|
|
[ predator99 @ 19.07.2017. 11:27 ] @
|
| Postovanje svima
totalni sam pocetnik u pyhtonu poceo sam da ucim ali slabo mi ide suva teorija bez prakse
treba mi neko ko zna da radi da mi pokaze a primam sve sugestije posto imam ogromnu zelju da naucim.
molim za bilo kakvu pomoc.
unapred zahvalan
|
[ disko @ 05.08.2017. 22:21 ] @
[ kvaju @ 05.08.2017. 23:26 ] @
[ predator99 @ 07.08.2017. 17:42 ] @
hvala. vise sam mislio ovde ko se bavi time pa malo na volontersko ucenje i rad.
uglavnom hvala.
[ mjanjic @ 07.08.2017. 21:01 ] @
[ aditya12 @ 22.12.2018. 03:35 ] @
[ a1234567 @ 16.11.2019. 11:48 ] @
Da ne otvaram novu temu, jer sam isti kao i kolega, imam želju, ali ne i znanje. :)
Dakle, krenuo sam da učim prema knjizi Paul Barry: "Head First Python - A Brain-Friendly Guide" i dobro to napreduje, preći ću je celu, bez brige. Ali knjiga 600 strana, ja prešao tek trećinu, pa sam malo nestrpljiv. Nešto bih da praktično probam da uradim, da ne bude samo bubanje osnova. Ono što mene zanima je rad sa tekstom i mislim da je to najbolje učenje kad pokušavaš da rešiš problem koji te stvarno zanima. Elem, treba mi pomoć za siguran sam relativno banalan zadatak. Kako tekst iz fajla prebaciti u recimo LibraOffice spreadsheet, ali tako da svaka rečenica iz tog teksta bude u novom redu tabele?
Ako neko može da pomogne, mislim da bih mnogo naučio kroz takav praktičan primer. Hvala unapred.
[ Panta_ @ 17.11.2019. 08:50 ] @
Citat: Elem, treba mi pomoć za siguran sam relativno banalan zadatak
Samo preimenuj text fajl u csv. Na primer, moj_fajl.txt u moj_fajl.csv. Nema lakse. ;)
A u Pythonu, mozda nesto ovako:
Code (python):
import csv
with open('moj_fajl.csv', 'w', newline='') as csv_file:
writer = csv.writer(csv_file)
try:
fh = open('moj_fajl.txt')
lines = fh.read().splitlines()
for line in lines:
writer.writerow([line])
except IOError as e:
print(f'OS error: {e}')
finally:
fh.close()
https://realpython.com/openpyxl-excel-spreadsheets-python/[ a1234567 @ 17.11.2019. 13:01 ] @
Hvala, Panto.
Text preimenovao. To je stvarno bilo lako :)))
Ali import u Calc ne daje ono što mi treba, jer sve rečenice nisu u prvoj koloni,
već ih razbuca horizontalno i vertikalno.
Treba ih dakle prvo iseckati u cvf fajlu, da svaka bude poseban red, pa onda učitati.
To bi, koliko razumem trebalo da uradi ovaj kod koji si dao.
Isprobao ga, al IDLE javlja grešku
NameError: name 'fh' is not defined!
[ Branimir Maksimovic @ 17.11.2019. 13:10 ] @
Ne moze to tako lako. Treba prvo prepoznati recenicu...
[ Panta_ @ 17.11.2019. 13:53 ] @
Citat: Isprobao ga, al IDLE javlja grešku
NameError: name 'fh' is not defined!
Unsi putanju do tvog fajla gde ti se tekst nalazi, na primer: fh = open(' /putanja/do/tvoj_tekst_fajl.txt').
Citat: Ali import u Calc ne daje ono što mi treba, jer sve rečenice nisu u prvoj koloni,
već ih razbuca horizontalno i vertikalno.
Čekaj, zar ti nećeš da svaka rečenica bude u novom redu? Na primer:
Code:
| | A | B |
| 1 | Prva recenica
| 2 | Druga recenica | |
| 3 | Trca recenica | |
[ Deunan @ 17.11.2019. 15:42 ] @
Probaj ovaj regex: (?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?)\s
Kod mene radi...
Da se nadovezem na kod od @Panta_ :
Code:
import csv
import re
with open('moj_fajl.csv', 'w', newline='') as csv_file:
writer = csv.writer(csv_file)
try:
fh = open('text.txt')
oneLine = fh.read().strip('\n').replace('\n', ' ').replace('\r', '')
sentences = re.split(r'(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?)\s', oneLine)
for sentence in sentences:
writer.writerow([sentence.strip()])
except IOError as e:
print(f'OS error: {e}')
finally:
fh.close()
[ Panta_ @ 17.11.2019. 16:25 ] @
Ili, instaliraj NLTK paket:
Code:
pip install nltk
Zatim:
Code (python):import csv
import nltk
with open('/putanja/do/tvoj_fajl.csv', 'w', newline='') as csv_file:
writer = csv.writer(csv_file)
try:
fh = open('/putanja/do/tvoj_fajl.txt')
lines = fh.read().replace('\n', '')
lines = nltk.sent_tokenize(lines)
for line in lines:
writer.writerow([line])
except IOError as e:
print(f'OS error: {e}')
finally:
fh.close() [ predator99 @ 18.11.2019. 15:04 ] @
postovani evo kolega se upustio u diskusiju oko pajtona a ja i dalje trazim nekog pametnog oko pajtona ko radi sa njim da da neki cas posto ova citanje i ucenje mi nista ne pomaze, ne vidim kako sta da pravim
posto sam vizuelista kad znam sta treba onda povezujem sve to ovako mi nista ne ide. Dajte neki predlog.
[ a1234567 @ 20.11.2019. 11:17 ] @
Citat: Panta_:
Citat: Isprobao ga, al IDLE javlja grešku
NameError: name 'fh' is not defined!
Unsi putanju do tvog fajla gde ti se tekst nalazi, na primer: fh = open(' /putanja/do/tvoj_tekst_fajl.txt').
Citat: Ali import u Calc ne daje ono što mi treba, jer sve rečenice nisu u prvoj koloni,
već ih razbuca horizontalno i vertikalno.
Čekaj, zar ti nećeš da svaka rečenica bude u novom redu? Na primer:
Code:
| | A | B |
| 1 | Prva recenica
| 2 | Druga recenica | |
| 3 | Trca recenica | |
Da to pokušavam. Imam origial tekst (text 1) i imam prevod (text 2) i hteo bih da ih uporedim tako što ću svaku rečenicu iz text1 staviti u kolonu A, a svaku rečenicu iz text2 staviti u kolonu be, paralelno sa njenim originalom.
