccdjzdz ako je potrebno. Potrebno je samo ista pravila koristiti i pri formiranju vektora pretrage i pri formiraju upita i nije bitno da li korisnik koji pretražuje unosi ćirilicu ili latinicu. Ne znam da li postoji takva opcija u MySql.
[ bogdan.kecman @ 28.02.2014. 09:28 ] @
jok, tj jok na taj nacin, na mysql-u se to radi kroz kolacije
Copyright (C) 2001-2026 by www.elitesecurity.org. All rights reserved.
|