|
|
[ karlson @ 18.04.2016. 11:30 ] @
|
| Potrebno mi je prebacivanje podataka iz Excela u MySQL bazu. Pronašao sam u knjizi jedno rješenje koje
od Excelove XML datoteke generiše SQL kod, koji bih onda mogao kopirati u bazu preko PhpMyAdmin-a.
(Tako sam bar zamislio, valjda ne radim nešto mnogo pogrešno.)
Međutim, problem nastaje kod naših slova, tj. afrikata. Generisani SQL kod nekad ima više polja nego
što ih tabela sadrži. Npr. umjesto:
INSERT INTO IME_BAZE ( ARTIKAL, KUPAC, DATUM ) VALUES ( 'Guma', 'Marko Marković', '26.02.2016.' );
kao rezultat dobijem:
INSERT INTO IME_BAZE ( ARTIKAL, KUPAC, DATUM ) VALUES ( 'Guma', 'Marko Markovi', 'ć', '26.02.2016.' );
I vrlo često (iako ne uvijek) pravi takve prekide kod naših slova (ćĆčČđĐšŠžŽ).
Problem mi se dešavao i sa nekim drugim znakovima (apostrof, crtica, navodnici...), ali sam rješenje
našao u starim temama ovdje na forumu (korištenje funkcija addslashes, htmlspecialchars, strip_tags,
magic_quotes_gpc i sl.). Međutim, za ovaj problem nisam uspio naći rješenje, pa se nadam da će mi neko
pomoći.
Evo koda iz knjige:
Code:
<?php
$tables = array();
$indata = 0;
function encode( $text )
{
$text = preg_replace( "/'/", "''", $text );
return "'".$text."'";
}
function start_element( $parser, $name, $attribs )
{
global $tables, $indata;
if ( $name == "WORKSHEET" )
{
$tables []= array(
'name' => $attribs['SS:NAME'],
'data' => array()
);
}
if ( $name == "ROW" )
{
$tables[count($tables)-1]['data'] []= array();
}
if ( $name == "DATA" )
{
$indata = 1;
}
}
function text( $parser, $text )
{
global $tables, $indata;
if ( $indata )
{
$data =& $tables[count($tables)-1]['data'];
$data[count($data)-1] []= $text;
}
}
function end_element( $parser, $name )
{
global $indata;
if ( $name == "DATA" )
$indata = 0;
}
$parser = xml_parser_create( );
xml_set_element_handler( $parser, "start_element", "end_element" );
xml_set_character_data_handler( $parser, "text" );
while( !feof( STDIN ) ) {
$text = fgets( STDIN );
xml_parse( $parser, $text );
}
xml_parser_free( $parser );
foreach( $tables as $table ) {
$name = $table['name'];
$data =& $table['data'];
$cols = implode( ", ", $data[0] );
for( $in = 1; $in < count( $data ); $in++ ) {
$sqldata = implode( ", ", array_map( "encode", $data[$in] ) );
?>
INSERT INTO <?php echo( $name )?> ( <?php echo( $cols ) ?> ) VALUES ( <?php echo(
$sqldata ); ?> );
<?php } } ?>
|
[ jablan @ 18.04.2016. 11:37 ] @
Čini se kao posledica čudnog ponašanja funkcije xml-set-character-data-handler. Baci pogled tamo na komentare itd, ključna reč je "split".
Mada, reći da se PHP čudno ponaša je jednostavno pleonazam. :P [ jablan @ 18.04.2016. 13:01 ] @
BTW ako već radiš ručno, što ne eksportuješ CSV direktno iz Excela? mysql podržava import iz CSV.
[ karlson @ 18.04.2016. 13:28 ] @
Pa našao sam ovaj kod i mislio da će funkcionisati. Nisam neki veliki poznavalac PHP-a da bih mogao razlikovati koji format je
bolji za eksport. U suštini, trebam prebaciti podatke, a na koji način - sasvim je svejedno...
[ karlson @ 20.04.2016. 14:47 ] @
Odustao sam od XML-a i prešao na CSV. Skoro je proradilo ali i dalje imam problem sa našim slovima.
