|
|
[ MajorFatal @ 04.02.2005. 04:32 ] @
|
| Evo kako bi se mogli kompresovati/dekompresovati fajlovi:
1. Utvrdim velicinu fajla koji treba da se kompresuje i oznacim je sa N
2. napravim generator koji moze da generise sve fajlove koji su iste velicine kao i zadati fajl
3. napravim brojac koji moze da broji do 2^N
I. Prilikom kompresije:
Pustim generator da generise fajlove redom pocev od fajla koji sadrzi sve nule pa sve do fajla koji sadrzi sve jedinice, usput generisane fajlove poredim sa fajlom koji treba da se kompresuje. Kada dodje do poklapanja sa zadatim fajlom zaustavljam brojac i kao kompresovan fajl pamtim sledece podatke: a)Duzinu ulaznog fajla i b)Stanje na brojacu u trenutku poklapanja.
II. Prilikom dekompresije:
Na osnovu podataka iz kompresovanog fajla ponovo pravim generator fajlova koji moze da generise sve fajlove velicine kao i fajl koji treba da dekompresujem. Pustam generator u rad da generise sve fajlove redom pocev od fajla koji sadrzi sve nule i usput prebrojavam generisane fajlove. Generator zaustavljam u trenutku kad izgenerise "moj" pocetni fajl tj. kad stanje na brojacu bude identicno onom stanju koje sam "upamtio" u kompresovanom fajlu. Snimim fajl.
PS. Bog mi je dosapnuo
|
[ zi:: @ 04.02.2005. 04:49 ] @
Stanje na brojacu ce ti zauzeti isto toliko mesta kao i sam file, pa je bolje da ga zipujes ;)
[ random @ 04.02.2005. 07:12 ] @
Citat: zi::: Stanje na brojacu ce ti zauzeti isto toliko mesta kao i sam file, pa je bolje da ga zipujes ;)
Sušta istina :o)))). Bravo, slatko si me nasmejao. [ jablan @ 04.02.2005. 08:24 ] @
Trebalo je da pustite čoveka da iskodira. Ne bi ga napravio, ali bi se malo trenirao. 
Uzgred, brojač bi u trenutku kad pronađe dati fajl bio identičan tom fajlu, jer svaka sekvenca bajtova nije ništa drugo nego "brojač" same sebe. [ caboom @ 04.02.2005. 09:08 ] @
Citat: MajorFatal:
PS. Bog mi je dosapnuo
po Szasz-u se ovo naziva shizofrenija... [ Ivan Dimkovic @ 04.02.2005. 09:21 ] @
[ diff @ 04.02.2005. 11:15 ] @
To se kanda bog igrao gluvih telefona ;)
[ MajorFatal @ 05.02.2005. 06:04 ] @
Mozda sam bio malo konfuzan prilikom prvog javljanja pa:
Citat: zi::: Stanje na brojacu ce ti zauzeti isto toliko mesta kao i sam file, pa je bolje da ga zipujes ;)
Kao "brojac" istancovanih fajlova od strane generatora mislim da bi mogla da se iskoristi bilo koja "jaca" varijabla tipa Double, Extended. Broje do1.1*10^4932 tj. to je zapis od 19-20 cifara, a zauzima 10 bajtova na disku i to bi bilo sacuvano u kompresovanom fajlu kao drugi podatak (pored duzine fajla). Citat: jablan:
Uzgred, brojač bi u trenutku kad pronađe dati fajl bio identičan tom fajlu, jer svaka sekvenca bajtova nije ništa drugo nego "brojač" same sebe.
Ovde se mozda nismo najbolje razumeli. Nisam pominjao da brojac "trazi" ili "pronalazi" dati fajl. U ovoj poruci sam objasnio sta podrazumevam pod brojacem. Kod mene generator je taj koji stancuje fajlove po redu i ciji bi se sadrzaj u odredjenom trenutku poklopio sa sadrzajem pocetnog fajla. Ako bi bio konstruisan onako kako ja mislim da bi mozda moglo tj. kao string boolean varijabli zauzimao bi i vise nego pocetni fajl tj. posto je boolean verijabla velicine 1 bajt tj. 8 bita, generator bi u trenutku pronalazenja zadatog fajla zauzimao 8 puta vise tj. za svaki bit jos 8 bitova, ali to je samo priveremeno. Kad odrade posao i generator i brojac se brisu i ostaje samo zapis kompresovanog fajla koji je dovoljan da se fajl kasnije regenerise tj. dekompresuje u ovom slucaju ponovo napravi. Citat: jablan: Trebalo je da pustite čoveka da iskodira. Ne bi ga napravio, ali bi se malo trenirao. :)
Nije dosta sto sam otkrio resenje, sad jos i da kodiram? ;)
Napravicu ako se bas niko ne prihvati posla ali sa mojim znanjem Delphi-ja to ce biti dugooootrajan proces.
Citat: caboom: po Szasz-u se ovo naziva shizofrenija...
Ne, nego Vera.
Dakle jos jednom ali natenane:
Hocu da kompresujem fajl npr: 11010010
Na osnovu duzine fajla (8) program mi pravi generator koji stancuje sve redom fajlove duzine 8 bita
00000000
00000001
..
Brojac (varijabla) ih broji.
U trenutku kad generator istancuje fajl 11010010 zapisujem da je to npr. 175-ti fajl po redu.
Zapis kompresovanog fajla izgleda otprilike ovako 8/175 sto mi je dovoljno da fajl kasnije "regenerisem" tj. ponovo napravim po sledecem postupku:
Program iscita kompresovani fajl 8/175 napravi generator, pusti ga u rad i zaustavi kod 175 tog po redu fajla koji ovaj izgenerise - sto je ujedno i moj pocetni fajl.
U ovom primeru naravno nismo imali kompresiju jer 8 bita zauzima manje mesta od zapisa 8/175 (40 bita) ali kod vecih fajlova?
Vec fajl velicine oko 1KB zapisujem npr: kao 8976/2^6000 + 274 sto je zapis koji zauzima 136 bita. Dakle umesto 8976 bita - 136 bita
itd..
Sa jos vecim fajlovima jos vece iskoriscenje..
[ Alef @ 05.02.2005. 08:35 ] @
Grešiš, ovaj grešiš silno sine!
Zaista će ti za datoteku od 1kb u najboljem slučaju trebati samo jedan bajt da bi je kodirao, ali u najgorem (ako su sve jedinice) će ti trebati 2409, tako da si dobio ekspanziju sa faktorom 2.5.