Dakle, kao što si napravio, samo da dopunim
Code:
| | A | B |
| 1 | Prva recenica-textA | Prva rečenica-textB |
| 2 | Druga recenica-textA | Druga rečenica-textB |
| 3 | Trca recenica-textA | Treća rečenica-textB |
Ajde sad ću probati i ovaj predlog sa regex, pa odgovaeam [ a1234567 @ 20.11.2019. 13:50 ] @
Citat: Panta_:
Ili, instaliraj NLTK paket:
Code:
pip install nltk
Zatim:
Code (python):import csv
import nltk
with open('/putanja/do/tvoj_fajl.csv', 'w', newline='') as csv_file:
writer = csv.writer(csv_file)
try:
fh = open('/putanja/do/tvoj_fajl.txt')
lines = fh.read().replace('\n', '')
lines = nltk.sent_tokenize(lines)
for line in lines:
writer.writerow([line])
except IOError as e:
print(f'OS error: {e}')
finally:
fh.close()
Panto, instalirao nltk 3.4.5
Ali ne pomaže mnogo.
Elem, u Notepad sam iskopirao tekst:
Noël a lieu le 25 décembre. C’est une fête chrétienne qui célèbre la naissance de Jésus. Les familles se réunissent et partagent un bon repas le soir du 24 décembre, et on s’offre des cadeaux. Enfin, Pâques n’a pas de date fixe, c’est un dimanche compris entre le 22 mars et le 25 avril.
i sačuvao ga kao original.txt sa utf-8 encoding. Onda sam mu promenio ekstenziju u .csv
I kod je trenutno ovaj:
Code:
import csv
import nltk
with open('c:\FAJLOVI\Python_School\CSV\original.csv', 'w', newline='') as csv_file:
writer = csv.writer(csv_file)
try:
fh = open('c:\FAJLOVI\Python_School\CSV\original.csv')
lines = fh.read().replace('\n', '')
lines = nltk.sent_tokenize(lines)
for line in lines:
writer.writerow([line])
except IOError as e:
print(f'OS error: {e}')
finally:
fh.close()
Pokrenem, kad ono čitav mi roman IDLE ispisao i sve crveno, dakle - neće moći:
Code:
Traceback (most recent call last):
File "C:/FAJLOVI/Python_School/CSV/koverzija.py", line 9, in <module>
lines = nltk.sent_tokenize(lines)
File "C:\Users\ja_sa\AppData\Local\Programs\Python\Python37-32\lib\site-packages\nltk\tokenize\__init__.py", line 105, in sent_tokenize
tokenizer = load('tokenizers/punkt/{0}.pickle'.format(language))
File "C:\Users\ja_sa\AppData\Local\Programs\Python\Python37-32\lib\site-packages\nltk\data.py", line 868, in load
opened_resource = _open(resource_url)
File "C:\Users\ja_sa\AppData\Local\Programs\Python\Python37-32\lib\site-packages\nltk\data.py", line 993, in _open
return find(path_, path + ['']).open()
File "C:\Users\ja_sa\AppData\Local\Programs\Python\Python37-32\lib\site-packages\nltk\data.py", line 701, in find
raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource �[93mpunkt�[0m not found.
Please use the NLTK Downloader to obtain the resource:
�[31m>>> import nltk
>>> nltk.download('punkt')
�[0m
For more information see: https://www.nltk.org/data.html
Attempted to load �[93mtokenizers/punkt/english.pickle�[0m
Searched in:
- 'C:\\Users\\ja_sa/nltk_data'
- 'C:\\Users\\ja_sa\\AppData\\Local\\Programs\\Python\\Python37-32\\nltk_data'
- 'C:\\Users\\ja_sa\\AppData\\Local\\Programs\\Python\\Python37-32\\share\\nltk_data'
- 'C:\\Users\\ja_sa\\AppData\\Local\\Programs\\Python\\Python37-32\\lib\\nltk_data'
- 'C:\\Users\\ja_sa\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
- ''
**********************************************************************
[ a1234567 @ 20.11.2019. 13:54 ] @
Citat: predator99:
postovani evo kolega se upustio u diskusiju oko pajtona a ja i dalje trazim nekog pametnog oko pajtona ko radi sa njim da da neki cas posto ova citanje i ucenje mi nista ne pomaze, ne vidim kako sta da pravim
posto sam vizuelista kad znam sta treba onda povezujem sve to ovako mi nista ne ide. Dajte neki predlog.
Ako mogu da se ubacim. Možda da prvo smisliš za šta bi da koristiš python, neki lakši zadatak koji bi voleo da uradiš, kao recimo ja ovo sa tekstom. Pa da konkretno pitaš. Ovako generalno, ne znaju ljudi šta da i pomognu. [ a1234567 @ 20.11.2019. 14:03 ] @
Citat: Deunan:
Probaj ovaj regex: (?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?)\s
Kod mene radi...
Da se nadovezem na kod od @Panta_ :
Hvala. Probao sam ovo:
Code:
import csv
import re
with open('c:\FAJLOVI\Python_School\CSV\original.csv', 'w', newline='') as csv_file:
writer = csv.writer(csv_file)
try:
fh = open('c:\FAJLOVI\Python_School\CSV\original.csv')
oneLine = fh.read().strip('\n').replace('\n', ' ').replace('\r', '')
sentences = re.split(r'(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?)\s', oneLine)
for sentence in sentences:
writer.writerow([sentence.strip()])
except IOError as e:
print(f'OS error: {e}')
finally:
fh.close()
Ne prijavljuje nikakvu grešku, ali i ne ostane ništa od texta. Prazan fajl na kraju! [ djoka_l @ 20.11.2019. 14:07 ] @
Da li si pročitao uputstvo za instalaciju nltk?
Nije dovoljan samo nltk paket, treba da se skinu i data fajlovi sa opisima jezika.
[ Deunan @ 20.11.2019. 14:27 ] @
Otvaras isti fajl!
with open('c:\FAJLOVI\Python_School\CSV\original.csv', 'w', newline='') as csv_file: # FAJL U KOJI CES DA UPISUJES!
fh = open('fajlKojiCitas.txt') # FAJL KOJI CITAS (nije csv)!
[ a1234567 @ 20.11.2019. 16:09 ] @
Zamenio nazive fajova, kao što si napisao, ali mi javlja drugu grešku
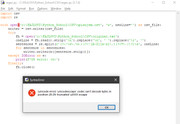 [ a1234567 @ 20.11.2019. 17:28 ] @
Sa mojim skoro nepostojećim znanjem pythona i uz googlanje, došao sam do nekog koda
Code:
import re
# Otvori fajl
with open("original.txt", encoding='utf-8') as of:
for line in of:
# Podeli tekst kad naiđeš na '.' or ? or !.
for l in re.split(r"\.|\?|\!",line):
# Izlistaj na ekranu
print(l)
# Upiši rezultat u novi.txt
with open('novi.txt', 'w') as nf:
print(l, file=nf)
E sad je problem što ovo upisivanje u fajl na kraju ne radi. Napravi fajl novi.txt, ali je prazan. Ne upiše to što izlistava na ekranu.
