Za ambiciozne pyhtoniste početnike materijala na engleskom koliko hoćeš, ali na srpskom slabo. Pa evo da ja kao isti takav početnik nešto doprinesem po tom pitanju, dok se ovi iskusniji ne reše da stvar preuzmu u svoje ruke.
U tu svrhu sam rešio da postavljam ovde zadatke iz knjige po kojoj radim, pa možda još nekom bude od koristi. Dakle, to je knjiga Al Sweigart: Automate The Boring Stuff With Python - Practical Programming For Total Beginners (No Starch Press, 2019). Da bi bilo zanimljivije, zamislio sam da postavim prvo output na ekranu koji treba da proizvede program. Na osnovu njega bi trebalo napisati kod. Naravno, u početku su to (za mnoge ovde) jednostavne stvari, ali kasnije će siguran sam naići i prave poslastice, da ne kažem korisne komplikacije :)
Koga bude zanimalo, nek postavi ovde svoje rešenje. A ja ću posle nekoliko dana postaviti i rešenje iz knjige, pa da uporedimo. Vidim da često pominju kako je isti zadatak moguće u pythonu rešiti na više načina, pa da vidimo koliko takvih rešenja ima. To je verujem odlična lekcija za proširivanje programerskih vidika :)
Eto zabave za sve prave i wannabe pythoniste. Uživajte!
[ a1234567 @ 09.12.2019. 03:04 ] @
Dobro, posle akademskog uvoda, evo i konkretnog zadatka za danas.
Zadatak broj 1: Pogađanje zamišljenog broja
Ispis ekrana je sledeći. Koji je kod?
Zamislio sam jedan broj između 1 i 20.
Šta misliš koji je?
Unesi neki broj: 4
Tvoj broj je suviše mali.
Unesi neki broj: 17
Tvoj broj je suviše mali.
Unesi neki broj: 20
Tvoj broj je suviše velik.
Unesi neki broj: 18
Tvoj broj je suviše mali.
Unesi neki broj: 19
Bravo majstore! Pogodio si moj broj u 5 pokušaja!
[ a1234567 @ 09.12.2019. 03:13 ] @
Da bi posao bio lakši, evo početnih redova koda:
# Ovo je igra pogađanja brojeva.
import random
tajniBroj = random.randint(1, 20)
print('Zamislio sam jedan broj između 1 i 20.')
E sad je pesma :)
[ mjanjic @ 09.12.2019. 23:46 ] @
To možeš i u JS u nekoliko linija koda, Python je interesantan za nešto ozbiljnije, tipa programčić koji će da predvidi koji ćeš broj uneti ako te pita da uneseš broj između 1 i 20 :)
[ a1234567 @ 10.12.2019. 00:57 ] @
E dobro, pošto nas je Janjić ohrabrio (hvala mu!), možemo da krenemo dalje.
I da ne dangubimo, evo odmah i zadatka broj 2, koji se tiče korišćenja funkcija.
Reč je o nizu brojeva nazvanom "3x+1 problem" ili "Collatzov niz" (nazvan po nemačkom matematičaru Lotharu Collatzu, 1910-1990). Ja kad sam prvi put pročitao zadatak, nije mi baš bilo jasno, jer sam još od osnovne škole alergičan na matematiku :))), ali na drugo čitanje se malo razbistrilo. A zadatak je sledeći:
Napiši funkciju u nazovi je collatz(). Ona ima jedan parametar nazvan broj. Funkcija radi tako što za neki zadati broj, ako je paran, računa broj // 2 vrednost. Ako je uneti broj neparan, tada collatz() izračunava 3 * broj + 1 vrednost.
Kad si napravio tu funkciju, napiši program koji ti omogućuje da uneseš bilo koji pozitivan integer i potom stalno poziva funkciju collatz() na taj broj, sve dok funkcija ne dobije na kraju vrednost 1.
Neverovatno ili ne, ovo radi za svaki integer, jer pre ili kasnije, koristeći ovaj metod stižemo do 1! Čak ni matematičari nemaju pojma zašto je to tako. Zato se Collatzov niz naziva i "najjednostavniji nerešivi matematički problem".
Ne zaboravi da vrednost unetu na input() kovertuješ u integer pomoću int() funkcije. Inače će ostati string vrednost.
Hint: Integer broj je paran ako broj % 2 == 0, a neparan je ako broj % 2 == 1.
I na kraju, ispis programa na ekranu je nešto ovako:
Unesi broj:
3
10
5
16
8
4
2
1
Ajd sad, srećna radnja pythonisti.
PS. Janjić može ovo da rešava i u JS (al na drugom topiku), pa da uporedimo.
[ Branimir Maksimovic @ 10.12.2019. 14:42 ] @
U matematici se konvergiranje ka nekom broju stalno koristi. Recimo najpoznatija je newton rafson metoda konvergencije tangente ka 0 zato
sto se koristi za izracunavanje deljenja preko mnozenja i sabiranja u svrhu optimizacije na Intel procesorima. Imas neki moj uradak na podforumu
programiranje u asembleru.
[ a1234567 @ 11.12.2019. 01:03 ] @
Hvala, Branimire, na poruci.
Imaš li rešenje za postavljeni zadatak?
[ Branimir Maksimovic @ 11.12.2019. 06:51 ] @
Ja rezignirano odbijam da pisem python, eto ti Rust:
Code:
fn main()->Result<(),String> {
let args:Vec<_> = std::env::args().collect();
let collatz = |n:i64|->i64 {
if n & 1 == 1 {
3*n+1
} else {
n/2
}
};
let mut n = args[1].parse::<i64>().unwrap();
while n != 1 {
println!("{}",n);
n = collatz(n);
}
Ok(())
}
Code:
~/examples >>> ./collatz 3
3
10
5
16
8
4
2
[ bojan_bozovic @ 11.12.2019. 07:21 ] @
Evo, u Adi.
Code:
with Ada.Text_IO;
with Ada.Integer_Text_IO;
use Ada.Text_IO;
use Ada.Integer_Text_IO;
procedure Collatztest is
procedure Collatz (Arg : in out Integer) is
begin
if (Arg mod 2) = 0 then
Arg := Arg / 2;
else
Arg := 3 * Arg + 1;
end if;
Ada.Integer_Text_IO.Put (Arg);
end Collatz;
Argument : Integer;
begin
Ada.Text_IO.Put_Line ("Unesi celobrojnu vrednost:");
Ada.Integer_Text_IO.Get (Argument);
while Argument /= 1 loop
Collatz (Argument);
end loop;
Ada.Text_IO.New_Line;
end Collatztest;
Moze i kao taj Rust kod da radi, malo drugaciji bi kod bio, uz Ada.Command_Line
[Ovu poruku je menjao bojan_bozovic dana 11.12.2019. u 09:14 GMT+1]
[ a1234567 @ 11.12.2019. 08:22 ] @
Citat:
Ja rezignirano odbijam da pisem python, eto ti Rust:
Branimire, ko/šta te tako rezigniralo!?
Python je baš lep jezik :)
Citat:
Evo, u Adi.
Hvala, Bojane na trudu. Nisam probao, ali verujem da radi.
Jedino se pythonisti ne oglašavaju :)
Ali dobro, dok pripale mašinu, pa dok krenu... mi već na zadatku broj 5! :))
[ Branimir Maksimovic @ 11.12.2019. 10:50 ] @
"Branimire, ko/šta te tako rezigniralo!?"
Brzina Pythona. Ako hoces nesto ozbiljno da uradis
sve moras da radis preko nekog drugog jezika.
Python koristis samo kao lepak poziva f-ja drugog jezika.
[ a1234567 @ 11.12.2019. 14:21 ] @
Dobro je, ja sam onda bezbedan. Dok ne stignem dotle, (ako ikada?) ima još dosta vode mutnim Dunavom da proteče. :)
[ Branimir Maksimovic @ 11.12.2019. 20:01 ] @
a vidi haskell tek sto je lep ;)
Code:
import System.Environment
main = do
(n:[]) <- getArgs
let callatz n = if n `mod` 2 == 0 then n `div` 2 else n * 3 + 1
go n | n /= 1 = do
print n
go $ callatz n
| otherwise = return n
go $ read n
E sad napisi ti u pitonu...
[ a1234567 @ 12.12.2019. 03:13 ] @
Pre svega je kratko, a ja volim minimalizam :)
Mada nisam siguran da je baš po standardu pisanje te petlje if - then u jednom redu. Zbog čitljivosti koda. Barem koliko sam shvatio to ne preporučuje python "pravopis".
Moje rešenje za zadatak br. 2 dajem u posebnom postu...
[ a1234567 @ 12.12.2019. 03:14 ] @
Moje rešenje za zadatak br. 2: Collatzov niz možete pronaći na ovom linku
Ima li još koje?
[ Branimir Maksimovic @ 12.12.2019. 05:17 ] @
Kad vec nitpikujes za if, ne ide ti print u collatz, to treba da bude f-ja koja obracunava vrednosti i ne radi nista vise
osim toga to radis redundantno.
[ a1234567 @ 12.12.2019. 06:19 ] @
Hvala na komentaru. Početničke greške. Kao što i dolikuje jednom pravom početniku
Bože, kako je lepo biti početnik! Rasterećen si opsesije da moraš biti savršen.
To valjda dođe kasnije
[ a1234567 @ 12.12.2019. 06:44 ] @
Evo probao da izvadim print funkciju izvan if...else statement, ali ne radi, jer naravno više ne prepoznaje promenljivu "rezultat"
Daj primer na šta konkretno misliš. Da nešto naučimo.
[ a1234567 @ 12.12.2019. 07:44 ] @
Evo stiže i zadatak broj 3: Nabrajanje!
Sasvim je jednostavan.
Unesemo četiri artikla i program ih na kraju izlista. S tim što iza svakog ubaci zarez, a pre poslednjeg artikla stavi veznik "i", kao što je i red.
Evo ispis ekrana. Boldom je označen unos, a plavim konačni ispis.
Unesi četiri artikla
prvi: so
drugi: biber
treći: hleb
cetvrti: voda so, biber, hleb i voda
Naravno, ovo u Rustu ne mož da uradiš ni u ludilu, a o Adi i Haskellu ne vredi ni govoriti :D
[ Panta_ @ 12.12.2019. 08:19 ] @
Citat:
Evo probao da izvadim print funkciju izvan if...else statement, ali ne radi, jer naravno više ne prepoznaje promenljivu "rezultat"
Daj primer na šta konkretno misliš. Da nešto naučimo.
def collatz(number: int) -> Iterator[int]:
while number != 1:
number = number // 2 if number % 2 == 0 else number * 3 + 1
yield number
try:
user_input = int(input('Enter some number: '))
for num in collatz(user_input):
print(num)
except ValueError as err:
print(f'Value must be an integer.\n{err}')
[ a1234567 @ 12.12.2019. 09:09 ] @
Ja napravio program sa 12 redova, Panta ga slupao u jednom!!!
Šta reći do -- genije!
PANTU ZA PREDSEDNIKA
[ djoka_l @ 13.12.2019. 11:36 ] @
Ja sam imao sličnu ideju kao Panta, a pošto sam manijak za testiranje, program je morao da radi ispravno bez obzira na argument. Pošto je trebalo naći sekvencu, meni je bilo logično da vratim listu...
Code: def colatz(n):
lista = [n]
try:
if (n != int(n) or n<1):
raise ValueError
except ValueError:
lista.append("Error: positive integer expected")
return lista
while (n>1):
if(n%2==0):
n=int(n/2)
else:
n=int(3*n+1)
lista.append(n)
return lista
[Ovu poruku je menjao a1234567 dana 13.12.2019. u 13:58 GMT+1]
[ a1234567 @ 13.12.2019. 12:19 ] @
Vreme leti, a mi korak po korak, stigosmo i do četvrtog zadatka.
Za ove što vole kockarnice, prava poslastica. I to besplatna. Ne moraš posle da se vadiš :)
Daklem:
Zadatak 4: Pismo/glava
Za ovu vežbu ćemo pokušati da uradimo jedan eksperiment. Ako baciš novčić 100 puta i upišeš jedno P za „pismo“ i jedno G za „glavu“, napravićeš niz koji će izgledati otprilike ovako: “PPPPGGGGPP”. Ako pitaš drugara da napiše jedan takav niz, bez bacanja novčića, verovatno će krenuti da naizmenično stavlja „glave“ i „pisma“, nešto slično ovome: “PGPGPPGPGG”, što se ljudskom oku čini kao jedan nasumičan niz. Ali on nije matematički nasumičan. Tako čovek verovatno nikada neće napisati šest „glava“ ili šest „pisama“ u nizu, iako je vrlo verovatno da se to dogodi kada zaista bacamo novčić. Mi ljudi smo predvidljivo loši u proceni kada je u pitanju nasumičnost.
E kad ovo sve znamo, tvoj je zadatak da napišeš program koji će umesto nas utvrditi koliko puta se šest „glava“ ili šest „pisama“ zaista javlja u jednom nizu od većeg broja bacanja novčića. Tvoj program će tako ovaj eksperiment podeliti u dva dela: u prvom delu generiše listu nasumično dobijenih „pisama“ i „glava“, a u drugom delu proverava ima li i koliko nizova u njemu. Sav taj kod stavi u petlju koja će ovaj eksperiment ponoviti 10.000 puta, tako da utvrdimo koji procenat bačenih novčića sadrži niz od šest „pisama“ ili „glava“. Kao hint, napomenuću da će funkcija random.randint(0, 1) dati vrednost 0 u 50% odsto slučajeva, a vrednost 1 u ostalih 50% slučajeva.
Možeš krenuti od ovog obrasca:
Code: import random
brojNizova = 0
for brojEksperimenata in range(10000):
# Kod koji pravi listu od 100 glava/pismo vrednosti.
# Kod koji proverava postoji li niz od 6 „pisama-glava“.
print('Šanse za niz: %s%%' % (brojNizova / 100))
Naravno, ovo je samo procena, ali 10.000 pokušaja je solidan uzorak.
Ukoliko znaš matematiku, mogao bi da izračunaš procente i uštediš sebi muku pisanja programa. Ali opšte je poznato da su programeri vrlo loši matematičari.
[ djoka_l @ 13.12.2019. 23:16 ] @
Programeri MORAJU da znaju verovatnoću i još neke grane matematike (na primer algebru, logiku i teoriju skupova).
Pošto su bacanja novčića međusobno nezavisni događaj, svako bacanje ima verovatnoću od 1/2 da padne pismo ili glava.
U prvom bacanju u nekom nizu verovatnoća je 1 da će pasti pismo ili glava (siguran događaj), u svakom sledećem bacanju vefrovatnoća da će pasti ista strana kau u prvom je 1/2, pa je verovatnoća da će pasti 6 puta za redom ista strana 1/32 (32=2**5), odnosno u 100 bacanja očekuje se približno tri niza od po šest pisama ili glava (100/32 = 3.125)
Moj profesor programiranja sa faksa je imao običaj da kaže: "Čuvaj se Monte Karla, kako grada, tako i metode".
Ako te zanima verovatnoća, evo jednog malo težeg zadatka sa https://projecteuler.net/ (zadatak 205)
Aca ima 9 četvorostranih kockica za igru (tetraedara) na čijim su stranicama brojevi 1,2,3 i 4
Boban ima 6 šestostranih (normalnih) kockica sa brojevima 1-6 na stranama.
Aca i Boban bacaju istovremeno kockice i pobednik je onaj koji dobije veći zbir.
Koja je verovatnoća da će Aca da pobedi? Dati verovatnoću na 7 decimala.
rešenje je 0.5731441
Zadatak je rangiran sa težinom 15% (zadaci imaju težinu od 5-100% u koracima po 5)
[ a1234567 @ 14.12.2019. 02:23 ] @
Ne znam šta moraju, ali eto Sweigart kaže da slabo znaju :)
A završio je i sam computer science.
Inače, deluje mi kao jedna baš zanimljiva personality
pre svega zato što je toliko stvari postavio na svom sajtu besplatno
Zanimljiv ti je taj sajt sa problemima koji si linkovao. Vidim prvi problem rešilo skoro milion ljudi. Međutim, kako dalje, rapidno opada broj.
Inače, bacao novčić po 100 puta i evo rezultata iz tri serije:
1 glava u nizu - 12
1 pismo u nizu - 5
2 glave u nizu - 7
2 pisma u nizu - 12
3 glave u nizu - 4
3 pisma u nizu - 6
4 glave u nizu - 1
5 pisama u nizu - 1
6 pisama u nizu - 1
----------------------
1 glava u nizu - 17
1 pismo u nizu - 14
2 glave u nizu - 5
2 pisma u nizu - 11
3 glave u nizu - 3
3 pisma u nizu - 1
4 glave u nizu - 1
5 pisama u nizu - 1
8 glava u nizu - 1
8 pisama u nizu - 1
-----------------------
1 glava u nizu - 13
1 pismo u nizu - 10
2 glave u nizu - 6
2 pisma u nizu - 8
3 glave u nizu - 2
3 pisma u nizu - 5
4 glave u nizu - 3
4 pisma u nizu - 1
5 pisama u nizu - 1
7 glava u nizu - 1
[ a1234567 @ 15.12.2019. 03:41 ] @
Dok čekamo odgovore ambicioznih pythonista, imam jedno pitanje.
Danas na Sololearn challenge jedno od pitanja je bilo sledeće:
x = [[0], [1]]
print(len('a'.join(list(map(str, x)))))
rešenje je 7
Međutim, meni nikako nije jasno kakva je to magija u pitanju.
Jel može neko da razjasni misteriju?
Pre svega mi ovo "map" zadaje problem, jer ne razumem šta ovde radi. Gledao nek primere i objašnjenje, ali nije mnogo pomoglo u ovom slučaju.
[ tuxserbia @ 15.12.2019. 11:32 ] @
Možda te zbunjuju duple, namerno stavljene uglaste zagrade?
Probaj primer bez njih
Code:
x = [0, 1]
Ako te zbunjuje kompletna linija, uvek možeš da razdvojiš funkcije koje pozivaš
Code:
x = [[0], [1]]
print(len('a'.join(list(map(str, x)))))
x = [[0], [1]]
print('a'.join(list(map(str, x))))
x = [[0], [1]]
print(list(map(str, x)))
[ Panta_ @ 15.12.2019. 11:41 ] @
Citat:
Pre svega mi ovo "map" zadaje problem, jer ne razumem šta ovde radi.
Izvršava str za svaku stavku iz liste x, npr. str(x[0]), str(x[1]).
Koliko je python pozajmio iz funkcionalnog ptogramiranja:
Code:
{- x = [[0], [1]]
print(len('a'.join(list(map(str, x))))) -}
main = do
let x = [[0],[1]]
print $ concat $ "a":map show x
[ Branimir Maksimovic @ 15.12.2019. 12:20 ] @
Samo sto Haskell to moze na vise nacina:
Code:
main = do
let x = [[0],[1]]
(print.length.concat) $ "a":map show x
ili ovako:
Code:
main = do
let x = [[0],[1]]
(print.length) $ 'a':(concat $ map show x)
[ a1234567 @ 15.12.2019. 16:41 ] @
Citat:
tuxserbia:
Možda te zbunjuju duple, namerno stavljene uglaste zagrade?
Probaj primer bez njih
x = [0, 1]
Razumeo sam da se radi o listi koja u sebi ima dve liste od jednog člana.
Ako uklonim zagrade, onda je to jedna lista [0, 1] i rezultat je drugačiji:
0a1
len = 3
Citat:
Ako te zbunjuje kompletna linija, uvek možeš da razdvojiš funkcije koje pozivaš
Odlična ideja. Hvala!
Code:
x = [[0], [1]]
print(list(map(str, x)))
>>> ['[0]', '[1]']
Code:
print('a'.join(list(map(str, x))))
>>> [0]a[1]
i na kraju:
Code:
print(len('a'.join(list(map(str, x)))))
>>>7
Pa jel moguće da ga na kraju čita kao string '[0]a[1]' koji ima 7 karaktera!?
[ sneguljko @ 15.12.2019. 19:05 ] @
Gledam ovo pa me sramota koliko malo znam. Tri dana sam učio payton, dobio online sertifikat.... i MISLIO SAM da nešto znam. Bruka. Moram još da bistrim vodu. Sad ću jednu fuka vruću pa da se bacim na video tutorijale ili pdf na srpskom, videću. :) :(
[ a1234567 @ 16.12.2019. 01:51 ] @
Ako ti je za utehu, nisi jedini.
Ali dan po dan, naučićemo i nas dvojica nešto. :)
Evo vežbe radi jedan ne suviše težak zadatak:
Napravi program u kojem korisnik prvo unese tri integera, a potom ih program ispiše sortirane po veličini (od najmanjeg do najvećeg). Koristi min i max funkciju da nađeš najmanji i najveći broj. Srednju vrednost ćeš utvrditi računajući zbir sve tri vrednosti i onda od njega oduzeti najmanju i najveću.
Eto, probaj pa da vidimo kakva ćemo rešenja pronaći.
Ako zapne, a neće, ja sam moje rešenje stavio ovde:
[Ovu poruku je menjao a1234567 dana 16.12.2019. u 03:27 GMT+1]
[ Branimir Maksimovic @ 16.12.2019. 07:30 ] @
Hm malo mi je to glupo da prvo racunas zbir 3 vrednosti a onda da oduzimas dve. Zar srednja vrednost nije sum(niz)/len niz?
[ a1234567 @ 16.12.2019. 08:09 ] @
Koliko ja razumem, tvojim metodom ćemo dobiti srednju vrednost
4 + 7 + 8 = 19 / 3 = 6.3333
a nama treba srednji broj po veličini, dakle 7
[ Branimir Maksimovic @ 16.12.2019. 08:21 ] @
ako znas najmanji i najveci preostali je srednji, ne treba ti tu nikakva matematika...
[ sneguljko @ 16.12.2019. 08:39 ] @
brano malo si zabrazdio, to je aritmetička sredina a ne traženi broj.
[ sneguljko @ 16.12.2019. 08:59 ] @
Rešio sam problem na identičan način :) Idemo nešto teže.
[ Branimir Maksimovic @ 16.12.2019. 09:31 ] @
Citat:
sneguljko:
brano malo si zabrazdio, to je aritmetička sredina a ne traženi broj.
Ma sad vidim ne znas koji je od a, b, c pa moras da racunas ;)
[ Branimir Maksimovic @ 16.12.2019. 09:32 ] @
Aj sad na ovu temu od n unetih brojeva naci max min i srednji ;)
To je malo teze ;)
[ sneguljko @ 16.12.2019. 09:47 ] @
0.o
uuuu al teškooooooo...
[ a1234567 @ 16.12.2019. 10:10 ] @
Code: Sneguljko:
Rešio sam problem na identičan način :) Idemo nešto teže.
Idemo
Štampanje tabele
Napiši funkciju printTabela() koja uzima listu lista stringova i prikazuje je na ekranu, tako da je svaka kolona pravilno poravnata udesno. Pretpostavićemo da svaka od unutrašnjih lista ima isti broj stringova. Na primer, vrednosti mogu ovako da izgledaju:
Tvoja printTabela funkcija treba da isprinta sledeće:
Hint: Tvoj kod treba prvo da nađe koji je najduži string u svakoj od unutrašnjih lista, tako da bi kolona bila dovoljno široka da taj string stane u nju. Tu maksimalnu širinu svake kolone možeš da sačuvaš kao listu integera. printTabela() funkcija može da počne sa kolShir = [0] * len(podaciTabela), što će napraviti listu koja sadrži isti broj 0 vrednosti koliko ima i unutrašnjih lista u podaciTabela. Na taj način kolShir može da širinu najdužeg stringa smesti u podaciTabela[1] i tako dalje. Potom možeš da nađeš najveću vrednost u kolShir listi, kako bi utvrdio koji integer za širinu treba da proslediš rjust() string metodu.
Ajd sad...
[ Branimir Maksimovic @ 16.12.2019. 11:00 ] @
Evo u haskell-u, jer moze krace u pythonu ;)?
Code:
import qualified Data.Text as T
import Data.List
main = do
let podaciTabela = [["Panta", "Branimir", "Sneguljko", "a1234567"],
["python", "haskell", "turbo pascal", "cbasic"],
["profi nivo", "srednji nivo", "osnovni nivo", "nema nivo"]]
let maxlen :: Int
maxlen = foldl (\m x->max m $ maximum $ map length x) 0 podaciTabela
mapM_ (\x -> do mapM_ (\x->putStr $ (T.unpack $ T.justifyRight maxlen ' ' $ T.pack x) ++ " ") x
putStrLn "") $ transpose podaciTabela
Code:
~/examples/haskell >>> ./tabela
Panta python profi nivo
Branimir haskell srednji nivo
Sneguljko turbo pascal osnovni nivo
a1234567 cbasic nema nivo
[ a1234567 @ 16.12.2019. 11:05 ] @
Ne može. Nema šanse.
Prebacićemo te na profi nivo
[ sneguljko @ 16.12.2019. 14:35 ] @
teško. Ja sad vidim da je python suva matematika, a ja sam hteo da pravim prozore i nešto da mi skačka u okviru.
[ a1234567 @ 16.12.2019. 14:51 ] @
Nema u ovom zadatku matematike, samo slova, abeceda, a može i azbuka :)
[ Branimir Maksimovic @ 16.12.2019. 15:04 ] @
Citat:
sneguljko:
teško. Ja sad vidim da je python suva matematika, a ja sam hteo da pravim prozore i nešto da mi skačka u okviru.
Ako nekoga interesuje kako da se reši moj zadatak (euler.net zaadatak 205), postaviću ovde jedno moguće rešenje.
Ko još uvek želi da pokuša da ga reši, neeka preskoči ovaj post
Code:
#frequency of posible sums for 4 and 6 dices games
dice4sum = 36*[0]
dice6sum = 36*[0]
for d1 in range (1,5):
for d2 in range (1,5):
for d3 in range (1,5):
for d4 in range (1,5):
for d5 in range (1,5):
for d6 in range (1,5):
for d7 in range (1,5):
for d8 in range (1,5):
for d9 in range (1,5):
s = d1+d2+d3+d4+d5+d6+d7+d8+d9
dice4sum[s-1] += 1
for d1 in range (1,7):
for d2 in range (1,7):
for d3 in range (1,7):
for d4 in range (1,7):
for d5 in range (1,7):
for d6 in range (1,7):
s = d1+d2+d3+d4+d5+d6
dice6sum[s-1] += 1
partsum = 0
#win probability for 4 dices player is:
#frequency of outcome n when 6 dices player has outcome lese then n
#divided by product of both total outcomes
for i in range (1,36):
#calculate running sum of 6 dices games
dice6sum[i] += dice6sum[i-1]
#number of outcomes when player with 4 dices wins
partsum += dice4sum[i]*dice6sum[i-1]
#print(dice4sum)
#print(dice6sum)
#print(partsum)
print(round(partsum/(4**9*6**6),7))
[ Panta_ @ 16.12.2019. 20:27 ] @
Citat:
Branimir Maksimovic:
Evo u haskell-u, jer moze krace u pythonu ;)?
Code:
import qualified Data.Text as T
import Data.List
main = do
let podaciTabela = [["Panta", "Branimir", "Sneguljko", "a1234567"],
["python", "haskell", "turbo pascal", "cbasic"],
["profi nivo", "srednji nivo", "osnovni nivo", "nema nivo"]]
let maxlen :: Int
maxlen = foldl (\m x->max m $ maximum $ map length x) 0 podaciTabela
mapM_ (\x -> do mapM_ (\x->putStr $ (T.unpack $ T.justifyRight maxlen ' ' $ T.pack x) ++ " ") x
putStrLn "") $ transpose podaciTabela
Code:
~/examples/haskell >>> ./tabela
Panta python profi nivo
Branimir haskell srednji nivo
Sneguljko turbo pascal osnovni nivo
a1234567 cbasic nema nivo
Ajde da probam sa dve linije Python koda:
Code: for row in zip(*podaciTabela):
print(' '.join(s.rjust(len(max(map(lambda x: x[1], podaciTabela)))) for s in row))
Panta python profi nivo
Branimir haskell srednji nivo
Sneguljko turbo pascal osnovni nivo
a1234567 cbasic nema nivo
[ Branimir Maksimovic @ 17.12.2019. 02:46 ] @
Samo sto ne odredjuje maksimalnu duzinu svih, nego samo duzinu jedne kolone...
[ a1234567 @ 17.12.2019. 02:54 ] @
Panto, hajde objasni taj kod. Sve si smućkao u jedan red, ko palačinku kad zaviješ. Protresi to malo
Sad gledam, lambda je no-name privremena funkcija, ali šta ti je ovo [1] pored x, koji deo podaciTabela to obuhvata? Liči mi na index kod liste, ali zašto baš 1? Ovako mi izgleda kao da mapira samo drugi član u svakoj listi. Jel to zato što odokativno vidiš da je "turbo pascal" najduži string, pa ne proveravaš ostale članove liste?
Ostalo ovako razumem: map mu kaže da funkciju primeni na svaki član liste podaciTabela. I funkcija ide kroz drugi član svake liste. max vraća najveću vrednost u iteratoru (ako mu je to pravi srpski prevod?), dakle, najduži string. len daje broj karaktera tog najdužeg stringa. rjust poravnava udesno za toliko koliko je dužina + onaj jedan spejs ' ' na početku. Ali šta ti je ovaj s? Verovatno frljoka varijabla, koja se pojavljuje i na kraju i preko row povezuje ime funkcije u prvom redu sa njenim statement u drugom. join valjda dodaje taj jedan spejs svakom članu iteratora, tj. svakom članu tabele.
zip pravi tuple spajajući prve, druge, treće itd. članove različitih iteratora.
Ovako kad razložim mi je ponešto i jasno. Ali nema šanse da to ovako sklopim
[ Branimir Maksimovic @ 17.12.2019. 03:21 ] @
"ali zašto baš 1?"
Zato sto je u toj koloni najveca duzina, sto nije resenje zadatka. Trazi se maksimalna duzina svih ne samo jedne kolone.
[ a1234567 @ 17.12.2019. 03:37 ] @
Ma fušerira Panta. Odmah sam ga provalio :)
[ sneguljko @ 17.12.2019. 07:57 ] @
vi ste krejzi, meni mozak ne radi tako napredno. Mora da ste napredni.
------------------
Jel može sad neko da kaže, šta mi treba da se program hello world izvrši u prozoru a ne u terminalu. Jel komplikovano?
[Ovu poruku je menjao sneguljko dana 17.12.2019. u 09:59 GMT+1]
[ a1234567 @ 17.12.2019. 09:27 ] @
Kakvom terminalu?
Pa koristiš neki interpreter, ne terminal. Jednostavno je.
Sa instalacijom pythona valjda ide i IDLE interpreter ili shell. U njemu kucaš komande i u njemu se i izvršavaju.
Naravno kad je više linija, lakše je ukucati sve u običnom text fajlu. Za to ideš u IDLE meniju gore File > New (ili ctrl + N)
i otvoriš prazan fajl, kucaš (ako znaš šta) i u meniju Run > Run Module (ili F5) pokreneš program u IDLE i vidiš koju ti grešku javlja
Možeš i da instaliraš neki drugi interpreter. Vrlo je jednostavan ovaj
Mož da probaš online ili gore link za Download, pa instaliraš. I onda... pesma
Srećno!
[ sneguljko @ 17.12.2019. 09:56 ] @
ja sam na linuxu, sve ide preko terminala. Mislio sam eto da nacrtam jedan krug :) Kako ćeš tu kad je loša rezolucija.
---
vidi ovoooo :)
Code:
import turtle
t = turtle.Turtle()
t.circle(50)
[ a1234567 @ 17.12.2019. 10:03 ] @
Onda će morati linux majstori da te remontuju.
Ja sam prozordžija.
[ sneguljko @ 17.12.2019. 10:07 ] @
Od početka sam znao da ti nešto fali
[ Deunan @ 17.12.2019. 14:08 ] @
Citat:
sneguljko:
vi ste krejzi, meni mozak ne radi tako napredno. Mora da ste napredni.
------------------
Jel može sad neko da kaže, šta mi treba da se program hello world izvrši u prozoru a ne u terminalu. Jel komplikovano?
Treba ti neki compiler. Ja volim pyinstaller. Pyinstaller koristim na windowsu, nisam isprobavao na linuxu, ali bi trebalo da radi potpuno isto. Na kojem ga sistemu kompajliras, na tom ce da radi.
Ako koristis python 3.8, pyinstaller iz pip repo-a ima neki bug, skini ga ovako:
Pyinstaller ce sve da spakuje u jedan fajl u "dist" folderu (kreirace sam). U tom fajlu ti je ceo program i sve python skripte za izvrsenje. Ne moras da instaliras python na drugom sistemu da bi pokrenuo program. Kreirace i fajl "myapp.spec" gde mozes da podesavas: ikonu programa, fajlove koje da includuje...
Da bi imao graficke elemente (dugmice, input, select...), treba ti neka GUI biblioteka. Ja volim PyQt, imas jos Tkinter, Kiwi, ... (moraces sam da odlucis koja ti odgovara. Kao da nekog pitas sta je bolje: react.js, vue.js, angular...). Posto je Tkinter vec deo python-a, najbolje pocni malo sa njim. Recimo, kreiraj fajl myapp.py i kopiraj kod:
I pokreni. Kod je prilicno jednostavan, ali ako si ikad radio neki front end (javascript, android sdk, swift, kotlin...) vrlo lako bi trebalo da razumes kako funkcionise. Kad budes zavrsio, zapakuj ga:
Code: pyinstaller myapp.py --onefile
[ gglavni @ 17.12.2019. 16:13 ] @
@Deunan
Izvinjavam se, promenio sam nik jer sam imao problem, zaboravio sam mail, ja sam sneguljko.
[ Deunan @ 17.12.2019. 16:48 ] @
Kad hoces da instaliras python pakete ne ulazis u python shell. Samo otvoris cmd ili powershell i kucas.
"pip" je packet manager, kao composer za php, ili npm za js.
Vrati se jos malo na pocetne stvari, ne vredi preskakati osnove, samo ces da se pogubis. Znam da nekad zelis samo da "krenes da radis", ali cesto to oduzima vise vremena nego da se uci redom. Sve je to jednostavno.
Tkinter mozes da koristis bez instaliranja ako te interesuju desktop aplikacije. Prekopiraj gornju skriptu i pokreni program kao i do sad sto si radio.
[ gglavni @ 17.12.2019. 17:02 ] @
Hvala. Nisam dodao putanju u PATH, pip mi je već bio instaliran, ali ko što kažem problem je bio path do njega.
Sad ću da probam program.
---
radi ovaj prozorčić. Ali me nervira pyinstaller ovaj, trebao bi hello world da convertuje u exe valjda... Neće. a i "auto py to exe" neće da se instalira, izgleda da je problem verzija 3.8 pythona, pa još nisu sredili, možda sam trebao da instaliram stariju verziju pythona.
[Ovu poruku je menjao gglavni dana 17.12.2019. u 18:16 GMT+1]
[ gglavni @ 17.12.2019. 19:22 ] @
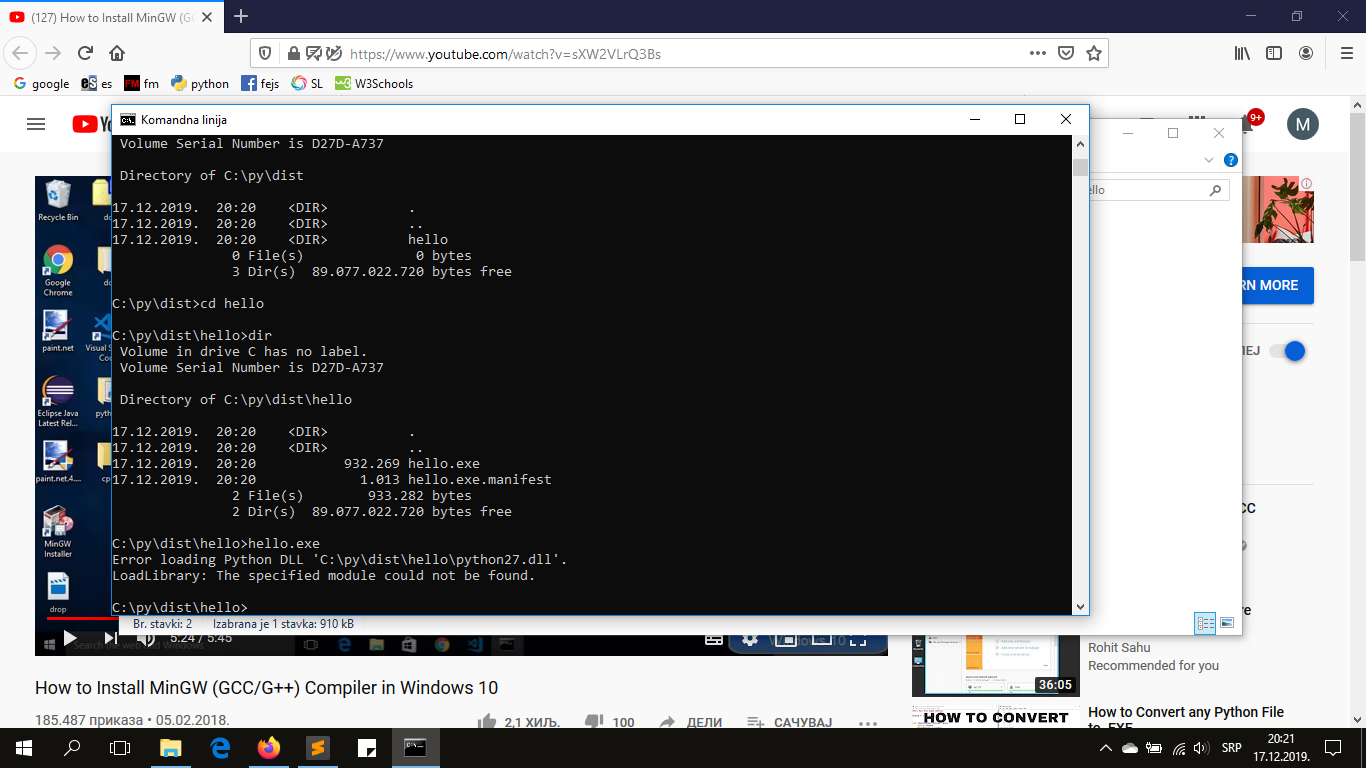
I šta je sad ovo??? Ne može običan hello world da kompajlira...
evo slike, gde grešim, pomagajte.
[ Deunan @ 17.12.2019. 20:54 ] @
Zasto koristis python 2.7?
To je skoro drugi jezik i bukvalno se "penzionise" za 14 dana . Debagovati to nema nikakvog smisla.
[ gglavni @ 17.12.2019. 21:12 ] @
na 3.8 mi još gore radi. Probaću ponovo 3.8 ali izlaze mi silne crvene greške kad nešto kompajliram.
---
nisam zabeležio koje, ali probao sam ovako, instalirao sam pyinstaller i to je dobro prošlo, a onda 'pyinstaller helloworld.py' iz komandne linije i krene da kompajlira i silne greške, probaću sutra za danas je dosta.
[ Deunan @ 17.12.2019. 21:44 ] @
Kako si instalirao pyinstaller?
Ako si instalirao standardno "pip install pyinstaller", ima neki bug.
Moraces da uninstaliras "pip uninstall pyinstaller" pa da instaliras ovako:
P.S. Uostalom, sto ne vrati na python 3.7, gde nadje 2.7. Ima 10 godina.
[Ovu poruku je menjao Deunan dana 17.12.2019. u 22:57 GMT+1]
[ gglavni @ 17.12.2019. 21:55 ] @
Evo sad probam tako kao što si rekao. Javljam za koji minut.
----
RADI !!!
kad udjem u dist folder onda radi. To je izgleda ceo program a ne samo jedan fajl. Probao sam da ga prebacim van foldera, onda ne radi. Ukapirao sam suštinu.
p.s. Deunan imaš piće od mene. A svakako će koristiti svima, po jedan dinar svako. :)
p.s.2 Hebi ga vratih na 2.7 kao prosto program manje zahtevan, a ono karambol. Valjda će da isprave grešku na default instaliranom pyinstalleru, inače mora svako da gituje.
[ Deunan @ 17.12.2019. 22:02 ] @
Ako hoces jedan fajl moras da uneses --onefile:
Code: pyinstaller myapp.py --onefile
[ gglavni @ 17.12.2019. 22:09 ] @
E strava. Čovek si nema dalje.
[ a1234567 @ 19.12.2019. 08:48 ] @
Pošto je sve instalirano što se instalirati može, da se vratimo na zadatak 4, koji je još uvek pending
Zadatak 4: Pismo/glava
Za ovu vežbu ćemo pokušati da uradimo jedan eksperiment. Ako baciš novčić 100 puta i upišeš jedno P za „pismo“ i jedno G za „glavu“, napravićeš niz koji će izgledati otprilike ovako: “PPPPGGGGPP”. Ako pitaš drugara da napiše jedan takav niz, bez bacanja novčića, verovatno će krenuti da naizmenično stavlja „glave“ i „pisma“, nešto slično ovome: “PGPGPPGPGG”, što se ljudskom oku čini kao jedan nasumičan niz. Ali on nije matematički nasumičan. Tako čovek verovatno nikada neće napisati šest „glava“ ili šest „pisama“ u nizu, iako je vrlo verovatno da se to dogodi kada zaista bacamo novčić. Mi ljudi smo predvidljivo loši u proceni kada je u pitanju nasumičnost.
E kad ovo sve znamo, tvoj je zadatak da napišeš program koji će umesto nas utvrditi koliko puta se šest „glava“ ili šest „pisama“ zaista javlja u jednom nizu od većeg broja bacanja novčića. Tvoj program će tako ovaj eksperiment podeliti u dva dela: u prvom delu generiše listu nasumično dobijenih „pisama“ i „glava“, a u drugom delu proverava ima li i koliko nizova u njemu. Sav taj kod stavi u petlju koja će ovaj eksperiment ponoviti 10.000 puta, tako da utvrdimo koji procenat bačenih novčića sadrži niz od šest „pisama“ ili „glava“. Kao hint, napomenuću da će funkcija random.randint(0, 1) dati vrednost 0 u 50% odsto slučajeva, a vrednost 1 u ostalih 50% slučajeva.
Ja sam sa ovo malo znanja uspeo da napravim prvi korak, to jest da izlistam prvih 100 bacanja:
Code: import random
print('Koliko puta da bacim novčić?')
while True:
odgovor = input()
if odgovor.isdecimal():
brojBacanja = int(odgovor)
break
for i in range (1, brojBacanja):
if random.randint(0, 1) == 0:
baci = '1glava'
else:
baci = '0pismo'
print(baci[0], end='')
i dobijem ovaj ispis na ekranu:
Koliko puta da bacim novčić?
100
011011011111111010011101101011011111000000001000110111011110010010010110100101111101110001101001000
E sad kako dalje? Kako da u ovom nizu od 100 bacanja izbrojim nizove od 6 ponavljanja!?
[ gglavni @ 19.12.2019. 11:53 ] @
lako je tebi da čitaš zadatke iz knjiga koji imaju rešenja i onda nas ovde tovariš. Ja još nisam ni junior ja sam jaje, a dal sam mućak ili plodonosno, videćemo za koji mesec kad malo proučim još knjige. Zeza me to što nemam strpljenje pa učim i C++ istovremeno.
print('Koliko puta da bacim novčić?')
while True:
odgovor = input()
if odgovor.isdecimal():
brojBacanja = int(odgovor)
break
with open('pismo_glava.txt', 'a+') as file:
for i in range (1, brojBacanja):
if random.randint(0, 1) == 0:
baci = '1'
file.write(baci)
else:
baci = '0'
file.write(baci)
file.close()
with open('pismo_glava.txt', 'r') as file:
data = file.read()
Koliko puta da bacim novčić?
100000
Broj glava je: 800
Broj pisama je: 796
Ovaj kod bi sigurno mogao u tri reda da se spakuje.
Ali meni apsolutnom početniku srce puno i ovako kad sam ga rešio :)))
[ Deunan @ 19.12.2019. 18:26 ] @
Nema potrebe da kod pakujes u 2, 3... reda. Mnogo je vaznije da je razumljiv i efikasan.
Ti si verovatno zapisivao u fajl zato sto si to prethodno naucio :) Sto neko rece, "ako jedino znas da koristis cekic, svaki problem ti izgleda ko ekser".
Evo jedno resenje koje ce da razume i neko ko ne poznaje python, a koristi samo jednu "for" petlju:
Code: import random
brojNizova = 0 # broj nizova od 6 istih
trenutniStatus = 0 # prethodni bacen status, pismo ili glava (0 ili 1)
brojPonavljanja = 0
for i in range(10000):
rand = random.randint(0, 1)
if trenutniStatus == rand:
brojPonavljanja += 1
else:
trenutniStatus = rand
brojPonavljanja = 1
if brojPonavljanja == 6:
brojNizova += 1
brojPonavljanja = 0
print(f"Broj nizova: {brojNizova}")
[ a1234567 @ 20.12.2019. 01:33 ] @
Hvala na komentaru.
Zapisivao sam u fajl zato što nisam znao kako da posle te petnje dobijeni niz nula i jedinica stavim u neku varijablu,
pa da prebrojavam nizove sa count.
Bogami sam se i oko tog zapisivanja namučio dok nisam prokljuvio, ali sam tako valjda nešto i naučio.
Ono što mene buni kod tvog koda je da mi se čini da on broji samo niz od 6 ponavljanja, ili nula ili jedinica,
a ne pravi razliku koliko jednih koliko drugih.
Druga stvar o kojoj sam počeo da razmišljam kad sam napravio ovaj moj kod je kako da ga apdejujem :))
Naime, ako imam string
0011101011110000000101011111000111111111110000011
kako da pronađem koliko u njemu ima nizova od recimo 2, 3, 4, 5 i 6 istih karaktera?
Naravno, mogao bih sa
print('Broj glava je:', data.count('00'))
print('Broj glava je:', data.count('000'))
print('Broj glava je:', data.count('0000'))
print('Broj glava je:', data.count('00000'))
pa isto za jedinice, ali mora da ima neke elegantnije rešenje.
[ a1234567 @ 20.12.2019. 08:03 ] @
Moram da se podelim događaj
Danas naiđem na rečenicu
“MAN IS A ROPE
STRETCHED
BETWEEN THE
ANIMAL AND
THE SUPERMAN –
A ROPE OVER
AN ABYSS.”
Friedrich Nietzsche, Thus Spoke Zarathustra
koja mi treba, ali napisana redovno, a ne velikim slovima.
Ništa, šta ću, otvorim dokument i krenem da je prekucam. Posle prve reči zastanem i "programer" u glavi mi kaže... alo, prijatelju, šta to radiš!? pa jesmo već zaboravili na x.lower()!
I konvertujem je programski. Niko srećniji od mene, kez od uveta do uveta.
Posle pogledam, ima i funkcija capitalize. Sad sam i nju naučio.
Svakog dana u svakom pogledu...
[ Panta_ @ 20.12.2019. 09:51 ] @
Citat:
Naime, ako imam string
0011101011110000000101011111000111111111110000011
kako da pronađem koliko u njemu ima nizova od recimo 2, 3, 4, 5 i 6 istih karaktera?
Code: for i in range(2, 7):
print(f"{'0' * i} = {'0011101011110000000101011111000111111111110000011'.count('0' * i)}")
Ova tema, od kada sam je otvorio pre deset dana ima skoro 2500 pregleda.
Izgleda ima dosta onih koji gledaju sa strane, ali se ne hvataju tastature
Ne stidite se, slobodno se uključite, od mene sigurno više znate. Ja učim python eto cele dve nedelje
I zato evo nova šansa i novi zadatak za ove što vole da šifriraju i hakerišu!
Zadatak broj 5: Cezarova šifra
Jedan od prvih poznatih primera šifriranja koristio je Julije Cezar. Slao je pisana naređenja svojim generalima, ali nije želeo da ona padnu u neprijateljske ruke. Zato je razvio sistem koji će kasnije biti nazvan Cezarova šifra. A ideja je bila sasvim jednostavna (i zato je ovako kodiran tekst lako dešifrovati savremenim tehnikama), a sastojala se u tome da se svako slovo u originalnoj poruci pomeri za tri mesta u abecedi. Tako A postaje D, B postaje E, C postaje F itd. Poslednja tri slova abecede se tako pomeraju na početak, pa X postaje A, Y postaje B, a Z postaje C. Znakovi interpunkcije su ostajali nepromenjeni. Naravno, mi ćemo koristiti našu latinicu:
abcčćddžđefghijklljmnnjoprsštuvzž
Napiši program koji rešava Cezarovu šifru. Korisnik unosi poruku i broj slova za koliko će biti pomeranje kod šifriranja. Program zatim ispisuje šifriranu poruku. Vodi računa da program šifrira i velika i mala slova. Tvoj program bi takođe trebalo da podržava pomeranje za negativan broj, tako da može i da kodira i da dekodira poruke.
Ajde sad. Lako je )
[Ovu poruku je menjao a1234567 dana 20.12.2019. u 18:14 GMT+1]
[ BogOtac @ 20.12.2019. 16:22 ] @
Mene zanima (da vi mene kažete) zašto, kad kompajliram program u .exe jako sporo se pokreće.
[ a1234567 @ 20.12.2019. 16:39 ] @
Imam i ja jedno pitanje za tebe.
Što ne otvoriš posebnu temu, pa pitaš, ko što je red?
Ova je za zadatke, kao što piše na ulazu :)
[ BogOtac @ 20.12.2019. 16:45 ] @
Pa zgodno mi je ovde, pre će da vide ljudi. :)
[ a1234567 @ 21.12.2019. 16:25 ] @
Evo izborih se nekako sa ovim zadatkom, doduše polovično.
Code: # Cezarova šifra
poruka = input('Unesi poruku: ')
pomeranje = input('Za koliko mesta pomeriti slova? ')
for i in poruka:
if i in abc:
ind = abc.index(i)
ind2 = ind + int(pomeranje)
if ind2 > 26:
ind2 = ind2 - 30
else:
ind2 = ind2
slovo = abc[ind2]
print(slovo, end='')
else:
i == i
slovo = i
print(slovo, end='')
Ispis na ekranu:
>>> Unesi poruku: Ovo je poruka.
>>> Za koliko mesta pomeriti slova? 4
Obš mi tšuanć.
>>> Unesi poruku: Obš mi tšuanć.
>>> Za koliko mesta pomeriti slova? -4
Ovo je poruka.
Radi i šifrovanje i dešifrovanje.
Ali postoji problem sa našim slovima koja imaju dva znaka: lj, nj, dž.
Jer petlja ide slovo po slovo, pa ih tretira odvojeno kod dešifrovanja.
Jedino da se dopisujemo na engleskom :=))
[ djoka_l @ 22.12.2019. 14:48 ] @
Ovaj tvoj program je loš po toliko mnogo osnova, da će objašnjenje šta je loše biti mnogo duže od samog programa.
Nemoj ovo da shvatiš kao napad na tvoju ličnost, nadam se da ćeš iz ovoga nešto da naučiš
Da krenem redom:
Code: ind2 = ind + int(pomeranje)
je bezveze, jer u svakom prolazu kroz petlju ponovo radiš konvertovanje u int. Umesto toga, dovoljno je da to uradiš jednom, pre petlje
Code: pomeranje = int(input('Za koliko mesta pomeriti slova? '))
Code: else:
ind2 = ind2
je besmisleno, uopšte ti ne treba taj else. if može da bude i bez else dela
Code: ind = abc.index(i)
ind2 = ind + int(pomeranje)
if ind2 > 26:
ind2 = ind2 - 30
else:
ind2 = ind2
slovo = abc[ind2]
print(slovo, end='')
je višestruko loše. Bezveze koristiš varijable ind, ind2 slovo. Koristiš ono što se zove "magični brojevi". Imaš 26 i 30, a na oba mesta treba da bude 30. Python oprašta greške i dozvoljava negativne vrednoste indeksa, ali samo pukim slučajem program radi.
Code: else:
i == i
slovo = i
print(slovo, end='')
Uh, "i==i" - ZAŠTO TO PIŠEŠ??? čak i da si hteo da napišeš i=i to ti ne treba. Zar nije jednostavnije da samo staviš print(i, end='')
Evo tvog programa, bez ulaženja u ispravku logike, koji radi isto što i tvoj kod, samo malo ispravnije:
Code:
# Cezarova šifra
poruka = input('Unesi poruku: ')
pomeranje = int(input('Za koliko mesta pomeriti slova? '))
abc = 'abcčćdđefghijklmnoprsštuvzž'
n=len(abc)
for i in poruka:
if i in abc:
print(abc[(abc.index(i)+pomeranje) % n], end='')
else:
print(i, end='')
Problem sa slovima lj, nj i dž je REŠEN. Tretiraju se kao dva slova.
Uzmi reči nadživeti, konjunkcija, injekcija. Ovo su slučajevi kada znaci dž i nj predstavljaju DVA slova. Ne mogu da se setim primera da je nekada i lj dva slova.
Sada još samo da rešiš problem velikih slova, pa si rešio zadatak...
[ djoka_l @ 22.12.2019. 15:21 ] @
Evo ti varijanta programa koja zna da radi i sa velikim slovima.