Code:
>>> x = 1000*8 # u bitovima
>>> y = 2**x # 2^x
>>> print y
173766203193809456599982445949435627061939786100117250547173286503262376
022458008465094333630120854338003194362163007597987225472483598640843335
685441710193966274131338557192586399006789292714554767500194796127964596
906605976605873665859580600161998556511368530960400907199253450604168622
770350228527124626728538626805418833470107651091641919900725415994689920
112219170907023561354484047025713734651608777544579846111001059482132180
956689444108315785401642188044178788629853592228467331730519810763559577
944882016286493908631503101121166109571682295769470379514531105239965209
245314082665518579335511291525230373316486697786532335206274149240813489
201828773854353041855598709390675430960381072270432383913542702130202430
186637321862331068861776780211082856984506050024895394320139435868484643
843368002496089956046419964019877586845530207748994394501505588146979082
629871366088121763790555364513243984244004147636040219136443410377798011
608722717131323621700159335786445601947601694025107888293017058178562647
175461026384343438874861406516767158373279032321096262126551620255666605
185789463207944391905756886829667520553014724372245300878786091700563444
079107099009003380230356461989260377273986023281444076082783406824471703
499844642915587790146384758051663547775336021829171033411043796977042190
519657861762804226147480755555085278062866268677842432851421790544407006
581148631979148571299417963950579210719961422405768071335213324842709316
205032078384168750091017964584060285240107161561019930505687950233196051
962261970932008838279760834318101044311710769457048672103958655016388894
770892065267451228938951370237422841366052736174160431593023473217066764
172949768821843606479073866252864377064398085101223216558344281956767163
876579889759124956035672317578122141070933058555310274598884089982879647
974020264495921703064439532898207943134374576254840272047075633856749514
044298135927611328433323640657533550512376900773273703275329924651465759
145114579174356770593439987135755889403613364529029604049868233807295134
382284730745937309910703657676103447124097631074153287120040247837143656
624045055614076111832245239612708339272798262887437416818440064925049838
443370805645609424314780108030016683461562597569371539974003402697903023
830108053034645133078208043917492087248958344081026378788915528519967248
989338592027124423914083391771884524464968645052058218151010508471258285
907685355807229880747677634789376
Što je sve, samo ne broj od 19-20 cifara  .
A da ne pričam o tome da će ti za datoteku veličine 1kb sa procesorom od
3 GHz trebati, u najgorem slučaju:
Code:
629724589381059130970437218052604287388344517286791514630620013420534811
997021122218940108828444061527879953475983937080478457173601502648558873
977827463194775219726529525232247586456437242569235223237641502239489008
141646650017662049212077263760232501671988587955355900555386861651694653
802820281681251818252296248479447827317922921981742117491938160450423715
707107236743580348461564278559519223931321220354351837758212145691571287
079399304589098301810691411336445562911696717505498774119445570644196484
543313822883575808623262669859991699542227642855223525094336106544774984
581119383436683986864939086487027517998429723079409781859368519391220878
458464788919160113994341919948812897587812829855883104709511858122064326
254393425608215803659407045774743991391266398582646206857068333219122431
845212736450278886882727998912363509623578342208430798367418961176266879
139926672784379806445442358894121853460912327448141694340956042537500948
063791828409522438574180386266744951611225969504631036794292448280650312
297822085903977092392771640634801617646151454378112133531027108268705534
484994793099747741921275954300454883500089600537237446107074333915211437
555653761719951367073843813833660858425694075818815960291307555354322329
128957899962266399022920772818959004766746473252051291625149659263036132
926208095103298637919405506831504233032058667383642939955866458448963566
649085424292051066534094237698699756178739662266319023466019152144340495
053388701834343517036377345017251160542535194466260529483539719624541755
317322501021993325649637001950065392156667280774982503819521109720913585
456592249284087950057807386523964779901618961274771441592460220399604131
959664306812508539824142444925941788303247391103947294913185047317413799
654199788936453417538857423998413209650406097540444569829977857443211016
793579272653191646968324755012712702523644909236936551594823635053814285
874821105775209568867593102332150288150963618081009289248858174427287668
134792270690573206470392067608015834614819759835578763680032738302874300
145990906522930020695454293238035250866484130876832960498804986001100444
386624105291281118475919546324231134568378136143500097189389232895012823
234655380320393651934406421794653487937821981479203957287828523222088221
461578796240650623607335087038820349528732130466863734104934146988357066
715005407070828527629496962281236951746642911691158288580888992068052061
7079269254447701 godina
256 dana
14 h
0 min
51 s
Ukoliko ti je poređenje stringova jedna procesorska instrukcija  .
[ sspasic @ 05.02.2005. 08:47 ] @
Citat:
U trenutku kad generator istancuje fajl 11010010 zapisujem da je to npr. 175-ti fajl po redu.
Fajl je 210. po redu, ako brojiš od nule. Binarni zapis broja 210 je... 11010010. Dakle, brojač je jedak samom fajlu.
Pročitaj ipak link koji ti je dao Ivan.
[ negyxo @ 05.02.2005. 09:54 ] @
Citat:
Kao "brojac" istancovanih fajlova od strane generatora mislim da bi mogla da se iskoristi bilo koja "jaca" varijabla tipa Double, Extended. Broje do1.1*10^4932 tj. to je zapis od 19-20 cifara, a zauzima 10 bajtova na disku i to bi bilo sacuvano u kompresovanom fajlu kao drugi podatak (pored duzin0e fajla).
Pa ti bi sve kombinacije da svedes na 16 bajtova a to je ne moguce. Zdrav razum ti valda govori da onaj broj sto si naveo da je konacan a kombinacija je beskonacno.
[ jablan @ 05.02.2005. 11:22 ] @
Nego, da ti nisi iz Leskovca, možda? [ kobrejabre @ 05.02.2005. 12:24 ] @
Ma to se opet Marko Tasic javlja sa usavrsenom verzijom svoje prethodne savrsene kompresije.
Ova kompresija je jos genijalnija jer sve informacije ovoga sveta moze da smesti u jedan double...
Sta li je sledece? Dokaz da se ni iz cega moze napraviti sve? Nova teorija nastanka univerzuma?