Gde gešim? [ Panta_ @ 20.11.2019. 18:10 ] @
Citat: Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('punkt')
Lepo ti kaže, prvo nltk.download('punkt'), pa onda pokreni kod.
Code (python):import csv
import nltk
nltk.download('punkt')
with open('/putanja/do/tvoj_fajl.csv', 'w', newline='') as csv_file:
writer = csv.writer(csv_file)
try:
fh = open('/putanja/do/tvoj_fajl.txt')
lines = fh.read().replace('\n', '')
lines = nltk.sent_tokenize(lines)
for line in lines:
writer.writerow([line])
except IOError as e:
print(f'OS error: {e}')
finally:
fh.close() [ Panta_ @ 20.11.2019. 18:23 ] @
Citat: E sad je problem što ovo upisivanje u fajl na kraju ne radi. Napravi fajl novi.txt, ali je prazan. Ne upiše to što izlistava na ekranu.
Gde gešim?
Umesto w (write) stavi a (append): with open('novi.txt', 'a') as nf[ djoka_l @ 21.11.2019. 08:34 ] @
Mislim da si odabrao pogrešan problem za učenje Pythona.
NLP je ozbiljan problem, a nltk komplikovan paket. Procesiranje prirodnih jezika je težak problem za veštačku inteligenciju.
Kažeš, želiš da ispišeš svaku rečenicu iz teksta u novom redu.
E, sada dolazi kvaka 22: definiši šta je to rečenica u tekstu pisanom u nekom prirodnom jeziku. Daj mi bilo koju definiciju, a ja ću ti dati 10 primera koji će da pokažu da postoje rečenice koje se ne uklapaju u tvoju definiciju.
Nećeš daleko da stigneš, a Python će ti biti najmanji problem...
[ peromalosutra @ 21.11.2019. 13:06 ] @
@a1234567
Sto se tice greske sa poslednjeg screenshota, ne mozes da koristis backslash (\) karakter unutar stringa, jer on ima specijalno znacenje i sluzi za definisanje escape sequenci. Da bi ubacio taj karakter u string, moras i njega da "ekskejpujes" (jbg, ne znam nas termin), tako sto koristis dupli backslash "\\".
dakle, umjesto ovog:
Code:
a = 'c:\neka\putanja.txt'
stavi ovo:
Code:
a = 'c:\\neka\\putanja.txt' [ a1234567 @ 21.11.2019. 15:40 ] @
Citat: Panta_:
Citat: Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('punkt')
Lepo ti kaže, prvo nltk.download('punkt'), pa onda pokreni kod.
Code (python):import csv
import nltk
nltk.download('punkt')
with open('/putanja/do/tvoj_fajl.csv', 'w', newline='') as csv_file:
writer = csv.writer(csv_file)
try:
fh = open('/putanja/do/tvoj_fajl.txt')
lines = fh.read().replace('\n', '')
lines = nltk.sent_tokenize(lines)
for line in lines:
writer.writerow([line])
except IOError as e:
print(f'OS error: {e}')
finally:
fh.close()
Panto, genije si. Punkt punktiran, da ne kažem daunlodovan. I sada tvoj kod radi kao sat.
Evo i dokaz

E a sad dolazi faza 2. Ovo je ubačen originalni tekst. Sad da iseckam prevod tog teksta, to znam kako ću. Ali kako da ga ubacim u istu ovu tabelu, ali da ga stavi u drugu kolonu, tako da se upari sa prvom?
[ a1234567 @ 21.11.2019. 15:51 ] @
Citat: djoka_l:
Mislim da si odabrao pogrešan problem za učenje Pythona.
NLP je ozbiljan problem, a nltk komplikovan paket. Procesiranje prirodnih jezika je težak problem za veštačku inteligenciju.
Kažeš, želiš da ispišeš svaku rečenicu iz teksta u novom redu.
E, sada dolazi kvaka 22: definiši šta je to rečenica u tekstu pisanom u nekom prirodnom jeziku. Daj mi bilo koju definiciju, a ja ću ti dati 10 primera koji će da pokažu da postoje rečenice koje se ne uklapaju u tvoju definiciju.
Nećeš daleko da stigneš, a Python će ti biti najmanji problem...
E baš si me ohrabrio. :)))
Pa još da definišem rečenicu. Pa nisam ja veštačka inteligencija :))
Sve je pod kontrolom. Ja i ne nameravam daleko da stignem, već da nešto naučim. Koliko, videćemo. Nisam u žurbi. Mlad sam, tek sam otišao u penziju :)
Važno je svaki dan pomalo. A rad sa tekstovima me stvarno jako zanima, jer sam prevodilac i svaki dan radim sa njima. Pa da sebi malo olakšam.
Naravno, završivši studije jezika, nemam pojma o programiranju. Jedina olakšavajuća okolnost mi je što sam ceo vek bio znatiželjan i nije mi teško da učim nove stvari.
Tako da koliko god od pythona da naučim, čist dobitak. Programerima sigurno neću uzimati lebac.
I za kraj, ovo oko rečenice. U tekstovima sa kojima ja radim, rečenica se završava (uglavnom) tamo gde je tačka, znak pitanja ili uzvika i tu je sečem. Naravno, tačaka ima i unutar rečenice, ali to ćemo Panta i ja da rešimo u trećoj fazi ovog mega projekta. Sad smo još na početku druge :)
U svakom slučaju, hvala ti na komentaru i ako budeš imao ideja kako da rešimo ove naše petljavine, slobodno piši, pošto vidim da si upućen u NLTK. Unapred sam ti zavalan. [ a1234567 @ 21.11.2019. 15:59 ] @
Citat: peromalosutra:
@a1234567
Sto se tice greske sa poslednjeg screenshota, ne mozes da koristis backslash (\) karakter unutar stringa, jer on ima specijalno znacenje i sluzi za definisanje escape sequenci. Da bi ubacio taj karakter u string, moras i njega da "ekskejpujes" (jbg, ne znam nas termin), tako sto koristis dupli backslash "\\".
dakle, umjesto ovog:
Code:
a = 'c:\neka\putanja.txt'
stavi ovo:
Code:
a = 'c:\\neka\\putanja.txt'
Jao jeste, to sam pročitao u ovoj knjizi po kojoj idem, ali... zaboravio :(
Hvala ti na podsećanju.
Sad se sećam, kad je novi red onda ide \n ili enter \r
Interpreter mi javlja grešku, a ja ga ignorišem :)))
"eskejpuješ", pa to je naša stara reč, nema brige. Vuk Karadžić je još koristio kad je bežao iz Srbije :))) [ a1234567 @ 21.11.2019. 17:00 ] @
Citat: Panta_:
Citat: E sad je problem što ovo upisivanje u fajl na kraju ne radi. Napravi fajl novi.txt, ali je prazan. Ne upiše to što izlistava na ekranu.
