[ loto17 @ 28.07.2014. 09:55 ] @
| Da li postoji neki program koji ce ispravno konvertovati PDF fajl ( koji sadrzi gomilu matematickih formula) u Word 2007/2010? |
|
[ loto17 @ 28.07.2014. 09:55 ] @
[ Miroslav Jeftić @ 28.07.2014. 10:03 ] @
Možeš probati sa Abbyy FineReader-om ili Nuance Omnipage-om, ali kod komplikovanih pdf-ova rezultati mogu da budu šareni, od prilično dobrih do neupotrebljivih.
[ Lavlja_Jazbina @ 28.07.2014. 10:10 ] @
Probaj sa acrobatom (puna verzija) i OCR pretvoris u tekst i takav kopiras u Word bez konvertovanja.
[ anon142305 @ 28.07.2014. 10:16 ] @
Nisam petljao sa programima, ali jesam sa on-line resenjima i meni se najbolje pokazao ovaj:
http://convertonlinefree.com/PDFToWORDEN.aspx Ali posto ti je PDF komplikovan, kao sto kaze Miroslav, ne ocekuj cuda. [ Jpeca @ 28.07.2014. 10:34 ] @
Word verzija 2013 meni vrlo korektno otvara i konvetuje PDF fajlove, bez potrebe za nekom drugom aplikacijom. Naravno, uslov je da je PDF fajl "pravi", da nije slučaj da su stranice ubačene u PDF kao slike. U tom slučjau treba ti neki OCR kako je naveo Miroslav Jeftić.
Evo blic provera. U prilogu je PDF sa nekim slajdovima koji sadrže tabele, slike ... Otvoreno pomoću Worda i snimljeno bez ikakve moje intervencije [ loto17 @ 28.07.2014. 11:31 ] @
Hvala svima na odgovorima!
Ipak nisam uspeo... U prilogu saljem fajl koji neuspesno pokusavam da konvertujem [ anon142305 @ 28.07.2014. 11:37 ] @
Ako nemas mnogo stranica, ako je ovo ceo dokumet, najjednostavnije bi bilo da
svaku stranicu sa Print Screen ubacis u neki program za slike, iseces viskove (crop), pa odatle u Word. [ loto17 @ 28.07.2014. 11:41 ] @
@ IUOP_1
Nije to resenje :( [ anon142305 @ 28.07.2014. 12:05 ] @
Jesi li siguran sta tacno hoces da uradis?
Sad sam ovaj tvoj dokument prebacio u Word, trajalo je 1 min. U Adobe Acrobat Pro postoji opcija da svaku stranicu pretvori u sliku, pa ih onda rucno ubacujes u Word.  Zar mislis da bi ti kovertovanje dalo brzi i bolji rezultat?? [ anon142305 @ 28.07.2014. 12:20 ] @