[ Dusan Marjanovic @ 05.02.2005. 15:29 ] @
Citat: jablan: Nego, da ti nisi iz Leskovca, možda? ;)
Ja znam na šta si ciljao, pa se ne vređam, ali neki drugi korisnik ni kriv ni dužan, a igrom slučaja iz Leskovca, mogao bi da se uvredi zbog ovakve izjave. [ zi:: @ 05.02.2005. 16:42 ] @
Ja inace na ovu pretpostavku gledam sasvim pozitivno: drago mi je da vidim da neko razmislja, dodje do (na zalost jako pogresnog) zakljucka, i kasnije bude sretan zbog toga i odluci to podeliti sa drugima. Vazno da se istrazuje, ali, izgleda da je jos vaznije da se pre toga nesto i nauci. Knjiga, hvala Bogu, ima dovoljno.
Naslusao sam se mnogo slicnih primera, npr. kada je prijatelj u srednjoj skoli odusevljeno pricao da je smislio podmornicu od obicnog metala koja moze da ide na proizvoljnu dubinu u moru, ili pametnih likova koji su se ubijali da dokazu (pa su na kraju i 'dokazali') da je pisac neke fakultetske matematicke knjige pogresio u nekoj onovnoj teoremi i slicno.
Ja sam takodje upao u slicnu zamku: setajuci pored reke, nadosao sam na jednostavan dokaz da je kardinalni broj partitivnog skupa prirodnih brojeva jednak kardinalnom skupu realnih brojeva (skraceno: 2 na alef0 = c). Bio sam sretan dok rezultat nisam ispricao cimeru, koji me je pitao, aha, a ovaj slucaj? ... svejedno, zaboravi :) :)
[ jablan @ 05.02.2005. 23:02 ] @
Citat: Dusan Marjanovic: Ja znam na šta si ciljao, pa se ne vređam, ali neki drugi korisnik ni kriv ni dužan, a igrom slučaja iz Leskovca, mogao bi da se uvredi zbog ovakve izjave.
Uh pa nije čovek napisao nešto ne znam ni ja koliko strašno pa da se neko treći uvredi zbog fore, štaviše kao što zi:: reče, sve je prilično pozitivno. Da je sreća pa da ceo Leskovac (ma šta Leskovac, Srbija!) razmišlja o kompresijama...
Jednostavno, pre nekog vremena se (isto) pojavio momak sa sumnjivim predlogom za kompresiju, pa pomislih da nisu neki rod.
Ajde da ispoštujem protokol: izvinjavam se ako sam ikog uvredio svojim komentarom. [ MajorFatal @ 07.02.2005. 03:22 ] @
A gde je ono: “Tako se ne prave aeroplani, a bogami ni kompresori”?
Necu koristiti varijablu za lociranje zeljenog fajla, vec nov fajl koji se sastoji samo iz nula tj. sve dok ne dodj do “poklapanja” sa pocetnim fajlom za svaki novo napravljeni fajl generisacu po jednu novu nulu I smestati je u novi fajl “sa strane”. Takav novonastali fajl posto je izuzetno jednolik tj. sastavljen je samo od nula savrsen je za pamcenje/kompresovanje uz pomoc “stare” vreste kompresije x*0 (pa I red je da “stara” vrsta kompresije pomogne “novoj” narocito sad prilikom nastajanja;) Tako bih fajl 11010010 iz mog prvog javljanja zapisao kao 10/210*0, a “najgori” (po Alef-u) (da ne kazem i “najozloglaseniji”;) tj. poslednji fajl iz primera sa 1K bi bio umesto 8000/2^8000 ili 8000/y, a y je brojka od oko 2500 cifara ili preciznije 2409 (zahvaljujuci Alef-u opet), dakle poslednji fajl bi bio 8000/301B*0;1b*0 sto bi tumacili kao 301 “prazan” bajt tj. bajt sastavljen samo od nula I jos jedan bit 0. Pretposlednji bi bio 8000/301B*0 sto bi tumacili kao 301 “praznih” bajtova tj. bajtova sastavljenih samo od nula. Prilikom odabira nacina zapisivanja fajlova odlucio sam se za najvece “brojeve” koje sam nasao na trenutnom trzistu. Naime Kilo, Mega, Giga, Tera..su sjajni za ovaj trenutni posao. Nisu brojevi u bukvalnom smislu reci ali su mnogo bolje resenje nego da zapisujem 2500 cifara u svoj kompresovani fajl. Ako bi hteo da kompresujem fajl velicine oko 1MB a ako je ekspanzija za njega I dalje oko 2,5 a generator/brojac ga nasao negde na ¾ puta tj.pred kraj trazenja, zapis bi otprilike bio 8000000/2M700B5b*0 tj. 2 Mega 700 bajta I 5 bita koji su svi nule. Primecujem naravno da broj oznaka u kompresovanom fajlu raste ali to je zanemarljivo u odnosu rast samog fajla koji zelimo da kompresujemo. Ko sto rekoh veci fajl – vece iskoriscenje tj. veci stepen kompresije.
[ MajorFatal @ 07.02.2005. 03:23 ] @
Duzan sam naravno I par objasnjenja u vezi sa javljanjem od 05.02.2005:
Do zbrke sa koriscenjem varijable u cilju lociranja trazenog fajla doslo je na sledeci nacin: Stvarno sam mislio da vrednost varijable Extended mogu da zapisem sa 20 cifara. U mojoj knjizi na srpskom jeziku lepo pise: Opis varijable Extended: Broj cifara: 19-20; Velicina 10 bajtova. Kada sam kasnije pogledao prirucnu pomoc Delphi-ja lepo je na engleskom pisalo sve isto sto sam primetio da je kolona Significant digits (eng. Znacajne cifre) prevedena kao Broj cifara. Valjda se misli da je onih par hiljada cifara posle prvih 19-20 beznacajno? Size in bytes: I dalje 10.
Te sad ja imam par pitanja za tebe Alef. U najboljem slucaju 1 bajt za kodovanje, u najgorem slucaju 2409 (bita) tj 301 bajt? Siguran sam za ShortInt varijablu da se nece mrdnuti sa za nju predvidjene velicine od 1 bajt ma sta upisao u nju. Ima raspon vrednosti -127 +127 tj 256 razlicitih vrednosti, pretpostavljam I da je konstruisana kao neka vrsta brojaca? Ako je iskoristim za zapisivanje vrednosti -127, -1, 0, 1 ili 127 uvek ce u memoriji zauzimati 1 bajt koliko je I predvidjeno za nju? Kao I Integer -32768 +32768 uvek ce zauzimati 2 bajta I kad u nju upisem 1 I kad upisem 32000? A LongInt 4 bajta. Na koji nacin varijabla Extended uspeva da se “smanji” na 1 bajt ako u nju upisem manji broj tj. ako fajl nadjem na pocetku pretrage, a da se prosiri na 300 bajta ako upisem veci broj tj. ako fajl nadjem pri kraju pretrage. Kako je konstrusana? Ako je za nju po specifikaciji rezervisano 10 bajtova gde dobija dozvolu da se prosiri/smanji, ko joj daje tu dozvolu?