Code: # Cezarova šifra
poruka = input('Unesi poruku: ')
pomeranje = int(input('Za koliko mesta pomeriti slova? '))
abc = 'abcčćdđefghijklmnoprsštuvzž'
n=len(abc)
for i in poruka:
c=i.lower()
up=i.isupper()
if c in abc:
s=abc[(abc.index(c)+pomeranje) % n]
print(s.upper() if up else s, end='')
else:
print(i, end='')
[ a1234567 @ 22.12.2019. 16:13 ] @
Pozdrav Đoko,
Veliko hvala na trudu. Upravo mi to treba, povratna informacija i komentar za moj program, kako bih nešto naučio i ispravio greške.
Jer ja u stvari još ništa ne znam. Više nagađam i guglujem, nego što sam siguran kako treba. Ali valjda je to tako uvek u početku.
Dakle, uopšte ne shvatam tvoje komentare kao napad na ličnost, već sam zahvalan što si se uopšte potrudio da pogledaš šta sam uradio.
To mu dođe kao kad nastavnik ispravi domaći zadatak crvenom olovkom, pa iz grešaka učenik nešto nauči. :)
Proučiću pažljivo prvo tvoje komentare, a onda i rešenje koje si ponudio.
Ako budem imao dodatnih pitanja, šaljem i njih.
HVALA JOŠ JEDNOM ZA TRUD!
[ a1234567 @ 22.12.2019. 17:29 ] @
Proučio sam primedbe. Uglavnom su mi jasne i vidim gde sam grešio.
Suviše mnogo koraka tamo gde je moguće pojednostaviti.
Nisam se setio da za oduzimanje iskoristim modulo.
Valjda zato što mi je ostalo u glavi da je on za deljenje.
Novost je za mene i da if ne mora da ima else.
Zato sam i pisao to što sam pisao, da nešto bude i u else :))
I naravno to je višak.
Najviše mi se od svega sviđa abc string bez lj, nj, i dž.
Odlična ideja. Ja sam video problem tamo gde ga nema.
Stavio sam i moju (apdejtovanu) i tvoju verziju programaovde, ako nekom zatreba.
[ mjanjic @ 22.12.2019. 17:52 ] @
Sledeći korak: napraviti rešenje koje koristi chr() i ord() funkcije, a radi i za naša slova - za engleski alfabet može da se realizuje jednom linijom koda :)
[ Branimir Maksimovic @ 23.12.2019. 05:02 ] @
Bolje uradi rot13 to se bar koristi.
[ a1234567 @ 23.12.2019. 16:48 ] @
Idemo dalje.
Za opuštanje jedan sasvim lak zadatak, čak i meni :)
Zadatak broj 6
Treba zvezdicama iscrtati pravougaonik.
Jedan način je naravno ovako, ali je tada veličina fiksirana.
Else blok može u jednoj liniji (doduše, manje jasno, ali zanimljivo za razmišljanje):
Code: for i in range (y):
print('*' + ('*' * (x-2) if (i == 0 or i == y-1) else ' ' * (x-2)) + '*')
[ a1234567 @ 24.12.2019. 01:51 ] @
ja sam ovo tvoje ('*' + ('*' * (x-2) malo pojednostavio
Code: for i in range (y):
print('*' * x) if (i == 0 or i == y-1) else print('*' + ' ' * (y+2) + '*')
E sad mi je bilo zanimljivo da sam morao da stavim print i posle else, inače ne radi program kako treba.
[ djoka_l @ 24.12.2019. 08:30 ] @
Citat:
E sad mi je bilo zanimljivo da sam morao da stavim print i posle else, inače ne radi program kako treba.
Obrati pažnju na zagrade!!
mjanjic je napisao izraz
print ( NEŠTO if USLOV else NEŠTODRUGO )
ti si napisao
print ( NEŠTO ) if USLOV else print ( NEŠTODRUGO )
[ a1234567 @ 24.12.2019. 08:47 ] @
Aha, dobro.
Sad i moja verzija radi bez drugog print,
kad sam uklonio višak zagrada
Code: x = 10
y = 6
for i in range (y):
print('*' * x if i == 0 or i == y-1 else '*' + ' ' * (y+2) + '*')
[ djoka_l @ 24.12.2019. 09:02 ] @
To što si ti napisao nije greška.
U tom primeru, if-else konstrukcija je TERNARNI operator, odnosno operator koji računa sa tri izraza.
Kao što je "+" BINARNI operator i <izraz> + <izraz> je BINARNA operacija koja kao rezultat vraća <izraz>, tako i
<izraz> if <logicki_izraz> else <izraz>
ternarna operacija koja vraća vrednost.
Ti sada možeš da koristiš povratnu vrednost za nešto drugo, recimo za print:
print( <izraz> if <logicki_izraz> else <izraz> )
a može i sam izraz da bude print() ili neka druga funkcija.
Dakle ispravno je i
print( <izraz> if <logicki_izraz> else <izraz> )
i
print( <izraz> ) if <logicki_izraz> else print( <izraz> )
Samo treba da znaš zašto se to dešava.
A da je i print() funkcija, vidi se jasno jer sve funkcije se pozivaju kao ime_funkcije( argumenti ) (bitno je da stoji zagrada posle imena). Tako je, bar u pythonu 3.
Da je print funkcija, koja vraća neku vrednost, možeš i sam da proveriš sa:
print( print ('x') )
[ mjanjic @ 24.12.2019. 09:19 ] @
Ja sam hteo još "komplikovanije" da napravim koristeći product() ili neki drugi način da izbegnem petlje, nego da na neki drugi način realizujem iscrtavanje karaktera u formi pravougaonika, ali sam odustao. Moglo bi kao dvostruki niz pa da posle odštampa samo elemente niza, ali da bi se taj niz formirao treba poprilično koda.
Drugi problem, koji mi je bio interesantniji, jeste da se detektuje rezolucija ekrana i/ili broj karaktera koji može da se ispiše horizontalno i vertikalno pa da se zvezdice odštampaju samo uz ivicu, međutim tu je potrebna dodatna biblioteka, čija primena se dodatno komplikuje ako je uključeno skaliranje (obično kod 2k displeja sa malim ekranima i većine 4k displeja), ali nigde nisam našao mogućnost da se detektuju dimenzije "output" box-a (npr. kod onlih online interpretera), tj. moramo ih znati unapred.
[ Branimir Maksimovic @ 24.12.2019. 09:45 ] @
Na Linux-u imas environment variable LINES i COLUMNS...
[ a1234567 @ 24.12.2019. 10:24 ] @
Citat:
mjanjic:
Ja sam hteo još "komplikovanije" da napravim koristeći product()...
Janjiću samo bez komplikovanja... ovo je kindergarten. Ne obeshrabruj poletarce
[ a1234567 @ 24.12.2019. 10:36 ] @
Citat:
djoka_l:
Dakle ispravno je i
print( <izraz> if <logicki_izraz> else <izraz> )
i
print( <izraz> ) if <logicki_izraz> else print( <izraz> )
Ali je zanimljivo da ovo ne radi
Code: print('*' * x if i == 0 or i == y-1) else ('*' + ' ' * (y+2) + '*')
Po meni bi i ovo imalo logike jer je if uslov za prvi izraz bude štampan, dakle ide uz njega, a else mu dođe obaška, kao alternativa.
[ djoka_l @ 24.12.2019. 11:10 ] @
Nije logično.
Po istom principu, trebalo bi da bude ispravno i
print( a + b )
i
print( a + ) b
A ovo drugo sigurno nije ispravno.
Tebi je if ostalo u prvoj zagradi (od print) a else si stavio van zagrade, a one je deo istog izraza sa if.
Dakle, treba
( if ... else )
a ne
( if ... ) else
[ a1234567 @ 24.12.2019. 15:39 ] @
OK, shvatam, if... else su par i ne može taraba između njih.
I to mi ima logike :))
[ a1234567 @ 24.12.2019. 16:23 ] @
E dobro, logiku smo pretresli do u sitna crevca.
Vreme je za relaksaciju, to jest kartanje
Zadatak broj 7: Mešanje karata
Standarni špil karata sadrži 52 karte. Svaka karta ima jednu od četiri boje: pik (♠), herc (♥), karo (♦) i tref (♣). Karte su po hijerarhiji poređane: 2, 3, 4, 5, 6, 7, 8, 9, 10, J (Jack), Q (Queen), K (King), A (Ace).
Svaka karta može se predstaviti sa dva karaktera. Prvi karakter je vrednost karte, gde su vrednosti od 2 do 9 direktno predstavljene. Karakteri “T”, “J”, “Q”, “K” i “A” se koriste da predstave 10, Jack, Queen, King i Ace. Drugi karakter se koristi da predstavi boju karte. To je obično malo slovo: „p“ (pik), „h“ (herc), „k“ (karo) i „t“ (tref). Evo nekoliko primera kako su karte predstavljene sa dva karaktera:
Jack pik = Jp
dva tref = 2t
deset karo = Tk
Ace herc = Ah
devet pik = 9p
Počni tako što ćeš napisati funkciju napraviShpil. Ona će koristiti petlju da napravi ceo špil sortirajući dvoslovne oznake za sve 52 karte u listu. Return listu karata kao jedini rezultat te funkcije. Tvoja funkcija ne zahteva nikakve parametre.
Napiši drugu funkciju i nazovi je meshanje, koja randomizuje redosled karata u listi. Jedna tehnika za ovakvo mešanje karata je da prođeš svaki elemenat u listi i zameniš mu mesto sa nekim drugim, nasumično odabranim elementom liste. Moraš napisati sopstvenu petlju za mešanje karata. Ne možeš koristiti pythonovu izvornu shuffle funkciju
Sada iskoristi obe funkcije da napraviš glavni program koji prikaže ceo špil pre i posle mešanja.
Ajmo da krenemo. Ko meša?
[ mjanjic @ 24.12.2019. 21:01 ] @
A baš mora "prosta" petlja za kreiranje špila, ja bih da koristim product() da naučimo i nešto novo, obične petlje smo valjda savladali?
Evo funkcije za kreiranje špila pomoću product():
Code: from itertools import product
def createDeck():
cardList = product(['2','3','4','5','6','7','8','9','T','J','Q','K','A'], ['p','t','k','h'])
cards = []
for card in cardList:
cards.append(''.join(card))
return cards
[ Branimir Maksimovic @ 24.12.2019. 21:57 ] @
haskell:
Code:
let cards = [(face,sign)|face<-['2','3','4','5','6','7','8','9','T','J','Q','K','A'],
sign <- ['p','t','k','h']]
Da li ti sam smišljaš ove zadatke?
Pitam zato što je ovo loš način da se predstavi špil karata. Koristiš dvoslovne oznake, a to je pogrešno.
Tako ti je, na primer, sedmica pik predstavljena kao string '7p'. Zar ti nije logičnije da bude predstavljena kao ['7', 'pik']?
Ovo je greška koju često vidim kod početnika - prave nekakve "samogovoreće" šifre za predstavljanje entiteta iz modela.
Špil karata može i da se predstavi i kao niz cifara od 0 - 51, tako da je za kartu n vrednost v=n % 13 a boja b=n // 4
Posebno držiš niz oznaka za karte 0-12, posebno boje za vrednosti 0-3.
Zamisli, recimo, da je ovo mešanje samo uvod u neki program za igranje bridža. Tada ti odjednom zatreba da karatama dodeliš honor poene, (A=4, K=3, Q=2, J=1), a boje treba poređati u redosledu tref, karo, herc, pik.
Zato je bolje kartu predstaviti kao neki objekat ili strukturu podataka, tako da modifikacija bude jednostavna.
[ a1234567 @ 25.12.2019. 10:44 ] @
Ne smišljam ja, nisam tako talentovan, već kad naiđem na neki zadatak koji mi je zanimljiv, postavim ga ovde.
A ovaj mi je bio zanimljiv po ovom random premeštanju elemenata skupa, koje se može primeniti u različitim igrama.
No, u pravu si, ovo je samo bio uvod. Ima i nastavak zadatka
Zadatak broj 8
Sad kad smo promešali karte, najprirodniji sledeći potez je da ih i podelimo.
Dakle, treba napisati novu funkciju, koja se nadovezuje na prethodne dve i radi sledeće:
* podeli po 6 karata četvorici igrača,
* ispiše koje karte ko od njih ima i
* naravno, ukloni te karte iz preostalog špila.
* pa onda i njega izlista, čisto da proverimo da nije neka od karata u opticaju ostala u njemu.
Ko deli?
[ a1234567 @ 25.12.2019. 14:35 ] @
Dok ne vidimo ko deli, imam jedno praktično pitanje:
imali li random modul neki metod koji bi vraćao nasumični element niza, ali unutar određenog raspona njegovih indeksa, recimo [4:10]?
U slučaju ove liste, to bi značilo da metod vraća ili jedan od ovih elemenata: '4', '6', '24', '19', '32', '9' ili njegov index.
[ Panta_ @ 25.12.2019. 15:02 ] @
Ima, random.choice.
[ a1234567 @ 25.12.2019. 15:57 ] @
Panto, gledao sam i njega.
Ali koliko sam razumeo on vraća bilo koji član liste, ne vidim da može da se suzi izbor.
Dokumentacija kaže:
random.choice(seq)
Return a random element from the non-empty sequence seq. If seq is empty, raises IndexError.
djoka_l:
Da li ti sam smišljaš ove zadatke?
Pitam zato što je ovo loš način da se predstavi špil karata. Koristiš dvoslovne oznake, a to je pogrešno.
Tako ti je, na primer, sedmica pik predstavljena kao string '7p'. Zar ti nije logičnije da bude predstavljena kao ['7', 'pik']?
Ovo je greška koju često vidim kod početnika - prave nekakve "samogovoreće" šifre za predstavljanje entiteta iz modela.
Špil karata može i da se predstavi i kao niz cifara od 0 - 51, tako da je za kartu n vrednost v=n % 13 a boja b=n // 4
Posebno držiš niz oznaka za karte 0-12, posebno boje za vrednosti 0-3.
Zamisli, recimo, da je ovo mešanje samo uvod u neki program za igranje bridža. Tada ti odjednom zatreba da karatama dodeliš honor poene, (A=4, K=3, Q=2, J=1), a boje treba poređati u redosledu tref, karo, herc, pik.
Zato je bolje kartu predstaviti kao neki objekat ili strukturu podataka, tako da modifikacija bude jednostavna.
Đoko, pokušao sam da napravim ovo što si predložio i izgleda da mi je uspelo.
A najviše mi se dopada što sam pojednostavio staru for petlju.
fromrandomimport sample
cards =[value+color for value in"23456789TJQKA"for color in"ptkh"] for player inrange(1,5):
hand = sample(cards, k=6) print(f"Player {player}: {hand}") for i in hand:
cards.remove(i) print(f"Remaining cards: {cards}")
Player 1: ['5h','3t','9k','8p','5p','5t']
Player 2: ['4k','6t','Ah','9p','6h','6k']
Player 3: ['Ap','7k','2p','Qh','9t','2k']
Player 4: ['Jt','Tp','Jh','Tt','Jp','7p']
Remaining cards: ['2t','2h','3p','3k','3h','4p','4t','4h','5k','6p','7t','7h','8t','8k','8h','9h','Tk','Th','Jk','Qp','Qt','Qk','Kp','Kt','Kk','Kh','At','Ak']
[ a1234567 @ 27.12.2019. 02:05 ] @
Panta ga slupao u tri reda!
Ali si vidim jednu stvar zaboravio i to vrlo važnu!
Posle mešanja karata, a pre deljenja, moraju karte da se precepe, naravno.
Zato sam pitao za random.choice.
Panto ako ne znaš kako da precepiš karte, nije problem,
pogledaj moj kod ovde
Eto, rešismo još jedan zadatak.
Uskoro postavljam novi. Stay tuned
[ a1234567 @ 27.12.2019. 04:48 ] @
Evo jedan lak
Zadatak broj 9:
Ubedi python da odštampa nešto ovako:
1
2 2
3 3 3
4 4 4 4
5 5 5 5 5
[ a1234567 @ 28.12.2019. 00:56 ] @
Evo i rešenja:
Code:
for i in range(6):
for x in range(i):
print (i, end=" ")
print("\n")
[ Panta_ @ 28.12.2019. 06:35 ] @
Imas novu liniju posle svakog for loopa, zameni print("\n") sa print(). Evo malo jednostavnijeg resenja:
Code: for i in range(6):
print((str(i) + ' ') * i)
1
2 2
3 3 3
4 4 4 4
5 5 5 5 5
[ a1234567 @ 28.12.2019. 12:23 ] @
Evo Panto ja još skratio
Code: for i in range(6):
print(str(i) * i)
Ti si izgleda veliki ljubitelj kratkih formi, samo skraćuješ.
Evo ti onda jedne super kratke priče velikog Danila Harmsa, pa uživaj:
Bio jedan riđi čovek
Bio jednom jedan riđi čovek. Taj nije imao ni oči ni uši. Ni kosu nije imao, tako da su ga riđim zvali tek uslovno. Ni da govori nije mogao, jer taj ni usta nije imao. Nije imao ni nos. Nije imao čak ni ruke ni noge. Ni stomak nije imao, ni leđa nije imao, ni kičmu nije imao, ni unutrašnje organe. Ništa taj nije imao. Tako da se ni ne zna o kome se radi. Bolje onda da o njemu više i ne govorimo.
[ Branimir Maksimovic @ 28.12.2019. 13:26 ] @
evo pascalov trougao:
Code:
~/examples/haskell >>> cat pascal.hs
fac :: (Num a,Enum a) =>a->a
fac = product . enumFromTo 1
binCoef :: Integer->Integer->Integer
binCoef n k = (fac n) `div` ((fac k) * (fac $ n - k))
pascal :: Integer -> [[Integer]]
pascal n = map (\x -> map (binCoef $ x - 1) [0..x-1]) [1..n]
main = do
line <- getLine
let n = read line
putStrLn $ unlines $ map (unwords.map (show)) $ pascal n
Evo onda za tebe jedne Paskalove misli: Lepa reč ne košta mnogo. A ipak postiže mnogo.
[ a1234567 @ 28.12.2019. 14:39 ] @
A odmah zatim da postavim kratki i jubilarni
Zadatak broj 10
Napiši funkciju koja određuje da li je lista brojeva koje je uneo korisnik sortirana (po rastućem ili opadajućem nizu, svejedno) ili je nasumična. Funkcija treba da dâ rezultat True ukoliko je lista već sortirana pri unosu, a u suprotnom False.
Napiši glavni program u kojem korisnik unese recimo 5 brojeva i onda iskoristi svoju funkciju da napraviš izveštaj je li lista sortirana ili nije.
[ Panta_ @ 28.12.2019. 15:31 ] @
Citat:
a1234567:
Evo Panto ja još skratio :D
Code: for i in range(6):
print(str(i) * i)
Nemas razmak izmedju brojeva. Zar ne treba 5 5 5 5 5?
[ a1234567 @ 28.12.2019. 15:37 ] @
Pa kad smo već krenuli u minimalizam, ja reko da zakinem što je moguće više
Inače za ovaj deseti zadatak kao privremeno rešenje dok ne nađem bolje,
dajem takozvano "brute force" rešenje
Code:
lista = [6, 15, 23, 31, 52]
def provera():
if lista[0] <= lista[1] and lista[1] <= lista[2] and lista[2] <= lista[3] and lista[3] <= lista[4]:
return True
elif lista[0] >= lista[1] and lista[1] >= lista[2] and lista[2] >= lista[3] and lista[3] >= lista[4]:
return True
else:
return False
print(provera())
proverio, radi!
[ a1234567 @ 28.12.2019. 15:52 ] @
Malo elegantnije rešenje zadataka 10 postavio sam na mestu za rešenja, ako nekom zatreba.
[ Panta_ @ 28.12.2019. 16:04 ] @
Code: True if lista == sorted(lista) or lista == sorted(lista)[::-1] else False
[ Branimir Maksimovic @ 28.12.2019. 16:14 ] @
samo lista == sorted ne treba True ili False.
[ Panta_ @ 29.12.2019. 06:47 ] @
True, zato što operator vraća boolean vrednost (True ili False), ali mi je sa if else za ovaj primer delovalo čitkije.
[ a1234567 @ 29.12.2019. 11:32 ] @
E nešto sam razmišljao o ovim trouglovima od brojeva što smo pravili.
Geometrija je čudo. Pa mi pade na pamet, kako napraviti ovako nešto!?
[Ovu poruku je menjao Panta_ dana 29.12.2019. u 15:54 GMT+1]
[Ovu poruku je menjao Panta_ dana 29.12.2019. u 16:08 GMT+1]
[ a1234567 @ 29.12.2019. 14:25 ] @
E to, majstore, svaki dan nešto novo naučim :)
The chain() function takes several iterators as arguments and returns a single iterator that produces the contents of all of them as though they came from a single sequence.
Code: from itertools import *
for i in chain([1, 2, 3], ['a', 'b', 'c']):
print i
$ python itertools_chain.py
1
2
3
a
b
c
[ a1234567 @ 30.12.2019. 13:46 ] @
Zadatak 11. Pronađi proste brojeve
Prvo, da se podsetimo šta je prost broj? Svaki pozitivan broj od 1 do n, koji je deljiv jedino brojem 1 i samim sobom.
E sad treba u nizu od 1 do nekog zadatog broja izlistati sve proste brojeve.
Recimo u nizu od 1 do 50, to su brojevi: 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47.
Napiši funkciju, čiji je opis sledeći:
Code: Napravi listu sa svim brojevima od 0 do n.
izbaci 0 i 1, jer nisu prosti brojevi.
Postavi p jednako 2 i odatle krećeš
Dok je p manje od n radi ovo:
Izbaci iz liste sve brojeve koji su proizvod broj p tako što ćeš im dati vrednost 0 (ali ne izbacuj samo p).
Postavi da je p jednako narednom broju u listi, a koji već nije pretvoren u vrednost 0
Isprintaj kao proste sve brojeve koji nisu postali 0.
[ mjanjic @ 30.12.2019. 20:59 ] @
Zar nije logičnije napraviti novi niz pa vrednosti prostih brojeva upisivati u njega?
Za ovo kako si ti opisao je pogodna neka vrsta heš tabele, ali je besmisleno jer nas zanimaju samo brojevi koji su prosti. Na kraju, logično je imati niz koji sadrži samo proste brojeve do broja n, a ne da većina članova niza budu 0, pa pri štampanju treba opet da proveravamo za svaki element niza da li je različit od nule.
Od ovakvih zadačića se prosečnom početniku smuči programiranje, jer ne vidi poentu rešavanja zadataka koji se u takvom obliku nikad neće pojaviti u praksi.
Uzmi npr. one jednostavnije zadačiće iz knjiga tipa "Coding interviews".
[ a1234567 @ 31.12.2019. 04:17 ] @
Takav je zadatak na koji sam naišao. Ne mogu ja autoru da krojim kapu :)
Evo i rešenja za zadatak 11.
Nije problem, ako imaš i ti neki zadatak za početnike, postavi ga ovde, pa da se zabavljamo :)
E da, najvažnije!
SVIMA VAM ŽELIM SVE NAJBOLJE U NOVOJ GODINI
i još mnogo programerskih "zadačića" da rešimo :D
Kada praviš Eratostenovo sito, ne treba petlja da ide do "limit", nego do sqrt(limit)
Tako, na primer, ako želiš da nađeš proste brojeve do 100, petlja se vrti samo do 10. Kada izbaciš sve brojeve deljive sa 2, 3, 5 i 7, sve što ostane je prost broj.
Ako broj nije prost, tada može da se napiš kao proizvod dva broja k=m*n.
m i n su veći od 1 (ne moraju da budu prosti) i neka je m<=n
Tada je maksimalna vrednost za m u slučaju da je m=n, pa m ne može biti veće od sqrt(k)
[ Branimir Maksimovic @ 31.12.2019. 08:34 ] @
Ene de nisam se udubio u resenje ;)
Imam ja nesto komplikovaniju stvar koju sam koristtio za resavanja ojlera 512, al ajde :P
[ a1234567 @ 08.01.2020. 17:56 ] @
Stiže i Zadatak 12: Pretraga rečnika
Napravi funkciju i nazovi je pretragaRecnika. Ona će potom imati rečnik i vrednost za pretragu kao svoje jedine parametre.
Napravi i glavni program koji pokazuje da pretragaRecnika funkcioniše kao deo rešenja za ovu vežbu. Tvoj program treba da kreira rečnik i onda da pokaže da funcija ispravno radi kada za rezultat ima više ključeva, jedan ili nijedan ključ.
Eto. Kratko i valjda je jasno.
[ anon70939 @ 08.01.2020. 20:15 ] @
Kupio sam na Udemy za oko 9$ neki kurs za ucenje pajtona u obliku zadataka. Svideo mi se ali sam prosao samo 30% jer sam posle otisao na neku drugu stranu.
Ovaj kurs https://www.udemy.com/course/python-video-workbook/
Pored toga sam na tel instalirao i SoloLearn pa u kojekakvim redovima dok sam cekao zabavljao sam se s tim.
Ovo sa rečnikom mi se baš dopada. Mogao bi i pravi rečnik da se napravi sa ovom funkcijom.
Jel može neko da kaže, koji se program uz python koristi za pravljenje interfejsa?
[ B3R1 @ 10.01.2020. 19:50 ] @
Da li je ovo tvoje resenje ili je to prepisano iz knjige? Zadatak je postavljen prilicno nejasno. Da li se trazi englesko-srpski recnik ili obrnuto? Recnik koji si postavio online podrazumeva da su reci s leve strane srpske, s desne engleske, a onda autor resenja pravi recnik (odnosno 'dict' strukturu) u kome su stvari postavljene obrnuto - kljucevi su engleske reci, a vrednosti srpske. Da bi na kraju program za zadate srpske reci vracao engleske ... prilicno konfuzno, ako mene pitas.
Ako ti vec treba srpsko-engleski recnik, zar nije prirodnije definisati dict u stilu:
u kom slucaju funkcija pretraga postaje krajnje jednostavna:
def pretraga (data, key):
if (key in data):
return data[key]
else:
return ''
Ova funkcija gore podrazumeva da je recnik konstruisan u strogom 1:1 maniru. Medjutim, ovaj tvoj nije. Ima slucajeva kada se iste engleske reci mapiraju u vise srpskih reci i obrnuto:
Kao sto vidis, druga definicija reci 'agent' je zamenila ovu prvu.
Tu dolazimo do problema ucitavanja recnika. Python dict od nekih 20-30 key:value parova, ako se ne menjaju tokom vremena, mozes da 'hard-kodujes' u samom programu, kao sto si to i uradio. Medjutim, ako dict sadrzi nekih 10000 key:value parova sigurno je bolje ucitati to iz nekog fajla, sto je u pythonu trivijalno:
srEn = {}
for line in open('recnik.txt', 'r'):
key, value = line.strip().split(':')
srEn[key] = value
Ovo ti je osnovni kod koji ilustruje princip. Metod split(delimiter) razdvaja string u niz (listu) stringova koristeci znak 'delimiter' kao razdvajac - npr.
string='The;Big;Brown;Fox'
words = string.split(';')
vraca niz 'words' koji ce u sebi imati 4 elementa: [ 'The', 'Big', 'Brown', 'Fox' ].
Ali to je sve daleko od resenja, jer recnik koji si postavio sadrzi nekoliko zackoljica koje moras da razresis.
Prvi problem je ovo sto je vec opisano gore. Najjednostavniji nacin je da prevode razmaknes znakom ';', kao sto se to radi u pravim recnicima. Kod onda postaje:
srEn = {}
for line in open('recnik.txt', 'r'):
key, value = line.strip().split(':')
if (key not in srEn):
srEn[key] = value
else:
srEn[key] += '; ' + value
Drugi nacin, koji lici na ovo tvoje resenje, je da ti prevodi uvek budu nizovi, odnosno liste, pa da dobijes recnik tipa:
Takvu strukturu mozes da napunis iz fajla na sledeci nacin:
srEn = {}
for line in open('recnik.txt', 'r'):
key, value = line.strip().split(':')
if (key not in srEn)
srEn[key] = [ value ]
else:
srEn[key].append(value)
Verovatno primecujes da sam na pocetku u oba slucaja stavio:
srEn = {}
Mada Python ne zahteva da promenljive deklarises kao u C/C++ na primer, svaka promenljiva koju koristis mora da bude definisana pre prvog koriscenja:
b = a + 1
ce vratiti gresku ako 'a' nigde nije definisano. Ispravno je:
a = 0 # ili neka druga vrednost
b = a + 1
Slicno je i sa listama i recnicima - njih takodje moras da inicijalizujes pre koriscenja:
Drugi problem je sto ces, ako napravis fajl identican ovom zadatom recniku, u kome su reci s leve i s desne strane oivicene navodnicima, prilikom citanja fajla parametri 'key' i 'value' ce dobiti dvostruke navodnike i jos poneki razmak izmedju:
A to nije ono sto si hteo. Znaci, prilikom ucitavanja recnika moraces da skines navodnike (odnosno apostrofe), kao i da se resis razmaka. Za brisanje razmaka s leve i desne strane stringa (a.k.a. "trimovanje") koristis funkciju (odnosno metod) strip():
key, value = line.split(':')
key = key.strip()
value = value.strip()
Ostaje jos da skines navodnike na pocetku i kraju izraza, sto je najelegantnije da uradis ovako:
key = key[1:-1] # Izdvaja rec od drugog do pretposlenjeg znaka
value = value[1:-1]
A sada - tutti ... odnosno sve to spojeno u jedno:
srEn = {}
for line in open('recnik.txt', 'r'):
key = line.split(':')[0].strip()[1:-1]
value = line.split(':')[1].strip()[1:-1]
if (key not in srEn)
srEn[key] = [ value ]
else:
srEn[key].append(value)
Potom, neke linije u tvom recniku sadrze samo znak '$'. Njih bi najbolje bilo da preskocis, odnosno da preskocis sve linije koje ne sadrze dvotacku kao separator:
for line in open('recnik.txt', 'r'):
if (':' not in line):
continue
key = ...
Ovde bih stao za sada. Mada, pricu mozemo da sirimo i dalje. Sta raditi kada ti taj fajl s recnikom od 10000 elemenata ukucava neko ko bas nije mnogo pedantan, pa dobijes:
Moram da ti ukažem na jednu tvoju veliku grešku u ratmišljanju:
Citat:
Ovo sa rečnikom mi se baš dopada. Mogao bi i pravi rečnik da se napravi sa ovom funkcijom.
Ti si trenutno u poziciji koja je opisana u literaturi o "situational leadership" (vidi, na primer https://www.atlassian.com/blog...hip-styles-for-every-situation) koja se naziva "enthusiastic beginner" ili D1.
Svi smo mi bili u tom položaju, bilo kada smo pokušavali da naučimo programiranje, ili skijanje, ili da vozimo kola, ili da sviramo gitaru (nastavi niz)...
Imaš jaku želju da naučiš programiranje, imaš motivaciju, ali vrlo malo iskustva i znanja. Ne znaš šta ne znaš. Ono što je problematično je to što ova pozicija (D1) zahteva vođstvo koje se zove S1 - tutorstvo.
Ljudima u ovoj poziciji jako je potrebno da imaju nekoga koji im TAČNO kaže šta dalje da rade.
I to je veliki problem sa svima koji hoće da nauče neku veštinu, a nemaju instruktora, nego idu sa nekim Internet "samoučenjem".
A problem je to što je sledeća faza u procesu napredavanja faza D2 koja se zove "disilusioned lerner". U toj fazi nastupa razočaranost, dolaziš do shvatanja koliko zapravo malo znaš i to je faza, u kojoj bez dobrog vođstva, napuštaš to što si počeo da radiš.
Sada si oduševljen python distionary strukturom podataka. A ne znaš, na primer, da je dictionary u pythonu realizovan kao hash tabela. Ne znaš šta je hash tabela. Ne znaš da pretraživanje hash tabele ima linernu kompleksnost i da se ta linearna kompleksnost obeležava kao O(n), Ne znaš ni šta je to O notacija. Ne znaš da efikasni algoritmi pretraživanja, kao na primer B-stablo imaju kompleksnost od O(log n). Ne znaš ni šta je to B-stablo, pa ni obično stablo.
I sada bi ti pravio grafičku aplikaciju za rečnik, koristeći neefikasnu strukturu podataka i bez najbliže predstave koliko to može da bude komplikovano.
Nemam nameeru da ti dam savet kako da napraviš takvu aplikaciju, jer bi to samo povećalo broj pitanja za koje ni ne znaš da postoje, niti znaš odgovore na njih.
Svi tvoji dosadašnji python programi imaju po desetak linija koda. Onda kada budeš u stanju da napišeš python program od 1000 linija koda (koji RADI), počni da razmišljaš o sebi kao o junior programeru.
Do tada, rešavaj ove fizz buzz probleme, a pokušaj i da nađeš nekog predavača ili da odeš na neki kurs python programiranja.
[ a1234567 @ 11.01.2020. 01:47 ] @
Đoko, prijatelju, još jednom hvala na dobronamernim savetima.
Sve sam te razumeo i sve si u pravu. Imam želju, imam motivaciju i radim svaki dan pomalo, pa dokle stignem.
Nažalost, ovo što si na kraju savetovao, nije ostvarimo. U situaciji u kojoj sam, ne mogu da nađem ni (živog) predavača, niti da se upišem na kurs. Možda jednog dana. Zato pokušavam da nešto naučim koristeći ono što mi je na raspolaganju, a to su net i knjige. Ako hoćeš da se prihvatiš uloge onlajn instruktora, primljen si na posao odmah
Druga alatka mi je upravo to što si naveo, motivacija. A kako je održavam? Pa tako što pokušavam da nađem problem KOJI ME ZANIMA. I otuda ideja o rečniku, jer mi se to čini kao zanimljiv projekat. Već sam pisao, najviše me zapravo zanima rad sa tekstom, a ne kojekakvi matematički problemi.
Dakle, skočim u vodu i probam da plivam. Nailazim na probleme usput i rešavam kako u tom trenutku znam i umem, bez pritiska rokova ili toga da uopšte moram nešto da postignem. Niti ja pravim neki poizvod za nekoga, pa da mora biti savršeno, niti mi egzistencija od toga zavisi, već je to za sada za mene hobi. Dakle, baš kao skijanje koje si naveo. Spustim se niz BLAGU padinu, pa ako i padnem koji put, nije smak sveta. Ali to što usput naučim ne bih naučio ako ostanem na vrh staze i nastavim da proveravam vezove, nameštam kapu i rukavice ili skakućem okolo sa jednom skijom na nozi.
Sve u svemu, pokušavam da sebi pronađem izazov, koji će mi održavati motivaciju i vući dalje. Ako imaš bolji konkretan predlog, biće mi neobično drago da ga saslušam. I još jednom, zaista sam ti zahvalan na svakom savetu.
E da, juče čačkam po netu i naiđem na ovaj, meni zanimljiv problem, koji je zapravo zadatak broj 13:
Kako da sabiraš ili oduzimaš ovakve stringove? '1plus2plus3plus4'
rezultat = 10
ili: '1plus2plus3minus4'
rezultat = 2
[ Branimir Maksimovic @ 11.01.2020. 06:53 ] @
Djoka:"Ne znaš da pretraživanje hash tabele ima linernu kompleksnost"
Djoko, mislim da si umoran ;)
[ Panta_ @ 11.01.2020. 07:50 ] @
Citat:
a1234567:
Ako nije definisan, verovatno je zadavač mislio da ga sami definišemo.
Ali evo ovde imaš jedan za nuždu.
Nije ti dobro definisan taj rečnik, npr. imaš 'glava me boli, my head aches' kao i '$'.
Inače, Python dictionary ima get funkciju koja vraća vrednost ključa ako je ključ u rečniku ili porazumevanu None.
Code: mydict = eval(open("recnik.txt").read()) # kreira recnik iz fajla "recnik.txt"
Program ili biblioteka? Ovo nabrojano su biblioteke i frejmvorci. Na primer QtCreator je program koji sadrži UI builder.
[ a1234567 @ 11.01.2020. 16:30 ] @
Citat:
B3R1:
Da li je ovo tvoje resenje ili je to prepisano iz knjige? Zadatak je postavljen prilicno nejasno. Da li se trazi englesko-srpski recnik ili obrnuto? Recnik koji si postavio online podrazumeva da su reci s leve strane srpske, s desne engleske, a onda autor resenja pravi recnik (odnosno 'dict' strukturu) u kome su stvari postavljene obrnuto - kljucevi su engleske reci, a vrednosti srpske. Da bi na kraju program za zadate srpske reci vracao engleske ... prilicno konfuzno, ako mene pitas.
Ako ti vec treba srpsko-engleski recnik, zar nije prirodnije definisati dict u stilu:
u kom slucaju funkcija pretraga postaje krajnje jednostavna:
def pretraga (data, key):
if (key in data):
return data[key]
else:
return ''
Ova funkcija gore podrazumeva da je recnik konstruisan u strogom 1:1 maniru. Medjutim, ovaj tvoj nije. Ima slucajeva kada se iste engleske reci mapiraju u vise srpskih reci i obrnuto...
Ako je rešenje za prethodni zadatak konfuzno, to je zaštitni znak da je moje
Svaka čast, Berislave, baš si se potrudio da mi objasniš i veliko hvala.
Kao prvo, meni je u glavi pre englesko-srpski, nego srpsko-engleski rečnik. Mada kad napraviš jedan, nije pretpostavljam nepremostiv problem napraviti i obrnuto.
Dosta si napisao i treba mi vremena da to u glavi raspetljam. Ono što sam shvatio je da nije dobar ovaj sistem 1:1 sa više reči u keys
'gaol, prison, lock-up' : 'aps'
jer vidim da ako u polje za pretragu ukucam samo 'court' neće pronaći prevod u rečniku. Stvari dodatno komplikuje ako ima više reči i u keys i u values. Npr.:
'gaol, prison, lock-up' : 'aps, zatvor'
Da li onda da svako značenje izdvojim u poseban par?
gaol : aps, gaol : zatvor, prison : aps, prison : zatvor, gaol : aps, gaol : zatvor
ali onda gubim neke odrednice, kao što si ti pokazao u primeru.
Kao sto vidis, druga definicija reci 'agent' je zamenila ovu prvu.
Kako izbeći da se jedna definicija ne izgubi?
Naravno, ovaj deo o učitavanju rečnika iz fajla nije problem. Svakako da definicije neće biti deo programa, već u eksternom fajlu, jer će ih biti na hiljade.
Ništa od interfejsa za sada. Stavljamo ga na ler.
Iskrsni problemi neviđeni oko heš tabele, ne mož raspetljati ni pod razno
Kao što je Đoka i predviđao. Zna čovek gde su nagazne mine.
Odoh da vidim šta su te heš tabele, pa ćemo onda na kanal da budžimo
I naravno, hvala za apdejtovani rečnik. Mada je to tek test verzija, sad je čista ko suza!
[Ovu poruku je menjao a1234567 dana 11.01.2020. u 18:25 GMT+1]
[ Panta_ @ 11.01.2020. 17:44 ] @
Citat:
Panto ovaj tvoj mydic.get metod ne rešava problem koji imamo kad je više istih ključeva:
Hvala za link. Ovo sa Wiki je pisano za vanzemaljce. Ništa ne razumem.
Pa sam našao na Stackoverflow nešto svarljivije. Možda će još nekom trebati, pa prenosim ovde.
Naravno, ostaje pitanje, kako sve to tehnički implementirati, ali bar mi je malo jasniji princip rada. Koliko shvatam, to mu dođe nešto kao bar-kod.
Here's an explanation in layman's terms.
Let's assume you want to fill up a library with books and not just stuff them in there, but you want to be able to easily find them again when you need them.
So, you decide that if the person that wants to read a book knows the title of the book and the exact title to boot, then that's all it should take. With the title, the person, with the aid of the librarian, should be able to find the book easily and quickly.
So, how can you do that? Well, obviously you can keep some kind of list of where you put each book, but then you have the same problem as searching the library, you need to search the list. Granted, the list would be smaller and easier to search, but still you don't want to search sequentially from one end of the library (or list) to the other.
You want something that, with the title of the book, can give you the right spot at once, so all you have to do is just stroll over to the right shelf, and pick up the book.
But how can that be done? Well, with a bit of forethought when you fill up the library and a lot of work when you fill up the library.
Instead of just starting to fill up the library from one end to the other, you devise a clever little method. You take the title of the book, run it through a small computer program, which spits out a shelf number and a slot number on that shelf. This is where you place the book.
The beauty of this program is that later on, when a person comes back in to read the book, you feed the title through the program once more, and get back the same shelf number and slot number that you were originally given, and this is where the book is located.
The program, as others have already mentioned, is called a hash algorithm or hash computation and usually works by taking the data fed into it (the title of the book in this case) and calculates a number from it.
For simplicity, let's say that it just converts each letter and symbol into a number and sums them all up. In reality, it's a lot more complicated than that, but let's leave it at that for now.
The beauty of such an algorithm is that if you feed the same input into it again and again, it will keep spitting out the same number each time.
Ok, so that's basically how a hash table works.
Technical stuff follows.
First, there's the size of the number. Usually, the output of such a hash algorithm is inside a range of some large number, typically much larger than the space you have in your table. For instance, let's say that we have room for exactly one million books in the library. The output of the hash calculation could be in the range of 0 to one billion which is a lot higher.
So, what do we do? We use something called modulus calculation, which basically says that if you counted to the number you wanted (i.e. the one billion number) but wanted to stay inside a much smaller range, each time you hit the limit of that smaller range you started back at 0, but you have to keep track of how far in the big sequence you've come.
Say that the output of the hash algorithm is in the range of 0 to 20 and you get the value 17 from a particular title. If the size of the library is only 7 books, you count 1, 2, 3, 4, 5, 6, and when you get to 7, you start back at 0. Since we need to count 17 times, we have 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, and the final number is 3.
Of course modulus calculation isn't done like that, it's done with division and a remainder. The remainder of dividing 17 by 7 is 3 (7 goes 2 times into 17 at 14 and the difference between 17 and 14 is 3).
Thus, you put the book in slot number 3.
This leads to the next problem. Collisions. Since the algorithm has no way to space out the books so that they fill the library exactly (or the hash table if you will), it will invariably end up calculating a number that has been used before. In the library sense, when you get to the shelf and the slot number you wish to put a book in, there's already a book there.
Various collision handling methods exist, including running the data into yet another calculation to get another spot in the table (double hashing), or simply to find a space close to the one you were given (i.e. right next to the previous book assuming the slot was available also known as linear probing). This would mean that you have some digging to do when you try to find the book later, but it's still better than simply starting at one end of the library.
Finally, at some point, you might want to put more books into the library than the library allows. In other words, you need to build a bigger library. Since the exact spot in the library was calculated using the exact and current size of the library, it goes to follow that if you resize the library you might end up having to find new spots for all the books since the calculation done to find their spots has changed.
I hope this explanation was a bit more down to earth than buckets and functions :)
[ B3R1 @ 11.01.2020. 18:06 ] @
Citat:
a1234567:
Već sam pisao, najviše me zapravo zanima rad sa tekstom, a ne kojekakvi matematički problemi.
Sada si me podsetio na one dve legendarne scene iz filma Karate Kid - prve, kao i one kasnije u filmu, druge ... gde ucitelj objasnjava klincu kako je sve u zivotu Kung Fu. A sto rece profesor Edsger Dijkstra: "Programiranje je jedna od najtezih oblasti primenjene matematike. Losim matematicarima bi bilo najbolje da se drze ciste matematike".
Matematicki problemi u pocetnickim zbirkama iz programiranja su vojnicki dril za buduceg programera. Svrha tih zadataka je da te nauce da razmisljas kao programer, sto tebi u ovom trenutku prilicno nedostaje i to se recimo videlo na onom zadatku s bacanjem novcica. Lepo si iskoristio funkciju random.randint(0,1) da dobijes uniformno raspodeljene slucajne ishode nule ili jedinice, a onda si napisao:
Znaci, ako ti je rezultat 0 ti to tumacis kao '1glava', a ako ti je rezultat 1 tebi je to '0pismo', da bi kasnije 'pismo' i 'glavu' odsekao i ispisao samo 0 i 1. Nazivi 'glava' i 'pismo' su cist visak. Takodje, nema potrebe da obrces rezultat funkcije randint(), ako imas u vidu da je verovatnoca ishoda 0 i 1 fifty-fifty, zar ne? Prema tome, zasto ne odmah:
print (random.randint(0,1), end='')
Slicno si uradio i sa ovim recnikom - napravio si strukturu u kojoj su ti kljucevi engleske reci, a vrednosti srpske, da bi onda vrsio obrnuto prevodjenje.
Nemoj da me shvatis pogresno, ovo sto radis je sjajna stvar. Ucis! I to je super! Zapravo, trenutno samo opipavas teren, ali sada je vec vreme da malcice naucis neke temelje struke, kako bi ti se kockice slozile na pravi nacin. Recimo, na netu ces naci gomilu kurseva posveceih uvodu u programiranje i strukturama podataka. Moj favorit je ovaj uvodni Python kurs sa MIT - pokriva sve aspekte Pythona, veoma lep, akademski, metodican, imas video snimke profesora koji pricaju, mozes da skines slajdove da ih listas dok slusas predavanja, sve besplatno dostupno, mozes sve i da downloadujes. I nije namenjen samo buducim programerima, vec studentima svih inzenjerskih disciplina koje se tamo izucavaju, jer je na MIT Python neka vrsta programerskog bukvara za sve studente ... kasnije oni koji rade number crunching uce SciPy/SymPy, a programeri napredne algoritme itd. Mislim da bi ti ovaj kurs pomogao da popunis rupe u znanju. Oni imaju i zadatke za vezbu itd. A mozes i paralelno da nastavis da eksperimentises, naravno. Jednom kada odslusas kurs videces kako ovi zadaci koje postujes ovde pocinju da ti imaju vise smisla.
Na kraju, da se nadovezem na ovo sto je Djole lepo rekao:
Citat:
Onda kada budeš u stanju da napišeš python program od 1000 linija koda (koji RADI), počni da razmišljaš o sebi kao o junior programeru.
A onda kada budes shvatio da je tocak i vatru vec izmislio neko drugi ... i da je vecinu standardnih programerskih zadataka neko vec resio i napravio i Python modul za to ... i da je tvoje samo da proucis dokumentaciju za taj modul, vidis koje su ti funkcije potrebne i opalis jedan 'import modul_taj_i_taj' na pocetku programa (prethodno ces morati da radis 'pip install', doduse ...) - videces da se mnogi problemi resavaju i sa 10 linija, umesto 10000 linija koda. E tada postajes vec medior programer, koji uspesno koristi ono sto vec postoji i ne izmislja toplu vodu svaki put iznova i iznova. A senior ces postati onda kada i sam budes uspeo da napises svoje module. Otprilike tako.
P.S. Ja nisam programer, niti mi je softverski inzenjering ikada bio core business. Kodiranje mi je sporedna stvar u poslu. Bavim se mrezama (IP/MPLS), a Python koristim samo za scripting / network automation ... za sta sam do sada koristio Perl, ponekad bash/awk ...
[ Zurg @ 11.01.2020. 18:27 ] @
Koncept heš tabele je jednostavan. Da bi razumeo heš tabelu, odnosno Dictionary potrebno je prvo da razumeš nizove. Elementima niza pristupaš na osnovu indeksa. Takav pristup je direktan (brz) i vreme pristupa je konstantno. Na primer:
Code:
niz = ["nula", "jedan", "dva"]
print(niz[0]) # 0 je indeks
#print prikazuje vrednost "nula"
Ako imaš gomilu podataka kojima treba da pristupiš na osnovu ključa, a želiš da vreme pristupa ne zavisi od broja elemenata, onda koristiš heš tabelu. Heš tabela ima funkciju koja za svaki ključ generiše indeks i pod tim indeksom čuva vrednost u nizu. Ako ovo razumeš i ne planiraš da implementiraš svoju heš funkciju/tabelu mislim da za sada tu možeš da se zaustaviš i nastaviš da koristiš Dictionary.
(Stvari su malo komplikovanije od onoga što sam napisao. Kada bi imali beskonačno memorije radilo bi odlično, međutim pošto je to nemoguće, onda su neophodni neki kompromisi i zato je bitno pametno osmisliti strategiju heširanja i smeštanja podataka u slučaju da heš funkcija generiše isti indeks za različite ključeve...)
Mali test, da li je Dictionary (heš tabela) dobar izbor ako želimo da u okviru for petlje prođemo kroz sve unose i zašto?
[ Branimir Maksimovic @ 12.01.2020. 00:01 ] @
Beri:"E tada postajes vec medior programer, koji uspesno koristi ono sto vec postoji i ne izmislja toplu vodu svaki put iznova i iznova. "
Zurg, prvo hvala na konstruktivnom doprinosom u ovoj temi. Drugo, nisam pogrešio kada sam rekao da je kompleksnost pretrage hash tabele O(n). Pogledaj i sam link na wiki koji si ostavio
Doduše, ta kompleksnost je "worst case" scenario, ali ga je vrlo lako isprogramirati izborom lošeg hash algoritma i "štimovanjem" podataka da postigneš worst case.
Drugo, postavljaču teme predlažem da pokuša da piše FUNKCIONALNE SPECIFIKACIJE.
Ne zato da ga obeshrabrim, nego da ga usmerim na pravi put.
Funkcionalnu specifikaciju možeš da posmatraš, sa jedne strane, kao niz obećanja klijentu šta ćeš da uradiš, a sa druge strane, kada programiraš za svoju dušu, podsetnik šta treba da se uradi. To je okvirni plan rada. Kaže se: plan nije ništa, planiranje je sve. Kako drugačije da proceniš da li napreduješ, ako nisi zacrtao ciljeve koje želiš da postigneš?
Ja uvek imam običaj da pravim funkcionalnu specifikaciju za svaki program za koji mi je potrebno više od jednog dana da ga napišem.
Kako bi izgledala funkcionalna specifikacija za rečnik:
1. pretraga rečnika, za reč iz jezika J1 naći reči u jeziku J2.
2. obezbediti pretragu rečnika iz komandne linije
3. obezbediti grafički interfejs za pretragu rečnika (ovo može i kasnije)
4. unos nove odrednice
5. unos novog pevoda
6. postojanje više od dva jezika u rečniku (ako nije suviše teško)
7. snimanje izmena rečnika u fajl
8. korišćenje baze podataka za smeštanje reči
itd.
Onda kreneš da planiraš da uradiš one delove koji su ti lakši da prvo isprogramiraš, a one teže ostaviš za kraj.
U nekom trenutku, uporediš svoju funkcionalnu specifikaciju, ako treba izmeniš ili dodaš novu funkcionalnost i napraviš plan kako da tu funkcionalnost da uradiš.
Recimo, želim grafički interfejs, da li da interfejs napravim kao desktop aplikaciju, ili kao web aplikaciju? Podsetnik: proveri koje grafičke biblioteke mogu da iskoristim za desktop aplikaciju, a koje za web? Ako idem na web, šta mi je od dodatnog softvera potrebno da instaliram? Koliko vremena mi je potrebno da naučim da napravim jednostavnu desktop aplikaciju? Recimo da odredim dve nedelje, pa ako procenim posle nedelju dana da nije dovoljno, menjam plan...
[Ovu poruku je menjao djoka_l dana 12.01.2020. u 01:43 GMT+1]
[ djoka_l @ 12.01.2020. 00:39 ] @
Još neke napomene uz projekat rečnik:
Šta raditi u slučaju, recimo gramatičkih oblika koje imaju isti koren?
Na primer, play može biti imenica igra ili glagol u infinitivu igrati.
Ali play kao glagol može da se pojavi i u oblicima plays kada se koristi uz imenicu ili zamenicu trećeg lice jednine, ili u obliku playing.
Takođe, odrednice u srpskom mogu da budu i igram, igraš, igra, igramo, igrate igraju, igrajući, igrao, igralii i slično.
Šta raditi sa imenicama? Da li treba čuvati imenicu samo u nominativu jednine ili u svim padežima?
Da li treba čuvati rod imenice? U engleskom je to jednostavno, ali u srpskom i nemačkom nema strogog pravila...
Šta raditi sa rečima koje se isto pišu ortografski, ali imaju različito značenje. Na primer "da" može biti afirmacija "yes" ili predlog "to"
Da li ima smisla označavati neke reči kao sinonime ili antonime drugih reči (dakle veza između reči može biti između reči u istom jeziku, a ne samo između reči u različitim jezicima).
Dakle, ti si samo zagrebao vrh teme, a da nisi ozbiljno razmislio...
[ Branimir Maksimovic @ 12.01.2020. 00:40 ] @
"Drugo, nisam pogrešio kada sam rekao da je kompleksnost pretrage hash tabele O(n)."
Jesi. Nemo sad da se vadis ;)
"Doduše, ta kompleksnost je "worst case" scenario,"
worst case svakako, ali to ti je i worst case za stablo.
Kako i stablo biva balanasirano, tako i hash funkcija ne mapira sve kljuceve na jedan broj,
tako da je to teorijski moguce, prakticno nemoguce.
[ djoka_l @ 12.01.2020. 00:56 ] @
Recimo, da je hash tabela realizovana kao niz od k ulaza a svaki ulaz je lista parova key value za key koji daje istu hash vrednost.
Tada je prosečna dužina liste za svaku hash vrednost n/k a prosečno vreme pretrage n/2k, što daje kompleksnost od O(n). Ne treba da se posebno trudiš da postigneš worst case.