Gde gešim?
Umesto w (write) stavi a (append): with open('novi.txt', 'a') as nf
stavio a umesto w, ali opet samo napravi prazan novi.txt fajl, ne upisuje text u njega.
[ Panta_ @ 21.11.2019. 17:59 ] @
Citat: stavio a umesto w, ali opet samo napravi prazan novi.txt fajl, ne upisuje text u njega.
Stavio si with blok izvan for petlje tako da nema sta da upiše, petlja ti se izvršila (vidi šta ti je l, print(l), nakon izvršenja for petlje, to će i da upiše. Stavi with ispod print(l), ili nešto ovako:
Code (python):
with open('original.txt', encoding='utf-8') as of:
for line in of:
with open('novi.txt', 'a') as novi:
# Podeli tekst kad naiđeš na '.' or ? or !.
for l in re.split(r"\.|\?|\!",line):
# Izlistaj na ekranu
print(l)
# Upiši rezultat u novi.txt
novi.write(l)
[ Deunan @ 21.11.2019. 18:04 ] @
Citat:
E a sad dolazi faza 2. Ovo je ubačen originalni tekst. Sad da iseckam prevod tog teksta, to znam kako ću. Ali kako da ga ubacim u istu ovu tabelu, ali da ga stavi u drugu kolonu, tako da se upari sa prvom?
Iseckaj prevod kao sto si i original i spoji po dve recenice u jedan list: ['Tekst jedan ...', 'Tekst dva ...'].
I ubaci u csv red: writer.writerow([line1, line2])
Najbolje je da napravis univerzalno resenje, pa samo da dodajes jezike:
Code:
writeList = []
languages = ['rs.txt', 'en.txt', 'de.txt'] # nevazno koliko fajlova, samo dodaj path
for langId, languageFile in enumerate(languages):
fh = open(languageFile)
lines = fh.read().replace('\n', '')
fh.close()
lines = nltk.sent_tokenize(lines)
for lineId, line in enumerate(lines):
if langId == 0:
writeList.insert(lineId, [])
writeList[lineId].insert(langId, line)
with open('moj_fajl.csv', 'w', newline='') as csv_file:
writer = csv.writer(csv_file)
writer.writerows(writeList)
[ a1234567 @ 24.11.2019. 15:04 ] @
Citat: Panta_:
Citat: stavio a umesto w, ali opet samo napravi prazan novi.txt fajl, ne upisuje text u njega.
Stavio si with blok izvan for petlje tako da nema sta da upiše, petlja ti se izvršila (vidi šta ti je l, print(l), nakon izvršenja for petlje, to će i da upiše. Stavi with ispod print(l), ili nešto ovako:
Code (python):
with open('original.txt', encoding='utf-8') as of:
for line in of:
with open('novi.txt', 'a') as novi:
# Podeli tekst kad naiđeš na '.' or ? or !.
for l in re.split(r"\.|\?|\!",line):
# Izlistaj na ekranu
print(l)
# Upiši rezultat u novi.txt
novi.write(l)
Zanimljiv slučaj, popravio kod kao što si napisao
Code:
import re
with open('engleski.txt', encoding='utf-8') as eng:
for line in eng:
with open('engleski_redovi.txt', 'w+') as eng_red:
for l in re.split(r"\.|\?|\!",line):
print(l)
eng_red.write(l)
eng_red.close()
Na ekranu izlista tekst podeljen na rečenice, svaka u novom redu,
a u fajlu "engleski_redovi.txt" tekst nepromenjen, sav u jednom pasusu.
Druga stvar, ovaj regex kad ga secka na tački, on izbriše tačku. Kako da je ostavim na kraju rečenice?
[ a1234567 @ 24.11.2019. 15:24 ] @
Citat: Deunan:
Iseckaj prevod kao sto si i original i spoji po dve recenice u jedan list: ['Tekst jedan ...', 'Tekst dva ...'].
I ubaci u csv red: writer.writerow([line1, line2])
Najbolje je da napravis univerzalno resenje, pa samo da dodajes jezike:
Code:
writeList = []
languages = ['rs.txt', 'en.txt', 'de.txt'] # nevazno koliko fajlova, samo dodaj path
for langId, languageFile in enumerate(languages):
fh = open(languageFile)
lines = fh.read().replace('\n', '')
fh.close()
lines = nltk.sent_tokenize(lines)
for lineId, line in enumerate(lines):
if langId == 0:
writeList.insert(lineId, [])
writeList[lineId].insert(langId, line)
with open('moj_fajl.csv', 'w', newline='') as csv_file:
writer = csv.writer(csv_file)
writer.writerows(writeList)
Nemam ja više jezika, samo engleski i srpski.
Spojena dva teksta bi trebalo ovako da izgledaju pre uvoza u Calc tabelu:
eng_rečenica1,srp_rečenica1
eng_rečenica2,srp_rečenica2
eng_rečenica3,srp_rečenica3
Probao sam ovaj kod, ali javlja grešku:
File "C:\Users\ja_sa\AppData\Local\Programs\Python\Python37-32\lib\encodings\cp1252.py", line 23, in decode
return codecs.charmap_decode(input,self.errors,decoding_table)[0]
UnicodeDecodeError: 'charmap' codec can't decode byte 0x8d in position 5: character maps to <undefined>
Treba mu negde ubaciti encoding='utf-8'
jer windows je cp-1250, a moji txt fajlovi su utf-8 [ Branimir Maksimovic @ 24.11.2019. 19:55 ] @
Evo ti programce u Rust-u String je uvek utf-8.
Code:
use std::fs::File;
use std::io::Read;
use std::io::Write;
fn main()->Result<(),String> {
let args:Vec<_> = std::env::args().collect();
if args.len() < 4 {
return Err(format!("usage: {} infile1 infile2 outfile",args[0]));
} else {
let mut inf1 = File::open(&args[1]).unwrap();
let mut inf2 = File::open(&args[2]).unwrap();
let (text1,text2) = (format(&mut inf1),format(&mut inf2));
let mut ouf = File::create(&args[3]).unwrap();
for (line1,line2) in text1.lines().zip(text2.lines()) {
let _ = ouf.write(line1.as_bytes());
let _ = ouf.write(",".as_bytes());
let _ = ouf.write(line2.as_bytes());
let _ = ouf.write("\n".as_bytes());
}
Ok(())
}
}
fn format(inf:&mut File)->String {
let mut text = String::new();
let mut buf = String::new();
let _ = inf.read_to_string(&mut text);
for line in text.lines() {
buf.push_str(&line);
buf.push(' ');
}
text.clear();
let mut sent = String::new();
for c in buf.chars() {
if c != ' ' { sent.push(c); }
else { sent.push('_'); }
if c == '.' {
text.push_str(&sent);
text.push('\n');
sent.clear();
}
}
text.push_str(&sent);
sent.clear();
text
}
[ a1234567 @ 25.11.2019. 05:06 ] @
Hvala ti, Branimire, ali ne bih da menjam jezik.