Sto se tice drugog dela koda, o poredjenju stringova stvarno ne znam nista. Ni kako se porede ni koliko bi vremena trebalo za to. Ipak ako budem mogao uploadovacu program BerMetar koji simulira BER merenje na digitalnoj liniji tako sto generise pseudoslucajnu sekvencu bita, koduje je AMI ili HDB3 kodom zatim umece pogresne bite u kod I na kraju prilikom dekodovanja na osnovu krsenja pravila kodovanja zakljucuje koliko pogresnih bita je ubaceno. Program poredi veoma duge nizove bita (do 400000000 ~ 47,6GB) koji doduse ni u jednom trenutku nisu nigde zapisani vec samo neko vreme postoje u registrima. Poredjenje 2 niza od po 47GB bit po bit obavi se za ~ 45 sec.
-
Sorry nisam mogao da uploadujem program (cak ni zipovan):(
[ stsung @ 07.02.2005. 22:05 ] @
Pozd.
Da napomenem, bez ulazhenja u dubinu gorenavedenog ... mislim da do trenutka kada bi tehnologija dostigla procesnu moc za rad nekog "naprednijeg" nachina kompresije od kopresija koje danas postoje, ta ista tehnologija bi u sferi velichina hard diskova (ili kako se jelda tada budu zvali) i brzine komunikacija verovatno pojam kompresije napravila besmislenim
Svako dobro. [ Ivan Dimkovic @ 07.02.2005. 22:22 ] @
Citat:
U trenutku kad generator istancuje fajl 11010010 zapisujem da je to npr. 175-ti fajl po redu.
MajorFatal, ovo sto si ti opisao se ostro krsi sa Shannonovom teorijom informacija (mislim da bi stvarno trebalo da procitas taj rad) - sspasic ti je vec pokazao gde si pogresio u rezonu.
Nije nista strasno, svi mi ponekad pogresimo u rezonu - nemoj samo previse da "odlutas" :-) Ako si nameracio da uzmes pare od venture capitala, mislim da bi morao malo bolje da smislis strategiju, oni su posebno alergicni na ideju revolucionarnih kompresija - pogotovu posle fijaska sa ZeoSync i slicnim firmama :-)
Procitaj i arhive USENET grupe comp.compression - pogotovu FAQ, gde su primeri vrlo slicni tvojem opisani i pokazano je zasto ne rade (groups.google.com) [ MajorFatal @ 08.02.2005. 07:01 ] @
Citat: caboom: da ponovim, po Szasz-u se to naziva shizofrenija...
da ponovim, po nepisanom pravilu to se zove PS. od eng. Post Scriptum
Citat: Ivan Dimkovic: MajorFatal, ovo sto si ti opisao se ostro krsi sa Shannonovom teorijom informacija (mislim da bi stvarno trebalo da procitas taj rad) - sspasic ti je vec pokazao gde si pogresio u rezonu.
Sve ispred cega sam napisao npr. tumaciti kao na primer: "da sam ga nasao na npr. 175-om mestu se vise odnosilo na to kad ga nadjem kako cu da upamtim gde sam ga nasao tj. da dojavim generatoru da je na tom i tom mestu u nizu fajlova iste velicine i da to na neki nacin uspem da upamtim do sledece potrebe za tim podatkom tj. "regenerisanja" fajla. Lako je za fajl od 10 bita odrediti gde je to tacno. A kad budem pozeleo da koristim primer sa fajlom od 1GB? Hocete i onda brzo da mi dojavite na kom se on mestu tacno nalazi? Ne mislim da fajl koji sam takodje "lupio" samo primera radi na 175-om mestu, znam da je na 210-om. U medjuvremenu sam objasnio i kako to nameravam da zapisem. A narocito kako to nameravam da zapisem za vece fajlove.
[ Ivan Dimkovic @ 08.02.2005. 08:02 ] @
Ok, ako tako cvrsto verujes u to, probaj da to implementiras - videces da jednostavno nece raditi - jer ce ti za vecinu simbola trebati vise prostora da ih smestis i opises nego u originalu.
Svaki signal (konacni niz karaktera da se ogranicimo) ima jednu vrednost koja se zove entropija, i koja oblikuje teoretski minimum sa kojim ta ista informacija moze da se opise.
Vidi, zakon o informaciji za informaticare ti je isto sto i zakon termodinamike za fizicare - danas se manje-vise uzima za nesto sto se uopste ne dovodi u pitanje, i to sa debelim razlogom.
[ Reljam @ 08.02.2005. 08:56 ] @
MajorFatal, jedna stvar mi nije jasna kod tvog algoritma: kako se pravi generator za proizvoljni fajl?
[ zi:: @ 08.02.2005. 14:11 ] @
Ja vec razmisljam da ovo nije neka provokacija ... Odgovorili su ti mnogi koji su itekako kompetentni u ovoj oblasti sa vrlo stalozenim i razumnim objasnjenjem, a ti i dalje po svom.
Svejedno, ako ne uspes nas da ubedis, obrati se Jutarnjem programu RTS1, tamo se obicno javljaju progresivni naucnici koji su izmislili auto-motor na vodu ili elektromotor bez rotora, pa ce se naci i za beskonacnu kompresiju mesta.
Javi kako je proslo
[ MajorFatal @ 09.02.2005. 05:23 ] @
Citat: Ivan Dimkovic: jer ce ti za vecinu simbola trebati vise prostora da ih smestis i opises nego u originalu.
1. Koju vecinu simbola? Prilikom zapisivanja kompresovanog fajla nameravam da koristim deset cifara decimalnog sistema I b,B,M,G,T sto je jos pet, I jedan za razdvajanje dva zapisa u kompresovanom fajlu sve ukupno: 16. U slucaju pojave vrednosti iznad Tera za koju ne znam kako ce se zvati ali znam zasigurno da ce biti tacno 1024 Terabajta broj simbola mi se duplira sa 16 na 32 ali to nije nista u poredjenju sa povecanjem broja/velicine fajlova koje cu moci da kompresujem tj sa povecanjem sa T na 1024 T.