Mogu da se naprave i bolji algoritmi za razrešenje kolizije, ali sve je to linearna ili nešto malo bolja kompleksnost...
[ Branimir Maksimovic @ 12.01.2020. 01:00 ] @
Tacno, sa time da hash tabela raste kako se dodaju novi elementi tako da to n/k tezi jedinici. To je poenta hash tabele.
[ a1234567 @ 12.01.2020. 03:32 ] @
Evo prema Đokinom odličnom predlogu, pribeležih ono što mi je palo na pamet u vezi sa projektom rečnik.
Sigurno sam nešto zaboravio, pa dodajte ako imate ideju.
Englesko-srpski rečnik - specifikacija
A. Softver:
1. pretraživanje značenja prema unetoj reči (ili prvim slovima reči u desktop verziji - dropdaun lista)
2.1. preko konzole
2.1. kasnije napraviti desktop aplikaciju
2.2. još kasnije napraviti onlajn izdanje, gde bi korisnici mogli i sami da predlažu nove reči ili njihova značenja (crowdsourcing)
3. mogućnost unošenja novih reči za oba jezika i snimanje izmena
4. mogućnost popravljanja već unetih reči za oba jezika i snimanje izmena
5. mogućnost brisanja već unetih reči za oba jezika i snimanje izmena
6. veličina: do 100.000 reči u svakom od jezika.
7. operativni sistem: windows
B: Sadržaj:
1. Svaka engleska reč ima oznaku za vrstu (n = noun, v = verb, adj = adjective, pre = preposition itd.)
2. Na taj način se pravi razlika između onih koje imaju isti oblik:
play n. = 1. igra, zabava; 2. drama, pozorišna predstava
play v. = 1. igrati (se); 2. svirati; 3. glumiti
3. Različita polja značenja iste reči se odvajaju arapskim brojevima (vidi gornji primer).
4. Fraze u kojima se javlja neka reč idu na kraj značenja te reči i iza kose crte (/). Tako za play:
play v. = 1. igrati (se); 2. svirati; 3. glumiti / to bring into play = staviti u pogon, pokrenuti
5. Oblik imenica je uvek u prvom licu jednine (play, a ne plays)
6. Oblik glagola je uvek u infinitivu bez "to" (work, a ne working ili worked, sem naravno u frazama)
[ Zurg @ 12.01.2020. 06:37 ] @
Đoko, priznaj lepo da nisi u pravu da ne smetamo čoveku dok uči.
[ Branimir Maksimovic @ 12.01.2020. 08:36 ] @
Nego da ti odgovorim na ovo:
"Mali test, da li je Dictionary (heš tabela) dobar izbor ako želimo da u okviru for petlje prođemo kroz sve unose i zašto?"
Ukoliko zelimo sortiran prolaz nije, zato sto hash tabela za razliku od stabla nije sortirana. No u svakom drugom slucaju je hash tabela bolja od stabla.
Znaci uzmi najprostije recimo brojanje reci u nekom vecem tekstu i svako ce videti razliku O(1) hash tabela vs O(log n) stablo.
To ko bibli uoteci knjige i katalog, pa ne tražiš knjigu redom na polici, već u katalogu vidiš njenu signaturu, tj, mesto u magacinu.
E sad vidim ima kao neke kolizije. To kao kad staviš knjigu na pogrešno mesto, pa kad na to isto mesto hoćeš posle da staviš pravu, cvrc, ne može. :)
[ Branimir Maksimovic @ 12.01.2020. 23:26 ] @
"E sad vidim ima kao neke kolizije"
Kolizija je kada dva razlicita kljuca gadjaju isti slot u tabeli. To je ili zato sto hash funkcija nije savrsena ili zato sto ima vise kljuceva nego sto moze da stane.
U slucaju da je ovo drugo onda se poveca velicina i uradi rehashing posle nekog tresholda.
Inace hash tabela je obicno implementirana kao niz listi gde u liste idu kolizije.
[ a1234567 @ 15.01.2020. 12:44 ] @
Počeli smo da mešamo babe i žabe, pa ću napraviti novu temu za englesko-srpski rečnik, a ovde nastaviti da postavljam samo zadatke za ambiciozne početnike.
Evo ga novi, zadatak broj 14:
Napiši program koji će uporediti tri varijable: x, y, z
i ispisati najveći neparni broj među njima. Ako nijedna od varijabli nije
neparan broj, trebalo bi da ispiše odgovarajuću poruku.
Za pravljenje funkcije moguće koristiti jedino dve alatke:
1. if-elif-else petlju i
2. modulo, za proveru je li broj neparan.
Uživajte! :)
[ B3R1 @ 17.01.2020. 10:36 ] @
Zasto samo tri broja? Hajde da malo napravimo zadatak tezim. Neka to bude matrica N x M i da nadjes najveci neparan broj, ali da uz to ispises i koordinate (vrstu i kolonu) gde se taj broj nalazi.
[ a1234567 @ 17.01.2020. 12:03 ] @
Zašto samo tri broja?
Pa jer smo tako u mogućnosti u ovom trenutku :)
Elem, izborih se ja nekako sa 14. zadatkom i svoje rešenje sampostavio ovde.
E sad kad smo ovu preponu preskočili, da vidimo šta predlaže Berislav.
Dakle, treba da bude matrica.
Ali čekaj, pa još nisam radio sa matricama!?
Jesi ti siguran da se ovo može rešiti samo sa if... else?
Dobro, ako idem ovim metodom kojim sam rešio zadatak četrnaest, red po red, naći ću najveći neparan broj u svakom redu.
Onda od ta četiri broja opet nađem najveći.
Ali mi nije baš jasno kako ću odrediti njegovo mesto.
Jedino za svaki broj da bude promenljiva po nekom nizu, recimo
[a1, a2, a3, a4
b1, b2, b3, b4...]
pa da u odnosu na to koja bude najveća određujem poziciju. Gore bi to bila c2, dakle treći red, druga kolona.
Ili ima neka prečica?
[ B3R1 @ 17.01.2020. 13:31 ] @
Citat:
a1234567: Jesi ti siguran da se ovo može rešiti samo sa if... else?
Ocigledno ne, treba ti i petlja ... 'for' petlja. :-) Mislim, ako resavas opsti slucaj (dimenzija M x N).
Citat:
Ali mi nije baš jasno kako ću odrediti njegovo mesto. Jedino za svaki broj da bude promenljiva po nekom nizu, recimo
Zato sam ti i savetovao da prodjes onaj kurs sa MIT. Tamo lepo objasnjavaju strukture podataka, pocev od skalarnih tipova (str, int, float ...) do vektorskih (list, dict ...). Kada imas listu:
a = [ 10, 20, 50, 100, 200 ]
Elemente liste mozes da dobijes sa:
>>> a[0]
10
>>> a[2]
50
Prvi element liste s leve strane ima indeks 0, slede 1, 2 itd. Slicno tome, u matrici iz tvog primera (zaboravio si zareze na kraju vrsta).
U opstem slucaju brojevi[x][y], gde je x vrsta (0-3), a y kolona (0-3). Znaci, za svaki element liste, odnosno 'liste lista' (matrice) mozes lako da dobijes indeks elementa.
Kako mozes da odstampas / analiziras elemente liste, jedan iza drugog? Koriscenjem 'for' petlje. Imas dva nacina - iterativno, element po element:
lista = [ 10, 11, 12, 13, 14]
for element in lista:
print element
Ili pristupajuci klasicno, indeks po indeks:
for id in range(len(lista)): # len(lista) = 5 u gornjem primeru:
print lista[id]
A sada nesto sto mozda nisi znao: za razliku od nekih drugih programskih jezika u Pythonu su liste dinamicke, implementirane kao ulancane liste s pointerima. Ako napravis praznu listu:
lista = []
Ona nece imati nijedan element, a ako pokusas da pristupis ili da direktno dodelis vrednost desetog elementa u listi, dobices:
>>> lista[9] = 12
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list assignment index out of range
Listu mozes da definises ili direktno (lista = [1, 3, 5, 7, 11]) ili metodom element po element, koriscenjem append() metode:
Elemente liste mozes i da brises (pop() / remove()), da umeces elemente usred postojece liste (insert()) itd. Osnovne operacije sa listama mozes da vidis ovde
Medjutim, ponekad ti moze zatrebati prazna lista koja sadrzi svuda nule, a gde mozes proizvoljno da pristupis bilo kom elementu i dodelis mu vrednost. To je narocito pogodno kada prevodis prastare programe koje su neke fortrandzije pisale pre 40 godina, tamo su nizovi staticki definisani i automatski popunjeni nulama. Ili neki Perl skript, u Perlu su sve promenljive kada ih prvi put pozoves uvek nule (osim ako ne koristis 'use strict').
Praznu listu od 10 nula kreiras sa:
lista = [0]*10
>>> lista
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
>>> lista[5]=111
>>> lista
[0, 0, 0, 0, 0, 111, 0, 0, 0, 0]
Slicno tome, matricu 3 x 3 popunjenu nulama mozes da dobijes sa:
>>> matrica = [[0, 0, 0]]*3
ili:
>>> matrica = [[0]*3]*3
U oba slucaja rezultat je isti:
>>> matrica
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
Takozvanu jedinicnu matricu:
1 0 0
0 1 0
0 0 1
dobijas ovako:
Code: e = [] # Kreira praznu listu
for i in range(3):
e.append([]) # Dodaje praznu vrstu matrice
for j in range(3):
if (i==j):
e[i].append(1)
else:
e[i].append(0)
U gornjem izrazu 'i==j' je izraz tipa boolean, ciji je rezultat True ili False. Boolean se moze konvertovati u integer funkcijom int() (int(False) = 0, int(True) = 1). Samim tim, ovo gore mozes da skratis:
Code: e = [] # Kreira praznu listu
for i in range(3):
e.append([]) # Dodaje praznu vrstu matrice
for j in range(3):
e[i].append(int(i==j)) # Daje 0 ako je i!=j, a 1 ako je i==j
Moze li jos krace? Moze! U Pythonu imas lepu stvar koja se zove comprehension, koja ti omogucava da gornji kod skratis na jednu liniju (verovatno si video ovaj trik u Pantinim kodovima, na linku koji sam ti dao imas vise o tome):
Code: e = [ [ int(i==j) for i in range(3) ] for j in range (3) ]
Mislim da ti sada nece biti tesko da uradis zadatak.
[Ovu poruku je menjao B3R1 dana 17.01.2020. u 15:40 GMT+1]
[ B3R1 @ 17.01.2020. 14:46 ] @
Citat:
a1234567:
Dobro, ako idem ovim metodom kojim sam rešio zadatak četrnaest, red po red, naći ću najveći neparan broj u svakom redu.
Zamisli da stojis pred ljudima (oba pola, imuskarci i zene) postrojenim u vrstu. Ljudi nisu sortirani po visini. U ruci drzis kanap i lenjir. Kako ces odrediti visinu najvise zene u vrsti?
Ako znas odgovor na to pitanje znas da resis i ovaj problem. Misilm da sam ti dovoljno pomogao.
[ Panta_ @ 18.01.2020. 06:43 ] @
Citat:
Dobro, ako idem ovim metodom kojim sam rešio zadatak četrnaest, red po red, naći ću najveći neparan broj u svakom redu.
Onda od ta četiri broja opet nađem najveći.
Ali mi nije baš jasno kako ću odrediti njegovo mesto.
Python lista ima index() funkciju koja vraća poziciju tj. indeks elementa u listi, npr.
Code: [31, 20, 26, 41].index(41)
3
Sad samo prođi kroz listu i proveri da li je broj neparni i da li je veći od prethodnih, i ako je True, zabeleži ga, kao i njegovu poziciju.
[ B3R1 @ 18.01.2020. 12:31 ] @
Zaboravio sam da pomenem i enumerate(). Kada prolazis kroz listu u for-petlji, listajuci element po element:
for elem in [11, 13, 14, 17, 21]:
print elem
Dobices spisak elemenata liste, jedan ispod drugog. Ali ako zelis da uz to vodis racuna i o njihovim indeksima, mozes da koristis enumerate():
for i, elem in enumerate([11, 13, 14, 17, 21]):
print "%d\t%d" % (i, elem)
Inace, ovo je jedan od prvih algoritama koji se obradjuje na svakom pocetnom kursu programiranja - nalazenje minimuma i maksimuma niza. Analogija sa kanapom i strojem ljudi je bas potpuna. Prosta pravolinijska procedura. Ostavljam tebi da sam dodjes do tacnog postupka, nije tesko. A uz enumerate() funkciju diskusija o listama je recimo kompletna.
[ a1234567 @ 18.01.2020. 12:50 ] @
Prošao sam taj deo sa listama, indexima i ostalim.
Lupao glavu danas i evo došao do nekog rešenja kad je obična lista u pitanju:
Code: niz = [23, 33, 44, 55, 11]
niz_deo = len(niz) - 1
max = [niz[0]]
for i in niz[1:niz_deo]:
if i%2 != 0 and i > niz[0]:
max.append(i)
max1 = max.pop(0)
kolona = niz.index(max[0]) + 1
print('Najveći neparni broj je u koloni: ', kolona)
rezultat:
Najveći neparni broj je u koloni: 4
Onda sam krenuo na listu lista, tj matricu i jasno mi je da treba da imam dve petlje
for i in niz:
for j in i:
if j%2 != 0 and j > max:
ali imam problem sa upoređivanjem veličine dva broja.
Ovako u prvom prolazu upoređujem j sa prvim brojem u matrici,
ali ne vidim kako da taj max broj posle zamenjujem brojem iz prethodnog prolaza kako prolazim kroz petlju.
[ B3R1 @ 18.01.2020. 14:13 ] @
Mislim da tebi ozbiljno nedostaje algoritamski nacin razmisljanja. Nisam pomenuo uzaludno onu analogiju sa kanapom i vrstom ljudi. Recimo da treba da nadjes najviseg coveka, sta ces uraditi? Imas kanap i lenjir. Znaci, uzmes kanap, stanes ispred prvog coveka, izmeris ga od pete do glave i tacku na kanapu koja dodiruje vrh njegove glave uhvatis prstima (ili vezes cvor, obelezis flomasterom ... sta god ...). Stanes ispred sledeceg, izmeris ga ... pa ako je polozaj prstiju/cvora/fleke na kanapu iznad njegove glave, znaci on je nizi od prethodnog, tako da ides dalje ne menjajuci polozaj prsta ... kada nadjes nekog viseg, pomeras prst navise (ili vezes novi cvor). Na kraju, kada prodjes celu vrstu ljudi, uzmes lenjir i izmeris duzinu kanapa od pocetka do pozicije na kojoj se finalno nalazi prst (odnosno vezao cvor ili sta vec ...) Znaci:
Code: ljudi = [ 165, 190, 185, 172, 168, 173, 189, 188 ] # Visine ljudi u vrsti
kanap = ljudi[0] # Stajem ispred prvog coveka i izmerim ga
covek = 0 # Njegova pozicija je 0
for id, h in enumerate(ljudi):
if h > kanap: # Ako je glava coveka iznad kanapa - nasli smo viseg!
kanap = h # Pomeramo prst na njegovu visinu
covek = id # Upisujemo njegovu poziciju
print 'Najvisi covek u stroju je # ' + str(covek) + ', njegova visina izmerena kanapom je: ' + str(kanap)
Gornje resenje radi dobro, osim za specijalan slucaj kada rekord u visini deli vise ljudi. Onda bi verovatno trebalo da pamtis negde pozicije tih rekordera. Nije tesko izmeniti program da to postigne:
Code: ljudi = [ 165, 191, 185, 172, 168, 190, 190, 188 ] # Visine ljudi u vrsti
kanap = ljudi[0] # Stajem ispred prvog coveka i izmerim ga
covek = [ 0 ] # Upisujem ga u listu visinskih rekordera
for id, h in enumerate(ljudi):
if h > kanap: # Ako je glava coveka iznad kanapa - nasli smo viseg!
kanap = h # Pomeramo prst na njegovu visinu
covek = [ id ] # Ispraznimo listu i zapamtimo njegovu poziciju
elif h == kanap and id > 0: # Naisao si na coveka iste visine kao trenutno najviseg, ali koji nije prvi sleva
kanap = h
covek.append(id) # Dodaj poziciju na listu
if len(covek)>1:
print 'Najvisi ljudi u stroju su na pozicijama # ' + str(covek) + ', njihovavisina izmerena kanapom je: ' + str(kanap)
else:
print 'Najvisi covek u stroju je na poziciji # ' + str(covek[0]) + ', njegova visina izmerena kanapom je: ' + str(kanap)
Ovo je zaista bukvar programiranja i prvi zadatak koji se uci na prvim casovima, danas cak i u osnovnoj skoli. Tebi je potrebna dobra knjiga koja se bavi algoritmima i strukturama podataka. Programiranje ne moze da se uci bez sustinskog razumevanja nacina rada, odnonso algoritma programa.
[ Branimir Maksimovic @ 18.01.2020. 14:56 ] @
Cek ti pamtis sve duplikate bez obzira da li je max visina ili nije? Zar ne bi trebalo prvo da odradis maksimum pa onda skupis sve ljude sa datom visinom?
recimo:
Code:
import Data.List
collect l = (foldl (\m (i,h) -> if h == max_h then (i:m) else m) [] $ zip [0..] l , max_h)
where max_h = maximum l
main = do
let ljudi = [ 165, 191, 185, 172, 191, 168, 190, 190, 188 ]
print $ collect ljudi
Code:
~/examples/haskell >>> ./maxheight
([4,1],191)
[ B3R1 @ 18.01.2020. 15:35 ] @
Citat:
Branimir Maksimovic: Cek ti pamtis sve duplikate bez obzira da li je max visina ili nije? Zar ne bi trebalo prvo da odradis maksimum pa onda skupis sve ljude sa datom visinom?
Samo ako su ti ljudi isti kao i trenutni maksimum. U suprotnom, kada se pojavi novi maksimum lista se brise. Recimo, ako je niz [ 180 190 190 195 194 195 193 ], tada pamtim pozicije 1 i 2 (gde su ovi od 190), ali kada naidje ovaj 195 na poziciji 3, niz [1, 2] se brise i dobija vrednost [3]. Na kraju liste bice [3, 5]. Ovo mi je prvo palo na pamet i zahteva samo jedan prolaz kroz listu. Ova tvoja ideja zahteva dva prolaza, ako se ne varam? Ne poznajem haskell uopste. Sigurno ima i boljih resenja, ovo je bio sam brzinski demo ...
[ a1234567 @ 18.01.2020. 15:43 ] @
Citat:
B3R1:
Mislim da tebi ozbiljno nedostaje algoritamski nacin razmisljanja. Nisam pomenuo uzaludno onu analogiju sa kanapom i vrstom ljudi.
Ovo je zaista bukvar programiranja i prvi zadatak koji se uci na prvim casovima, danas cak i u osnovnoj skoli. Tebi je potrebna dobra knjiga koja se bavi algoritmima i strukturama podataka. Programiranje ne moze da se uci bez sustinskog razumevanja nacina rada, odnonso algoritma programa.
Hvala na vrlo plastičnom i jasnom primeru. Pomogao je.
Počeo sam inače da idem kroz Guttagovu knjigu koju si preporučio. Doduše ide polako, ali važno je da napredujem.
Analizirajući tvoj primer, rešio sam i nalaženje najvećeg broja za matrix.
max = niz[0][0]
for i in niz:
for j in i:
if j%2 != 0 and j > max:
max = j
print('Najveći broj je', str(max))
Da bih našao njegovu poziciju, da li i u matrixu mogu da nađem index sa nečim sličnim kao niz.index(max), kao što to radi u običnoj listi?
brojevi = [23, 54, 65, 3, 4, 5, 6, 16, 33, 44]
brojevi.index(65)
2
[ Branimir Maksimovic @ 18.01.2020. 15:49 ] @
Ber:"U suprotnom, kada se pojavi novi maksimum lista se brise."
ah, da, taj detalj sam propustio.
[ Panta_ @ 18.01.2020. 15:59 ] @
Citat:
ali imam problem sa upoređivanjem veličine dva broja.
Ovako u prvom prolazu upoređujem j sa prvim brojem u matrici,
ali ne vidim kako da taj max broj posle zamenjujem brojem iz prethodnog prolaza kako prolazim kroz petlju.
Napisao sam ti u gornjem postu. Na primer:
Code: for i in niz:
for j in i:
if j%2 != 0 and j > m:
m = j
p = i.index(j)
print(m, p)
85 3
Ili sa enumerate:
for i in niz:
for index, j in enumerate(i):
if j%2 != 0 and j > m:
m = j
p = index
Sa range i len:
for i in niz:
for index in range(len(i)):
if i[index] % 2 != 0 and i[index] > m:
m = i[index]
p = index
Bez pomoćnih funkcija:
for i in niz:
c = 0
for j in i:
if j % 2 != 0 and j > m:
m = j
p = c
c+=1
Kao što možeš da vidiš iz navedenih primera, Python ima dosta ugrađenih (built-in) funkcija, pored pomenutih, za tvoj zadatak možeš da iskoristiš npr. max() za najveći broj ili filter() da filtriraš neparne brojeve. Na primer:
Code: max(filter(lambda n: n[1] % 2 == 1, [(index, row) for sub in niz for index ,row in enumerate(sub)]), key=lambda i: i[1])
Bogami, ima dosta načina. Pribeležiću ih.
A ja ni da ubodem makar jedan :))
Za max() sam znao, ali zadatak je bio da se uradi sa for petljom, pa nisam hteo da sabotiram.
[ B3R1 @ 18.01.2020. 16:52 ] @
Citat:
a1234567:
Analizirajući tvoj primer, rešio sam i nalaženje najvećeg broja za matrix.
Ok, odlican pocetak! Ali ja sam ti nasao jedan bag ... ako je niz[0][0] paran broj veci od svih ostalih (npr. 1000), a ostatak matrice ima i neparne brojeve manje od 1000 najveci neparan broj ce biti pogresno ispisan da bude niz[0][0].
Analogija s kanapom: ako su vrsti ljudi stoje samo muskarci, a tebi je zadatak da nadjes najvisu zenu, ako podjes redosledom da meris prvog coveka bez obzira na pol - tu si pogresio. Znaci, moraces da kanap drzis smotan dok ne naidjes na prvu zenu u vrsti. Ako ne naidjes - rezultat je da medju ljudima nema nikoga zenskog pola.
Imas dva resenja: ako se zadatak ogranici samo na skup prirodnih brojeva, tada je ispravka jednostavna i svodi se na zamen linije:
max = niz[0][0]
alternativnom linijom:
max = -1
Takodje, print na kraju programa mora da postane:
if max < 0:
print 'Matrica ne sadrzi neparne brojeve'
else:
print('Najveći broj je', str(max))
Ako program mora da radi nad skupom celih brojeva, tada ces morati da primenis ovu analogiju s kanapom, pa program postaje nesto slozeniji (ali ne preterano):
Code: m = niz[0][0] # Najveci neparan broj
xm = -1 # Vrsta sa max neparnim brojem
ym = -1 # Kolona sa max neparnim brojem
for x, i in enumerate(niz):
for y, j in enumerate(i):
# Ako je broj paran, vrti dalje
if j%2 == 0:
continue
# Ako jos nismo nasli prvi neparan broj ILI ga vec imamo, ali ovaj neparan broj je veci ...
if (xm < 0) or (xm >=0 and j > m):
m = j
xm = x
ym = y
# Ispis
if (xm < 0):
print 'Matrica nema neparne brojeve'
else:
print 'Maksimum %d se nalazi na poziciji: [%d,%d]' % ( m, xm, ym)
U svakom slucaju, napredujes odlicno, svaka cast!
[ a1234567 @ 19.01.2020. 01:50 ] @
U ovom drugom primeru mi nije jasno šta ti radi prva polovina ove linija: if (xm < 0) or (xm >=0 and j > m):
Kad je skratim samo na if j > m:
Program i dalje radi kako treba.
[ a1234567 @ 19.01.2020. 05:19 ] @
Posle napornog rada, evo nešto malo za opuštanje :)
[ Branimir Maksimovic @ 19.01.2020. 06:10 ] @
Citat:
a1234567:
U ovom drugom primeru mi nije jasno šta ti radi prva polovina ove linija: if (xm < 0) or (xm >=0 and j > m):
Kad je skratim samo na if j > m:
Program i dalje radi kako treba.
Dobro si to uocio. Za sve vrednosti xm ovo prolazi tako da xm ne utice na uslov.
[ B3R1 @ 19.01.2020. 10:44 ] @
Evo novog zadatka, ovog puta jedan od klasicnih algoritama. Ostajemo u svetu nizova i matrica.
Dat je veoma dugacak niz prirodnih brojeva, sortiranih u rastucem redosledu - niz = [ 3, 7, 11, 21, 25, 38, 41 ... ], kao i prirodni broj n (npr. n=123). Ubaciti broj n u niz, na odgovarajuce mesto, tako da niz ostane sortiran. Program treba da radi optimalno i za ekstremno velike nizove.
Na prvi pogled, zadatak je jednostavan: prodjes kroz niz od prvog do poslednjeg elementa, pa kada vidis zgodno mesto tu broj zasadis. To je tzv. linearni algoritam i njegova slozenost je O(n), jer je vreme izvrsavanja programa u opstem slucaju proporcionalno velicini niza. Moze li bolje i efikasnije?
Prednog u odgovoru ima postavljac teme, ostali neka se za sada uzdrze ...
[ a1234567 @ 19.01.2020. 11:40 ] @
Evo, javlja se postavljač :)
Ja sam došao do ovakvog rešenja
Code: niz = [3, 7, 11, 21, 25, 38, 41, 95, 118, 129, 144, 153]
n = 138
for i in niz:
if i > n:
ind = niz.index(i)
niz.insert(ind, n)
print(niz)
break
Koja je kompleksnost index f-je? Pretpostavljam da je O(n), pa je to ukupno kvadratna slozenost... sto je gore od predlozenog resenja.
edit:
nije kvadratna nego 2n :P
[Ovu poruku je menjao Branimir Maksimovic dana 19.01.2020. u 13:21 GMT+1]
[ B3R1 @ 19.01.2020. 12:30 ] @
U redu, to je sasvim lepo, skolsko resenje. Ali da li ce program optimalno raditi i za 100,000,000 elemenata, ako prodjes kroz ceo niz da bi ustanovio da broj treba ubaciti negde pred sam kraj niza? Imas li neki bolji predlog?
Edit: uzgred, ne radi ti program kada je n > niz[-1] (npr. n=153), kao i kada se n poklapa sa nekim postojecim elementom u nizu.
[Ovu poruku je menjao B3R1 dana 19.01.2020. u 14:50 GMT+1]
[ Branimir Maksimovic @ 19.01.2020. 14:49 ] @
Nego niz nije bas najsrecnija struktura za insertovanje elemenata pogotovo kad je veliki. Lista takodje nije ali dvostruko ulancana lista jeste.
No pitanje je koja je struktura podataka optimalna za ovaj zadatak? Necu reci ali to moze dati ideju kako resiti za niz :P
[ a1234567 @ 19.01.2020. 15:07 ] @
Citat:
B3R1:
U redu, to je sasvim lepo, skolsko resenje. Ali da li ce program optimalno raditi i za 100,000,000 elemenata, ako prodjes kroz ceo niz da bi ustanovio da broj treba ubaciti negde pred sam kraj niza? Imas li neki bolji predlog?
Edit: uzgred, ne radi ti program kada je n > niz[-1] (npr. n=153), kao i kada se n poklapa sa nekim postojecim elementom u nizu.
[Ovu poruku je menjao B3R1 dana 19.01.2020. u 14:50 GMT+1]
Ne znam hoće li raditi, moram da ga testiram :D
Samo da mi ne zariba komp.
Nego, imam drugu ideju.
Šta ako prvo odredim sredinu niza i uporedim broj na sredini sa mojim.
Ako je veći idem desno, ako je manji, idem levo i uštedeo sam očas 50.000.000 prolaza.
Šta misliš? Mada još nemam ideju kakako to praktično da izvedem, ali kao koncept misli da može da prođe :)
Možda sa len(lista), pa podelim na pola i dobijem indeks broja u sredini... i onda uporedim.
Ako tako seckam na pola, doći ću i do liste od recimo 20 brojeva, a onda mogu da odradim kao ovo rešenje koje sam dao.
[ a1234567 @ 19.01.2020. 15:14 ] @
E da, da se pohvalim :)
Išao dalje po onoj tvojoj knjizi, pa došao do zadatka:
za string
s = '1.23, 2.4, 3.123'
izračunaj zbir brojeva.
Code: s = '1.23, 2.4, 3.123'
q = s.split(', ')
total = 0
for i in q:
total = total + float(i)
print(total)
i radi!
6.753
[ B3R1 @ 19.01.2020. 17:44 ] @
Citat:
a1234567:
Šta ako prvo odredim sredinu niza i uporedim broj na sredini sa mojim. Ako je veći idem desno, ako je manji, idem levo i uštedeo sam očas 50.000.000 prolaza.
...
Ako tako seckam na pola, doći ću i do liste od recimo 20 brojeva, a onda mogu da odradim kao ovo rešenje koje sam dao.
Tacno tako! Uporedis broj na sredini sa zadatim. Ako je zadati broj veci, pomeris donju granicu niza na sredinu. Ako je broj maji pomeras gornju granicu na sredinu. Sada tu polovinu u kojoj se nalazi broj opet delis na pola. Ako je broj manji, gornju granicu pomeras na tu novu sredinu; ako je veci pomeras donju itd. Onda tu cetvrtinu delis na pola itd. dok ne dodjes do liste od dva broja.
Pokusaj da implementiras, nije tesko. Vidis kako ti lepo ide ...
[ a1234567 @ 20.01.2020. 02:22 ] @
Ništa nije teško, kad rešiš :)
Ali zato dok ne rešiš, muke Isusove.
Mislim, ideja za rešenje mi je bila jasna relativno brzo,
ali sam celo popodne lupao glavu oko implementacije.
No, mislim da sam došao do rešenja:
while len(niz) != 1:
mid = int(len(niz)/2)
if broj > niz[mid]:
niz = niz[mid:]
else:
niz = niz[:mid]
br_niz = niz.pop(0)
indx = niz_2.index(br_niz)
if broj > br_niz:
niz_2.insert(indx + 1, broj)
elif broj < br_niz:
niz_2.insert(indx - 1, broj)
else:
niz_2.insert(indx - 1, broj) #ovo u slučaju da je zadati broj isti kao i neki u nizu
print(niz_2)
Dosta sam vremena izgubio oko while funkcije, jer sam prvo stavio
while len(niz) == 1:
misleći da će se izvršavati, dok len ne postane 1. Ali, naravno, ništa se nije dešavalo.
Posle n pokušaja i očajanja :) uzmem knjigu i pročitam o while funkciji, a tamo lepo piše da se izvršava
sve dok uslov nije ispunjen. I onda mi sine šta treba da menjam.
Imao sam takođe muku kad na kraju dobijem listu od jednog člana, recimo niz = [129], kako da vrednost
tog člana pretvorim u integer, da bih mogao da dobijem njegov index. I onda natrčim na niz.pop funkciju. Zlata vredi! :)
Eto tako. Ovo je rudarski posao. Korak po korak, kao da kopam tunel i pipam u mraku.
Ali zato kad ga prokopaš i na kraju te obasja svetlo rešenja! :))) Ništa lepše!
[ Branimir Maksimovic @ 20.01.2020. 06:59 ] @
E sad insert u niz je O(n)...
Koja struktura podataka je idealna za ovaj zadatak?
[ a1234567 @ 20.01.2020. 07:10 ] @
Šta ti je O(n)?
Koja vrsta?
Pa valjda lista.
[ Branimir Maksimovic @ 20.01.2020. 07:19 ] @
To znaci n operacija (linearno). Znaci kada umeces element u niz, onda moras sve elemente sa desne strane da pomeris za jedno mesto sto je O(n).
[ a1234567 @ 20.01.2020. 07:30 ] @
Aha, pa dobro, pomerio sam ih, naravno. Ne možeš drugačije da ubaciš.
A što je to bitno? I dalje ne razumem smisao pitanja. Što i nije čudo, kad se bolje razmisli :)
[ a1234567 @ 20.01.2020. 07:33 ] @
A evo i novog zadatka iz Guttagove knjige:
Napiši program koji traži od korisnika da unese neki integer,
a potom štampa dva druga integera, root i pwr, tako da 0 < pwr < 6,
a root**pwr je jednako integeru koji je uneo korisnik.
Ako takav par inetegera ne postoji, program ispisuje odgovarajuću poruku.
[ Branimir Maksimovic @ 20.01.2020. 11:43 ] @
Citat:
a1234567:
Aha, pa dobro, pomerio sam ih, naravno. Ne možeš drugačije da ubaciš.
A što je to bitno? I dalje ne razumem smisao pitanja. Što i nije čudo, kad se bolje razmisli :)
Pitanje je koja je struktura podataka idealna za ovaj zadatak ;)?
[ B3R1 @ 20.01.2020. 12:07 ] @
Citat:
a1234567:
Aha, pa dobro, pomerio sam ih, naravno. Ne možeš drugačije da ubaciš.
A što je to bitno? I dalje ne razumem smisao pitanja. Što i nije čudo, kad se bolje razmisli :)
Branimir je mislio da te natera da pogledas kako su liste u Pythonu implementirane interno ... bas kao sto je onomad bila diskusija o tome kako su implementirani dict-ovi, pa si naucio da je to hash tabela, sto te je nateralo da naucis malo vise o hashevima ... Nije tesko pronaci i ovo o listama, dovoljno je da odes na Gugl i otkucas: python lists implementation ... i izaci ce ti gomila clanaka na tu temu. Tu ces videti tacno kako radi insert(), pop() itd.
U tim clancima su ponedge ponudjene i alternative. Ali mislim da si u ovom trenutku suvise daleko od tih alternativa. To je neki intermediate nivo ...
[ Branimir Maksimovic @ 20.01.2020. 12:15 ] @
Mislio sam na binarno stablo al ajde ;)
Nego, jel u pythonu ispod lista ili niz? U haskell-u je lista, pa je pristup preko index-a O(n) a insert jedino moguc na pocetak...
il opet O(n).
Znaci bilo lista bilo niz insert ce da uzme O(n), tako da sam mislio da implementira binarno stablo :P
Binarno stablo pretrazivanja je 1) sortirano 2) insert uzima O(log n)
Idealno za niz od 100_000_000 elemenata.
[ B3R1 @ 20.01.2020. 12:27 ] @
Citat:
Branimir Maksimovic:
Nego, jel u pythonu ispod lista ili niz? U haskell-u je lista, pa je pristup preko index-a O(n) a insert jedino moguc na pocetak...
Znaci bilo lista bilo niz insert ce da uzme O(n), tako da sam mislio da implementira binarno stablo :P
Linkovane liste, dvostruko ulinkovane liste, binarna stabla ... su vec napredniji kurs, a covek je tek na pocetku pocetaka. :-)
Inace za sve te strukture postoje moduli.
[ a1234567 @ 20.01.2020. 12:57 ] @
Ja tek seo na bicikl, a Branimir bi već da me posadi u bolid.
Polako čoveče, trebal negde da se skrljam!? :)))
Binarna i druga listopadna stabla... doći će i to na red jednog dana.
Sad smo još kod zimzelenih stringova, lista, rečnika i tupli. Zimski period :)
[ a1234567 @ 20.01.2020. 13:02 ] @
Berislave, jesi pogledao rešenje za tvoj zadatak koje sam dao?
Ima li neki bag ili da ga štrikliram?
[ B3R1 @ 20.01.2020. 14:03 ] @
Citat:
a1234567: Berislave, jesi pogledao rešenje za tvoj zadatak koje sam dao?
Ima li neki bag ili da ga štrikliram?
Ako si ga dobro testirao i ako radi nema razloga da ti ne verujemo. :-) Testiranje bi trebalo da obuhvati broj manji od niz[0], broj veci od niz[-1] i neki broj u sredini. Potom da vidis kako ce program reagovati za niz tipa [ 5, 5, 5, 5, 5 ] a da je zadata vrednost 4, 5 ili 6. Potom da testiras za niz [ 5 ] i niz [ 5, 5 ] i [ 5, 6 ]. Ako za sve te slucajeve radi, resio si problem. Izmisli jos slucajeva. Testiranje softvera je nauka za sebe, inace ...
Moja jedina zamerka bi bila da su ti dva niza visak. Motivacija za to ti je verovatno bila da sacuvas prvobitni niz kako bi ga kasnije modifikovao, a da nad originalnim nizom radis svu "hirurgiju". Nema nikakve potrebe za hirurgijom, imajuci u vidu da ti vec rukujes indeksima. Niz menjas tek na kraju. Evo alternativnog resenja:
Code: niz = [3, 7, 11, 21, 25, 38, 41, 95, 118, 129, 144, 153, 174]
broj = 138
if broj < niz[0]:
niz.insert(0, broj)
elif broj > niz[-1]:
niz.append(broj)
else:
levo = 0
desno = len(niz)
while desno-levo > 1:
mid = (levo + desno) / 2
if broj >= niz[mid]:
levo = mid
else:
desno = mid
niz.insert(desno, broj)
print niz
[ Branimir Maksimovic @ 21.01.2020. 01:37 ] @
Mislim da generalno da radis binary search tako sto ces da slajsujes, a onda pozoves index nad elementom nije nesto sto ima intellectual merit :P
[ a1234567 @ 22.01.2020. 17:16 ] @
Novi, zanimljiv zadatak broj 15:
Napiši program koji će dešifrovati poruku pisanu Morzeovom azbukom?
U slučaju da možda, eventualno, ipak ne znate znakove ove azbuke, ovde su:
Hmmm ... i dalje ne kapiras kako radi Python dict:
Code: for i in poruka2:
for key, value in morse.items():
if i == key:
print(value, ' ', end='')
Cemu ovo? morse[key] ti daje direktnu vrednost 'value', prema tome dovoljno je reci:
Code: for i in poruka2:
if (i in morse):
print(morse[i], ' ', end='')
Nesto tezi slucaj je ovaj inverzni, kada sa Morzeovog koda prevodis u alfabet. Tu vec ima smisla ova "for key, value ..." petlja, mada moze i elegantnije: tako sto ces uvesti poseban dict gde su kljucevi Morzeovi kodovi, a vrednosti slova alfabeta. Ali svakako da ne moras da rucno pravis taj drugi dict - njega pravis na pocetku programa na osnovu 'morse':
Code: alphabet = {}
for key, value in morse:
alphabet[value] = key
ili skraceno:
Code: alphabet = dict((v, k) for k, v in morse.iteritems())
Time se program uproscava:
Code:
for i in poruka1:
if (i in alphabet):
print(alphabet[i], ' ', end='')
for i in poruka2:
if (i in morse):
print(morse[i], ' ', end='')
[ a1234567 @ 24.01.2020. 15:05 ] @
To rešenje za poruka2 sam samo prepisao od poruka1 i zamenio šta je trebalo zameniti :)
I pošto radi, ništa više ne pipam!
[ a1234567 @ 24.01.2020. 15:13 ] @
E a sada da mi krenemo na zadatak broj 16.
Ovoga puta je vrlo kratak, treba zadati broj ispisati slovima.
Unesi pozitivan broj od 1 do 1000: 529
petsto dvadeset devet
bilo je sa and, al ne radi kako treba
pa sam zato stavio u drugi red.
[ a1234567 @ 25.01.2020. 17:52 ] @
Zadatak broj 18
Treba napraviti računaljku za onu igru Scrabble, gde slažeš kockice sa slovima, kao u ukrštenim rečima,
Svako slovo nosi određeni broj bodova, tako da kad sastaviš reč, dobijaš zbir tih bodova.
Nije neki problem, sve dok nisam došao do sabiranja naših slova od dva znaka: LJ, NJ, DŽ
jer ih petlja razloži, pa računa svako slovo posebno.
Trebalo bi valjda sa nekim find prvo ustanoviti ima li ta tri slova u zadatoj reči i ako ima za svako dodati 10 bodova. Onda izbaciti iz reči to slovo i obračunati za ostala kao što je gore dato.
[ Panta_ @ 26.01.2020. 06:18 ] @
Recimo, jednostavno da kreiraš promenljivu npr. t i da bude t=i svaki put osim kada je t+i u recniku.
"bilo je sa and, al ne radi kako treba"
if i not in slova and i != ' '
[ Branimir Maksimovic @ 26.01.2020. 06:59 ] @
Kako je 'LJ' slovo od dva znaka, jednostavno tako treba i uneti.
[ a1234567 @ 26.01.2020. 07:05 ] @
Da, i onda ga računa
L = 3
J = 3
dakle ukupno 6,
a LJ je u stvari 10 bodova!?
[ djoka_l @ 27.01.2020. 18:38 ] @
Inženjeru koji ima samo čekić, svaki problem izgleda kao ekser.
Nemoj samo šablonski da razmišljaš...
while i<len(rec):
spec = rec[i:i+2]
if spec == 'LJ' or spec == 'NJ' or spec == 'DŽ':
zbir+=10
i+=2
else:
zbir += bodovi[rec[i]]
i+=1
print('Zbir za ovu reč je:', zbir)
Inače, programi za parsiranje regularnih izraza koriste "look ahead" odnosno "look behind" tehnike za uparivanje. Ovo je jedna implementacija look ahead tehnike. Nije dovoljno sam na osnovu tekućeg slova da se odredi vrednost, nego je, ponekad, potrebno i sledeće slovo...
[ djoka_l @ 27.01.2020. 18:51 ] @
Drugim rečima, ako ti trebaju dva slova, ima da uzmeš dva slova...
for i in rec: if t !=''and bodovi.get(t+i):
zbir += bodovi[t+i]
zbir-=bodovi[t] else:
zbir += bodovi[i]
t=i
print('Zbir za ovu reč je:', zbir)
Zbir za ovu reč je: 14
Radi i kada nije vrednost za sva tri slova 10.
[ djoka_l @ 27.01.2020. 20:28 ] @
Uradi si praktično isto što i ja, možda malo elegantnije.
Moja ideja je samo bila da pokažem da nije hash lista jedini alat (čekić) u torbi sa alatom, nego da može i na drugačiji način da se radi.
[ a1234567 @ 28.01.2020. 03:17 ] @
E super ste obojica, hvala na rešenju!
Ali:
Đokino rešenje mi je sasvim jasno,
a tvoje Panto uopšte ne kapiram šta radi taj t = ''
Kako on dobije vrednost drugačiju od praznog niza?
Daj neki komentar, ne škrtari :)
[ Panta_ @ 28.01.2020. 07:51 ] @
Prilično jednostavno. Osnovno, ukoliko uslov (if) nije ispunjen tj. ako t+i nije u rečniku, izvršava se else, tj. t=i, zatim, pri narednom prolasku petlje (for), t je L a i je J, kako je 'L' + 'J' u rečniku, izvršava se if, itd.
Sad sam uklavirio. Kad sam video da oduzimaš t u slučaju da je [t+i]. Toga se ne bih nikad setio.
Lepo sam ja rekao još onomad, Panta mađioničar :)
E pa dobro, ovo je bilo korisno, jer sam naučio novu stvar koju je Đoka pomenuo: look ahead.
Moram to malo pogledati na netu. Nego mi pada na pamet da smo tom tehnikom mogli izbrojati one nizove jedinica i nula kad smo računali pismo i glava.
00011100001111010100111100
[ a1234567 @ 05.02.2020. 15:58 ] @
Evo stiže i zadatak broj 19.
Još malo pa jubilej!
E ovoga puta je stvar malo drugačija. Do sada sam kucao tekst u IDLE, pa F5 i program se izvrši. Sada menjamo taktiku.
Dakle, treba napisati program, sačuvati ga na disku, pa ga pokrenuti preko komandne linije.
Pri pokretanju programa dodajemo i jedan argument, a to je ime tekstualnog fajla.
Nešto ovako:
>>> python moj_program.py text.txt
Naš programčić treba da učita taj tekstualni fajl, proveri da li je dat argument. Ako nije, ispiše odgovarajuću poruku.
Ako jeste dat, onda ispiše poslednjih deset redova teksta iz učitanog fajla..
Kažu da u unix sistemima postoji isti ovakav program, koji se zove tail. Ajd da im verujemo :)
[Ovu poruku je menjao a1234567 dana 06.02.2020. u 02:55 GMT+1]
[Ovu poruku je menjao a1234567 dana 06.02.2020. u 02:56 GMT+1]
[ Branimir Maksimovic @ 05.02.2020. 16:23 ] @
Nije isti, moze mnogo vise.
[ a1234567 @ 06.02.2020. 01:54 ] @
Pa šta smo mi windowsaši šugavi, pa je taj program samo za unix!?
E napravićemo još bolji i još stariji
[Ovu poruku je menjao a1234567 dana 06.02.2020. u 05:21 GMT+1]
[ Branimir Maksimovic @ 06.02.2020. 02:17 ] @
Citat:
a1234567:
Pa šta smo mi windowsaši šugavi, pa je taj program samo za unix!?
E napravićemo još bolji i još stariji :D
tail koristim za pracenje log-ova, i da vidim zadnje linije izlaza neke komande.
recimo tail -f logfile ili : komanda | tail -n 10
znaci, u prvom slucaju -f opcija da se prati fajl kako raste a u drugom cita sa stdin-a
pa -n prikazuje zadnjih toliko linija izlaza.
Napravi tako na Win-u :P
[ a1234567 @ 06.02.2020. 04:22 ] @
Napravio sam da se vidi poslednjih deset lniija.
Nisam još probao, ali pretpostavljam da mogu da ga prepravim da vidi poslednjih n linija, a da -n bude argument.
[ Panta_ @ 06.02.2020. 11:28 ] @
"Napravio sam da se vidi poslednjih deset lniija."
Dobro je to ako imaš mali fajl, npr. par MB ili malo više, a ša ako recimo imaš fajl od par GB ili više. Na primer:
Code: du -h log.txt
1.6G log.txt
# Komanda tail
$ time tail log.txt
tail log.txt 0.00s user 0.00s system 85% cpu 0.002 total
# Tvoj tail program
$ time ./tail.py
./tail.py 8.74s user 0.40s system 99% cpu 9.139 total
Problem je što tvoj kod prolazi kroz ceo fajl da bi prikazao poslednjih 10 linija, zar nije bolje da krene od poslednje linije u fajlu.
Da definišeš poziciju, pogledaj seek funkciju:
Citat:
seek(target, whence=0, /) method of _io.BufferedReader instance
Change stream position.
Change the stream position to the given byte offset. The offset is
interpreted relative to the position indicated by whence. Values
for whence are:
* 0 -- start of stream (the default); offset should be zero or positive
* 1 -- current stream position; offset may be negative
* 2 -- end of stream; offset is usually negative
Return the new absolute position.
Na primer:
Code: # Krece od poslednje linije
position = fh.seek(0, 2)
# ....
$ time ./tail.py
./tail.py 0.02s user 0.00s system 97% cpu 0.025 total
Mnogo bolje zar ne? Sad ti samo ostaje da implementiraš ostatak koda.
[ a1234567 @ 06.02.2020. 11:45 ] @
"97% cpu"
Ovo mi se najviše dopada. Al sam ga nagazio, do daske! :D
Pa nek radi. Bolje nego da se hvata na njega prašina :)
Dobro, veliki fajl. Ja sam krenuo sa txt fajlom od 50 redova, sitno,
a ti Panto bi odmah u veleprodaju. Lagano, dok se uhoda radnja.
Za seek znam. E to sam se patio dok nisam prokljuvio, zašto neće da čita fajl opet ispočetka, već došao do kraja i na print samo mi kaže "".
Ni makac!
Da bolje je otići na kraj fajla, pa krenuti odnazad.
A jel ima neka komanda reverse, ko u listi [-1], pa pretumba redove i čita poslednje od početka?
[ Panta_ @ 06.02.2020. 12:04 ] @
Tvom programu treba 9 sekundi da se izvši dok se tail komanda izvršava za 0.002.
[ djoka_l @ 06.02.2020. 12:14 ] @
To 97% ne znači to što ti misliš.
To samo znači da je 97% realnog vremena (vremena između momenta od kada si lupio enter dok se nije komanda završila) procesor radio nad tvojim programom u poređenju sa vremenom koje je tvoj program stvarno potrošio.
Drugim rečima, računar nije radio ništa pametno, osim što je izvršavao python program.
Da je bilo nešto drugo da se radi, ne bi ti bio dodeljeno 97% procesorskog vremena. Idealno, želeo bi da dobiješ iznad 98% , ali to je malo teže na sistemu koji ima šta pametno da radi, a ne da vrti školske python programe.
[ Panta_ @ 06.02.2020. 12:23 ] @
"A jel ima neka komanda reverse, ko u listi [-1], pa pretumba redove i čita poslednje od početka?"
Ima reversed ili readlines()[::-1].
[ Branimir Maksimovic @ 06.02.2020. 15:56 ] @
Inace ovo se najbrze radi tako sto se fajl mapira u memoriju pa se cita od pozadi. E sad ne verujem da je to izvodljivo u Pythonu osim preko C biblioteke, a verujem da to mora
da ima.
[ a1234567 @ 06.02.2020. 16:46 ] @
Naišao sam na ovo zanimljivo rešenje
Code: with open('logfile.txt', 'rb') as f:
f.seek(-2, 2)
while f.read(1) != b'\n':
f.seek(-2, 1)
print(f.readline().decode())
Vrati ga do kraja fajla i onda ide redom unazad po dva bajta dok ne naiđe na kraj reda.
Ali tako otprinta samo poslednji red fajla.
E sad kako da to uradi recimo 5 puta.
Stavio ga u petlju, ali mi printa pet puta poslednju rečenicu :)
Kako ga ubediti da nastavi unazad od prvog kraja reda?
[ Panta_ @ 06.02.2020. 19:52 ] @
Zapamti poziciju pre f.readline(). readline() resetuje poziciju na kraj linije, pa petlja ponovo vrti istu liniju. Na primer:
Tako sam i ja zamišljao da mu sa fajl.tell() zabeležim poziciju,
ali nisam znao kako da nastavim.
No, ovo tvoje rešenje štampa redove unazad, 5, 4, 3, 2, 1.
Ja sam još malo doradio i sad printa redovnim redosledom 1, 2, 3, 4, 5
Code: redovi = []
with open('new1.txt', 'rb') as f:
f.seek(-2, 2)
counter = 0
while counter < 5:
while f.read(1) != b'\n':
f.seek(-2, 1)
pos = f.tell()
redovi.append(f.readline().decode())
f.seek(pos - 2)
counter += 1
print(*redovi[::-1], sep='\n')
[ Panta_ @ 07.02.2020. 05:25 ] @
Nije to moje rešeje već tvoje, samo sam ti napisao kao da pređe na novu liniju, da ne vrti uvek istu. Ima tu još nedostataka, šta ako recimo fajl ima samo 3 linije, tj. manje od onoga što je navedeno u counter. Linuksova tail komanda radi iako je podrazumevano 10.
Nije naročito veliki program, samo 2537 linija C koda, mogu da se nauče lepe stvari...
[ a1234567 @ 07.02.2020. 15:25 ] @
Citat:
Panta_:
Nije to moje rešeje već tvoje, samo sam ti napisao kao da pređe na novu liniju, da ne vrti uvek istu. Ima tu još nedostataka, šta ako recimo fajl ima samo 3 linije, tj. manje od onoga što je navedeno u counter. Linuksova tail komanda radi iako je podrazumevano 10.
Hm. Pa zato smo tražili ovo rešenje, jer su pretpostavljeni fajlovi mnooogo veći od 3 reda.
Mada, ok, mogao bi prvo program da prebroji redove u fajlu i onda limitira broj traženih redova za izlistavanje.
Ali onda smo opet na početku. Kako prebrojati redove, a da program ne prođe kroz ceo fajl?
Što smo hteli da izbegnemo :)
Nije naročito veliki program, samo 2537 linija C koda, mogu da se nauče lepe stvari...
Pogledao, lepo izgleda, samo što ne razumem mnogo.
No, blizu sam. Još svega 2530 redova :))
Nego, kod ovog pozivanja programa preko komandne linije,
kako dajem mogućnost za dodatne parametre?
Recimo, ako hoću da zadam broj linija koje treba da izlista.
> python tail.py new1.txt 5
[ Panta_ @ 07.02.2020. 21:02 ] @
Citat:
Hm. Pa zato smo tražili ovo rešenje, jer su pretpostavljeni fajlovi mnooogo veći od 3 reda.
Mada, ok, mogao bi prvo program da prebroji redove u fajlu i onda limitira broj traženih redova za izlistavanje.
A možeš samo da proveriš poziciju, tj. ako je f.tell() == 0 (početak fajla), onda prekineš dalje izvršavanje (break) i ispišeš linije.
[ a1234567 @ 08.02.2020. 02:00 ] @
Ne razumem ideju.
Posle open svakako je pozicija na početku fajla, koliko god da ima redova taj fajl.
U čemu je poenta sa proveravanjem pozicije?
[ djoka_l @ 08.02.2020. 02:11 ] @
Ideja koju ti je Panta dao je da kreneš UNAZAD (seek metoda) od kraja fajla i da brojiš redove.
Kada izbrojiš 10 redova ILI kada si u pretrazi došao do početka (tell daje 0), onda izlaziš iz petlje i ispisuješ redove.