Odlučio sam se da naučim koliko-toliko python, pa dokle stignem.
Sad samo čekam još da Panta i Deunan postignu da mi daju neki hint. :))
[ Branimir Maksimovic @ 25.11.2019. 05:25 ] @
Pa prevedi ovo u python onda :P
Ja sam mislio da tebi treba program za to...
[ Panta_ @ 25.11.2019. 05:34 ] @
Citat: Na ekranu izlista tekst podeljen na rečenice, svaka u novom redu,
a u fajlu "engleski_redovi.txt" tekst nepromenjen, sav u jednom pasusu.
A gde ti je nov red u write? Dakle, stavi eng_red.write('{}\n'.format(l)) ili eng_red.write(f'{l}\n') u zavisnosti koju verziju Pythona koristis.
Citat: Druga stvar, ovaj regex kad ga secka na tački, on izbriše tačku. Kako da je ostavim na kraju rečenice?
Na primer:
Code:
text = 'Prva recenica. Druga recenica! Treca recenica? Cetvrta, recenica.'
for l in re.split(r"(?<=\.|\?|\!)\s", text):
print(l)
Prva recenica.
Druga recenica!
Treca recenica?
Cetvrta, recenica.
Pogledaj (?<=) (positive lookbehind assertion)[ Panta_ @ 25.11.2019. 05:54 ] @
Citat: Evo ti programce u Rust-u
Jos malo pa kao u Brainfucku.  [ a1234567 @ 25.11.2019. 16:00 ] @
Citat: Branimir Maksimovic:
Pa prevedi ovo u python onda :P
Ja sam mislio da tebi treba program za to...
Treba mi program, ali bih umesto ribe, voleo da naučim da pecam :)
U svakom slučaju, hvala još jednom na trudu.
[ djoka_l @ 25.11.2019. 16:52 ] @
Ajde mi podeli na rečenice sledeći odlomak iz Kraljević Marko po drugi put među Srbima
Citat:
- Kakvim ste poslom došli onda?
- Kako: kakvim poslom? Pa zovete me iz dana u dan već pet stotina godina. Jednako me pevate u pesmama i kukate: "Gde si, Marko? Dođi, Marko! Kuku, Kosovo!" pa mi se već u grobu dodijalo, i zamolih boga da me pusti da dođem ovamo.
- O, brate slatki, glupo si uradio! Koješta, ta to se samo tako peva. Na pesmu, da si bio pametan, ne bi ni polagao, niti bismo sad imali toliku nevolju i mi s tobom i ti s nama. Da si zvanično, pozivom, pozvat, e to je već drugo. A ovako nemaš olakšavajuće okolnosti... Koješta, kakva posla ti ovde možeš imati... - završi kapetan nervozno, a u sebi pomisli: "Idi dovraga i ti i pesma! Izmotavaju se ljudi te pevaju koješta, pa sad mene ovde hvata groznica!"
[ a1234567 @ 01.12.2019. 16:22 ] @
Evo ga Kraljević Marko podeljen
 [ a1234567 @ 01.12.2019. 16:59 ] @
Citat: Panta_:
Citat: Na ekranu izlista tekst podeljen na rečenice, svaka u novom redu,
a u fajlu "engleski_redovi.txt" tekst nepromenjen, sav u jednom pasusu.
A gde ti je nov red u write? Dakle, stavi eng_red.write('{}\n'.format(l)) ili eng_red.write(f'{l}\n') u zavisnosti koju verziju Pythona koristis.
Citat: Druga stvar, ovaj regex kad ga secka na tački, on izbriše tačku. Kako da je ostavim na kraju rečenice?
Na primer:
Code:
text = 'Prva recenica. Druga recenica! Treca recenica? Cetvrta, recenica.'
for l in re.split(r"(?<=\.|\?|\!)\s", text):
print(l)
Prva recenica.
Druga recenica!
Treca recenica?
Cetvrta, recenica.
Pogledaj (?<=) (positive lookbehind assertion)
Panto, ovo je super rešenje. Em što ostavi tačku, nema ni to jedno polje razmaka koje je ranije bilo na početku svake rečenice kad ih isecka.
Sad tekst izgleda savršeno.
Ostala je poslednja faza. Kako kad imam dva fajla iseckana na rečenice: engleski.txt i srpski.txt da učitam u Excel i to engleski.txt u prvu kolonu i srpski.txt u drugu kolonu tabele? [ Panta_ @ 03.12.2019. 09:25 ] @
Isto kao što si čitao/pisao sa open('filename', 'rw'), tako isto i iz engleski/srpski i upiši u npr. englesko-spski.csv.
Na primer:
Code (python):engleski = ['First sentence.', 'Second sentence!', 'Third sentence?', 'Fourth sentence.']
srpski = ['Prva rečenica.', 'Druga rečenica!', 'Treca rečenica?', 'Četvrta, rečenica.']
import csv
with open('englesko-srpski.csv', 'w') as csv_file:
writer = csv.writer(csv_file)
for index, value in enumerate(engleski):
writer.writerow([value] + [srpski[index]])
# Ili sa zip(), "more pythonic"
with open('englesko-srpski.csv', 'w') as csv_file:
writer = csv.writer(csv_file)
for en, sr in zip(engleski, srpski):
writer.writerow([en] + [sr])
Code:
First sentence.,Prva rečenica.
Second sentence!,Druga rečenica!
Third sentence?,Treca rečenica?
Fourth sentence.,"Četvrta, rečenica."
[Ovu poruku je menjao Panta_ dana 03.12.2019. u 13:43 GMT+1][ a1234567 @ 06.12.2019. 14:40 ] @
Sledeća stepenica:
Kada radi sa engleskim, sve lepo secka, kad krene srpski da secka, nešto mu ne prija.
Izgleda da windows 10 koji imam enkodira po cp1252.py, iako u skriptu lepo piše encoding=utf-8.
Malo sam gledao, svuda kaže da je utf-8 default za python 3.7 koji ja imam, ali windows ga ne zarezuje izgleda.
Kako da ih usaglasim?
A ovo je poruka koju mi šalje python:
 [ djoka_l @ 06.12.2019. 14:51 ] @
Kakve veze ima Windows???
Lepo ti kaže da ne zna kako da kodira znak 010d. Ovo je malo slovo č u UTF16 i UTF32 enkodingu, ali ne postoji u UTF8. Uzmi lepo neki hex editor ili običan editor i pronađi koji su TAČNO bajtovi na toj poziciji, pa da krenemo dalje.