Citat: Ivan Dimkovic:
Vidi, zakon o informaciji za informaticare ti je isto sto i zakon termodinamike za fizicare - danas se manje-vise uzima za nesto sto se uopste ne dovodi u pitanje, i to sa debelim razlogom.
2.Mislim da ga nisam ugrozio, to sto neki tvrde da sve pokusavam da spakujem u 16 bajta ili 1 double znak je da nisu dobro procitali kako izgleda kompresovan fajl.
Citat: Reljam: MajorFatal, jedna stvar mi nije jasna kod tvog algoritma: kako se pravi generator za proizvoljni fajl?
3. Potencijalni engine/program/implementacija ga pravi dinamicki. Ali ne u smislu da se ucitava iz nekakve dll biblioteke jer bi u tom slucaju za nase potrebe ta biblioteka 1. narasla do u beskonacno 2. bila nefunkcionalna – jos jedna pretraga, jos jedno uporedjivanje. Vec onako bas dinamicki tj. u hodu. Ako nista bar ima jednostavan zadatak napraviti generator(brojac) fajlova te I te duzine (N) koji ce poceti da generise fajlove od “prvog” tj. onog sa svim nulama pa sve do “prepoznavanja”. To je ujedno I jedan od retkih delova programa koji ostaje tu gde jeste tj. ne brise se po zavrsenom poslu.
Citat: zi::: Ja vec razmisljam da ovo nije neka provokacija ... Odgovorili su ti mnogi koji su itekako kompetentni u ovoj oblasti sa vrlo stalozenim i razumnim objasnjenjem, a ti i dalje po svom.
4. I ne samo to odgovorili su mi I da “zipujem brojac” a posle se nisu potrudili da citaju dalje I da vide da sam u post-u od 07.02.2005. zipovo ono sto sam u svom prvom post-u nesretnim izborom terminologije nazvao brojacem. I to sam ga zipovo iz sve snage, bas je bio zgodan za zipovanje.
Citat: zi::: Svejedno, ako ne uspes nas da ubedis,
5. Nikog nista ne ubedjujem
Citat: zi::: obrati se Jutarnjem programu RTS1, tamo se obicno javljaju progresivni naucnici koji su izmislili auto-motor na vodu ili elektromotor bez rotora, pa ce se naci i za beskonacnu kompresiju mesta.
6. Hvala za savet I za informaciju. Za auto-motor prvi put cujem, cuo sam za neke motore sa unutrasnjim sagorevanjem koji koriste alternativne izvore energije voda, plemeniti gasovi itd. Provericu.
[ Reljam @ 09.02.2005. 07:32 ] @
Cekaj, opet mi nije jasan taj generator, zvuci kao da je brojac identican vrednosti fajla. Ako bi imao fajl koji izgleda ovako:
0x1234567812345678
Kako bi izgledao generator i koja bi bila vrednost brojaca?
[ Shadowed @ 09.02.2005. 13:18 ] @
Interesantno je to sto kaze za zapisivanje samo sa jedinicama. Ono kao, ako se 42. generisano fajl poklapa sa onim koji treba da se kompresuje to ce biti 111111111111111111111111111111111111111111 ili 42*1. Ono sto mu nije palo na pamet je da kad to uradi sa realnim fajlom imace zapis o broju jedinica istovetan originalnom fajlu sto samo znaci da ce povecati originalni fajl za dva bajta - "*1".
BTW, ako nekoga interesuje (skoro) beskonacna kompresija slika moze pogledati temu http://www.elitesecurity.org/tema/93788 sa programom koji sam dao u ovoj poruci. Nije lose procitati bar prvih nekoliko postova da se vidi o cemu se radi pre isprobavanja prorama.
Eto, 1440000*2 11520000 bajtova smesteno u 24KB [ filmil @ 09.02.2005. 13:28 ] @
Citat:
Citat: Citat: Ivan Dimkovic:
Vidi, zakon o informaciji za informaticare ti je isto sto i zakon termodinamike za fizicare - danas se manje-vise uzima za nesto sto se uopste ne dovodi u pitanje, i to sa debelim razlogom.
2.Mislim da ga nisam ugrozio, to sto neki tvrde da sve pokusavam da spakujem u 16 bajta ili 1 double znak je da nisu dobro procitali kako izgleda kompresovan fajl.
I ja bih rekao da ga nisi ugrozio, taman posla. Tvoj algoritam ima dva problema:
1) Jako je nepraktičan jer ima eksponencijalnu složenost.
2) Zapravo ne uradi ništa sa podacima, već je u najboljem slučaju samo permutacija na skupu svih datoteka zadate dužine N. Inverz se uvek lako nađe kao inverzna permutacija (u smislu da je lako napisati algoritam; samo treba sačekati jaaako dugo da se izvrši, da zanemarimo to sad), ali na žalost odnos veličina datoteke posle i pre kompresije ne može biti manji od 1.
Iako u novinama s vremena na vreme mogu da se pročitaju priče o neverovatnim algoritmima za kompresiju (ovde se recimo vrti priča, izdaju knjige i pišu hvalospevi o izvesnom inženjeru koji je smislio neverovatan sistem za kompresiju, ali je umro dan pre nego što će u Filipsu (Philips) napraviti demo i potpisati ugovor vredan više milijardi čvrste valute; naravno i svi njegovi spisi i laboratorijski logovi su misteriozno nestali), kompresija nije nikakva mitologija. U pitanju je deo teorije informacija koja je vrlo dobro utemeljena matematička disciplina. Iako put do savršene kompresije nije zacrtan, tačno je poznato dokle ta savršena kompresija može da komprimuje datoteku. Ako recimo hoćeš da kompresuješ datoteku dužine N, jedini, ali zaista jedini način da to uspeš jeste da nekako znaš da se od svih mogućih datoteka dužine N ne mogu javiti baš sve datoteke. Pretpostavimo da nekako znamo koje se datoteke javljaju a koje ne javljaju. Onda napravimo prenumeraciju: jedan brojač koji broji preko svih datoteka koje mogu da se jave. Pošto njih ima manje od 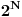 , brojač je manje dužine od polazne datoteke pa smo dobili kompresiju. To je tvoja osnovna ideja koja je gore izložena.