[ a1234567 @ 08.02.2020. 07:09 ] @
E sad sam skapirao. Polako to ide, ali eto, mrda :)
Dakle, plan:
zadaš broj redova, recimo 5
otvoriš fajl
pomeriš kursor na kraj-2
while petlja 1:
ideš unazad po dva bajta dok ne dođeš do kraja prethodnog reda, \n
ona je unutar while petlje 2
koja broji redove do 5
a sve to je u if... else
if fajl.tell() != 0:
vrti petlju
else:
print('nema toliko redova')
E ovo je loš plan, jer sam probao i kod kratkog fajla od tri reda, ne stigne do 5, već javi grešku.
Dakle, trebalo bi verovatno ovu drugu petlju napraviti if...else, da zaustavi brojanje,
pa ako dođe do 0, da ne vrti dalje. Moram i to probati, samo još da vidim kako.
[ Branimir Maksimovic @ 08.02.2020. 07:15 ] @
To je znaci samo za Windows resenje. Na OSX \r i na Linux-u \n su samo jedan bajt.
[ Panta_ @ 08.02.2020. 07:20 ] @
Citat:
tail koristim za pracenje log-ova, i da vidim zadnje linije izlaza neke komande.
recimo tail -f logfile ili : komanda | tail -n 10
Da li si siguran da ti radi taj primer? Komanda tail -f konstantno čita iz log fajla, tj. nikad se ne završava, kako onda da prosledi izlaz drugoj tail komandi?
[ Branimir Maksimovic @ 08.02.2020. 07:25 ] @
Ne ne, to su dva primera, ne jedan. Znaci jedna je da pratis log, druga da prikazes zadnjih 10 linija neke komande.
[ Panta_ @ 08.02.2020. 07:39 ] @
Ja sam zbog | znaka mislio da je jedna.
"Dakle, trebalo bi verovatno ovu drugu petlju napraviti if...else, da zaustavi brojanje"
Ili da ukloniš jednu petlju, dovoljna je jedna, ova što broji linije. Zatim proveriš poziciju, ako nije nula, onda proveriš znak, ako je \n, pročitaš liniju i uvećaš brojač, itd.
[ a1234567 @ 08.02.2020. 09:56 ] @
Nešto sam ovako nabo, ali na žalost ne radi kad je u fajlu manje linija od zadatih.
Što je još gore, ne vidim zašto.
Code: redovi = []
red = 0
with open('new1.txt', 'rb') as f:
f.seek(-2, 2)
while red < 5:
while f.read(1) != b'\n':
f.seek(-2, 1)
if f.tell() == 0:
print('kratak fajl')
break
pos = f.tell()
redovi.append(f.readline().decode())
f.seek(pos - 2)
red += 1
print(*redovi[::-1], sep='\n')
[ Panta_ @ 08.02.2020. 11:06 ] @
Na pogrešnom mestu ti je if. Prvo proveriš sa f.tell() da li je početak fajla, pa onda pomeriš poziciju sa f.seek(). Takođe, pošto imaš jednu petlju viška, moraš i njeno izvršavanje da prekineš, inače ona i dalje nastavlja izvršavanje. Na primer:
Code (python):
redovi =[]
red =0
done=False withopen('new1.txt','rb')as f:
f.seek(-2,2) while red <5: while f.read(1)!= b'\n': if f.tell()<=1:
f.seek(0)
redovi.append(f.readline().decode())
done=True # break else:
f.seek(-2,1) if done: break
pos = f.tell()
redovi.append(f.readline().decode())
f.seek(pos - 2)
red +=1 print(*redovi[::-1], sep='')
Malo je komplikovano, zato sam i naveo jednostavniji primer sa jednom petljom.
[ a1234567 @ 08.02.2020. 12:21 ] @
Vala mene i jeste komplikovano.
Ovo done mi je novost. Što si tu stavio done = True, a ne obično break?
[ Branimir Maksimovic @ 08.02.2020. 12:36 ] @
Zato sto python nema goto? Ili break label.
[ Panta_ @ 08.02.2020. 13:21 ] @
"Što si tu stavio done = True, a ne obično break?"
Zato što isti neće da prekine izvršavanje prve petlje.
"The break statement allows the programmer to terminate a loop early, and the continue statement allows the programmer to move to the next iteration of a loop early. In Python currently, break and continue can apply only to the innermost enclosing loop."
Zanimljivo.
[ B3R1 @ 09.02.2020. 08:32 ] @
Citat:
a1234567: In Python currently, break and continue can apply only to the innermost enclosing loop."
Nije to samo u Pythonu. Identicna filozofija je i u PHP, Perlu i mnogim drugim jezicima. Zapravo, sve vuce korene iz C, gde je to tako reseno.
[ Branimir Maksimovic @ 09.02.2020. 09:04 ] @
Noviji jezici imaju rust, nim, golang. to je zato sto je koriscenje goto tu prirodno, a kao sto znamo goto je evil :P
[ a1234567 @ 09.02.2020. 09:17 ] @
Eto Rosum pretabačio C i pravi se toša :D
A što je goto evil?
Pa bilo bi lepo da njime možeš da zakočiš jednu petlji i skočiš drugu.
[ Branimir Maksimovic @ 09.02.2020. 09:28 ] @
Ma goto je evil od ranijih dana kada nije postojalo struktuirano programiranje pa je skakanje sa linije na
liniju pravilo spageti kod. No sada, kada imas while for case koriscenje i nije neophodno osim eto
kada ne mozes da izadjes iz unutrasnje petlje ili kada treba da skocis na obradu greske.
[ djoka_l @ 09.02.2020. 11:35 ] @
Samo što svi ti nabrojani jezici imaju i goto, kada baš zatreba.
A i C, koji nema exception konstrukciju, ima longjump
[ a1234567 @ 09.02.2020. 15:29 ] @
Došao je na red i jubilarni 20. zadatak.
Vidim da ovaj čovek traži Python program za OCR-ovanje, pa umalo da to postavim kao zadatak. :)
Ali se bojim da bi malo potrajalo, a čoveku se sigurno žuri...
Zato ipak idemo na nešto drugo, a možda i to nekom zatreba.
Ovoga puta treba spojiti dva fajla u treći i to iz komandne linije.
Nešto ovako:
> python spoji.py fajl1.txt fajl2.txt fajl3.txt
Malo sam eksperimentisao i nije tako teško kao što mi se u prvi trenutak učinilo.
Pa sam svoje rešenje postavio ovde.
[ a1234567 @ 09.02.2020. 15:43 ] @
E sad pitanje.
Jel moguća varijanta da se ne zada broj fajlova unapred?
I kako?
Pa šta, jel fora da koliko god mu zadaš argumenata u komandnoj liniji, sys modul to upiše u argv?
[ djoka_l @ 10.02.2020. 14:45 ] @
Naravno, zar si mislio da računar telepatijom pogađa koliko ti argumenata treba, pa ti onda toliko šalje, ili da šalje sve što si napisao u komandnoj liniji?
Naravno, na normalnim operativnim sistemima (Linux), shell radi ekspanziju naziva fajlova, dok glupavi Windows to ne ume da radi.
Na linuxu bi
py argv.py *.txt velikifajl.txt
Umesto *.txt stavio sve fajlove koji u direktorijumu iz kog si pozvao fajl imaju ekstenziju txt, dok Win šalje tačno ono što je napisano, pa onda ti traži fajlove koji odgovoraju imenu sa džoker znacima.
[ a1234567 @ 10.02.2020. 15:09 ] @
Nisam mislio baš na telepatiju, ali jesam da mu možda u kodu definišeš broj argumenata, pa modul odatle to čita.
[ a1234567 @ 10.02.2020. 16:46 ] @
Zadatak 21
Napravi program koji čita tekst iz fajla, dodaje redni broj ispred svakog reda
i tako numerisan tekst snima u novi fajl.
Naziv oba fajla će biti dat iz komandne linije.
Svaki red u novom fajlu počinje rednim brojem, dvotačkom i razmakom.
Samo toliko za ovaj put.
[ Panta_ @ 11.02.2020. 08:30 ] @
Citat:
Na linuxu bi
py argv.py *.txt velikifajl.txt
Umesto *.txt stavio sve fajlove koji u direktorijumu iz kog si pozvao fajl imaju ekstenziju txt, dok Win šalje tačno ono što je napisano, pa onda ti traži fajlove koji odgovoraju imenu sa džoker znacima.
Ima Python glob modul kome može da se prosledi argument, na primer:
Ako neko ima neku drugačiju ideju, nek iskomentariše.
[ Panta_ @ 13.02.2020. 13:55 ] @
Code (python):
importfileinput importsys
withopen(sys.argv[2],'w')as fh: for line infileinput.input(files=sys.argv[1]):
fh.write(f'{fileinput.lineno()}: {line}')
Zadatak je sličan Linuksovoj nl komandi, ili više cat -n komandi koja takođe numeriše prazne linije. Obe komande imaju opcije da numerišu ili preskoče prazne linije, takođe mogu da procesuiraju više od jednog fajla. Na primer:
Code (bash):
# Komand `cat -n` slično tvom programu numeriše prazne linije # što u nekim slučajevima i inije baš najbolje rešenje
cat-n1.txt 2.txt 1 one 2 two 3 three 4 four 5 6 five 7 six
# Za razliku od pomenute, komanda `nl` podrazumevano preskače prazne linije
nl1.txt 2.txt 1 one 2 two 3 three 4 four
5 five 6 six
Probaj da implementiraš nešto slično u tvom programu.
[ a1234567 @ 13.02.2020. 16:53 ] @
Pa evo ova petlja preskače prazne redove:
Code: import sys
novi = open('novi.txt', 'w', encoding='utf-8')
broj = 1
with open('stari.txt', 'r') as f:
for line in f:
if len(line) == 1:
novi.writelines(line)
else:
novi.writelines(str(broj) + ' ' + line)
broj += 1
novi.close()
Ispis: 1 First Part.
2 By whom missioned falls the mind shot to its mark?
3 By whom yoked moved the first life-breath forward on its paths?
4 By whom impelled is this word that men speak?
5 What god set eye and ear to their workings?
6 That which is hearing of our
7 The wise are released beyond
8 There sight not, nor speech, nor the
[ Panta_ @ 14.02.2020. 05:08 ] @
Dobro, sad napiši da radi sa više fajlova, recimo da spojiš 4 u jedan fajl, slično kao gore pomenuta nl komanda, stim što tvoj program upisuje u fajl. Na primer:
tu je, spaja 4 fajla i numeriše svaki red, sem praznih:
Code: if len(sys.argv) != 6:
print("Unesi ime 4 ulazna i 1 izlaznog fajla u komandnoj liniji.")
quit()
broj = 1
novi = open(sys.argv[5], "w")
try:
for i in range(1, 4)
with open(sys.argv[i], 'r') as f:
for line in f:
if len(line) == 1:
novi.writelines(line)
else:
novi.writelines(str(broj) + ' ' + line)
broj += 1
except:
print("Dogodila se greška pri učitavanju fajla.")
quit()
kako da mu zadam i opcije, da recimo u jednoj varijanti numeriše sve redove (-ns), a u drugoj da preskoči prazne redobe (-nt)?
I kako onda da mu napravim help fajl da pokaže šta koja opcija znači (-h)?
Nego, taman se ja izborio sam ovim tail programčićem, kad danas natrčim na ovo
Code: from collections import deque
def tail(filename, n=10):
with open(filename) as f:
return deque(f, n)
print(tail('new2.txt'))
Da sam video ranije, nisam se morao mučiti
[ a1234567 @ 15.02.2020. 14:30 ] @
Pogledao argparse i nije mi jasno kad jednom postavim argumente,
kako napravim skretnicu da jedan argument usmerava ka petlji koja numeriše sve redove,
a drugi kao petlji koja preskače prazne redove.
Trebalo bi u jednoj negde da udenem agparse.numesve,
a kod druge agparse.neprazne, ali ne znam kako :)
Code: import sys
import argparse
parser = argparse.ArgumentParser(description='Numeriši redove u tekstu.')
parser.add_argument('--numsve', type=str, help='numeriši sve redove')
parser.add_argument("--neprazne", type=str, help='preskoči prazne redove')
args = parser.parse_args()
# Provera da su dati svi argumenti.
if len(sys.argv) != 4:
print("Unesi naziv 2 ulazna i 1 izlaznog fajla u komandnoj liniji.")
quit()
broj = 1
novi = open(sys.argv[3], 'w')
try:
for i in range(1, 3):
with open(sys.argv[i], 'r') as f:
for i, line in enumerate(f, start=1):
novi.writelines(('{}: {}'.format(i, line)))
except:
print("Dogodila se greška pri učitavanju fajla.")
quit()
try:
for i in range(1, 3):
with open(sys.argv[i], 'r') as f:
for line in f:
if len(line) == 1:
novi.writelines(line)
else:
novi.writelines(str(broj) + ' ' + line)
broj += 1
except:
print("Dogodila se greška pri učitavanju fajla.")
quit()
[ Panta_ @ 15.02.2020. 20:18 ] @
Nisu ti potrebna dva argumenta, dovoljan je jedan. Ne znam šta te buni, jednostavno "if args.numsve: petlja 1 else: petlja 2" ili elif ako imaš više argumenata. Kako argument ne zahteva neku vrednost, zameni type=str sa action="store_true".
[ a1234567 @ 16.02.2020. 05:07 ] @
Uradio, ali javlja grešku. Ne prepoznaje poslednja 2 argumenta.
parser = argparse.ArgumentParser(description='Numeriši redove u tekstu.')
parser.add_argument('--numsve', action='store_true', help='numeriši sve redove')
args = parser.parse_args()
# Provera da su dati svi argumenti.
if len(sys.argv) != 4:
print("Unesi naziv 2 ulazna i 1 izlaznog fajla u komandnoj liniji.")
quit()
broj = 1
novi = open(sys.argv[3], 'w')
if args.numsve:
try:
for i in range(1, 3):
with open(sys.argv[i], 'r') as f:
for i, line in enumerate(f, start=1):
novi.writelines(('{}: {}'.format(i, line)))
except:
print("Dogodila se greška pri učitavanju fajla.")
quit()
else:
try:
for i in range(1, 3):
with open(sys.argv[i], 'r') as f:
for line in f:
if len(line) == 1:
novi.writelines(line)
else:
novi.writelines(str(broj) + ' ' + line)
broj += 1
except:
print("Dogodila se greška pri učitavanju fajla.")
quit()
# Provera da su dati svi argumenti. iflen(args.files)!=3: print("Unesi naziv 2 ulazna i 1 izlaznog fajla u komandnoj liniji.")
quit()
broj =1
novi =open(args.files[2],'w')
if args.numsve: try: for i inrange(len(args.files) - 1): withopen(args.files[i],'r')as f: for i, line inenumerate(f, start=1):
novi.writelines(('{}: {}'.format(i, line)))
except: print("Dogodila se greška pri učitavanju fajla.")
quit()
else: try: for i inrange(len(args.files) - 1): withopen(args.files[i],'r')as f: for line in f: iflen(line)==1:
novi.writelines(line) else:
novi.writelines(str(broj) + ' ' + line)
broj +=1
except: print("Dogodila se greška pri učitavanju fajla.")
quit()
Inače, ova linija "for i, line in enumerate(f, start=1)" počinje ponovo od broja 1 prilikom narednog prolaska prethodne for petlje, pa imaš ponovo numerisanje od 1, 2, 3, itd.
[ Panta_ @ 16.02.2020. 09:11 ] @
Evo malo jednostavnijeg rešenja bez duplih try i for:
Code (python):
importsys import argparse importfileinput
parser= argparse.ArgumentParser(description='Numeriši redove u tekstu.') parser.add_argument('--numsve', action='store_true',help='numeriši sve redove') parser.add_argument("files", nargs=argparse.REMAINDER)
args =parser.parse_args()
# Provera da su dati svi argumenti. iflen(args.files)!=3: print("Unesi naziv 2 ulazna i 1 izlaznog fajla u komandnoj liniji.") parser.print_help() sys.exit()
broj =1
novi =open(args.files[2],'w')
try: for line infileinput.input(files=args.files[:2]): if args.numsve: if line.strip()=='':
novi.write(line) else:
novi.write(f'{broj}: {line}')
broj+=1 else:
novi.write(f'{broj}: {line}')
broj+=1 except FileNotFoundError as err: print(f'No such file: {err.filename}') parser.print_help() finally:
novi.close()
[ a1234567 @ 17.02.2020. 10:57 ] @
Da, ja sam samo kopirao obe petlje, a naravno da mogu obe da se stave u jednu.
Hvala Panto na lekciji!
[ a1234567 @ 17.02.2020. 11:10 ] @
Sledi naravno zadatak broj 22
Napiši program koji nalazi najdužu reč/reči u tekstu. Prvo uklanja
svu interpunkciju, a na kraju ispisuje odgovarajuću poruku,
koja uključuje broj slova najduže reči, zajedno sa svim rečima
te dužine koje se nalaze u tekstu.
Nema nikakvih komentara za rešenje zadatka broj 22,
što jedino mogu da protumačim tako da je bez mana
Zato idemo na zadatak broj 23:
# Jedna od tehnika koje se koriste pri razbijanju neke jednostavnije forme enkripcije je utvrđivanje
# koja slova se u nekom tekstu najčešće pojavljuju. Zatim se ona mapiraju najučestalijim
# slovima iz datog jezika. Ne znam koja su najučestalija slova u srpskom, ali uz ovaj program možemo to utvrditi,
# ako uzmemo dovoljno velik uzorak. Ovaj program broji koliko se svako slovo teksta puta ponavlja i ispisuje
# odgovarajuću tabelu: "slovo = broj ponavljanja". Korisnik prilikom pokretanja programa navodi ime fajla za analizu.
# Program ga upozorava ako to nije učinio ili ako nije u stanju da otvori traženi fajl.
Zašto brojiš samo slova, a pri tom praviš razliku između malih i velikih slova?
Budi dosledan, ili prebroj SVE znake, uključujući interpunkciju i razmake, ili broj samo slova, ali onda nemoj da praviš razliku mala/velika slova.
[ a1234567 @ 19.02.2020. 02:49 ] @
Takav je zadatak. Naći koje slovo je najčešće.
Ali u pravu si, nema potrebe da razdvajam velika i mala slova.
Zato sam dodao jedan
tekst.lower()
i sve u redu
Sada je ispis slova sortiran po abecedi. Bilo bi zanimljivo da postoji i
opcija da se ispis sortira po učestalosti. Od najvećeg do najmanjeg broja.
I kao šlag na tortu, da program sabere sve te brojeve i ispiše koliko je
ukupno slova u tekstu.
Moram još to da provalim, pre nego što rešenje pošaljem guglu
Sada ispisuje sortirano i po slovima i po broju ponavljanja,
u zavisnosti šta mušterija odabere. :)
Kao bonus, dobija na kraju i ukupan broj slova.
Ma sve servirano ko na tacni :))
Ostala je još jedna začkoljica.
Kad ispisuje prema broju ponavljanja, ide od najmanjeg ka najvećem:
15019 = l
15341 = d
15365 = p
17206 = m
19288 = k
19598 = v
19610 = u
21376 = t
23857 = j
27513 = s
34764 = n
43633 = e
47215 = o
52152 = i
53968 = a
Ne znam kako da ga sortiram u opadajućem nizu.
[ Branimir Maksimovic @ 19.02.2020. 05:54 ] @
A evo i nesto u rustu:
Code:
use std::fs::File;
use std::io::prelude::*;
use std::collections::*;
fn main()-> Result<(),String> {
let args:Vec<_> = std::env::args().collect();
if args.len() != 2 {
return Err(format!("expected: {} file_name",args[0]));
}
let mut f = File::open(args[1].clone()).unwrap();
let mut contents = String::new();
let _ = f.read_to_string(&mut contents);
let filtered = contents.chars().filter(|c|c.is_alphabetic()).collect::<String>().to_lowercase();
let mut hm:HashMap<char,i32>=HashMap::new();
for l in filtered.chars() {
let r = hm.entry(l).or_insert(0);
*r += 1;
}
let mut sorted:Vec<(i32,char)> = Vec::new();
for (k,v) in hm {
sorted.push((v,k));
}
sorted.sort();
for (k,v) in sorted.iter().rev() {
println!("{} = {}",k,v);
}
println!("chars {}", sorted.iter().fold(0,|s,(num,_)|s+num));
Ok(())
}
za poredjenje izmenjeni python:
Code:
import sys
import re
import string
import operator
# Provera da su dati svi argumenti.
if len(sys.argv) != 2:
print("Unesi ime fajla za slovnu analizu. Npr. >> 154.py fajl.txt")
quit()
sva_slova = {}
# uklanjanje interpunkcije
try:
with open(sys.argv[1], 'r', encoding='utf-8') as f:
tekst = f.read()
tekst1 = tekst.lower()
samo_reci = re.sub('['+string.punctuation+', 0-9, r\n, ' ']', '', tekst1)
sorta = ''.join(sorted(samo_reci))
for slovo in sorta:
if slovo in sva_slova:
sva_slova[slovo] += 1
else:
sva_slova[slovo] = 1
except:
print("Dogodila se greška pri učitavanju fajla.")
quit()
# pravljenje liste sa tuplama, kako bi se dobio ispis
lista = [(k, v) for k, v in sva_slova.items()]
print()
print('Ovo je učestalost po broju ponavljanja:')
lista.sort(key = operator.itemgetter(1))
for item in lista:
print(str(item[1]) + str(' = ') + str(item[0]))
# izračunavanje ukupnog broja slova u tekst
zbir = 0
lista.reverse()
for char in lista:
zbir += char[1]
print('Ukupno u tekstu {} slova'.format(zbir))
/code]
A sad vreme izvrsavanja:
rust:
Code:
~/examples/rust >>> time ./letter_count bible.txt
437385 = e
323802 = t
292940 = h
291659 = a
253611 = o
236506 = n
214156 = s
209062 = i
179738 = r
160755 = d
140235 = l
91170 = u
90659 = m
83210 = f
66586 = w
61424 = c
59411 = y
58877 = g
52207 = b
46827 = p
32426 = v
26908 = k
13753 = j
4810 = z
2662 = x
953 = q
chars 3431732
./letter_count bible.txt 0.16s user 0.00s system 99% cpu 0.168 total
python:
Code:
/examples/rust >>> time python letter_count.py bible.txt
Ovo je učestalost po broju ponavljanja:
953 = q
2662 = x
4810 = z
13753 = j
26908 = k
31102 =
32426 = v
46827 = p
52207 = b
58877 = g
59411 = y
61424 = c
66586 = w
83210 = f
90659 = m
91170 = u
140235 = l
160755 = d
209062 = i
214156 = s
236506 = n
253611 = o
291659 = a
292940 = h
323802 = t
437385 = e
Ukupno u tekstu 3283096 slova
python letter_count.py bible.txt 1.02s user 0.08s system 99% cpu 1.097 total
Kao sto vidis rust je vise nego 5 puta brzi :)
[ Branimir Maksimovic @ 19.02.2020. 05:56 ] @
Zeznuo sam se u pythonu samo koju listu d uradim reverse :)
Drugo, python broji i space-ove ....
# for slovo in sorta: # if slovo in sva_slova: # sva_slova[slovo] += 1 # else: # sva_slova[slovo] = 1
sva_slova = Counter(sorta)
except: print("Dogodila se greška pri učitavanju fajla.")
quit()
# pravljenje liste sa tuplama, kako bi se dobio ispis #lista = [(k, v) for k, v in sva_slova.items()]
print() print('Ovo je učestalost po broju ponavljanja:') #lista.sort(key = operator.itemgetter(1))
lista =sorted(sva_slova.items(), key=operator.itemgetter(1), reverse=True) for item in lista: print(str(item[1]) + str(' = ') + str(item[0]))
# izračunavanje ukupnog broja slova u tekst #zbir = 0 #lista.reverse() #for char in lista: # zbir += char[1]
zbir =sum(i[1]for i in lista) print('Ukupno u tekstu {} slova'.format(zbir))
Python:
Code: time python3 letter_count.py pg10.txt
Ovo je učestalost po broju ponavljanja:
412265 = e
317765 = t
282690 = h
275735 = a
243208 = o
225065 = n
193974 = i
190038 = s
170339 = r
158103 = d
129947 = l
83550 = f
83476 = u
79945 = m
65496 = w
58578 = y
55307 = g
55070 = c
48880 = b
43260 = p
30368 = v
22295 = k
8890 = j
2972 = z
1479 = x
964 = q
Ukupno u tekstu 3239659 slova
real 0m 1.25s
user 0m 1.18s
sys 0m 0.07s
Rust:
Code: time ./letter_count pg10.txt
412265 = e
317765 = t
282690 = h
275735 = a
243208 = o
225065 = n
193974 = i
190038 = s
170339 = r
158103 = d
129947 = l
83550 = f
83476 = u
79945 = m
65496 = w
58578 = y
55307 = g
55070 = c
48880 = b
43260 = p
30368 = v
22295 = k
8890 = j
2972 = z
1479 = x
964 = q
chars 3239659
real 0m 2.82s
user 0m 2.81s
sys 0m 0.01s
Gledam nešto ovaj Rust Docker image mnogo veliki? rust alpine 753MB
[ Branimir Maksimovic @ 19.02.2020. 08:01 ] @
Kako si useo da ti Rust radi tako sporo? ;)
Code:
~/examples/rust >>> time ./letter_count bible.txt
437385 = e
323802 = t
292940 = h
291659 = a
253611 = o
236506 = n
214156 = s
209062 = i
179738 = r
160755 = d
140235 = l
91170 = u
90659 = m
83210 = f
66586 = w
61424 = c
59411 = y
58877 = g
52207 = b
46827 = p
32426 = v
26908 = k
13753 = j
4810 = z
2662 = x
953 = q
chars 3431732
./letter_count bible.txt 0.16s user 0.01s system 99% cpu 0.174 total
~/examples/rust >>> time python letter_count.py bible.txt
Ovo je učestalost po broju ponavljanja:
437385 = e
323802 = t
292940 = h
291659 = a
253611 = o
236506 = n
214156 = s
209062 = i
179738 = r
160755 = d
140235 = l
91170 = u
90659 = m
83210 = f
66586 = w
61424 = c
59411 = y
58877 = g
52207 = b
46827 = p
32426 = v
26908 = k
13753 = j
4810 = z
2662 = x
953 = q
Ukupno u tekstu 3431732 slova
python letter_count.py bible.txt 0.63s user 0.06s system 99% cpu 0.703 total
rust vise nego 4 puta brzi ;)
probaj da ukljucis optimizacije:
Code:
rustc -O -C target-cpu=native letter_count.rs
[ Panta_ @ 19.02.2020. 08:11 ] @
"probaj da ukljucis optimizacije:"
Tako radi dosta brže.
real 0m 0.20s
user 0m 0.20s
sys 0m 0.00s
[ Panta_ @ 19.02.2020. 10:48 ] @
Sad tek vidim da Python dvaput sortira, dovoljno je "sorta = ''.join(i for i in re.findall('[a-z]+', tekst.lower()))". Onda je "samo" 3 puta sporiji. :)
[ Branimir Maksimovic @ 19.02.2020. 11:08 ] @
I ako izbacis regex ubrzaces jos vise ;)
[ a1234567 @ 19.02.2020. 11:25 ] @
A kad izbaciš učitavanje fajla, biće ko munja :D
[ Panta_ @ 19.02.2020. 12:17 ] @
"I ako izbacis regex ubrzaces jos vise ;)"
Neće, čak je i sporije.
[ Branimir Maksimovic @ 19.02.2020. 13:34 ] @
Pa da, regex implementacija u C-u ;)
[ Panta_ @ 19.02.2020. 14:32 ] @
Fora je što regex + čita koliko god može karaktera u opsegu od a-z dok ne naiđe na neki ne a-z karakter i vrati match, tzv. greedy quantifier, dok bi recimo bez + za svaki a-z karakter vratio match.
Code: %timeit ''.join(i for i in tekst.lower() if i.isalpha())
1 loop, best of 5: 368 ms per loop
%timeit ''.join(filter(lambda i: i.isalpha(), tekst))
1 loop, best of 5: 508 ms per loop
%timeit ''.join(re.findall('[a-z]+', tekst.lower()))
1 loop, best of 5: 276 ms per loop
[ djoka_l @ 20.02.2020. 17:31 ] @
Citat:
Panta_:
Gledam nešto ovaj Rust Docker image mnogo veliki? rust alpine 753MB
Najveći je 450MB. A ide od 125MB pa na gore. Java HelloWorld ne može da se spakuje na manje od 1GB...
[ Branimir Maksimovic @ 21.02.2020. 01:29 ] @
Citat:
Panta_:
Fora je što regex + čita koliko god može karaktera u opsegu od a-z dok ne naiđe na neki ne a-z karakter i vrati match, tzv. greedy quantifier, dok bi recimo bez + za svaki a-z karakter vratio match.
Code: %timeit ''.join(i for i in tekst.lower() if i.isalpha())
1 loop, best of 5: 368 ms per loop
%timeit ''.join(filter(lambda i: i.isalpha(), tekst))
1 loop, best of 5: 508 ms per loop
%timeit ''.join(re.findall('[a-z]+', tekst.lower()))
1 loop, best of 5: 276 ms per loop
Ma ne, pazi ova petlja gde ide samo prolaz i provera, u kompajliranom jeziku, nema teorije da bi bila
sporija od regex-a. Zato kad radis u Pythonu, napravis heavy workload u C-u, a onda samo pozivas
f-je.
[ djoka_l @ 21.02.2020. 09:12 ] @
Citat:
Panta_:
Fora je što regex + čita koliko god može karaktera u opsegu od a-z dok ne naiđe na neki ne a-z karakter i vrati match, tzv. greedy quantifier, dok bi recimo bez + za svaki a-z karakter vratio match.
Code: %timeit ''.join(i for i in tekst.lower() if i.isalpha())
1 loop, best of 5: 368 ms per loop
%timeit ''.join(filter(lambda i: i.isalpha(), tekst))
1 loop, best of 5: 508 ms per loop
%timeit ''.join(re.findall('[a-z]+', tekst.lower()))
1 loop, best of 5: 276 ms per loop
isalpha i regex [a-z]+ nisu isto. regex neće da radi za UTF-8
[ Panta_ @ 21.02.2020. 10:02 ] @
"Ma ne, pazi ova petlja gde ide samo prolaz i provera, u kompajliranom jeziku, nema teorije da bi bila
sporija od regex-a."
Mislio sam na regex [a-z]+ vs [a-z]: "regex + čita koliko god može karaktera u opsegu od a-z dok ne naiđe na neki ne a-z karakter i vrati match, tzv. greedy quantifier, dok bi recimo bez + za svaki a-z karakter vratio match
"isalpha i regex [a-z]+ nisu isto. regex neće da radi za UTF-8"
Neće, ali nisam u primeru imao takva slova pa sam upotrebio taj jednostavan regex. Python re modul ne podržava POSIX character class ili unicode properties, pa ne može jednostavno [:alpha:] ili \p{L}, već recimo [^\W\d_].
To je compressed size, kada se raspakuje onda je znatno više.
[ a1234567 @ 28.02.2020. 06:30 ] @
Stiže zadatak broj 25.
Napiši program koji će prikazati 5 reči koje se najčešće pojavljuju u datom tekstu. Posle učitavanja teksta,
program će prvo ukloniti sve znakove interpuncije, a prilikom brojanja reči zanemariti mala i velika slova.
Svoje polurešenje sa okačio ovde.
Njime dobijem ovakvu listu iz rečnika:
that 3
which 1
is 6
hearing 1
of 7
our 6
hearing, 1
mind 1
speech 2
too 1
life 1
life-breath 1
and 3
sight 2
Ali nisam još otkrio kako da sortiram po opadajućem nizu ponavljanja reči.
I kako da ispis ograničim na prvih 5 reči.
Radim na fazi 2 :)
[ Branimir Maksimovic @ 28.02.2020. 06:54 ] @
Stavis u listu parova (broj_ponavljanja,rec) pa sortiras reverse ili sortiras pa obrnes ili ides iteraciju reverse.
Da li python ima `take` iz iteracije kao Haskell ili Rust? Ako nema onda ides petlju po brojacu.
[ djoka_l @ 28.02.2020. 07:06 ] @
Ovo je prilično neobičan engleski tekst, kada "the" nije najčešća reč.
Osim toga, pojavljuje se haering dva puta:
hearing 1
hearing, 1
Očigledno, ne radi ti baš dobro uklanjanje interpunkcije.
A i pitanje je šta da se radi sa "life-breath"? Da li je to jedna ili dve reči...
[ Panta_ @ 28.02.2020. 13:45 ] @
Citat:
Ali nisam još otkrio kako da sortiram po opadajućem nizu ponavljanja reči.
I kako da ispis ograničim na prvih 5 reči.
Radim na fazi 2 :)
Importovao si re i collections module ali ih nigde nisi upotrebio. Moga si da vidiš kako sam ih ja upotrebio u prethodnom zadatku. Na primer za ovaj zadatak:
Code: import re
import collections
text = open('textfile.txt').read()
words = re.findall('\w+', text)
most_common(self, n=None)
List the n most common elements and their counts from the most
common to the least. If n is None, then list all element counts.
I da, promenio sam uzorak teksta i sada je stvarno 'the' najčešća reč :)
[ Panta_ @ 28.02.2020. 14:36 ] @
Evo malo drugačijeg rešenja:
Code: import string
text = open('textfile.txt').read()
words = text.translate(str.maketrans('', '', string.punctuation)).split()
sorted([(word, words.count(word)) for word in set(words)], key=lambda x: x[1], reverse=True)[:5]
[('and', 24), ('more', 21), ('which', 18), ('for', 18), ('to', 16)]
[ a1234567 @ 28.02.2020. 14:49 ] @
Zanimalo me i za srpski tekst kako stoje stvari.
Proverio sam Crnjanskog, prva knjiga Seoba.
Generalno je ova situacija, ubedljivo vode uglavnom veznici i predlozi
što je za očekivati. Jedino je ime glavnog junaka ušlo u prvih 40:
i = 3517
je = 2485
da = 2122
se = 1983
u = 1846
na = 919
su = 738
kao = 690
sa = 650
mu = 590
što = 575
od = 467
ne = 442
za = 440
ga = 400
koji = 351
nije = 349
sve = 347
po = 346
tako = 326
a = 294
on = 290
beše = 283
ni = 273
to = 259
kad = 247
bio = 242
ih = 241
iz = 239
isakovič = 231
će = 230
ona = 225
pred = 221
bi = 216
pod = 213
joj = 211
više = 204
još = 190
pri = 184
koje = 181
[ a1234567 @ 28.02.2020. 15:05 ] @
Citat:
Panta_:
Evo malo drugačijeg rešenja:
Code: import string
text = open('textfile.txt').read()
words = text.translate(str.maketrans('', '', string.punctuation)).split()
sorted([(word, words.count(word)) for word in set(words)], key=lambda x: x[1], reverse=True)[:5]
[('and', 24), ('more', 21), ('which', 18), ('for', 18), ('to', 16)]
Au Panto, al si ga skvizovao!
A ja tri dana ulupao da nažem rešenje.
Mogao nive Seobe da napišem za to vreme :D
Zanimljivi ti je taj string modul. Moram to malo bolje proučiti.
Ako s nečim radim u ovoj fazi, onda su to stringovi.
>>> trantab = maketrans(intab, outtab)
Traceback (most recent call last):
File "<pyshell#68>", line 1, in <module>
trantab = maketrans(intab, outtab)
NameError: name 'maketrans' is not defined
[ a1234567 @ 28.02.2020. 17:23 ] @
Citat:
djoka_l:
Ovo sam ja izvukao iz jedne knjige (top 15):
Code: JE 2696
I 1857
DA 1789
SE 1587
U 1303
NA 870
SU 595
ON 560
ZA 513
TO 496
SA 477
A 457
ONA 414
NE 390
ALI 351
Da, to su sve reči od 2-3 slova.
Nije baš nešto informativno.
Ja sam eksperimentisao sa zadavanjem dužine reči koje lista.
Kad mu stavim da ispiše reči duže od 5 slova, dobijem kod Crnjanskog ovo kao najčešće:
isakovič = 231
svojim = 149
kojima = 93
aranđel = 84
sasvim = 79
nekoliko = 79
jednom = 65
toliko = 65
kolima = 52
činilo = 49
isakoviča = 48
njegove = 46
svojih = 45
naročito = 43
najposle = 43
međutim = 42
vojnika = 41
jednog = 40
berenklau = 40
njegova = 38
činjaše = 37
gospoža = 36
velikim = 35
potpuno = 34
vojnici = 34
rukama = 33
dafina = 33
osećao = 32
njegovog = 31
varoši = 31
iznenada = 31
Ovo sad uraditi analizu više pisaca, pa upoređivati, taman za magistarski :)
[ djoka_l @ 28.02.2020. 17:28 ] @
U toj knjizi, pojavljuje se oko 17500 reči, ali samo 4300 reči se pojavljuje 2 i više puta. Ostale samo po jednom...
Citat:
>>> import string
i onda probam, ali se buni interpreter
>>> trantab = maketrans(intab, outtab)
Traceback (most recent call last):
File "<pyshell#68>", line 1, in <module>
trantab = maketrans(intab, outtab)
NameError: name 'maketrans' is not defined
maketrans je metoda klase string.
Ne može tako da se poziva, nego
'nesto'.maketrans
ili
string.maketrans
ili
stringvarijabla.maketrans
[ a1234567 @ 28.02.2020. 17:33 ] @
A ja našao ovaj primer i probao da ga odradim kod mene na računaru
from string import maketrans # Required to call maketrans function.
str = "this is string example....wow!!!";
print str.translate(trantab)
When we run above program, it produces following result −
th3s 3s str3ng 2x1mpl2....w4w!!!
[ djoka_l @ 28.02.2020. 17:41 ] @
Citat:
Ovo sad uraditi analizu više pisaca, pa upoređivati, taman za magistarski :)
Ovo je pre za neki seminarski rad, nije čak ni za diplomski.
Klasična metoda analize prirodnog jezika (jedna od) je da se rečenica posmatra kao "bag of words". Dakle ne analiziraš gramatiku, stil itd, nego izdvojiš reči, pa onda odbaciš iz tog skupa reči 100 (500, 1000, koliko god najčešćih) jer one ne nose mnogo značenja, a ono što ti ostane su ključne reči.
"U gužvi koja je tada nastala, Mitrović je skočio najviše i plasirao loptu u mrežu!"
Kada izbaciš u, koja, je, tada, i
ostane ti gužvi, nastala, Mitrović, skočio, najviše, plasirao, loptu, gol.
Onda vrlo lako možeš da shvatiš kontekst...
Dakle, to su reči koje zaista nose informaciju, ostale samo čine da bude rečenica gramatički ispravna.
[ a1234567 @ 28.02.2020. 18:10 ] @
Ja sam mislio više na stilsku analizu vokabulara koji pisac koristi.
Iz ovo malo reči kod Crnjanskog, možeš povaditi
aranđel
najposle
berenklau
činjaše
gospoža
dakle arhaizme, strane reči ili glagolske oblike koji nisu deo savremenog govora
i raspredati o njegovom stilu.
Pa onda te zaključke uporediti sa istim takvim zaključcima kod nekih drugih pisaca
koji pripadaju možda različitim umetničkim pravcima ili epohama itd.
Mogućnosti su velike.
[ Panta_ @ 28.02.2020. 19:38 ] @
Citat:
A ja našao ovaj primer i probao da ga odradim kod mene na računaru
from string import maketrans # Required to call maketrans function.
str = "this is string example....wow!!!";
print str.translate(trantab)
When we run above program, it produces following result −
th3s 3s str3ng 2x1mpl2....w4w!!!
Koju verziju Pythona koristiš? U Pythonu 3 string modul nema maketrans i translate funkcije, zamenjene su sa str.maketrans i str.translate metodama str klase, help(str). Tako da maketrans(intab, outtab) zameni sa str.maketrans(intab, outtab). Takođe, print str.translate(trantab) sa print(str.translate(trantab)).
Inace maketrans ima i treći argument koji je string, koji sam ja u primeru iskoristio da uklonim znakove interpuncije.
maketrans(x, y=None, z=None, /)
| Return a translation table usable for str.translate().
|
| If there is only one argument, it must be a dictionary mapping Unicode
| ordinals (integers) or characters to Unicode ordinals, strings or None.
| Character keys will be then converted to ordinals.
| If there are two arguments, they must be strings of equal length, and
| in the resulting dictionary, each character in x will be mapped to the
| character at the same position in y. If there is a third argument, it
| must be a string, whose characters will be mapped to None in the result.
[ a1234567 @ 29.02.2020. 02:14 ] @
A to je kvaka, koristim Python 3.8.
Što ti ne pređeš na noviju verziju?
Da, to sam video sa tri argumenta, da si koristio. Vrlo korisno, jer uklanja iz stringa sve što je u tom trećem arg.
Pa još kad se kombinuje sa .punctuation.
Sa string.maketrans praviš translacionu tabelu
a sa str.translate ga odradi.
A čemu služi maketrans sa jednim argumentom.
Vidim da u rečniku pretvara slovo u unikod broj.
Kad mi to treba?
[ Panta_ @ 29.02.2020. 05:17 ] @
Kao što piše u gore citiranom, ako je samo jedan argument, on mora da bude dictionary. Na primer, prvi i drugi argument moraju da budu iste dužine, tj. da imaju isti broj karaktera, recimo da hoćeš slovo h da zameniš sa XYZ:
Code: 'hello, world!'.translate(str.maketrans('h', 'XYZ'))
ValueError: the first two maketrans arguments must have equal length
Ili na primer, kao u zadatku da ukloniš znakove interpuncije, umesto da koristiš kao treći argument string.punctuation, možeš da ih definišeš u rečniku, npr.:
Ma video sam da kod jednog argumenta mora d abude rečnik, ali mi to nije mnogo pomoglo.
Ali sad vidim da je to u stvari skoro pa isto.
Ili imaš dva argumenta, pa drugi menja prvi, ili imaš jedan, tj. rečnik, koji se takođe sastoji od para - key: value
pa mu opet dođe kao da imaš dva argumenta :)
Jedina je razlika u dužini. I ovo mi se sviđa što value menja key bez obzira na dužinu jednog i drugog.
Hvala na jasnim objašnjenjima, sad mi je jasno šta i kako radi.
[ Panta_ @ 29.02.2020. 06:23 ] @
"Jedina je razlika u dužini. I ovo mi se sviđa što value menja key bez obzira na dužinu jednog i drugog."
Dužina ključa mora da bude 1, npr. recimo da hoćeš he da zameniš sa XYZ:
Code: 'hello, world!'.translate(str.maketrans({'he': 'XYZ',}))
ValueError: string keys in translate table must be of length 1
I da ne bi mnogo dangubili, evo i naredni zadatak broj 26.
Napravi program koji računa zbir brojeva koje unese korisnik,
a ignoriše unos koji nije ceo ili decimalni broj. Program treba da
ispiše tekući zbir posle svakog unetog broja. Takođe, ispisuje
poruku posle svakog ne-brojčanog unosa i potom nastavlja
da sabira ako je naredni unos ispravan. Izlazak iz programa je
sa praznim unosom, tj. enterom.
Testirajući program sa unosom decimalnih brojeva imam često ovakvu situaciju:
Unesi neki broj. Enter za izlaz: 2
Zbir je: 2.0
Unesi neki broj. Enter za izlaz: 6
Zbir je: 8.0
Unesi neki broj. Enter za izlaz: 5
Zbir je: 13.0
Unesi neki broj. Enter za izlaz: 3
Zbir je: 16.0
Unesi neki broj. Enter za izlaz: 2.6
Zbir je: 18.6
Unesi neki broj. Enter za izlaz: 5.1
Zbir je: 23.700000000000003
Pa jel to python ima problem sa sabiranjem decimalnih brojeva!?
Gvido alert! Možeš ti to i bolje.
[ Branimir Maksimovic @ 29.02.2020. 06:34 ] @
Nepreciznost floating point aritmetike.... nije to do Pythona.
[ a1234567 @ 29.02.2020. 06:35 ] @
Citat:
Panta_:
"Jedina je razlika u dužini. I ovo mi se sviđa što value menja key bez obzira na dužinu jednog i drugog."
Dužina ključa mora da bude 1, npr. recimo da hoćeš he da zameniš sa XYZ:
Code: 'hello, world!'.translate(str.maketrans({'he': 'XYZ',}))
ValueError: string keys in translate table must be of length 1
Dobro, sad sam i to regulisao.
Ono sa milion decimala izgleda stvarno ružno.
stavio sam
round(zbir,2)
Jedino u tvojim primerima index 2, a zaokruži na 1 decimalu!?
[ Branimir Maksimovic @ 29.02.2020. 07:40 ] @
Probaj sa 2 decimale gde zadnja nije 0. od 23.70 valjda odbaci 0.
[ Panta_ @ 29.02.2020. 08:21 ] @
Code: round(23.70000, 2)
23.7
f'{23.70000:.2f}'
'23.70'
[ a1234567 @ 03.03.2020. 07:31 ] @
Evo nama zadatak broj 27:
Piton koristi # znak da obeleži početak komentara. Komentar se nastavlja od tog znaka do kraja reda.
Napravi program koji uklanja sve komentare iz python izvornog koda. Sačuvaj modifikovani fajl pod novim imenom.
Imena ulaznog i izlaznog fajla treba da unese korisnik u komandnoj liniji. Obezbedi da program prijavi grešku
ukoliko ima problem da pristupi jednom od fajlova.
Stigao sam dovde i sve lepo radi:
Code: with open('fajl1.txt', 'r') as f:
redovi = f.readlines()
with open('fajl2.txt', 'w') as g:
for red in redovi:
red = red.split('#')
obrishi = red[0].rstrip()
g.writelines(obrishi)
g.writelines('\n')
Ali kad sam pokušao da to apgrejdujem do pune verzije kakva se traži u zadatku,
nešto ne radi. A ne vidim razlog.
Code: import sys
# Provera da su dati svi argumenti.
if len(sys.argv) != 3:
print("Unesi ime fajla čije komentare brišeš i ime za novi fajl. Npr. >> 27.py komentari.py bez.txt")
quit()
try:
with open(sys.argv[1], 'r') as f:
redovi = f.readlines()
with open(sys.argv[2], 'w') as g:
for red in redovi:
red = red.split('#')
obrishi = red[0].rstrip()
g.writelines(obrishi)
g.writelines('\n')
except:
print("Greška pri učitavanju fajla.")
quit()
[ djoka_l @ 03.03.2020. 08:24 ] @
quit() mora da bude indentovano isto kao print, inače svaki put izlalziš iz programa posle if-a
[ B3R1 @ 03.03.2020. 09:10 ] @
Ovo uopste nije lak zadatak. Tvoje resenje recimo da radi, ali ne bas za sve slucajeve. Pogledaj sta tvoj program radi za ovakve linije koda:
Code: print "# je nekom taraba, a nekom povisilica (F#==Fis)" # A ovo je komentar
linija = re.sub('#.*$', '', linija) # Jos jedan nacin da se ovo uradi, ali opet ne radi bas ono sto hocemo
print 'Za stanje na racunu otkucajte "*101#" ...' # Ako imamo '#' u liniji (# je separator komentara u Pythonu, ali ne u C#, tamo se koristi //)
print "*106*" + telefon + "#123#" + '#' # Ako imamo '#' u liniji (# je separator komentara u Pythonu, ali ne u C#, tamo se koristi //)
Evo, smislio sam ti bas primere da se pomucis ...
[ djoka_l @ 03.03.2020. 10:07 ] @
Beri, malo ti je sintaksa zastarela, ovo ne prolazi u Pythonu 3
Mislim da bi bio "overkill" da ga nateramo da koriti paket tokenize ili da sam pravi leksički analizator.
[ a1234567 @ 03.03.2020. 10:24 ] @
Citat:
djoka_l:
quit() mora da bude indentovano isto kao print, inače svaki put izlalziš iz programa posle if-a
Bravo Đoko
Pa da, ovako nije ni išao kroz petlju,
a ja se čudim što ne radi :)
[ a1234567 @ 03.03.2020. 10:31 ] @
Citat:
B3R1:
Ovo uopste nije lak zadatak. Tvoje resenje recimo da radi, ali ne bas za sve slucajeve. Pogledaj sta tvoj program radi za ovakve linije koda:
Code: print "# je nekom taraba, a nekom povisilica (F#==Fis)" # A ovo je komentar
linija = re.sub('#.*$', '', linija) # Jos jedan nacin da se ovo uradi, ali opet ne radi bas ono sto hocemo
print 'Za stanje na racunu otkucajte "*101#" ...' # Ako imamo '#' u liniji (# je separator komentara u Pythonu, ali ne u C#, tamo se koristi //)
print "*106*" + telefon + "#123#" + '#' # Ako imamo '#' u liniji (# je separator komentara u Pythonu, ali ne u C#, tamo se koristi //)
Evo, smislio sam ti bas primere da se pomucis ...
pa ništa, dodao tri spejsa pre # i oljušti ga od komentara ko kuvarica mlad krompir :D
Code: import sys
# Provera da su dati svi argumenti.
if len(sys.argv) != 3:
print("Unesi ime fajla čije komentare brišeš i ime za novi fajl. Npr. >> 27.py komentari.py bez.txt")
quit()
try:
with open(sys.argv[1], 'r') as f:
redovi = f.readlines()
with open(sys.argv[2], 'w') as g:
for red in redovi:
red = red.split(' #')
obrishi = red[0].rstrip()
g.writelines(obrishi)
g.writelines('\n')
except:
print("Greška pri učitavanju fajla.")
quit()
[ Panta_ @ 03.03.2020. 11:43 ] @
Sada ti ne radi ako linija počinje sa # ili ako ima dva ili manje razmaka ispred. ;)
[ B3R1 @ 03.03.2020. 11:56 ] @
Citat:
a1234567:
pa ništa, dodao tri spejsa pre # i oljušti ga od komentara ko kuvarica mlad krompir :D
Code: >>> print "String se zavrsava sa #"#A odavde pocinje komentar, koji moze imati i "#hashtag" ili "nesto drugo@"
String se zavrsava sa #
Naravoucenije: razmaci su nebitni.
[ a1234567 @ 03.03.2020. 11:56 ] @
Panto, zadatak je odrađen.
A ti sad zakeraj koliko hoćeš
[ B3R1 @ 03.03.2020. 12:38 ] @
Citat:
a1234567: Panto, zadatak je odrađen.
A ti sad zakeraj koliko hoćeš :D
Pa i nije bas ... vidi gornji primer koji ne radi. Da bi ga resio moraces da analiziras karakter po karakter i da pamtis stanje. Kriticni karakteri koje treba da pamtis su ti apostrof, navodnici ili taraba.
* Ako navodnik naidje prvi (pre tarabe) - tada smatras da si u string-modu, pa tarabe i apostrofe smatras delom stringa sve dok ne naidje zavrsni navodnik (kada zatvaras string)
* Ako apostrof naidje prvi (pre tarabe) - tada smatras da si u string-modu, pa tarabe i navodnike smatras delom stringa sve dok ne naidje zavrsni apostrof (kada zatvaras string).
* Ako naidje taraba, a nisi u string-modu - to je prelomni znak od koga treba da "ljustis" sve zdesna.
Eto, sada napisi kod ... Eh da, ima i dva posebna slucaja - znaci \' i \" koji se, ako se nadju unutar stringa, smatraju delom stringa:
Code: print "Ovaj # je deo stringa, kao i \"ovaj #\", a mozda i # isto tako"# Ali ovaj nije
Ali hajde, preskoci taj slucaj za pocetak, to mozes da odradis i kasnije ... mada nije tesko.
[ djoka_l @ 03.03.2020. 12:40 ] @
U pythonu, za razliku od nekih drugih jezika, znak "#" ne može da bude deo identifikatora (imena varijable ili rezervisana reč).
Dakle, "#" može da se pojavi ISKLJUČIVO u dva konteksta - ili kao početak komentara, ili kao deo stringa.
Utoliko je onda lakše da se uradi analiza teksta i izbace komentari.
String literal može da počne i da se završi jednostrukim znakom navoda, dvostrukim znakom navoda, ili da se (multilinijski string literal) započne i završi sa tri jednostruka znaka navoda ili 3 dvostruka znaka naloga.
Onda parser treba da zna da pronađe početak i kraj string literala (treba paziti na to da se unutar string može nalaziti \' ili \" kako bi se uneo znak navoda u string), a sve što nije "quoted" tekst da se čita do prve pojave "#" i da se onda od tog znaka do kraja reda ignoriše ostatak linije.
[Ovu poruku je menjao djoka_l dana 03.03.2020. u 14:45 GMT+1]
[ a1234567 @ 04.03.2020. 08:42 ] @
Evo verzije 2.0 rešenja zadatka 27,
koja sada uklanja komentare i u redovima koji imaju više #.
Idem slovo po slovo od kraja reda i tražim #, tu podelim red i odsečem desni deo.
Nije jako komplikovano.
Code: with open('fajl1.txt', 'r') as f:
redovi = f.readlines()
with open('fajl2.txt', 'w') as g:
for red in redovi:
if len(red.strip()) == 0: # sačuvaj prazne linije
g.writelines(red)
elif red[0] == '#': # ukloni ceo red ako počinje sa #
g.writelines('\n')
elif '#' not in red: # prekopiraj red ako nema #
g.writelines(red)
else: # briši deo red desno od poslednjeg #
for i in range(len(red) -1, -1, -1):
if red[i] == '#':
red1 = red.split(red[i])
obrishi = red1[0].rstrip()
g.writelines(obrishi)
g.writelines('\n')
Ostale egzibicije ostavljam iskusnim programerima
[ Branimir Maksimovic @ 04.03.2020. 08:47 ] @
a kamo ako je # u okviru string literala?