Podesio sam encoding pri kreiranju baze na utf-8:
Code:
CREATE DATABASE ime_baze DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci;
a prilikom importa CSV-a koristio sam ovaj kod:
Code:
LOAD DATA INFILE 'putanja/do/file.csv'
IGNORE INTO TABLE ime_tabele
CHARACTER SET UTF8
FIELDS TERMINATED BY ';'
OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n';
i kad u localhostu pokušam
Code:
SELECT * FROM ime_tabele;
nedostaju naša slova, tačnije kada naiđe na naše slovo nedostaje ostatak podatka od tog slova pa do kraja. [ jablan @ 20.04.2016. 15:06 ] @
Jel si siguran da su ti u CSV-u dobro enkodovana naša slova? Zašto su ti polja odvojena tačkom i zarezom, a ne zarezom?
[ karlson @ 20.04.2016. 19:04 ] @
Prvo sam stavio
Code:
FIELDS TERMINATED BY ','
pa kad sam vidio da pokazuje sadržaj baze ni sličan onome što bi trebalo da bude, zavirio sam u CSV fajl
(preko Notepada) i vidio da su polja odvojena tačka-zarezom, ali naša slova u CSV su prikazana ispravno. [ jablan @ 21.04.2016. 09:02 ] @
mysql je prilično robustan što se ovakvih stvari tiče tako da sumnjam da je problem na njegovoj strani. predložio bih ti da negde okačiš CSV ili neki njegov deo (ali bez kopi-pejstovanja iz windowsa, znači direktno ono što imaš na disku) pa da vidimo šta je unutra.
[ karlson @ 21.04.2016. 10:36 ] @
Hvala ti za trud i pomoć.
Evo okačio sam jedan mali probni CSV faj. [ dusans @ 21.04.2016. 10:41 ] @
Ovo nije enkodovano kao UTF-8.
[ djoka_l @ 21.04.2016. 10:44 ] @
Tačno tako - ovo je Windows 1250 encoding.
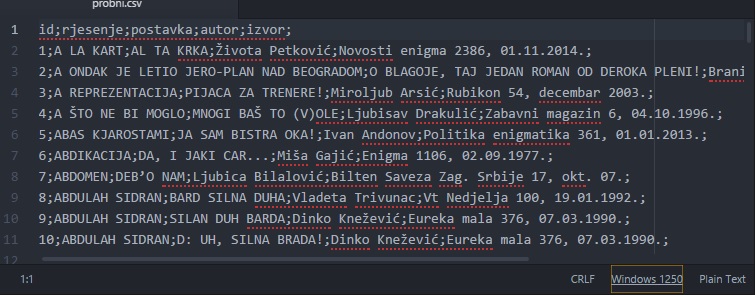
Uzgred, anagram 6 nije tačan, nema B, a ima R u anagramu...
[Ovu poruku je menjao djoka_l dana 21.04.2016. u 12:00 GMT+1][ karlson @ 22.04.2016. 07:44 ] @
Hvala za pomoć i izvinjavam se zbog ovog encodinga, nisam znao da se treba dodatno podesiti i u Excelu.
Inače, kojim alatom prepoznajete encoding nekog fajla?
@djoka_l
Dobro si zapazio. :)
Ispravnost ovih anagrama je poseban problem koji mi sada nije prioritet...
[ jablan @ 22.04.2016. 08:55 ] @
Očima. Menjaš enkoding dok ne vidiš da su sva slova OK. Teoretski, moglo bi neko statističko prepoznavanje da se obavi bazirano na n-gramima.
http://superuser.com/questions...auto-detect-text-file-encoding
Pretpostavljam da neki editori imaju ugrađenu detekciju. [ karlson @ 27.04.2016. 15:08 ] @
Da zaključim ovu temu zbog nekog ko će možda nekad imati ovakav problem.
Sam encoding u UTF-8 za CSV fajl mi nije riješio problem.
Malo sam pogledao opcije za gorepomenutu LOAD DATA INFILE naredbu.
Pa u njoj ima (a i gore se koristi):
Code:
OPTIONALLY ENCLOSED BY '"'
Tako da sam prvo u Excelu svakom polju na početku i kraju dodao znak # (umjesto navodnika,
jer se oni pojavljuju u nekim poljima, pa mi je stvaralo novi problem), a onda koristio ovako:
Code:
OPTIONALLY ENCLOSED BY '#'
i tek tada je sve bilo manje-više OK...
[ dakipro @ 27.04.2016. 18:14 ] @
Hvala sto si podelio rešenje
[ karlson @ 28.04.2016. 11:24 ] @
Pa to je najmanje što ovdje mogu uraditi za druge...
Copyright (C) 2001-2026 by www.elitesecurity.org. All rights reserved.
|