Problemi su: 1) to jako dugo traje, 2) ne postoji jednostavan način da znamo koja se datoteka može pojaviti a koja ne i 3) ako sigurno znamo da je svaka od datoteka moguća onda je apsolutno nemoguće išta kompresovati bez gubitaka. 1) je očigledno, jer je algoritam eksponencijalan. 3) je dokazao Šenon. 2) je problematično jer je praktično nemoguće napraviti brojač koji bi radio to što želiš. Zato se ljudi pomažu statistikom koja je u neku ruku surogat za univerzalno znanje o svim datotekama. Statistike naravno zavise od uzorka (podsećanje: statistika je funkcija na skupu slučajnih promenljivih) a pošto su uzorci razni (slika, zvuk, datoteke, tekst itd), to imaš mnogo različitih statistika koje rade dobro u nekom ograničenom opsegu slučajeva.
Drugim rečima: ideja koju imaš je ispravna u principu, ali od nje nikada neće direktno da ispadne neki koristan algoritam — osim u slučaju da tačno znaš raspodelu svih datoteka — u kom slučaju je sasvim opravdano ono što si rekao da ti je bog došapnuo: on je verovatno jedini kandidat za takvo univerzalno znanje. (U računarskoj terminologiji se radije koristi izraz oracle, što izbegava religiozne konotacije).
Za kraj, da iskomentarišem onu Ivanovu referencu na Šenona i da bacim par linkova.
Nekad jeste lepo vratiti se i popiti vodu sa izvora, ali od Šenonovog vremena pojavili su se ljudi koji teoriju informacija objašnjavaju na daleko lepši i lakši način. (Na žalost pomenute knjige nema na Internetu a i malo je skupa.)
Od javno dostupnih knjiga za čitanje preporučujem knjigu (koja je izašla na hartiji ali je dostupna i online) Dejvida Mekkeja (David MacKay), koja odlično i matematički precizno opisuje mnoge probleme koji imaju veze sa teorijom informacija. Kompresija je samo jedna od njih.
Dejvid Mekkej je inače jedan od nekoliko ljudi koji su izmislili danas najefikasnije metode kodiranja tako da bi trebalo da zna šta priča, knjiga je puna slika i primera koji pokazuju čemu sve to služi i od nje možete da napravite 3 do 4 prilično zahtevna kursa za neke redovne, odnosno postdiplomske studije. Uzgred, tu se nalazi i problem Šeširdžija koji se pojavio u forumu Matematika pre nekoliko meseci.
Takođe možete pogledati i [url=http://lthc www.epfl.ch/mct/index.php]knjigu u pripremi Ruedigera Urbankea[/url] koja se doduše bavi kodiranjem za prenos podataka (što je „druga strana medalje“ od kompresije) i takođe je [url=http://lthc www.epfl.ch/papers/mct.ps]dostupna online[/url].
Samo da napomenem da nemam nameru da pridikujem kako treba ili ne treba prilaziti kompresiji podataka. Ako pogledate gore pomenute knjige i prošarate Internetom videćete da o kompresiji svakako nije rečena poslednja reč. Ali kao što ćete se složiti da nema smisla da budem stolar ako nemam alat — čekić, eksere, turpiju itd. — tako nema mnogo smisla baviti se i kompresijom podataka a da se ne pročitaju osnovne stvari.
f [ MajorFatal @ 10.02.2005. 07:37 ] @
Citat: Shadowed: Interesantno je to sto kaze za zapisivanje samo sa jedinicama. Ono kao, ako se 42. generisano fajl poklapa sa onim koji treba da se kompresuje to ce biti 111111111111111111111111111111111111111111 ili 42*1. Ono sto mu nije palo na pamet je da kad to uradi sa realnim fajlom imace zapis o broju jedinica istovetan originalnom fajlu sto samo znaci da ce povecati originalni fajl za dva bajta - "*1". ;)
In medias res-stari latini po zanimanju-balkanci
42*1 po novoj nomenklaturi bice 42bita=42/8=5celih bajtova+2bita=pisem u kompresovani fajl
B5b2..tj zapis koji u memoriji zauzima 4*8=32bita a posto smo krenuli od 42 bita a stigli do
32 tu bi negde trebalo da bude i teoretska granica nove kompresije. Inace ispravno
razmisljanje naveo sam primer sa nulama ali nije bitno da budu samo nule bitno je da fajl bude
"jednolican" tj. mogu i samo jedinice, a nije lose resenje 0101itd smanjuje drugi deo
kompresovanog fajla na pola (ako se potrudim da zapamtim samo nule ili samo jedinice)
resenja ima dosta ipak prvo do kojeg sam dosao izgledalo je ovako sve nule i jedna jedina
jedinica na mestu "prepoznavanja" pocetnog fajla. I slikom:
Ako trazim fajl:
10100110101
A na brojacu:
00000000000 0-Ovde pocinje "jednolicni" fajl tj fajl podlozan "staroj" kompresiji
00000000001 0
. 0
. 0
ga nadjem ovde: 0
10100110101 1-Jedna jedina jedinica tj. jedan jedini bit jedan u celom fajlu
. 0
. 0
a brojac da je 0
nastavio do kraja 0
bi stigo dovde: 0
11111111110 0
11111111111 0-Jednolicni fajl se zavrsava ovde.
Kasnije sam skapirao..sve ostalo!
HVALA! [ MajorFatal @ 10.02.2005. 11:57 ] @
Daklem, ispravka jedne uocene greske u racunu: posto sam se ranije u ovim postovima odlucio za 16 oznaka kojima cu kodovati zapis u kompresovanom fajlu, za tih 16 oznaka trebace mi po 4 bita za svaku a ne po 8 kao u prethodnom postu, dakle umesto 4*8 treba da stoji 4*4=16 bita iskoriscenih. te takodje: Posto je "jednolicni" niz dug 42 bita a sigurno se nalazi u rasponu do 2^N, 2^N mora biti (najmanje) 64 te ce jedan od najmanjih fajlova za koga ovo vazi biti "dug" 8 bita ili 1 bajt, ali taj svakako nece moci da bude kompresovan ovom metodom.
[ Gojko Vujovic @ 10.02.2005. 12:01 ] @
Pošto ja mislim da te niko ovde ne razume... hajde ti napravi kompresor i dekompresor i postani poznat i zaradi velike pare.. i mi ćemo onda da lupamo glavu kako smo oterali talenta sa foruma.
Ili će se desiti suprotno tj. shvatićeš šta pričaju ovi ljudi gore.
[ Shadowed @ 10.02.2005. 12:48 ] @
Eh, nemoj tako, niko ga ne juri sa foruma.
[ Not now, John! @ 10.02.2005. 13:20 ] @
A šta, ako bi se, umjesto broja inkrementiranja fajla (koji zauzima koliko i originalni fajl, pa nema smisla) pamtila veličina fajla, MD5 string i redni broj fajla koji zadovoljava taj MD5 string? Broj fajlova TE veličine koji zadovoljavaju TAJ MD5 string ima mnogo manje od 2n gdje je n broj bita fajla.