[ a1234567 @ 04.03.2020. 08:58 ] @
Nema veze, komentar je na kraju reda, tako da prvi desni # označava komentar
svi ostali, pa i ti u stringu, su levo od njega.
[ B3R1 @ 04.03.2020. 10:31 ] @
Citat:
a1234567: Nema veze, komentar je na kraju reda, tako da prvi desni # označava komentar
svi ostali, pa i ti u stringu, su levo od njega.
Pa i nije bas:
Code:
print "Primer koda" # Komentar pocinje ovde, # a ne ovde
Evo resenja koje obuhvata sve slucajeve, s objasnjenjem sta se tu tacno radi ... napominjem da je ovo bas osnovacko resenje, ali korisno da uvidis neke stvari koje se koriste u slicnim problemima (eksperti bi to odradili drugacije, ali o tom potom):
Code:
#!/usr/bin/python
import sys
for line in open(sys.argv[1], 'r').readlines():
line = line.rstrip()
q_single = False # Apostrof (')
q_double = False # Navodnik (")
escape = False # Backslash (\)
prev_char = '' # Pamti prethodni znak u redu
for pos,ch in enumerate(line):
if (q_single or q_double) and escape:
escape = not escape
continue
elif (q_single or q_double) and (ch == "\\"):
escape = not escape
continue
elif (ch == '"' and prev_char != "\\" and not q_single and not escape):
q_double = not q_double
elif (ch == "'" and prev_char != "\\" and not q_double and not escape):
q_single = not q_single
elif (ch == '#' and not q_single and not q_double):
line = line[:pos]
break
prev_char = ch
print line
Kao sto sam vec pomenuo, u ovom problemu moras da ispitas da li se taraba nalazi unutar string literala ("Ova # je unutar literala") ili ne ("Ovo je literal" # A ovo komentar). I kao sto sam ti vec predlozio gore, moras da skeniras znak po znak u svakoj liniji i da donosis odluku da li ti je trenutna pozicija "skenera" unutar ili van literala. U gornjem primeru smo definisali tri logicke promenljive, cije vrednosti menjamo u toku programa koristeci logiku:
Code:
var = False
...
var = not var
Ova klik-klak tehnika u programiranju, poput prekidaca, se inace naziva 'toggle'. Kad god prodjes kroz liniju 'var = not var', promenljiva var naizmenicno menja vrednost od True ka False i obrnuto. U ovom kontekstu toggle smo koristili kao indikator STANJA, odnosno moda. Kada naidjemo na navodnik ("), prolazimo kroz toggle (q_double = not q_double), cime menjamo stanje literala - ako smo bili van literala sada smo unutar i obrnuto. Znaci - kada naidjes na prvi navodnik, program smatra da je string literal zapocet, a kada ponovo naidjes na isti tip navodnika literal je zavrsen. Slicno vazi i za apostrof, za literale koji su oiviceni apostrofima koristimo toggle q_single. Ali recimo, navodnik (") unutar literala oivicenog apostrofima (npr. 'Ovaj znak " je unutra') ili obrnuto ("Ovaj znak ' je unutra") ne sme da se broji ni kao pocetak, ni kao kraj literala, vec kao njegov deo. Osnovni program bi znaci bio:
Code:
...
if (ch == '"' and not q_single): # Naisao je ", ali ne unutar literala oivicenog sa '
q_double = not q_double
elif (ch == "'" and not q_double): # Naisao je ', ali ne unutar literala oivicenog sa "
q_single = not q_single
...
Ostaje da resimo slucaj \" i \'. To su escape znaci, koriste se kada unutar literala koristis isti znak kojim se definisu granice literala - npr. "Rec \"google\" oznacava inace ...". Tu u igru vec ulazi pamcenje prethodnog znaka, za sta se koristi prev_char. Na kraju, najtezi slucaj je kada se pojavi \\ unutar literala, sto se u Pythonu koristi za sam backslash. Tu uvodimo i ovaj toggle escape kojim se taj slucaj resava.
Gornji primer je prost, ali resava konkretan deo sintakse Pythona (parsiranje komentara). Profesionalci koji pisu kompajlere ne rade to tako pesice. Parsiranje sintakse teskta je nauka za sebe, ali i nije neka visa matematika i fizika ... :-). Kao sto se vidi cak i u gornjem primeru, kljucni pojam je STANJE (namerno napisano velikim slovima) - biti unutar i van literala je primer stanja. Biti unutar for() ili while() petlje ili if() strukture je takodje primer stanja. Znaci, treba nam algoritam koji pamti stanje sistema i u zavisnosti koji karakter/slovo/rec/sta god ... dodje dok si u stanju X, sistem prelazi u stanje Y ili Z. Ta problematika je stara vec solidnih 60 godina, time su se bavili i Turing, kao i Moore i Mealy i naziva se teorija konacnih automata. (Finite State Machines - FSM). Na ovom blog postu lik je zaista lepo objasnio kako se FSM moze implementirati u Pythonu.
Medjutim, FSM je samo temelj price. Svakako da profesionalci ne prave FSM bas uvek od nule. Postoje gotovi alati za parsiranje sintakse - lex, yacc, bison, flex ... o njima mozes da procitas ovde ako te zanima, ali to ti je vec masterclass nivo.
Ali ima i nesto sto mozes da savladas cak i na ovom nivou. Programeri ne prave kompajlere svaki dan ... osim ako se ne zovu Guido van Rossum :-). Obicnim smrtnicima - IT-sljakerima je mnogo potrebnije da parsiraju dokumente formatirane u nekom markup jeziku - HTML, SGML, XML ... Recimo, s nekog servera ti stize HTML tabela, sa sve onim <TD></TD> tagovima, a zelis da izdvojis podatke iz te tabele. Ili neki XML fajl, tipa: <TEMPERATURA>27</TEMPERATURA><PRITISAK>1000</PRITISAK> ... naravno, i to moze da se radi alatima opisanim gore, ali ljudi vise vole gotovanska prosta resenja. Srecom, ima tako nesto, zove se BeautlfulSoup, koji ti omogucava da neki HTML ili XML dokument parsiras lako ... bs4 moze da koristi i apsolutni pocetnik. Eto ti ideje za neki naredni zadatak ...
[Ovu poruku je menjao B3R1 dana 04.03.2020. u 11:48 GMT+1]
[ Panta_ @ 04.03.2020. 19:41 ] @
Evo sličnog rešenja, osim što prolazi znak po znak samo linije koje sadrže # znak:
Code (python):
lines =open('python_file.py').readlines()
for line in lines:
line = line.rstrip() if'#'in line:
in_str=False
pos=0 for char in line: if char =='"'or char =="'": ifnot in_str:
in_str=True
quote=char else: if char == quote and prev_char !='\\':
in_str=False elif char =='#'andnot in_str:
line = line[:pos] break
prev_char = char
pos+=1 print(line)
[ a1234567 @ 05.03.2020. 08:20 ] @
Baš ste se obojica potrudili da mi objasnite. Hvala vam.
Potrudio sam se i ja da razumem, ali slabo ja to kapiram. :(
Biće da još nisam na tom nivou.
[ a1234567 @ 05.03.2020. 10:00 ] @
Sigurno bi pomoglo ako bi se stvar pojednostavila, da bude samo jedan slučaj.
Recimo, da u stringu uklonim deo iza # ako nije unutar duplih navoda, a ako jeste da ostane.
Recimo ovakav slučaj:
line = 'They are designed "to whet your #appetite", not fill you up.'
Ali ja za sada umem da ga uklonim u svakom slučaju:
Code: for pos, ch in enumerate(line):
if ch == '#':
line = line[:pos]
print(line)
i dobijem 'They are designed "to whet your'
Teorijski mi je jasno, naravno, da "skener" idući slovo po slovo kad naiđe na prvi navodnik uključi stanje False
i ako u tom stanju naiđe na # ne briše ga.
Kad naiđe na drugi navodnik, prebaci na stanje True i posle toga ako naiđe na # briše nastavak reda.
Ali nažalost ni pored primera ne kapiram baš kako to prevesti u kod.
[ Panta_ @ 05.03.2020. 14:44 ] @
"Sigurno bi pomoglo ako bi se stvar pojednostavila, da bude samo jedan slučaj."
Evo malo pojednostavljen slučaj sa samo jednom vrstom navodnika i bez escape (\) znaka:
Code (python):
linija =""" 'Ovo je # znak unutar stringa' # Ove je # znak izvan stringa """.strip()
da_li_sam_u_stringu ='Nisam'
for pozicija, znak inenumerate(linija): if znak =="'": print(f'{pozicija}. {znak} Našao sam znak {znak}. Proveravam da li sam unutar stringa...') if da_li_sam_u_stringu =='Nisam':
da_li_sam_u_stringu ='Jesam' print(f'Da li sam u stringu? {da_li_sam_u_stringu}') else:
da_li_sam_u_stringu ='Nisam' print(f'Da li sam u stringu? {da_li_sam_u_stringu}') elif znak =='#': print(f'{pozicija}. {znak} Našao sam znak {znak}. Proveravam da li sam u stringu...') if da_li_sam_u_stringu =='Nisam': print(f'Nisam u stringu. Ispisujem liniju do pozicije {znak} znaka i prekidam izvršavanje:\n') print(linija[:pozicija]) break else: print(f'Još uvek sam u stringu. Nsatavljam.') else: print(f'{pozicija}. {znak}')
Izlaz:
0. ' Našao sam znak '. Proveravam da li sam unutar stringa... Da li sam u stringu? Jesam 1. O 2. v 3. o 4. 5. j 6. e 7. 8. # Našao sam znak #. Proveravam da li sam u stringu...
Još uvek sam u stringu. Nsatavljam. 9. 10. z 11. n 12. a 13. k 14. 15. u 16. n 17. u 18. t 19. a 20. r 21. 22. s 23. t 24. r 25. i 26. n 27. g 28. a 29. ' Našao sam znak '. Proveravam da li sam unutar stringa... Da li sam u stringu? Nisam 30. 31. # Našao sam znak #. Proveravam da li sam u stringu...
Nisam u stringu. Ispisujem liniju do pozicije # znaka i prekidam izvršavanje:
'Ovo je # znak unutar stringa'
[ B3R1 @ 05.03.2020. 15:07 ] @
Python dopusta koriscenje apostrofa (') i navodnika (") kao oznake granice niza znakova (string), s tim da se za pocetak i kraj stringa moraju da koriste isti znaci. Znaci:
Code:
'ili ovo'
"ili ovo"
'NE MOZE OVAKO" # OVO JE NEPRAVILNO!
"NITI OVAKO' # I OVO JE GRESKA!
"Ispred slova 'I' pocinje, a iza tacke se zavrsava."
'Ispred slova "I" pocinje, a iza tacke se zavrsava.'
U kodu iz primera koji si naveo, ispred prve reci (They) nalazi se APOSTROF ('), dok se ispred "to" nalazi NAVODNIK ("). To su dva razlicita karaktera ...
Python dopusta i jednu i drugu varijantu ravnopravno, ali moras da budes dosledan - kako pocinjes string, tako ga i zavrsavas, ne mozes da mesas babe i zabe.
Inace, u nekim drugim programskim jezicima postoji znacajna, ali bitna razlika izmedju stringova oivicenih navodnicima ("blabla") ili apostrofima ('blabla'). Recimo, PHP i Perl kada napises:
Code:
$ dan = "Ponedeljak";
print "Danas je $dan\n"; # U PHP: echo umesto print
print 'Danas je $dan\n'; # U PHP: echo umesto print
Dobijes kao rezultat:
Code:
Danas je ponedeljak
Danas je $dan\n
U prvom slucaju (navodnici) Perl i PHP zamenjuju $dan vrednoscu promenljive $dan unutar stringa oivicenog navodnicima ("). Ako se string oivici apostrofima (') string se prikazuje as-is, odnosno nema zamene promenljivih, niti tumacenja escape sekvenci (\n, \r itd.).
[ a1234567 @ 06.03.2020. 10:18 ] @
Citat:
Panta_:
"Sigurno bi pomoglo ako bi se stvar pojednostavila, da bude samo jedan slučaj."
Evo malo pojednostavljen slučaj sa samo jednom vrstom navodnika i bez escape (\) znaka:
Panto, svaka čast za pedagoški pristup :)
Treba da objaviš negde tutorial za ovo.
Da, sad mi je slika mnogo bistrija, jer je i primer jednostavniji.
Dakle ovo sad sasvim lepo radi
Code: linija = """ 'Ovo je # znak unutar stringa' # Ove je # znak izvan stringa """.strip()
stanje = False
for index, char in enumerate(linija):
if char == "'":
if stanje == False:
stanje = True
else:
stanje = False
elif char == "#":
if stanje == False:
print(linija[:index])
break
[ a1234567 @ 06.03.2020. 10:30 ] @
Citat:
B3R1:
Python dopusta koriscenje apostrofa (') i navodnika (") kao oznake granice niza znakova (string), s tim da se za pocetak i kraj stringa moraju da koriste isti znaci. Znaci:
Code:
'ili ovo'
"ili ovo"
'NE MOZE OVAKO" # OVO JE NEPRAVILNO!
"NITI OVAKO' # I OVO JE GRESKA!
"Ispred slova 'I' pocinje, a iza tacke se zavrsava."
'Ispred slova "I" pocinje, a iza tacke se zavrsava.'
U kodu iz primera koji si naveo, ispred prve reci (They) nalazi se APOSTROF ('), dok se ispred "to" nalazi NAVODNIK ("). To su dva razlicita karaktera ...
Berislave, znam za pravilo da nema mešanja navodnika. Što je sasvim razumljivo. To su različiti karakteri.
Kod mene su dupli navodnici unutar stringa koji počinje i završava jednostrukim navodnicima.
Tako da mislim da nije greška.
Evo napravio sam ovu kombinaciju:
Code: linija = 'They are designed "to whet your appetite" # not fill you up.'
lin = linija.strip()
stanje = False
for index, char in enumerate(lin):
if char == '"':
if stanje == False:
stanje = True
else:
stanje = False
elif char == "#":
if stanje == False:
print(lin[:index])
break
i rezultat je
They are designed "to whet your appetite"
[ a1234567 @ 07.03.2020. 11:45 ] @
Zadatak broj 28
Napiši program koji čita fajl sa listom reči, zatim nasumično bira dve ili tri od njih i spaja, kako bi napravio
novu lozinku. Kada pravi lozinku, njena dužina ne treba da bude manja od 10 slova, a da reči koje se koriste nisu
kraće od tri slova. Neka početna slova tih reči budu velika, tako da korisnik lako vidi gde se završava jedna i gde
počinje sledeća reč. Na kraju, program ispisuje novu lozinku za korisnika.
"Kada pravi lozinku, njena dužina ne treba da bude manja od 10 slova, a da reči koje se koriste nisu kraće od tri slova"
Tvoje rešenje koristi i reči kraće od tri slova. Treba u random.choice() da filtriraš reči duže od dva slova.
[ a1234567 @ 08.03.2020. 11:03 ] @
Ja sam to elegantno rešio tako što sam u početni fajl words.txt stavio samo reči koje imaju 3 i više slova
Ali dobro, sad sam ubacio još jednu petlju da selektujem takve reči, ako u fajlu ima kraćih
Code: import random
lozinka = ''
redovi3 = ''
with open('words.txt', 'r') as fajl:
redovi2 = fajl.readlines()
for i in redovi2:
if len(i) >= 4:
redovi3 += i.capitalize()
while len(lozinka) <= 12:
lozinka += random.choice(redovi3.split()).rstrip()
print('Tvoja nova lozinka je:\n\n', lozinka)
[ B3R1 @ 08.03.2020. 15:02 ] @
"Kada pravi lozinku, njena dužina ne treba da bude manja od 10 slova, a da reči koje se koriste nisu kraće od tri slova"
Mislim da nisi dobro procitao zadatak. U matematici, "A nije manje od B" znaci "A >= B", a "A nije vece od B" znaci "A <= B". Ako duzina lozinke nije manja od 10 slova, znaci da mora da bude veca ili jednaka od 10. U tvom programu vidim 12 (?!). Slicno tome, zadatak kaze da reci nisu krace od 3 slova, a ti poredis duzinu reci sa 4. Po meni bi trebalo:
Code:
import random
lozinka = ''
redovi3 = ''
with open('words.txt', 'r') as fajl:
redovi2 = fajl.readlines()
for i in redovi2:
if len(i) >= 3:
redovi3 += i.capitalize()
while len(lozinka) < 10:
lozinka += random.choice(redovi3.split()).rstrip()
print('Tvoja nova lozinka je:\n\n', lozinka)
Takodje, zasto filtriranje duzine ne radis odmah prilikom citanja iz fajla? Ne vidim razlog zasto bi prolazio kroz petlju dva puta. A ako to vec radis, zasto ti je redovi3 string, a ne lista? Elemente liste redovi2 ti nadovezujes u string redovi3, da bi kasnije koristio redovi3.split() (sto je opet treci prolazak kroz petlju, istina ovaj put "ispod haube" Pythona). Pokusaj da to malo optimizujes, nije tesko.
[ a1234567 @ 08.03.2020. 17:32 ] @
Ovo je originalni zadatak iz knjige Ben Stephenson: The Python Workbook (2019)
Exercise 159: Two Word Random Password
While generating a password by selecting random characters usually creates one that
is relatively secure, it also generally gives a password that is difficult to memorize.
As an alternative, some systems construct a password by taking two English words
and concatenating them. While this password may not be as secure, it is normally
much easier to memorize.
Write a program that reads a file containing a list of words, randomly selects two
of them, and concatenates them to produce a new password. When producing the
password ensure that the total length is between 8 and 10 characters, and that each
word used is at least three letters long. Capitalize each word in the password so that
the user can easily see where one word ends and the next one begins. Finally, your
program should display the password for the user.
Ja sam stavio u kodu dužinu lozinke na 12 slova, što je sigurno sigurno :))
Što se tiče dužine pojedinačnih reči, prvo sam stavio len >= 3
ali mi je program u lozinku ubacivao i reči od dva slova!?
I tu mi ništa nije bilo jasno, jel neki bag u pythonu ili šta je!? :)))
Prošlo je tu vremena dok mi u jednom trenutku nije sinulo da originalni fajl sa rečima izgleda ovako
Both
no
Check
Ensure
is
Python
Save
accessing
all
and
appropriate
character
...
i da program broji kao karakter i kraj reda \n.
Onda sam povećao na 4.
A ovo za optimizaciju, moram razmotriti, pa javljam rezultat :)
Stavio sam redovi3 prvo da bude lista, da ne moram posle da splitujem,
ali sad se više ne sećam gde je zapinjalo, pa sam prebacio na string.
[ B3R1 @ 08.03.2020. 18:25 ] @
Citat:
Što se tiče dužine pojedinačnih reči, prvo sam stavio len >= 3 ali mi je program u lozinku ubacivao i reči od dva slova!?
I tu mi ništa nije bilo jasno, jel neki bag u pythonu ili šta je!? :)))
Nije bag. Kompjuteri ne rade ono sto ti zelis, vec ono sto im zadas. A ti si rekao:
Code:
with open('words.txt', 'r') as fajl:
redovi2 = fajl.readlines()
for i in redovi2:
if len(i) >= 3:
Tekstualni fajlovi na kraju svake linije imaju tebi nevidljiv (ali kompjuteru itekako vidljiv) separator linije - tzv. newline. To je ono sto ti nesvesno u programima pises kao '\n' (to je inace karakter s ASCII kodom 10). Funkcija readlines() cita liniju po liniju i smesta je u listu, ali ako u python shellu otkucas prve 2 linije svog programa i onda kazes samo "redovi2", videces: [ 'Both\n', 'no\n', 'secure\n' ... ]. Bas zato ti je svaka rec realno 1 karakter duza. Tu imas dva resenja - ili da koristis 4 umesto 3 (sto si ti i uradio) ili da stripujes '\n' tokom ucitavanja fajla. Ako radis to drugo, onda mozes lepo da istovremeno upucs dve muve istim udarcem:
Code:
redovi = []
lozinka = ''
for red in open('words.txt', 'r'):
red = red.strip()
if (line(red)>=3):
redovi.append(red)
while (len(lozinka)<10):
lozinka += random.choice(redovi)
print('Tvoja nova lozinka je:\n\n', lozinka)
Inace, mala zanimljivost. Newline separator varira od jednog do drugog operativnog sistema, ali danas su u upotrebi dve varijante. Unix i njegovi derivati (medju njima i Linux) koriste '\n' (linefeed ili LF - ASCII kod 10 (dec)). DOS i njegovi naslednici (Windows), kao i stari Digitalovi sistemi, koriste '\r\n' (carriage return + line feed - CR+LF, ASCII kodovi 13+10). Medjutim, Linux (i GNU) softver preveden na Windows takodje koristi Unix-ovski '\n'. U ovo poslednje spada i Python.
[ a1234567 @ 09.03.2020. 02:06 ] @
Kod tvog koda mi je otkriće da posle otvaranja ne moram da koristim readline,
već mogu odmah da pređem na operacije sa stringom.
Ja sam stalno išao na ovo
Code: with open('words.txt', 'r') as fajl:
redovi2 = fajl.readlines()
U kojim se onda slučajevima koristi readline?
Inače dodao sam kod tebe .capitalize()
i imao si if (line(red)>=3):
umesto if (len(red)>=3):
Vidim da stavljaš zagrade pre len i na kraju.
Jel to tako bilo u python 2.x?
U trojci može i bez zagrada.
Sad je kod sledeći:
Code: import random
redovi = []
lozinka = ''
for red in open('words.txt', 'r'):
red = red.strip().capitalize()
if len(red) >= 3:
redovi.append(red)
while len(lozinka) < 10:
lozinka += random.choice(redovi)
print('Tvoja nova lozinka je:\n\n', lozinka)
[ Panta_ @ 09.03.2020. 11:58 ] @
"U kojim se onda slučajevima koristi readline?"
readline čita jednu liniju do znaka za novu liniju ili kraja fajla i vraća string uključujući i znak za novu liniju (\n). Na primer:
Code (python):
open('file.txt').readline() 'Programming fundamental tasks\n'
open('file.txt').readline().rstrip('\n') 'Programming fundamental tasks'
readlines vraća listu linija uključujući i \n znak:
Code (python):
open('/fajl.txt').readlines() ['Programming fundamental tasks\n', 'Database programming with python\n', 'Object Oriented programming\n']
[line.rstrip()for line inopen('fajl.txt').readlines()] ['Programming fundamental tasks', 'Database programming with python', 'Object Oriented programming']
read čita do kraja fajla ili n broj znakova i vraća string:
Code (python):
open('fajl.txt').read(11) 'Programming'
open('fajl.txt').read() 'Programming fundamental tasks\nDatabase programming with python\nObject Oriented programming \n'
open('fajl.txt').read().split('\n') ['Programming fundamental tasks', 'Database programming with python', 'Object Oriented programming', '']
open('fajl.txt').read().splitlines() ['Programming fundamental tasks', 'Database programming with python', 'Object Oriented programming ']
Vidim da stavljaš zagrade pre len i na kraju.
Jel to tako bilo u python 2.x?
U trojci može i bez zagrada.
To je samo znak kućnog vaspitanja :)
Zagrade je uvek pametno stavljati. Možda su ponekad nepotrebne, ali si bar siguran kojim redosledom će se uraditi operacije...
[ a1234567 @ 09.03.2020. 16:00 ] @
Hvala, Panto, sad smo čitanje fajlova apsolvirali do u detalje. :)
Đoko, pozdravljam kućno vaspitanje. To uvek dobro dođe.
A i od viška (zagrada) glava ne boli (uvek). :)
Nego, krenuo ja da radim naredni zadatak:
Napiši program koji čita fajl sa informacijama o hemijskim elementima i skladišti ih u odgovarajući strukturu podataka.
Potom prima input od korisnika. Ako je input integer, , onda program ispisuje simbol i naziv elementa sa tim brojem protona.
Ako korisnik unese naziv ili simbol elementa, program ispisuje njegov broj protona. Takođe, program ispisuje porucu o grešci
ako ne postoji elemenat koji bi odgovarao unetom nazivu, simbolu ili broju protona. Program nastavlja da učitava input sve
dok nije uneta prazna linija.
Gledao sam kako od liste da napravim rečnik i sve što sam uspeo je da napravim tri liste,
Ali ne znam kako da ih na pravi način ukomponujem u jedan rečnik.
Za sad sam stigao dovde
Ovo je prvi zadatak u kome moras da razmisljas out-of-the-box ...
Tebi je bitno da za zadat simbol, puno ime ili broj protona izbacis sve (ili odabrane) podatke o elementu. To prakticno znaci da ti je potrebna struktura u kojoj sva tri atributa (simbol, ime, protoni) mogu u isto vreme da budu i kljucevi i vrednosti. Tu imas vise resenja.
Prvi nacin, pomalo pocetnicki, je da se formiraju 2 recnika. U prvom ce kljucevi biti imena i simboli, a vrednosti brojevi protona. Drugi ce sluziti za obrnuto mapiranje:
Ostatak programa je trivijalan - ako je uneta numericka vrednost (integer) p, ispisujes ime[p].
Ako je uneta nenumericka vrednost (string) s, ispisujes proton[s].
Naravno, moras da ispitas da li se p i s nalaze unutar recnika.
Na kraju, mozes ta dva recnika da spojis i u jedan ...
Drugi, napredniji nacin je da napravis visedimenzionu hash tabelu sa ili/ili kljucevima. Prednost je sto imas samo jedan recnik i taj recnik ima svega N elemenata, gde je N broj linija u fajlu koji ucitavas (1,H,Hydrogen,2,He,Helium ...). Naravno, neces to da radis iz pocetka, ljudi su to vec napravili i zove se multi_key_dict.
def find_in_matrix( table, element):
element = element.lower()
for row in table:
for col in row:
if element == str(col).lower():
return row
return [ element ]
def output( row ):
print()
if len( row ) == 3:
print('Atomic number: ', row[0])
print('Symbol : ', row[1])
print('Name : ', row[2])
else:
print('Matching element not found: ', row[0])
def main_loop():
pt=get_test_data()
while True:
print()
print('Enter atomic number, chemical symbol or element name')
print('to get the rest of the data, or an empty line for end:')
search = input()
if len(search)==0:
break
result = find_in_matrix(pt,search)
output(result)
print()
print('Bye!')
main_loop()
Code: py .\elements.py
Enter atomic number, chemical symbol or element name
to get the rest of the data, or an empty line for end:
1
Atomic number: 1
Symbol : H
Name : Hydrogen
Enter atomic number, chemical symbol or element name
to get the rest of the data, or an empty line for end:
he
Atomic number: 2
Symbol : He
Name : Helium
Enter atomic number, chemical symbol or element name
to get the rest of the data, or an empty line for end:
carbon
Atomic number: 6
Symbol : C
Name : Carbon
Enter atomic number, chemical symbol or element name
to get the rest of the data, or an empty line for end:
fe
Matching element not found: fe
Enter atomic number, chemical symbol or element name
to get the rest of the data, or an empty line for end:
Bye!
[ djoka_l @ 10.03.2020. 22:32 ] @
Opservacija:
mislim da sam ti jednom već napisao - inženjeru koji ima samo čekić, svaki problem izgleda kao ekser.
Tako i tebi, svaki zadatak je nerešiv ako ne znaš kako podatke da staviš u dictionary.
Moje rešenje je elementarno, praktično ne koristim ni jednu python caku, ali ti pokazuje da svaki zadatak može da se reši na više načina.
Ja obično biram najprostiji način.
Razdvojiš funkcionalnosti u FUNKCIJE.
Tako ćeš lako da dodaš učitavanje iz fajla, a ne predefinisanu tabelu koju sam ja napravio.
Ako ti se ne sviđa moj način traženja podatka promeniš samo jednu FUNKCIJU.
Ostalo ne moraš da menjaš.
Koristi FUNKCIJE, tako ćeš logičke celine svog rešenje lako zamenjivati kada smisliš bolje rešenje.
[ Panta_ @ 11.03.2020. 08:02 ] @
Evo rešenje sa pomenutim rečnikom:
Code (python):
tabela =[]
for line inopen('elements.txt'):
line = line.strip().split(',')
tabela.append({'simbol': line[1],'ime': line[2],'broj protona': line[0]})
whileTrue:
user_input =input( "Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa): ") # Ako je user_input prazan string, prekidam izvršavanje while petlje if user_input =='': print('Izlazim.') break
founded =False for elements in tabela: ifnot founded: for element in elements.values(): # Ako element value odgovara inputu, dodeljujem founded promenljivoj # vrednost True kao bih prekinuo dalje izvršavanje prve for petlje if element == user_input.title():
founded =True # Ukoliko je input integer, ispisujem simbol, ime i broj # protona. U suprotnom, ispisujem samo broj protona if element.isdigit(): print(f"Simbol: {elements['simbol']} \ \nIme: {elements['ime']} \ \nBroj protona: {elements['broj protona']}\n") else: print(f"Broj protona: {elements['broj protona']}\n") else: break ifnot founded: print(f"Element {user_input} nije pronađen! Pokusajte ponovo.\n")
Code: Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa): carbon
Broj protona: 6
Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa): he
Broj protona: 2
Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa): 3
Simbol: Li
Ime: Lithium
Broj protona: 3
Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa): fe
Element fe nije pronađen! Pokusajte ponovo.
Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa):
Izlazim.
Naravno, umesto rečnika možeš da koristiš liste ili tuple, posebno za ovaj zadatak pošto ti ključevi nisu neophodni.
[ a1234567 @ 11.03.2020. 10:10 ] @
Au, šta je materijala za razmatranje.
Hvala na trudu!
Za početak sam razmotrio Pantino rešenje.
Vidim da si promenio tip strukture podataka, pa si umesto rečnika napravio listu, čiji su elementi rečnici.
Ja sam očigledno na samom početku nepotrebno zakomplikovao, misleći da treba da koristim nested dictionary.
Jedino što tvoje rešenje ne daje ispis tačno kako se traži u zadatku.
"If the user enters a non-integer value then your program should display the
number of protons for the element with that name or symbol."
Zato sam malo "dopisao" ovo pretposlednje else
Code: tabela = []
for line in open('elements.txt'):
line = line.strip().split(',')
tabela.append({'simbol': line[1], 'ime': line[2], 'broj protona': line[0]})
while True:
user_input = input(
"Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa): ")
# Ako je user_input prazan string, prekidam izvršavanje while petlje
if user_input == '':
print('Izlazim.')
break
founded = False
for elements in tabela:
if not founded:
for element in elements.values():
# Ako element value odgovara inputu, dodeljujem founded promenljivoj
# vrednost True kako bih prekinuo dalje izvršavanje prve for petlje
if element == user_input.title():
founded = True
# Ukoliko je input integer, ispisujem simbol, ime i broj
# protona. U suprotnom, ispisujem samo broj protona
if element.isdigit():
print(f"Simbol: {elements['simbol']} \
\nIme: {elements['ime']} \
\nBroj protona: {elements['broj protona']}\n")
else:
if element in elements['simbol']:
print(f"Ime: {elements['ime']} \
\nBroj protona: {elements['broj protona']}\n")
elif element in elements['ime']:
print(f"Simbol: {elements['simbol']} \
\nBroj protona: {elements['broj protona']}\n")
else:
break
if not founded:
print(f"Element {user_input} nije pronađen! Pokušajte ponovo.\n")
Sad ispisuje ovako:
Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa): Calcium
Simbol: Ca
Broj protona: 20
Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa): 100
Simbol: Fm
Ime: Fermium
Broj protona: 100
Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa): fm
Ime: Fermium
Broj protona: 100
[ Panta_ @ 11.03.2020. 12:16 ] @
Citat:
Jedino što tvoje rešenje ne daje ispis tačno kako se traži u zadatku.
"If the user enters a non-integer value then your program should display the
number of protons for the element with that name or symbol."
Zašto onda nisi tako napisao već:
Citat:
Ako korisnik unese naziv ili simbol elementa, program ispisuje njegov broj protona.
Citat:
Zato sam malo "dopisao" ovo pretposlednje else
else:
if element in elements['simbol']:
print(f"Ime: {elements['ime']} \
\nBroj protona: {elements['broj protona']}\n")
elif element in elements['ime']:
print(f"Simbol: {elements['simbol']} \
\nBroj protona: {elements['broj protona']}\n")
Dovoljno je samo u print funkciji ispred "Broj protona" da dodaš Simbol: {elements['ime'] if element in elements['simbol'] else elements['simbol']}, npr:
print(f"Simbol: {elements['ime'] if element in elements['simbol'] else elements['simbol']}\nBroj protona: {elements['broj protona']}\n")
Moja greška, nisam video da treba i ime.
[Ovu poruku je menjao Panta_ dana 11.03.2020. u 13:51 GMT+1]
[Ovu poruku je menjao Panta_ dana 11.03.2020. u 13:52 GMT+1]
[ a1234567 @ 12.03.2020. 15:06 ] @
Citat:
B3R1:
Ovo je prvi zadatak u kome moras da razmisljas out-of-the-box ...
Tebi je bitno da za zadat simbol, puno ime ili broj protona izbacis sve (ili odabrane) podatke o elementu. To prakticno znaci da ti je potrebna struktura u kojoj sva tri atributa (simbol, ime, protoni) mogu u isto vreme da budu i kljucevi i vrednosti. Tu imas vise resenja.
Prvi nacin, pomalo pocetnicki, je da se formiraju 2 recnika. U prvom ce kljucevi biti imena i simboli, a vrednosti brojevi protona. Drugi ce sluziti za obrnuto mapiranje:
Berislave, razmotrio sam ovu trivijalnu varijantu i napravio sa tri rečnika za listu elemenata 1,H,Hydrogen
2,He,Helium
3,Li,Lithium
4,Be,Beryllium...
U svakom su ključevi naziv elementa, simbol, odnosno broj protona:
Code: ime = {}
simbol = {}
proton = {}
for line in open('elements.txt'):
line = line.strip().split(',')
ime[line[2]] = [line[1], int(line[0])]
simbol[line[1]] = [line[2], int(line[0])]
proton[int(line[0])] = [line[2], line[1]]
user_input = input("Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa): ")
if user_input == '':
print('Izlazim.')
elif user_input.isdigit():
print('Ime elementa je', proton[int(user_input)][0], '\ni njegov simbol je', proton[int(user_input)][1])
elif user_input.title() in simbol.keys():
print('Ime elementa je', simbol[user_input.title()][0], '\ni on ima', simbol[user_input.title()][1], 'protona')
elif user_input.title() in ime.keys():
print('Simbol elementa je', ime[user_input.title()][0], '\ni on ima', ime[user_input.title()][1], 'protona')
else:
print('Uneta vrednost se ne nalazi u tabeli prirodnih elemenata.')
I dobijam
Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa): h
Ime elementa je Hydrogen
i on ima 1 protona
Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa): be
Ime elementa je Beryllium
i on ima 7 protona
Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa): boron
Simbol elementa je B
i on ima 5 protona
Unesite ime, simbol ili broj protona (ili Enter za izlaz iz programa): kdsjd
Uneta vrednost se ne nalazi u tabeli prirodnih elemenata.
[ a1234567 @ 12.03.2020. 15:31 ] @
Citat:
djoka_l:
Opservacija:
mislim da sam ti jednom već napisao - inženjeru koji ima samo čekić, svaki problem izgleda kao ekser.
Tako i tebi, svaki zadatak je nerešiv ako ne znaš kako podatke da staviš u dictionary.
Moje rešenje je elementarno, praktično ne koristim ni jednu python caku, ali ti pokazuje da svaki zadatak može da se reši na više načina.
Ja obično biram najprostiji način.
Razdvojiš funkcionalnosti u FUNKCIJE.
Tako ćeš lako da dodaš učitavanje iz fajla, a ne predefinisanu tabelu koju sam ja napravio.
Ako ti se ne sviđa moj način traženja podatka promeniš samo jednu FUNKCIJU.
Ostalo ne moraš da menjaš.
Koristi FUNKCIJE, tako ćeš logičke celine svog rešenje lako zamenjivati kada smisliš bolje rešenje.
Mislim da mi još treba vremena da pohvatam ove osnovne stvari. A funkcije su malo viša faza, čini mi se.
No, probaću u rešenja za naredne zadatke i njih da uključim.
[ a1234567 @ 12.03.2020. 15:38 ] @
I evo da napravim i poseban post za ovaj zadatak, lakše će se snaći oni koji budu gledali ovaj topik.
Zadatak broj 29
Napiši program koji čita fajl sa informacijama o hemijskim elementima i skladišti ih u odgovarajući strukturu podataka.
Potom prima input od korisnika. Ako je input integer, , onda program ispisuje simbol i naziv elementa sa tim brojem
protona. Ako korisnik unese naziv ili simbol elementa, program ispisuje njegov broj protona. Takođe, program ispisuje
porucu o grešci ako ne postoji elemenat koji bi odgovarao unetom nazivu, simbolu ili broju protona. Program nastavlja
da učitava input sve dok nije uneta prazna linija.
Napiši program koji čita spisak reči iz fajla i izračunava procenat reči koje koriste
određeno slovo abecede. Ispiši taj procenat za svako slovo, a na kraju i poruku
koje slovo se najređe pojavljuje. Program ignoriše znakove interpunkcije i
isto tako velika i mala slova tretira kao isto slovo.
a se javlja u 40.09 odsto reči
b se javlja u 6.23 odsto reči
c se javlja u 16.85 odsto reči
d se javlja u 18.44 odsto reči
e se javlja u 49.71 odsto reči
f se javlja u 11.07 odsto reči
g se javlja u 9.93 odsto reči
h se javlja u 21.55 odsto reči
i se javlja u 30.47 odsto reči
j se javlja u 0.48 odsto reči
k se javlja u 3.08 odsto reči
l se javlja u 17.02 odsto reči
m se javlja u 13.56 odsto reči
n se javlja u 32.13 odsto reči
o se javlja u 35.70 odsto reči
p se javlja u 9.13 odsto reči
q se javlja u 0.45 odsto reči
r se javlja u 28.23 odsto reči
s se javlja u 28.40 odsto reči
t se javlja u 41.34 odsto reči
u se javlja u 14.46 odsto reči
v se javlja u 5.26 odsto reči
w se javlja u 8.89 odsto reči
x se javlja u 1.00 odsto reči
y se javlja u 8.61 odsto reči
z se javlja u 0.62 odsto reči
Slovo koje se najređe pojavljuje je: q
[ B3R1 @ 18.03.2020. 11:46 ] @
Lepo uradjeno. Popravio si stil kodiranja, nemas vise suvisne korake. Sve u svemu, napredujes.
[ a1234567 @ 18.03.2020. 14:01 ] @
Hvala, Berislave.
To je po onome, i ćorava koka ubode neko zrno.
Tako i ja ovoga puta
[ djoka_l @ 18.03.2020. 18:19 ] @
Pridružujem se čestitkama!
Naravno, uvek može i malo bolje
Korišćenjem regularnog izraza i skupa umesto liste, eliminisao sam jednu petlju, jedan if sa tri logička izraza i append, pa sam na milion izvršavanja dobio upola kraće vreme.
Ovo jeste teranje maka na konac, ali pokazuje da uvek ima mesta da se unapredi algoritam i da se odabere bolja struktura podataka za dati problem.
[ Panta_ @ 18.03.2020. 20:46 ] @
Citat:
Korišćenjem regularnog izraza i skupa umesto liste, eliminisao sam jednu petlju, jedan if sa tri logička izraza i append, pa sam na milion izvršavanja dobio upola kraće vreme.
Ako zamniš ch >= "a" and ch <= "z" sa ch in 'abcdefghijklmnopqrstuvwxyz' kao i set regex sa {ch for ch in MyWord if ch in 'abcdefghijklmnopqrstuvwxyz'} dobićeš jos kraće vreme.
Code: %timeit set(regex.sub("", MyWord))
1.36 µs per loop
%timeit {ch for ch in MyWord if ch in 'abcdefghijklmnopqrstuvwxyz'}
1.26 µs per loop
%timeit [ch for ch in MyWord if ch >= "a" and ch <= "z"]
1.4 µs per loop
%timeit [ch for ch in MyWord if ch in 'abcdefghijklmnopqrstuvwxyz']
1.07 µs per loop
[ Panta_ @ 18.03.2020. 21:30 ] @
Citat:
To je po onome, i ćorava koka ubode neko zrno.
Po mom mišljnju opet imaš koje zrno viška, na primer:
Code:
brojac = {}
for ch in 'abcdefghijklmnopqrstuvwxyz':
brojac[ch] = 0
br_reci = 0
spisak = open('reci2.txt', 'r', encoding='utf-8')
for rec in spisak:
rec = rec.lower().rstrip()
# Lista slova koja se pojavljuju u rečima, ali bez ponavljanja.
slova = []
for ch in rec:
if ch not in slova and ch >= "a" and ch <= "z":
slova.append(ch)
# Brojač za slova
for ch in slova:
brojac[ch] = brojac[ch] + 1
# Brojač za reči
br_reci = br_reci + 1
Imaš dve suvišne for petlje, nema potrebe da prvo dodaješ slova u brojač.
Recimo da hoćeš da prebrojiš i naša ili neka druga slova, a nemaš ih u rečniku, dobio bi Key error grešku pošto isti nije u rečniku.
# Lista slova koja se pojavljuju u rečima, ali bez ponavljanja.
slova = []
for ch in rec:
if ch not in slova and ch >= "a" and ch <= "z":
slova.append(ch)
# Brojač za slova
if ch not in brojac:
brojac[ch]=1
else:
brojac[ch]+=1
br_reci = br_reci + 1
Takođe, za brojač može da se iskoristi defaultdict iz collections modula:
Code: from collections import defaultdict
brojac = defaultdict(int)
# Umesto if/else
if ch not in brojac:
brojac[ch]=1
else:
brojac[ch]+=1
# je dovoljno
brojac[ch]+=1
[ a1234567 @ 25.03.2020. 16:07 ] @
Borim se sa zadatkom broj 31:
Podaci se sastoje od preko 200 fajlova. Svaki fajl sadrži spisak od 100 imena koja su u SAD bila najpolularnija u datoj godini, zajedno s brojem upotreba svakog imena. Imena su u fajlu poređana od najviše korišćenog pa naniže. Postoje dva fajla za svaku godinu: jedan sadrži imena koja se koriste za devojčice, a drugi sadrži imena za dečake. Skup podataka uključuje podatke za svaku godinu od 1900. do 2012. godine.
Napisati program koji čita svaki fajl i identifikuje sva imena koja su bila najpopularnija najmanje u jednoj godini. Program ispisuje dve liste:
jedna sadrži najpopularnija imena za dečake, a druga za djevojčice. Nijedan spisak ne sadrži ponovljena imena.
fajlovi u folderu:
1900_BoysNames.txt
1900_GirlsNames.txt
1901_BoysNames.txt
1901_GirlsNames.txt
itd.
podaci u fajlu:
John 9830
William 8580
James 7245
George 5403
Charles 4101
Robert 3824
Joseph 3714
Frank 3477
itd.
Uspeo sam da pokupim unikatna imena iz prvog reda svakog fajla, ali sve u jedan fajl:
Code: import glob
imena = []
with open('imena.txt2', 'w') as spisak:
for filename in glob.glob('*.txt'):
fajl = open(filename, 'r', encoding='utf-8')
line = fajl.readline().strip().split()
ime = line[0]
if ime not in imena:
imena.append(ime)
spisak.writelines(str(imena)+'\n')
Kako da selektujem na muška i ženska imena, nemam ideju :(
[ Panta_ @ 25.03.2020. 17:02 ] @
Probaj ovako:
Code:
boys = []
girls = []
for filename in glob.glob('*txt'):
if 'Boys' in filename:
name = open(filename).readline().split()[0]
if name not in boys:
boys.append(name)
elif 'Girls' in filename:
name = open(filename).readline().split()[0]
if name not in girls:
girls.append(name)
[ a1234567 @ 26.03.2020. 04:29 ] @
Probao. Radi :)
Znači mogu detaljnije da biram koje će glob fajlove da globi, a ne samo preko ekstenzije.
To nisam bio prokljuvio.
Dobro, sad je kod ovakav
Code: boys = []
girls = []
with open('decaci.txt2', 'w') as spisak1:
with open('devojcice.txt2', 'w') as spisak2:
for filename in glob.glob('*txt'):
if 'Boys' in filename:
name = open(filename).readline().split()[0]
if name not in boys:
boys.append(name)
elif 'Girls' in filename:
name = open(filename).readline().split()[0]
if name not in girls:
girls.append(name)
spisak1.writelines('\n'.join(boys))
spisak2.writelines('\n'.join(girls))
Pošto se fajlovi u koje upisujem selektovana imena nalaze u istom folderu sa imenima dece, ovaj glob krene da otvara i njih.
Zato sam, kao što vidiš, njihove extenzije promenio u .txt2.
Kako da ovome writelines dam putanju za neki drugi folder gde će upisivati fajlove sa odabranim imenima?
[ Panta_ @ 26.03.2020. 06:40 ] @
Citat:
Znači mogu detaljnije da biram koje će glob fajlove da globi, a ne samo preko ekstenzije.
glob vraća listu imena datoteka koje se završavaju sa .txt, dakle isto kao da si napisao: for filename in ['2010_GirlsNames.txt', '1917_BoysNames.txt', itd...]:
Citat:
Kako da ovome writelines dam putanju za neki drugi folder gde će upisivati fajlove sa odabranim imenima?
Navedi putanju u open('/putanja/do/decaci.txt', 'w'), ili putanja = '/putanja/do/decaci.txt', pa onda u open(putanja, 'w') itd...
[ a1234567 @ 26.03.2020. 07:22 ] @
Aha, to sa globom je u stvari onda lista imena fajlova. Kapiram.
Da, sad kad stavim putanju, radi sve kako treba.
Konačno rešenje je ovde.
Hvala, Panto!
Sad mogu da krenem na naredni zadatak....
[ Panta_ @ 26.03.2020. 08:32 ] @
Citat:
Sad mogu da krenem na naredni zadatak
Pre nego što kreneš na naredni zadatak, bio bi red da program pored imena ispiše i godine u kojima je ime bilo najpopularnije, kao i broj datih imena. Na primer:
E ako bi bio red, onda nema druge nego da uradim, samo ako budem umeo :))
"Jer red je red, sve ja to poštujem... "
[ a1234567 @ 26.03.2020. 15:30 ] @
Evo dovde sam stigao.
Program ne prijavljuje nikakvu grešku, ali ništa ni ne upisuje u rečnike.
Negde nešto fali, ali ne mogu da uklavirim šta.
Code: import glob
decaci = {}
devojcice = {}
with open('c:/FAJLOVI/Python_School/Stephenson_ThePythonWorkbook/decaci.txt2', 'w') as spisak1:
with open('c:/FAJLOVI/Python_School/Stephenson_ThePythonWorkbook/devojcice.txt2', 'w') as spisak2:
for filename in glob.glob('*txt'):
if 'Boys' in filename:
name = open(filename).readline().split()[0]
broj = open(filename).readline().split()[1]
godina = filename[0:4]
for k1, v1 in decaci.items():
for k2, v2 in v1.items():
if name not in v2.keys():
decaci['Boys Names'][name][godina] = [broj]
elif 'Girls' in filename:
name = open(filename).readline().split()[0]
broj = open(filename).readline().split()[1]
godina = filename[0:4]
for k1, v1 in devojcice.items():
for k2, v2 in v1.items():
if name not in v2.keys():
devojcice['Girls Names'][name][godina] = [broj]
[ Panta_ @ 26.03.2020. 19:56 ] @
Fali svašta. Nema potrebe za tolikim for petljama, ionako u decaci i devojcije dictionary nemaš ništa, a i imaš već for petlju za filename. Ranije gore sam ti pomenu defaultdict iz collections modula koji kreira ključ ukoliko isti ne postoji kako ne bi dobio key error. Na primer:
Code (python):
fromcollectionsimport defaultdict
decaci = defaultdict(dict)
# ili https://docs.python.org/3/library/stdtypes.html#dict.setdefault # decaci.setdefault('Boys', {})
for filename inglob.glob('*txt'): if'Boys'in filename:
name, broj =open(filename).readline().split() # broj = open(filename).readline().split()[1]
godina = filename[:4] if name notin decaci['Boys']:
decaci['Boys'].update({name: {godina: broj}}) else:
decaci['Boys'][name].update({godina: broj})
Nisam gledao detaljno, ali ovako na brzinu palo mi je u oci nekliko detalja:
Code:
name = open(filename).readline().split()[0]
broj = open(filename).readline().split()[1]
Fajl se otvara samo jednom, a svaki sledeci poziv funkcije readline() cita sledecu linju iz fajla. Ovako kako si napisao program ce svaki put otvoriti fajl iznova i uvek procitati samo prvu liniju. Ono sto si hteo da uradis je:
Code:
for filename in glob.glob('*txt'):
lines = open(filename).readlines()
if 'Boys' in filename:
for line in lines:
name = line.strip().split()[0]
broj = line.strip().split()[1]
godina = filename[0:4]
...
Drugo, cemu ti sluze ove dve petlje na pocetku:
Code:
with open('c:/FAJLOVI/Python_School/Stephenson_ThePythonWorkbook/decaci.txt2', 'w') as spisak1:
with open('c:/FAJLOVI/Python_School/Stephenson_ThePythonWorkbook/devojcice.txt2', 'w') as spisak2:
Mislim da treba samo da otvoris ta dva fajla za upisivanje bez 'with' strukture. I da svaki put u petlji samo upisujes u njih koristeci write() funkciju - npr:
Code:
spisak1 = open('c:/FAJLOVI/Python_School/Stephenson_ThePythonWorkbook/decaci.txt2', 'w')
spisak2 = open('c:/FAJLOVI/Python_School/Stephenson_ThePythonWorkbook/devojcice.txt2', 'w')
# ... Program ide dalje
# Ispis
...
spisak1.write(promenljiva + '\n')
spisak2.write(promenljiva + '\n')
# OBAVEZNO NA KRAJU:
spisak1.close()
spisak2.close()
Sledeca stvar su dictovi, odnosno hash tabele:
Code:
decaci = {}
...
for k1, v1 in decaci.items():
for k2, v2 in v1.items():
if name not in v2.keys():
decaci['Boys Names'][name][godina] = [broj]
Ispravno bi bilo:
Code:
decaci = { 'Boys Names': {} }
for k1, v1 in decaci.items():
for k2, v2 in v1.items():
if name not in v2.keys():
decaci['Boys Names'][name] = {}
if godina not in decaci['Boys Names'][name] :
decaci['Boys Names'][name][godina] = broj
Naime, decaci{} ti je hash tabela ciji je kljuc 'Boys Names', a vrednost nova hash tabela kojoj su kljucevi imena, a vrednosti treca hash tabela ciji su kljucevi godista, a vrednosti frekvencija imena:
Da pojasnimo: kada definises hash tabelu decaci kao praznu (decaci = {}), Python ce ti dopustiti da kreiras key:value parove kako god zelis:
Code:
decaci['Mark'] = 1
decaci['Peter'] = 'abc123'
...
Ali kada kazes:
Code:
decaci['Mark']['1976'] = 123
dobijas gresku jer je decaci['Mark'] inicijalizovano kao skalar, a ne kao nova hash tabela. Da bi formirao hash tabelu unutar druge hash tabele moras da najpre kazes da je vrednost kljuca 'Mark' takodje hash tabela:
Code:
decaci['Mark'] = {}
decaci['Mark']['1976'] = 123
Kao sto je Panta rekao, tu moze da ti pomogne defaultdict, mada je daleko cistije raditi postepenu inicijalizaciju, jer se kasnije lakse uocavaju i ispravljaju greske.
Druga stvar koja mi upada u oci je:
Code:
decaci['Boys Names'][name][godina] = [broj]
Ovako kako si napisao ti zapravo dobijas:
{'Boys Names': {
'David': {'1960': ['85928']},
'Jacob': {'1999': ['35342'], '2000': ['34460'] }
}}
Cemu ti sluzi lista kao vrednost u ovom slucaju?
I ono poslednje - godista i frekvencije pojavljivanja imena su numericke vrednosti, pa nema smisla skladistiti ih kao stringove. Numericke vrednosti mogu da se direktno obradjuju. Pre bi imlao smisla:
Code: name = int(line.strip().split()[0])
broj = int(line.strip().split()[1])
Za kraj jedna zanimljivost: funkcija int(x) u vecini jezika vraca nulu ako x nije numericka vrednost. Npr. int('23') ce biti 23, dok ce int('hello') biti 0. U Pythonu to nije slucaj, int('hello') ce prijaviti gresku. Ja obicno koristim modifikovanu verziju funkcije int() koja izgleda ovako:
Code:
# aint() - The int() function, as we got used in other languagues
def aint(x):
try:
retval = int(x)
except:
retval = 0
return retval
I pozivam je sa aint(x) ... vraca nulu ako x nije numericko.