Ko zna po kom enkodingu je napisan tekst, da li Win1250 ili UTF8 ili UTF16 ili nešto deseto.
To šta piše u skriptu je isto kao i ono što piše na tarabi. Treba da staviš onaj enkoding koji je KORIŠĆEN, a ne onaj koji misliš da je korišćen.
[ a1234567 @ 06.12.2019. 15:51 ] @
Đoko, ti baš nisi za nastavnika. Nešto si mnogo napet. Opusti se, čoveče.
Nije pitanje života i smrti. Zabavljamo se i učimo.
Vidiš kako Panta ima strpljenja sa nama početnicima.
Elem, kad sam snimao tekst u fajl, uradio sam to sa običnim Notepadom i sačuvao ga sa utf-8 encoding.
tako da imam
engleski.txt - (utf-8)
srpski.txt - (utf-8)
Kada u srpskom skinem kuke i kvake od č,ć,š,đ i ž i pretvorim ih u c,s,d
sve radi kao sat.
Vidi ovde

Kontrole radi, učitao sam fajl i u Notepad++
i on kaže da je utf-8
 [Ovu poruku je menjao a1234567 dana 06.12.2019. u 17:09 GMT+1]
[Ovu poruku je menjao a1234567 dana 06.12.2019. u 17:09 GMT+1][ djoka_l @ 06.12.2019. 16:18 ] @
Imao sam jednog programera (nije bio dugo programer kod mene), koji bi svaki put kada napravi sintaksnu grešku u kodu, prijavljivao da je našao Oracle bag.
Svaki put bih ga pitao - šta misliš da je verovatnije: da si prvi od 10 miliona programera koji rade u Oraclu koji je otkrio bag, ili da si ti napravio grešku?
Ti si odmah pretpostavio, ili da je Windows zabrljao, ili da je Python pogrešio, samo na sebe ne sumnjaš.
Ne znaš ni da protumaćiš tekst greške koji ti je Python javio.
Ovde sam desetinama puta pisao - pogrešno je pitati koji programski jezik je najbolje da se uči. Pravo pitanje je kako naučiti da programiraš.
Uzeo si da praviš nešto komplikovano, a da nemaš nikakvo iskustvo u programiranju.
Umesto toga, napiši 100 jednostavnih programa u Pythonu, napravi 500 grešaka u tom procesu i iz svake greške nešto nauči.
Nemoj na svakoj grešci da staneš i pitaš forum šta dalje.
Ja, da sam na tvom mestu, kako bih razmišlajo:
1. moj program ima problema sa tekstom i to sa slovom koje se nalayi na 35. poziciji, daj da vidim koje je to slovo
2. to slovo je č - očigledno, ja ne znam da radim sa tekstom koji ima malo slovo č, ajde da zamenim na tom mestu slovo č sa cx, pa da vidim da li radi.
3. PROŠLO JE! Ali sada mi javlja grešku na slovu ć.
4. očigledno je da ne znam šta da radim sa našim slovima, daj da zamenim sva naša slova čćšđž ČĆŠĐŽ nekim drugim slovima, pa da ponovo probam program.
5. USPEH!!! Notiraj: prouči razlog greške. Koja slova očekuje moj program? Koja slova se nalaze u tekstu? Da li promenom enkodinga mogu da nateram program da radi? Da li izmenom programa mogu da obradim tekst sa postojećim enkodingom?
[ djoka_l @ 06.12.2019. 16:30 ] @
Evo ti uputstvo kako da u Notepad++ instaliraš HEX editor
https://superuser.com/question...-the-notepad-hex-editor-plugin
SVAKO ko radi sa tekstom MORA da ima opciju u svom editoru da pogleda kako ZAISTA izgleda tekst. Ako si na Linuxu, možeš da koristiš "od", na Windowsu ti treba dodatak za HEX view. [ a1234567 @ 06.12.2019. 16:41 ] @
1. Objasnio sam ti da sam bio siguran da je encding mog fajla utf-8.
S druge strane poruka interpretera je:
Traceback (most recent call last):
File "C:/FAJLOVI/Python_School/CSV/proba2.py", line 5, in <module>
content = infile.read().replace('\n', '')
File " C:\Users\ja_sa\AppData\Local\Programs\Python\Python37-32\lib\encodings\cp1252.py", line 23, in decode
return codecs.charmap_decode(input,self.errors,decoding_table)[0]
UnicodeDecodeError: 'charmap' codec can't decode byte 0x8d in position 36: character maps to <undefined>
Dakle iz ovog boldovanog vidim da python ne koristi utf-8, iako kažu da mu je to default, već cp1252. I to me je bunilo.
Onda pročitam ovo i vidim da u stvari windows ima problem sa utf-8
vidi ovde
2. Upravo sam to uradio što si predložio. Skinuo kvake i program radi. Izgleda da nisi moju poslednju poruku pročitao do kraja.
3. Ovo oko 100 jednostavnih programa. Išao po knjizi i nisam baš 100 ali sigurno 30-40 sam napisao, ali to su sve programi matematičkog tipa. Zabole me za fibonačijev niz ili da simuliram rulet. Meni treba rad sa textom, a to sam u knjizi slabo našao. Zato i pitam ovde.
4. Sve ovo je dobrovoljno, tako da nema potrebe da se nerviraš. Zanemari moja pitanja, ako su ti suviše banalna. Velik je forum, naći ćeš druga koja su na tvom nivou.
5. Da zaključim. Najlakše je popljuvati nekog. Najteže prepoznati svoj ego.
Svako dobro ti želim. [ djoka_l @ 06.12.2019. 16:42 ] @
Pretpostavljam da znaš engleski. Bilo bi dobro da pročitaš sledeći članak: http://catb.org/~esr/faqs/smart-questions.html
Evo nekih delova:
Citat: Before You Ask
Before asking a technical question by e-mail, or in a newsgroup, or on a website chat board, do the following:
1. Try to find an answer by searching the archives of the forum or mailing list you plan to post to.
2. Try to find an answer by searching the Web.
3. Try to find an answer by reading the manual.
4. Try to find an answer by reading a FAQ.
5. Try to find an answer by inspection or experimentation.
6. Try to find an answer by asking a skilled friend.
7. If you're a programmer, try to find an answer by reading the source code. Citat: Don't rush to claim that you have found a bug
When you are having problems with a piece of software, don't claim you have found a bug unless you are very, very sure of your ground. Hint: unless you can provide a source-code patch that fixes the problem, or a regression test against a previous version that demonstrates incorrect behavior, you are probably not sure enough. This applies to webpages and documentation, too; if you have found a documentation “bug”, you should supply replacement text and which pages it should go on.
Remember, there are many other users that are not experiencing your problem. Otherwise you would have learned about it while reading the documentation and searching the Web (you did do that before complaining, didn't you?). This means that very probably it is you who are doing something wrong, not the software.