Ovo je, naravno, samo teorija. U praksi bi ovakva kompresija i dekompresija, trajala veoma dugo.
Znači: 1 MB, 2f65bc103fafefd176bf588351f1525b, 12
Onda krenete od 000 ... 000 do 111 ... 111 i uzimate u obzir samo one fajlove koji imaju traženi MD5 string. Izaberete 12-ti po redu i to je traženi fajl.
[ filmil @ 10.02.2005. 13:40 ] @
Citat: Onda krenete od 000 ... 000 do 111 ... 111 i uzimate u obzir samo one fajlove koji imaju traženi MD5 string. Izaberete 12-ti po redu i to je traženi fajl.
Za MD5 se pretpostavlja da daje uniformnu raspodelu datoteka po prostoru ključeva. To znači ako je datoteka dugačka N bita, a MD5 ključ m bita (gde je m manje od N), za opis rednog broja svih datoteka će trebati tačno N-m bita. Drugim rečima, nema kompresije jer je potrebno m bita za MD5 i N-m za redni broj.
Da bi kompresija radila, moraš da izmisliš neki „digest“ za koji može da se dokaže da ne daje uniformnu raspodelu po prostoru ključeva, odn. da je očekivani broj bita za kodiranje manji od N-m.
Ideja ti nije pogrešna sama po sebi (kao ni ideja koju je dao OP), ali u oba slučaja nema nikakve garancije da će indeks da zahteva manje od N-m bita za pamćenje.
Kod OP-a je bilo m=0, kod tebe je m=160, ili koliko već bita ima MD5, ali priča je potpuno ista.
f [ zi:: @ 10.02.2005. 19:25 ] @
Sve me ovo podseca na matematicke glavolomke koje su imale cilj da zbune: lepo i logicno izgleda na prvi pogled, nakon par minuta razmisljanja znas da nije istina, ali treba otkriti gde je problem.
Znate sigurno za onu algebarsku caku da je 1=2 (a zapravo se u jednom koraku krati sa nulom), ili za malo starije ono sa integralima da je 0=1 (a zaboravimo konstantu koja se mora dodati) ....
Kada sam prvi put odgovarao na ovaj post, hteo sam dopisati:
... ako ikada sacekas da se ovaj algoritam izracuna.
Nisam, jer je toliko ocigledno da je inicijalni algoritam ovog posta toliko vremenski neefikasan.
Kasnije smo pricali samo o prostoru (efikasnosti kompresije), ali ne i o vremenu algoritma, makar su obe dimenzije jako bitne.
Cuo sam da je neko resio problem trgovackog putnika u realnom vremenu, makar mu treba nerealni prostor. well...
Sto se tice trgovackog putnika, jednom sam posetio prijatelja (tada je jos bio srednjoskolac) koji je resavao zadatke takmicenja mladih informaticara iz Madjarske, zadaci su mogli da se nose kuci. Jedan od zadataka je bio problem trgovackog putnika(?!). Pitam, kako si resio ovo? Kaze, lako je bilo, ali kada unese neki veci broj, kompjuter nesto previse razmislja ;) U zadatku je bilo naglaseno da algoritam treba da radi za 20 gradova. :)
Smatram ovo pozitivnim, oni koji su sastavljali test hteli su videti ko ce kako napasti ovaj zadatak, i do kojih ce zakljucaka doci.
Izvinjavam se na digresiji, ali, ako nista drugo, inicijalni post je izazvao mnogo interesantnih komentara, pa rek'o, bolje ovde da postujem, nego da pocinjem nove jalove teme.
A sto se tice kompresije: literature, hvala bogu ima. A kada se smisli algoritam --> na implementaciju, to zna isto biti uzbudljivo.
[ Not now, John! @ 10.02.2005. 21:42 ] @
Citat: filmil: Za MD5 se pretpostavlja da daje uniformnu raspodelu datoteka po prostoru ključeva. To znači ako je datoteka dugačka N bita, a MD5 ključ m bita (gde je m manje od N), za opis rednog broja svih datoteka će trebati tačno N-m bita. Drugim rečima, nema kompresije jer je potrebno m bita za MD5 i N-m za redni broj.
Proznajem da ne razumijem ovo... Ne bavim se kompresijom, ali mi je čitjaući ovu temu palo na pamet ovo što sam napisao u prethodnom postu.
Nedavno se Net-om proširila vijest da je neka grupa matematičara uspjela da slučajni niz 0 i 1 kompresuje u odnosu 1:10. To bi značilo da se svaki fajl (bez obzira koliko heterogen on bio) može bez gubitaka smanjiti 10 puta. Sigurno se ne radi o statističkom kodovanju koje ima drugačije ograničenje (nisam još polagao osnove telekomunikacija ;-) ).
Tada sam razmišljao o faktorijelima, npr. 123! daje mnogo veliki broj, pa bi to mogla da bude neka kompresija. Problem je što se ne može svaki veliki broj predstaviti kao faktorijel manjeg broja.
Možda nešto sa Gamma funkcijom? Lupam. [ Ivan Dimkovic @ 10.02.2005. 21:47 ] @
Citat:
Nedavno se Net-om proširila vijest da je neka grupa matematičara uspjela da slučajni niz 0 i 1 kompresuje u odnosu 1:10.
Onda taj niz nije slucajan ;) (think :-)
[ kobrejabre @ 11.02.2005. 00:47 ] @
Citat: Not now, John!:
Nedavno se Net-om proširila vijest da je neka grupa matematičara uspjela da slučajni niz 0 i 1 kompresuje u odnosu 1:10. To bi značilo da se svaki. fajl (bez obzira koliko heterogen on bio) može bez gubitaka smanjiti 10 puta.
Sto znaci da bi brojem primena tog algoritma (prvo na pocetni fajl a onda i na rezultujuce fajlove) koji tezi beskonacnosti velicina kompresovanog fajla tezila nuli...
Svega toga ne bi bilo kada bi se ljudi prisetili barem srednjoskolske matematike... [ Not now, John! @ 11.02.2005. 11:22 ] @
Citat: kobrejabre: Sto znaci da bi brojem primena tog algoritma (prvo na pocetni fajl a onda i na rezultujuce fajlove) koji tezi beskonacnosti velicina kompresovanog fajla tezila nuli...