[ Branimir Maksimovic @ 27.03.2020. 11:21 ] @
Citat:
a1234567:
Borim se sa zadatkom broj 31:
Podaci se sastoje od preko 200 fajlova. Svaki fajl sadrži spisak od 100 imena koja su u SAD bila najpolularnija u datoj godini, zajedno s brojem upotreba svakog imena. Imena su u fajlu poređana od najviše korišćenog pa naniže. Postoje dva fajla za svaku godinu: jedan sadrži imena koja se koriste za devojčice, a drugi sadrži imena za dečake. Skup podataka uključuje podatke za svaku godinu od 1900. do 2012. godine.
Napisati program koji čita svaki fajl i identifikuje sva imena koja su bila najpopularnija najmanje u jednoj godini. Program ispisuje dve liste:
jedna sadrži najpopularnija imena za dečake, a druga za djevojčice. Nijedan spisak ne sadrži ponovljena imena.
fajlovi u folderu:
1900_BoysNames.txt
1900_GirlsNames.txt
1901_BoysNames.txt
1901_GirlsNames.txt
itd.
podaci u fajlu:
John 9830
William 8580
James 7245
George 5403
Charles 4101
Robert 3824
Joseph 3714
Frank 3477
itd.
Uspeo sam da pokupim unikatna imena iz prvog reda svakog fajla, ali sve u jedan fajl:
Code: import glob
imena = []
with open('imena.txt2', 'w') as spisak:
for filename in glob.glob('*.txt'):
fajl = open(filename, 'r', encoding='utf-8')
line = fajl.readline().strip().split()
ime = line[0]
if ime not in imena:
imena.append(ime)
spisak.writelines(str(imena)+'\n')
Kako da selektujem na muška i ženska imena, nemam ideju :(
Gde se nalaze fajlovi da probam i ja u Rust-u ili Haskell=u ;)?
[ Panta_ @ 27.03.2020. 13:28 ] @
"Gde se nalaze fajlovi da probam i ja u Rust-u ili Haskell=u ;)?"
evo ga Rust. Znaci program se nazalizi u diru iznad BabyNames, testirano na Linux-u mozda samo zmaeniti '/' sa '\\' za Windows.
Code:
~/.../examples/rust >>> cat girlsboys.rs
use std::io;
use std::fs::File;
use std::fs::read_dir;
use std::io::prelude::*;
fn main()->io::Result<()>{
let mut maxs_girls:Vec<(i32,String)> = Vec::new();
let mut maxs_boys:Vec<(i32,String)> = Vec::new();
let mut max:(i32,String);
let mut buf = String::new();
if let Ok(dir) = read_dir("BabyNames") {
for file in dir {
let file = file?;
let mut f = File::open(file.path())?;
buf.clear();
let _ = f.read_to_string(&mut buf);
max = (0,"".to_string());
for line in buf.lines() {
let two:Vec<_> = line.split_whitespace().collect();
if let Ok(number) = two[1].parse::<i32>(){
let name = two[0];
if max.0 < number {
max = (number,name.to_string());
}
}
}
let path = file.path();
let fname = path.to_str().unwrap().to_string();
let it = fname.split('_').collect::<Vec<_>>();
let it1 = it[0].split('/').collect::<Vec<_>>();
let year = it1[1].parse::<i32>().unwrap();
max.0 = year;
if it[1] == "GirlsNames.txt" {
maxs_girls.push(max);
} else {
maxs_boys.push(max);
}
}
} else {
println!("Not in directory above BabyNames...");
}
maxs_girls.sort();
maxs_boys.sort();
for i in maxs_girls.iter().zip(maxs_boys) {
println!("{:?}",i);
}
Ok(())
}
use std::io;
use std::fs::File;
use std::fs::read_dir;
use std::io::prelude::*;
use std::collections::BTreeMap;
fn main()->io::Result<()>{
let mut maxs_girls:BTreeMap<String,Vec<(i32,i32)>> = BTreeMap::new();
let mut maxs_boys:BTreeMap<String,Vec<(i32,i32)>> = BTreeMap::new();
let mut max:(i32,String);
let mut buf = String::new();
if let Ok(dir) = read_dir("BabyNames") {
for file in dir {
let file = file?;
let mut f = File::open(file.path())?;
buf.clear();
let _ = f.read_to_string(&mut buf);
max = (0,"".to_string());
for line in buf.lines() {
let two:Vec<_> = line.split_whitespace().collect();
if let Ok(number) = two[1].parse::<i32>(){
let name = two[0];
if max.0 < number {
max = (number,name.to_string());
}
}
}
let path = file.path();
let fname = path.to_str().unwrap().to_string();
let it = fname.split('_').collect::<Vec<_>>();
let it1 = it[0].split('/').collect::<Vec<_>>();
let year = it1[1].parse::<i32>().unwrap();
if it[1] == "GirlsNames.txt" {
let r = maxs_girls.entry(max.1).or_insert(Vec::new());
(*r).push((year,max.0));
(*r).sort();
} else {
let r = maxs_boys.entry(max.1).or_insert(Vec::new());
(*r).push((year,max.0));
(*r).sort();
}
}
} else {
println!("Not in directory above BabyNames...");
}
println!("Girls");
for i in maxs_girls {
println!("{:?}",i);
}
println!("Boys");
for i in maxs_boys {
println!("{:?}",i);
}
Ok(())
}
Ashley
Emily
Emma
Isabella
Jennifer
Jessica
Linda
Lisa
Mary
Sophia
Mrzelo me da napravim for petlju, pa da linija bude malo kraća...
[ djoka_l @ 28.03.2020. 09:50 ] @
Na mnogobrojne zahteve, evo kraće, sa for petljom
$ for g in 'Boys' 'Girls'; do echo -e "\n\n${g}:\n" ; head -1 -q BabyNames/*${g}*.txt | awk '{print $1}' | sort -u ; done
Boys:
David
Jacob
James
John
Michael
Robert
Girls:
Ashley
Emily
Emma
Isabella
Jennifer
Jessica
Linda
Lisa
Mary
Sophia
[ a1234567 @ 28.03.2020. 09:57 ] @
Hvala Panto i Berislave na korekcijama.
Komplikovani ovi nested rečnici :)
Berislave, nisam iz tvojih komentara još uvek uspeo da sklopim program.
Ono što sam dobio je ovo:
Code: for filename in glob.glob('*txt'):
lines = open(filename).readlines()
if 'Boys' in filename:
for line in lines:
name = line.strip().split()[0]
broj = line.strip().split()[1]
godina = filename[0:4]
decaci = { 'Boys Names': {} }
for k1, v1 in decaci.items():
for k2, v2 in v1.items():
if name not in v2.keys():
decaci['Boys Names'][name] = {}
if godina not in decaci['Boys Names'][name]:
decaci['Boys Names'][name][godina] = broj
Ali kad se kod izvrši, rečnik je još uvek prazan, {'Boys Names': {}}
iako kad pozovem godina ispiše 2012, što znači da je prošao sve fajlove.
[ a1234567 @ 28.03.2020. 10:00 ] @
Đoko, slabo je to.
Nemaš ni godine ni brojeve.
2+
[ djoka_l @ 28.03.2020. 10:15 ] @
Citat:
Napisati program koji čita svaki fajl i identifikuje sva imena koja su bila najpopularnija najmanje u jednoj godini. Program ispisuje dve liste:
jedna sadrži najpopularnija imena za dečake, a druga za djevojčice. Nijedan spisak ne sadrži ponovljena imena.
1. Čita svaki fajl
2. Nalazi u svakom fajlu najčešće ime te godine
3. Ispisuje dve liste
4. Nijedno ime se ne ponavlja
Samo sam hteo da pokažem zašto ljudi, koji poznaju Linux/Unix, ne žele tako lako da pređu na drugi sistem.
Skoro za svaki posao, Linux ima gomilu programa koji mogu da urade ceo ili deo posla...
[ a1234567 @ 28.03.2020. 10:28 ] @
Ma šalim se malo, da razvedrim dan od ovih korona vesti.
Čim naučim Python, prelazim na učenje Linuxa :)
[ djoka_l @ 28.03.2020. 11:01 ] @
Evo legende:
for VARIJABLA in LISTA ... do ... done : Bash for petlja
echo -e: ispisuje string na standardni izlaz i (-e) interpretira specijalne znake u stringu (\n novi red)
head -1 -q: ispisuje prvih nekoliko (-1 jednu) linija i ne ispisjue (-q) naziv fajla iz kojeg su te linije
awk '{print $1}': posebna priča koja treba da se nauči (a nauči se za 2-3 sata). Ovaj awk program za svaku liniju sa ulaza, ispisuje prvu reč na izlaz
sort -u: sortira ono što mu dođe na ulaz, a (-u) izbacuje duplikate (unique sort)
| : pipe - povezuje dve komande, tako što izlaz komande sa leve strane prosleđuje na ulaz komande sa desne strane
; : razdvaja dve komande u istoj linij.
IMEVARIJABLE, $IMEVARIJABLE : ime, odnosno vrednost varijable, u primeru g i $g. ${g} je isto što i $g ali se koristi u slučajevima kada postoje neki specijalni znaci u liniji, pa da se zna šta je varijabla. Recimo $g* nije baš jasno šta je, ali je ${g}* nedvosmisleno.
[ Branimir Maksimovic @ 28.03.2020. 11:20 ] @
Citat:
djoka_l:
Na mnogobrojne zahteve, evo kraće, sa for petljom
$ for g in 'Boys' 'Girls'; do echo -e "\n\n${g}:\n" ; head -1 -q BabyNames/*${g}*.txt | awk '{print $1}' | sort -u ; done
Boys:
David
Jacob
James
John
Michael
Robert
Girls:
Ashley
Emily
Emma
Isabella
Jennifer
Jessica
Linda
Lisa
Mary
Sophia
Da al ispisujes samo imena, to i klasicni program moze kratko...
[ djoka_l @ 28.03.2020. 11:30 ] @
Ma jeste, ali je poenta u 1-lineru
Svojevremeno, kada sam išao na intervencije kod korisnika, uvek se skupi po nekoliko ljudi iz IT-a da pohvataju sve šta kucam u terminalu, da bi kasnije mogli da analiziraju šta sam radio i iskoriste u svojim programima
Meni je bilo čudno što je uvek gužva oko mene, ali kad su mi rekli razlog, počeo sam sve da zapisujem u fajlove, da ljudi mogu da analiziraju na miru...
[ B3R1 @ 28.03.2020. 15:52 ] @
Citat:
a1234567:
Komplikovani ovi nested rečnici :)
Ali kad se kod izvrši, rečnik je još uvek prazan, {'Boys Names': {}}
Logicno da je prazno, jer program ne radi nista:
Code:
decaci = { 'Boys Names': {} }
for k1, v1 in decaci.items():
...
Recnik je prazan, pa for-petlja analizira taj prazan recnik i odmah zavrsava. Recnik treba inicijalizovati na pocetku, a puniti ga tokom ucitavanja linija iz fajla:
Code:
decaci = { 'Boys Names': {} }
for filename in glob.glob('*txt'):
lines = open(filename).readlines()
if 'Boys' in filename:
for line in lines:
name, broj = line.strip().split()
godina = filename[0:4]
if name not in decaci['Boys Names']:
decaci['Boys Names'][name] = {}
if godina not in decaci['Boys Names'][name]:
decaci['Boys Names'][name][godina] = broj
...
One promenljive k1, v1, k2, v2 itd. su ti nepotrebne, bas kao i funkcija keys(). Kada pretrazujes recnik 'dict' i kazes 'for element in dict:' podrazumeva se dict.keys(). Isto tako ako ispitujes da li je kljuc k u recniku dovoljno je da kazes 'if k in dict'.
Takodje, misli da ti je ovaj 'Boys Names' cist visak. Ako vec imas posebne recnike za decake i devojcice, nema svrhe da uvodis jos jedan nivo u strukturu recnika. Dovoljno je reci:
Code:
decaci = {}
for filename in glob.glob('*txt'):
lines = open(filename).readlines()
if 'Boys' in filename:
for line in lines:
name, broj = line.strip().split()
godina = filename[0:4]
if name not in decaci:
decaci[name] = {}
if godina not in decaci[name]:
decaci[name][godina] = broj
...
[ Branimir Maksimovic @ 28.03.2020. 17:53 ] @
A evo ga i Haskell (nije me mrzelo:)
Code:
import Data.List
import Data.List.Split
import System.Directory
import Data.Map.Strict
import Control.Monad
import Text.Printf
main = do
files <- listDirectory "BabyNames"
let maxs_girls = empty :: Map String [(Int,Int)]
maxs_boys = empty :: Map String [(Int,Int)]
(maxs_girls',maxs_boys') <- foldM (\gb filename -> do
cnt <- readFile $ "BabyNames/"++filename
let [year,girlsboys] = splitOn "_" filename
year' = read year
let (name,number) = Data.List.foldl (\max ln -> let
[name,number] = words ln
number' = read number
in if snd max < number'
then (name,number')
else max ) ("",0) $ lines cnt
return $ if girlsboys == "GirlsNames.txt"
then (insertWith (++) name [(year',number)] (fst gb), snd gb)
else (fst gb,insertWith (++) name [(year',number)] (snd gb))
) (maxs_girls,maxs_boys) files :: IO (Map String [(Int,Int)], Map String [(Int,Int)])
let a = foldlWithKey (\fv name list -> fv ++ (printf "%s\n" $ name ++ ":" ++ show (sort list))) "" maxs_girls'
let b = foldlWithKey (\fv name list -> fv ++ (printf "%s\n" $ name ++ ":" ++ show (sort list))) "" maxs_boys'
putStrLn $ "Girls\n" ++ a ++ "Boys\n" ++ b
Evo novog izazova u narednoj poruci i za tebe i za mene :)
[ a1234567 @ 29.03.2020. 17:06 ] @
Žurka za dečijim imenima se nastavlja.
Zadatak broj 32: Pronaći imena koja su rodno neutralna
Neka imena kao što su Ben, Jonathan i Andrew se obično koriste samo za dečake,
dok su Rebecca i Flora obično rezervisane za devojčice. No, ima imena
kao što su Chris i Alex, koja se mogu koristiti i kao muška i kao ženska.
Napiši program koji nalazi i prikazuje sva dečija imena koja su korišćena i za dečake
i za devojčice u godini koju unese korisnik. Program takođe treba da generiše
odgovarajuću poruku ukoliko u odabranoj godini nije bilo rodno neutralnih imena.
Takođe, prikaži odgovarajuću poruku ako nemaš podatke za unetu godinu.
Ja sam sklepao nešto ovako:
Code: import glob
spisak = open('c:/FAJLOVI/Python_School/Stephenson_ThePythonWorkbook/unisex.txt', 'w')
for filename in glob.glob('*txt'):
if 'Boys' in filename:
lines = open(filename).readlines()
for line in lines:
name = line.strip().split()[0]
godina = int(filename[0:4])
lista_m.append(name)
elif 'Girls' in filename:
lines = open(filename).readlines()
for line in lines:
name = line.strip().split()[0]
godina = int(filename[0:4])
lista_z.append(name)
a rečnik imena izgleda ovako, uz "mali" problem da se javljaju neka imena kojih nema u oba spiska za datu godinu (na primer Shannon), al nemam pojma zašto:
use std::io;
use std::fs::File;
use std::fs::read_dir;
use std::io::prelude::*;
use std::collections::BTreeMap;
use std::collections::BTreeSet;
fn main()->io::Result<()>{
let mut girls:BTreeMap<i32,BTreeSet<String> > = BTreeMap::new();
let mut boys:BTreeMap<i32,BTreeSet<String> > = BTreeMap::new();
let mut common:BTreeMap<i32,BTreeSet<String> > = BTreeMap::new();
let mut buf = String::new();
if let Ok(dir) = read_dir("BabyNames") {
for file in dir {
let file = file?;
let mut f = File::open(file.path())?;
buf.clear();
let _ = f.read_to_string(&mut buf);
let mut tmp_set = BTreeSet::new();
for line in buf.lines() {
let two:Vec<_> = line.split_whitespace().collect();
tmp_set.insert(two[0].to_string());
}
let path = file.path();
let fname = path.to_str().unwrap().to_string();
let it = fname.split('_').collect::<Vec<_>>();
let it1 = it[0].split('/').collect::<Vec<_>>();
let year = it1[1].parse::<i32>().unwrap();
let _ = if it[1] == "GirlsNames.txt" {
girls.entry(year).or_insert(tmp_set)
} else {
boys.entry(year).or_insert(tmp_set)
};
}
} else {
println!("Not in directory above BabyNames...");
}
for ((y,g),(_,b)) in girls.iter().zip(boys) {
for i in g.intersection(&b) {
let r = common.entry(*y).or_insert(BTreeSet::new());
(*r).insert(i.clone());
}
}
for i in common {
println!("{:?}",i);
}
Ok(())
}
files =sorted(glob.glob('*txt'))
names ={} for file1, file2 inlist(zip(files, files[1:]))[::2]: withopen(file1)as boys_file,open(file2)as girls_file:
boys_names =[name.split()[0]for name in boys_file]
girls_names =[name.split()[0]for name in girls_file]
name_exist_in_both_lists =[name for name in boys_names if name in girls_names]
year =int(file1[:4]) if name_exist_in_both_lists:
names[year]=name_exist_in_both_lists
for year in names: print(year,', '.join(name for name in names[year]))
Izlaz:
1900 Willie, Jessie 1901 Willie, Jessie 1902 Willie, Jessie 1903 Willie, Jessie 1904 Willie, Jessie 1905 Willie, Jessie 1906 Willie, Jessie 1907 Willie, Jessie 1908 Willie, Jessie 1909 Willie, Jessie 1910 Willie, Jessie 1911 Willie, Jessie 1912 Willie 1913 Willie 1914 Willie 1915 Willie 1916 Willie 1917 Willie 1918 Willie 1919 Willie 1920 Willie 1921 Willie 1922 Willie 1923 Willie 1924 Willie 1925 Willie 1926 Willie 1927 Willie 1928 Willie 1929 Willie 1930 Willie 1931 Willie 1932 Willie 1933 Willie 1935 Willie 1954 Terry 1955 Terry, Kim 1956 Terry 1957 Terry 1958 Terry 1959 Terry 1966 Tracy 1967 Tracy 1968 Kelly 1972 Shannon 1973 Shannon 1974 Jamie 1975 Jamie 1976 Jamie, Shannon 1977 Jamie 1978 Jamie 1979 Jamie 1986 Casey 1987 Casey 1988 Casey 1989 Jordan, Taylor 1990 Jordan, Taylor 1991 Jordan, Taylor 1992 Jordan, Taylor 1993 Jordan, Taylor 1994 Jordan, Taylor 1995 Jordan, Taylor 1996 Jordan, Taylor 1997 Jordan, Taylor 1998 Jordan 1999 Jordan 2000 Jordan 2001 Jordan 2002 Jordan, Riley 2003 Jordan 2004 Jordan 2005 Jordan 2006 Jordan 2007 Jordan
[ B3R1 @ 30.03.2020. 16:32 ] @
Citat:
a1234567:
"mali" problem da se javljaju neka imena kojih nema u oba spiska za datu godinu (na primer Shannon), al nemam pojma zašto:
Napravio si dve greske. Prva je klasican problem "kumulativnog trpanja" podataka u niz. Problem je sto promenljive lista_m, lista_z i lista_unikat praznis samo na pocetku. Svaki sledeci fajl koji otvoris ih "nasledjuje" u potpunosti i kumulativno dodaje imena u njih. Otuda ti se npr. Shannon, koji se javlja prvi put 1972. godine provlaci i dalje kroz sve naredne godine. Problem zapravo pocinje jos od 1954, gde je Leslie nasledjen(a) iz 1953. i nadalje se provlaci kroz naredne godine. Ok, ovo nije tesko resiti, inicijalizaciju treba ukloniti s vrha i staviti iza linije
lines = open(filename).readlines()
Medjutim, tu postoji jos jedan problem: glob.glob() i os.listdir() vracaju listu fajlova sortiranu po nekoj internoj logici operativnog sistema. Dok Windows sortira fajlove po imenima, Unix/Linux vraca totalno nesortirane fajlove. Znaci, trebalo bi dodati:
for filename in sorted(glob.glob('*txt')):
Na kraju, lepo je sto si iskoristio skup kao strukturu podataka, jer ti to efikasno resava 'uniq' funkciju. Ali sta ce ti onda liste koje pretvaras u skup? Zasto odmah ne koristis skup.add() za dodavanje elementa u skup? Inace, add() funkcija lepo ignorise elemente koji vec postoje u skupu, odnosno dodaje element samo ako vec nije u skupu. Takodje, s obzirom da svaka godina ima muska i zenska imena, nebitno je ispitivati da li je 'Boys' ili 'Girls' u imenu fajla i beleziti posebno muska i zenska imena.
Recimo nesto ovako (nisam testirao, moguce je da sam napravio neki bag, ali ideja je tu):
Code (python):
importglob
spisak =open('c:/FAJLOVI/Python_School/Stephenson_ThePythonWorkbook/unisex.txt','w')
imena ={}
for filename insorted(glob.glob('*txt')):
godina =int(filename[0:4])
lines =open(filename).readlines()
lista=set()# Lista imena u fajlu, pol je nebitan for line in lines:
name = line.strip().split()[0]
lista.add(name) if(godina notin imena): # U prvom fajlu iz godine X hashtable imena je prazna
imena[godina]= lista else: # U drugom fajlu iz godine X trazimo uniq(m,f)
imena[godina]= imena[godina].intersection(lista)
spisak.write(str(imena) + '\n')
spisak.close()
[ B3R1 @ 30.03.2020. 16:50 ] @
A za to vreme u Unix shellu, one-liner:
$ cd BabyNames; grep . * | sed -e 's/ .*$//g' -e 's/_.*:/:/g' | sort | uniq -d
Zadatak broj 33: Kreiranje registra imena u Excelu
Evo mog predloga za novi zadatak, prilicno lak. Oslanja se na iste podatke kao prethodna dva, a sluzi za snalazenje s raspolozivim Python modulima. Od fajlova sa imenima treba napraviti program koji generise tabelu u Excelu u sledecem formatu:
+========+========+======+======+======+
| Name | Gender | 2020 | 2019 | 2018 | ...
+========+========+======+======+======+
| Aice | F | 234 | 234 | 234 |
| Anna | F | 13 | 13 | 13 |
| Bob | M | 1234 | 1234 | 1234 |
Imena su u prvoj koloni (A) koja treba sortirati. Pol je u drugoj koloni (B) i moze da bude 'M' ili 'F'. U naredne kolone upisati frekvenciju pojavljivanja imena. Godine sortirati u opadajucem redosledu - kolona C je posldnja godina, kolona D pretposlednja itd. kao u gornjem primeru.
Vrstu koja predstavlja zaglavlje (Name / Gender / godine ...) obojiti u svetlo sivu boju.
Svaku sledecu vrstu obojiti u svetlo plavu ako su u pitanju decaci, a svetlo roze ako su u pitanju devojcice.
Program mora da generise Excel fajl koji se direktno ucitava takav kakav je, formatiran i obojen kao sto je zadato.
Kako poceti? Google => generate excel file from python ...
[ a1234567 @ 31.03.2020. 03:34 ] @
Citat:
Panta_:
Code (python):
importglob
files =sorted(glob.glob('*txt'))
names ={} for file1, file2 inlist(zip(files, files[1:]))[::2]: withopen(file1)as boys_file,open(file2)as girls_file:
boys_names =[name.split()[0]for name in boys_file]
girls_names =[name.split()[0]for name in girls_file]
name_exist_in_both_lists =[name for name in boys_names if name in girls_names]
year =int(file1[:4]) if name_exist_in_both_lists:
names[year]=name_exist_in_both_lists
for year in names: print(year,', '.join(name for name in names[year]))
Panto, šta ti je ovo? for file1, file2 in list(zip(files, files[1:]))[::2]
Šta su ti ovi indeksi [1:] i [::2]?
[ a1234567 @ 31.03.2020. 04:33 ] @
Citat:
B3R1:
Citat:
a1234567:
"mali" problem da se javljaju neka imena kojih nema u oba spiska za datu godinu (na primer Shannon), al nemam pojma zašto:
Napravio si dve greske. Prva je klasican problem "kumulativnog trpanja" podataka u niz. Problem je sto promenljive lista_m, lista_z i lista_unikat praznis samo na pocetku. Svaki sledeci fajl koji otvoris ih "nasledjuje" u potpunosti i kumulativno dodaje imena u njih. Otuda ti se npr. Shannon, koji se javlja prvi put 1972. godine provlaci i dalje kroz sve naredne godine. Problem zapravo pocinje jos od 1954, gde je Leslie nasledjen(a) iz 1953. i nadalje se provlaci kroz naredne godine. Ok, ovo nije tesko resiti, inicijalizaciju treba ukloniti s vrha i staviti iza linije
lines = open(filename).readlines()
Medjutim, tu postoji jos jedan problem: glob.glob() i os.listdir() vracaju listu fajlova sortiranu po nekoj internoj logici operativnog sistema. Dok Windows sortira fajlove po imenima, Unix/Linux vraca totalno nesortirane fajlove. Znaci, trebalo bi dodati:
for filename in sorted(glob.glob('*txt')):
Na kraju, lepo je sto si iskoristio skup kao strukturu podataka, jer ti to efikasno resava 'uniq' funkciju. Ali sta ce ti onda liste koje pretvaras u skup? Zasto odmah ne koristis skup.add() za dodavanje elementa u skup? Inace, add() funkcija lepo ignorise elemente koji vec postoje u skupu, odnosno dodaje element samo ako vec nije u skupu. Takodje, s obzirom da svaka godina ima muska i zenska imena, nebitno je ispitivati da li je 'Boys' ili 'Girls' u imenu fajla i beleziti posebno muska i zenska imena.
Recimo nesto ovako (nisam testirao, moguce je da sam napravio neki bag, ali ideja je tu):
Code (python):
importglob
spisak =open('c:/FAJLOVI/Python_School/Stephenson_ThePythonWorkbook/unisex.txt','w')
imena ={}
for filename insorted(glob.glob('*txt')):
godina =int(filename[0:4])
lines =open(filename).readlines()
lista=set()# Lista imena u fajlu, pol je nebitan for line in lines:
name = line.strip().split()[0]
lista.add(name) if(godina notin imena): # U prvom fajlu iz godine X hashtable imena je prazna
imena[godina]= lista else: # U drugom fajlu iz godine X trazimo uniq(m,f)
imena[godina]= imena[godina].intersection(lista)
spisak.write(str(imena) + '\n')
spisak.close()
Da, kad prebacim liste u petlju, radi.
Meni je bila ideja da pokupim sva muška imena u jednu listu, sva ženska u drugu i onda nađem presek te dve liste.
Kod tvog koda mi nisu baš najjasnije neke stvari. Evo kako ga ja čitam:
Code: for filename in sorted(glob.glob('*txt')): # OK, sortiranje fajlova pre otvaranja, da bi išlo po godinama, mada kod men u WIn to je već sortirano.
godina = int(filename[0:4]) # beleži prva 4 karaktera iz imena fajla, što je godina
lines = open(filename).readlines() # učitava u memoriju ceo tekst fajla
lista= set() # tip liste je skup, što znači nema ponavljanja
for line in lines:
name = line.strip().split()[0] # promenljiva name je indeks[0] u listi, npr. ['James', 32340]
lista.add(name) # dodaje to ime u listu
OVDE IMAM PROBLEM: kad dovde izvršim program za jednu godinu sa:
for filename in sorted(glob.glob('1990*txt')):)
u listi imam samo ženska imena:
Šta se dešava sa muškim imenima? Koji je smisao ove liste?
I onda mi ni ovo što sledi nije jasno:
if (godina not in imena): # U prvom fajlu iz godine X hashtable imena je prazna
imena[godina] = lista
else: # U drugom fajlu iz godine X trazimo uniq(m,f)
imena[godina] = imena[godina].intersection(lista)
[ a1234567 @ 31.03.2020. 04:38 ] @
Citat:
B3R1: Zadatak broj 33: Kreiranje registra imena u Excelu
Evo mog predloga za novi zadatak, prilicno lak. Oslanja se na iste podatke kao prethodna dva, a sluzi za snalazenje s raspolozivim Python modulima. Od fajlova sa imenima treba napraviti program koji generise tabelu u Excelu u sledecem formatu:
+========+========+======+======+======+
| Name | Gender | 2020 | 2019 | 2018 | ...
+========+========+======+======+======+
| Aice | F | 234 | 234 | 234 |
| Anna | F | 13 | 13 | 13 |
| Bob | M | 1234 | 1234 | 1234 |
Eto nama zabave u karantinu :)))
Ću da probam, pa javljam rezulate...
[ Branimir Maksimovic @ 31.03.2020. 05:53 ] @
Hehe, Beri mi zapaprio, Rust i Haskell nemaju podrsku za excel out of box ;)
Ali ima eksternih biblioteka :P
edit:
nasao za Haskell, za Rust ima samo reader :(
[Ovu poruku je menjao Branimir Maksimovic dana 31.03.2020. u 07:15 GMT+1]
[ Panta_ @ 31.03.2020. 05:55 ] @
Citat:
Panto, šta ti je ovo?
for file1, file2 in list(zip(files, files[1:]))[::2]
Šta su ti ovi indeksi [1:] i [::2]?
To je list slicing, valjda si do sada to prošao. Evo primer:
Code: l = [1, 2, 3, 4, 5, 6]
l[1:] # od indeksa 1 do kraja, u Pythonu indeksiranje pocinje od 0
[2, 3, 4, 5, 6]
Ma znam slajsing, to sam odavno savladao.
Nego mi nije jasna njegova uloga u tvom kodu.
Šta ti znači da čitaš naziv fajla od indeksa [1],
pa svako drugo slovo!?
Al sad vidim da ima nekog smisla.
[ B3R1 @ 31.03.2020. 16:24 ] @
Evo, sad sam ubacio onaj kod koji sam napisao i radi ispravno.
Citat:
a1234567:
Code:
lista.add(name) # dodaje to ime u listu
OVDE IMAM PROBLEM: kad dovde izvršim program za jednu godinu sa:
for filename in sorted(glob.glob('1990*txt')):)
u listi imam samo ženska imena:
Zato sto si ga izvrsio "dovde". Program se izvrsava od pocetka do kraja. :-) Kada izvrsavas liniju po liniju verovatno dodjes do ove tacke:
Code (python):
>>>importglob >>> >>> imena ={} >>> >>>for filename insorted(glob.glob('1910*txt')):
... godina=int(filename[0:4])
... lines=open(filename).readlines()
... lista=set()# Lista imena u fajlu, pol je nebitan
... for line in lines:
... name= line.strip().split()[0]
... lista.add(name)
...
Verovatno si ovde pritisnuo enter, dok je kursor stajao tik uz ove tri tackice, zar ne? Ako si to uradio python je izvrsio spoljasnju for petlju (for filename ...) i u listi si dobio zenska imena, jer su muska ucitana u prvom prolazu petlje. Ako hoces da to proveris, uradi ovo (uh, sad zvucim kao ovi nasi novinski portali - "evo sta vam treba za ovo" ili "ovo vam treba za evo").
Code (python):
>>>importglob >>> >>> imena ={} >>> >>>for filename insorted(glob.glob('1910*txt')):
... print"\nFILE: " + filename
... godina=int(filename[0:4])
... lines=open(filename).readlines()
... lista=set()# Lista imena u fajlu, pol je nebitan
... for line in lines:
... name= line.strip().split()[0]
... lista.add(name)
... printstr(lista)
...
Kao sto vidis, citaju se oba fajla, jedan za drugim.
Citat:
I onda mi ni ovo što sledi nije jasno:
Code:
if (godina not in imena): # U prvom fajlu iz godine X hashtable imena je prazna
imena[godina] = lista
else: # U drugom fajlu iz godine X trazimo uniq(m,f)
imena[godina] = imena[godina].intersection(lista)
Hash tabela imena se sastoji od kljuceva koji su godine, a vrednosti su skupovi imena:
{1910: set(['Jessie', 'Willie'])}
Za svaku godinu imas dva fajla - muska i zenska imena. Petlja "for filename in ..." prolazi najpre fajl sa muskim imenima, tu se promenljiva lista napuni imenima iz fajla. Potom ispitujemo da li je godina vec prisutna u hash tabeli (recniku). Ako nije dodajemo je u recnik, a vrednost ce biti skup imena (u ovom slucaju muskih). Potom se petlja "for filename ..." nastavlja citanjem fajla sa zenskim imenima gde se formira nova lista. Kada ponovo izvrsis deo koda "if godina not in imena" - godina ce vec biti definisana u tabeli, pa se izvrsava else, koji menja vrednost - postavlja tako da bude presek skupa muskih imena (trenutna vrednost imena[godina]) i zenskih imena (koja su trenutno u skupu 'lista'). Rezultat za 1910. godinu je:
{1910: set(['Jessie', 'Willie'])}
[ Panta_ @ 31.03.2020. 16:29 ] @
Citat:
Nego mi nije jasna njegova uloga u tvom kodu.
Šta ti znači da čitaš naziv fajla od indeksa [1],
pa svako drugo slovo!?
Al sad vidim da ima nekog smisla.
Da čita iz oba fajla za istu godinu kako bi izdvojio ista imena ukoliko postoje u oba fajla.
Što se tiče Excel tabele:
Code (python):
importglob import xlsxwriter
data ={}
files =sorted(glob.glob('*.txt'), reverse=True)
for filename in files:
year =int(filename[:4]) if'Boys'in filename:
gender ='M' else:
gender ='F'
lines =open(filename).readlines() for line in lines:
name, num = line.strip().split()
name_num =int(num) if name notin data:
data[name]=[gender,(year, name_num)] else:
data[name].append((year, name_num))
book = xlsxwriter.Workbook('BabyNames.xlsx')
sheet = book.add_worksheet("My sheet")
hc = book.add_format({'bg_color': '#e0e0e0'}) gc= book.add_format({'bg_color': '#f9c7ff'})
bc = book.add_format({'bg_color': '#b8bbff'})
sheet.set_row(0, cell_format=hc)
sheet.write(0,0,'Name')
sheet.write(0,1,'Gender')
years =sorted(set([i[:4]for i in files]), reverse=True)
col=2
years_cols ={} for i in years:
sheet.write(0, col, i)
years_cols[int(i)]=col
col+=1
row=1
col=0 for name insorted(data): if data[name][0]=='F':
sheet.set_row(row, cell_format=gc) else:
sheet.set_row(row, cell_format=bc)
sheet.write(row, col, name)
col+=1
sheet.write(row, col, data[name][0]) for i in data[name][1:]:
sheet.write(row, years_cols[i[0]], i[1])
row+=1
col=0
book.close()
Ne radi sa Google docs, jednostavno pomeri sve ćelije ulevo, ako neko želi online da testira, može na https://sheet.zoho.com.
Takođe mora da se instalira xlsxwriter: pip install xlsxwriter
[ B3R1 @ 31.03.2020. 16:32 ] @
Citat:
Branimir Maksimovic:
Hehe, Beri mi zapaprio, Rust i Haskell nemaju podrsku za excel out of box ;)
Ali ima eksternih biblioteka :P
Pa ni Python nema resenje out of the box, vec se koristi modul za to. Zapravo postoje dva, moguce i vise, ali ja znam za jedan koji radi i citanje i pisanje xlsx fajlova. Ideja zadatka je naci modul koji to radi, procitati dokumentaciju, shvatiti kako radi i iskoristiti ga. Dokumentacija sadrzi i gotov primer koji moze da se kopira i iskoristi.
Sad videh da je Panta iskoristio xslxwriter. Meni se vise svidja openpyxl.
Inace, Pandas moze da cita Excel (nisam siguran da li ima podrsku i za generisanje Excel fajlova).
[ Branimir Maksimovic @ 31.03.2020. 17:12 ] @
Znas kako da nadjem C biblioteku koja to radi pa da vrapujem, ne da mi se pored svega posla koji me ceka :P
E sad e sad, wrapovati, wrapovati :p
mislim ne mora da bude user friendly ;)
[Ovu poruku je menjao Branimir Maksimovic dana 31.03.2020. u 22:58 GMT+1]
[ a1234567 @ 01.04.2020. 02:06 ] @
Citat:
B3R1:
Citat:
Branimir Maksimovic:
Hehe, Beri mi zapaprio, Rust i Haskell nemaju podrsku za excel out of box ;)
Ali ima eksternih biblioteka :P
Pa ni Python nema resenje out of the box, vec se koristi modul za to. Zapravo postoje dva, moguce i vise, ali ja znam za jedan koji radi i citanje i pisanje xlsx fajlova. Ideja zadatka je naci modul koji to radi, procitati dokumentaciju, shvatiti kako radi i iskoristiti ga. Dokumentacija sadrzi i gotov primer koji moze da se kopira i iskoristi.
Sad videh da je Panta iskoristio xslxwriter. Meni se vise svidja openpyxl.
Inace, Pandas moze da cita Excel (nisam siguran da li ima podrsku i za generisanje Excel fajlova).
Koji onda modul da koristim?
Ja sam već instalirao xlsxwriter modul i gledam dokumentaciju.
Napravio sam do pola, ali imam posle stanovitih problema. Što je i za očekivati :)
Ako ih danas ne rešim, postaviću to koliko sam uradio.
[ Panta_ @ 01.04.2020. 06:37 ] @
Citat:
Koji onda modul da koristim?
Koji god želiš (openpyxl, xslxwriter, pandas).
Inače, niko nije primetio da sam izostavio (zaboravio) ova zajednička imena za devojčice i dečake Šanon, Džesi, Džordan, Vili, itd. Evo jednostavne ispravke za prethodni kod:
Code (python):
importglob import xlsxwriter
data ={}
files =sorted(glob.glob('*.txt'), reverse=True)
for filename in files:
year =int(filename[:4]) if'Boys'in filename:
gender ='M' else:
gender ='F'
lines =open(filename).readlines() for line in lines:
name, name_num = line.strip().split() if name in data and gender != data[name][0]: if name+'_'notin data:
data[name+'_']=[gender,(year, name_num)] else:
data[name+'_'].append((year, name_num)) elif name notin data:
data[name]=[gender,(year, name_num)] else:
data[name].append((year, name_num))
book = xlsxwriter.Workbook('/tmp/BabyNames.xlsx')
sheet = book.add_worksheet("My sheet")
hc = book.add_format({'bg_color': '#e0e0e0'}) gc= book.add_format({'bg_color': '#f9c7ff'})
bc = book.add_format({'bg_color': '#b8bbff'})
sheet.set_row(0, cell_format=hc)
sheet.write(0,0,'Name')
sheet.write(0,1,'Gender')
years =sorted(set([i[:4]for i in files]), reverse=True)
col=2
years_cols ={} for i in years:
sheet.write(0, col, i)
years_cols[int(i)]=col
col+=1
row=1
col=0 for name insorted(data): if data[name][0]=='F':
sheet.set_row(row, cell_format=gc) else:
sheet.set_row(row, cell_format=bc) if'_'in name:
new_name = name.replace('_','') else:
new_name = name
sheet.write(row, col, new_name)
col+=1
sheet.write(row, col, data[name][0]) for i in data[name][1:]:
sheet.write(row, years_cols[i[0]], i[1])
row+=1
col=0
book.close()
Mislim da su sada tu sva imena.
[ Branimir Maksimovic @ 01.04.2020. 07:21 ] @
Vidim da xlsxwriter ima defineove za boje? Jel mora bas da u hexa obliku stavljas boje zato sto to nisu definisali kada su wrappovali bilioteku?
[ Panta_ @ 01.04.2020. 08:23 ] @
Može i sa color name, ali mi je ovako bilo lakše da u color picker izaberem boje nego npr. lightblue, lightštaveć.
Heh, Panta haker ;)
Nego smorno mi da pravim projekt uvlacim eksterni lib, podesavam build skripte ;)
Da je bar to neko uradio za mene (Rust) pa okacio kao za Python :P
Ipak ovo treba da bude laganica za opustanje ...
[ B3R1 @ 01.04.2020. 09:36 ] @
Citat:
a1234567:
Koji onda modul da koristim?
Svejedno je. Zapravo, princip kod svih je slican i polazi od same strukture Excel dokumenta, koji se sastoji od radne sveske (workbook) i listova (sheets). Svaki od njih mora da:
* Kreira workbook
* Kreira worksheet
* Za svako polje postavlja boju pozadine, boju slova i ostale atribute i upisuje vrednost.
* Koordinate se odredjuju bilo numericki (npr. (0,0) = prvo polje levo gore) ili u Excel notaciji (npr. A1), zavisno od modula (sto se moze procitati u dokumentaciji).
[ a1234567 @ 02.04.2020. 12:17 ] @
Uzeo sam samo dve prve godine za test i to tek prvih 7-8 imena.
No, svejedno, upletoh se ko pile u kučinu...
row = 0
col = 2
files = sorted(glob.glob('*txt'))
for file1, file2 in list(zip(files, files[1:]))[::2]:
worksheet.write(row, col, file1[0:4]) #upisuje godine
col += 1
col = 0
row = 1
it = iter(files)
for chunk in zip(it, it):
for filename in list(chunk):
if 'Boys' in filename:
lines = open(filename).readlines()
for item in lines:
name = item.strip().split()[0]
worksheet.write(row, col, name) # upisuje imena
worksheet.write(row, col + 1, 'M') # upisuje pol
row += 1
else:
lines = open(filename).readlines()
for item in lines:
name = item.strip().split()[0]
worksheet.write(row, col, name)
worksheet.write(row, col + 1, 'F')
row += 1
col = 2
row = 1
it = iter(files)
for chunk in zip(it, it):
for txt in list(chunk):
lines = open(txt).readlines()
for item in lines:
broj = item.strip().split()[1]
worksheet.write(row, col, broj) # upisuje brojeve
row += 1
col += 1
col = 1
row = 1
for filename in files:
if 'Boys' in filename:
worksheet.write(row, col, 'M')
row += 1
else:
worksheet.write(row, col, 'F')
row += 1
workbook.close()
Imam problem kako da ista imena iz naredne godine na upisujem iznova, već samo brojeve za njih.
A ovo je šta trenutno dobijam
[ a1234567 @ 02.04.2020. 13:01 ] @
Sad sam pogledao Pantino rešenje, pa vidim da on prvo pravi rečnik, a onda upisuje u tabelu.
A ja krenuo direkt, da ne dangubim
[ Branimir Maksimovic @ 04.04.2020. 17:34 ] @
nije me ipak mrzelo ali nisam pravio posebnu biblioteku nego samo sta koristim.
Potrebno je imati instaliran libxlsxwiter.
use std::io;
use std::fs::File;
use std::fs::read_dir;
use std::io::prelude::*;
use std::collections::BTreeMap;
type map_t = BTreeMap<i32,i32>;
fn main()->io::Result<()>{
let mut common:BTreeMap<String,Vec<(char,map_t)>> = BTreeMap::new();
let mut buf = String::new();
if let Ok(dir) = read_dir("BabyNames") {
for file in dir {
let file = file?;
let mut f = File::open(file.path())?;
let path = file.path();
let fname = path.to_str().unwrap().to_string();
let it = fname.split('_').collect::<Vec<_>>();
let it1 = it[0].split('/').collect::<Vec<_>>();
let year = it1[1].parse::<i32>().unwrap();
let c = if it[1] == "GirlsNames.txt" {
'F'
} else {
'M'
};
buf.clear();
let _ = f.read_to_string(&mut buf);
for line in buf.lines() {
let two:Vec<_> = line.split_whitespace().collect();
let r = common.entry(two[0].to_string()).or_insert(vec!{(c,map_t::new())});
(*r).last_mut().unwrap().1.insert(year,two[1].parse::<i32>().unwrap());
}
}
} else {
println!("Not in directory above BabyNames...");
}
let wkbk = lxw_workbook::new("example.xlsx");
let wksht = wkbk.add_worksheet("Names");
let hc = wkbk.add_format();
hc.set_bg_color(0xe0e0e0);
let gc = wkbk.add_format();
gc.set_bg_color(0xf9c7ff);
let bc = wkbk.add_format();
bc.set_bg_color(0xb8bbff);
let _ = wksht.write_string(0,0, "Name",hc.clone());
let _ = wksht.write_string(0,1, "Gender",hc.clone());
for (ord,(name,pair)) in common.iter().enumerate() {
for (gender,map) in pair.iter() {
for (ord1,(year,value)) in map.iter().rev().enumerate() {
let _ = wksht.write_string(0,ord1 as u16+2,year.to_string().as_str(),hc.clone());
let clr;
if *gender == 'F' {
clr = gc.clone();
let _ = wksht.write_string(ord as u32+1,0,name,gc.clone());
let _ = wksht.write_string(ord as u32+1,1,"F",gc.clone());
} else {
clr = bc.clone();
let _ = wksht.write_string(ord as u32+1,0,name,bc.clone());
let _ = wksht.write_string(ord as u32+1,1,"M",bc.clone());
}
let _ = wksht.write_string(ord as u32+1,ord1 as u16+2, value.to_string().as_str(),clr);
}
}
}
Ok(())
}
[ Branimir Maksimovic @ 04.04.2020. 20:25 ] @
Jedan propust, imena nisam rasporedio po datumima, nego su isla u opadajucem obliku bez obzira na datum,
ispravka:
use std::io;
use std::fs::File;
use std::fs::read_dir;
use std::io::prelude::*;
use std::collections::BTreeMap;
type map_t = BTreeMap<i32,i32>;
fn main()->io::Result<()>{
let mut common:BTreeMap<String,Vec<(char,map_t)>> = BTreeMap::new();
let mut buf = String::new();
if let Ok(dir) = read_dir("BabyNames") {
for file in dir {
let file = file?;
let mut f = File::open(file.path())?;
let path = file.path();
let fname = path.to_str().unwrap().to_string();
let it = fname.split('_').collect::<Vec<_>>();
let it1 = it[0].split('/').collect::<Vec<_>>();
let year = it1[1].parse::<i32>().unwrap();
let c = if it[1] == "GirlsNames.txt" {
'F'
} else {
'M'
};
buf.clear();
let _ = f.read_to_string(&mut buf);
for line in buf.lines() {
let two:Vec<_> = line.split_whitespace().collect();
let r = common.entry(two[0].to_string()).or_insert(vec!{(c,map_t::new())});
(*r).last_mut().unwrap().1.insert(year,two[1].parse::<i32>().unwrap());
}
}
} else {
println!("Not in directory above BabyNames...");
}
let wkbk = lxw_workbook::new("example.xlsx");
let wksht = wkbk.add_worksheet("Names");
let hc = wkbk.add_format();
hc.set_bg_color(0xe0e0e0);
let gc = wkbk.add_format();
gc.set_bg_color(0xf9c7ff);
let bc = wkbk.add_format();
bc.set_bg_color(0xb8bbff);
let mut years = BTreeMap::new();
for (i,j) in (1900..=2012).rev().enumerate() {
years.insert(j,i);
let _ = wksht.write_string(0,i as u16+2,j.to_string().as_str(),hc.clone());
}
let _ = wksht.write_string(0,0, "Name",hc.clone());
let _ = wksht.write_string(0,1, "Gender",hc.clone());
for (ord,(name,pair)) in common.iter().enumerate() {
for (gender,map) in pair.iter() {
for (year,value) in map.iter().rev() {
let clr;
if *gender == 'F' {
clr = gc.clone();
let _ = wksht.write_string(ord as u32+1,0,name,gc.clone());
let _ = wksht.write_string(ord as u32+1,1,"F",gc.clone());
} else {
clr = bc.clone();
let _ = wksht.write_string(ord as u32+1,0,name,bc.clone());
let _ = wksht.write_string(ord as u32+1,1,"M",bc.clone());
}
let _ = wksht.write_string(ord as u32+1,years[&*year]as u16+2,value.to_string().as_str(),clr);
}
}
}
Ok(())
}
[ Panta_ @ 06.04.2020. 07:42 ] @
Citat:
Jedan propust, imena nisam rasporedio po datumima
Zaboravio si i na zajednička imena za devojčice i dečake, tako da recimo imaš Jordan samo za devojčice.
[ Branimir Maksimovic @ 06.04.2020. 16:43 ] @
A ne, ispisujem sva imena, nema nikakve obrade. To je namerno.
[ a1234567 @ 11.04.2020. 17:38 ] @
Stiže zadatak 33.
Kopiram iz knjige, da ne prevodim...
Spell Checker
A spell checker can be a helpful tool for people who struggle to spell words correctly.
In this exercise, you will write a program that reads a file and displays all of the words
in it that are misspelled. Misspelled words will be identified by checking each word
in the file against a list of known words. Any words in the user’s file that do not
appear in the list of known words will be reported as spelling mistakes.
The user will provide the name of the file to check for spelling mistakes as a
command line argument. Your program should display an appropriate error message
if the command line argument is missing. An error message should also be displayed
if your program is unable to open the user’s file. Make solution to this exercise
so that words followed by a comma, period or other punctuation mark are not reported
as spelling mistakes. Ignore the capitalization of the words when checking their spelling.
Hint: While you could load all of the English words from the words data set
into a list, searching a list is slow if you use Python’s in operator. It is much
faster to check if a key is present in a dictionary, or if a value is present in a
set. If you use a dictionary, the words will be the keys. The values can be the
integer 0 (or any other value) because the values will never be used.
[ a1234567 @ 11.04.2020. 17:40 ] @
Ovako nešto sa pokušao:
Code: import argparse
import re
import string
import sys
wordlist_recnik = {}
# Otvori listu engleskih reči u odnosu na koje će dati tekst biti proveravan.
# Napravi rečnik u kojem je svaka od reči key. Value je 0, jer nikada neće biti korišćeno.
with open('c:/FAJLOVI/Python_School/Stephenson_ThePythonWorkbook/wordlist.txt', "r", encoding='utf-8') as recnik:
reci = recnik.readlines()
reci[:] = [line.rstrip('\n') for line in reci]
for rec in reci:
wordlist_recnik[rec] = 0
greske = []
# Provera da su dati svi argumenti.
if len(sys.argv) != 2:
print("Unesi ime fajla za slovnu analizu. Npr. >> 167.py fajl.txt")
quit()
try:
with open(sys.argv[1], 'r', encoding='utf-8') as tekst:
text = tekst.read()
except:
print("Dogodila se greška pri učitavanju fajla.")
quit()
print(text)
def words(text):
samo_reci = re.sub(r'[^\w\s]','',text)
lista = samo_reci.lower().split()
for word in lista:
if word not in wordlist_recnik:
greske.append(word)
print()
print('Ovo su reči koje treba popraviti:')
print(*greske, sep='\n')
return
words(text)
[ Branimir Maksimovic @ 11.04.2020. 17:46 ] @
Citat:
a1234567:
Stiže zadatak 33.
Kopiram iz knjige, da ne prevodim...
Spell Checker
A spell checker can be a helpful tool for people who struggle to spell words correctly.
In this exercise, you will write a program that reads a file and displays all of the words
in it that are misspelled. Misspelled words will be identified by checking each word
in the file against a list of known words. Any words in the user’s file that do not
appear in the list of known words will be reported as spelling mistakes.
The user will provide the name of the file to check for spelling mistakes as a
command line argument. Your program should display an appropriate error message
if the command line argument is missing. An error message should also be displayed
if your program is unable to open the user’s file. Make solution to this exercise
so that words followed by a comma, period or other punctuation mark are not reported
as spelling mistakes. Ignore the capitalization of the words when checking their spelling.
Hint: While you could load all of the English words from the words data set
into a list, searching a list is slow if you use Python’s in operator. It is much
faster to check if a key is present in a dictionary, or if a value is present in a
set. If you use a dictionary, the words will be the keys. The values can be the
integer 0 (or any other value) because the values will never be used.
Mozda bi bilo bolje da se zada i 33', tj za ulaznu rec naci najblize korektne alternative.
To ako hoces da trazis posao u guglu :P
[ a1234567 @ 11.04.2020. 17:54 ] @
Zvali su me, al sam im rekao da nemam vremena.
Učim python na elite forumu
[ a1234567 @ 12.04.2020. 04:15 ] @
Jedno pitanjce.
Nešto sam eksperimentisao, pa mi nije jasan rezultat.
Code: x = ['Ovo ', 'je', ' test']
for i in x:
if i[0] or i[-1] == ' ':
print(i)
Ovo
je
test
Kako to da se 'je' nalazi u ispisu kad nema razmak!?
[ Panta_ @ 12.04.2020. 05:14 ] @
Zato što ne proverava da li ima razmak, treba:
Code: if i[0] == ' ' or i[-1] == ' '
ili
if ' ' in i
[ a1234567 @ 12.04.2020. 07:55 ] @
Aha, mora odvojeno. Dobro.
A ja hteo da se ugledam na tebe, pa da sve smlatim ujedno, kad ono neće moći :)))
Dalje, napisati program koji podrazumevano (ako je pokrenut bez argumenata)
ispisuje podatke sortirane po broju potvrđenih slučajeva od najvišeg, na primer:
Code:
Country Confirmed Deaths Recovered
US 526396 20463 31270
itd...
Serbia 3380 74 0
Zatim, ako je npr. unet argument top, program ispisuje 10 država sa najviše
potvrdjenih slučajeva, a pored toga i broj novih slučaja, ili npr. top deaths
sa najviše umrlih:
Code:
Top 10 Deaths:
Country Deaths New Deaths
US 20463 2125
Italy 19468 619
itd...
Top 10 Recovered:
Country Recovered New Recovered
China 77877 86
Spain 59109 3441
itd...