Zaboravio sam da okacim kako izgleda u Wordu.
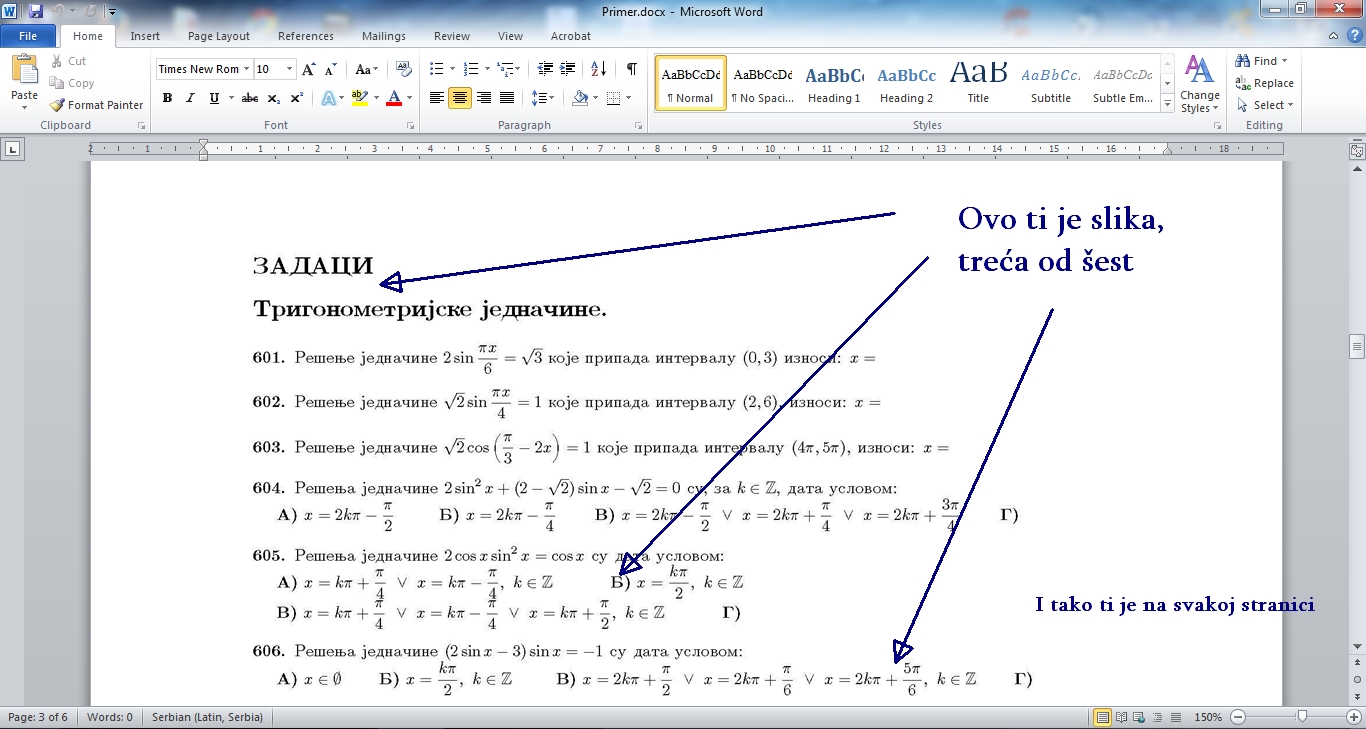 [ Hackman @ 28.07.2014. 15:22 ] @
To najbolje radi program za skeniranje ABBYY FineReader. On je bez premca u
tome, jeste da je veliki ali se isplati. Trenutna verzija je 12 [ newtesla @ 29.07.2014. 08:15 ] @
Ja na Linuxu to radim sa LibreOffice paketom - koji postoji i za windows.
edit: eve, pokušaj od 2 sekunde - izgleda da nemam ćirilični font, pa je Lindža sve transkribovao u latinicu  malo parsovanja regularnim izrazima, i dovešće se u savršenstvo malo parsovanja regularnim izrazima, i dovešće se u savršenstvo  [ Jpeca @ 29.07.2014. 10:51 ] @
Sličan rezultat se dobije i otvaranje PDF dokumenta u Wordu. Tekst je konvetovan u latinicu što se da popraviti (doduše pošto se radi o tekstu koji kombinuje ćirilično i latinično pismo nije baš jednostavno!) . Prilikom konverzij č je postalo q š je postalo x, ali najveći problem je što su se ć i ž slova izgubila. Nisam siguran kako to može da se izbegne.
[ loto17 @ 30.07.2014. 09:50 ] @
Probao sam ABBYY FineReader 12 i Adobe Acrobat XI Pro ali su rezultati dosta sareni.
Ostaje mi da probam da istaliram fontove koji su korisceni u originalnom dokumentu pa da pokusam jos jednom.  [ Hackman @ 30.07.2014. 13:21 ] @
Ako to fajnrider nije prebacio kako treba e onda sa tim dokumentom nešto baš
nije u redu, jer on 99 posto dokumenata prebaci u tekst na zadovoljavajući, čak jako dobar način. [ rgdrajko @ 27.09.2014. 01:20 ] @
Citat: Hackman: To najbolje radi program za skeniranje ABBYY FineReader. On je bez premca u tome, jeste da je veliki ali se isplati. Trenutna verzija je 12 Nisi u pravu, bolji je Readiris 14: http://www.irislink.com/c2-280...onvert---manage-documents.aspx Copyright (C) 2001-2026 by www.elitesecurity.org. All rights reserved.
|