The people who wrote the software work very hard to make it work as well as possible. If you claim you have found a bug, you'll be impugning their competence, which may offend some of them even if you are correct. It's especially undiplomatic to yell “bug” in the Subject line.
When asking your question, it is best to write as though you assume you are doing something wrong, even if you are privately pretty sure you have found an actual bug. If there really is a bug, you will hear about it in the answer. Play it so the maintainers will want to apologize to you if the bug is real, rather than so that you will owe them an apology if you have messed up. [ a1234567 @ 06.12.2019. 16:49 ] @
Citat: djoka_l:
Evo ti uputstvo kako da u Notepad++ instaliraš HEX editor
https://superuser.com/question...-the-notepad-hex-editor-plugin
SVAKO ko radi sa tekstom MORA da ima opciju u svom editoru da pogleda kako ZAISTA izgleda tekst. Ako si na Linuxu, možeš da koristiš "od", na Windowsu ti treba dodatak za HEX view.
Izgleda ni ti nečitaš moje poruke do kraja :)))
Upravo sam stavio screeshot notepada++ koji kaže da je encoding utf-8
Na win 10 sam i imam hex plugin instaliran za Notepad++. Python stane kod prvog našeg slova, a to je č (c48d). Ne zna šta da radi sa njim.
"codec can't decode byte 0x8d in position 36"
Ne razumem doduše zašto kaže 0x8d, a ne c48d, kako ja vidim u hex editoru da je č dva bajta. [ a1234567 @ 06.12.2019. 17:00 ] @
[quote] djoka_l:
Pretpostavljam da znaš engleski. Bilo bi dobro da pročitaš sledeći članak: http://catb.org/~esr/faqs/smart-questions.html
Evo nekih delova:
Citat: Before You Ask
Before asking a technical question by e-mail, or in a newsgroup, or on a website chat board, do the following:
1. Try to find an answer by searching the archives of the forum or mailing list you plan to post to.
2. Try to find an answer by searching the Web.
3. Try to find an answer by reading the manual.
4. Try to find an answer by reading a FAQ.
5. Try to find an answer by inspection or experimentation.
6. Try to find an answer by asking a skilled friend.
7. If you're a programmer, try to find an answer by reading the source code.
Znam engleski i prvo što uradim je da guglam. Uglavnom pogledam hitove koji upućuju na Stack Overflow.
Kad mi to ne pomaže, pređem na savet broj 6 :))
Ako je problem što pitam, kaži, neću više dosađivati.
Ali ne vidim da je ovde baš neka navala sa pitanjima, pa ste smoreni.
Ili ste sve razjurili ili nema ovakvih početnika kao ja. :)))
Već sam pisao o tome. Krenuo sam sa knjigom i posle sto strana shvatim da se bakćem sa nekim matematičkim problemima koji mi nikada neće trebati. Onda rešim da probam drugi metod. Zadam sebi zadatak, šta bih to voleo da radi taj moj novi program? To me ond amotiviše, jer sam stvarno zainteresovan. I pojavim se ovde, jer u svojoj okolini nemam koga da pitam. Mislim da sam na taj način, naravno zahvaljujući Panto tebi, više naučio iz tih nekoliko postova, nego iz onih 100 strana knjige.
[ djoka_l @ 06.12.2019. 17:06 ] @
Python zna, ali ti ne znaš.
Prvo, c48d JESTE UTF8 kod za malo slovo č
Drugo, Python ISPRAVNO prepoznaje to slovo kao \u010d (interno konvertuje u UTF16)
Treće, Python ti kaže da ne zna kako da \u010d konvertuje u CP1252.
Očigledno je da pokušavaš da UTF8 tekst PIŠEŠ kao CP1252.
Kada imaš grešku u programu OBAVEZNO postuj taj deo program koji greši.
[ Panta_ @ 07.12.2019. 08:24 ] @
@a1234567
Da li imaš naveden encoding kada upisuješ u fajl ( open('fajl.txt', 'w', encoding='utf-8') ), na Windowsu moraš da navedeš i prilikom čitanja i pisanja pošto je podrazumevani cp1252. Na Linuxu ili Mac OS Xu nije potrbno zato što je podrazumevani UTF-8, pa je dovoljno samo open('fajl.txt') za čitanje ili open('fajl.txt', 'w') za upisivnje.
Code:
import locale
# Linux
locale.getpreferredencoding()
'UTF-8'
# Windows
locale.getpreferredencoding()
'cp1252'
Ukoliko ne znaš file encoding, možeš u open funkciji da nevedeš errors='ignore' (ignoriše greške) ili errors='replace' (zameniće č i ć sa ?).
Citat: The errors parameter is the same as the parameter of the decode() method but supports a few more possible handlers. As well as 'strict', 'ignore', and 'replace' (which in this case inserts a question mark instead of the unencodable character), there is also 'xmlcharrefreplace' (inserts an XML character reference), backslashreplace (inserts a \uNNNN escape sequence) and namereplace (inserts a \N{...} escape sequence). [ a1234567 @ 07.12.2019. 11:55 ] @
Panto, ovo je kod koji imam do sada:
Code:
import re
import csv
with open('engleski.txt', encoding='utf-8') as eng:
for line in eng:
with open('engleski_redovi.txt', 'a') as eng_red:
for en in re.split(r"(?<=\.|\?|\!)\s", line):
print(en)
eng_red.write(f'{en}\n')
eng_red.close()
with open('srpski.txt', encoding='utf-8') as srp:
for line in srp:
with open('srpski_redovi.txt', 'w+') as srp_red:
for sr in re.split(r"(?<=\.|\?|\!)\s", line):
print(sr)
srp_red.write(f'{sr}\n')
srp_red.close()
with open('englesko-srpski.csv', 'w') as csv_file:
writer = csv.writer(csv_file)
for en, ser in zip(engleski, srpski):
writer.writerow([en] + [ser])
csv_file.close()
Dakle, kod otvaranja oba fajla piše utf-8, u tom sam encodingu i sačuvao text, ali windows to ne zarezuje.
Prijavi grešku
Traceback (most recent call last):
File "C:\FAJLOVI\Python_School\CSV\najnoviji.py", line 17, in <module>
srp_red.write(f'{sr}\n')
File "C:\Users\ja_sa\AppData\Local\Programs\Python\Python37-32\lib\encodings\cp1252.py", line 19, in encode
return codecs.charmap_encode(input,self.errors,encoding_table)[0]
UnicodeEncodeError: 'charmap' codec can't encode character '\u010d' in position 35: character maps to <undefined>
Na position 35 je prvo naše slovo u tekstu sa kukom, a to je č.
