[ Ivan Dimkovic @ 16.06.2019. 17:15 ] @
| Izvor: https://neurohive.io/en/news/e...-scaling-deep-neural-networks/ Citat: In their paper “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”, researchers from Google argue that the scaling of deep neural networks should not be done arbitrarily and proposed a method for structured scaling of deep networks. They proposed an approach where different dimensions of the model can be scaled in a different manner using scaling coefficients. To obtain those scaling coefficients, they perform a grid search to find the relationship between those scaling dimensions and how they affect the overall performance. Then, they apply those scaling coefficients to a baseline network model to achieve maximum performance given a (computational) constraint. Rezultat? 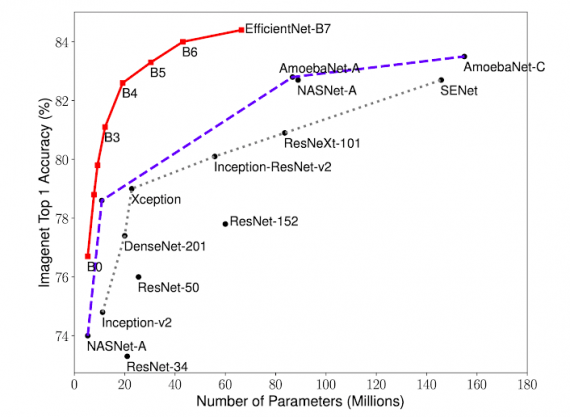 EfficientNet-B7 postize najbolje rezultate sa drasticno manjim brojem parametara. Prakticno moze da postigne iste performanse kao sledeci najbolji model sa skoro 8x manje parametara (!). Sa ovim polako ulazimo u eru gde ce inovacije u skaliranju mreza biti nalazene automatizovanim algoritmima za optimizaciju a ne nagadjanjem. EfficientNet postize 97.1% Top-5 preciznost na ImageNet datasetu u isto vreme bivajuci 8.4x manji i 6.1x brzi od Gpipe-a. Cisto poredjenja radi, AlexNet, koji je izazvao "deep learning" revoluciju pre 7 godina je dostizao 80.3% Top-5 preciznost. Uzgred, ljudi postizu 94.9% preciznost na istom datasetu. Papir: https://arxiv.org/abs/1905.11946 Model: https://ai.googleblog.com/2019...et-improving-accuracy-and.html |