Svega toga ne bi bilo kada bi se ljudi prisetili barem srednjoskolske matematike...
Samo prenosim vijest :-) [ sallle @ 16.02.2005. 18:46 ] @
Eo moje misljenje vezano za kompresiju.
Ne treba smisljati algoritam koji ce da dobro pakuje fajlove.
Treba smisljati fajlove koji ce da budu dobro pakovani...
over and out
[ Dark Icarus @ 20.02.2005. 01:00 ] @
Citat: MajorFatal:U slucaju pojave vrednosti iznad Tera za koju ne znam kako ce se zvati ali znam zasigurno da ce biti tacno 1024 Terabajta
Prefiksi iza Tera:
Peta (P) = 10^15 ili (ako se koristi u informatici) 2^50
Egza (E)= 10^18 ili 2^60
Zeta (Z)= 10^21 ili 2^70
Jota (I)= 10^24 ili 2^80
Mislim, kada već planiraš da kompresuješ velike količine podataka, onda pucaj visoko... Samo nemoj da ti se fajl od 1 terabajta arhivira u fajl od jednog jotabajta... [ MajorFatal @ 25.12.2005. 10:30 ] @
Zdravo drugari. Nismo se culi odavno pa cu iskoristiti priliku da vas podsetim da na stranicama elitesecurity foruma trune I skuplja prasinu I paucinu najznacajniji noviji softverski pronalazak: kompresija random-like podataka.
Ipak sam sam kriv napravio sam mnogo gresaka prilikom prezentovanja ove ideje pa cu se potruditi da ih ovim putem ispravim. Najznacajniju gresku sam napravio prilikom objasnjenja zapisivanja kompresovanog fajla. Tada sam tvrdio da drugi deo kompresovanog fajla odnosno duzinu onog “praznog” fajla treba zapisati uz pomoc Kilo, Mega , Giga, Tera bita. Presao sam se. Drugi deo kompresovanog fajla treba zapisati kao zbir eksponenata celih brojeva I ostaviti da se tacna vrednost istog izracunava tek prilikom dekompresije. Da podsetim: to je zapis 2^8000 (koji zauzima 48 bita u memoriji) umesto 2500 cifara (koji zauzimaju 20000 bita u memoriji) tj mnogo manje I od 8000 (duzina originalnog fajla- primer sa fajlom od ~1Kb) bita u odnosu na koje se racuna kompresija. 48 bita u odnosu na 8000 je znacajna usteda.
Naravno postavlja se pitanje sta sa fajlovima na pozicijama izmedju 2^7999 I 2^8000 kojih takodje ima izuzetno mnogo. Moj predlog je da se koriste eksponenti I drugih brojeva osim 2 koji ce u zbiru davati trazeni broj.
Takodje se postavlja pitanje kako odrediti eksponente koji ce davati trazeni broj. To vec ne znam, ja sam kontao nesto sa korenovanjem pa trazenjem najpribliznijih celobrojnih vrednosti ali za to bi mi verovatno rekli da je nemoguce ili da je vremenski neefikasno pa cu ovo pitanje ostaviti pametnijima od mene.
Sve u svemu kako ovo nije jedina greska koju sam napravio posle mnogo premisljanja odlucio sam se da pokrenem novu temu: “Kompresija random-like podataka” u kojoj cu na mnogo precizniji nacin izneti kako sam zamislio ovu kompresiju I nadam se oslobodjenu gresaka. Pozivam vas da ucestvujete.
[ Ivan Dimkovic @ 25.12.2005. 10:41 ] @
Ogovoreno ti je na istoj temi zasto ta stvar ne moze da funkcionise u praksi.
Prelistaj malo comp.compression USENET arhivu - ima bar 1000 istih pokusaja i lepa argumentacija zasto to nije moguce.
[ MajorFatal @ 25.12.2005. 10:46 ] @
Ama prelisto sam comp compresion odavno. Jeste smesno i tuzno u isto vreme ali bar svedoci da mnogi ljudi osecaju da je ipak moguce.
[ Ivan Dimkovic @ 25.12.2005. 10:58 ] @
"Osecati" je losa stvar, to sto "osecas" se krsi sa osnovim zakonom o informaciji, a onda nije bas dobro.
Bez uvrede, mnogi ljudi mogu i da "osete" da mogu da polete - pa se cela stvar obicno jako lose zavrsi po njih ;)
[ MajorFatal @ 26.12.2005. 10:11 ] @
Citat: Ivan Dimkovic:
Bez uvrede, mnogi ljudi mogu i da "osete" da mogu da polete - pa se cela stvar obicno jako lose zavrsi po njih ;)
To se ne bi moglo reci za ljude koji su osecali i verovali da mogu da polete masinom tezom od vazduha sve do brace Rajt. To sto nisu uspeli ne znaci da nisu bili u pravu. [ Ivan Dimkovic @ 26.12.2005. 10:44 ] @
Vidi, to sto su braca Rajt zamislila je ipak bilo sasvim u skladu sa fizickim zakonima, samo je to tad obicnom coveku izgledalo jako tesko izvodljivo.
To sto si ti zamislio se direktno krsi sa zakonima o prenosu informacija, a i matematicki je netacno.
Braca Rajt nisu mislila da mogu da lete bez protoka vazduha ;) Kao sto ne moze biti kompresije bez viska informacija ;) Sorry.
[ jablan @ 26.12.2005. 10:56 ] @
Citat: Ivan Dimkovic: Braca Rajt nisu mislila da mogu da lete bez protoka vazduha ;)
Kahm. A raketni motor? ;) [ zi:: @ 26.12.2005. 11:40 ] @
@MajorFatal:
Ako te zdravorazumski ne možemo ubediti, zašto ne probaš da napišeš programče u bilo kojem programskom jeziku, i probaš kompresovati par random fileova?
Već si bio dovoljno otvoren i ljubazan da podeliš sa nama svoj super/truper algoritam, napiši i programče, pa da vidimo.
Do tada, argumenti i iskustvo većine od nas ovde stoje na drugoj strani :)
[ MajorFatal @ 26.12.2005. 20:52 ] @
Da znam da programiram ne bih se obracao vama na elitesecurity za pomoc. Ucio sam od srede do petka al... sve sto sam naucio je da u Delphy-u u proceduri buton1.click izmedju begin i end upisem Close; za dugme ciji sam caption prethodno imenovao u exit. Posle mi to dugme zatvara formu, cool a?
Copyright (C) 2001-2026 by www.elitesecurity.org. All rights reserved.
|