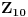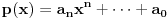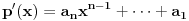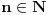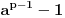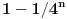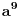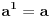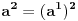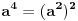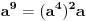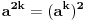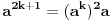[ Jorgovan88 @ 15.11.2025. 00:01 ] @
| Jedan od delova mog master rada ce biti security i tu sam se bio dotakao ove krive koju inace koristi i bitcoin.... E sad ono sto je mene onako zaintrigiralo jeste da koji god algoritam (BSGS ili Pholard's Rho ili Kengur) da se koristi za resavanje (pronalazak javnog privatnog kljuca od javnog kljuca) uvek se resenje svodi na rodjendanski paradoks tj Birthday paradox... pa samim tim ukoliko npr je potrebno skenirati 1.000.000 kljuceva da bi se doslo do resenja - potrebno je da poznati i nepoznati skener obave oko 1000 iteracija... i tada ce doci do nekog sudara koji ce dati resenje (u prevodu dvoje random ljudi u autobusu imace isti rodjendan ukoliko je u autobusu oko 23je ljudi jer ukupan broj dana je 365 ako izostavimo 29ti februar kao extremni slucaj) Ovo nas dovodi do algoritma koji ima vremensko resenje koren iz N tj O(sqrtN) E sad da li mislite da je moguce napraviti brzi algoritam? (ne koristeci naravno Shorov algoritam koji zahteva Kvantni racunar) Hvala |