Dalje, dopuniti program po svom izboru, na primer pored navedenih podataka,
ispisati vreme kada su poslednji put ažurirani ili geografske kordinate,
ukupan broj potvrdjenih, umrlih i oporavljenih, ako je kao argument unet datum,
ispisati samo podatke za isti, itd.
Malo opširniji zadatak, ali eto da se zanimate dok ste u izolaciji.
[ Branimir Maksimovic @ 12.04.2020. 23:35 ] @
Jedino sad ne bih smestao u json, posto je taj format za transfer preko neta, tj serijalizaciju. Nego bolje u bazu, bar po meni.
(import iz csv-a je standardna stvar za baze)
Zgodno je sto je git repo pa moze da se svuce i apdejtuje prostim git komandama :P
[ Panta_ @ 13.04.2020. 05:25 ] @
Citat:
Nego bolje u bazu, bar po meni.
Da, ali onda i korisnik mora da je ima instaliranu. Ovako je u pitanju običan fajl. Python podrazumevano ima podršku za json i csv, kao i urllib.request modul da se preuzmu potrebni podaci (da ne mora Git da se instalira). Mislim da i Rust ima navedeno, ili pak može da se instalira preko Cargo paket menadžera.
Ako mora baza, onda preporuka za Sqlite.
[ Branimir Maksimovic @ 13.04.2020. 05:38 ] @
" ili pak može da se instalira preko Cargo paket menadžera."
Da, mora da se napravi projekt, tj Cargo.toml i da se izlistaju dependency-ji/
Nista strasno, cim nadjem vremena uradicu. Inace vec sam sve svukao u postgres :P
[ Branimir Maksimovic @ 15.04.2020. 15:10 ] @
Heh, lakse je sa git, ovako prvo moras da formiras url tj prvo da povuces preko github apija listu fajlova, parsujes json, pa onda iz liste da vuces fajl parsujes json pa base64 decode
i tek onda dobijas csv content, pa onda parsuj csv content i stavljaj u json :P
Sva sreca da za sve postoje biblioteke :P
[ Branimir Maksimovic @ 15.04.2020. 18:29 ] @
Bad news za korisnike api-ja:
Code:
{"message":"API rate limit exceeded for 109.72.51.23. (But here's the good news: Authenticated requests get a higher rate limit. Check out the documentation for more details.)","documentation_url":"https://developer.github.com/v3/#rate-limiting"}
Nije ni pola fajlova skinulo...
[ Panta_ @ 15.04.2020. 21:03 ] @
Ja nisam koristio api, već sam povadio linkove do csv fajlova.
Code:
from urllib.error import URLError
from urllib.request import Request, urlopen
import re
req = Request('https://github.com/CSSEGISandD...ta/csse_covid_19_daily_reports')
try:
with urlopen(req) as response:
html = response.read().decode('utf-8')
except URLError as e:
print(e.reason)
raise
Da, a kako ces da dodjes do csv fajlova? Problem je kada pocnes da skidas...
Inace otparsovao sam csv ostalo je smestanje u json, a tu je naravno i problem struktuiranja
podataka jer nisu svi fajlovi sa istim headerima...
Program ce pokusavati sve dok ne upise i poslednji fajl. Limit je 60 reqs/sat
edit:
bilda se sa `cargo build --release` kada se udje u dir
[ Panta_ @ 16.04.2020. 05:55 ] @
Citat:
Da, a kako ces da dodjes do csv fajlova? Problem je kada pocnes da skidas...
Kreiram url od csv linkova i preuzimam ih na isti gore navedeni način, zatim čitam sa csv reader, itd..
Citat:
tu je naravno i problem struktuiranja podataka jer nisu svi fajlovi sa istim headerima
Da, to sam tek kasnije video da su izmenili. Takođe, treba voditi računa da su za pojedine države (USA, Kina, itd.) dati podaci pojedinačno za svaku državu, odnosno provinciju.
[ Branimir Maksimovic @ 16.04.2020. 06:11 ] @
"Kreiram url od csv linkova i preuzimam ih na isti gore navedeni način, zatim čitam sa csv reader, itd.."
kako kada dobijas html, a ne csv?
[ Panta_ @ 16.04.2020. 06:17 ] @
Citat:
bilda se sa `cargo build --release` kada se udje u dir
Neće:
Code: error[E0554]: `#![feature]` may not be used on the stable release channel
--> src/main.rs:1:1
|
1 | #![feature(try_blocks)]
| ^^^^^^^^^^^^^^^^^^^^^^^
error: aborting due to previous error
For more information about this error, try `rustc --explain E0554`.
error: could not compile `covid19report`.
A, evo i razlog:
Code: rustc --explain E0554
Feature attributes are only allowed on the nightly release channel. Stable or
beta compilers will not comply.
Example of erroneous code (on a stable compiler):
```
#![feature(non_ascii_idents)] // error: `#![feature]` may not be used on the
// stable release channel
```
If you need the feature, make sure to use a nightly release of the compiler
(but be warned that the feature may be removed or altered in the future).
Probao sam sa rustup install nightly, ali opet ista greška.
~/.../rust/covid19report >>> ./target/release/reports --key Country --key_value Serbia --columns Country,Confirmed,Deaths,Recovered,Active,Last_update ±[●●][master]
Country Confirmed Deaths Recovered Active Last_update
Serbia 4873 99 0 4774 2020-04-15 22:56:32
Options:
-k, --key Column name
set sorting key
-f, --file filename set input file
-d, --date mm-dd-yyyy
set date
-s, --sort asc or desc
set sort
-c, --columns colname1,colname2,..
set columns
-r, --results number
set number of results
--key_value key value
set particular value of key
-t, --type numeric or string
set type of key column
-h, --help print this help menu
To bi bilo to, ako nemas nekih primedbi :p
[ Panta_ @ 17.04.2020. 05:05 ] @
Nisu ti tačni podaci za USA, a u Kini izgleda da nema zaraženih. Kao što sam naveo u jednoj od prethodnih poruka, podaci za USA, Kina i još neke države su dati pojedinačno za države, provincije, kolonije, itd.
[ Branimir Maksimovic @ 17.04.2020. 05:10 ] @
Sumiranje kljuceva nije onako kako su podaci zadati, po provincijama i drzavama u USA. Ja ne prepoznajem kolone mozes da sortiras po bilo cemu, ovo bi zahtevalo
specijalan tretman kolone "drzava" i onda ne bi ovo moglo da se primeni na bilo kom podatku.
edit: al ajde dodacu opciju multi_key i sum_columns gde ce se naznaciti koje kolone da se sabiraju pod kojim kljucem.
[ Branimir Maksimovic @ 17.04.2020. 13:05 ] @
Sredio, dodao multi-key ali nisam sort_columns jer provalim da li ne int ili string.
Evo ga:
Nego razmisljam koji feature da dodam, i prvo mi padne na pamet razlika po datumima, znaci od prethodnog dana za navedena polja ;)
To umesto onog sum_columns sad ide diff_columns ;)
[ Panta_ @ 17.04.2020. 18:19 ] @
Ja sam dodao ukupan broj slučajeva što sam bio zaboravio, kao i "checking for updates, please wait" poruku.
Code: python covid19.py --sum
Confirmed 2152647
Deaths 143801
Recovered 542107
Active 1466739
[ mjanjic @ 17.04.2020. 23:54 ] @
Ovo je za pohvalu, ali po meni ovi csv fajlovi imaju smisla ako je potrebno analizirati broj zaraženih po određenim datumima u pojedinim državama. Ili da se bar keširaju, tj. sačuvaju lokalno stariji CSV fajlovi pa da se samo proveri datum zadnje izmene (u principu, za to može da se koristi lokalni git koji bi povukao sve izmene, a python koristio fajlove iz lokalnog repozitorijuma.
Mada i u tom slučaju mogu samo da se dodaju novi podaci, da se ne otvara ponovo blizu 100 fajlova, naravno ako već ranije obrađeni fajlovi nisu menjani.
Zbirni podaci po datumima (ukupan broj zaraženih do tog datuma) su dati svi u jednoj tabeli ovde: https://github.com/CSSEGISandD...data/csse_covid_19_time_series
pa je možda lakše sve pročitati iz jednog fajla ako su potrebni samo zbirni podaci do određenog datuma, a može se lako izračunati i broj novozaraženih po datumima na osnovu razlike vrednosti u dve kolone.
[ Branimir Maksimovic @ 18.04.2020. 00:04 ] @
Nece vise to da apdejtuju, ovi dejliji su aktuelni. E sad jedino ako se koristi git mozes dobiti apdejtovane fajlove.
Inace ovo je vise za vezbanje jer sam ja sa git-om i csvkitom importovao u postgres za 5 minuta ;)
A kad je u bazi imas sql pa mozes da izvlacis kakve hoces podatke ::
Inace ovo mi je vezba da ne zardjam sa Rust-om jer radim samo C++ ;)
Panta_:
Ne, za sada samo poslednji i pretposlednji da izračuna nove slučajeve.
Pa samo umesto indeksa -1 i -2 stave se indeksi od odgovarajućih datuma. Ali, kao što reče neko ranije, lakše je ako je sve u bazi.
Takođe, zavisi da li češće trebaju brojevi po datumima ili ukupni do određenog datuma, pa tako treba i formirati kolone, odnosno u slučaju baze podatke u vrstama.
Da, treba sabrati sve datume između, ako su podaci dati pojedinjačno za datume, prebacio sam se na varijantu koju sam predložio, da kolone po datumima predstavljaju broj ukupno zaraženih do tog datuma.
Ako su potrebni grafikoni za broj novorazaženih i druge slične podatke po pojedinačnim datumima, onda mogu ovi podaci, a ako je potreban grafik za broj ukupno zaraženih na svaki datum, onda je bolje imati drugi fajl sa takvim podacima.
Samo jedna stvar mi nije jasna, da li iko negde predstavlja i broj trenutno zaraženih, koji se dobija oduzimanjem broja onih koji više nemaju virus od broja ukupno zaraženih od početka praćenja podataka?
I da staviš negde na Github, da mogu da te citiraju :)
[ Panta_ @ 18.04.2020. 22:16 ] @
Citat:
Samo jedna stvar mi nije jasna, da li iko negde predstavlja i broj trenutno zaraženih, koji se dobija oduzimanjem broja onih koji više nemaju virus od broja ukupno zaraženih od početka praćenja podataka?
Da ima, aktivni slučajevi na koje sam zaboravio.
Code: covid19.py -D 04-12-2020 03-29-2020
COUNTRY CONFIRMED DIFF DEATHS DIFF RECOVERED DIFF ACTIVE DIFF
Ja sam u medjuvremenu dodao, --no_multi_key zbog toga sto postoji kolona Combined_Key.
recimo zbog ovoga:
Code:
~/.../rust/covid19report >>> ./target/release/reports --results 10 --key Confirmed --columns Active,Combined_Key
Active Combined_Key Confirmed Country
628693 Abbeville, South Carolina, US732197 US
96886 Spain 191726 Spain
107771 Italy 175925 Italy
93217 French Guiana, France149149 France
53483 Germany 143342 Germany
99402 Anguilla, United Kingdom115314 United Kingdom
1537 Anhui, China 83787 China
69986 Turkey 82329 Turkey
19850 Iran 80868 Iran
23382 Belgium 37183 Belgium
pa sad:
Code:
~/.../rust/covid19report >>> ./target/release/reports --results 10 --key Confirmed --columns Active,Combined_Key --no_multi_key
Active Combined_Key Confirmed Country
96886 Spain 191726 Spain
107771 Italy 175925 Italy
92663 France 147969 France
53483 Germany 143342 Germany
122370 New York City, New York, US135572 US
98753 United Kingdom 114217 United Kingdom
69986 Turkey 82329 Turkey
19850 Iran 80868 Iran
122 Hubei, China 68128 China
23382 Belgium 37183 Belgium
[ Branimir Maksimovic @ 19.04.2020. 06:48 ] @
A tu je i convenient opcija -l da se izlistaju postojece kolone za odredjen datum posto postoji opcija --columns
Code:
~/.../rust/covid19report >>> ./target/release/reports -l --date 02-04-2020
Confirmed
Country/Region
Deaths
Last Update
Province/State
Recovered
~/.../rust/covid19report >>> ./target/release/reports -l
Active
Admin2
Combined_Key
Confirmed
Country_Region
Deaths
FIPS
Last_Update
Lat
Long_
Province_State
Recovered
~/.../rust/covid19report >>>
[ a1234567 @ 22.04.2020. 18:07 ] @
Zadatak 34:
Napisati funkciju koja će u datom engleskom tekstu izračunati zbir brojeva.
Računaju se samo posebni brojevi. Ako je broj deo reči, ne ulazi u zbir.
Mustre za text i očekivani zbir:
('hi') == 0
('who is 1st here') == 0
('my numbers is 2') == 2
('This picture is an oil on canvas '
'painting by Danish artist Anna '
'Petersen between 1845 and 1910 year') == 3755
('5 plus 6 is') == 11
('') == 0
Ja sam napravio ovakvo rešenje:
Code: def sum_numbers(text: str) -> int:
zbir = 0
a = text.split()
a = ['' if x == '1st' else x for x in a]
for i in a:
if i.isdigit():
zbir += int(i)
return zbir
print("Example:")
print(sum_numbers(('This picture is an oil on canvas '
'painting by Danish artist Anna '
'Petersen between 1845 and 1910 year')))
[Ovu poruku je menjao a1234567 dana 22.04.2020. u 19:24 GMT+1]
[ djoka_l @ 22.04.2020. 21:21 ] @
Ne valja. Ne treba da radi samo za zadate primere nego i za druge slučajeve.
Probaj:
2nd
2020-04-22
Pa ćeš videti da ne radi kako treba.
[ djoka_l @ 22.04.2020. 22:20 ] @
Ne znam šta je cilj, da se nauče regularni izrazi ili nešto drugo.
Tvoj program ne prepoznaje int ako ima predznak + ili -
Code:
def MySum( InStr ):
sum=0
for i in InStr.split():
try:
sum += int(i)
except:
None
return sum
print(MySum('1 2 3 abc 45 -11 +12a +1'))
[ a1234567 @ 23.04.2020. 05:20 ] @
Nije u zadatku tj. u tekstu predviđeno da bude brojeva sa + i -.
Nego, probao sam nešto sa pozitivnim/negativnim brojevima u listi
i sabiranjem onih sa parnim indeksom,
pa mi nije jasno zašto petlja preskače jedan index. Na primer:
Hteo sam sve te brojeve da gurnem u nova_lista i uradim sum(nova_lista)
ali stalno sam dobijao pogrešan rezultat. Nije mi bilo jasno zašto, sve dok nisam napravio ispis.
[ Branimir Maksimovic @ 23.04.2020. 05:37 ] @
To je zato sto index f-ja vraca prvi index elementa u nizu, a taj broj se vec nalazi na prethodnoj pozijiciji.
Da li postoji nacin da for vraca i index i broj kao sto recimo u Rustu to radis sa funkcijom enumerate?
[ Panta_ @ 23.04.2020. 06:16 ] @
Citat:
Da li postoji nacin da for vraca i index i broj kao sto recimo u Rustu to radis sa funkcijom enumerate
Da, sa enumerate funkcijom. ;) for i, v in enumerate(lista):...itd
[ a1234567 @ 23.04.2020. 06:34 ] @
Ovo je za mene vrlo čudno.
Očekivao sam da funkcija ide element po element i vraća index jedan za drugim.
Kakve veze ima što je isti element već bio u listi!?
[ djoka_l @ 23.04.2020. 10:32 ] @
Citat:
index() is an inbuilt function in Python, which searches for given element from start of the list and returns the lowest index where the element appears.
Dakle, index vraća poziciju PRVE pojave vrednosti u listi.
Ti u for petlji zaista dobijaš sve elemente liste, ali sa index dobijaš gde se element pojavio prvi put.
Da si napisao
for i in range(len(lista)):
dobio bi ono što si želeo, a to je indeks tekućeg elemnta u listi.
To je problem sa svakim programskim jezikom, obično dobiješ tačno ono što si napisao, a malo ređe ono što si želeo...
[ a1234567 @ 23.04.2020. 11:50 ] @
Jel tebi to logično?
Da petlja ide element po element redom, ali index ide samo do prvog pojavljivanja.
Očekivao bih da daje element i njegov index.
Da li se zna zašto je uzeto takvo rešenje?
[ djoka_l @ 23.04.2020. 12:51 ] @
Jedno je šta ti očekuješ, drugo je šta je NAPISANO u dokumentaciji.
Ono što je meni nelogično je što uopšte for petlja ide REDOM kroz listu.
U awk jeziku, recimo, foreach konstrukcija ide slučajnim redosledom kroz listu. Vraća sve elemente, ali ne onim redom kojim su uneti.
U SQL jeziku SELECT vraća redove u slučajnom rasporedu.
Ovo slučajno, treba čitati, onako kako je najbrže.
Generalno, hash tabele (a tako je implementirana lista u pythonu) elemente raspoređuju tako što je indeks elementa dobijen nekakvom transformacijum ključa.
Recimo da je indeks integer podatka dobijen tako što se radi mod 7 nad vrednošću.
Tako, kada upisuješ niz 1, 3, 5, 7, 8 tada su ti hash vreendosti 1, 3, 5, 0, 1
Ako bi hash tabelu čitao po redosledu ključeva, dobio bi niz 7, 1, 8, 3, 5
[ Branimir Maksimovic @ 23.04.2020. 13:12 ] @
Citat:
a1234567:
Ovo je za mene vrlo čudno.
Očekivao sam da funkcija ide element po element i vraća index jedan za drugim.
Kakve veze ima što je isti element već bio u listi!?
To je zato sto funkcija ide redom kroz niz i vraca indeks prvog lelemnta cija se vrednost poklapa
sa parametrom.
[ Branimir Maksimovic @ 23.04.2020. 13:25 ] @
Citat:
djoka_l:
Ono što je meni nelogično je što uopšte for petlja ide REDOM kroz listu.
Isti je i u Haskell-u, samo sto je u Haskellu u pitanju prava lista,
pa se indeks operacija retko koristi zato sto je O(n).
E sad da li se ovde uopste radi o listi ili je to zapravo niz,
kao u Rustu?
[ a1234567 @ 23.04.2020. 15:56 ] @
Citat:
Branimir Maksimovic:
Citat:
a1234567:
Ovo je za mene vrlo čudno.
Očekivao sam da funkcija ide element po element i vraća index jedan za drugim.
Kakve veze ima što je isti element već bio u listi!?
To je zato sto funkcija ide redom kroz niz i vraca indeks prvog lelemnta cija se vrednost poklapa
sa parametrom.
Onda su ga mogli nazvati i findex (od first index) :))
[ Branimir Maksimovic @ 23.04.2020. 16:18 ] @
Pa ajde razmisli kako bi ti implementirao. Ulazni parametri su niz i vrednost elementa.
[ djoka_l @ 23.04.2020. 16:40 ] @
Nikako da ti zašrafimo glavu na pravo mesto?
Šta misliš da treba da vrati komanda:
'alabama'.index('a')
Code:
py
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> 'alabama'.index('a')
0
>>>
Ti bi da ti index jednom vrati 0, pa 2, pa 4, pa 6.
A, ono, uvek vrati 0!
[ a1234567 @ 23.04.2020. 16:45 ] @
Da su me pitali, ja ne bih to komplikovao.
Koji je element, njegov i index i da te bog vidi:
Code: lista = [37, 36, 19, 99, 36]
for i in lista:
print(lista.index(i), i)
0 37
1 36
2 19
3 99
4 36
Zato sam pitao koja je logika postojećeg rešenja.
Koja je situacija kad je bolje da imaš indeks prvog istog elementa u nizu, a ne tekućeg?
Meni je to kontraintuitivno, ali bože moj, nije smak sveta. Guido tako rešio, nek mu je alal :)
[ Branimir Maksimovic @ 23.04.2020. 16:52 ] @
"a ne tekućeg?"
Takvog parametra nema. Imas samo vrednost i niz. f-ja index ni ne zna da se for vrti...
[ a1234567 @ 24.04.2020. 01:49 ] @
Vidim da nema i to mi je čudno.
A bilo bi i korisno da ima :)
[ a1234567 @ 24.04.2020. 05:31 ] @
Zanimljiv zadatak za početnike
Dat je string:
Code: rečenica sa viškom razmaka
koju treba ispisati inverzno, ali da svaka reč (kao i razmak) ostane na svom mestu.
Code: acinečer as mokšiv akamzar
[ X Files @ 24.04.2020. 09:03 ] @
Code:
s="recenica sa viskom razmaka"
#s=" recenica sa viskom razmaka"
#s=" "
#s=""
#s="r e c e n i ca"
#s="recenica"
i=0
s2=""
while ( i<len(s) ):
if ( s[i] != " "):
index = i
length = 0
while (i<len(s) and s[i] != " "):
length+=1
i+=1
i-=1
for j in range(length):
s2+=s[index+length-1-j]
else:
s2+=" "
i+=1
print(s)
print(s2)
Pazi, ja ne znam Python, sem baš elementarnog. Ovo je neko rešenje, ne baš skroz elegantno, da se još optimizovati.
Ako je ovi školski zadatak, onda treba videti šta je profesor zapravo želeo da vidi u rešenju (ugrađene funkcije, posebne funkcije, sintaksni slice, ...)
[ a1234567 @ 24.04.2020. 09:32 ] @
Pozdrav, Vladimire, supermoderatoru,
doborodošao na temu :)
Nije to zadatak za profesora, već sam ja pod stare dane rešio da sam sebe nešto naučim o programiranju, od kojeg pre dva meseca nisam znao ni "p".
A evo pomaže mi i nekoliko "profesora" ovde, dovoljno ljubaznih da priskoče u pomoć kad mi zapne. A zapne često :)
Dakle, kad nađem neki meni zanimljiv zadatak, ja ga ovde okačim.
Ovaj sam našao na https://checkio.org/, gde sam krenuo da rešavam gomilu zadataka od početka. Pa dokle stignem.
Moje rešenje za ovaj zadatak je (tamo traže da bude u formi funkcije):
if __name__ == '__main__':
print("Primer:")
print(string_unazad('recenica sa viskom razmaka'))
[ Branimir Maksimovic @ 24.04.2020. 09:48 ] @
Evo i Rusta ;)
Code:
fn main() {
let s = "rečenica sa viškom razmaka";
println!("{}",rev_words(s));
}
fn rev_words(words:&str)->String {
words.to_string().split(' ').fold("".to_string(),|v,x| v +
&x.to_string().chars().rev().collect::<String>()+" ")
}
[ B3R1 @ 24.04.2020. 10:49 ] @
Citat:
a1234567: Zadatak 34:
Napisati funkciju koja će u datom engleskom tekstu izračunati zbir brojeva.
Računaju se samo posebni brojevi. Ako je broj deo reči, ne ulazi u zbir.
'Petersen between 1845 and 1910 year') == 3755
'2020-02-20' == 2062
Ima vise resenja, koja se svode na isto: sve sto nije cifra zameniti razmkom, pa onda udariti split() i sabrati. Osnovacko reesnje:
Code (python):
def sum_numbers(text): sum=0
newtext =''
text = text.lower()
text = text.replace('1st',' ')
text = text.replace('2nd',' ')
text = text.replace('3rd',' ') for ch in text:
newtext += ch if ch.isdigit()else' ' for n in newtext.split(): sum +=int(n) returnsum
Resenje sa regularnim izrazima:
Code (python):
importre
def sum_numbers(text): sum=0 for n inre.sub('\D',' ',re.sub('1st|2nd|3rd',' ', text.lower())).split(): sum +=int(n) returnsum
ili, da bude jasnije:
Code (python):
importre
def sum_numbers(text): sum=0
text =re.sub('1st|2nd|3rd',' ', text.lower())# Zameni 1st, 2nd i 3rd razmaknicom
text =re.sub('\D',' ', text)# Zameni sve non-digit znakove razmaknicom for n in text.split(): sum +=int(n) returnsum
U ovom gornjem reesnju smo najpre zamenili stringove '1st', '2nd' i '3rd' razmakom. Slucaj radi i za '1ST', '2nD' i tome slicno, za sta se pobrinuo lower(). Potom u takvom stringu zamenimo sve znake koji nisu cifre (regexp '\D'). Ostatak je identican - split() to pretvori u niz kontinualnih karaktera (npr. ' 4 55 6666 ' daje ['4', '55', '6666']), sto onda saberemo.
Ako treba uzeti u obzir i znake + i -, tada je prica malcice slozenija, ali ne preterano. Najpre treba razdvojiti + i - znake koji stoje uz cifre i one koji ne stoje uz cifre. Npr. '-G' i '+A' s uobicni stringovi, dok su '-3' i '+123' brojevi. Najlakse je primeniti:
text = text.replace('-', ' -0').replace('+', ' +0')
Primer:
Code (python):
>>> text='44, is - -G 2002-02+02' >>> text = text.replace('-',' -0').replace('+',' +0') >>> text '44, is -0 -0G 2002 -002 +002'
Nadalje je lako, split() ce ovo gore da pretvori u niz, a int(-0) i int(+0) je uvek 0.
[ a1234567 @ 24.04.2020. 11:46 ] @
Al si ga izanalizorao, svaka čast!
Mnogo mi pomaže ovo, da vidim logiku različitih rešenja.
Hvala!
[ Panta_ @ 24.04.2020. 19:09 ] @
Code: ' '.join(word[::-1] for word in 'rečenica sa viškom razmaka'.split(' '))
'acinečer as mokšiv akamzar'
[ a1234567 @ 25.04.2020. 02:05 ] @
Panta zvani one-liner.
Nisam ništa duže ni očekivao
Lep dan vam svima želim!
[ Branimir Maksimovic @ 25.04.2020. 07:50 ] @
Evo gai Haskell:
Code:
rev words = concat $ splitSpace words
splitSpace words = splitSpace' words [] []
where
splitSpace' (' ':words) cumul list = cumul:[' ']: splitSpace' words [] list
splitSpace' (c:words) cumul list = splitSpace' words (c:cumul) list
splitSpace' [] cumul list = cumul:list
main = do
putStrLn $ rev "rečenica sa viškom razmaka"
Ovo je nesto komplikovanije jer moraju da se sacuvaju razmaci inace
bi bilo samo ovo:
Code:
rev wrds = unwords $ map reverse $ words wrds
main = do
putStrLn $ rev "rečenica sa viškom razmaka"
[ a1234567 @ 30.04.2020. 17:01 ] @
Zadatak 35: Encryption Algorithm
Make a function that encrypts a given input with these steps:
Input: "apple"
Step 1: Reverse the input: "elppa"
Step 2: Replace all vowels using the following chart:
a => 0
e => 1
o => 2
u => 3
# "1lpp0"
Step 3: Add "aca" to the end of the word: "1lpp0aca"
def encr(rec):
obrnuto = rec[::-1]
for i in obrnuto:
if i in vokali:
novo += obrnuto.replace(i, str(vokali[i]))
novo += i
novo += 'aca'
return novo
encr('jabuka')
ali mi prijavljuje grešku: UnboundLocalError: local variable 'novo' referenced before assignment
Nije mi jasno šta treba da popravim.
[ djoka_l @ 30.04.2020. 21:28 ] @
Fantastičan primer kako ne treba programirati.
Varijable vokali i novo su globalne, deklarisane su van tela funkcije. Koja je njihova svrha, ako se koriste samo u funkciji?
Možda si preskočio deo koji priča o "vidljivosti" (scope) varijabli. novo je globalna varijhabla. U telu funkcije koje se nalazi ispod deklaracije varijable, njena vrednost može da se pročita, ispiše, svašta može sa njom.
Jedena stvar ne može. NE MOŽE JOJ SE DODELITI VREDNOST.
Ako pokušaš da joj dodeliš vrednost (ako je staviš sa leve strane znaka =), u tom momentu napravi se LOKALNA varijabla sa istim imenom.
Dakle, u funkciji si pogao da napišeš print(novo), ali novo+= je potpuno nova neinicijalizovana lokalna varijabla.
Gomila jezika dozvoljava da se manipuliše globalnom varijablom. I to je ogroman izvor grešaka, takozvani side-effect.
Rezultat funkcije treba da zavisi od ulaznih varijabli, ali ne i od nečega što je deklarisano van funkcije.
Funkcija treba da vrati vrednost, ali ne treba da menja globalne varijable.
Zamisli šta bi se desilo, kada bi tvoj program radio, a ti pozvao DVA puta funkciju. novo bi imalo sadržaj od prethodnog poziva i dobio bi neočekivan rezukltat.
POMERI DEKLARACIJU VARIJABLE U TELO FUNKCIJE.
I, molim te, nemoj da me pitaš zašto ne valja to što si napisao, kao i zašto nije logično da tvoja funkcija radi...
for i in rec:
if i in vokali:
i = str(vokali[i])
novo += i
else:
novo += i
print(novo)
encr('jabuke')
ispis j0b4k1
[ Branimir Maksimovic @ 01.05.2020. 07:44 ] @
U Haskellu nema problema posto je sve f-ja tj nema varijabli ; )
U Rustu moze globalna da bude mut, ali menjanje vrednosti mora da se stavi u "unsafe" blok.
>>> string = 'ppy!'
>>> fruit = 'a'.join(list(string))
šta dobiješ?
papaya! :)
[ mjanjic @ 03.05.2020. 15:14 ] @
Citat:
djoka_l:
Da, ovo je recimo primer koji treba da se, između ostalih, pokazuje na časovima programiranja, umesto što se samo pokazuju ispravni primeri iz literature, pa posle imamo "programere" koji ne znaju šta da rade kad im se pojavi greška, a čini im se da je sve u redu.
Nego, za taj slučaj korišćenja globalnih promenljivih unutar definicije funkcije je zanimljivo kada se radi o nizovima. Onda .append() metoda funkcioniše bez problema (jer nije dodela nove vrednosti).
Tada će program raditi bez greške, pa će se "uspešno" koristiti globalna promenljiva na pogrešan način.
Drugi problem nastaje ako se (greškom) unutar funkcije za "novo" dodeli vrednost praznog niza (novo =[]), čime se u stvari kreira lokalna promenljiva, a globalna ostaje nepromenjena. Ako je namera bila da definisana funkcija pri pozivu menja vrednost globalne promenljive, desiće se "bug".
Al' hajde, ovo i nije toliki problem, ali ako baš mora da se koristi non-local promenljiva u funkciji, može da se primeni closure:
Zato ne volim Piton. Ne znas dal definises novu varijablu ili joj dodeljujes vrednost...
[ mjanjic @ 04.05.2020. 02:36 ] @
A što, u JS je drugačije (doduše, ima var/let, pa je programer koliko-toliko siguran).
To su stvari vezane za sintaksu jezika. Mada, mnogi ne nauče dobro osnovnu sintaksu i njena značenja, pa posle...
[ a1234567 @ 04.05.2020. 08:06 ] @
Zadatak 36: Value of a sentence
Each letter in a sentence is worth its position in the alphabet (i.e. a = 1, b = 2, c = 3, etc...). However, if a word is all in UPPERCASE, the value of that word is doubled.
Create a function which returns the value of a sentence.
get_sentence_value("abc ABC Abc") ➞ 24
# a = 1, b = 2, c = 3
# abc = 1 + 2 + 3 = 6
# ABC = (1+2+3) * 2 = 12 (ALL letters are in uppercase)
# Abc = 1 + 2 + 3 = 6 (NOT ALL letters are in uppercase)
# 6 + 12 + 6 = 24
Examples
get_sentence_value("HELLO world") ➞ 176
get_sentence_value("Edabit is LEGENDARY") ➞ 251
get_sentence_value("Her seaside sea-shelling business is really booming!") ➞ 488
Notes
Ignore spaces and punctuation.
Remember that the value of a word isn't doubled unless all the letters in it are uppercase.
==========
Malo sam neispavan pa sam probao neka rešenja za koja sam mislio da su jednostavnija korišćenjem find() metode, ali opet ima previše uslova (da li find() vraća -1 ili indeks karaktera).
Međutim, ne radi ti ovo dobro ako imaš npr. tekst "!Aaa", vraća nulu. Jeste da se toga nema u pravom tekstu, ali šta ako je neko pogrešio u kucanju, pa stavio razmak ispred umesto iza znaka uzvika?
Potom, zanimljivo bi bilo modifikovati kod tako da prepozna rečenice iz većeg stringa (i npr. nađe rečenicu sa najvećim brojem vrednošću).
Zanimiljivo rešenje bi bilo da se koristi nešto tipa PERMITTED_CHARS = string.ascii_letters, ili možda samo string.letters ako se prethodno pozove locale.setlocale().
Potom za svaku rečenicu ukloniti sve karaktere koji nisu slova, pa je dalje računanje vrednosti jednostavnije.
U suprotnom, malo ima previše upita oko provere da li npr. alphabet.find vraća -1 ili indeks karakera u alfabetu (alphabet je npr. string.ascii_lowercase).
Kod uvek može da se skrati, čak može dosta toga da se napravi kao složen upit u jednoj liniji, kao npr. (neki kod sa Stackoverflow, nema veze sa ovim zadatkom)
Code: sum(i for i in array if array.index(i) % 2 == 0)*array[-1] if array != [] else 0
međutim, pitanje je da li se takav kod izvršava brže nego kod koji ima if...else strukturu. Nekada se izvršava brže, ali češće ne.
[ djoka_l @ 04.05.2020. 14:27 ] @
@a1234567
Moram nešto da te pitam, ali nemoj da se ljutiš. Cenim tvoj entuzijazam, ali prošlo je 4 meseca, a ti si na zadatku 36. Realno, tvoj napredak je ravan kursu python programiranja posle 20 časova kursa, pod uslovom da kurs ima 100 časova.
Kakav ti je plan? Realno, trebaće ti jedno dve godine da stigneš do kraja knjige.
Nama je ovo razbibriga, zadaci su na nivou rešavanja u roku od 5-10 minuta. Ne znam čime se baviš u životu, ali da si posvetio učenju pythona 6 sati nedeljno, do sada bi već mogao da praviš programe od 1000 linija KOJI RADE...
[ Branimir Maksimovic @ 04.05.2020. 14:32 ] @
Djoka:"ali da si posvetio učenju pythona 6 sati nedeljno, do sada bi već mogao da praviš programe od 1000 linija KOJI RADE... "
Jedno je Python, a drugo programiranje. Za programiranje treba mnogo vise vremena, a Python bar po meni nije najsrecnije
resenje za ucenje programiranja.
[ a1234567 @ 04.05.2020. 15:23 ] @
Đoko, cenim i ja tvoju brigu.
Zadatak je 36, ali ovde, ne u Stivensonovoj knjizi.
Tamo ih je mnogo više, ali sam ja odabrao neke koji su meni bili zanimljivi.
Pošto sam došao do kraja knjige, krenuo sam po netu da tražim ove Python challenge sajtove i naišao na Checkio,
koji je meni prilično zanimljiv, tako da sam tamo krenuo od početka. No ti početni zadaci su laki, tako da nisam hteo da ih stavljam ovde. Ali meni su dobri za utvrđivanje gradiva. Kad naiđu teži, postaviću, ne brini :)
Drugi challenge sajt koji je možda i bolji od ovog prvog je Edabit, jer možeš da biraš odmah zadatke po stepenu težine. Odatle sam uzeo poslednja dva zadatka.
Ne sećam se više da li sam objasnio svoju poziciju po pitanju svega ovoga, ali evo da probam. Ja dolazim iz oblasti humanističkih nauka, dakle nemam veze ni sa tehnikom, ni sa matematikom, a ni sam računarima. U školi sam matematiku buvalno mrzeo, što je donekle i uticalo na koju ću stranu da se usmerim u školovanju, iako mi je brat bio mašinac. Mi smo dakle po obrazovanju, interesovanjima, a onda i sposobnostima, dva potpuno različita sveta, te vas zato molim za razumevanje i strpljenje. Inače, kompjutere koristim dugo, naravno samo kao korisnik. No, isto toliko dugo me je znatiželja navodila da se pitam šta se u toj crnoj kutiji dogodi između pritisnutog tastera i ispisa na ekranu, ali nisam bio u prilici da za to odvojim vreme. Sada ga imam u ograničenim količinama i krenuo sam u istraživanje i to zaista sa velikom radošću, jer volim da učim nove stvari. A ovo je za mene kao da otkrivan novi, do sada nepoznati kontinent. Dakle, nisam ni pod kakvim pritiskom promene karijere ili slično, već je za mene ovo čist hobi i radost učenja, proširivanja vidika i obogaćivanja načina razmišljanja. Uvek su me inspirisali ljudi koji nisu fah idioti i misle da je to što rade jedina važna stvar na svetu, već oni koji imaju šire obrazovanje.
Nažalost, ne mogu učenju programiranja da posvetim 6 sati, samo onoliko koliko mi slobodno vreme dopušta, a to je sat-dva dnevno. Što na duže staze i nije tako malo. No, problem je što ja krećem ne od nule, već od minus 10 :)) Ali u isto vreme, kada sednem da rešavam neki zadatak, radim to zaista sa zadovoljstvom i uzbuđenjem pred novim izazovom. Pošto sam samouk potrošim sigurno pet puta više vremena nego da sam na nekom kursu sa živim predavačem, jer jednostavno dok rešavam zadatak nemam koga da pitam sem brata Gugla. Ali šta da mu radim. Uvek sam u životu pokušavao da uradim najbolje od onoga što mi je na raspolaganju, umesto da kukam i odustanem ili maštam šta bi bilo kad bi bilo. Dakle, moj napredak jeste spor, ali to je verovarno tako sa svakim ko je samouk. A i ako nije, who cares? :)
Ja lično sam zadovoljan. Do pre koji mesec nisam znao gomilu stvari koje sada znam. Drugi bitan faktor ograničenja je i to što moj mozak jednostavno nije navikao da razmišlja na programerski način. Skloniji je metaforama, nego algoritmima, pa su moja rešenja toliko "kreativna", da ne kažem komplikovana i pogrešna :)) Ali nadam se da ću vremenom i to savladati.
Sve u svemu, kad povučem crtu, ne mogu da kažem da sam nezadovoljan, sve dok napredujem, pa makar i mic po mic. Hvala vam svima što ste se potrudili da mi pomognete. Bez toga bi taj mic bio još manji.
Eto, malo sam odužio, ali nadam se da vam je sada lakše da se stavite u moje cipele i možda razumete zašto napredak nije brži nego što jeste :)
[ djoka_l @ 04.05.2020. 19:51 ] @
Gledao sam onaj drugi sajt (Edabit) zato što nije trebalo da se ulogujem. Pretpostavljam da je i prvi sličan. Sličan i kao project euler.
Uglavnom, ti sajtovi nisu dobri za UČENJE programiranja. Nećeš naučiti jezik tako što ćeš da rešavaš "cake". Treba da se vratiš na onu tvoju knjigu i da ponovo prođeš zadatke koje idu posle lekcija. Bitno je da naučiš KONCEPTE.
Slabo koristiš funkcije, ne koristiš exception, ne praviš projekte koji se sastoje od više python programa. Ne praviš svoje biblioteke.
Vrati se ponovo na onaj tvoj projkat rečnika. To će ti više značiti nego rešavanje ovih zadataka od 5 linija.
[ X Files @ 04.05.2020. 20:31 ] @
Slazem se sa djoka_i, poslusaj ga.
[ a1234567 @ 05.05.2020. 10:40 ] @
Mislim da sam pisanje fiunkcija utrenirao, jer na ovom jednom sajtu rešenja su isključivo u formi funkcija.
Neki od zadataka koje sam rešio do sad su ovde .
Mada još toliko nisam ni stavljao na Github.
Da, u pravu si, trebalo bi da oživim projekat rečnika.
Do sada sam od funkcija napravio pretraživanje, dodavanje nove reči i ispravljanje postojećih.
No, to je još uvek skript, ako se to tako zove. Probaću da napravim aplikaciju tako da pretraživanje ide na komandnoj liniji.
Tako da funkcioniše:
> python recnik --prevedi room
> soba, prostorija
Probaću takođe da napravim da ide u oba smera pretraživanje i prevod.
Ako me posluži sreća junačka da sve to isplivam, onda u sledećoj fazi da pravim grafički interfejs.
Đoko, šta misliš o planu? To taman do kraja godine da slistim
[ djoka_l @ 05.05.2020. 11:11 ] @
Grafički interfejs ostavi za nikad. Suviše je komplikovano za tebe, koji si još uvek na prvom programskom jeziku u životu, da se baviš Windows GUI programiranjem.
Koncentriši se na rad iz komandne linije.
Ako želiš nekakvo grafičko okruženje, bolje da to bude web, pretraživač će ti odraditi gomilu stvari, koje ti za sada ne znaš.
Za web ti treba da naučiš, ili obnoviš, znanje HTML, CSS, a onda ide Django.
Naravno, ako ne želiš da ti Django radi kao web server moraćeš da naučiš kako da napraviš WAMP okruženje i nešto malo Apache konfiguracije. Osim ako ne odlučiš da umesto Apache stavih nginx, onda moraš da naučiš kako da ga instaliraš i konfigurišeš. Neizostavno, treba da naučiš SQL i da instaliraš i postaviš MySQL bazu.
Ako misliš da je sve to komplikovano, pa Windows GUI je još komplikovaniji...
Uzgred, ja kao profesionalac, koristim Excel kada treba da napravim nešto na brzinu, a da ima grafiku, da se ne bih zamarao sa GUI na Windowsu.
Kada sam prvi put morao da napravim nešto za Windows okruženje u C++, bilo je tako zamorno, da sam sve svoje module napravio na SCOUnixu, a na windowsu ih samo kompajlirao. Toliko je bilo zamorno da postavim okruženje za rad u VisualStudio IDE, da sam lepo, ko čovek, sve odradio samo pomoću vi editora, pa onda liferovao svoje fajlove na integracioni server.
[ a1234567 @ 05.05.2020. 12:46 ] @
Pa ćemu onda služi tkinter?
Da, jedna od narednih faza bi bilo da taj rečnik stavim i na neki sajt, da bude online.
Za sada znam malo HTML. I to je nešto :)
[ Branimir Maksimovic @ 05.05.2020. 12:59 ] @
Pa dobro ne mora da se zeza sa win32 api u pythonu. Verujem da i pygtk vrsi posao dobro.
[ mjanjic @ 06.05.2020. 09:58 ] @
Generalno, mnogo će lakše naći postao ako razvija neki Web GUI (neki od framework-a ili čist JS), a ako solidno nauči programiranje, neki backend nije toliki problem. U nekoliko firmi u kojima znam programere, kažu da su Java i .NET tu negde, s tim što raste broj poslova za .NET Core, ali se traže i nodeJS, php, itd.
Uglavnom se ide na odvajanje front/back, retki su oni koji znaju i jedno i drugo na istom nivou...
HTML, CSS, JS mora da nauči osnove za Web, ali ako nije cilj rad sa implementacijom dizajna, onda neki od FW-a (react, vue, angular...).
[ Branimir Maksimovic @ 06.05.2020. 11:15 ] @
Cek da prvo nauci da programira, onda ce lako naci posao.... pisanje GUI programa je deo tog procesa.
To sto vecina firmi radi web, i poznatu kombinaciju jezika, ne mora da znaci da bas mora da se koncentrise
na to sada. Nije krenuo ni sa JS, ni sa .NET, ni sa Java, ni PHP, nego sa Pythonom.
[ mjanjic @ 07.05.2020. 07:43 ] @
Da, nego to je reakcija da mu Python nije baš dobar izbor ako hoće da radi GUI. OK ako neko odlično zna Python pa mu je lakše tako.
Python je ipak pogodniji za neke druge stvari, pa ako je nekome primarno to u čemu je Python relativno dominantan, onda OK.
Đoko, u skladu sa tvojom sugestijom,
nova verzija rečnika je na temi "Pravljenje englesko-srpskog rečnika".
Pogledaj, molim te, pa javi kako dalje.
Hvala unapred.
A ovde novi zadatak broj 37:
# You have a text and a list of words. You need to check if the words in a list appear in the
# same order as in the given text.
# Cases you should expect while solving this challenge:
# word from the list is not in the text - your function should return False;
# any word can appear more than once in a text - use only the first one;
# two words are the same - your function should return False;
# the condition is case sensitive, which means 'hi' and 'Hi' are two different words.
# text includes only English letters and spaces
# Input: Two arguments. The first one is a given text, the second is a list of words.
# Output: A bool.
def words_order(text: str, words: list) -> bool:
# your code here
return False
if __name__ == '__main__':
print("Example:")
print(words_order('hi world im here', ['world', 'here']))
# These "asserts" are used for self-checking and not for an auto-testing
assert words_order('hi world im here', ['world', 'here']) == True
assert words_order('hi world im here', ['here', 'world']) == False
assert words_order('hi world im here', ['world']) == True
assert words_order('hi world im here', ['world', 'here', 'hi']) == False
assert words_order('hi world im here', ['world', 'im', 'here']) == True
assert words_order('hi world im here', ['world', 'hi', 'here']) == False
assert words_order('hi world im here', ['world', 'world']) == False assert words_order('hi world im here', ['country', 'world']) == False
assert words_order('hi world im here', ['wo', 'rld']) == False
assert words_order('', ['world', 'here']) == False
for i in collections.Counter(words).values():
if i > 1:
return False
for i in dic_words.values():
for ind, rec in dic_text.items():
if i in rec:
indexi.append(ind)
indexi1 = sorted(indexi)
if indexi == indexi1:
return True
else:
return False
if __name__ == '__main__':
print("Example:")
print(words_order('hi world im here', ['world']))
ali mi javlja grešku na proveri assert words_order('hi world im here', ['country', 'world']) == False
Nije mi jasno zašto to treba da bude False.
Kod mene je True, jer je jedina reč koja se javlja u tekstu, pa je time automatski redosled OK.
[ Branimir Maksimovic @ 07.05.2020. 09:21 ] @
"Nije mi jasno zašto to treba da bude False."
Pa ocigledno lista reci mora u tom redosledu da se pojavi u stringu.
[ a1234567 @ 07.05.2020. 09:33 ] @
U tome je stvar što ne mora.
U listi mogu biti reči koje se ne pojavljuju u stringu.
Ali ako u listi ima više reči koje se pojavljuju, treba proveriti da li je njihov redosed isti kao u stringu.
Mene ovaj slučaj buni zato što ima samo jedna reč koja se pojavljuje, te je otuda redosled OK, pošto je jedina.
[ Branimir Maksimovic @ 07.05.2020. 09:39 ] @
"U listi mogu biti reči koje se ne pojavljuju u stringu."
Mislim da to nisi dobro shvatio. Proveri primere ulaza i sta vraca.
[ a1234567 @ 07.05.2020. 09:46 ] @
Da, moguće je da nisam dobro ovo razumeo:
# word from the list is not in the text - your function should return False;
ako znači da svaka reč iz liste mora biti u stringu i da ako jedna nije, automatski je false
[ Branimir Maksimovic @ 07.05.2020. 10:11 ] @
Pise lepo ako jedna rec iz liste nije u tekstu, onda false.
Generalno, mnogo će lakše naći postao ako razvija neki Web GUI (neki od framework-a ili čist JS), a ako solidno nauči programiranje, neki backend nije toliki problem. U nekoliko firmi u kojima znam programere, kažu da su Java i .NET tu negde, s tim što raste broj poslova za .NET Core, ali se traže i nodeJS, php, itd.
Šta fali Pythonu? Ima veliki izbor Python web frameworka, najpoznatiji su svakako Django i Flask, ali ima i dosta drugih. Isto tako i za razvoj GUI aplikacija.
Za razvoj Web aplikacija mu danas nije potrebno neko veliko znanje HTMLa i CSSa, ima i za tu namenu dosta frameworkova, npr. Bootstrap pa je dovoljno neko osnovno znanje. Za web server, Django i Flask dolaze podrazumevano sa istim tako da ni tu nije potrebno neko podešavanje, dovoljno je pokrenuti run server komandu, ili na primer sa gunicorn koji je lakši za podešavanje od Nginxa ili Apachea. Za bazu podataka, Django podrazumevano dolazi sa ORM podrškom za različite baze (SQLite, PostgreSQL, MariaDB, MySQL, Oracle), dok je za Flask potrebno instalirati npr. Flask-SQLAlchemy, tako da nije potrebno poznavanje SQL jezika za rad sa bazama.
Evo kao primer, ja sm onaj covid19 python skript jednostavno konvertovao u Web app uz pomoć navedenih tehnologija.
U svom rešenju upotrebio si najgori algoritam za pronalaženje duplikata.
U tvom konkretnom slučaju to i nije toliko bitno, u pitanju su kratke liste i efikasnost ne igra neku veliku ulogu.
Međutim, potrebno je da, zbog učenja, pišeš EFIKASNE programe. Kao što je jedan moj profestor sa ETF-a govorio "Program mora da se završi za života programera". Uvek je voleo da spominje programere sa Matematičkog fakulteta koji pišu programe koji se završavaju posle konačnog broja koraka, a ne brzo...
[ Branimir Maksimovic @ 07.05.2020. 11:49 ] @
Kolko vidim koristi hash tabelu, sto je efikacnije od sorta u svakom slucaju. Mozda
jedino sto tu efikasnije moze da se uradi je da ne formira komplet, nego umesto counter,
da koristi obicnu, pa izadje odmah na pojavu prvog duplikata. Koliko kapiram
fora je da se vrati False ukoliko ima duplikata u listi?
edit:
no ovo trazenje reci u redosledu ima mesta za improvement svakako.
[ a1234567 @ 08.05.2020. 03:21 ] @
Zadatak broj 38, za koji nemam ideju kako ga rešiti, a da pohvata sve ove mavedene slučajeve.
Ako neko ima, eto prilike da nešto naučim.
# You are given a list of files. You need to sort this list by file extension. The files with the same extestion should be sorted by name.
#
# Some possible cases:
# Filename cannot be an empty string;
# Files without extensions should go before the files with extensions;
# Filename ".config" has an empty extenstion and name ".config";
# Filename "config." has an empty extenstion and name "config.";
# Filename "table.imp.xls" has an extesntion "xls" and name "table.imp";
# Filename ".imp.xls" has extension "xls" and name ".imp".
#
# Input: A list of filenames.
# Output: A list of filenames.
Code: from typing import List
def sort_by_ext(files: List[str]) -> List[str]:
# your code here
return files
if __name__ == '__main__':
print("Example:")
print(sort_by_ext(['1.cad', '1.bat', '1.aa']))
# These "asserts" are used for self-checking and not for an auto-testing
assert sort_by_ext(['1.cad', '1.bat', '1.aa']) == ['1.aa', '1.bat', '1.cad']
assert sort_by_ext(['1.cad', '1.bat', '1.aa', '2.bat']) == ['1.aa', '1.bat', '2.bat', '1.cad']
assert sort_by_ext(['1.cad', '1.bat', '1.aa', '.bat']) == ['.bat', '1.aa', '1.bat', '1.cad']
assert sort_by_ext(['1.cad', '1.bat', '.aa', '.bat']) == ['.aa', '.bat', '1.bat', '1.cad']
assert sort_by_ext(['1.cad', '1.', '1.aa']) == ['1.', '1.aa', '1.cad']
assert sort_by_ext(['1.cad', '1.bat', '1.aa', '1.aa.doc']) == ['1.aa', '1.bat', '1.cad', '1.aa.doc']
assert sort_by_ext(['1.cad', '1.bat', '1.aa', '.aa.doc']) == ['1.aa', '1.bat', '1.cad', '.aa.doc']
[ djoka_l @ 08.05.2020. 08:35 ] @
HINT:
Code:
py
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> print(sorted( [ ('cad', '1'), ('bat', '1'), ('aa','1') ] ));
[('aa', '1'), ('bat', '1'), ('cad', '1')]
>>> quit();
[ a1234567 @ 09.05.2020. 17:51 ] @
Baš me namuči ovaj zadatak.
Lupao glavu, ali nisam uspeo da rešim sve slučajeve,
čak ni uz pomoć Đokinog hinta.
Sve što sam napravio je seckanje stringa i zamena mesta imena i ekstenzije, pa sortiranje.
Ali ostaje mi problem kad ima više fajlova bez imena.
Code: def sort_by_ext(files):
b = []
for i in files:
b.append(i.split('.'))
# [['1', 'cad'], ['1', 'bat'], ['1', 'aa'], ['2', 'bat']]
d = []
for i in range(len(b)):
d.append([b[i][1]] + [b[i][0]])
# d = [['aa', '1'], ['bat', '1'], ['cad', '1'], ['bat', '2']]
e = []
e = sorted(d, key=lambda x: x[0])
[['aa', '1'], ['bat', '1'], ['bat', '2'], ['cad', '1']]
f = []
for i in range(len(e)):
f.append(e[i][1] + '.' + e[i][0])
# f = ['1.aa', '1.bat', '2.bat', '1.cad']
for i in range(len(f)):
if f[i][0] == '.':
a = f[i]
f.remove(a)
f.insert(0, a)
break
return f
[ djoka_l @ 09.05.2020. 18:52 ] @
Vrati se lepo na tvoju knjigu na odeljak o tipovima podataka. Pogledaj ponovo tip TUPLE.
Obrati pažnjuj na to kako se tuple list sortira - prvo po prvom elementu, pa po drugom ... pa po poslednjem
Jedno vreme si se uhvatio za disctionary, pa si sve rešavao sa tim, posle si sve radio sa fajlovima, sada sve sa listama.