Dakle, kad pokrenem skript, na ekranu izlista ovo:
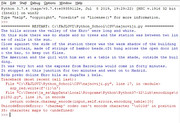
Naravno, ne odgovara mi da mi naša slova zameni sa ? :((
[ Panta_ @ 07.12.2019. 15:38 ] @
Citat: Dakle, kod otvaranja oba fajla piše utf-8
Ne, piše u cp1252 a čita utf-8. Ni jedan open('w') nema definisan encoding, a na Windowsu je podrazumevano cp1252, tako da kada upisuje u fajl engleski_redovi.txt to prolazi, dok kad upisuje ( srp_red.write(f'{sr}\n'), linija 17 ) u srpski_redovi.txt tu izbacuje UnicodeEncodeError grešku. Na primer:
Code:
s = 'rečenica'
s.encode('cp1252')
UnicodeEncodeError: 'charmap' codec can't encode character '\u010d' in position 2: character maps to <undefined>
s.encode('utf-8')
b're\xc4\x8denica'
bs = s.encode('utf-8')
print(bs)
b're\xc4\x8denica'
type(bs)
bytes
bs.decode('utf-8')
'rečenica'
import encodings
encodings.aliases.aliases.values()
dict_values(['iso8859_15', 'johab', 'cp869', 'iso8859_8', 'cp1258', 'cp1140', 'mac_roman', 'gbk', 'utf_32', 'cp865', 'ptcp154',
'shift_jis', 'iso8859_9', 'euc_kr', 'latin_1', 'cp500', 'hz', 'cp1252', 'mac_roman', 'cp863', 'iso8859_8', 'ascii', 'iso8859_7', 'cp273',
'utf_8', 'cp1251', 'iso8859_10', 'bz2_codec', 'cp775', 'cp855', 'cp1125', 'iso8859_14', etc...])
encodings.aliases.aliases['utf8']
'utf_8'
Takođe ova liija: for en, ser in zip(engleski, srpski), gde su ti engleski i srpski u navedenom kodu?
Nema potrebe ni da toliko puta koristiš with, na primer:
Code (python):
import re
import csv
with open('engleski.txt', encoding='utf-8') as eng_fh, open('srpski.txt', encoding='utf-8') as srp_fh:
for eng, srp in zip(eng_fh, srp_fh):
engleski = re.split(r"(?<=\.|\?|\!)\s", eng.strip())
srpski = re.split(r"(?<=\.|\?|\!)\s", srp.strip())
with open('englesko-srpski.csv', 'a', encoding='utf-8') as csv_file:
writer = csv.writer(csv_file)
for en, sr in zip(engleski, srpski):
writer.writerow([en] + [sr])
[ a1234567 @ 08.12.2019. 03:40 ] @
Panto, hvala još jednom na hintovima.
Sad sam ispeglao kod i RADI!!!
Izgleda da sam ipak nešto naučio.
Baš lep osećaj kad bacim pogled na tabelu :))
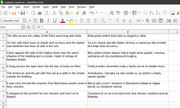
Jedina sitna začkoljica je da u svakoj ćeliji tabele na kraju teksta ima jedan LF viška. Jel mu to csv.writer ubacuje? Jer kad gledam prethodni fajl srpski_redovi.txt, tu je sve u redu. Dobro, to mogu lako da rešim u tabeli sa nađi/zameni, ali me zanima u čemu je stvar. Koliko sam guglao, kaže da bi newline='' trebalo da to reši, ali eto ne rešava. Ili nešto nisam dobro razumeo :)
Dakle, program Panta_konvertor ver. 1.0 spreman za distribuciju!
Sad ću morati da smišljam kako da ga apgrejdujem. Treba se održati na tržištu :))) [ a1234567 @ 08.12.2019. 03:46 ] @
Evo i krajni kod:
Code:
# Panta_konvertor ver. 1.0 // © Aleksandar Pantić, Kragujevac, 2019.
import re
import csv
with open('engleski.txt', encoding='utf-8', newline='') as eng, \
open('engleski_redovi.txt', 'a', encoding='utf-8', newline='') as eng_red:
for line in eng:
for en in re.split(r"(?<=\.|\?|\!)\s", line):
print(en)
eng_red.write(f'{en}\n')
with open('srpski.txt', encoding='utf-8', newline='') as srp, \
open('srpski_redovi.txt', 'a', encoding='utf-8', newline='') as srp_red:
for line in srp:
for sr in re.split(r"(?<=\.|\?|\!)\s", line):
print(sr)
srp_red.write(f'{sr}\n')
with open('englesko-srpski.csv', 'w+', encoding='utf-8', newline='') as csv_file, \
open('engleski_redovi.txt', 'r+', encoding='utf-8', newline='') as eng_red, \
open('srpski_redovi.txt', 'r+', encoding='utf-8', newline='') as srp_red:
writer = csv.writer(csv_file)
for en, ser in zip(eng_red, srp_red):
writer.writerow([en] + [ser])
[ Branimir Maksimovic @ 08.12.2019. 05:07 ] @
Znas kako se to zove? Bloat ;)
[ a1234567 @ 08.12.2019. 05:43 ] @
:)))
[ Panta_ @ 08.12.2019. 05:51 ] @
Citat: Dakle, program Panta_konvertor ver. 1.0 spreman za distribuciju!
Nemoj da ga distribuiraš pod mojim imenom molim te.
Opet imaš viška "with open". Takođe, nema potrebe za engleski_redovi.txt i srpski_redovi.txt fajlovima. Pogledaj gornji primer koji sam ti napisao, radi isti posao a duplo je kraći. [ a1234567 @ 08.12.2019. 15:32 ] @
Panto, nisi ni svestan kakvu priliku propuštaš. Imam već naručioce, distibucija samo što nije krenula :)
Dobro, modifikovaću kopirajt. © Elitesecurity Forum, 2019.
Znam, video sam tvoju verziju, ali sačuvaću i ovu moju. Nekako mi je preglednija. Sve se jasno vidi šta za čim ide.
U tvojoj je to nešto smandrljano, na brzinu. Kud žuriš? Moj kod ti je kao istorijski roman. Krene lepo od uvoda, likovi, opis prirode, istorijske okolnosti, pa lagano pređe na razradu. Ma milina jedna čitati :))))
Gledam sad, postavio sam prvu poruku na forum pre tri nedelje. I evo već (za mene veliki) rezultat, zahvaljujući naravno tebi! HVALA!
Nešto sam naučio. I to je najveća radost.
Ništa, nastavljam sa knjigom i naravno javljam se uskoro kad budem imao novu ideju za konvertor ver. 2.0.
[ @ 18.11.2022. 17:17 ] @
Da li je bolje da skinem neke knjige o Pythonu sa neta tipa:
Headfirst Python
Ili da platim Udemy/Coursera?
[ Panta_ @ 18.11.2022. 21:15 ] @
Copyright (C) 2001-2026 by www.elitesecurity.org. All rights reserved.
|