Kada bi jedan tip podatka bio dovoljan, ne bi pisci jezika izmišljali sve ove druge tipove.
Drugo, pogledaj split odnosno rsplit funkcije. Postoji parametar koji kaže na koliko elemenata se lista splituje. A možeš da izabereš i da li ćeš da splituješ s leva u desno ili s desna u levo.
Treće, reši onaj deo koji znaš. Kada budeš našao na primer koji ne znaš, onda zakukaj...
Samo ne razumem čemu ova varijabla "i" u 4. redu!?
dalje je nigde nema u funkciji.
Jel to u stvari treba da bude "t"?
Ali mi onda opet nije jasno svrha kad za drugi string dobiješ index = 3
[ a1234567 @ 10.05.2020. 14:21 ] @
Citat:
djoka_l:
Vrati se lepo na tvoju knjigu na odeljak o tipovima podataka. Pogledaj ponovo tip TUPLE.
i samo služi za to da se podigne exception, ako u stringu postoji samo jedna tačka na prvom mestu.
Ako se exception desi (ne postoji tačka u nazivu fajla osim, možda, na prvom mestu), onda je ekstenzija prazan string, a naziv fajla ceo sadržaj varijable:
t=['', fn]
Ako se exception ne desi, onda se ide na else deo, pa se za ekstenziju uzima POSLEDNJI string posle tačke (rsplit, - sa desne strane se string splituje po tačkama, ali se uzima samo dva stringa, prvi string je sve do poslednje tačke, a drugi strig ono što je posle poslednje tačke), a naziv fajla je ceo fn:
t= [fn.rsplit('.',1)[1], fn]
fn.rsplit('.',1)[0] zanemarujem, uopšte mi nije potreban
'a.b.c.d'.rsplit('.',1) bi dao
['a.b.c', 'd']
ali mi a.b.c nije potrebno
Rezultat fiunkcije je lista od dva stringa, prvi strig je ekstenzija, drugi string je naziv fajla (s tim što ekstenzija može da bude prazan string)
[ Panta_ @ 12.05.2020. 09:44 ] @
Citat:
Baš me namuči ovaj zadatak.
Lupao glavu, ali nisam uspeo da rešim sve slučajeve,
čak ni uz pomoć Đokinog hinta.
Sve što sam napravio je seckanje stringa i zamena mesta imena i ekstenzije, pa sortiranje.
Ali ostaje mi problem kad ima više fajlova bez imena.
Sorted funkcija ima key parametar kome prosleđuješ funkciju koja treba da vrati ime fajla ako isti nema ili ima istu ekstenziju, ili u suprotnom ekstenziju, na primer:
Dakle, prvo proveriš da li fajl ima ekstenziju, ako da, proveriš da li ima još neki fajl sa istom ekstenzijom u files listi, ako da, vratiš ime fajla, ili u suprotnom ekstenziju. Obrati pažnju da se fajlovi koji počinju tačkom sortiraju ispred onih koji počinju alpha ili num karakterom.
Code: sorted(['a', 'c', 'b', '1', '.'])
['.', '1', 'a', 'b', 'c']
[ a1234567 @ 12.05.2020. 14:06 ] @
uklavirio sam kako da proverim da li ima fajlova sa i bez ekstenzije i da ih sortiram, kao što je ovaj slučaj
Code: def lista(fajlovi):
nema_ext = []
ima_ext = []
for i in fajlovi:
if i.rsplit('.', 1)[0] == '':
nema_ext.append(i)
else:
ima_ext.append(i)
print(sorted(nema_ext) + sorted(ima_ext))
lista(['1.cad', '1.bat', '.aa', '.bat'])
['.aa', '.bat', '1.bat', '1.cad']
ali i dalje mi nije jasno kako grupišem fajlove sa istom ekstenzijom.
[ a1234567 @ 14.05.2020. 09:29 ] @
Zadatak broj 39:
Podeli string dužine 0 < str < 100 u delove po dva znaka. Ako je broj znakova u stringu neparan, poslednjem znaku dodaj _ da bi napravio par.
Code: def split_pairs(a):
your code here
return something
if __name__ == '__main__':
print("Example:")
print(list(split_pairs('abcd')))
# These "asserts" are used for self-checking and not for an auto-testing
assert list(split_pairs('abcd')) == ['ab', 'cd']
assert list(split_pairs('abc')) == ['ab', 'c_']
assert list(split_pairs('abcdf')) == ['ab', 'cd', 'f_']
assert list(split_pairs('a')) == ['a_']
assert list(split_pairs('')) == []
print("Coding complete? Click 'Check' to earn cool rewards!")
proveris da li je parni ili neparni,
dodas po potrebi da bude na dvojcicu,
i onda veslas kao da je sve sa dvojcicom devojcicom.
[ a1234567 @ 16.05.2020. 07:36 ] @
Zadatak broj 40:
# In a given word you need to check if one symbol goes right after another.
# Cases you should expect while solving this challenge:
# If more than one symbol is in the list you should always count the first one
# one of the symbols are not in the given word - your function should return False;
# any symbol appears in a word more than once - use only the first one;
# two symbols are the same - your function should return False;
# if the first instance of the second symbol comes before the first one, that should return False
# the condition is case sensitive, which mease 'a' and 'A' are two different symbols.
# Input: Three arguments. The first one is a given string, second is a symbol that shoud go first, and the third is a symbold that should go after the first one.
# Output: A bool.
Ovaj zadatak je sličan prethodnom, ali teži. Treba pronaći reč u višelinijskom u tekstu, horizontalno ili vertikalno i dati njene koordinate.
Napravio sam nešto ovako za horizontalni slučaj, ali za vertikalni nisam baš siguran kako da rešim.
# You are given a rhyme (a multiline string), in which lines are separated by "newline" (\n).
# Casing does not matter for your search, but whitespaces should be removed before your search.
# You should find the word inside the rhyme in the horizontal (from left to right) or vertical
# (from up to down) lines. For this you need envision the rhyme as a matrix (2D array). Find
# the coordinates of the word in the cut rhyme (without whitespaces).
# The result must be represented as a list -- [row_start,column_start,row_end,column_end], where
# row_start is the line number for the first letter of the word.
# column_start is the column number for the first letter of the word.
# row_end is the line number for the last letter of the word.
# column_end is the column number for the last letter of the word.
# Counting of the rows and columns start from 1.
# Input: Two arguments. A rhyme as a string and a word as a string (lowercase).
# Output: The coordinates of the word.
# Precondition: The word is given in lowercase
# 0 < |word| < 10
# 0 < |rhyme| < 300
Code: def checkio(text, word):
novi = text.strip().replace(' ', '')
reci = novi.split('\n')
red = 1
indeks = 1
spisak1 = []
spisak2 = []
duzina = len(word)
vert = ''
for i in novi:
indeks += 1
if i == word[0]:
spisak1.append(red)
spisak2.append(indeks)
if reci[red-1][indeks-1:indeks-1+duzina] == word:
return [int(spisak1[0]), int(spisak2[0]), int(spisak1[0]), int(spisak2[0])+duzina-1]
break
if i == '\n':
red += 1
indeks = 0
# These "asserts" using only for self-checking and not necessary for auto-testing
if __name__ == '__main__':
assert checkio("""DREAMING of apples on a wall,
And dreaming often, dear,
I dreamed that, if I counted all,
-How many would appear?""", "ten") == [2, 14, 2, 16]
assert checkio("""He took his vorpal sword in hand:
Long time the manxome foe he sought--
So rested he by the Tumtum tree,[/quote]
And stood awhile in thought.
And as in uffish thought he stood,
The Jabberwock, with eyes of flame,
Came whiffling through the tulgey wood,
And burbled as it came!""", "noir") == [4, 16, 7, 16]
[ mjanjic @ 17.05.2020. 19:04 ] @
Pa za vertikalan slučaj je slična petlja, samo što uzimaš slova po vertikali u reci[][], tj. u unutrašnjoj petlji je drugi indeks konstantan, a menjaš prvi. Međutim, nisu ti sve "vrste" iste dužine.
Možda bi bilo najjednostavnije konvertovati slova u numeričke ekvivalente 1-26, formirati dvodimenzionu matricu na osnovu teksta, s tim što se stavi 0 tamo gde nema dovoljno teksta - broj kolona je dužina najduže "reči", tj. stiha.
Tada može numpy paketom lako da se manipuliše vrstama i kolonama, pa je lakše pretraživati niz brojeva po koloni koji je jedna nizu numeričkih ekvivalenata za traženu reč.
Dosta bi bilo nezgodnije da treba u samoj pesmi naći reči koje se rimuju, a da se traži isto ovako po "vertikali".
[ a1234567 @ 18.05.2020. 08:05 ] @
Nema veze što su redovi nejednake dužine, svaki kreće od 0. Važne su kolone
U principu mi je jasno i za vertikalnu reč. Kada jednom nađem koordinatu prvog slova u reči,
idem nadole, red po red, po istoj koloni. Nešto ovako.
Ali iz nekog razloga ne ispada onako kako treba.
for i in novi:
for j in i:
indeks += 1
if j == word[0]:
spisak1.append(red)
spisak2.append(indeks)
if novi[red-1][indeks-1:indeks-1+duzina] == word:
return [int(spisak1[0]), int(spisak2[0]), int(spisak1[0]), int(spisak2[0])+duzina-1]
break
else:
for s in novi:
for t in s:
indeks += 1
if i == word[0]:
vert1.append(red)
vert2.append(indeks)
for v in range(len(word)):
vert += reci[red+v][indeks]
return [int(vert1[0]), int(vert2[0]), int(vert1[0]), int(vert2[0+len(word)])]
if i == '\n':
red += 1
indeks = 0
# These "asserts" using only for self-checking and not necessary for auto-testing
if __name__ == '__main__':
assert checkio("""DREAMING of apples on a wall,
And dreaming often, dear,
I dreamed that, if I counted all,
-How many would appear?""", "ten") == [2, 14, 2, 16]
assert checkio("""He took his vorpal sword in hand:
Long time the manxome foe he sought--
So rested he by the Tumtum tree,[/quote]
And stood awhile in thought.
And as in uffish thought he stood,
The Jabberwock, with eyes of flame,
Came whiffling through the tulgey wood,
And burbled as it came!""", "noir") == [4, 16, 7, 16]
[ djoka_l @ 18.05.2020. 08:37 ] @
Ovaj kod ti je tako neuredan da je problem da se prati logika programa.
Opet pokazuješ svoju staru slabost: NE RAZUMEŠ STRUKTURE PODATAKA...
Uzmimo, kao primer, varijable spsiak1 i spisak2.
Zašto su one liste?
Šta stavljaš u listu?
Zašto radiš konverziju u int?
Kada se prođe kroz tvoj kod, jasno je da se u LISTE stavlja samo JEDNA vrednost, pa ti lista ni ne treba!
Jasno je da se u listu stavlja int, pa je konverzija NEPOTREBNA.
Jasno je da se varijablama spisak1 i spsisak2 uvek dodeljuje vrednosti red i indeks, PA TI TE VARIJABLE NI NE TREBAJU!
Code:
Umesto:
if j == word[0]:
spisak1.append(red)
spisak2.append(indeks)
if novi[red-1][indeks-1:indeks-1+duzina] == word:
return [int(spisak1[0]), int(spisak2[0]), int(spisak1[0]), int(spisak2[0])+duzina-1]
break
TREBA:
if j == word[0]:
if novi[red-1][indeks-1:indeks-1+duzina] == word:
return [red, indeks, red, indeks+duzina-1]
break
Pa onda imaš jedna ELSE koji nije poravnat sa IF. Bezveze se pojavio.
Pa onda imaš ovaj biser - porediš i sa novim redom, a znake za novi red si na početku izbacio:
Code: if i == '\n':
red += 1
indeks = 0
Čak ti u zadatku stoji sugestija da koristiš MATRICU, ali ti od matrice bežiš kao đavo od krsta, zato što nisi naučio da koristiš matrice.
[ mjanjic @ 18.05.2020. 13:58 ] @
Da, sa matricama može da koristi numpy paket u kome može lako da radi direktno sa kolonama, ali kada konvertuje tekst u numeričke elemente matrice, mora da dopuni sve vrste koje su kraće od najduže vrste.
Može i sa običnim Python array da se radi, ali je sa numpy dosta lakše jer može da izdvoji kolonu (npr. textArray[ : , column_index]), pa može na pretragu po traženoj reči da primeni istu funkciju koju koristi za pretragu po vrsti.
[ a1234567 @ 18.05.2020. 14:30 ] @
Hvala Đoko na sugestijama.
Ispravio, ali ne radi i dalje.
@mjanjic nije predviđeno da se koristi numpy.
Idemo dalje...
Zadatak broj 42: Ptičiji jezik
Today the bird spoke its first word: "hieeelalaooo". This sounds a lot like "hello", but with too many vowels. Stephan asked Nikola for help and he helped to examine how the bird changes words. With the information they discovered, we should help them to make a translation module.
The bird converts words by two rules:
- after each consonant letter the bird appends a random vowel letter (l ⇒ la or le);
- after each vowel letter the bird appends two of the same letter (a ⇒ aaa);
Vowels letters == "aeiouy".
You are given an ornithological phrase as several words which are separated by white-spaces (each pair of words by one whitespace). The bird does not know how to punctuate its phrases and only speaks words as letters. All words are given in lowercase. You should translate this phrase from the bird language to something more understandable.
Input: A bird phrase as a string.
Output: The translation as a string.
Code: def translate(phrase):
"your code here"
return output
if __name__ == '__main__':
print("Example:")
print(translate("hieeelalaooo"))
# These "asserts" using only for self-checking and not necessary for auto-testing
assert translate("hieeelalaooo") == "hello", "Hi!"
assert translate("hoooowe yyyooouuu duoooiiine") == "how you doin", "Joey?"
assert translate("aaa bo cy da eee fe") == "a b c d e f", "Alphabet"
assert translate("sooooso aaaaaaaaa") == "sos aaa", "Mayday, mayday"
print("Coding complete? Click 'Check' to review your tests and earn cool rewards!")
Vezano za zadatak 41 - koristis previse promenljivih koje ne sluze nicemu i tesko mozes da pohvatas gde je sta. Potrebna ti je samo jedna lista, koju dobijas split() funkcijom, sto si vec lepo uradio. Nazovimo je rows (to je ovo sto ti zoves 'novi'). Takodje, ja bih dodao i funkciju lower(), kojom eliminises mala/velika slova (tekst zadatka kaze "case is not important"):
Code (python):
rows = text.replace(' ','').split('\n').lower()
Ta lista vec sadrzi linije teksta, koje su obicni stringovi, unutar kojih rec definisanu promenljivom word trazis funkcijom find(). Funkcija find() vraca poziciju stirnga unutar veceg stringa, pa imas:
Code (python):
>>> verse ='The woods are lovely, dark and deep' >>> verse.find('wood') 4 >>> verse.find('forest')
-1
Time resavas skeniranje teksta po horizontali. Ostaje da resis skeniranje po vertikali, sto nije toliko slozeno, imajuci u vidu da svakom slovu unutar stringa mozes da pridjes po njegovom indeksu. Na primer, ako ti rows sadrzi:
Tada ti je rows[0][1] == 'h' (drugo slovo prvog reda). Znaci, nisu ti potrebni nikakvi indeksi. Jedini problem je sto su elementi liste nejednake duzine, tako da najpre moras da odredis najvecu duzinu elementa liste koja ce ti odrediti opseg skeniranja. Dobijas kod u formi:
Code (python):
def checkio (text, word):
rows = text.replace(' ','').split('\n')# Smesta linije teksta u listu rows
# Najpre odredimo maksimalnu duzinu linije
max_len =0 for row in rows: if(len(row)>max_len):
max_len =len(row)
# Iteracija po vertikali, slovo po slovo svakog reda, do maksimalne duzine reda for j inrange(0,max_len):
col =''# Ovde smestamo kolone teksta for i,row inenumerate(rows): if(j >=len(row)): continue
col += row[j]# Slovo na poziciji 'j' unutar stringa 'row' # col - ce sadrzati celu kolonu teksta
Ostaje ti da nadjes poziciju reci u stringovima row i col. Tu imas dve ideje. Onako skolski, pocetnicki bi bilo da kolone smestas u posebnu listu (npr. cols), koju inicijalizujes na pocetku i kada formiras kolonu (col) na kraju ovog koda gore dodas:
Code (python):
if(col):
cols.append(col)
U nastavku koda onda ponovo iteriras po svim vrstama i svim kolonama i koristis funkciju find(). To je korektno resenje, ali time nepotrebno ponovo ulazis u petlju. Da ustedis vreme, pretrazivanje stringova mozes da radis vec i u petljama gore. Prva petlja iterira po kolonama, druga za svaku kolonu skenira vrste od 0 do len(rows). U principu, dovoljno je ispitati vrste samo jednom i idealno je to uraditi tokom skeniranja prve kolone. Slicno tome, skeniranje kolone je najbolje uraditi kada se kolona formira. Time kod postaje (nisam testirao, ali mislim da je ok):
Code (python):
def checkio (text, word):
rows = text.replace(' ','').split('\n')# Smesta linije teksta u listu rows
# Najpre odredimo maksimalnu duzinu linije
max_len =0 for row in rows: if(len(row)>m):
max_len =len(row)
# Iteracija po vertikali, slovo po slovo svakog reda for j inrange(0,max_len):
col =''# Ovde smestamo kolone teksta for i,row inenumerate(rows): if(j ==0): # Tokom formiranja prve kolone skeniramo vrstu
pos = row.find(word) if(pos >=0): return[ i, pos, i, pos+len(word)-1] if(j >=len(row)): continue
col += row[j]
pos = col.find(word) if(pos >=0): return[ pos, j, pos+len(word)-1, j ] return[]
Moze li to bolje? Moze! Recimo, ako se rec ne nalazi uopste u tekstu zasto bismo je trazili u svakom redu? Na samom pocetku funkcije treba onda dodati:
Code (python):
def checkio (text, word):
search_rows = word in text
I onda u liniji gde ispitujemo da li je j == 0 izmeniti:
Code (python):
if((j ==0)and search_rows): # Tokom formiranja prve kolone skeniramo vrstu, samo ako je search_row == True
Zadatak moze da se malcice uopsti i da se traze sve koordinate gde se zadata rec nalazi ... i da se to vraca u formi:
[ [ x1, y1, z1, u1 ], [ x2, y2, z2, u2 ], ... ]
To ti ostavljam za domaci ...
[Ovu poruku je menjao B3R1 dana 18.05.2020. u 19:27 GMT+1]
[ a1234567 @ 20.05.2020. 16:16 ] @
Hvala Berislave na detaljnom objašnjenju.
Sad mi je jasno i ne izgleda teško :))
Vidi se da imaš pedagoški dar. Treba da praviš tutoriale za python na youtube :))
Idemo dalje, zadatak broj 43:
# Joe Palooka has fat fingers, so he always hits the “Caps Lock” key whenever he actually intends
# to hit the key “a” by itself. (When Joe tries to type in some accented version of “a” that needs
# more keystrokes to conjure the accents, he is more careful in the presence of such raffinated
# characters ([Shift] + [Char]) and will press the keys correctly.) Compute and return the result
# of having Joe type in the given text. The “Caps Lock” key affects only the letter keys from “a”
# to “z” , and has no effect on the other keys or characters. “Caps Lock” key is assumed to be
# initially off.
# Input: A string. The typed text.
# Output: A string. The showed text after being typed.
if __name__ == '__main__':
print("Example:")
print(caps_lock("Why are you asking me that?"))
# These "asserts" are used for self-checking and not for an auto-testing
assert caps_lock(
"Why are you asking me that?") == "Why RE YOU sking me thT?"
assert caps_lock(
"Always wanted to visit Zambia.") == "AlwYS Wnted to visit ZMBI."
print("Coding complete? Click 'Check' to earn cool rewards!")
Zadatak broj 44: Suglasnici i samoglasnici naizmenično
# Our robots are always working to improve their linguistic skills. For this mission, they
# research the latin alphabet and its applications.
# The alphabet contains both vowel and consonant letters (yes, we divide the letters).
# Vowels -- A E I O U Y
# Consonants -- B C D F G H J K L M N P Q R S T V W X Z
# You are given a block of text with different words. These words are separated by white-spaces
# and punctuation marks. Numbers are not considered words in this mission (a mix of letters and
# digits is not a word either). You should count the number of words (striped words) where the
# vowels with consonants are alternating, that is; words that you count cannot have two
# consecutive vowels or consonants. The words consisting of a single letter are not striped --
# do not count those. Casing is not significant for this mission.
# Input: A text as a string (unicode)
# Output: A quantity of striped words as an integer.
# Precondition:The text contains only ASCII symbols.
# 0 < len(text) < 105
Code: def checkio(text):
"tvoj kod ovde"
return rezultat
#These "asserts" using only for self-checking and not necessary for auto-testing
if __name__ == '__main__':
assert checkio("My name is ...") == 3, "All words are striped"
assert checkio("Hello world") == 0, "No one"
assert checkio("A quantity of striped words.") == 1, "Only of"
assert checkio("Dog,cat,mouse,bird.Human.") == 3, "Dog, cat and human"
assert checkio("To take a trivial example, which of us ever undertakes laborious physical exercise, except to obtain some advantage from it?") == 8
print('If it is done - it is Done. Go Check it NOW!')
Previse si se upetljao s ovim indeksima i par-nepar sistemom. Pokusaj da problem resis na nacin kako bi ga resavao pesice, da nemas kompjuter. Zadas neku rec, tipa "maramica". Treba da ispitas da li u toj reci ima dva susedna samoglasnika ili suglasnika. Algoritam bi bio:
* Uvedes varijablu kojom pratis prethodno slovo u reci (npr. 'prev_ch'). U pocetku je to prazan string ('').
* Za svako slovo u reci gledas da li je samoglasnik ili suglasnik. Ako je samoglasnik i prethodno slovo je samoglasnik - prekidas petlju.
* Slicno ako je suglasnik i prethodno slovo je suglasnik.
* U suprotnom prev_ch postavljas na vrednost tekuceg karaktera i ides dalje.
Takodje, nema potrebe da imas VOWELS in CONSONANTS u posebnim promenljivim - ako slovo nije samoglasnik ono je suglasnik, nema treceg.
I nema potrebe da pravis silne liste, zapravo novi_txt3 ti uopste nije potrebna. Cemu to?
Na kraju, mnogo puta prolazis kroz istu petlju, dok sve mozes da obavis u samo jednom prolazu.
Znaci:
Code (python):
def checkio(text):
count =0
words =re.split(r'[?,.!\s]', text.upper()) for word in words: if(len(word)<=1orre.search(r'[0-9]', word)): continue
valid_word =True
prev_ch = word[0] for ch in word[1:]: if((ch in VOWELS and prev_ch in VOWELS)or(ch notin VOWELS and prev_ch notin VOWELS)):
valid_word =False break
prev_ch = ch if(valid_word):
count +=1 return count
Moze to i krace. Posto si u kodu vec pokazao da umes da koristis regularne izraze, njihovim koriscenjem izbegavas iteraciju po slovima:
Code (python):
def checkio(text):
count =0 for word inre.split(r'[?,.!\s]', text.upper()): if(len(word)<=1orre.search(r'[0-9]', word)): continue if(notre.search('[AEIOYU]{2}', word)andnotre.search('[BCDFGHJKLMNPQRSTVWXZ]{2}', word)): # [x]{2} = najmanje dva pojavljivanja znakova iz skupa [x]
count +=1 return count
A moze i sve u jednom if-u:
Code (python):
def checkio(text):
count =0 for word inre.split(r'[?,.!\s]', text.upper()): if(len(word)>1andnotre.search(r'[0-9]', word)andnotre.search('[AEIOYU]{2}', word)andnotre.search('[BCDFGHJKLMNPQRSTVWXZ]{2}', word)):
count +=1 return count
[ a1234567 @ 22.05.2020. 17:18 ] @
Berislave, ja sam to uradio ekstenzivnom metodom da pokažem svoj raskošan talenat :)))
Ma ja sam bio prezadovoljan da sam uošte uspeo da rešim. Kako god.
Da, ta provera prethodnog slova mi je trebala, ali nisam znao kako.
Sad imam mustru.
Hvala na analizi i primerima.
Sačuvaću i proučiću, da nešto novo naučim.
To što kažeš na početku jeste vrlo važno.
Ja kad vidim zadatak, odmah krenem da kucam kod i da testiram u terminalu.
A trebalo bi prvo da napravim to što zovu pseudo kod, tj. recept, pa tek onda
da krenem da kuvam.
I tu dolazim do zadatka 45: Ukloni nepar zagrade
koji mi izgleda komplikovan, jer ne vidim jasan recept, ni kratak ni dugačak.
Prvo što mi pada na pamet je da prebrojim zagrade i stavim u rečnik.
Onda vidim kojih ima nepar, pa te uklonim. Ali nisam siguran da će to baš da radi.
Moram probati. Zavisi valjda od primera.
# Your task is to restore the balance of open and closed brackets by removing unnecessary ones,
# while trying to use the minimum number of deletions.
# Only 3 types of brackets (), [] and {} can be used in the given string.
# Only a parenthesis can close a parenthesis. That is. in this expression "(}" - the brackets
# aren’t balanced. In an empty string, i.e., in a string that doesn’t contain any brackets
# - the brackets are balanced, but removing all of the brackets isn’t considered to be an
# optimal solution.
# If there are more than one correct answer, then you should choose the one where the character
# that can be removed is closer to the beginning. For example, in this case "[(])", the correct
# answer will be "()", since the removable brackets are closer to the beginning of the line.
# Input: A string of characters () {} []
# Output: A string of characters () {} []
Code: def remove_brackets(a):
# your code here
return None
if __name__ == '__main__':
print("Example:")
print(remove_brackets('(()()'))
# These "asserts" are used for self-checking and not for an auto-testing
assert remove_brackets('(()()') == '()()'
assert remove_brackets('[][[[') == '[]'
assert remove_brackets('[[(}]]') == '[[]]'
assert remove_brackets('[[{}()]]') == '[[{}()]]'
assert remove_brackets('[[[[[[') == ''
assert remove_brackets('[[[[}') == ''
assert remove_brackets('') == ''
print("Coding complete? Click 'Check' to earn cool rewards!")
def zagrade(string):
stack = []
out = ''
stack = [i for i in string if i in o_lista]
for i in string:
if i in z_lista:
pos = z_lista.index(i) # pos == 2
if o_lista[pos] in stack:
out += o_lista[pos] + z_lista[pos]
stack.remove(o_lista[pos])
if len(stack) == 0:
return out
return out
print(zagrade('({[()}}]]()'))
Ispis: (){}[]()
[ B3R1 @ 23.05.2020. 10:51 ] @
Pa i nije bas ono sto se trazi. Tvoj program za '(())' vraca '()()', a trebalo bi '(())'.
[ a1234567 @ 23.05.2020. 11:27 ] @
Kako?
Ja sam išao logikom onoga što je dato kao primer u zadatku 45.
assert remove_brackets('(()()') == '()()'
[ djoka_l @ 23.05.2020. 12:26 ] @
Tvoje rešenje UOPŠTE ne valja.
Pre svega, ne prolazi primer 3 i 4 iz originalnog zadatka.
I stalno ponavljaš iznova iste greške.
Recimo, već sam ti nekoliko puta pisao da ne stavljaš da su varijable koje koristiš SAMO u funkciji van tela funkcije (o_lista i z_lista u zadatku 45, VOWELS, CONSONANTS u zadatku 44), dupli kod (u zadatku 44), nepotrebne varijable (44) itd.
I dalje ne znaš STRUKTURE PODATAKA. Ne znaš šta je stek. Ne znaš više da koristiš ništa osim liste, kao što sam već napisao (jedno vreme sve si stavljao u fajlove, onda si naučio directory, pa si ga za sve koristio, onda liste, pa ne korisitš ništa drugo).
Opet ti kažem, tvoje učenje pythona NE NAPREDUJE. Zadaci koje si izabrao su "cake", ti nemaš OSNOVE...
Vrati se na udžbenik i ponovo pročitaj svako poglavlje i reši sve zadatke posle tog poglavlja. Udžbenik je napisan sistematski i polako te uvodi u problematiku (ako je dobar).
Ovako, rešavaš zadatke na preskok - zidaš kuću od krova, umesto da kreneš od temelja.
Zadatak 45, je van tvojih mugućnosti rešavanja. On ne samo da je težak za tebe, ni mnogi programeri ne bi ga rešili.
Ne samo da se bavi parsiranjem izraza, koji je sam po sebi nešto što se uči znatno kasnije nego osnove nekog programskog jezika, nego je još teži od toga. Samo parsiranje bi bilo umereno teško - recimo problem da proveriš da li su zagrade pravilno uparene. Ovo je jedan nivo iznad: parsiranje + oporavak od grešaka.
[ djoka_l @ 23.05.2020. 12:57 ] @
Stek ima DVE operacije PUSH / stavi na vrh steka, POP / skini sa vrha steka. Eventualno, PEEK / vrati vrednost sa vrha steka bez uklanjanja elementa (PEEK može da se uradi i kao POP-PUSH, ako već nećeš da implementiraš PEEK). UVEK RADIŠ SAMO SA SA VRHOM STEKA.
Ti si stek koristio kao listu, vadiš element iz sredine liste - to nije stek...
[ mjanjic @ 23.05.2020. 19:44 ] @
Problem uparivanja zagrada je vrlo nezgodan, čak i ako se radi o nekom tekstu (string), da ne pričamo o programskom kodu u kome treba pronaći da li ima zagrada viška ili manjka, jer to zavisi od sintakse programskog jezika i još nekih faktora (da li je funkcija, klasa, if/else blok, itd.).
Generalno, ako postoji neki editor koji ima podršku za to, a otvorenog je koda (npr. VSC), može se pogledati kako izlazi na kraj sa tim problemom. Ali je sigurno da ceo taj kod nije baš tako jednostavan, jer može da postoji paran broj levih i desnih zagrada, kao i da ugneždavanje bude ispravno, ali da opet neki kod ne može da se kompajlira jer su zagrade na pogrešnim mestima.
A što se tiče osnova programiranja, ne znam da li je Python uopšte pogodan za učenje programiranja u smislu algoritama, struktura podataka itd.
Ne uči se tek tako Pascal (ne znam da li ima i danas smisla) ili C na mnogim fakultetima na 1. godini.
C se možda i ne koristi toliko za razvoj aplikacija danas, možda više za neko embeded programiranje, kontrolere i sl., ali su mnogi jezici kasnije preuzeli sličnu sintaksu i koriste slične ili čak iste algoritme za pojedine probleme.
Ja sam imao (ne)sreću da sam studirao nešto levo, računarima se bavio na neki drugi način, tj. nisam se toliko zanimao za programiranje iako sam C i C++ naučio relativno dobro za neko osnovno programiranje što se tiče sintakse još pre 20-ak godina (relativno kasno, za današnje pojmove, ali tamo krajem 90-ih je reko ko imao računar kod kuće, tako da...), radio nešto totalno drugo sa drugim alatima, ali sam recimo pročitao "Programming Pearls" i još dosta sličnih knjiga u jednom dahu (više su me zanimali algoritmi i rešavanje problema sa matematičke tačke gledišta nego sama sintaksa jezika), knjiga je čak dostupna ovde: https://tfetimes.com/wp-conten...15/04/ProgrammingPearls2nd.pdf
djoka je potpuno u pravu, ako neko ne želi da na ispravan način recimo koristi ulančane/povezane liste ili dvostruko povezane liste, stek, binarno stablo, svoju implementaciju pretrage ili sortiranja, ili bilo šta drugo, nego nabudži neki kod bez pravilnog znanja o koracima pri rešavanju takvim problema, to je potpuno pogrešan put čak i za učenje sintakse nekog jezika, jer se na pogrešan način uči "programiranje", i tu naviku kasnije bude vrlo teško promeniti.
A mogu i da se uzmu primeri iz zbirki zadataka za C/C++, Javu i slično, pa da se za ta rešenja prvo uradi slično/isto Python rešenje, a da se potom kod "optimizuje" korišćenjem onoga što Pythong pruža, a čega nema u tim drugim jezicima.
[ djoka_l @ 23.05.2020. 22:38 ] @
Evo rešenje, moj kohai, i slušaj šta ti kaže senpai.
Ovaj zadatak bi bio piece of cake da je trebalo da se samo proveri da li su zagrade pravilno uparene.
Bio bi tek malo teži da je izraz trebalo DOPUNITI nedostajućim zagradama.
Moje rešenje radi ono što je bio zadatak i ne samo što daje rešenje koje se dobije tako što se izbace znaci koji su najbliži početku, nego i daje najduže takvo rešenje.
Code: # Class Stack implements stack as a list of items
class Stack:
def __init__(self):
self.items = []
def isEmpty(self):
return self.items == []
def push(self, item):
self.items.append(item)
# Warning: pop from the empty stack raises exception IndexError
def pop(self):
return self.items.pop()
# myTranslate removes non-allowed characters from a string
# Parameters:
# inString (string) input string
# allowed (string) characters that are allowed
# Output (string):
# string that contains only allowed characters from the inString
def myTranslate( inString, allowed ):
# find ALL unique characters in input string (by convarting it into set)
s=set(inString)
for i in s:
if i not in allowed:
# remove not-allowed characters
inString = inString.replace(i,'')
return inString
# myTrim removes from string leading 'left' characters and trailing 'right' characters
# Parameters:
# inString (string) input string
# Left (string) leading characters to be removed
# Right (string) trailing charactes to be removed
# Output (string):
# left and right trimmed string
def myTrim( inString, Left, Right ):
start = 0
# find the position of the FIRST character not in "Left" and remove leading "Left" characters
for i in range(len(inString)):
if inString[i] not in Left:
break
else:
start+=1
inString = inString[start:]
# Find trailing "Right" characters and remove them from string
end = 0
for i in range(len(inString)):
if inString[-1-i] not in Right:
break
else:
end-=1
if end == 0:
return inString
return inString[:end]
# removeChar deletes a single character from string at given position
# Parameters:
# inString (string): input string
# pos (int): character position 0..len(inString)-1
def removeChar( inString, pos):
return (inString[:pos] + inString[pos+1:])
def remove_brackets(a):
# First, lets define some constants
OPENING = '([{' # List of opening brackets
CLOSING = ')]}' # List of closing brackets
BRACKETS = OPENING + CLOSING # List of all brackets
PAIRS = ['{}', '[]', '()'] # List of bracket pairs
# Local function isValid
# Parameters:
# expression (string): string that contains only brackets
# Output (Boolean):
# True if all opening brackets are matched with corresponding closing brackets in order of apperance
# False otherwise
# Require: Function uses class Stack
def isValid(expression):
s=Stack()
for i in (expression):
if i in OPENING:
# opening bracket shuld be pushed to the stack
s.push(i)
else:
# Closing bracket MUST be mached with the opening bracket from the non-empty stack top
if s.isEmpty() or (s.pop() + i not in PAIRS):
# If pair of brackets are not mached, then expression is invalid
return False
# if ALL brackets are matched, stack MUST be empty
if s.isEmpty():
return True
# otherwise, brackets are unbalanced
return False
a=myTranslate( a, BRACKETS ) # Remove all non-breacket symbols from input string
a=myTrim( a, CLOSING, OPENING) # Remove closing brackets from the left side and opening brackets from the right side
# of the input string, since they can not be matched with correcponding bracket
# Now we have 'clean' string
checkList = [] # list of potentionally valid bracket expressions
# expression with balanced brackets MUST have even length, otherwise its useless to check if its valid
if len(a)%2 == 1:
for i in range(len(a)):
# for odd expression length, add to checkList each substring derived from originall string by removing single character from expression
checkList.append( removeChar( a, i ) )
else:
checkList.append(a)
# Main loop - checking elements from the checkList
# The first valid string is the result of the function.
# In case that we checked ALL elemnts from checkList, return empty string
while checkList != []:
i = checkList[0]
if isValid(i):
# Qapla' (success in Klingon)!!! We made it!!!
return i
else:
# remove the first (checked) element
checkList.pop(0)
# generate all substrings of checked element by removing TWO characters from the expression
# and adding resulting string to the end of list
for j in range(len(i)-1):
for k in range(j+1, len(i)):
newstring = removeChar( i, k )
newstring = removeChar( newstring, j )
if newstring not in checkList:
checkList.append( newstring )
# we chacked all posible substrings without success
return ''
if __name__ == '__main__':
print("Example:")
print(remove_brackets('(()()'))
# These "asserts" are used for self-checking and not for an auto-testing
assert remove_brackets('(()()') == '()()'
assert remove_brackets('[][[[') == '[]'
assert remove_brackets('[[(}]]') == '[[]]'
assert remove_brackets('[[{}()]]') == '[[{}()]]'
assert remove_brackets('[[[[[[') == ''
assert remove_brackets('[[[[}') == ''
assert remove_brackets('') == ''
print("Coding complete? Click 'Check' to earn cool rewards!")
// zapamti visited string
HashSet<string> visit = new HashSet<string>();
// queue
Queue<string> q = new Queue<string>();
string temp;
// pushing string kao start node u queue
q.Enqueue(str);
visit.Add(str);
while (q.Count != 0)
{
str = q.Peek(); q.Dequeue();
if (IsValidString(str, lParen, rParen))
{
return;
}
for (int i = 0; i < str.Length; i++)
{
if (!IsBracket(str[i], lParen, rParen))
continue;
// remove zagradu iz str i gurni u queue ako nije obradjen ranije
temp = str.Substring(0, i) +
str.Substring(i + 1);
if (!visit.Contains(temp))
{
q.Enqueue(temp);
visit.Add(temp);
}
}
}
}
Have you ever heard of such markup language as YAML? It’s a friendly data serialization format.
In fact it’s so friendly that both people and programs can read it quite well. You can play around
with the standard by following this link.
YAML is a text, and you need to convert it into an object. But I’m not asking you to implement
the entire YAML standard, we’ll implement it step by step.
The first step is the key-value conversion. The key can be any string consisting of Latin letters and numbers.
The value can be a single-line string (which consists of spaces, Latin letters and numbers) or a number (int).
I’ll show some examples:
name: Alex
age: 12
Converted into an object.
{
"name": "Alex",
"age": 12
}
Note that the number automatically gets type int
Another example shows that the string may contain spaces.
name: Alex Fox
age: 12
class: 12b
Will be converted into the next object.
{
"age": 12,
"name": "Alex Fox",
"class": "12b"
}
Pay attention to a few things. Between the string "age" and the string "class" there is an empty string that doesn’t interfere with parsing.
The class starts with numbers, but has letters, which means it cannot be converted to numbers, so its type remains a string (str).
Input: A format string.
Output: An object.
Precondition: YAML 1.2 is being used with JSON Schema.
Code: def yaml(a):
# your code here
return None
if __name__ == '__main__':
print("Example:")
print(yaml("""name: Alex
age: 12"""))
# These "asserts" are used for self-checking and not for an auto-testing
assert yaml("""name: Alex
age: 12""") == {'age': 12, 'name': 'Alex'}
assert yaml("""name: Alex Fox
age: 12
YAML sam ti vec pomenuo u ovom postu. Puna specifikacija je prilicno slozena, zato i postoji 'yaml' modul kojim se sve to resava. Ali dobro, poenta je ovde vezbanje pythona. Par napomena:
Code (python):
a =[i for i in a iflen(i)!=0]
a =sorted(a)
Cemu ovo gore? Primecujem da bas u svaki program ubacujes "list comprehension", cak i tamo gde tome nije mesto. S druge strane, onda jos i sortiras kljuceve. To su dva nepotrebna koraka kojima samo usporavas program. Ispitivanje da li je red prazan si mogao da ubacis i u "for" petlju, nakon linije 7. Nema potrebe prolaziti vise puta kroz petlju.
Druga stvar: tvoj program (linije 10-12) ne radi ono sto se trazilo u zadatku:
Citat:
The value can be a single-line string (which consists of spaces, Latin letters and numbers) or a number (int).
Ti umesto toga ispitujes da li je kljuc == 'age' i ako jeste konvertujes njegovu vrednost u int, dok npr. 'class' moze da bude isto tako int ... Ti treba da ispitas da li je vrednost (desno od dvotacke) int ili str i ako je int treba da primenis int() funkciju.
[ a1234567 @ 26.05.2020. 16:13 ] @
Berislave, hvala na komentarima.
Bio sam pod utiskom da treba sortirati, jer se redosled ulaznih i izlaznih podataka razlikuje.
Evo sad sam napravio apdejtovanu verziju i sve radi.
Code: def yaml(a):
recnik = {}
b = []
a = a.split('\n')
a = sorted(a)
for i in a:
if len(i) != 0:
b = i.split(':')
recnik[b[0]] = b[1].strip()
for k, v in recnik.items():
if v.isdigit():
recnik[k] = int(v)
else:
recnik[k] = v
return recnik
[ B3R1 @ 26.05.2020. 17:42 ] @
Dobro, to je vec bolje. Ali moze jos bolje. Opet imas dve petlje, a sve mozes da uradis u jednom potezu. Lepo si razdvojio kljuc i vrednost koristeci split(). Zasto nisi odmah ispitao da li je b[1] numericki podatak ili ne. I ako jeste, da ga odmah prebacis u int. Takodje, strip() je trebalo da primenis ranije, jer u suprotnom 'if len(i)' ce proci takve redove i imaces gresku kod funkcije split(). Znaci:
for i in a:
i = i.strip()
if len(i) and (':' in i):
b = i.split(':')
if b[1].isdigit():
b[1] = int(b[1])
recnik[b[0]] = b[1]
return recnik
Cilj kodiranja je da sa manje prostijih alata postignes sto vise i napravis sto brzi i efikasniji program, a ne da hiltijem busis rupetinu u zidu samo da bi okacio nesto tesko 50 grama, sto si mogao da zavrsis i obicnim cekicem i ekserom.
Vezano za "less is more", evo ti jedne mozgalice, nije tesko: data je celobrojna pozitivna (int) varijabla n, n >= 0. Napisi program koji umanjuje n za 1 ako je n neparno, a uvecava ga za 1 ako je parno, ali tako da koristis sto manje karaktera (razmaci se ne broje, kao ni unos i ispis, treba mi samo kod koji ispituje i menja vrednost n). Na primer, ako je n = 49, kod treba da vrati 48, ako je npr. 62 kod treba da vrati 63. Da vidimo koliko ti karaktera treba da napravis taj kod. Mozes da koristis sve strukture podataka, sve operatore, sve module ... sve sto Python ima. I sve alate. Ukljucujuci i hilti ... :-)))
[ djoka_l @ 26.05.2020. 19:59 ] @
Citat:
Bio sam pod utiskom da treba sortirati, jer se redosled ulaznih i izlaznih podataka razlikuje.
Imao si pogrešan utisak. Ako nisi siguran, proveri:
Code: py
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> print( {"age":20, "sex":"male"} == { "sex":"male", "age":20} )
True
>>>
[ a1234567 @ 28.05.2020. 13:08 ] @
Citat:
B3R1:
Vezano za "less is more", evo ti jedne mozgalice, nije tesko: data je celobrojna pozitivna (int) varijabla n, n >= 0. Napisi program koji umanjuje n za 1 ako je n neparno, a uvecava ga za 1 ako je parno, ali tako da koristis sto manje karaktera (razmaci se ne broje, kao ni unos i ispis, treba mi samo kod koji ispituje i menja vrednost n). Na primer, ako je n = 49, kod treba da vrati 48, ako je npr. 62 kod treba da vrati 63. Da vidimo koliko ti karaktera treba da napravis taj kod. Mozes da koristis sve strukture podataka, sve operatore, sve module ... sve sto Python ima. I sve alate. Ukljucujuci i hilti ... :-)))
Ovako nešto?
Code: if n % 2 == 0:
print(n + 1)
else:
print(n - 1)
[ djoka_l @ 28.05.2020. 14:04 ] @
Code: n+=1-(n%2)*2
[ B3R1 @ 28.05.2020. 17:15 ] @
@a1234567:
Ti si iskoristio 29 karaktera i resio si ga bas skolski ... Ideja je bila da uradis sa sto manje karaktera.
Djoka je iskoristio 12 karaktera i pokazao ono sto sam hteo da kazem: ponekad kada resavas probleme moras da zaviris i ispod haube, gde se nalazi matematika. Kao sto su ti ljudi rekli: strukture podataka, matematicke operacije ...
Medjutim, ima i jos krace resenje ... zahteva svega 4 znaka. Ali da bi to resio treba se podsetiti cinjenice da su svi brojevi kojima Python i ostali jezici barataju zapravo nizovi jedinica i nula. Na primer, broj 12 je zapravo 1010 (binarno), dok je 13 zapravo 1011. U cemu se razlikuju? Kao sto vidis, samo u poslednjem bitu - parni broj ima 0, neparni 1. U opstem slucaju svaki integer mozes da predstavis kao niz bita u formi bb...bb0 ili bb...bb1, gde je deo "bb...bb" zajednicki u oba slucaja. Tebi treba operacija koja te vodece 'b' bite nece dirati, dok ce poslednji bit kao je 0 pretvoriti u 1 i obrnuto - ako je 1 da ga pretvori u 0. Za manipulacije na nivou bita u Pythonu zaduzeni su bitwise operatori. Ako uzmes XOR (^) videces da on daje rezultat koji tebi treba.
bbbbb0 ^ 000001 = bbbbb1
bbbbb1 ^ 000001 = bbbbb0
Shodno tome:
n=n^1
odnosno:
n^=1
Isti problem, nekoliko resenja, izbegavanje nepotrebnih koraka. Kao sto smo vec to rekli: osnovna aritmetika, logika, strukture podataka, pocev od najprostijih kakvi su celi brojevi, preko slozenijih (liste, hash tabele) do onih najslozenijih (ulancane liste, stabla ...). Jednom kada to savladas shvatices koju alatku kada koristiti i zasto.
[ a1234567 @ 28.05.2020. 18:01 ] @
Shvatam tvoju poentu. Pojednostavljivanje. I to je nešto čemu treba težiti.
Ali ja sam još na nivou da sam srećan ako uopšte znam kako da rešim neki zadatak.
Mnogo je onih za koje ne znam ni kako da krenem.
Verovatno ću kroz praksu doći i do nivoa da razmišljam o pojednostavljivanju.
Kad nešto uradiš sto puta, prirodno je da kreneš da razmišljaš, hej, jel može
to nekako jednostavnije!? Kao što je bilo sa ovim for petljama. Već sam ih toliko
napisao, a onda naiđem na list comprehension i vidim, može i tako. Super,
umesto tri reda, napišem jedan i idemo dalje.
Sve je to praksa. Ali meni još ostaje mnogo rada da uošte celu sintasu jezika
ili bar njene glavne delove prođem tih 100 puta, pa da onda krenem da
mozgam o pojednostavljivanju. U ovom trenutku mi je mnogo realniji zadatak
da recimo eliminišem primere kakav je bio poslednji zadatak, da ne prolazim petlju
dva puta ako može samo jednom. Već to će biti veliki korak za mene :)
[ B3R1 @ 29.05.2020. 13:23 ] @
Citat:
Shvatam tvoju poentu. Pojednostavljivanje. I to je nešto čemu treba težiti.
Da, ali nije sve samo u tome, vec u tome da ti se fragmenti znanja koje usvajas svakim danom sloze na pravom mestu u glavi. Ti si naucio prve engleske reci i odmah si uzeo Šekspira. Ili još gore, uzeo si Čoserove Kenterberijske priče, koje svega 5% visoko obrazovanih rodjenih Engleza ume da procita i uopste shvate sta su tu procitali. Na tom nivou mozda ces i uspeti da shvatis neka poglavlja, ali da sklopis celinu od svega toga - hm, tesko.
Tako je to i u programiranju. Cilje je da savladas dobro osnove, tako da kada ti se pojavi problem tacno znas da li da koristis listu, recnik ili mozda najobicniji int/float/str ... stvari tipa "list comprehension" su trikovi, ali oni ti nece pomoci ako ne shvatis OSNOVE. A osnove su da su brojevi nizovi jedinica i nula. Da je svako slovo ('A', 'B', 'C' itd. takodje niz jedinica i nula kodirana ASCII kodom. Recimo, 'A' je 65 (decimalno), odnosno 01000001, 'B' je 66 (odnosno 01000010) itd. Koliko slova ima izmedju A i M, ne racunajuci sama slova A i M? Kako ces to prebrojati? Da, verovatno ces reci:
dok ce neko ko je ucio programiranje od temelja, kako i dolikuje, znati da kaze:
Code: broj = ord('M') - ord('A') - 1
Zato sto zna da je svako slovo interno predstavljeno ASCII kodom i da se ASCII kod slova x dobija funkcijom ord(x), a karakter ciji je ASCII kod n se dobija funkcijom chr(n).
Kada naucis te stvari, na redu su slozenije. Recimo, upravljanje datumima i vremenom. Koliko je dana proteklo od Bozica do Uskrsa ove godine? Ili - zadatak sa casova programiranja iz srednje skole iz vremena mog skolovanja: ispisati vremena u toku dana (hh:mm:ss) kada se kazaljke na satu poklope. Ideja je da naucis manipulaciju vremenima i module time i datetime. A mozes i pesice, koristeci samo int i float ... Moja preporuka bi bila da pocnes od tog "pesackog" nacina.
Onda dolaze na red liste. Taman mislis da si naucio liste i krenes:
Code:
>>> a = [1, 2, 3]
>>> b = a
>>> b
[1, 2, 3]
Bas lepo radi. Ali onda u listu a dodas jos jedan element:
WTF?! Zasto? Kako?! Odakle???!!! Pa ja sam azurirao listu a, listu b nisam ni taknuo - zar ne? A pazi sad ovo - hocu da izbrisem treci element liste b:
Code:
>>> del b[2]
>>> b
[1, 2, 10]
>>> a
[1, 2, 10]
Hmmm ... izgleda da sam ja nekako "vencao" ove dve liste, pa kud svi Turci tu i mali Mujo? E vidis, tu vec moras da zaviris malo i ispod haube. Neke slozenije strukture u Pythonu (liste, skupovi i recnici) se ponasaju malcice drugacije od nekih drugih (int, float, str, bool ...). Eventualno, naici ces na neko brzinsko objasenjenje, poput ovog ovde. Ok, covek je to objasnio na bazicnom nivou, cisto da ukapiras da kada imas listu a, pa kazes b=a, ti zapravo ne kopiras VREDNOST liste a u listu b, vec postavis POINTER liste b tamo gde je a. Ako ti treba kopija liste to mozes da uradis na vise nacina, covek je to lepo objasnio - npr:
Code: a = [1,2,3]
b = list(a)
Ovim si dobio dve nezavisne liste, sto mozes da proveris i ako u Python shellu otkucas id(a), odnosno id(b). Tako, da ako sada dodajes elemente listi a lista b se nece menjati. Identicno se ponasaju i recnici, odnosno hash tabele:
Code: >>> a={'name': 'John'}
>>> b=a
>>> a
{'name': 'John'}
>>> b
{'name': 'John'}
>>> a['surname']='Doe'
>>> a
{'surname': 'Doe', 'name': 'John'}
>>> b
{'surname': 'Doe', 'name': 'John'}
Ali zato:
Code:
>>> a={'name': 'John'}
>>> b=dict(a)
>>> a
{'name': 'John'}
>>> b
{'name': 'John'}
>>> a['surname']='Doe'
>>> a
{'surname': 'Doe', 'name': 'John'}
>>> b
{'name': 'John'}
I time si shvatio stvar ... mozda ... onako povrsno. Da bi shvatio stvari do kraja moras da se udubis jos vise u nacin na koji je Python implementiran. Lep tekst na tu temu je dat ovde.
Kada to ukapiras, onda ces umeti da objasnis razliku izmedju ovog koda:
>>> def modint(x):
... x += 1
...
>>> y = 3
>>> y
3
>>> modint(y)
>>> y
3
>>>
Iskusniji programeri, koji su vec prosli kroz nekoliko drugih, klasicnih programskih jezika, znaju za princip prenosa argumenata po vrednosti i po imenu (referenci, deskriptoru ...). U prvi mah ce shvatiti da Python prenosi skalare (bool, int, float ...) po vrednosti, a vektore (lists, dicts, sets) po referenci. Kasnije, kada se udubi u materiju, shvatice zasto je to tako. Odgovor je dat i ovde. Opet - rec je o PRINCIPU koji se uci. Jednom kada to savladas, shvatices kako to radi i u nekim drugim jezicima.
Ovo sto sam ti opisao gore su tek samo mali detalji. Kockice mozaika ... A ti detalji mogu da ti upropaste program koji pises do te mere da ga analiziras danima i uopste ne kapiras zasto ne radi ... a u pitanju su neke banalne stvari koje nisu naucio u pocetku, jer si krenuo da ucis Python s krajeva.
Mislim da je sada vreme da malo iscitas poglavlja o strukturama podataka i shvatis kako stvari funkcionisu u Pythonu. Usput mozes da radis i zadatke iz te zbirke, ali bez solidnog razumevanja teorije tapkaces u mestu ...
Nemoj ovo da shvatis kao neko pametovanje. Svi smo prosli manje-vise kroz tu istu metodu uzaludnih pokusaja u svojim prvim programerskim koracima. Pre ili kasnije smo shvatili da smo izgubili dosta vremena, pa smo seli i ucili ...
[Ovu poruku je menjao B3R1 dana 29.05.2020. u 16:28 GMT+1]